


《计算机应用》唯一官方网站 ›› 2023, Vol. 43 ›› Issue (9): 2836-2844.DOI: 10.11772/j.issn.1001-9081.2022081259
申云飞1, 申飞2,3, 李芳2,3, 张俊2,3( )
)
收稿日期:2022-08-25
修回日期:2022-11-02
接受日期:2022-11-08
发布日期:2023-01-11
出版日期:2023-09-10
通讯作者:
张俊
作者简介:申云飞(1996-),女,安徽阜阳人,硕士研究生,主要研究方向:计算机视觉、深度学习编译器基金资助:
Yunfei SHEN1, Fei SHEN2,3, Fang LI2,3, Jun ZHANG2,3()
Received:2022-08-25
Revised:2022-11-02
Accepted:2022-11-08
Online:2023-01-11
Published:2023-09-10
Contact:
Jun ZHANG
About author:SHEN Yunfei, born in 1996, M. S. candidate. Her research interests include computer vision, deep learning compiler.Supported by:摘要:
随着人工智能(AI)技术的蓬勃发展,深度神经网络(DNN)模型被大规模应用到各类移动端与边缘端。然而,边缘端算力低、内存容量小,且实现模型加速需要深入掌握边缘端硬件知识,这增加了模型的部署难度,也限制了模型的推广应用。因此,基于张量虚拟机(TVM)提出一种DNN加速与部署方法,从而实现卷积神经网络(CNN)模型在现场可编程门阵列(FPGA)上的加速,并在分心驾驶分类应用场景下验证了所提方法的可行性。通过计算图优化方法减小了模型的访存和计算开销,通过模型量化方法减小了模型尺寸,通过计算图打包方法将卷积计算卸载到FPGA上执行以提高模型推理速度。与微处理器(MPU)相比,所提方法可使ResNet50和ResNet18在MPU+FPGA上的推理时间分别减少88.63%和77.53%;而在AUC(American University in Cairo)数据集上,相较于MPU,两个模型在MPU+FPGA上的top1推理精度仅下降了0.26和0.16个百分点。可见,所提方法可以降低不同模型在FPGA上的部署难度。
中图分类号:
申云飞, 申飞, 李芳, 张俊. 基于张量虚拟机的深度神经网络模型加速方法[J]. 计算机应用, 2023, 43(9): 2836-2844.
Yunfei SHEN, Fei SHEN, Fang LI, Jun ZHANG. Deep neural network model acceleration method based on tensor virtual machine[J]. Journal of Computer Applications, 2023, 43(9): 2836-2844.
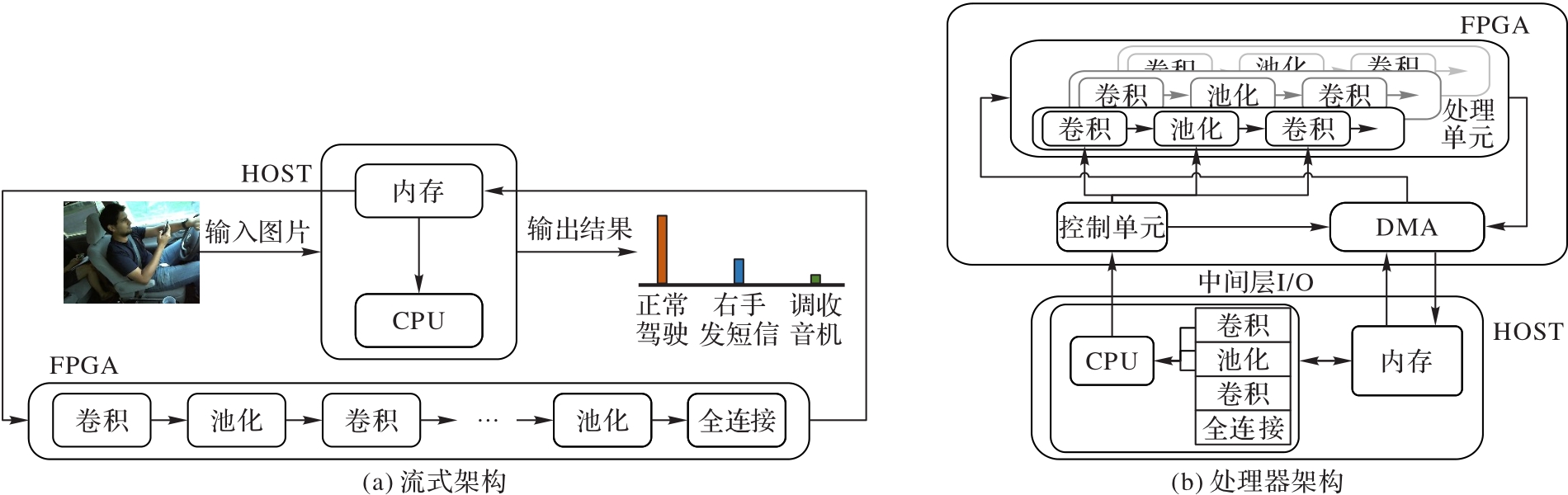
图1 专用型FPGA加速器架构
Fig. 1 Architecture of dedicated FPGA accelerator
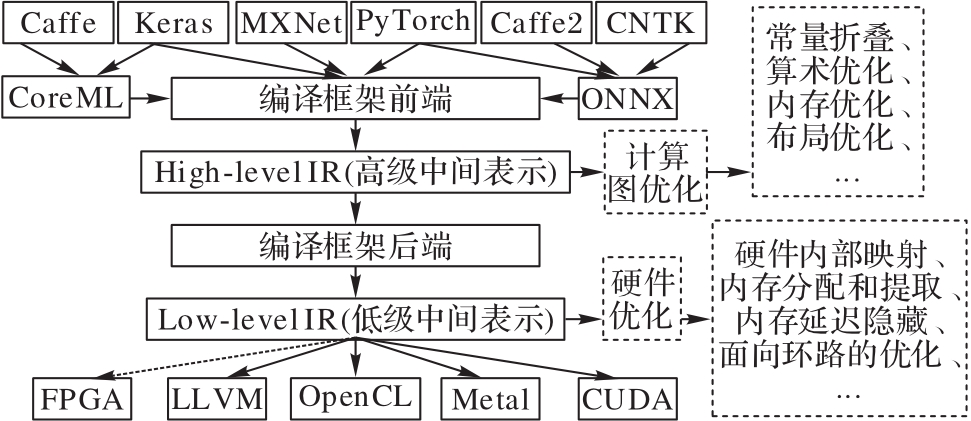
图2 深度学习编译器结构
Fig. 2 Deep learning compiler structure
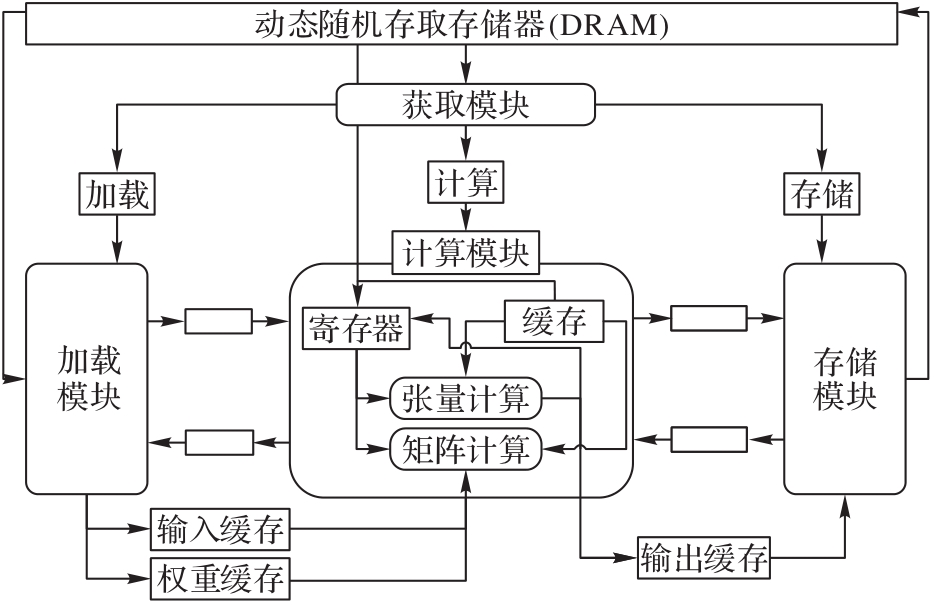
图3 VTA结构
Fig. 3 VTA structure
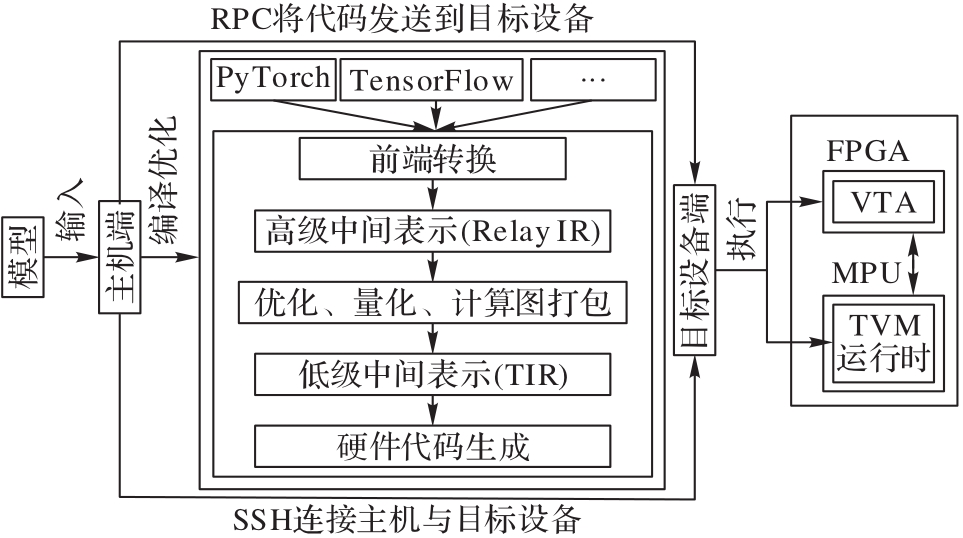
图4 模型编译流程
Fig. 4 Model compilation flow
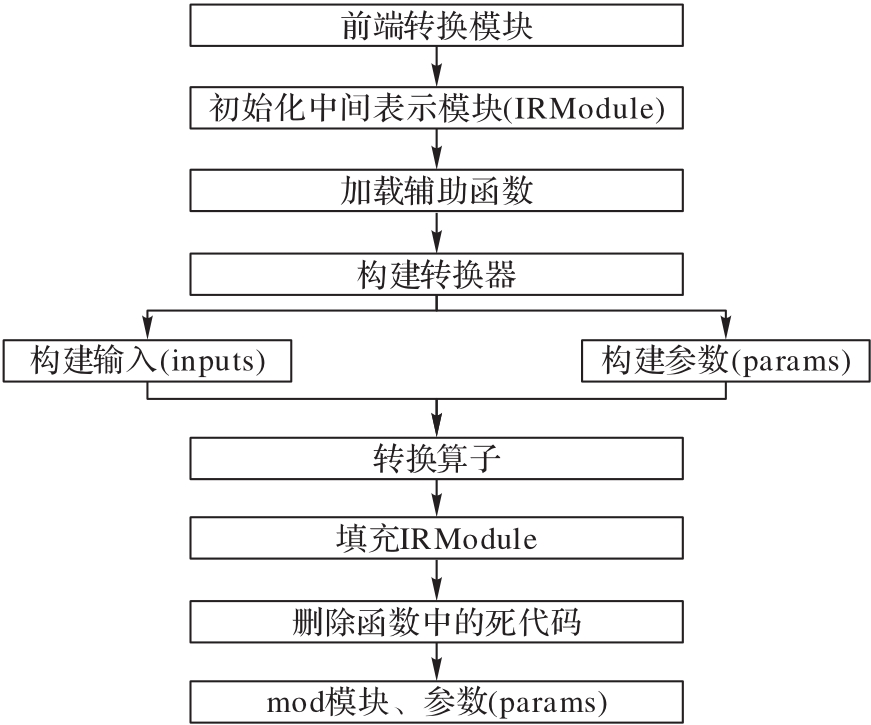
图5 前端转换流程
Fig. 5 Front end conversion flow

图6 计算图优化流程
Fig. 6 Computational graph optimization flow
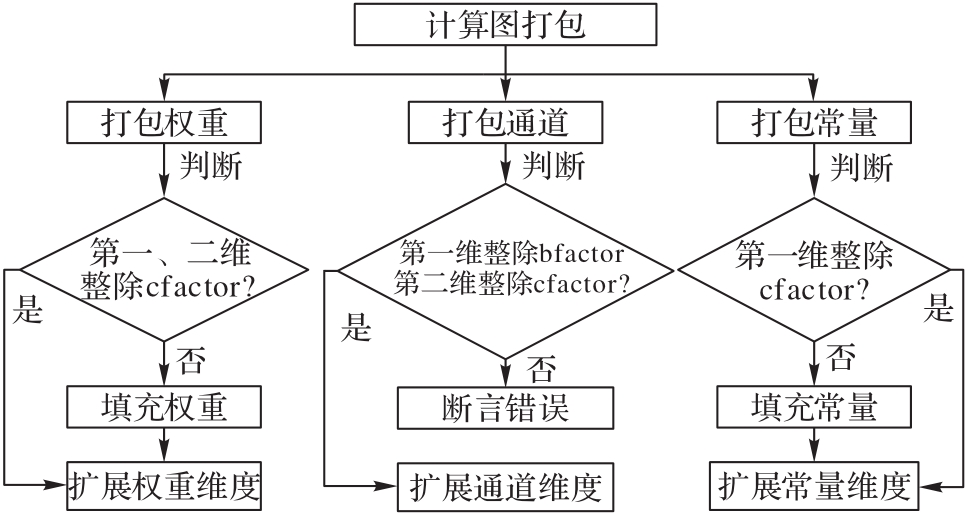
图7 计算图打包流程
Fig. 7 Computational graph packaging flow
| 维度扩展 | 维度扩展规则 |
|---|---|
| 扩展权重维度 | [a,b,c,d]→[a1,cfactor,b1,cfactor,c,d] (a=a1×cfactor,b=b1×cfactor) |
