


《计算机应用》唯一官方网站 ›› 2024, Vol. 44 ›› Issue (1): 65-72.DOI: 10.11772/j.issn.1001-9081.2022101527
林于翔1,2, 吴运兵1,2( ), 阴爱英3, 廖祥文1,2
), 阴爱英3, 廖祥文1,2
收稿日期:2022-10-14
修回日期:2023-02-08
接受日期:2023-02-14
发布日期:2023-04-12
出版日期:2024-01-10
通讯作者:
吴运兵
作者简介:林于翔(1998—),男,福建平潭人,硕士研究生,主要研究方向:多模态摘要、自然语言处理;基金资助:
Yuxiang LIN1,2, Yunbing WU1,2(), Aiying YIN3, Xiangwen LIAO1,2
Received:2022-10-14
Revised:2023-02-08
Accepted:2023-02-14
Online:2023-04-12
Published:2024-01-10
Contact:
Yunbing WU
About author:LIN Yuxiang, born in 1998, M. S. candidate. His research interests include multimodal summarization, natural language processing.Supported by:摘要:
多模态生成式摘要往往采用序列到序列(Seq2Seq)框架,目标函数在字符级别优化模型,根据局部最优解生成单词,忽略了摘要样本全局语义信息,使得摘要与多模态信息产生语义偏差,容易造成事实性错误。针对上述问题,提出一种基于语义相关性分析的多模态摘要模型。首先,在Seq2Seq框架基础上对多模态摘要进行训练,生成语义多样性的候选摘要;其次,构建基于语义相关性分析的摘要评估器,从全局的角度学习候选摘要之间的语义差异性和真实评价指标ROUGE (Recall-Oriented Understudy for Gisting Evaluation)的排序模式,从而在摘要样本层面优化模型;最后,不依赖参考摘要,利用摘要评估器对候选摘要进行评价,使得选出的摘要与源文本在语义空间中尽可能相似。实验结果表明,在公开数据集MMSS上,相较于MPMSE (Multimodal Pointer-generator via Multimodal Selective Encoding)模型,所提模型在ROUGE-1、ROUGE-2、ROUGE-L评价指标上分别提升了3.17、1.21和2.24个百分点。
中图分类号:
林于翔, 吴运兵, 阴爱英, 廖祥文. 基于语义相关性分析的多模态摘要模型[J]. 计算机应用, 2024, 44(1): 65-72.
Yuxiang LIN, Yunbing WU, Aiying YIN, Xiangwen LIAO. Multi-modal summarization model based on semantic relevance analysis[J]. Journal of Computer Applications, 2024, 44(1): 65-72.

图1 摘要事实性错误示例
Fig. 1 Example of factual error of summary

图2 基于语义相关性分析的多模态摘要模型流程
Fig. 2 Flow of multi-modal summarization model based on semantic relevance analysis
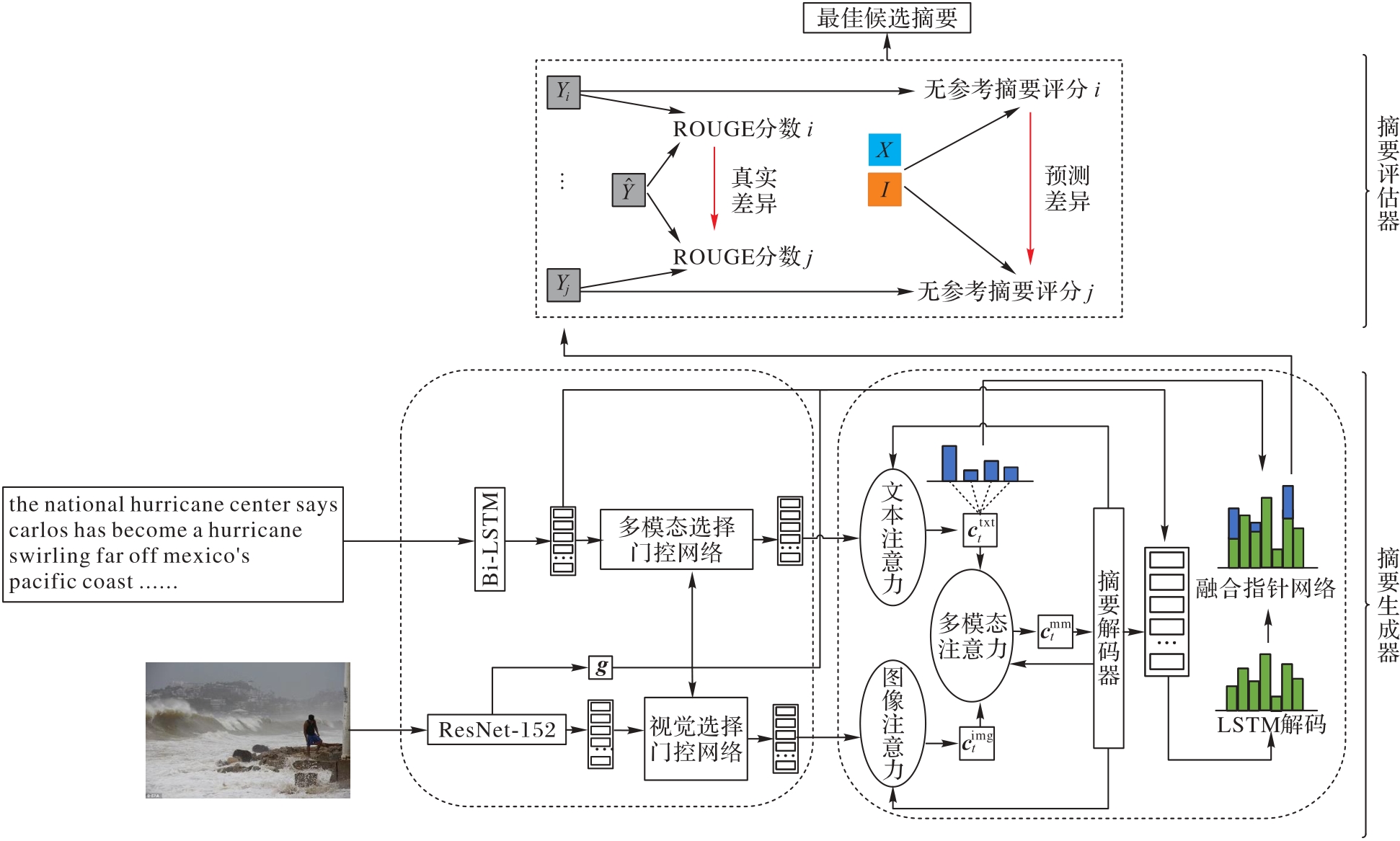
图3 基于语义相关性分析的多模态摘要模型
Fig. 3 Multi-modal summarization model based on semantic relevance analysis
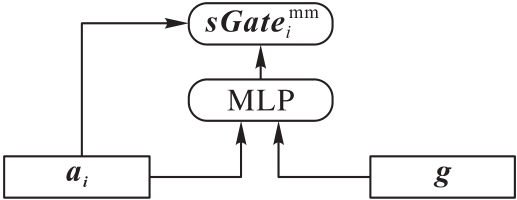
图4 视觉选择门控网络
Fig. 4 Visual selective gated network

图5 多模态选择门控网络
