


Journal of Computer Applications ›› 2024, Vol. 44 ›› Issue (2): 445-451.DOI: 10.11772/j.issn.1001-9081.2023020153
Special Issue: 人工智能
• Artificial intelligence • Previous Articles Next Articles
Yuanchao LI1, Chongben TAO1,2( ), Chen WANG1
), Chen WANG1
Received:2023-02-21
Revised:2023-04-20
Accepted:2023-05-05
Online:2023-08-14
Published:2024-02-10
Contact:
Chongben TAO
About author:LI Yuanchao, born in 1999, M. S. candidate. His research interests include artificial intelligence, biped robot motion control.Supported by:
李源潮1, 陶重犇1,2(), 王琛1
通讯作者:
陶重犇
作者简介:李源潮(1999—),男,江苏连云港人,硕士研究生,主要研究方向:人工智能、双足机器人运动控制基金资助:CLC Number:
Yuanchao LI, Chongben TAO, Chen WANG. Gait control method based on maximum entropy deep reinforcement learning for biped robot[J]. Journal of Computer Applications, 2024, 44(2): 445-451.
李源潮, 陶重犇, 王琛. 基于最大熵深度强化学习的双足机器人步态控制方法[J]. 《计算机应用》唯一官方网站, 2024, 44(2): 445-451.
Add to citation manager EndNote|Ris|BibTeX
URL: https://www.joca.cn/EN/10.11772/j.issn.1001-9081.2023020153

Fig.1 Overall framework of the proposed gait control method
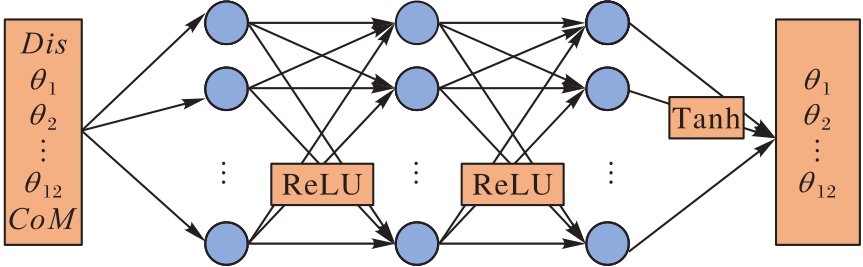
Fig. 2 Structure of policy network
| 参数 | 描述 |
|---|---|
| Dis | 行走距离 |
| HipR/L pitch | 髋关节绕y轴旋转的角度 |
| HipR/L roll | 髋关节绕x轴旋转的角度 |
| HipR/L yaw | 髋关节绕z轴旋转的角度 |
| KneeR/L pitch | 膝关节绕y轴旋转的角度 |
| AnkleR/L pitch | 踝关节绕y轴旋转的角度 |
| AnkleR/L roll | 踝关节绕x轴旋转的角度 |
| CoMoffx | 质心在x轴的偏差 |
| CoMoffy | 质心在y轴的偏差 |
Tab. 1 State space
| 参数 | 描述 |
|---|---|
| Dis | 行走距离 |
| HipR/L pitch | 髋关节绕y轴旋转的角度 |
| HipR/L roll | 髋关节绕x轴旋转的角度 |
| HipR/L yaw | 髋关节绕z轴旋转的角度 |
| KneeR/L pitch | 膝关节绕y轴旋转的角度 |
| AnkleR/L pitch | 踝关节绕y轴旋转的角度 |
| AnkleR/L roll | 踝关节绕x轴旋转的角度 |
| CoMoffx | 质心在x轴的偏差 |
| CoMoffy | 质心在y轴的偏差 |
| 参数 | 描述 |
|---|---|
| HipR/L pitch | 髋关节绕y轴旋转的角度 |
| HipR/L roll | 髋关节绕x轴旋转的角度 |
| HipR/L yaw | 髋关节绕z轴旋转的角度 |
| KneeR/L pitch | 膝关节绕y轴旋转的角度 |
| AnkleR/L roll | 踝关节绕x轴旋转的角度 |
| AnkleR/L pitch | 踝关节绕y轴旋转的角度 |
Tab. 2 Action space
| 参数 | 描述 |
|---|---|
| HipR/L pitch | 髋关节绕y轴旋转的角度 |
