


《计算机应用》唯一官方网站 ›› 2023, Vol. 43 ›› Issue (9): 2948-2954.DOI: 10.11772/j.issn.1001-9081.2022081242
陈蒙蒙, 乔志伟( )
)
收稿日期:2022-08-22
修回日期:2023-01-05
接受日期:2023-01-06
发布日期:2023-09-10
出版日期:2023-09-10
通讯作者:
乔志伟
作者简介:陈蒙蒙(1998—),女,山西介休人,硕士研究生,主要研究方向:医学图像重建、图像处理;
基金资助:Received:2022-08-22
Revised:2023-01-05
Accepted:2023-01-06
Online:2023-09-10
Published:2023-09-10
Contact:
Zhiwei QIAO
About author:CHEN Mengmeng, born in 1998, M. S. candidate. Her research interests include medical image reconstruction, image processing.
Supported by:摘要:
针对解析法稀疏重建中产生的条状伪影问题,提出一种融合通道注意力的U型Transformer(CA-Uformer),以实现高精度计算机断层成像(CT)的稀疏重建。CA-Uformer融合了通道注意力和Transformer中的空间注意力,双注意力机制使网络更容易学习到图像细节信息;采用优秀的U型架构融合多尺度图像信息;采用卷积操作实现前向反馈网络设计,从而进一步耦合卷积神经网络(CNN)的局部信息关联能力和Transformer的全局信息捕捉能力。实验结果表明,与经典U-Net相比,CA-Uformer的峰值信噪比(PSNR)、结构相似性(SSIM)提高了3.27 dB、3.14%,均方根误差(RMSE)降低了35.29%,提升效果明显。可见,CA-Uformer稀疏重建精度更高,压制伪影能力更强。
中图分类号:
陈蒙蒙, 乔志伟. 基于融合通道注意力的Uformer的CT图像稀疏重建[J]. 计算机应用, 2023, 43(9): 2948-2954.
Mengmeng CHEN, Zhiwei QIAO. Sparse reconstruction of CT images based on Uformer with fused channel attention[J]. Journal of Computer Applications, 2023, 43(9): 2948-2954.
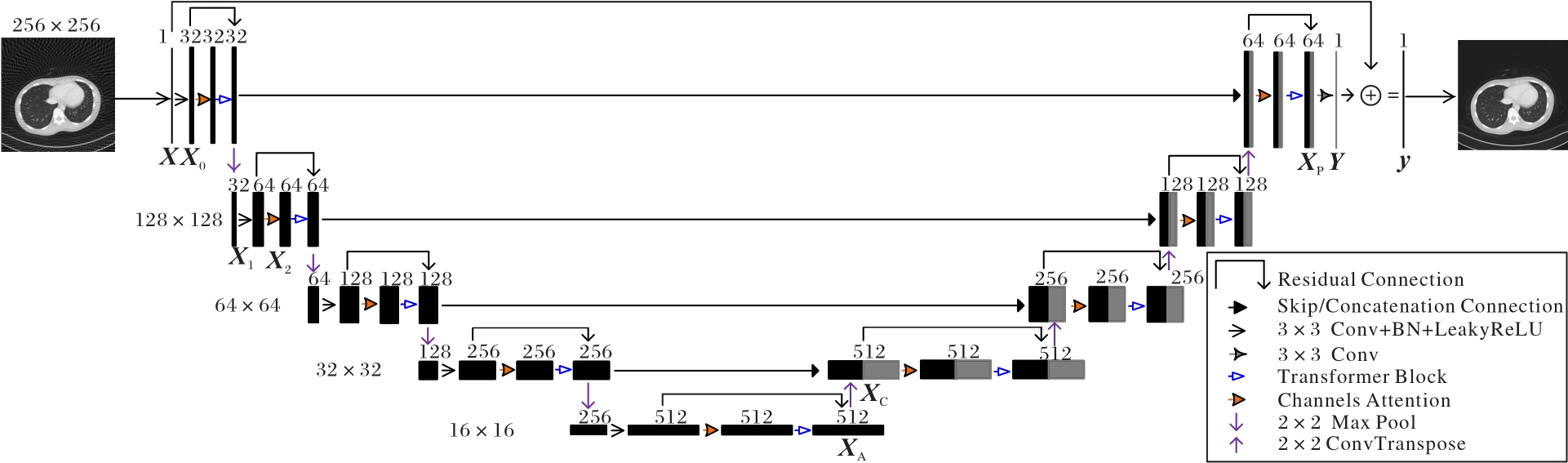
图1 CA-Uformer的网络结构
Fig. 1 Network structure of CA-Uformer

图2 通道注意力块结构
Fig. 2 Structure of channel attention block

图3 Transformer块总体结构
Fig. 3 Overall structure of Transformer block
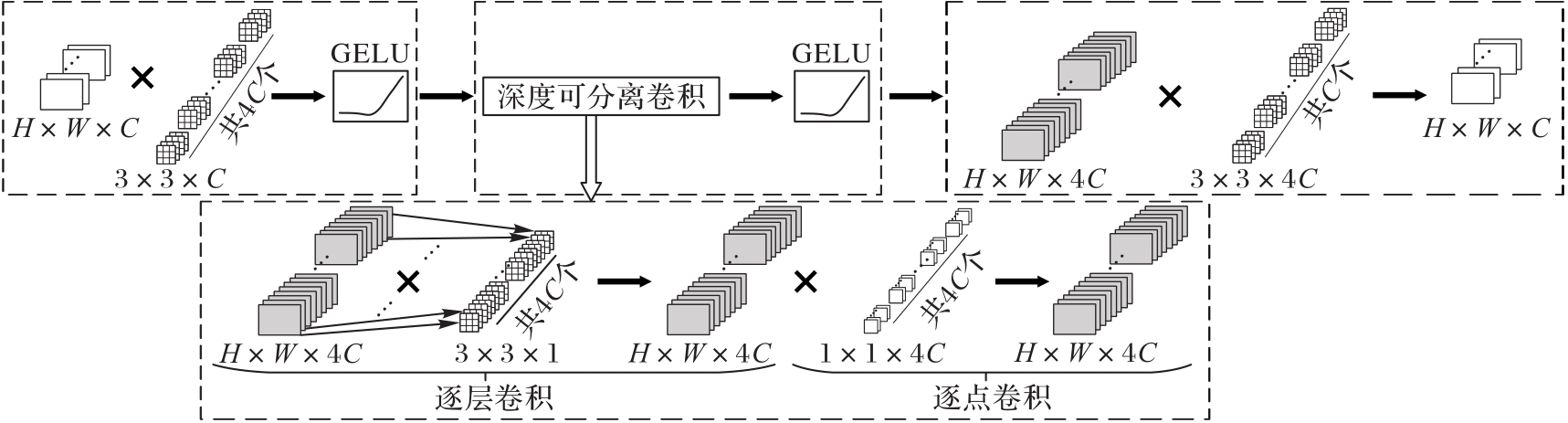
图4 卷积实现的LFE块的结构
Fig. 4 Structure of convolutional implemented LFE block

图5 不同算法的腹部重建结果
Fig. 5 Abdominal reconstruction results of different algorithms
| 算法 | PSNR/dB | SSIM | RMSE | 参数量/106 | 浮点运算量/GFLOPs | 重建时间/s |
|---|---|---|---|---|---|---|
| DnCNN | 32.18 | 0.939 | 0.026 | 0.14 | 18.45 | 0.18 |
| RED-CNN | 32.96 | 0.963 | 0.023 | 0.21 | 24.60 | 0.18 |
| U-Net | 36.03 | 0.955 | 0.017 | 7.77 | 27.42 | 0.18 |
| FBPConvNet | 37.69 | 0.962 | 0.014 | 9.16 | 29.60 | 0.19 |
| Uformer | 38.54 | 0.982 | 0.012 | 20.77 | 82.01 | 0.31 |
| CA-Uformer | 39.30 | 0.985 | 0.011 | 76.61 | 311.25 | 0.30 |
表1 不同算法在测试集上的实验结果