Fig. 5 Multi-modal selective gated network
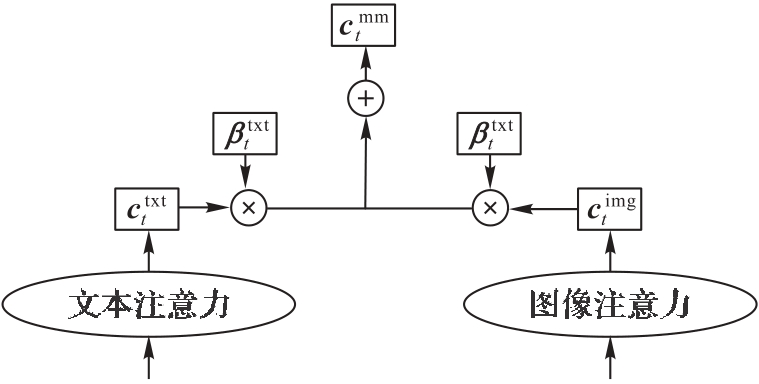
图6 多模态信息融合层原理
Fig. 6 Principle of multimodal information fusion layer
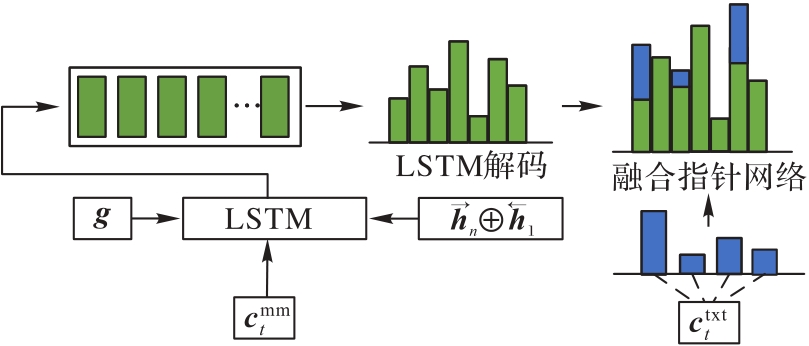
图7 解码流程
Fig. 7 Flow of decoding
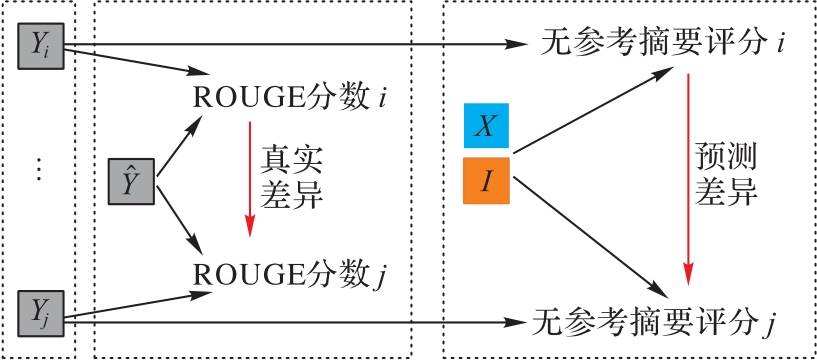
图8 摘要评估器
Fig. 8 Summary evaluator
| 数据集类别 | 句子-标题数 | 图片数 |
|---|---|---|
| 训练集 | 62 000 | 62 000 |
| 验证集 | 2 000 | 2 000 |
| 测试集 | 2 000 | 2 000 |
表1 MMSS数据集信息
Tab. 1 Information of MMSS dataset
| 数据集类别 | 句子-标题数 | 图片数 |
|---|---|---|
| 训练集 | 62 000 | 62 000 |
| 验证集 | 2 000 | 2 000 |
| 测试集 | 2 000 | 2 000 |
| 参数名称 | 值 | 参数名称 | 值 |
|---|---|---|---|
| 隐藏状态维度 | 512 | 初始学习率 | 0.000 5 |
| 词嵌入维度 | 300 | 学习率衰减率 | 0.5 |
| batch_size | 8 | Dropout | 0.2 |
| 集束搜索的束宽大小 | 16 | 梯度裁剪 | 2.0 |
表2 摘要生成模块的实验参数设置
Tab. 2 Experimental parameter settings of summary generation module
| 参数名称 | 值 | 参数名称 | 值 |
|---|---|---|---|
| 隐藏状态维度 | 512 | 初始学习率 | 0.000 5 |
| 词嵌入维度 | 300 | 学习率衰减率 | 0.5 |
| batch_size | 8 | Dropout | 0.2 |
| 集束搜索的束宽大小 | 16 | 梯度裁剪 | 2.0 |
| 参数名称 | 值 | 参数名称 | 值 |
|---|---|---|---|
| batch_size | 8 | warmup steps | 1 000 |
| num_epoch | 8 | max_lr | 0.002 |
表3 摘要评估模块的实验参数设置
Tab. 3 Experimental parameter settings of summary evaluation module
| 参数名称 | 值 | 参数名称 | 值 |
|---|---|---|---|
| batch_size | 8 | warmup steps | 1 000 |
| num_epoch | 8 | max_lr | 0.002 |
| 模型 | ROUGE-1 | ROUGE-2 | ROUGE-L |
|---|---|---|---|
| Compress[ | 31.56 | 11.02 | 28.87 |
| ABS[ | 35.95 | 18.21 | 31.89 |
| SEASS[ | 44.86 | 23.03 | 41.92 |
| PGNet[ | 46.05 | 24.18 | 44.16 |
| MAtt[ | 45.78 | 23.45 | 43.16 |
| MPID[ | 48.11 | 24.70 | 44.96 |
| MPMSE[ | 48.19 | 25.64 | 45.27 |
| 本文模型 | 51.36 | 26.85 | 47.51 |
表4 在MMSS数据集上的实验结果 ( %)
Tab. 4 Experimental results on MMSS dataset
| 模型 | ROUGE-1 | ROUGE-2 | ROUGE-L |
|---|---|---|---|