| HipR/L roll | 髋关节绕x轴旋转的角度 |
| HipR/L yaw | 髋关节绕z轴旋转的角度 |
| KneeR/L pitch | 膝关节绕y轴旋转的角度 |
| AnkleR/L roll | 踝关节绕x轴旋转的角度 |
| AnkleR/L pitch | 踝关节绕y轴旋转的角度 |
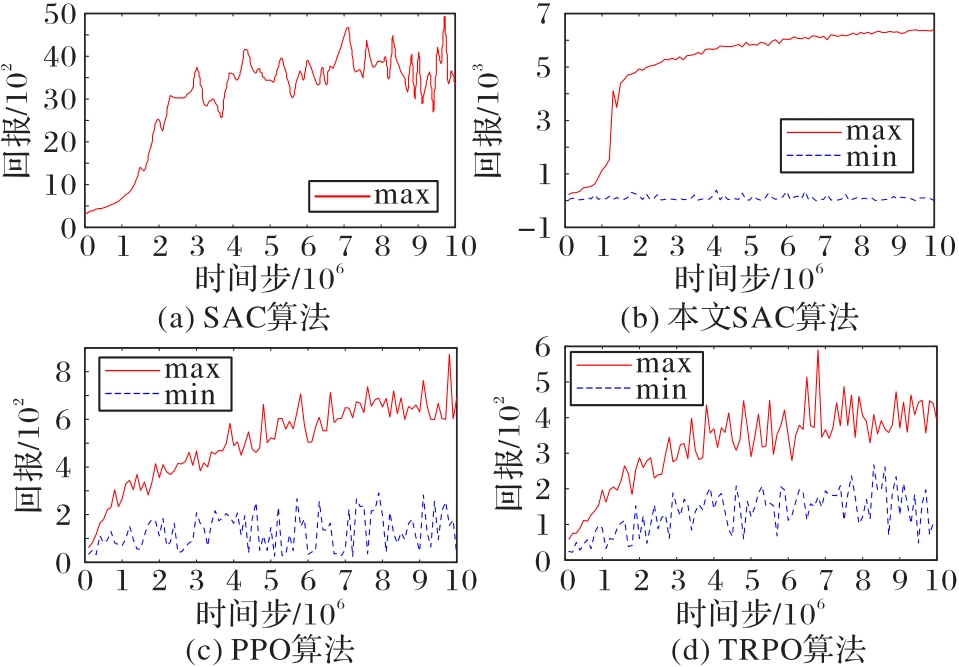
Fig. 3 Comparison of reward values among four algorithms
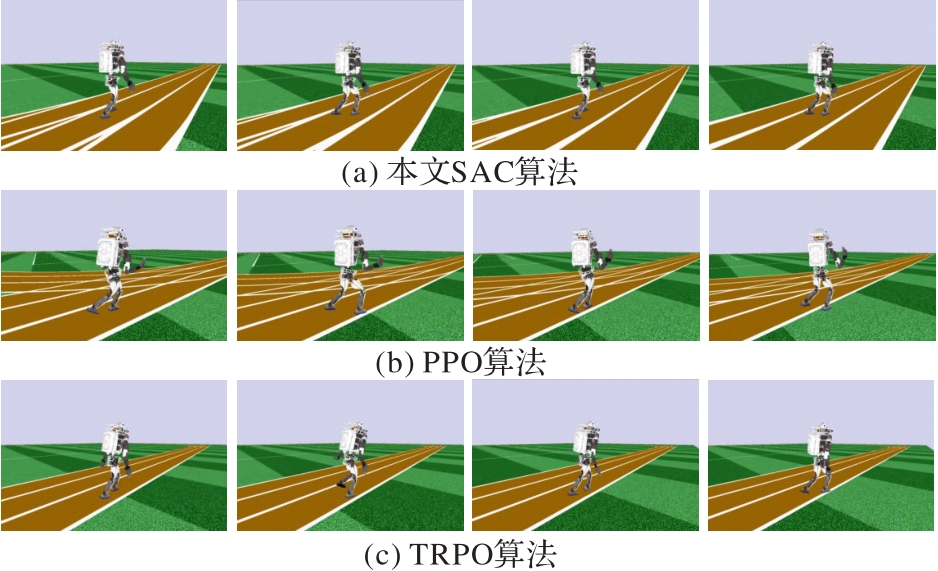
Fig.4 Detail of biped robot walking in Roboschool
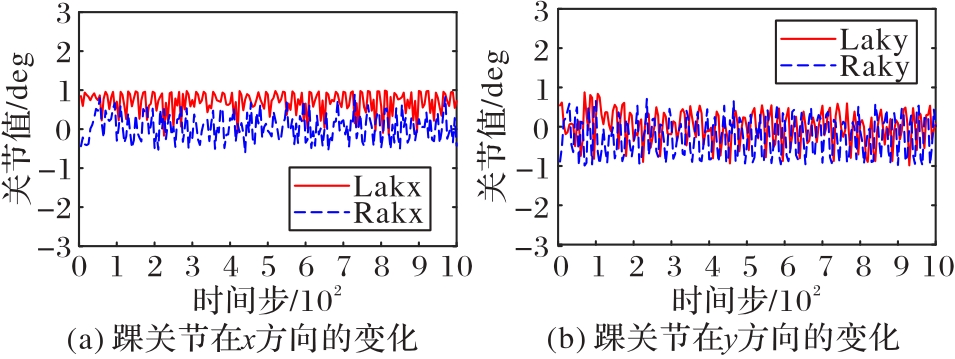
Fig. 5 Changes in ankle joint angle
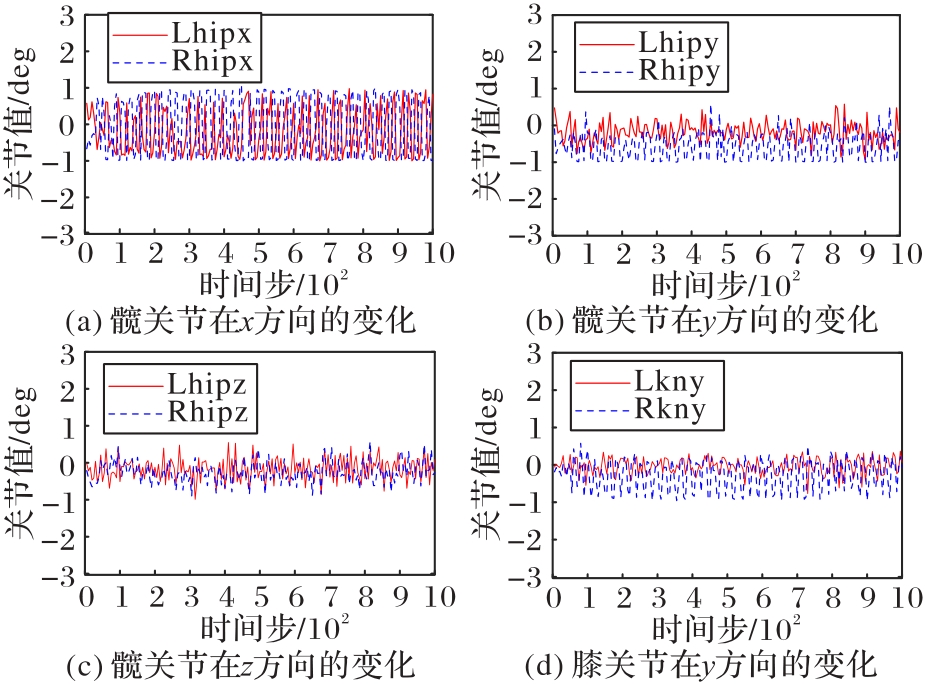
Fig. 6 Changes in angles of hip and knee joints

Fig. 7 Robust control when external forces being applied forward

Fig. 8 Robust control when external forces being applied to right side of biped robot
| 1 | LI Z, CHENG X, PENG X B, et al. Reinforcement learning for robust parameterized locomotion control of bipedal robots[C]// Proceedings of the 2021 IEEE International Conference on Robotics and Automation. Piscataway: IEEE, 2021: 2811-2817. 10.1109/icra48506.2021.9560769 |
| 2 | KHAN A T, LI S, CAO X. Human guided cooperative robotic agents in smart home using beetle antennae search[J]. Science China Information Sciences, 2022, 65: 122204. 10.1007/s11432-020-3073-5 |
| 3 | XIN S, VIJAYAKUMAR S. Online dynamic motion planning and control for wheeled biped robots[C]// Proceedings of the 2020 IEEE/RSJ International Conference on Intelligent Robots and Systems. Piscataway: IEEE, 2020: 3892-3899. 10.1109/iros45743.2020.9340967 |
| 4 | KHAN A T, LI S, ZHOU X. Trajectory optimization of 5-link biped robot using beetle antennae search[J]. IEEE Transactions on Circuits and Systems II: Express Briefs, 2021, 68(10): 3276-3280. 10.1109/tcsii.2021.3062639 |
| 5 | JEONG H, LEE I, OH J, et al. A robust walking controller based on online optimization of ankle, hip, and stepping strategies[J]. IEEE Transactions on Robotics, 2019, 35(6): 1367-1386. 10.1109/tro.2019.2926487 |
| 6 | 廖发康, 周亚丽, 张奇志. 变长度柔性双足机器人行走控制及稳定性分析[J]. 计算机应用, 2023, 43(1): 312-320. |