| 扩展通道维度 | [a,b,c,d]→[a1,bfactor,b1,cfactor,c,d] (a=a1×bfactor,b=b1×cfactor) |
| 扩展常量维度 | [a,b,c]→[a1,cfactor,b,c,1](a=a1×cfactor) |
表1 计算图打包的维度扩展规则
Tab. 1 Dimension expansion rules of computational graph packing
| 维度扩展 | 维度扩展规则 |
|---|---|
| 扩展权重维度 | [a,b,c,d]→[a1,cfactor,b1,cfactor,c,d] (a=a1×cfactor,b=b1×cfactor) |
| 扩展通道维度 | [a,b,c,d]→[a1,bfactor,b1,cfactor,c,d] (a=a1×bfactor,b=b1×cfactor) |
| 扩展常量维度 | [a,b,c]→[a1,cfactor,b,c,1](a=a1×cfactor) |

图8 硬件代码生成流程
Fig.8 Hardware code generation flow

图9 PYNQ-Z2开发板
Fig. 9 PYNQ-Z2 development board

图10 分心驾驶数据集样例
Fig. 10 Samples of distracted driving dataset

图11 AUC和StateFarm数据分布
Fig. 11 AUC and StateFarm data distribution
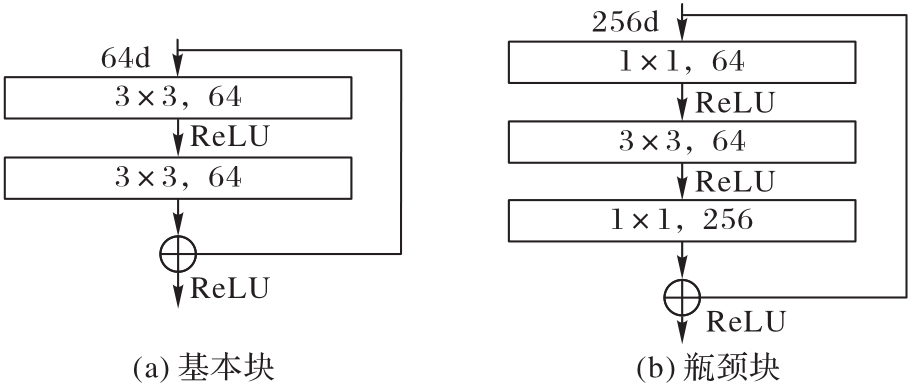
图12 残差结构
Fig. 12 Residual blocks
| 模型 | AUC | StateFarm |
|---|---|---|
| ResNet18 | 95.20 | 89.05 |
| ResNet34 | 95.27 | 90.23 |
| ResNet50 | 95.04 | 90.40 |
表2 ResNet模型在AUC和StateFarm数据集上的测试准确率 ( %)
Tab. 2 Test accuracies of ResNet models on AUC and StateFarm datasets
| 模型 | AUC | StateFarm |
|---|---|---|
| ResNet18 | 95.20 | 89.05 |
| ResNet34 | 95.27 | 90.23 |
| ResNet50 | 95.04 | 90.40 |
| 模型 | VTA模拟器 | MPU | MPU+FPGA |
|---|---|---|---|
| ResNet18 | 963.23 | 1 583.01 | 355.67 |
| ResNet34 | 1 764.66 | — | 459.45 |
| ResNet50 | 2 123.13 | 5 262.63 | 598.28 |
表3 ResNet模型在不同硬件上的推理时间对比 ( ms)
Tab. 3 Comparison of inference time of ResNet models on different hardware
| 模型 | VTA模拟器 | MPU | MPU+FPGA |
|---|---|---|---|
| ResNet18 | 963.23 | 1 583.01 | 355.67 |
| ResNet34 | 1 764.66 | — | 459.45 |
| ResNet50 | 2 123.13 | 5 262.63 | 598.28 |
| 数据集 | 模型 | PyTorch | MPU | MPU+FPGA | VTA模拟器 | ||||
|---|---|---|---|---|---|---|---|---|---|
| top1 | top5 | top1 | top5 | top1 | top5 | top1 | top5 | ||
| AUC | ResNet18 | 95.20 | 99.86 | 95.20 | 99.86 | 95.04 | 99.82 | 95.04 | 99.82 |
| ResNet34 | 95.27 | 99.82 | — | — | 95.20 | 99.86 | 95.20 | 99.86 | |
| ResNet50 | 95.04 | 99.91 | 95.04 | 99.91 | 94.78 | 99.88 | 94.78 | 99.88 | |
| StateFarm | ResNet18 | 89.05 | 98.20 | 89.05 | 98.20 | 88.19 | 98.04 | 88.19 | 98.04 |