| Compress[ | 31.56 | 11.02 | 28.87 |
| ABS[ | 35.95 | 18.21 | 31.89 |
| SEASS[ | 44.86 | 23.03 | 41.92 |
| PGNet[ | 46.05 | 24.18 | 44.16 |
| MAtt[ | 45.78 | 23.45 | 43.16 |
| MPID[ | 48.11 | 24.70 | 44.96 |
| MPMSE[ | 48.19 | 25.64 | 45.27 |
| 本文模型 | 51.36 | 26.85 | 47.51 |
| 模型 | ROUGE-1 | ROUGE-2 | ROUGE-L |
|---|---|---|---|
| 本文模型 | 51.36 | 26.85 | 47.51 |
| w/o | 50.40 | 26.12 | 46.68 |
| w/o | 48.79 | 25.94 | 45.72 |
表5 去除不同模块对实验结果的影响 ( %)
Tab. 5 Influence of removing different modules on experimental results
| 模型 | ROUGE-1 | ROUGE-2 | ROUGE-L |
|---|---|---|---|
| 本文模型 | 51.36 | 26.85 | 47.51 |
| w/o | 50.40 | 26.12 | 46.68 |
| w/o | 48.79 | 25.94 | 45.72 |
| 模型 | ROUGE-1 | ROUGE-2 | ROUGE-L |
|---|---|---|---|
| 无摘要评估器 | 48.79 | 25.94 | 45.72 |
| 摘要评估器 | 51.36 | 26.85 | 47.51 |
| 摘要评估器 | 49.86 | 26.14 | 46.54 |
表6 不同摘要评估器的实验结果 ( %)
Tab. 6 Experimental results of different summary evaluators
| 模型 | ROUGE-1 | ROUGE-2 | ROUGE-L |
|---|---|---|---|
| 无摘要评估器 | 48.79 | 25.94 | 45.72 |
| 摘要评估器 | 51.36 | 26.85 | 47.51 |
| 摘要评估器 | 49.86 | 26.14 | 46.54 |
| 模型 | ROUGE-1 | ROUGE-2 | ROUGE-L |
|---|---|---|---|
| 本文模型 | 51.36 | 26.85 | 47.51 |
| 50.40 | 26.12 | 46.68 | |
| 50.75 | 26.16 | 46.76 | |
| 50.46 | 25.72 | 46.32 |
表7 去除不同模块视觉全局信息对实验结果的影响 ( %)
Tab. 7 Influence of removing visual global information of different modules on experimental results
| 模型 | ROUGE-1 | ROUGE-2 | ROUGE-L |
|---|---|---|---|
| 本文模型 | 51.36 | 26.85 | 47.51 |
| 50.40 | 26.12 | 46.68 | |
| 50.75 | 26.16 | 46.76 | |
| 50.46 | 25.72 | 46.32 |
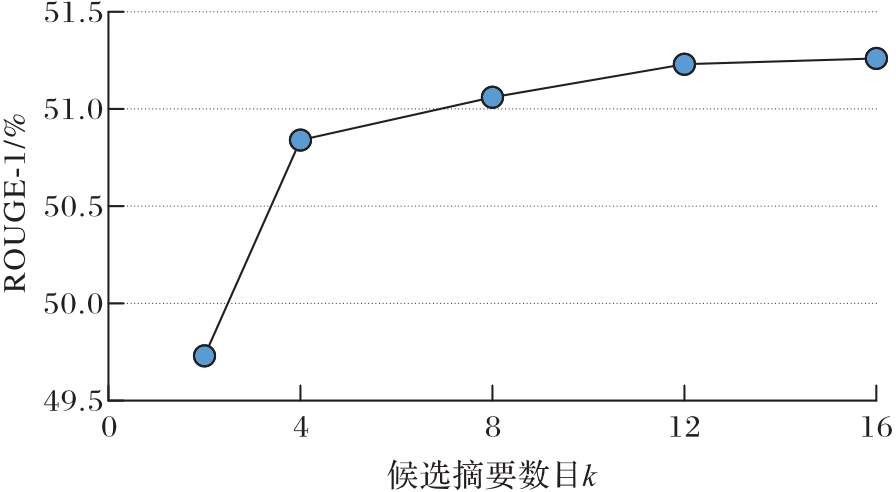
图9 候选摘要个数对实验结果的影响
Fig. 9 Influence of number of candidate summaries on experimental results

图10 原摘要与生成摘要的对比
Fig. 10 Comparison of original and generated summaries