Tab. 1 Experimental results of different algorithms on test set
| 算法 | PSNR/dB | SSIM | RMSE | 参数量/106 | 浮点运算量/GFLOPs | 重建时间/s |
|---|---|---|---|---|---|---|
| DnCNN | 32.18 | 0.939 | 0.026 | 0.14 | 18.45 | 0.18 |
| RED-CNN | 32.96 | 0.963 | 0.023 | 0.21 | 24.60 | 0.18 |
| U-Net | 36.03 | 0.955 | 0.017 | 7.77 | 27.42 | 0.18 |
| FBPConvNet | 37.69 | 0.962 | 0.014 | 9.16 | 29.60 | 0.19 |
| Uformer | 38.54 | 0.982 | 0.012 | 20.77 | 82.01 | 0.31 |
| CA-Uformer | 39.30 | 0.985 | 0.011 | 76.61 | 311.25 | 0.30 |

图6 不同稀疏角度下头部的重建结果图
Fig. 6 Head reconstruction results under different sparse angles
| 稀疏角度数 | PSNR/dB | SSIM | RMSE |
|---|---|---|---|
| 15 | 33.11 | 0.956 | 0.022 |
| 30 | 36.40 | 0.974 | 0.015 |
| 60 | 39.30 | 0.985 | 0.011 |
| 90 | 40.36 | 0.988 | 0.010 |
表2 不同稀疏角度数时测试集的实验结果
Tab. 2 Experimental results on test set with different sparse angles
| 稀疏角度数 | PSNR/dB | SSIM | RMSE |
|---|---|---|---|
| 15 | 33.11 | 0.956 | 0.022 |
| 30 | 36.40 | 0.974 | 0.015 |
| 60 | 39.30 | 0.985 | 0.011 |
| 90 | 40.36 | 0.988 | 0.010 |

图7 不同模块的腹部重建结果
Fig. 7 Abdominal reconstruction results with different modules
| 模型 | PSNR/dB | SSIM | RMSE | 参数量 /106 | 浮点运算量/FLOPs | 重建时间/s |
|---|---|---|---|---|---|---|
| No-CA | 36.44 | 0.975 | 0.015 | 76.56 | 311.22 | 0.30 |
| No-Res | 38.83 | 0.984 | 0.012 | 76.61 | 311.25 | 0.30 |
| CA-Uformer | 39.30 | 0.985 | 0.011 | 76.61 | 311.25 | 0.30 |
表3 不同模块在测试集上的结果
Tab. 3 Results on test set with different modules
| 模型 | PSNR/dB | SSIM | RMSE | 参数量 /106 | 浮点运算量/FLOPs | 重建时间/s |
|---|---|---|---|---|---|---|
| No-CA | 36.44 | 0.975 | 0.015 | 76.56 | 311.22 | 0.30 |
| No-Res | 38.83 | 0.984 | 0.012 | 76.61 | 311.25 | 0.30 |
| CA-Uformer | 39.30 | 0.985 | 0.011 | 76.61 | 311.25 | 0.30 |

图8 通道注意力块的不同摆放位置示意图
Fig. 8 Schematic diagram of different positions of channel attention blocks

图9 模块位置不同的肺部重建结果
Fig. 9 Lung reconstruction results with different module locations
| 模块位置设计 | PSNR/dB | SSIM | RMSE |
|---|---|---|---|
| CA-Identity | 38.04 | 0.984 | 0.013 |
| Transformer-CA | 38.57 | 0.983 | 0.012 |