| LIAO F K, ZHOU Y L, ZHANG Q Z. Walking control and stability analysis of flexible biped robot with variable length legs[J]. Journal of Computer Applications, 2023, 43(1): 312-320. | |
| 7 | 张瑞, 张奇志, 周亚丽. 变长度弹性伸缩腿双足机器人半被动起步行走仿人控制[J]. 计算机应用, 2022, 42(1): 252-257. |
| ZHANG R, ZHANG Q Z, ZHOU Y L. Starting and walking human-like control of semi-passive bipedal robot with variable length telescopic legs[J]. Journal of Computer Applications, 2022, 42(1): 252-257. | |
| 8 | YU J, LIU Y, LI R, et al. Stable walking of seven-link biped robot based on CPG-ZMP hybrid control method[C]// Proceedings of the 2021 IEEE International Conference on Robotics and Biomimetics. Piscataway: IEEE, 2021: 870-874. 10.1109/robio54168.2021.9739430 |
| 9 | YAMAMOTO T, SUGIHARA T. Foot-guided control of a biped robot through ZMP manipulation[J]. Advanced Robotics, 2020, 34(21/22): 1472-1489. 10.1080/01691864.2020.1827031 |
| 10 | TAN J, ZHANG T, COUMANS E, et al. Sim-to-real: learning agile locomotion for quadruped robots[EB/OL]. (2018-05-16) [2023-02-11]. . 10.15607/rss.2018.xiv.010 |
| 11 | HAARNOJA T, HA S, ZHOU A, et al. Learning to walk via deep reinforcement learning[EB/OL]. (2019-06-19) [2023-02-11]. . 10.15607/rss.2019.xv.011 |
| 12 | ARULKUMARAN K, DEISENROTH M P, BRUNDAGE M, et al. Deep reinforcement learning: a brief survey[J]. IEEE Signal Processing Magazine, 2017, 34(6): 26-38. 10.1109/msp.2017.2743240 |
| 13 | LILLICRAP T P, HUNT J J, PRITZEL A, et al. Continuous control with deep reinforcement learning[EB/OL]. (2019-07-05) [2023-02-11]. . |
| 14 | MNIH V, BADIA A P, MIRZA M, et al. Asynchronous methods for deep reinforcement learning[C]// Proceedings of the 2016 International Conference on Machine Learning. New York: JMLR.org, 2016: 1928-1937. |
| 15 | WU Y, YAO D, XIAO X, et al. Intelligent controller for passivity-based biped robot using deep Q network[J]. Journal of Intelligent & Fuzzy Systems, 2019, 36(1): 731-745. 10.3233/jifs-172180 |