| 1 | SOLEYMANI M, GARCIA D, JOU B, et al. A survey of multimodal sentiment analysis [J]. Image and Vision Computing, 2017, 65(9): 3-14. 10.1016/j.imavis.2017.08.003 |
| 2 | LI H, ZHU J, LIU T, et al. Multi-modal sentence summarization with modality attention and image filtering [C]// Proceedings of the Twenty-Seventh International Joint Conference on Artificial Intelligence. Palo Alto: AAAI Press, 2018: 4152-4158. 10.24963/ijcai.2018/577 |
| 3 | LI H, ZHU J, ZHANG J, et al. Multimodal sentence summarization via multimodal selective encoding [C]// Proceedings of the 28th International Conference on Computational Linguistics. [S.l.]: International Committee on Computational Linguistics, 2020: 5655-5667. 10.18653/v1/2020.coling-main.496 |
| 4 | MIHALCEA R, TARAU P. TextRank: Bringing order into text [C]// Proceedings of the 2004 Conference on Empirical Methods in Natural Language Processing. Stroudsburg, PA: Association for Computational Linguistics, 2004: 404-411. 10.3115/1220355.1220517 |
| 5 | RUSH A M, CHOPRA S, WESTON J. A neural attention model for abstractive sentence summarization [C]// Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing. Stroudsburg, PA: Association for Computational Linguistics, 2015: 379-389. 10.18653/v1/d15-1044 |
| 6 | CHOPRA S, AULI M, RUSH A M. Abstractive sentence summarization with attentive recurrent neural networks [C]// Proceedings of the 2016 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. Stroudsburg, PA: Association for Computational Linguistics, 2016: 93-98. 10.18653/v1/n16-1012 |
| 7 | NALLAPATI R, ZHOU B, SANTOS C D, et al. Abstractive text summarization using sequence-to-sequence RNNs and beyond [C]// Proceedings of the 20th SIGNLL Conference on Computational Natural Language Learning. Stroudsburg, PA: Association for Computational Linguistics, 2016: 280-290. 10.18653/v1/k16-1028 |
