


《计算机应用》唯一官方网站 ›› 2022, Vol. 42 ›› Issue (5): 1563-1569.DOI: 10.11772/j.issn.1001-9081.2021030498
所属专题: 多媒体计算与计算机仿真
张晔1, 刘蓉1, 刘明2( ), 陈明1
), 陈明1
收稿日期:2021-04-02
修回日期:2021-06-28
接受日期:2021-07-01
发布日期:2022-06-11
出版日期:2022-05-10
通讯作者:
刘明
作者简介:张晔(1997—),女,河北石家庄人,硕士研究生,主要研究方向:模式识别、智能信息处理基金资助:
Ye ZHANG1, Rong LIU1, Ming LIU2(), Ming CHEN1
Received:2021-04-02
Revised:2021-06-28
Accepted:2021-07-01
Online:2022-06-11
Published:2022-05-10
Contact:
Ming LIU
About author:ZHANG Ye, born in 1997,M. S. candidate. Her research interestsinclude pattern recognition,intelligent information processing.Supported by:摘要:
针对现有的图像超分辨率重建方法存在生成图像纹理扭曲、细节模糊等问题,提出了一种基于多通道注意力机制的图像超分辨率重建网络。首先,该网络中的纹理提取模块通过设计多通道注意力机制并结合一维卷积实现跨通道的信息交互,以关注重要特征信息;然后,该网络中的纹理恢复模块引入密集残差块来尽可能恢复部分高频纹理细节,从而提升模型性能并产生优质重建图像。所提网络不仅能够有效提升图像的视觉效果,而且在基准数据集CUFED5上的结果表明所提网络与经典的基于卷积神经网络的超分辨率重建(SRCNN)方法相比,峰值信噪比(PSNR)和结构相似度(SSIM)分别提升了1.76 dB和0.062。实验结果表明,所提网络可提高纹理迁移的准确性,并有效提升生成图像的质量。
中图分类号:
张晔, 刘蓉, 刘明, 陈明. 基于多通道注意力机制的图像超分辨率重建网络[J]. 计算机应用, 2022, 42(5): 1563-1569.
Ye ZHANG, Rong LIU, Ming LIU, Ming CHEN. Image super-resolution reconstruction network based on multi-channel attention mechanism[J]. Journal of Computer Applications, 2022, 42(5): 1563-1569.
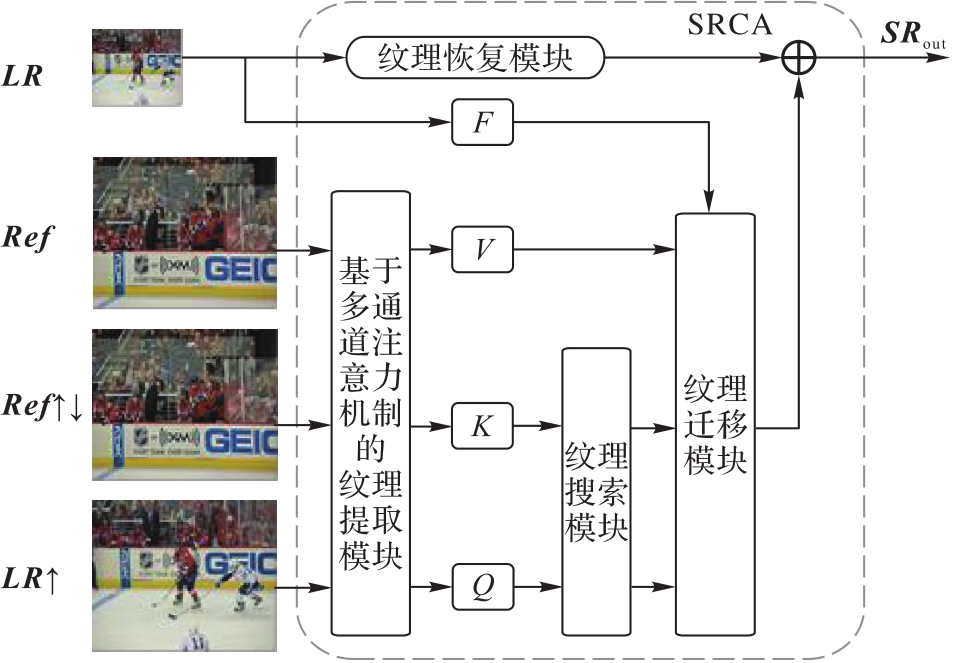
图1 SRCA模型的网络结构
Fig. 1 Network structure of SRCA model

图2 多通道注意力机制结构
Fig. 2 Multi-channel attention mechanism structure

图3 纹理恢复模块
Fig. 3 Texture recovery module

图4 RRDB模块
Fig. 4 RRDB module
| 方法 | 算法 | CUFED5 | Sun80 | Urban100 | Manga109 | ||||
|---|---|---|---|---|---|---|---|---|---|
| PSNR/dB | SSIM | PSNR/dB | SSIM | PSNR/dB | SSIM | PSNR/dB | SSIM | ||
| SISR | SRCNN | 25.33 | 0.745 | 28.26 | 0.781 | 24.41 | 0.738 | 27.12 | 0.850 |
| MDSR | 25.93 | 0.777 | 28.52 | 0.792 | 25.51 | 0.783 | 28.93 | 0.891 | |
| RDN | 25.95 | 0.769 | 29.63 | 0.806 | 25.38 | 0.768 | 29.24 | 0.894 | |
| RCAN | 26.06 | 0.769 | 29.86 | 0.810 | 25.42 | 0.768 | 29.38 | 0.895 | |
| SRGAN | 24.40 | 0.702 | 26.76 | 0.725 | 24.07 | 0.729 | 25.12 | 0.802 | |