| ResNet34 | 90.23 | 98.42 | — | — | 90.01 | 98.47 | 90.01 | 98.47 | |
| ResNet50 | 90.40 | 98.28 | 90.40 | 98.28 | 87.47 | 97.63 | 87.47 | 97.63 | |
表4 AUC、StateFarm数据集训练的ResNet模型在不同硬件上的推理精度对比 ( %)
Tab. 4 Comparison of inference accuracy of ResNet models trained on AUC and StateFarm datasets on different hardware
| 数据集 | 模型 | PyTorch | MPU | MPU+FPGA | VTA模拟器 | ||||
|---|---|---|---|---|---|---|---|---|---|
| top1 | top5 | top1 | top5 | top1 | top5 | top1 | top5 | ||
| AUC | ResNet18 | 95.20 | 99.86 | 95.20 | 99.86 | 95.04 | 99.82 | 95.04 | 99.82 |
| ResNet34 | 95.27 | 99.82 | — | — | 95.20 | 99.86 | 95.20 | 99.86 | |
| ResNet50 | 95.04 | 99.91 | 95.04 | 99.91 | 94.78 | 99.88 | 94.78 | 99.88 | |
| StateFarm | ResNet18 | 89.05 | 98.20 | 89.05 | 98.20 | 88.19 | 98.04 | 88.19 | 98.04 |
| ResNet34 | 90.23 | 98.42 | — | — | 90.01 | 98.47 | 90.01 | 98.47 | |
| ResNet50 | 90.40 | 98.28 | 90.40 | 98.28 | 87.47 | 97.63 | 87.47 | 97.63 | |
| 模型 | VTA模拟器 | MPU+FPGA | ||
|---|---|---|---|---|
| 方案1 | 方案2 | 方案3 | 方案3 | |
| ResNet18 | 369.48 | 267.22 | 963.23 | 355.67 |
| ResNet34 | 404.74 | 330.84 | 1 764.66 | 459.45 |
| ResNet50 | 547.09 | 402.90 | 2 123.13 | 598.28 |
表5 ResNet模型在不同硬件上使用不同优化方案的推理时间对比 (ms)
Tab. 5 Comparison of inference time of ResNet models using different optimization schemes on different hardware
| 模型 | VTA模拟器 | MPU+FPGA | ||
|---|---|---|---|---|
| 方案1 | 方案2 | 方案3 | 方案3 | |
| ResNet18 | 369.48 | 267.22 | 963.23 | 355.67 |
| ResNet34 | 404.74 | 330.84 | 1 764.66 | 459.45 |
| ResNet50 | 547.09 | 402.90 | 2 123.13 | 598.28 |
| 数据集 | 模型 | VTA模拟器 | MPU+FPGA | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 方案1 | 方案2 | 方案3 | 方案1 | 方案2 | 方案3 | ||||||||
| top1 | top5 | top1 | top5 | top1 | top5 | top1 | top5 | top1 | top5 | top1 | top5 | ||
| AUC | ResNet18 | 95.20 | 99.86 | 95.04 | 99.82 | 95.04 | 99.82 | — | — | 95.04 | 99.82 | 95.04 | 99.82 |
| ResNet34 | 95.27 | 99.82 | 95.20 | 99.86 | 95.20 | 99.86 | — | — | 95.20 | 99.86 | 95.20 | 99.86 | |
