


Journal of Computer Applications ›› 2024, Vol. 44 ›› Issue (1): 47-57.DOI: 10.11772/j.issn.1001-9081.2023060861
• Cross-media representation learning and cognitive reasoning • Previous Articles Next Articles
Jia WANG-ZHU, Zhou YU( ), Jun YU, Jianping FAN
), Jun YU, Jianping FAN
Received:2023-07-01
Revised:2023-09-05
Accepted:2023-09-11
Online:2023-10-09
Published:2024-01-10
Contact:
Zhou YU
About author:WANG-ZHU Jia, born in 1998, M. S. candidate. Her research interests include multimedia understanding.Supported by:
王朱佳, 余宙(), 俞俊, 范建平
通讯作者:
余宙
作者简介:王朱佳(1998—),女,上海人,硕士研究生,主要研究方向:多媒体理解;基金资助:CLC Number:
Jia WANG-ZHU, Zhou YU, Jun YU, Jianping FAN. Video dynamic scene graph generation model based on multi-scale spatial-temporal Transformer[J]. Journal of Computer Applications, 2024, 44(1): 47-57.
王朱佳, 余宙, 俞俊, 范建平. 基于多尺度时空Transformer的视频动态场景图生成模型[J]. 《计算机应用》唯一官方网站, 2024, 44(1): 47-57.
Add to citation manager EndNote|Ris|BibTeX
URL: https://www.joca.cn/EN/10.11772/j.issn.1001-9081.2023060861
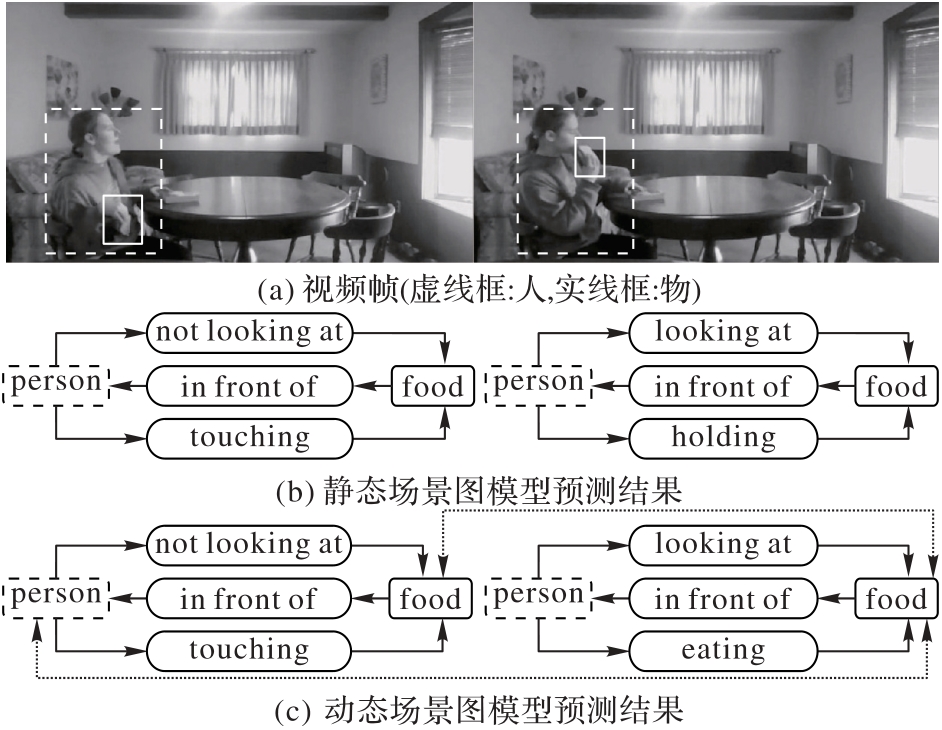
Fig. 1 Comparison of scene graph generation tasks over static image and dynamic video

Fig. 2 Overall architecture of dynamic scene graph generation model based on multi-scale spatial-temporal Transformer
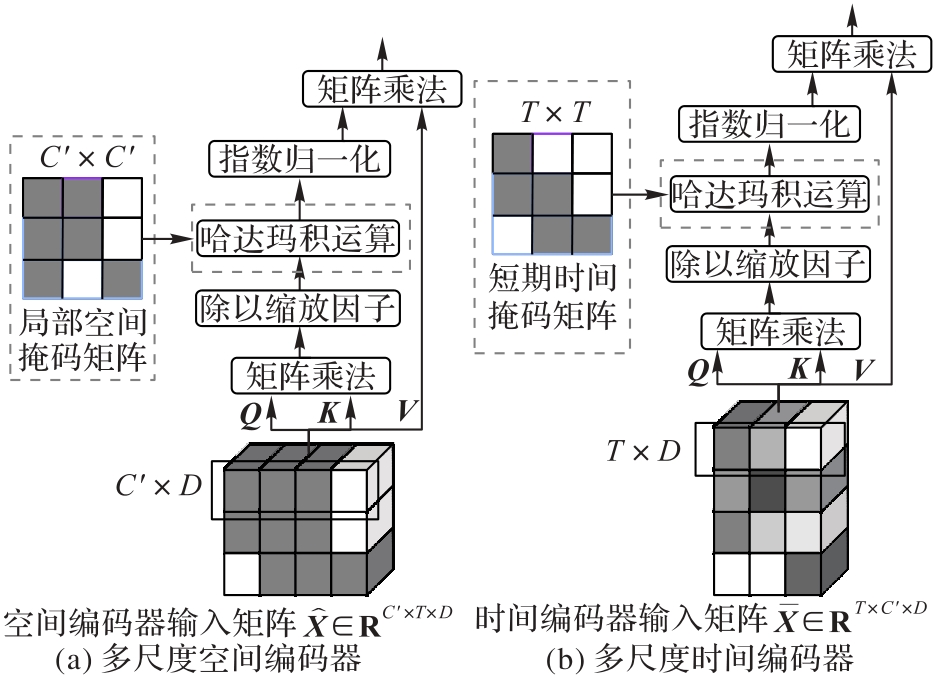
Fig. 3 Attention architectures for multi-scale spatial encoder and temporal encoder
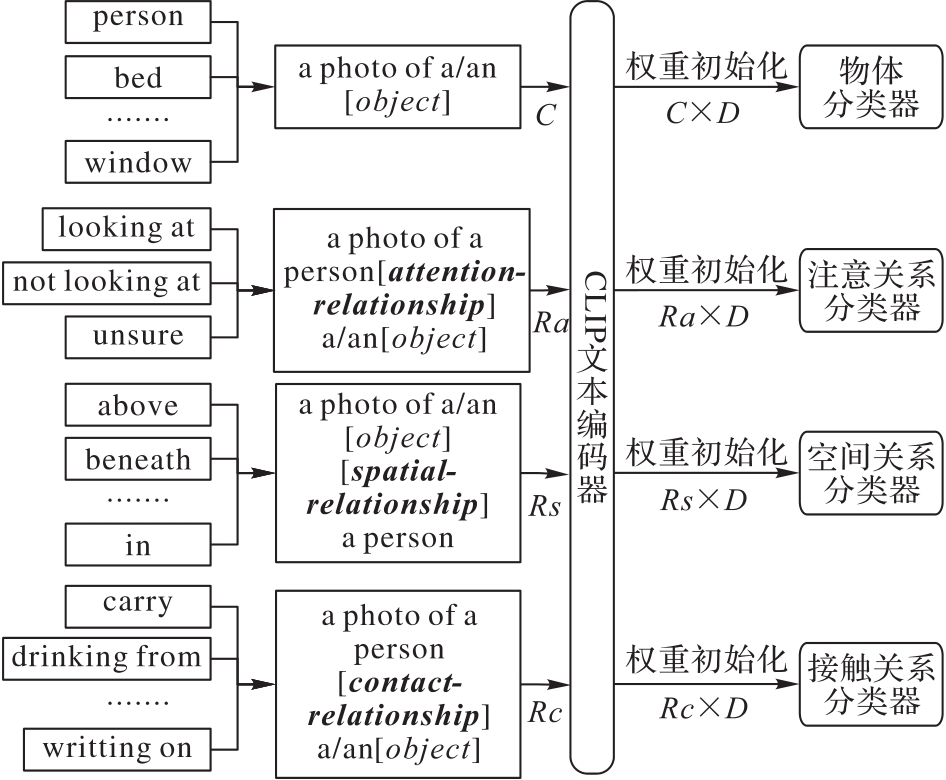
Fig. 4 Classification network enhanced by CLIP model
| 模型名称 | 带约束 | 无约束 | ||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| PredCls | SgCls | SgDet | PredCls | SgCls | SgDet | |||||||||||||
| R@10 | R@20 | R@50 | R@10 | R@20 | R@50 | R@10 | R@20 | R@50 | R@10 | R@20 | R@50 | R@10 | R@20 | R@50 | R@10 | R@20 | R@50 | |
| VRD[ | 51.7 | 54.7 | 54.7 | 32.4 | 33.3 | 33.3 | 19.2 | 24.5 | 26.0 | 59.6 | 78.5 | 99.2 | 39.2 | 49.8 | 52.6 | 19.1 | 28.8 | 40.5 |
| MotifNet [ | 62.4 | 65.1 | 65.1 | 40.8 | 41.9 | 41.9 | 23.7 | 31.4 | 33.3 | 73.4 | 92.4 | 99.6 | 50.4 | 60.4 | 64.2 | 22.8 | 34.3 | 46.4 |
| MSDN[ | 65.5 | 68.5 | 68.5 | 43.9 | 45.1 | 45.1 | 24.1 | 32.4 | 34.5 | 74.9 | 92.7 | 99.0 | 51.2 | 61.8 | 65.0 | 23.1 | 34.7 | 46.5 |
| VCTREE[ | 66.0 | 69.3 | 69.3 | 44.1 | 45.3 | 45.3 | 24.4 | 32.6 | 34.7 | 75.5 | 92.9 | 99.3 | 52.4 | 62.0 | 65.1 | 23.9 | 35.3 | 46.8 |
| ReIDN[ | 66.3 | 69.5 | 69.5 | 44.3 | 45.4 | 45.4 | 24.5 | 32.8 | 34.9 | 75.7 | 93.0 | 99.0 | 52.9 | 62.4 | 65.1 | 24.1 | 35.4 | 46.8 |
| GPS-Net[ | 66.8 | 69.9 | 69.9 | 45.3 | 46.5 | 46.5 | 24.7 | 33.1 | 35.1 | 76.2 | 93.6 | 99.5 | 53.6 | 63.3 | 66.0 | 24.4 | 35.7 | 47.3 |
| STTran[ | 68.6 | 71.8 | 71.8 | 46.4 | 47.5 | 47.5 | 25.2 | 34.1 | 37.0 | 77.9 | 94.2 | 99.1 | 54.0 | 63.7 | 66.4 | 24.6 | 36.2 | 48.8 |
| Li模型[ | 69.4 | 73.8 | 73.8 | 47.2 | 48.9 | 48.9 | 26.3 | 36.1 | 38.3 | 78.5 | 95.1 | 99.2 | 55.1 | 65.1 | 68.7 | 25.7 | 37.9 | 50.1 |