| ENet | 24.24 | 0.695 | 26.24 | 0.702 | 23.63 | 0.711 | 25.25 | 0.802 | |
| ESRGAN | 21.90 | 0.633 | 24.18 | 0.651 | 20.91 | 0.620 | 23.53 | 0.797 | |
| RSRGAN | 22.31 | 0.635 | 25.60 | 0.667 | 21.47 | 0.624 | 25.04 | 0.803 | |
| RefSR | CrossNet | 25.48 | 0.764 | 28.52 | 0.793 | 25.11 | 0.764 | 23.36 | 0.741 |
| SRNTT_rec | 26.24 | 0.784 | 28.54 | 0.793 | 25.50 | 0.783 | 28.95 | 0.885 | |
| SRNTT | 25.61 | 0.764 | 27.59 | 0.756 | 25.09 | 0.774 | 27.54 | 0.862 | |
| TTSR_rec | 27.09** | 0.804** | 30.02* | 0.814* | 25.87** | 0.784** | 30.09** | 0.907** | |
| TTSR | 25.53 | 0.765 | 28.59 | 0.774 | 24.62 | 0.747 | 28.70 | 0.886 | |
| SRCA_rec | 27.09* | 0.807* | 29.93** | 0.813** | 25.93* | 0.786* | 30.25* | 0.909* | |
| SRCA | 25.87 | 0.771 | 28.75 | 0.777 | 25.04 | 0.757 | 29.33 | 0.891 | |
表1 在四个不同数据集上不同算法的PSNR/SSIM比较
Tab. 1 PSNR/SSIM comparison of different algorithms on four different datasets
| 方法 | 算法 | CUFED5 | Sun80 | Urban100 | Manga109 | ||||
|---|---|---|---|---|---|---|---|---|---|
| PSNR/dB | SSIM | PSNR/dB | SSIM | PSNR/dB | SSIM | PSNR/dB | SSIM | ||
| SISR | SRCNN | 25.33 | 0.745 | 28.26 | 0.781 | 24.41 | 0.738 | 27.12 | 0.850 |
| MDSR | 25.93 | 0.777 | 28.52 | 0.792 | 25.51 | 0.783 | 28.93 | 0.891 | |
| RDN | 25.95 | 0.769 | 29.63 | 0.806 | 25.38 | 0.768 | 29.24 | 0.894 | |
| RCAN | 26.06 | 0.769 | 29.86 | 0.810 | 25.42 | 0.768 | 29.38 | 0.895 | |
| SRGAN | 24.40 | 0.702 | 26.76 | 0.725 | 24.07 | 0.729 | 25.12 | 0.802 | |
| ENet | 24.24 | 0.695 | 26.24 | 0.702 | 23.63 | 0.711 | 25.25 | 0.802 | |
| ESRGAN | 21.90 | 0.633 | 24.18 | 0.651 | 20.91 | 0.620 | 23.53 | 0.797 | |
| RSRGAN | 22.31 | 0.635 | 25.60 | 0.667 | 21.47 | 0.624 | 25.04 | 0.803 | |
| RefSR | CrossNet | 25.48 | 0.764 | 28.52 | 0.793 | 25.11 | 0.764 | 23.36 | 0.741 |
| SRNTT_rec | 26.24 | 0.784 | 28.54 | 0.793 | 25.50 | 0.783 | 28.95 | 0.885 | |
| SRNTT | 25.61 | 0.764 | 27.59 | 0.756 | 25.09 | 0.774 | 27.54 | 0.862 | |