| ResNet50 | 95.04 | 99.91 | 94.78 | 99.88 | 94.78 | 99.88 | — | — | 94.78 | 99.88 | 94.78 | 99.88 | |
| StateFarm | ResNet18 | 89.05 | 98.20 | 88.19 | 98.04 | 88.19 | 98.04 | — | — | 88.19 | 98.04 | 88.19 | 98.04 |
| ResNet34 | 90.23 | 98.42 | 90.01 | 98.47 | 90.01 | 98.47 | — | — | 90.01 | 98.47 | 90.01 | 98.47 | |
| ResNet50 | 90.40 | 98.28 | 87.47 | 97.63 | 87.47 | 97.63 | — | — | 87.47 | 97.63 | 87.47 | 97.63 | |
表6 AUC和StateFram数据集训练的ResNet模型在不同硬件上使用不同方案的推理精度对比 (%)
Tab. 6 Inference accuracy comparison of ResNet models trained on AUC and StateFram datasets using different schemes on different hardwares
| 数据集 | 模型 | VTA模拟器 | MPU+FPGA | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 方案1 | 方案2 | 方案3 | 方案1 | 方案2 | 方案3 | ||||||||
| top1 | top5 | top1 | top5 | top1 | top5 | top1 | top5 | top1 | top5 | top1 | top5 | ||
| AUC | ResNet18 | 95.20 | 99.86 | 95.04 | 99.82 | 95.04 | 99.82 | — | — | 95.04 | 99.82 | 95.04 | 99.82 |
| ResNet34 | 95.27 | 99.82 | 95.20 | 99.86 | 95.20 | 99.86 | — | — | 95.20 | 99.86 | 95.20 | 99.86 | |
| ResNet50 | 95.04 | 99.91 | 94.78 | 99.88 | 94.78 | 99.88 | — | — | 94.78 | 99.88 | 94.78 | 99.88 | |
| StateFarm | ResNet18 | 89.05 | 98.20 | 88.19 | 98.04 | 88.19 | 98.04 | — | — | 88.19 | 98.04 | 88.19 | 98.04 |
| ResNet34 | 90.23 | 98.42 | 90.01 | 98.47 | 90.01 | 98.47 | — | — | 90.01 | 98.47 | 90.01 | 98.47 | |
| ResNet50 | 90.40 | 98.28 | 87.47 | 97.63 | 87.47 | 97.63 | — | — | 87.47 | 97.63 | 87.47 | 97.63 | |
| 硬件 | 编译平台 | 价格/$ | DSP资源数 | 推理时间/ms |
|---|---|---|---|---|
| ZCU102 | Vitis A | 2 994 | 2 520 | 20.99 |
| ZCU104 | Vitis AI | 1 554 | 1 728 | 19.64 |
| VCK190 | Vitis AI | 13 195 | 1 968 | 1.18 |
| PYNQ-Z2 | TVM | 150~200 | 220 | 598.28 |
表7 Vitis AI支持的FPGA与PYNQ-Z2的硬件价格、硬件资源数和 ResNet50推理时间的对比
Tab. 7 Comparison of hardware price, hardware resources and ResNet50 inference time of Vitis AI-supported FPGA and PYNQ-Z2
| 硬件 | 编译平台 | 价格/$ | DSP资源数 | 推理时间/ms |
|---|---|---|---|---|
| ZCU102 | Vitis A | 2 994 | 2 520 | 20.99 |