| MSTT | 70.4 | 73.2 | 73.2 | 47.4 | 48.5 | 48.5 | 26.3 | 34.7 | 37.5 | 82.9 | 96.5 | 99.9 | 56.8 | 64.4 | 66.5 | 27.5 | 38.5 | 49.7 |
Tab. 1 Comparison of proposed model with state-of-the-art models on Action Genome dataset
| 模型名称 | 带约束 | 无约束 | ||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| PredCls | SgCls | SgDet | PredCls | SgCls | SgDet | |||||||||||||
| R@10 | R@20 | R@50 | R@10 | R@20 | R@50 | R@10 | R@20 | R@50 | R@10 | R@20 | R@50 | R@10 | R@20 | R@50 | R@10 | R@20 | R@50 | |
| VRD[ | 51.7 | 54.7 | 54.7 | 32.4 | 33.3 | 33.3 | 19.2 | 24.5 | 26.0 | 59.6 | 78.5 | 99.2 | 39.2 | 49.8 | 52.6 | 19.1 | 28.8 | 40.5 |
| MotifNet [ | 62.4 | 65.1 | 65.1 | 40.8 | 41.9 | 41.9 | 23.7 | 31.4 | 33.3 | 73.4 | 92.4 | 99.6 | 50.4 | 60.4 | 64.2 | 22.8 | 34.3 | 46.4 |
| MSDN[ | 65.5 | 68.5 | 68.5 | 43.9 | 45.1 | 45.1 | 24.1 | 32.4 | 34.5 | 74.9 | 92.7 | 99.0 | 51.2 | 61.8 | 65.0 | 23.1 | 34.7 | 46.5 |
| VCTREE[ | 66.0 | 69.3 | 69.3 | 44.1 | 45.3 | 45.3 | 24.4 | 32.6 | 34.7 | 75.5 | 92.9 | 99.3 | 52.4 | 62.0 | 65.1 | 23.9 | 35.3 | 46.8 |
| ReIDN[ | 66.3 | 69.5 | 69.5 | 44.3 | 45.4 | 45.4 | 24.5 | 32.8 | 34.9 | 75.7 | 93.0 | 99.0 | 52.9 | 62.4 | 65.1 | 24.1 | 35.4 | 46.8 |
| GPS-Net[ | 66.8 | 69.9 | 69.9 | 45.3 | 46.5 | 46.5 | 24.7 | 33.1 | 35.1 | 76.2 | 93.6 | 99.5 | 53.6 | 63.3 | 66.0 | 24.4 | 35.7 | 47.3 |
| STTran[ | 68.6 | 71.8 | 71.8 | 46.4 | 47.5 | 47.5 | 25.2 | 34.1 | 37.0 | 77.9 | 94.2 | 99.1 | 54.0 | 63.7 | 66.4 | 24.6 | 36.2 | 48.8 |
| Li模型[ | 69.4 | 73.8 | 73.8 | 47.2 | 48.9 | 48.9 | 26.3 | 36.1 | 38.3 | 78.5 | 95.1 | 99.2 | 55.1 | 65.1 | 68.7 | 25.7 | 37.9 | 50.1 |
| MSTT | 70.4 | 73.2 | 73.2 | 47.4 | 48.5 | 48.5 | 26.3 | 34.7 | 37.5 | 82.9 | 96.5 | 99.9 | 56.8 | 64.4 | 66.5 | 27.5 | 38.5 | 49.7 |
实验 编号 | 空间编码器 | 时间编码器 | CLIP 初始化 | SgCls | |||
|---|---|---|---|---|---|---|---|
| 局部 | 全局 | 短期 | 长期 | Recall@10 | Recall@20 | ||
| 1 | √ | √ | √ | 46.6 | 47.9 | ||
| 2 | √ | √ | √ | 46.7 | 47.8 | ||
| 3 | √ | √ | √ | √ | 47.3 | 48.3 | |
| 4 | √ | √ | √ | √ | 47.1 | 48.2 | |
| 5 | √ | √ | √ | √ | 47.2 | 48.2 | |
| 6 | √ | √ | √ | √ | 47.0 | 48.1 | |
| 7 | √ | √ | √ | √ | 46.7 | 47.9 | |
| 8 | √ | √ | √ | √ | √ | 47.4 | 48.5 |
Tab. 2 Ablation experiment results for SgCls task on Action Genome dataset with constraints
实验 编号 | 空间编码器 | 时间编码器 | CLIP 初始化 | SgCls | |||
|---|---|---|---|---|---|---|---|
| 局部 | 全局 | 短期 | 长期 | Recall@10 | Recall@20 | ||
| 1 | √ | √ | √ | 46.6 | 47.9 | ||
| 2 | √ | √ | √ | 46.7 | 47.8 | ||
| 3 | √ | √ | √ | √ | 47.3 | 48.3 | |
| 4 | √ | √ | √ | √ | 47.1 | 48.2 | |
| 5 | √ | √ | √ | √ | 47.2 | 48.2 | |
| 6 | √ | √ | √ | √ | 47.0 | 48.1 | |
| 7 | √ | √ | √ | √ | 46.7 | 47.9 | |
| 8 | √ | √ | √ | √ | √ | 47.4 | 48.5 |
| 实验编号 | 局部空间尺度参数 | SgCls | |
|---|---|---|---|
| Recall@10 | Recall@20 | ||