| 16 | WU X, LIU S, ZHANG T, et al. Motion control for biped robot via DDPG-based deep reinforcement learning[C]// Proceedings of the 2018 WRC Symposium on Advanced Robotics and Automation. Piscataway: IEEE, 2018: 40-45. 10.1109/wrc-sara.2018.8584227 |
| 17 | SCHULMAN J, WOLSKI F, DHARIWAL P, et al. Proximal policy optimization algorithms[EB/OL]. (2017-08-28) [2023-02-11]. . |
| 18 | SCHULMAN J, LEVINE S, MORITZ P, et al. Trust region policy optimization[C]// Proceedings of the 32nd International Conference on Machine Learning. New York: JMLR.org, 2015: 1889-1897. |
| 19 | WU Y-H, YU Z-C, LI C-Y, et al. Reinforcement learning in dual-arm trajectory planning for a free-floating space robot[J]. Aerospace Science and Technology, 2020, 98: 105657. 10.1016/j.ast.2019.105657 |
| 20 | 赵玉婷, 韩宝玲, 罗庆生. 基于deep Q-network双足机器人非平整地面行走稳定性控制方法[J]. 计算机应用, 2018, 38(9): 2459-2463. |
| ZHAO Y T, HAN B L, LUO Q S. Walking stability control method based on deep Q-network for biped robot on uneven ground[J]. Journal of Computer Applications, 2018, 38(9): 2459-2463. | |
| 21 | TAO C, XUE J, ZHANG Z, et al. Parallel deep reinforcement learning method for gait control of biped robot[J]. IEEE Transactions on Circuits and Systems II: Express Briefs, 2022, 69(6): 2802-2806. 10.1109/tcsii.2022.3145373 |
| 22 | RODRIGUEZ D, BEHNKE S. DeepWalk: omnidirectional bipedal gait by deep reinforcement learning[C]// Proceedings of the 2021 IEEE International Conference on Robotics and Automation. Piscataway: IEEE, 2021: 3033-3039. 10.1109/icra48506.2021.9561717 |
| 23 | HAARNOJA T, PONG V, ZHOU A, et al. Composable deep reinforcement learning for robotic manipulation[C]// Proceedings of the 2018 IEEE International Conference on Robotics and Automation. Piscataway: IEEE, 2018: 6244-6251. 10.1109/icra.2018.8460756 |
| 24 | MNIH V, KAVUKCUOGLU K, SILVER D, et al. Playing Atari with deep reinforcement learning[EB/OL]. (2013-12-19) [2023-02-11]. . 10.1038/nature14236 |