| 8 | GU J, LU Z, LI H, et al. Incorporating copying mechanism in sequence-to-sequence learning [C]// Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics. Stroudsburg, PA: Association for Computational Linguistics, 2016: 1631-1640. 10.18653/v1/p16-1154 |
| 9 | SEE A, LIU P J, MANNING C D. Get to the point: Summarization with pointer-generator networks [C]// Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Stroudsburg, PA: Association for Computational Linguistics, 2017: 1073-1083. 10.18653/v1/p17-1099 |
| 10 | ZHU J, LI H, LIU T, et al. MSMO: Multimodal summarization with multimodal output [C]// Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing. Stroudsburg, PA: Association for Computational Linguistics, 2018: 4154-4164. 10.18653/v1/d18-1448 |
| 11 | YE X, YUE Z, LIU R. MBA: A multimodal bilinear attention model with residual connection for abstractive multimodal summarization [J]. Journal of Physics: Conference Series, 2021, 1856: 012070. 10.1088/1742-6596/1856/1/012070 |
| 12 | ZHANG Z, WANG J, SUN Z, et al. LAMS: A location-aware approach for multimodal summarization [J]. Proceedings of the AAAI Conference on Artificial Intelligence, 2021, 35(18): 15949-15950. 10.1609/aaai.v35i18.17971 |
| 13 | LIU Y, LIU P. SimCLS: A simple framework for contrastive learning of abstractive summarization [C]// Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 2: Short Papers). Stroudsburg, PA: Association for Computational Linguistics, 2021: 1065-1072. 10.18653/v1/2021.acl-short.135 |
| 14 | PAULUS R, XIONG C, SOCHER R. A deep reinforced model for abstractive summarization [EB/OL]. [2022-10-01]. . |