| ZCU104 | Vitis AI | 1 554 | 1 728 | 19.64 |
| VCK190 | Vitis AI | 13 195 | 1 968 | 1.18 |
| PYNQ-Z2 | TVM | 150~200 | 220 | 598.28 |
| 1 | SOOMRO Z A, MEMON T D, NAZ F, et al. FPGA based real-time face authorization system for electronic voting system[C]// Proceedings of the 3rd International Conference on Computing, Mathematics and Engineering Technologies. Piscataway: IEEE, 2020: 1-6. 10.1109/icomet48670.2020.9073880 |
| 2 | PHAN-XUAN H, LE-TIEN T, NGUYEN-TAN S. FPGA platform applied for facial expression recognition system using convolutional neural networks[J]. Procedia Computer Science, 2019, 151: 651-658. 10.1016/j.procs.2019.04.087 |
| 3 | KIM J, KUMAR M, GOWDA D, et al. A comparison of streaming models and data augmentation methods for robust speech recognition[C]// Proceedings of the 2021 IEEE Automatic Speech Recognition and Understanding Workshop. Piscataway: IEEE, 2021:989-995. 10.1109/asru51503.2021.9688002 |
| 4 | LI G J, LIANG S, NIE S, et al. Deep neural network-based generalized sidelobe canceller for dual-channel far-field speech recognition[J]. Neural Networks, 2021, 141: 225-237. 10.1016/j.neunet.2021.04.017 |
| 5 | LIN J, KOVACS G, SHASTRY A, et al. Automatic correction of human translations[C]// Proceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. Stroudsburg, PA: ACL, 2022: 494-507. 10.18653/v1/2022.naacl-main.36 |
| 6 | LEE-THORP J, AINSLIE J, ECKSTEIN I, et al. FNet: mixing tokens with Fourier Transforms[C]// Proceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. Stroudsburg, PA: ACL, 2022: 4296-4313. 10.18653/v1/2022.naacl-main.319 |
| 7 | FAROUK Y, RADY S. Optimizing MRI registration using software/hardware co-design model on FPGA[J]. International Journal of Innovative Technology and Exploring Engineering, 2020, 10(2): 128-137. 10.35940/ijitee.b8300.1210220 |
| 8 | 焦李成,孙其功,杨育婷,等. 深度神经网络FPGA设计进展、实现与展望[J]. 计算机学报, 2022, 45(3):441-471. 10.11897/SP.J.1016.2022.00441 |