| CA-Uformer | 39.30 | 0.985 | 0.011 |
表4 模块位置不同在测试集上的结果
Tab. 4 Results of different module positions on test set
| 模块位置设计 | PSNR/dB | SSIM | RMSE |
|---|---|---|---|
| CA-Identity | 38.04 | 0.984 | 0.013 |
| Transformer-CA | 38.57 | 0.983 | 0.012 |
| CA-Uformer | 39.30 | 0.985 | 0.011 |
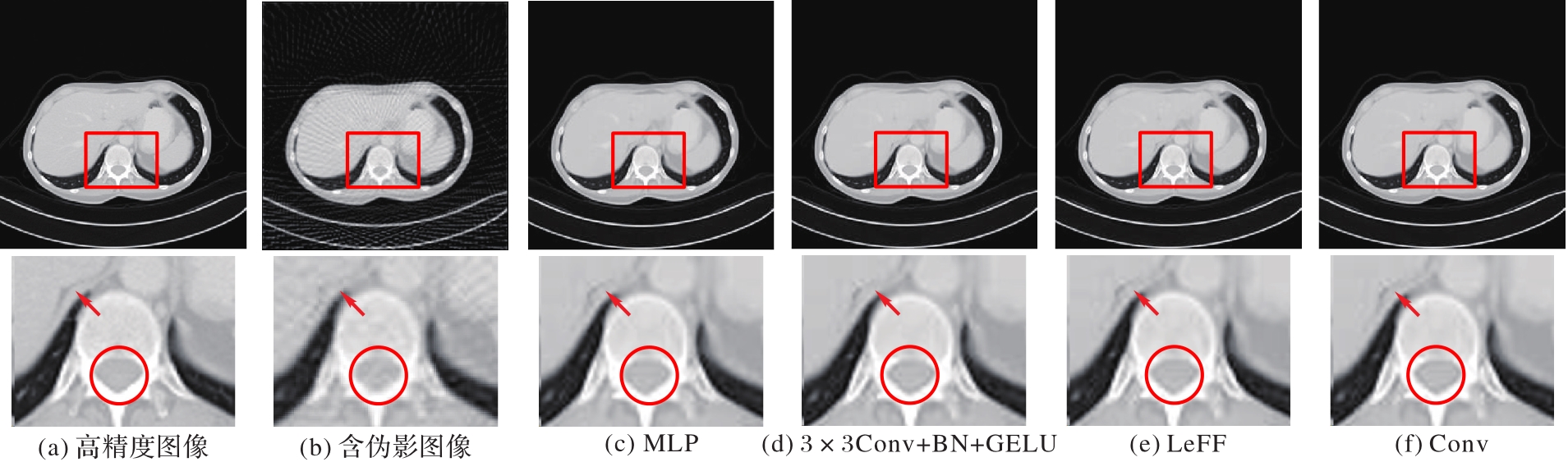
图10 不同LFE块的肺部重建结果及放大图
Fig. 10 Lung reconstruction results and magnification with different LFE blocks
| LFE块实现方式 | PSNR/dB | SSIM | RMSE | 参数量/106 | 浮点运算量/GFLOPs | 重建时间/s |
|---|---|---|---|---|---|---|
| MLP | 38.26 | 0.982 | 0.012 | 19.27 | 78.41 | 0.27 |
| 3×3Conv+BN+GELU | 38.53 | 0.974 | 0.012 | 20.66 | 84.24 | 0.27 |
| LeFF | 38.62 | 0.973 | 0.012 | 19.43 | 80.13 | 0.31 |
| Conv | 39.30 | 0.985 | 0.011 | 76.61 | 311.25 | 0.30 |
表5 不同LFE块在测试集上的结果
Tab. 5 Results of different LFE blocks on test set
| LFE块实现方式 | PSNR/dB | SSIM | RMSE | 参数量/106 | 浮点运算量/GFLOPs | 重建时间/s |
|---|---|---|---|---|---|---|
| MLP | 38.26 | 0.982 | 0.012 | 19.27 | 78.41 | 0.27 |
| 3×3Conv+BN+GELU | 38.53 | 0.974 | 0.012 | 20.66 | 84.24 | 0.27 |
| LeFF | 38.62 | 0.973 | 0.012 | 19.43 | 80.13 | 0.31 |
| Conv | 39.30 | 0.985 | 0.011 | 76.61 | 311.25 | 0.30 |
| 1 | SIDKY E Y, KAO C M, PAN X C. Accurate image reconstruction from few-views and limited-angle data in divergent-beam CT[J]. Journal of X-Ray Science and Technology, 2006, 14(2): 119-139. |
| 2 | 乔志伟. 总变差约束的数据分离最小图像重建模型及其 Chambolle-Pock求解算法[J]. 物理学报, 2018, 67(19):338-351. 10.7498/aps.67.20180839 |
| QIAO Z W. The total variation constrained data divergence minimization model for image reconstruction and its Chambolle-Pock solving algorithm[J]. Acta Physica Sinica,2018, 67(19):338-351. 10.7498/aps.67.20180839 | |
| 3 | BROOKS T, MILDENHALL B, XUE T F, et al. Unprocessing images for learned raw denoising[C]// Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2019: 11028-11037. 10.1109/cvpr.2019.01129 |
| 4 | LEE D, YOO J, YE J C. Deep residual learning for compressed sensing MRI[C]// Proceedings of the IEEE 14th International Symposium on Biomedical Imaging. Piscataway: IEEE, 2017: 15-18. 10.1109/isbi.2017.7950457 |