| 15 | LI S, LEI D, QIN P, et al. Deep reinforcement learning with distributional semantic rewards for abstractive summarization [C]// Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing. Stroudsburg, PA: Association for Computational Linguistics, 2019: 6038-6044. 10.18653/v1/d19-1623 |
| 16 | SHEN W, GONG Y, SHEN Y, et al. Joint generator-ranker learning for natural language generation [EB/OL]. (2022-10-19) [2023-02-06]. . 10.18653/v1/2023.findings-acl.486 |
| 17 | PAN H, LIN Z, FU P, et al. Modeling intra and inter-modality incongruity for multi-modal sarcasm detection [C]// Findings of the Association for Computational Linguistics: EMNLP 2020. Stroudsburg, PA: Association for Computational Linguistics, 2020: 1383-1392. 10.18653/v1/2020.findings-emnlp.124 |
| 18 | SCHUSTER M, PALIWAL K K. Bidirectional recurrent neural networks [J]. IEEE Transactions on Signal Processing, 1997, 45(11): 2673-2681. 10.1109/78.650093 |
| 19 | BAHDANAU D, CHO K, BENGIO Y. Neural machine translation by jointly learning to align and translate [EB/OL]. [2022-10-01]. . 10.1017/9781108608480.003 |
| 20 | HOCHREITER S, SCHMIDHUBER J. Long short-term memory [J]. Neural Computation, 1997, 9(8): 1735-1780. 10.1162/neco.1997.9.8.1735 |
| 21 | LIU Y, OTT M, GOYAL N, et al. RoBERTa: a robustly optimized BERT pretraining approach [EB/OL]. (2019-06-26) [2023-02-06]. . |
| 22 | 蔡中祥,孙建伟.融合指针网络的新闻文本摘要模型[J].小型微型计算机系统, 2021, 42(3): 462-466. 10.3969/j.issn.1000-1220.2021.03.003 |
| CAI Z X, SUN J W. News text summarization model integrating pointer network [J]. Journal of Chinese Computer Systems, 2021, 42(3): 462-466. 10.3969/j.issn.1000-1220.2021.03.003 | |
| 23 | LI H, YUAN P, XU S, et al. Aspect-aware multimodal summarization for Chinese e-commerce products [J]. Proceedings of the AAAI Conference on Artificial Intelligence, 2020, 34(5): 8188-8195. 10.1609/aaai.v34i05.6332 |