| TTSR_rec | 27.09** | 0.804** | 30.02* | 0.814* | 25.87** | 0.784** | 30.09** | 0.907** | |
| TTSR | 25.53 | 0.765 | 28.59 | 0.774 | 24.62 | 0.747 | 28.70 | 0.886 | |
| SRCA_rec | 27.09* | 0.807* | 29.93** | 0.813** | 25.93* | 0.786* | 30.25* | 0.909* | |
| SRCA | 25.87 | 0.771 | 28.75 | 0.777 | 25.04 | 0.757 | 29.33 | 0.891 | |

图5 在CUFED5:00004图像上放大4倍后不同模型重建结果对比
Fig. 5 Reconstructed result comparison of different models on CUFED5:00004 image with magnification 4

图6 在CUFED5:00064图像上放大4倍后不同模型重建结果对比
Fig. 6 Reconstructed result comparison of different models on CUFED5:00064 image with magnification 4

图7 在Sun80图像上放大4倍后不同模型重建结果对比
Fig. 7 Reconstructed result comparison of different models on Sun80 image with magnification 4

图8 在Manga109图像上放大4倍后不同模型重建结果对比
Fig. 8 Reconstructed result comparison of different models on Manga109 images with magnification 4
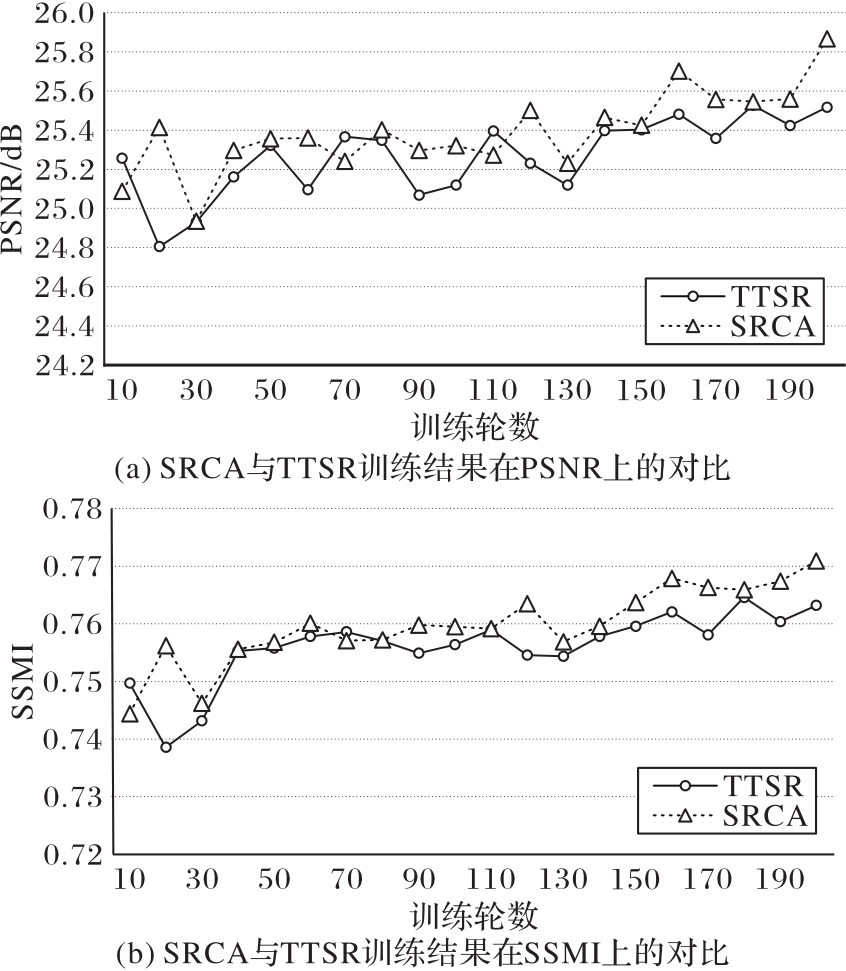
图9 SRCA与TTSR的训练结果对比
Fig. 9 Training result comparison of SRCA and TTSR
| 1 | FREEMAN W T, PASZTOR E C. Learning low-level vision [C]// Proceedings of the 1999 7th IEEE International Conference on Computer Vision. Piscataway: IEEE, 1999: 1182-1189. 10.1109/iccv.1999.790414 |
| 2 | 苏秉华,金伟其,牛丽红,等.超分辨率图像复原及其进展[J].光学技术,2001,27(1):6-9. 10.3321/j.issn:1002-1582.2001.01.018 |
| SU B H, JIN W Q, NIU L H, et al. Super-resolution image restoration and progress [J]. Optical Technique, 2001, 27(1): 6-9. 10.3321/j.issn:1002-1582.2001.01.018 | |
| 3 | FREEMAN W T, JONES T R, PASZTOR E C. Example-based super-resolution [J]. IEEE Computer Graphics and Applications, 2002, 22(2): 56-65. 10.1109/38.988747 |
| 4 | DONG C, LOY C C, HE K M, et al. Learning a deep convolutional network for image super-resolution [C]// Proceedings of the 2014 European Conference on Computer Vision, LNCS 8692. Cham: Springer, 2014: 184-199. |
| 5 | KIM J, LEE J K, LEE K M. Deeply-recursive convolutional network for image super-resolution [C]// Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2016: 1637-1645. 10.1109/cvpr.2016.181 |