| JIAO L C, SUN Q G, YANG Y T, et al. Development, implementation and prospect of FPGA-based deep neural networks[J]. Chinese Journal of Computers, 2022, 45(3):441-471. 10.11897/SP.J.1016.2022.00441 | |
| 9 | CHEN T Q, MOREAU T, JIANG Z H, et al. TVM: an automated end-to-end optimizing compiler for deep learning[C]// Proceedings of the 13th USENIX Symposium on Operating Systems Design and Implementation. Berkeley: USENIX Association, 2018: 579-594. |
| 10 | MOREAU T, CHEN T Q, VEGA L, et al. A hardware-software blueprint for flexible deep learning specialization[J]. IEEE Micro, 2019, 39(5): 8-16. 10.1109/mm.2019.2928962 |
| 11 | PAN C P, CAO H T, ZHANG W W, at el. Driver activity recognition using spatial-temporal graph convolutional LSTM networks with attention mechanism[J]. IET Intelligent Transport Systems, 2021, 15(2):297-307. 10.1049/itr2.12025 |
| 12 | SILVA OLIVEIRA F R DA, FARIAS F C. Comparing transfer learning approaches applied to distracted driver detection[C]// Proceedings of the 2018 IEEE Latin American Conference on Computational Intelligence. Piscataway: IEEE, 2018:1-6. 10.1109/la-cci.2018.8625214 |
| 13 | BAHETI B, TALBAR S, GAJRE S. Towards computationally efficient and realtime distracted driver detection with MobileVGG network[J]. IEEE Transactions on Intelligent Vehicles, 2020, 5(4):565-574. 10.1109/tiv.2020.2995555 |
| 14 | CHEN J, LEE C, HUANG P, at el. Driver behavior analysis via two-stream deep convolutional neural network[J]. Applied Sciences, 2020, 10(6):1908-1922. 10.3390/app10061908 |
| 15 | VENIERIS S I, BOUGANIS C S. fpgaConvNet: a framework for mapping convolutional neural networks on FPGAs[C]// Proceedings of the IEEE 24th Annual International Symposium on Field-Programmable Custom Computing Machines. Piscataway: IEEE, 2016. 40-47. 10.1109/fccm.2016.22 |
| 16 | WANG Y, XU J, HAN Y H, et al. DeepBurning: automatic generation of FPGA-based learning accelerators for the neural network family[C]// Proceedings of the 53nd ACM/EDAC/IEEE Design Automation Conference. New York: ACM, 2016: 1-6. 10.1145/2897937.2898003 |