| 1 | 47.4 | 48.5 | |
| 2 | 47.4 | 48.5 | |
| 3 | 47.3 | 48.5 | |
Tab. 3 Ablation experiment results for local spatial scale parameter on Action Genome dataset with constraints
| 实验编号 | 局部空间尺度参数 | SgCls | |
|---|---|---|---|
| Recall@10 | Recall@20 | ||
| 1 | 47.4 | 48.5 | |
| 2 | 47.4 | 48.5 | |
| 3 | 47.3 | 48.5 | |
| 实验编号 | 短期时间尺度参数 | SgCls | |
|---|---|---|---|
| Recall@10 | Recall@20 | ||
| 1 | 47.4 | 48.5 | |
| 2 | 47.3 | 48.5 | |
| 3 | 47.3 | 48.3 | |
| 4 | 47.4 | 48.5 | |
Tab. 4 Ablation experiment results for short-term temporal scale parameters on Action Genome dataset with constraints
| 实验编号 | 短期时间尺度参数 | SgCls | |
|---|---|---|---|
| Recall@10 | Recall@20 | ||
| 1 | 47.4 | 48.5 | |
| 2 | 47.3 | 48.5 | |
| 3 | 47.3 | 48.3 | |
| 4 | 47.4 | 48.5 | |

Fig. 5 Comparison of prediction results between MSTT and STTran models with constraints

Fig. 6 Incorrect prediction examples by MSTT
| 1 | GIRSHICK R, DONAHUE J, DARRELL T, et al. Rich feature hierarchies for accurate object detection and semantic segmentation [C]// Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition. Washington, DC: IEEE Computer Society, 2014: 580-587. 10.1109/cvpr.2014.81 |
| 2 | GIRSHICK R. Fast R-CNN [C]// Proceedings of the 2015 IEEE International Conference on Computer Vision. Piscataway: IEEE, 2015: 1440-1448. 10.1109/iccv.2015.169 |
| 3 | REN S, HE K, GIRSHICK R, et al. Faster R-CNN: Towards real-time object detection with region proposal networks [J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2017, 39(6): 1137-1149. 10.1109/tpami.2016.2577031 |
| 4 | HE K, GKIOXARI G, DOLLÁR P, et al. Mask R-CNN [C]// Proceedings of the 2017 IEEE International Conference on Computer Vision. Piscataway: IEEE, 2017: 2980-2988. 10.1109/iccv.2017.322 |
| 5 | QIAN X, ZHUANG Y, LI Y, et al. Video relation detection with spatio-temporal graph [C]// Proceedings of the 27th ACM International Conference on Multimedia. New York: ACM, 2019: 84-93. 10.1145/3343031.3351058 |
| 6 | XU L, QU H, KUEN J, et al. Meta spatio-temporal debiasing for video scene graph generation [C]// Proceedings of the 2022 European Conference on Computer Vision. Cham: Springer, 2022: 374-390. 10.1007/978-3-031-19812-0_22 |
| 7 | JUNG G, LEE J, KIM I. Tracklet pair proposal and context reasoning for video scene graph generation [J]. Sensors, 2021, 21(9): 3164. 10.3390/s21093164 |
| 8 | GAO K, CHEN L, NIU Y, et al. Classification-then-grounding: Reformulating video scene graphs as temporal bipartite graphs [C]// Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2022: 19475-19484. 10.1109/cvpr52688.2022.01889 |
| 9 | FENG S, MOSTAFA H, NASSAR M, et al. Exploiting long-term dependencies for generating dynamic scene graphs [C]// Proceedings of the 2023 IEEE/CVF Winter Conference on Applications of Computer Vision. Piscataway: IEEE, 2023: 5119-5128. 10.1109/wacv56688.2023.00510 |