| 6 | CAO C S, LIU X M, YANG Y, et al. Look and think twice: capturing top-down visual attention with feedback convolutional neural networks [C]// Proceedings of the 2015 IEEE International Conference on Computer Vision. Piscataway: IEEE, 2015: 2956-2964. 10.1109/iccv.2015.338 |
| 7 | WANG F, JIANG M Q, QIAN C, et al. Residual attention network for image classification [C]// Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2017: 6450-6458. 10.1109/cvpr.2017.683 |
| 8 | HU J, SHEN L, SUN G. Squeeze-and-excitation networks [C]// Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2018: 7132-7141. 10.1109/cvpr.2018.00745 |
| 9 | LU Y, ZHOU Y, JIANG Z Q, et al. Channel attention and multi-level features fusion for single image super-resolution [C]// Proceedings of the 2018 IEEE International Conference on Visual Communications and Image Processing. Piscataway: IEEE, 2018: 1-4. 10.1109/vcip.2018.8698663 |
| 10 | ZHANG Z F, WANG Z W, LIN Z, et al. Image super-resolution by neural texture transfer [C]// Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2019: 7974-7983. 10.1109/cvpr.2019.00817 |
| 11 | YANG F Z, YANG H, FU J L, et al. Learning texture transformer network for image super-resolution [C]// Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2020: 5790-5799. 10.1109/cvpr42600.2020.00583 |
| 12 | WANG Q L, WU B G, ZHU P F, et al. ECA-Net: efficient channel attention for deep convolutional neural networks [C]// Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2020: 11531-11539. 10.1109/cvpr42600.2020.01155 |
| 13 | 赵荣椿,赵忠明,赵歆波.数字图像处理与分析[M].北京:清华大学出版社,2013:36-40. |
| ZHAO R C, ZHAO Z M, ZHAO X B. Digital Image Processing and Analysis [M]. Beijing: Tsinghua University Press, 2013: 36-40. | |
| 14 | SIMONYAN K, ZISSERMAN A. Very deep convolutional networks for large-scale image recognition [EB/OL]. [2021-02-23].. 10.5244/c.28.6 |
| 15 | KINGMA D P, BA J L. Adam: a method for stochastic optimization [EB/OL]. [2021-02-23]. . |