| 17 | ABDELOUAHAB K, PELCAT M, SÉROT J, et al. Tactics to directly map CNN graphs on embedded FPGAs[J]. IEEE Embedded Systems Letters, 2017, 9(4): 113-116. 10.1109/les.2017.2743247 |
| 18 | LIU Z Q, DOU Y, JIANG J F, et al. Automatic code generation of convolutional neural networks in FPGA implementation[C]// Proceedings of the 2016 International Conference on Field-Programmable Technology. Piscataway: IEEE, 2016: 61-68. 10.1109/fpt.2016.7929190 |
| 19 | SHARMA H, PARK J, MAHAJAN D, et al. From high-level deep neural models to FPGAs[C]// Proceedings of the 49th Annual IEEE/ACM International Symposium on Microarchitecture. Piscataway: IEEE, 2016: 1-12. 10.1109/micro.2016.7783720 |
| 20 | GUO K Y, SUI L Z, QIU J T, et al. Angel-Eye: a complete design flow for mapping CNN onto embedded FPGA[J]. IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems, 2018, 37(1): 35-47. 10.1109/tcad.2017.2705069 |
| 21 | MA Y F, SUDA N, CAO Y, et al. ALAMO: FPGA acceleration of deep learning algorithms with a modularized RTL compiler[J]. Integration, 2018, 62: 14-23. 10.1016/j.vlsi.2017.12.009 |
| 22 | GUAN Y J, LIANG H, XU N Y, et al. FP-DNN: an automated framework for mapping deep neural networks onto FPGAs with RTL-HLS hybrid templates[C]// Proceedings of the IEEE 25th Annual International Symposium on Field-Programmable Custom Computing Machines. Piscataway: IEEE, 2017:152-159. 10.1109/fccm.2017.25 |
| 23 | CYPHERS S, BANSAL A K, BHIWANDIWALLA A, et al. Intel® nGraphTM: an intermediate representation, compiler, and executor for deep learning[EB/OL]. (2018-01-30) [2022-03-25].. |
| 24 | Tensorflow. XLA - TensorFlow compiled[EB/OL]. [2022-03-15].. |
| 25 | ROTEM N, FIX J, ABDULRASOOL S, et al. Glow: graph lowering compiler techniques for neural networks[EB/OL]. (2019-04-03) [2022-04-05].. |
| 26 | VASILACHE N, ZINENKO O, THEODORIDIS T, et al. Tensor comprehensions: framework-agnostic high-performance machine learning abstractions[EB/OL]. (2018-06-29) [2022-05-03].. |