| 24 | CLARKE J, LAPATA M. Global inference for sentence compression: An integer linear programming approach [J]. Journal of Artificial Intelligence Research, 2008, 31(1): 399-429. 10.1613/jair.2433 |
| 25 | ZHOU Q, YANG N, WEI F, et al. Selective encoding for abstractive sentence summarization [C]// Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics. Stroudsburg, PA: Association for Computational Linguistics, 2017: 1095-1104. 10.18653/v1/p17-1101 |
| [1] | 黄懿蕊, 罗俊玮, 陈景强. 基于对比学习和GIF标记的多模态对话回复检索[J]. 《计算机应用》唯一官方网站, 2024, 44(1): 32-38. |
| [2] | 王春雷, 王肖, 刘凯. 多模态知识图谱表示学习综述[J]. 《计算机应用》唯一官方网站, 2024, 44(1): 1-15. |
| [3] | 陈佳, 张鸿. 基于特征增强和语义相关性匹配的图像文本检索方法[J]. 《计算机应用》唯一官方网站, 2024, 44(1): 16-23. |
| [4] | 林剑, 叶璟轩, 刘雯雯, 邵晓雯. 求解带容量约束车辆路径问题的多模态差分进化算法[J]. 《计算机应用》唯一官方网站, 2023, 43(7): 2248-2254. |
| [5] | 何嘉明, 杨巨成, 吴超, 闫潇宁, 许能华. 基于多模态图卷积神经网络的行人重识别方法[J]. 《计算机应用》唯一官方网站, 2023, 43(7): 2182-2189. |
| [6] | 王惠茹, 李秀红, 李哲, 马春明, 任泽裕, 杨丹. 多模态预训练模型综述[J]. 《计算机应用》唯一官方网站, 2023, 43(4): 991-1004. |
| [7] | 李路宝, 陈田, 任福继, 罗蓓蓓. 基于图神经网络和注意力的双模态情感识别方法[J]. 《计算机应用》唯一官方网站, 2023, 43(3): 700-705. |
| [8] | 孙晓飞, 朱静远, 陈斌, 游恒志. 融合多模态数据的药物合成反应的虚拟筛选[J]. 《计算机应用》唯一官方网站, 2023, 43(2): 622-629. |
| [9] | 孙梦迪, 孙忠贵, 孔旭, 韩红燕. 针对多模态图像的自适应引导形态学设计[J]. 《计算机应用》唯一官方网站, 2023, 43(2): 560-566. |
| [10] | 窦猛, 陈哲彬, 王辛, 周继陶, 姚宇. 基于深度学习的多模态医学图像分割综述[J]. 《计算机应用》唯一官方网站, 2023, 43(11): 3385-3395. |
| [11] | 毕以镇, 马焕, 张长青. 增广模态收益动态评估方法[J]. 《计算机应用》唯一官方网站, 2023, 43(10): 3099-3106. |
| [12] | 吴明晖, 张广洁, 金苍宏. 基于多模态信息融合的时间序列预测模型[J]. 《计算机应用》唯一官方网站, 2022, 42(8): 2326-2332. |
| [13] | 韩滕跃, 牛少彰, 张文. 基于对比学习的多模态序列推荐算法[J]. 《计算机应用》唯一官方网站, 2022, 42(6): 1683-1688. |
| [14] | 余娜, 刘彦, 魏雄炬, 万源. 基于注意力机制和金字塔融合的RGB-D室内场景语义分割[J]. 《计算机应用》唯一官方网站, 2022, 42(3): 844-853. |
| [15] | 孙邱杰, 梁景贵, 李思. 基于BART噪声器的中文语法纠错模型[J]. 《计算机应用》唯一官方网站, 2022, 42(3): 860-866. |
| 阅读次数 | ||||||
|
全文 |
|
|||||
|
摘要 |
|
|||||