


Journal of Computer Applications ›› 2022, Vol. 42 ›› Issue (10): 3025-3032.DOI: 10.11772/j.issn.1001-9081.2021091571
Special Issue: 人工智能
• Artificial intelligence • Previous Articles Next Articles
Runchao LIN, Rong HUANG, Aihua DONG
Received:2021-09-06
Revised:2022-01-10
Accepted:2022-01-17
Online:2022-04-15
Published:2022-10-10
Contact:
Aihua DONG
About author:LIN Runchao, born in 1996, M. S. candidate. His research interests include deep learning, image processing.Supported by:林润超, 黄荣, 董爱华
通讯作者:
董爱华
作者简介:第一联系人:林润超(1996—),男,四川宜宾人,硕士研究生,主要研究方向:深度学习、图像处理基金资助:CLC Number:
Runchao LIN, Rong HUANG, Aihua DONG. Few-shot object detection based on attention mechanism and secondary reweighting of meta-features[J]. Journal of Computer Applications, 2022, 42(10): 3025-3032.
林润超, 黄荣, 董爱华. 基于注意力机制和元特征二次重加权的小样本目标检测[J]. 《计算机应用》唯一官方网站, 2022, 42(10): 3025-3032.
Add to citation manager EndNote|Ris|BibTeX
URL: https://www.joca.cn/EN/10.11772/j.issn.1001-9081.2021091571
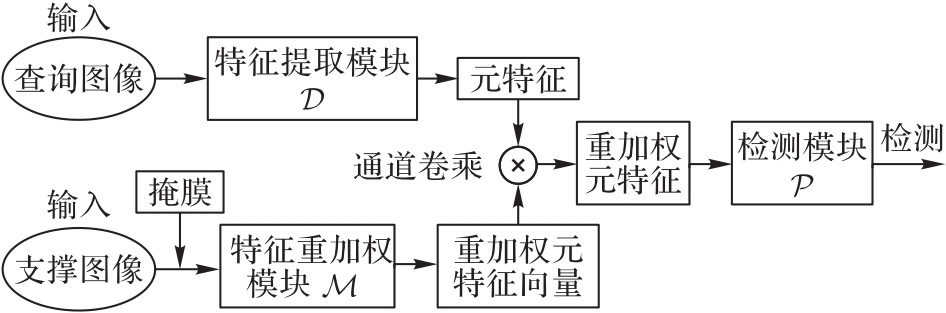
Fig. 1 Framework of original meta-feature transfer model