| 16 | SUN L B, HAYS J. Super-resolution from internet-scale scene matching [C]// Proceedings of the 2012 IEEE International Conference on Computational Photography. Piscataway: IEEE, 2012: 1-12. 10.1109/iccphot.2012.6215221 |
| 17 | HUANG J B, SINGH A, AHUJA N. Single image super-resolution from transformed self-exemplars [C]// Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2015: 5197-5206. 10.1109/cvpr.2015.7299156 |
| 18 | MATSUI Y, ITO K, ARAMAKI Y, et al. Sketch-based manga retrieval using Manga109 dataset [J]. Multimedia Tools and Applications, 2017, 76(20): 21811-21838. 10.1007/s11042-016-4020-z |
| 19 | LIM B, SON S, KIM H, et al. Enhanced deep residual networks for single image super-resolution [C]// Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition Workshops. Piscataway: IEEE, 2017: 1132-1140. 10.1109/cvprw.2017.151 |
| 20 | ZHANG Y L, TIAN Y P, KONG Y, et al. Residual dense network for image super-resolution [C]// Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2018: 2472-2481. 10.1109/cvpr.2018.00262 |
| 21 | ZHANG Y L, LI K P, LI K, et al. Image super-resolution using very deep residual channel attention networks [C]// Proceedings of the 2018 European Conference on Computer Vision, LNCS 11211. Cham: Springer, 2018: 294-310. 10.1007/978-3-030-01234-2_18 |
| 22 | LEDIG C, THEIS L, HUSZÁR F, et al. Photo-realistic single image super-resolution using a generative adversarial network [C]// Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition, Piscataway: IEEE, 2017: 105-114. 10.1109/cvpr.2017.19 |
| 23 | PASZKE A, CHAURASIA A, KIM S, et al. ENet: a deep neural network architecture for real-time semantic segmentation [EB/OL]. [2021-02-23]. . 10.1109/icsip49896.2020.9339426 |
| 24 | WANG X T, YU K, WU S X, et al. ESRGAN: enhanced super-resolution generative adversarial networks [C]// Proceedings of the 2018 European Conference on Computer Vision, LNCS 11133. Cham: Springer, 2018: 63-79. |