| 10 | JI J, DESAI R, NIEBLES J C. Detecting human-object relationships in videos [C]// Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision. Piscataway: IEEE, 2021: 8086-8096. 10.1109/iccv48922.2021.00800 |
| 11 | TENG Y, WANG L, LI Z, et al. Target adaptive context aggregation for video scene graph generation [C]// Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision. Piscataway: IEEE, 2021: 13668-13677. 10.1109/iccv48922.2021.01343 |
| 12 | CONG Y, LIAO W, ACKERMANN H, et al. Spatial-temporal transformer for dynamic scene graph generation [C]// Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision. Piscataway: IEEE, 2021: 16352-16362. 10.1109/iccv48922.2021.01606 |
| 13 | LI Y, YANG X, XU C. Dynamic scene graph generation via anticipatory pre-training [C]// Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2022: 13864-13873. 10.1109/cvpr52688.2022.01350 |
| 14 | JI J W, KRISHNA R, LI F-F, et al. Action genome: Actions as compositions of spatio-temporal scene graphs [C]// Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2020: 10233-10244. 10.1109/cvpr42600.2020.01025 |
| 15 | RADFORD A, KIM J W, HALLACY C, et al. Learning transferable visual models from natural language supervision [C]// Proceedings of the 38th International Conference on Machine Learning. New York: JMLR.org, 2021: 8748-8763. |
| 16 | JOHNSON J, KRISHNA R, STARK M, et al. Image retrieval using scene graphs [C]// Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2015: 3668-3678. 10.1109/cvpr.2015.7298990 |
| 17 | 彭耀鹏.基于多特征融合及短期记忆选择网络的视觉关系检测[D].杭州:浙江大学, 2023: 20-40. |
| PENG Y P. Visual relationship detection based on multi-feature fusion and short-term memory selection network [D]. Hangzhou: Zhejiang University, 2023: 20-40. | |
| 18 | DAI B, ZHANG Y, LIN D. Detecting visual relationships with deep relational networks [C]// Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2017: 3098-3308. 10.1109/cvpr.2017.352 |
| 19 | XU D, ZHU Y, CHOY C B, et al. Scene graph generation by iterative message passing [C]// Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2017: 5410-5419. 10.1109/cvpr.2017.330 |
| 20 | CHEN V, VARMA P, KRISHNA R, et al. Scene graph prediction with limited labels [C]// Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision. Piscataway: IEEE, 2019: 1772-1782. 10.1109/iccv.2019.00267 |
| 21 | CONG Y, ACKERMANN H, LIAO W, et al. NODIS: Neural ordinary differential scene understanding [C]// Proceedings of the 2020 European Conference on Computer Vision. Cham: Springer, 2020: 636-653. 10.1007/978-3-030-58565-5_38 |
| 22 | 龚小强.基于深度学习的视觉关系检测技术研究[D].南昌:南昌大学, 2019: 20-44. |
| GONG X Q. Research on visual relationship detection technology based on deep learning [D]. Nanchang: Nanchang University, 2019: 20-44. | |