Fig. 2 Overall structure of Up-YOLOv3

Fig. 3 Structure of CBAM-based attention mechanism

Fig. 4 Visual attention map

Fig. 5 Improved mask

Fig. 6 Structure of SE-SMFR module
| 模型 | 新类组合1 | 新类组合2 | 新类组合3 | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| k=1 | k=2 | k=3 | k=5 | k=10 | k=1 | k=2 | k=3 | k=5 | k=10 | k=1 | k=2 | k=3 | k=5 | k=10 | |
| LSTD[ | 10.8 | 12.2 | 23.9 | 29.5 | 33.4 | 10.2 | 14.5 | 20.5 | 26.6 | 32.4 | 10.1 | 14.4 | 19.7 | 25.8 | 34.7 |
| Base-YOLOv2[ | 12.3 | 17.8 | 25.8 | 31.3 | 35.1 | 10.2 | 16.3 | 22.4 | 32.1 | 36.5 | 12.7 | 20.2 | 20.5 | 31.0 | 36.2 |
| Base-YOLOv3 | 15.2 | 20.7 | 27.5 | 33.1 | 38.2 | 12.4 | 19.8 | 24.1 | 35.9 | 39.9 | 14.2 | 25.9 | 24.1 | 35.5 | 40.1 |
| Up-YOLOv2 | 12.1 | 18.2 | 25.2 | 32.4 | 36.9 | 11.5 | 18.1 | 23.5 | 33.2 | 37.2 | 11.4 | 21.4 | 20.6 | 33.4 | 38.9 |
| Up-YOLOv3(本文模型) | 15.5 | 21.2 | 28.1 | 36.2 | 40.3 | 13.9 | 22.6 | 28.8 | 35.6 | 41.9 | 15.1 | 27.8 | 29.6 | 38.4 | 41.7 |
Tab. 1 Comparison of mAP among different models for few-shot object images
| 模型 | 新类组合1 | 新类组合2 | 新类组合3 | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| k=1 | k=2 | k=3 | k=5 | k=10 | k=1 | k=2 | k=3 | k=5 | k=10 | k=1 | k=2 | k=3 | k=5 | k=10 | |
| LSTD[ | 10.8 | 12.2 | 23.9 | 29.5 | 33.4 | 10.2 | 14.5 | 20.5 | 26.6 | 32.4 | 10.1 | 14.4 | 19.7 | 25.8 | 34.7 |
| Base-YOLOv2[ | 12.3 | 17.8 | 25.8 | 31.3 | 35.1 | 10.2 | 16.3 | 22.4 | 32.1 | 36.5 | 12.7 | 20.2 | 20.5 | 31.0 | 36.2 |
| Base-YOLOv3 | 15.2 | 20.7 | 27.5 | 33.1 | 38.2 | 12.4 | 19.8 | 24.1 | 35.9 | 39.9 | 14.2 | 25.9 | 24.1 | 35.5 | 40.1 |
| Up-YOLOv2 | 12.1 | 18.2 | 25.2 | 32.4 | 36.9 | 11.5 | 18.1 | 23.5 | 33.2 | 37.2 | 11.4 | 21.4 | 20.6 | 33.4 | 38.9 |
| Up-YOLOv3(本文模型) | 15.5 | 21.2 | 28.1 | 36.2 | 40.3 | 13.9 | 22.6 | 28.8 | 35.6 | 41.9 | 15.1 | 27.8 | 29.6 | 38.4 | 41.7 |
| 模型 | 基类组合1 | 基类组合2 | 基类组合3 |
|---|---|---|---|
| YOLOv3(上界) | 74.5 | 76.9 | 76.1 |
| LSTD[ | 63.5 | 63.2 | 63.1 |
| Base-YOLOv2[ | 66.2 | 67.2 | 66.9 |
| Base-YOLOv3 | |||
| Up-YOLOv2 | 68.3 | 68.6 | 68.2 |
| Up-YOLOv3(本文模型) | 74.8 | 75.9 | 75.5 |
Tab. 2 Comparison of mAP among different models for large-sample object images
| 模型 | 基类组合1 | 基类组合2 | 基类组合3 |
|---|---|---|---|
| YOLOv3(上界) | 74.5 | 76.9 | 76.1 |
| LSTD[ | 63.5 | 63.2 | 63.1 |
| Base-YOLOv2[ | 66.2 | 67.2 | 66.9 |
| Base-YOLOv3 | |||
| Up-YOLOv2 | 68.3 | 68.6 | 68.2 |
| Up-YOLOv3(本文模型) | 74.8 | 75.9 | 75.5 |