| 27 | ABOUELNAGA Y, ERAQI H M, MOUSTAFA M N, et al. Real-time distracted driver posture classification[EB/OL]. (2018-11-29) [2022-05-25].. |
| 28 | State farm distracted driving detection’s dataset[DS/OL]. (2016) [2022-05-15].. 10.1037/e732042011-001 |
| 29 | 李文静. 图像识别中小样本学习方法与模型轻量化研究[D]. 合肥:中国科学技术大学, 2021. |
| LI W J. Research on few-shot learning and model light-weighting in image recognition[D]. Hefei: University of Science and Technology of China, 2021. | |
| 30 | HE K M, ZHANG X Y, REN S Q, et al. Deep residual learning for image recognition[C]// Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2016:770-778. 10.1109/cvpr.2016.90 |
| [1] | 王娜, 蒋林, 李远成, 朱筠. 基于图形重写和融合探索的张量虚拟机算符融合优化[J]. 《计算机应用》唯一官方网站, 2024, 44(9): 2802-2809. |
| [2] | 石锐, 李勇, 朱延晗. 基于特征梯度均值化的调制信号对抗样本攻击算法[J]. 《计算机应用》唯一官方网站, 2024, 44(8): 2521-2527. |
| [3] | 王美, 苏雪松, 刘佳, 殷若南, 黄珊. 时频域多尺度交叉注意力融合的时间序列分类方法[J]. 《计算机应用》唯一官方网站, 2024, 44(6): 1842-1847. |
| [4] | 肖斌, 杨模, 汪敏, 秦光源, 李欢. 独立性视角下的相频融合领域泛化方法[J]. 《计算机应用》唯一官方网站, 2024, 44(4): 1002-1009. |
| [5] | 颜梦玫, 杨冬平. 深度神经网络平均场理论综述[J]. 《计算机应用》唯一官方网站, 2024, 44(2): 331-343. |
| [6] | 柴汶泽, 范菁, 孙书魁, 梁一鸣, 刘竟锋. 深度度量学习综述[J]. 《计算机应用》唯一官方网站, 2024, 44(10): 2995-3010. |
| [7] | 尚绍法, 蒋林, 李远成, 朱筠. 异构平台下卷积神经网络推理模型自适应划分和调度方法[J]. 《计算机应用》唯一官方网站, 2023, 43(9): 2828-2835. |
| [8] | 赵旭剑, 李杭霖. 基于混合机制的深度神经网络压缩算法[J]. 《计算机应用》唯一官方网站, 2023, 43(9): 2686-2691. |
| [9] | 李校林, 杨松佳. 基于深度学习的多用户毫米波中继网络混合波束赋形[J]. 《计算机应用》唯一官方网站, 2023, 43(8): 2511-2516. |
| [10] | 李淦, 牛洺第, 陈路, 杨静, 闫涛, 陈斌. 融合视觉特征增强机制的机器人弱光环境抓取检测[J]. 《计算机应用》唯一官方网站, 2023, 43(8): 2564-2571. |
| [11] | 杨海宇, 郭文普, 康凯. 基于卷积长短时深度神经网络的信号调制方式识别方法[J]. 《计算机应用》唯一官方网站, 2023, 43(4): 1318-1322. |
| [12] | 马英杰, 肖靖, 赵耿, 曾萍, 杨亚涛. 可控网格多涡卷混沌系统族及其硬件电路实现[J]. 《计算机应用》唯一官方网站, 2023, 43(3): 956-961. |
| [13] | 宋斌威, 王耀. 面向FPGA 知识产权保护的低开销按次付费授权方案[J]. 《计算机应用》唯一官方网站, 2023, 43(10): 3142-3148. |
| [14] | 高媛媛, 余振华, 杜方, 宋丽娟. 基于贝叶斯优化的无标签网络剪枝算法[J]. 《计算机应用》唯一官方网站, 2023, 43(1): 30-36. |
| [15] | 刘小宇, 陈怀新, 刘壁源, 林英, 马腾. 自适应置信度阈值的非限制场景车牌检测算法[J]. 《计算机应用》唯一官方网站, 2023, 43(1): 67-73. |
| 阅读次数 | ||||||
|
全文 |
|
|||||
|
摘要 |
|
|||||