| 23 | ZELLERS R, YATSKAR M, THOMSON S, et al. Neural motifs: Scene graph parsing with global context [C]// Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2018: 5831-5840. 10.1109/cvpr.2018.00611 |
| 24 | ZHANG J, SHIH K J, ELGAMMAL A, et al. Graphical contrastive losses for scene graph parsing [C]// Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2019: 11527-11535. 10.1109/cvpr.2019.01180 |
| 25 | GARG S, DHAMO H, FARSHAD A, et al. Unconditional scene graph generation [C]// Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision. Piscataway: IEEE, 2021: 16342-16351. 10.1109/iccv48922.2021.01605 |
| 26 | LIAO W, LAN C, YANG M Y, et al. Target-tailored source-transformation for scene graph generation [C]// Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2021: 1663-1671. 10.1109/cvprw53098.2021.00182 |
| 27 | DENG Y, LI Y, ZHANG Y, et al. Hierarchical memory learning for fine-grained scene graph generation [C]// Proceedings of the 2022 European Conference on Computer Vision. Cham: Springer, 2022: 266-283. 10.1007/978-3-031-19812-0_16 |
| 28 | ZHU Y, ZHU X, SHANG Y, et al. Supplementing missing visions via dialog for scene graph generations [EB/OL]. (2022-04-23) [2022-05-01]. . |
| 29 | 钟冠华,黄巍.基于多特征提取网络的视觉关系检测方法研究[J].电脑与电信, 2022(7): 67-70. 10.3969/j.issn.1008-6609.2022.7.gddnydx202207016 |
| ZHONG G H, HUANG W. Research on visual relationship detection method based on multi-feature extraction network [J]. Computer & Telecommunication, 2022(7): 67-70. 10.3969/j.issn.1008-6609.2022.7.gddnydx202207016 | |
| 30 | LU C, KRISHNA R, BERNSTEIN M, et al. Visual relationship detection with language priors [C]// Proceedings of the 2016 European Conference on Computer Vision. Cham: Springer, 2016: 852-869. 10.1007/978-3-319-46448-0_51 |
| 31 | LI Y, OUYANG W, ZHOU L, et al. Scene graph generation from objects, phrases and region captions [C]// Proceedings of the 2017 IEEE International Conference on Computer Vision. Piscataway: IEEE, 2017: 1270-1279. 10.1109/iccv.2017.142 |
| 32 | YU R, LI A, MORARIU V I, et al. Visual relationship detection with internal and external linguistic knowledge distillation [C]// Proceedings of the 2017 IEEE International Conference on Computer Vision. Piscataway: IEEE, 2017: 1068-1076. 10.1109/iccv.2017.121 |
| 33 | LIANG X, LEE L, XING E P. Deep variation-structured reinforcement learning for visual relationship and attribute detection [C]// Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2017: 4408-4417. 10.1109/cvpr.2017.469 |
| 34 | LI Y, OUYANG W, ZHOU B, et al. Factorizable net: An efficient subgraph-based framework for scene graph generation [C]// Proceedings of the 2018 European Conference on Computer Vision. Cham: Springer, 2018: 346-363. 10.1007/978-3-030-01246-5_21 |