| 25 | HAARNOJA T, ZHOU A, ABBEEL P, et al. Soft actor-critic: off-policy maximum entropy deep reinforcement learning with a stochastic actor[C]// Proceedings of the 2018 International Conference on Machine Learning. New York: JMLR.org, 2018: 1861-1870. 10.1109/icra.2018.8460756 |
| 26 | SCHAUL T, QUAN J, ANTONOGLOU I, et al. Prioritized experience replay[EB/OL]. (2016-02-25) [2023-02-11]. . |
| 27 | FUJITA Y, NAGARAJAN P, KATAOKA T, et al. ChainerRL: a deep reinforcement learning library[J]. The Journal of Machine Learning Research, 2021, 22(1): 3557-3570. |
| 28 | CASTILLO G A, WENG B, HEREID A, et al. Reinforcement learning meets hybrid zero dynamics: a case study for rabbit[C]// Proceedings of the 2019 International Conference on Robotics and Automation. Piscataway: IEEE, 2019: 284-290. 10.1109/icra.2019.8793627 |
| [1] | Yi ZHOU, Hua GAO, Yongshen TIAN. Proximal policy optimization algorithm based on clipping optimization and policy guidance [J]. Journal of Computer Applications, 2024, 44(8): 2334-2341. |
| [2] | Tian MA, Runtao XI, Jiahao LYU, Yijie ZENG, Jiayi YANG, Jiehui ZHANG. Mobile robot 3D space path planning method based on deep reinforcement learning [J]. Journal of Computer Applications, 2024, 44(7): 2055-2064. |
| [3] | Xiaoyan ZHAO, Wei HAN, Junna ZHANG, Peiyan YUAN. Collaborative offloading strategy in internet of vehicles based on asynchronous deep reinforcement learning [J]. Journal of Computer Applications, 2024, 44(5): 1501-1510. |
| [4] | Rui TANG, Chuanlin PANG, Ruizhi ZHANG, Chuan LIU, Shibo YUE. DDPG-based resource allocation in D2D communication-empowered cellular network [J]. Journal of Computer Applications, 2024, 44(5): 1562-1569. |
| [5] | Xintong QIN, Zhengyu SONG, Tianwei HOU, Feiyue WANG, Xin SUN, Wei LI. Channel access and resource allocation algorithm for adaptive p-persistent mobile ad hoc network [J]. Journal of Computer Applications, 2024, 44(3): 863-868. |