| 25 | ZHANG W L, LIU Y H, DONG C, et al. RankSRGAN: generative adversarial networks with ranker for image super-resolution [C]// Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision. Piscataway: IEEE, 2019: 3096-3105. 10.1109/iccv.2019.00319 |
| 26 | ZHENG H T, JI M Q, WANG H Q, et al. CrossNet: an end-to-end reference-based super resolution network using cross-scale warping [C]// Proceedings of the2018 European Conference on Computer Vision, LNCS 11210. Cham: Springer, 2018: 87-104. |
| [1] | 赵志强, 马培红, 黑新宏. 基于双重注意力机制的人群计数方法[J]. 《计算机应用》唯一官方网站, 2024, 44(9): 2886-2892. |
| [2] | 秦璟, 秦志光, 李发礼, 彭悦恒. 基于概率稀疏自注意力神经网络的重性抑郁疾患诊断[J]. 《计算机应用》唯一官方网站, 2024, 44(9): 2970-2974. |
| [3] | 李力铤, 华蓓, 贺若舟, 徐况. 基于解耦注意力机制的多变量时序预测模型[J]. 《计算机应用》唯一官方网站, 2024, 44(9): 2732-2738. |
| [4] | 薛凯鹏, 徐涛, 廖春节. 融合自监督和多层交叉注意力的多模态情感分析网络[J]. 《计算机应用》唯一官方网站, 2024, 44(8): 2387-2392. |
| [5] | 汪雨晴, 朱广丽, 段文杰, 李书羽, 周若彤. 基于交互注意力机制的心理咨询文本情感分类模型[J]. 《计算机应用》唯一官方网站, 2024, 44(8): 2393-2399. |
| [6] | 高鹏淇, 黄鹤鸣, 樊永红. 融合坐标与多头注意力机制的交互语音情感识别[J]. 《计算机应用》唯一官方网站, 2024, 44(8): 2400-2406. |
| [7] | 李钟华, 白云起, 王雪津, 黄雷雷, 林初俊, 廖诗宇. 基于图像增强的低照度人脸检测[J]. 《计算机应用》唯一官方网站, 2024, 44(8): 2588-2594. |
| [8] | 莫尚斌, 王文君, 董凌, 高盛祥, 余正涛. 基于多路信息聚合协同解码的单通道语音增强[J]. 《计算机应用》唯一官方网站, 2024, 44(8): 2611-2617. |
| [9] | 刘丽, 侯海金, 王安红, 张涛. 基于多尺度注意力的生成式信息隐藏算法[J]. 《计算机应用》唯一官方网站, 2024, 44(7): 2102-2109. |
| [10] | 徐松, 张文博, 王一帆. 基于时空信息的轻量视频显著性目标检测网络[J]. 《计算机应用》唯一官方网站, 2024, 44(7): 2192-2199. |
| [11] | 李大海, 王忠华, 王振东. 结合空间域和频域信息的双分支低光照图像增强网络[J]. 《计算机应用》唯一官方网站, 2024, 44(7): 2175-2182. |
| [12] | 魏文亮, 王阳萍, 岳彪, 王安政, 张哲. 基于光照权重分配和注意力的红外与可见光图像融合深度学习模型[J]. 《计算机应用》唯一官方网站, 2024, 44(7): 2183-2191. |
| [13] | 熊武, 曹从军, 宋雪芳, 邵云龙, 王旭升. 基于多尺度混合域注意力机制的笔迹鉴别方法[J]. 《计算机应用》唯一官方网站, 2024, 44(7): 2225-2232. |
| [14] | 李欢欢, 黄添强, 丁雪梅, 罗海峰, 黄丽清. 基于多尺度时空图卷积网络的交通出行需求预测[J]. 《计算机应用》唯一官方网站, 2024, 44(7): 2065-2072. |
| [15] | 毛典辉, 李学博, 刘峻岭, 张登辉, 颜文婧. 基于并行异构图和序列注意力机制的中文实体关系抽取模型[J]. 《计算机应用》唯一官方网站, 2024, 44(7): 2018-2025. |
| 阅读次数 | ||||||
|
全文 |
|
|||||
|
摘要 |
|
|||||