| 35 | WANG W, WANG R, SHAN S, et al. Exploring context and visual pattern of relationship for scene graph generation [C]// Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2019: 8180-8189. 10.1109/cvpr.2019.00838 |
| 36 | LIN X, DING C, ZENG J, et al. GPS-Net: Graph property sensing network for scene graph generation [C]// Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2020: 3746-3753. 10.1109/cvpr42600.2020.00380 |
| 37 | LI P, YU Z, ZHAN Y. Deep relational self-attention networks for scene graph generation [J]. Pattern Recognition Letters, 2022, 153: 200-206. 10.1016/j.patrec.2021.12.013 |
| 38 | YIN G, SHENG L, LIU B, et al. Zoom-Net: Mining deep feature interactions for visual relationship recognition [C]// Proceedings of the 2018 European Conference on Computer Vision. Cham: Springer, 2018: 330-347. 10.1007/978-3-030-01219-9_20 |
| 39 | 黄勇韬,严华.结合注意力机制与特征融合的场景图生成模型[J].计算机科学, 2020, 47(6): 133-137. 10.11896/jsjkx.190600110 |
| HUANG Y T, YAN H. Scene graph generation model combining attention mechanism and feature fusion [J]. Computer Science, 2020, 47(6): 133-137. 10.11896/jsjkx.190600110 | |
| 40 | YANG J, LU J, LEE S, et al. Graph R-CNN for scene graph generation [C]// Proceedings of the 2018 European Conference on Computer Vision. Cham: Springer, 2018: 690-706. 10.1007/978-3-030-01246-5_41 |
| 41 | LIAO W, ROSENHAHN B, SHUAI L, et al. Natural language guided visual relationship detection [C]// Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops. Piscataway: IEEE, 2019: 444-453. 10.1109/cvprw.2019.00058 |
| 42 | WOO S, KIM D, CHO D, et al. LinkNet: Relational embedding for scene graph [C]// Proceedings of the 32nd International Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2018: 558-568. |
| 43 | LI Y, OUYANG W, WANG X, et al. ViP-CNN: Visual phrase guided convolutional neural network [C]// Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2017: 7244-7253. 10.1109/cvpr.2017.766 |
| 44 | ZAREIAN A, KARAMAN S, CHANG S-F. Bridging knowledge graphs to generate scene graphs [C]// Proceedings of the 2020 European Conference on Computer Vision. Cham: Springer, 2020: 606-623. 10.1007/978-3-030-58592-1_36 |
| 45 | KRISHNA R, ZHU Y, GROTH O, et al. Visual genome: Connecting language and vision using crowdsourced dense image annotations [J]. International Journal of Computer Vision, 2017, 123: 32-73. 10.1007/s11263-016-0981-7 |
| 46 | SCHUSTER S, KRISHNA R, CHANG A, et al. Generating semantically precise scene graphs from textual descriptions for improved image retrieval [C]// Proceedings of the Fourth Workshop on Vision and Language. Stroudsberg, PA: Assocation for Computational Linguistics, 2015: 70-80. 10.18653/v1/w15-2812 |