Fig. 7 SE-SMFR visualization
| 组号 | CBAM | SE-SMFR | mAP/% | |
|---|---|---|---|---|
| 大样本图像 | 小样本图像 | |||
| 1 | × | × | 73.5 | 38.9 |
| 2 | √ | × | 72.8 | 40.7 |
| 3 | × | √ | 75.6 | 39.2 |
| 4 | √ | √ | 75.9 | 41.7 |
Tab. 3 Comparison of ablation experimental results
| 组号 | CBAM | SE-SMFR | mAP/% | |
|---|---|---|---|---|
| 大样本图像 | 小样本图像 | |||
| 1 | × | × | 73.5 | 38.9 |
| 2 | √ | × | 72.8 | 40.7 |
| 3 | × | √ | 75.6 | 39.2 |
| 4 | √ | √ | 75.9 | 41.7 |
| 模型 | 参数量/106 | 浮点运算量/GFLOPs | 收敛时间/h |
|---|---|---|---|
| Base-YOLOv2 | 175 | 29.132 | 9.1 |
| Up-YOLOv2 | 178 | 29.346 | 9.7 |
| Base-YOLOv3 | 243 | 37.152 | 10.6 |
| Up-YOLOv3 | 245 | 37.254 | 11.2 |
Tab. 4 Comparison of model size and convergence time
| 模型 | 参数量/106 | 浮点运算量/GFLOPs | 收敛时间/h |
|---|---|---|---|
| Base-YOLOv2 | 175 | 29.132 | 9.1 |
| Up-YOLOv2 | 178 | 29.346 | 9.7 |
| Base-YOLOv3 | 243 | 37.152 | 10.6 |
| Up-YOLOv3 | 245 | 37.254 | 11.2 |
| 1 | SHEN D G, WU G R, SUK H I. Deep learning in medical image analysis[J]. Annual Review of Biomedical Engineering, 2017, 19: 221-248. 10.1146/annurev-bioeng-071516-044442 |
| 2 | 黄元涛. 基于深度学习的藏羚羊检测与跟踪[D]. 西安:西安电子科技大学, 2020: 3-69. |
| HUANG Y T. Detection and tracking of Tibetan Antelope based on deep learning[D]. Xi’an: Xidian University, 2020: 3-69. | |
| 3 | BANSAL A, SIKKA K, SHARMA G, et al. Zero-shot object detection[C]// Proceedings of the 2018 European Conference on Computer Vision, LNCS 11205. Cham: Springer, 2018: 397-414. |
| 4 | RAHMAN, S, KHAN, S, PORIKLI F. Zero-shot object detection: learning to simultaneously recognize and localize novel concepts[C]// Proceedings of the 2018 Asian Conference on Computer Vision, LNCS 11361. Cham: Springer, 2019: 547-563. |
| 5 | ZHU P K, WANG H X, SALIGRAMA V. Zero-shot detection[J]. IEEE Transactions on Circuits and System for Video Technology, 2020, 30(4): 998-1010. 10.1109/tcsvt.2019.2899569 |
| 6 | 潘兴甲,张旭龙,董未名,等. 小样本目标检测的研究现状[J]. 南京信息工程大学学报(自然科学版), 2019, 11(6): 698-705. |
| PAN X J, ZHANG X L, DONG W M, et al. A survey of few-shot object detection[J]. Journal of Nanjing University of Information Science and Technology (Natural Science Edition), 2019, 11(6): 698-705. | |
| 7 | VINYALS O, BLUNDELL C, LILLICRAP T, et al. Matching networks for one shot learning[C]// Proceedings of the 30th International Conference on Neural Information Processing Systems. Red Hook, NY: Curran Associates Inc., 2016: 3637-3645. |
| 8 | FINN C, ABBEEL P, LEVINE S. Model-agnostic meta-learning for fast adaptation of deep networks[C]// Proceedings of the 34th International Conference on Machine Learning. New York: JMLR.org, 2017: 1126-1135. 10.1109/icra.2016.7487173 |
| 9 | SNELL J, SWERSKY K, ZEMEL R S. Prototypical networks for few-shot learning [C]// Proceedings of the 31st Annual Conference on Neural Information Processing Systems. Red Hook, NY: Curran Associates Inc., 2017: 178-181. |
| 10 | MISRA I, SHRIVASTAVA A, HEBERT M. Watch and learn: semi-supervised learning of object detectors from videos[C]// Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2015: 3593-3602. 10.1109/cvpr.2015.7298982 |
| 11 | XING C, ROSTAMZADEH N, ORESHKIN B O. Adaptive cross-modal few-shot learning[C/OL]// Proceedings of the 33rd Conference on Neural Information Processing Systems. [2021-02-27].. |
| 12 | NI J, ZHANG S H, XIE H Y. Dual adversarial semantics-consistent network for generalized zero-shot learning[C/OL]// Proceedings of the 33rd Conference on Neural Information Processing Systems. [2021-02-27].. |
| 13 | REN M Y, LIAO R J, FETAYA E, et al. Incremental few-shot learning with attention attractor networks[C/OL]// Proceedings of the 33rd Conference on Neural Information Processing Systems. [2021-02-27].. |
| 14 | REN S Q, HE K M, GIRSHICK R, et al. Faster R-CNN: towards real-time object detection with region proposal networks[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2017, 39(6): 1137-1149. 10.1109/tpami.2016.2577031 |
| 15 | FAN Q, ZHUO W, TANG C K, et al. Few-shot object detection with attention-RPN and multi-relation detector[C]// Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2020: 4012-4021. 10.1109/cvpr42600.2020.00407 |
| 16 | 徐诚极,王晓峰,杨亚东. Attention-YOLO:引入注意力机制的YOLO检测算法[J]. 计算机工程与应用, 2019, 55(6): 13-23, 125. |
| XU C J, WANG X F, YANG Y D. Attention-YOLO: YOLO detection algorithm that introduces attention mechanism[J]. Computer Engineering and Applications, 2019, 55(6): 13-23, 125. | |
| 17 | REDMON J, FARHADI A. YOLOv3: an incremental improvement[EB/OL]. (2018-04-08) [2021-03-15].. |
| 18 | CHEN H, WANG Y L, WANG G Y, et al. LSTD: a low-shot transfer detector for object detection[C]// Proceedings of the 32nd AAAI Conference on Artificial Intelligence. Palo Alto, CA: AAAI Press, 2018: 2836-2843. 10.1609/aaai.v32i1.11716 |