| 5 | WOO S, PARK J, LEE J Y, et al. CBAM: convolutional block attention module[C]// Proceedings of the 2018 European Conference on Computer Vision, LNCS 11211. Cham: Springer, 2018: 3-19. |
| 6 | HUANG G, LIU Z, L van der MAATEN, et al. Densely connected convolutional networks[C]// Proceedings of the 2017 IEEE conference on computer vision and pattern recognition. Piscataway: IEEE, 2017: 2261-2269. 10.1109/cvpr.2017.243 |
| 7 | GOODFELLOW I J, POUGET-ABADIE J, MIRZA M, et al. Generative adversarial networks[C]// Proceedings of the 27th International Conference on Neural Information Processing Systems - Volume 2. Cambridge: MIT Press, 2014: 2672-2680. |
| 8 | RONNEBERGER O, FISCHER P, BROX T. U-net: convolutional networks for biomedical image segmentation[C]// Proceedings of the 2015 International Conference on Medical Image Computing and Computer-Assisted Intervention, LNCS 9351. Cham: Springer, 2015: 234-241. |
| 9 | JIN K H, McCANN M T, FROUSTEY E, et al. Deep convolutional neural network for inverse problems in imaging[J]. IEEE Transactions on Image Processing, 2017, 26(9): 4509-4522. 10.1109/tip.2017.2713099 |
| 10 | PAN X C, SIDKY E Y, VANNIER M. Why do commercial CT scanners still employ traditional, filtered back-projection for image reconstruction?[J]. Inverse Problems, 2009, 25(12): No.123009. 10.1088/0266-5611/25/12/123009 |
| 11 | CHEN H, ZHANG Y, KALRA M K, et al. Low-dose CT with a residual encoder-decoder convolutional neural network[J]. IEEE Transactions on Medical Imaging, 2017, 36(12): 2524-2535. 10.1109/tmi.2017.2715284 |
| 12 | HE K M, ZHANG X Y, REN S Q, et al. Deep residual learning for image recognition[C]// Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2016: 770-778. 10.1109/cvpr.2016.90 |
| 13 | HU J, SHEN L, SUN G. Squeeze-and-excitation networks[C]// Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2018: 7132-7141. 10.1109/cvpr.2018.00745 |