| 47 | YANG X, TANG K, ZHANG H, et al. Auto-encoding scene graphs for image captioning [C]// Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2019: 10677-10686. 10.1109/cvpr.2019.01094 |
| 48 | TANG K, ZHANG H, WU B, et al. Learning to compose dynamic tree structures for visual contexts [C]// Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2019: 6619-6628. 10.1109/cvpr.2019.00678 |
| 49 | ANDERSON P, FERNANDO B, JOHNSON M, et al. SPICE: Semantic propositional image caption evaluation [C]// Proceedings of the 2016 European Conference on Computer Vision. Cham: Springer, 2016: 382-398. 10.1007/978-3-319-46454-1_24 |
| 50 | LIANG W, JIANG Y, LIU Z. GraphVQA: Language-guided graph neural networks for scene graph question answering [C]// Proceedings of the Third Workshop on Multimodal Artificial Intelligence. Stroudsburg, PA: Association for Computational Linguistics, 2021, 2021: 79-86. 10.18653/v1/2021.maiworkshop-1.12 |
| 51 | 牛学硕.基于场景图和文本描述的图像生成方法研究[D].大连:大连理工大学, 2021: 32-66. 10.33075/2220-5861-2022-1-5-14 |
| NIU X S. The research on generating images based on scene graph and textual description [D]. Dalian: Dalian University of Technology, 2021: 32-66. 10.33075/2220-5861-2022-1-5-14 | |
| 52 | YU Z, ZHENG L, ZHAO Z, et al. ANetQA: A large-scale benchmark for fine-grained compositional reasoning over untrimmed videos [C]// Proceedings of the 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2023: 23191-23200. 10.1109/cvpr52729.2023.02221 |
| 53 | SIGURDSSON G A, VAROL G, WANG X, et al. Hollywood in homes: Crowdsourcing data collection for activity understanding [C]// Proceedings of the 2016 European Conference on Computer Vision. Cham: Springer, 2016: 510-526. 10.1007/978-3-319-46448-0_31 |
| 54 | VASWANI A, SHAZEER N, PARMAR N, et al. Attention is all you need [C]// Proceedings of the 31st International Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2017: 6000-6010. |
| 55 | PENNINGTON J, SOCHER R, MANNING C D. GloVe: Global vectors for word representation [C]// Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing. Stroudsburg, PA: Association for Computational Linguistics, 2014: 1532-1543. 10.3115/v1/d14-1162 |
| 56 | HE K, ZHANG X, REN S, et al. Deep residual learning for image recognition [C]// Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2016: 770-778. 10.1109/cvpr.2016.90 |
| 57 | LOSHCHILOV I, HUTTER F. Decoupled weight decay regularization [EB/OL]. (2019-06-04) [2022-01-09]. . |
| [1] | Jing QIN, Zhiguang QIN, Fali LI, Yueheng PENG. Diagnosis of major depressive disorder based on probabilistic sparse self-attention neural network [J]. Journal of Computer Applications, 2024, 44(9): 2970-2974. |
| [2] | Liting LI, Bei HUA, Ruozhou HE, Kuang XU. Multivariate time series prediction model based on decoupled attention mechanism [J]. Journal of Computer Applications, 2024, 44(9): 2732-2738. |