| 19 | KANG B Y, LIU Z, WANG X, et al. Few-shot object detection via feature reweighting[C]// Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision. Piscataway: IEEE, 2019: 8419-8428. 10.1109/iccv.2019.00851 |
| 20 | REDMON J, FARHADI A. YOLO9000: better, faster, stronger[C]// Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2017: 6517-6525. 10.1109/cvpr.2017.690 |
| 21 | WOO S, PRAK J, LEE J Y, et al. CBAM: convolutional block attention module[C]// Proceedings of the 2018 European Conference on Computer Vision, LNCS 11211. Cham: Springer, 2018: 3-19. |
| 22 | HU J, SHEN L, SUN G. Squeeze-and-excitation networks[C]// Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2018: 7132-7141. 10.1109/cvpr.2018.00745 |
| 23 | SELVARAJU R R, COGSWELL M, DAS A, et al. Grad-CAM: visual explanations from deep networks via gradient-based localization[C]// Proceedings of the 2017 IEEE International Conference on Computer Vision. Piscataway: IEEE, 2017: 618-626. 10.1109/iccv.2017.74 |
| 24 | EVERINGHAM M, VAN GOOL L, WILLIAMS C K I, et al. The PASCAL Visual Object Classes (VOC) challenge[J]. International Journal of Computer Vision, 2010, 88(2): 303-338. 10.1007/s11263-009-0275-4 |
| 25 | EVERINGHAM M, ESLAMI S M A, VAN GOOL L, et al. The PASCAL Visual Object Classes challenge: a retrospective[J]. International Journal of Computer Vision, 2015, 111(1): 98-136. 10.1007/s11263-014-0733-5 |
| 26 | MAATEN L V D, HINTON G. Visualizing data using t-SNE[J]. Journal of Machine Learning Research, 2008, 9: 2579-2605. |
| [1] | Jing QIN, Zhiguang QIN, Fali LI, Yueheng PENG. Diagnosis of major depressive disorder based on probabilistic sparse self-attention neural network [J]. Journal of Computer Applications, 2024, 44(9): 2970-2974. |
| [2] | Liting LI, Bei HUA, Ruozhou HE, Kuang XU. Multivariate time series prediction model based on decoupled attention mechanism [J]. Journal of Computer Applications, 2024, 44(9): 2732-2738. |
| [3] | Zhiqiang ZHAO, Peihong MA, Xinhong HEI. Crowd counting method based on dual attention mechanism [J]. Journal of Computer Applications, 2024, 44(9): 2886-2892. |
| [4] | Kaipeng XUE, Tao XU, Chunjie LIAO. Multimodal sentiment analysis network with self-supervision and multi-layer cross attention [J]. Journal of Computer Applications, 2024, 44(8): 2387-2392. |
| [5] | Pengqi GAO, Heming HUANG, Yonghong FAN. Fusion of coordinate and multi-head attention mechanisms for interactive speech emotion recognition [J]. Journal of Computer Applications, 2024, 44(8): 2400-2406. |
| [6] | Zhonghua LI, Yunqi BAI, Xuejin WANG, Leilei HUANG, Chujun LIN, Shiyu LIAO. Low illumination face detection based on image enhancement [J]. Journal of Computer Applications, 2024, 44(8): 2588-2594. |
| [7] | Shangbin MO, Wenjun WANG, Ling DONG, Shengxiang GAO, Zhengtao YU. Single-channel speech enhancement based on multi-channel information aggregation and collaborative decoding [J]. Journal of Computer Applications, 2024, 44(8): 2611-2617. |
| [8] | Wu XIONG, Congjun CAO, Xuefang SONG, Yunlong SHAO, Xusheng WANG. Handwriting identification method based on multi-scale mixed domain attention mechanism [J]. Journal of Computer Applications, 2024, 44(7): 2225-2232. |
| [9] | Huanhuan LI, Tianqiang HUANG, Xuemei DING, Haifeng LUO, Liqing HUANG. Public traffic demand prediction based on multi-scale spatial-temporal graph convolutional network [J]. Journal of Computer Applications, 2024, 44(7): 2065-2072. |
| [10] | Dianhui MAO, Xuebo LI, Junling LIU, Denghui ZHANG, Wenjing YAN. Chinese entity and relation extraction model based on parallel heterogeneous graph and sequential attention mechanism [J]. Journal of Computer Applications, 2024, 44(7): 2018-2025. |
| [11] | Li LIU, Haijin HOU, Anhong WANG, Tao ZHANG. Generative data hiding algorithm based on multi-scale attention [J]. Journal of Computer Applications, 2024, 44(7): 2102-2109. |
| [12] | Song XU, Wenbo ZHANG, Yifan WANG. Lightweight video salient object detection network based on spatiotemporal information [J]. Journal of Computer Applications, 2024, 44(7): 2192-2199. |
| [13] | Dahai LI, Zhonghua WANG, Zhendong WANG. Dual-branch low-light image enhancement network combining spatial and frequency domain information [J]. Journal of Computer Applications, 2024, 44(7): 2175-2182. |
| [14] | Wenliang WEI, Yangping WANG, Biao YUE, Anzheng WANG, Zhe ZHANG. Deep learning model for infrared and visible image fusion based on illumination weight allocation and attention [J]. Journal of Computer Applications, 2024, 44(7): 2183-2191. |
| [15] | Yan ZHOU, Yang LI. Rectified cross pseudo supervision method with attention mechanism for stroke lesion segmentation [J]. Journal of Computer Applications, 2024, 44(6): 1942-1948. |
| Viewed | ||||||
|
Full text |
|
|||||
|
Abstract |
|
|||||