| 14 | ZHANG Z C, LIANG X K, DONG X, et al. A sparse-view CT reconstruction method based on combination of DenseNet and deconvolution[J]. IEEE Transactions on Medical Imaging, 2018, 37(6): 1407-1417. 10.1109/tmi.2018.2823338 |
| 15 | XU L, REN J S J, LIU C, et al. Deep convolutional neural network for image deconvolution[C]// Proceedings of the 27th International Conference on Neural Information Processing Systems - Volume 1. Cambridge: MIT Press, 2014: 1790-1798. |
| 16 | WOLTERINK J M, LEINER T, VIERGEVER M A, et al. Generative adversarial networks for noise reduction in low-dose CT[J]. IEEE Transactions on Medical Imaging, 2017, 36(12): 2536-2545. 10.1109/tmi.2017.2708987 |
| 17 | VASWANI A, SHAZEER N, PARMAR N, et al. Attention is all you need[C]// Proceedings of the 31st International Conference on Neural Information Processing Systems. Red Hook, NY: Curran Associates Inc., 2017:6000-6010. |
| 18 | DOSOVITSKIY A, BEYER L, KOLESNIKOV A, et al. An image is worth 16x16 words: Transformers for image recognition at scale[EB/OL]. (2021-06-03) [2022-10-22].. |
| 19 | HUANG Z L, WANG X G, HUANG L C, et al. CCNet: criss-cross attention for semantic segmentation[C]// Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision. Piscataway: IEEE, 2019: 603-612. 10.1109/iccv.2019.00069 |
| 20 | LIU Z, LIN Y, CAO Y, et al. Swin Transformer: hierarchical vision transformer using shifted windows[C]// Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision. Piscataway: IEEE, 2021: 9992-10002. 10.1109/iccv48922.2021.00986 |
| 21 | WANG X L, GIRSHICK R, GUPTA A, et al. Non-local neural networks[C]// Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2018: 7794-7803. 10.1109/cvpr.2018.00813 |
| 22 | WANG Z D, CUN X D, BAO J M, et al. Uformer: a general U-shaped Transformer for image restoration[C]// Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2022: 17662-17672. 10.1109/cvpr52688.2022.01716 |
| 23 | PENG Z L, HUANG W, GU S Z, et al. Conformer: local features coupling global representations for visual recognition[C]// Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision. Piscataway: IEEE, 2021: 357-366. 10.1109/iccv48922.2021.00042 |