| [6] | Fuqin DENG, Huifeng GUAN, Chaoen TAN, Lanhui FU, Hongmin WANG, Tinlun LAM, Jianmin ZHANG. Multi-robot reinforcement learning path planning method based on request-response communication mechanism and local attention mechanism [J]. Journal of Computer Applications, 2024, 44(2): 432-438. |
| [7] | Ziyang SONG, Junhuai LI, Huaijun WANG, Xin SU, Lei YU. Path planning algorithm of manipulator based on path imitation and SAC reinforcement learning [J]. Journal of Computer Applications, 2024, 44(2): 439-444. |
| [8] | Jiachen YU, Ye YANG. Irregular object grasping by soft robotic arm based on clipped proximal policy optimization algorithm [J]. Journal of Computer Applications, 2024, 44(11): 3629-3638. |
| [9] | Jie LONG, Liang XIE, Haijiao XU. Integrated deep reinforcement learning portfolio model [J]. Journal of Computer Applications, 2024, 44(1): 300-310. |
| [10] | Yu WANG, Tianjun REN, Zilin FAN. Air combat maneuver decision-making of unmanned aerial vehicle based on guided Minimax-DDQN [J]. Journal of Computer Applications, 2023, 43(8): 2636-2643. |
| [11] | Ziteng WANG, Yaxin YU, Zifang XIA, Jiaqi QIAO. Sparse reward exploration mechanism fusing curiosity and policy distillation [J]. Journal of Computer Applications, 2023, 43(7): 2082-2090. |
| [12] | Heping FANG, Shuguang LIU, Yongyi RAN, Kunhua ZHONG. Integrated scheduling optimization of multiple data centers based on deep reinforcement learning [J]. Journal of Computer Applications, 2023, 43(6): 1884-1892. |
| [13] | Xiaolin LI, Yusang JIANG. Task offloading algorithm for UAV-assisted mobile edge computing [J]. Journal of Computer Applications, 2023, 43(6): 1893-1899. |
| [14] | Xiaohui HUANG, Kaiming YANG, Jiahao LING. Order dispatching by multi-agent reinforcement learning based on shared attention [J]. Journal of Computer Applications, 2023, 43(5): 1620-1624. |
| [15] | Tengfei CAO, Yanliang LIU, Xiaoying WANG. Edge computing and service offloading algorithm based on improved deep reinforcement learning [J]. Journal of Computer Applications, 2023, 43(5): 1543-1550. |
| Viewed | ||||||
|
Full text |
|
|||||
|
Abstract |
|
|||||