| [3] | Zhiqiang ZHAO, Peihong MA, Xinhong HEI. Crowd counting method based on dual attention mechanism [J]. Journal of Computer Applications, 2024, 44(9): 2886-2892. |
| [4] | Kaipeng XUE, Tao XU, Chunjie LIAO. Multimodal sentiment analysis network with self-supervision and multi-layer cross attention [J]. Journal of Computer Applications, 2024, 44(8): 2387-2392. |
| [5] | Pengqi GAO, Heming HUANG, Yonghong FAN. Fusion of coordinate and multi-head attention mechanisms for interactive speech emotion recognition [J]. Journal of Computer Applications, 2024, 44(8): 2400-2406. |
| [6] | Zhonghua LI, Yunqi BAI, Xuejin WANG, Leilei HUANG, Chujun LIN, Shiyu LIAO. Low illumination face detection based on image enhancement [J]. Journal of Computer Applications, 2024, 44(8): 2588-2594. |
| [7] | Shangbin MO, Wenjun WANG, Ling DONG, Shengxiang GAO, Zhengtao YU. Single-channel speech enhancement based on multi-channel information aggregation and collaborative decoding [J]. Journal of Computer Applications, 2024, 44(8): 2611-2617. |
| [8] | Wu XIONG, Congjun CAO, Xuefang SONG, Yunlong SHAO, Xusheng WANG. Handwriting identification method based on multi-scale mixed domain attention mechanism [J]. Journal of Computer Applications, 2024, 44(7): 2225-2232. |
| [9] | Huanhuan LI, Tianqiang HUANG, Xuemei DING, Haifeng LUO, Liqing HUANG. Public traffic demand prediction based on multi-scale spatial-temporal graph convolutional network [J]. Journal of Computer Applications, 2024, 44(7): 2065-2072. |
| [10] | Dianhui MAO, Xuebo LI, Junling LIU, Denghui ZHANG, Wenjing YAN. Chinese entity and relation extraction model based on parallel heterogeneous graph and sequential attention mechanism [J]. Journal of Computer Applications, 2024, 44(7): 2018-2025. |
| [11] | Li LIU, Haijin HOU, Anhong WANG, Tao ZHANG. Generative data hiding algorithm based on multi-scale attention [J]. Journal of Computer Applications, 2024, 44(7): 2102-2109. |
| [12] | Song XU, Wenbo ZHANG, Yifan WANG. Lightweight video salient object detection network based on spatiotemporal information [J]. Journal of Computer Applications, 2024, 44(7): 2192-2199. |
| [13] | Dahai LI, Zhonghua WANG, Zhendong WANG. Dual-branch low-light image enhancement network combining spatial and frequency domain information [J]. Journal of Computer Applications, 2024, 44(7): 2175-2182. |
| [14] | Wenliang WEI, Yangping WANG, Biao YUE, Anzheng WANG, Zhe ZHANG. Deep learning model for infrared and visible image fusion based on illumination weight allocation and attention [J]. Journal of Computer Applications, 2024, 44(7): 2183-2191. |
| [15] | Zexin XU, Lei YANG, Kangshun LI. Shorter long-sequence time series forecasting model [J]. Journal of Computer Applications, 2024, 44(6): 1824-1831. |
| Viewed | ||||||
|
Full text |
|
|||||
|
Abstract |
|
|||||