| 24 | YUAN K, GUO S P, LIU Z W, et al. Incorporating convolution designs into visual Transformers[C]// Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision. Piscataway: IEEE, 2021: 559-568. 10.1109/iccv48922.2021.00062 |
| 25 | ZHANG K, ZUO W M, CHEN Y J, et al. Beyond a Gaussian denoiser: Residual learning of deep CNN for image denoising[J]. IEEE Transactions on Image Processing, 2017, 26(7): 3142-3155. 10.1109/tip.2017.2662206 |
| [1] | 黄云川, 江永全, 黄骏涛, 杨燕. 基于元图同构网络的分子毒性预测[J]. 《计算机应用》唯一官方网站, 2024, 44(9): 2964-2969. |
| [2] | 杨鑫, 陈雪妮, 吴春江, 周世杰. 结合变种残差模型和Transformer的城市公路短时交通流预测[J]. 《计算机应用》唯一官方网站, 2024, 44(9): 2947-2951. |
| [3] | 任烈弘, 黄铝文, 田旭, 段飞. 基于DFT的频率敏感双分支Transformer多变量长时间序列预测方法[J]. 《计算机应用》唯一官方网站, 2024, 44(9): 2739-2746. |
| [4] | 贾洁茹, 杨建超, 张硕蕊, 闫涛, 陈斌. 基于自蒸馏视觉Transformer的无监督行人重识别[J]. 《计算机应用》唯一官方网站, 2024, 44(9): 2893-2902. |
| [5] | 方介泼, 陶重犇. 应对零日攻击的混合车联网入侵检测系统[J]. 《计算机应用》唯一官方网站, 2024, 44(9): 2763-2769. |
| [6] | 李金金, 桑国明, 张益嘉. APK-CNN和Transformer增强的多域虚假新闻检测模型[J]. 《计算机应用》唯一官方网站, 2024, 44(9): 2674-2682. |
| [7] | 陈彤, 杨丰玉, 熊宇, 严荭, 邱福星. 基于多尺度频率通道注意力融合的声纹库构建方法[J]. 《计算机应用》唯一官方网站, 2024, 44(8): 2407-2413. |
| [8] | 丁宇伟, 石洪波, 李杰, 梁敏. 基于局部和全局特征解耦的图像去噪网络[J]. 《计算机应用》唯一官方网站, 2024, 44(8): 2571-2579. |
| [9] | 邓凯丽, 魏伟波, 潘振宽. 改进掩码自编码器的工业缺陷检测方法[J]. 《计算机应用》唯一官方网站, 2024, 44(8): 2595-2603. |
| [10] | 杨帆, 邹窈, 朱明志, 马振伟, 程大伟, 蒋昌俊. 基于图注意力Transformer神经网络的信用卡欺诈检测模型[J]. 《计算机应用》唯一官方网站, 2024, 44(8): 2634-2642. |
| [11] | 李大海, 王忠华, 王振东. 结合空间域和频域信息的双分支低光照图像增强网络[J]. 《计算机应用》唯一官方网站, 2024, 44(7): 2175-2182. |
| [12] | 唐媛, 陈艳平, 扈应, 黄瑞章, 秦永彬. 基于多尺度混合注意力卷积神经网络的关系抽取模型[J]. 《计算机应用》唯一官方网站, 2024, 44(7): 2011-2017. |
| [13] | 黄梦源, 常侃, 凌铭阳, 韦新杰, 覃团发. 基于层间引导的低光照图像渐进增强算法[J]. 《计算机应用》唯一官方网站, 2024, 44(6): 1911-1919. |
| [14] | 黎施彬, 龚俊, 汤圣君. 基于Graph Transformer的半监督异配图表示学习模型[J]. 《计算机应用》唯一官方网站, 2024, 44(6): 1816-1823. |
| [15] | 吕锡婷, 赵敬华, 荣海迎, 赵嘉乐. 基于Transformer和关系图卷积网络的信息传播预测模型[J]. 《计算机应用》唯一官方网站, 2024, 44(6): 1760-1766. |
| 阅读次数 | ||||||
|
全文 |
|
|||||
|
摘要 |
|
|||||