


《计算机应用》唯一官方网站 ›› 2024, Vol. 44 ›› Issue (11): 3335-3344.DOI: 10.11772/j.issn.1001-9081.2023111645
胡新荣1, 陈静雪1, 黄子键1, 王帮超1( ), 姚迅1, 刘军平1, 朱强1, 杨捷2
), 姚迅1, 刘军平1, 朱强1, 杨捷2
收稿日期:2023-12-01
修回日期:2024-03-21
接受日期:2024-04-10
发布日期:2024-04-12
出版日期:2024-11-10
通讯作者:
王帮超
作者简介:胡新荣(1973—),女,湖北武汉人,教授,博士,CCF高级会员,主要研究方向:计算机视觉、机器学习、自然语言处理基金资助:
Xinrong HU1, Jingxue CHEN1, Zijian HUANG1, Bangchao WANG1(), Xun YAO1, Junping LIU1, Qiang ZHU1, Jie YANG2
Received:2023-12-01
Revised:2024-03-21
Accepted:2024-04-10
Online:2024-04-12
Published:2024-11-10
Contact:
Bangchao WANG
About author:HU Xinrong, born in 1973, Ph. D., professor. Her research interests include computer vision, machine learning, natural language processing.Supported by:摘要:
针对多项选择问答(MCQA)领域中原始数据信息不准确、样本质量低以及模型泛化能力差等问题,提出一种基于图卷积网络(GCN)的掩码数据增强模型GMDA(Graph convolution network-based MASK Data Augmentation)。该模型以GCN作为基础框架,首先将文章中的单词抽象为图节点,并利用问题-候选答案(QA)对节点进行连接,建立与相关的文章节点之间的联系;其次,计算节点之间的相似性,并应用掩码技术对图中的节点进行掩盖,从而生成增强样本;再次,利用GCN对增强样本进行特征扩充,以提升模型的信息表达能力;最后,引入打分器对原始样本和增强样本进行评分,并结合课程学习策略提高答案预测的准确性。综合评估实验结果表明:与RACE-M、RACE-H数据集上的最优基线模型EAM相比,所提模型GMDA的准确率分别平均提高了0.8、0.4个百分点,而与DREAM数据集上的最优基线模型STM(SelfTraining Method)相比,GMDA模型的准确率平均提高了1.4个百分点。此外,对比实验的结果也验证了GMDA模型在MCQA任务中的有效性,可为数据增强技术在该领域的进一步研究和应用提供帮助。
中图分类号:
胡新荣, 陈静雪, 黄子键, 王帮超, 姚迅, 刘军平, 朱强, 杨捷. 基于图卷积网络的掩码数据增强[J]. 计算机应用, 2024, 44(11): 3335-3344.
Xinrong HU, Jingxue CHEN, Zijian HUANG, Bangchao WANG, Xun YAO, Junping LIU, Qiang ZHU, Jie YANG. Graph convolution network-based masked data augmentation[J]. Journal of Computer Applications, 2024, 44(11): 3335-3344.
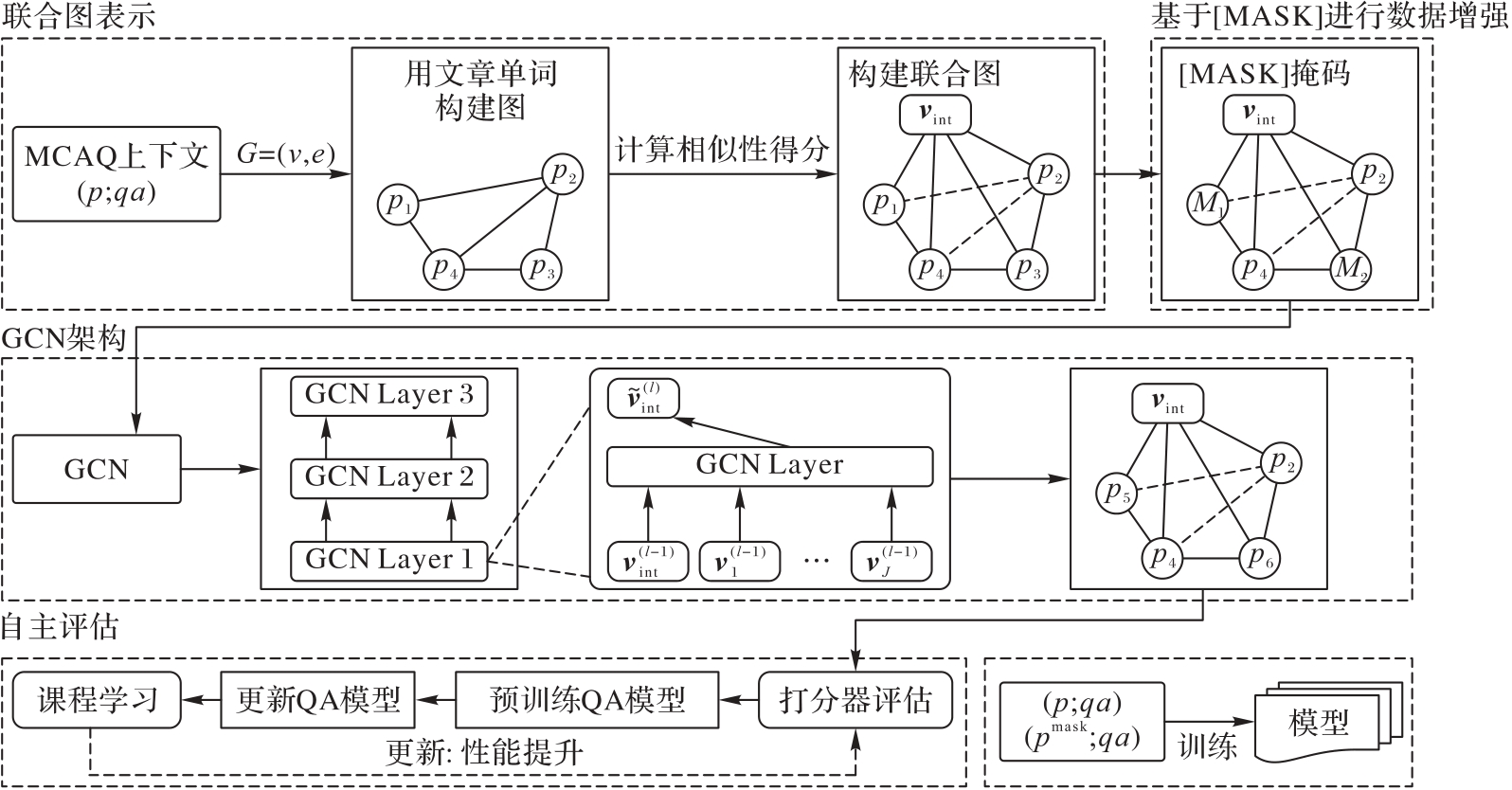
图1 GMDA模型框架
Fig. 1 Framework of GMDA model
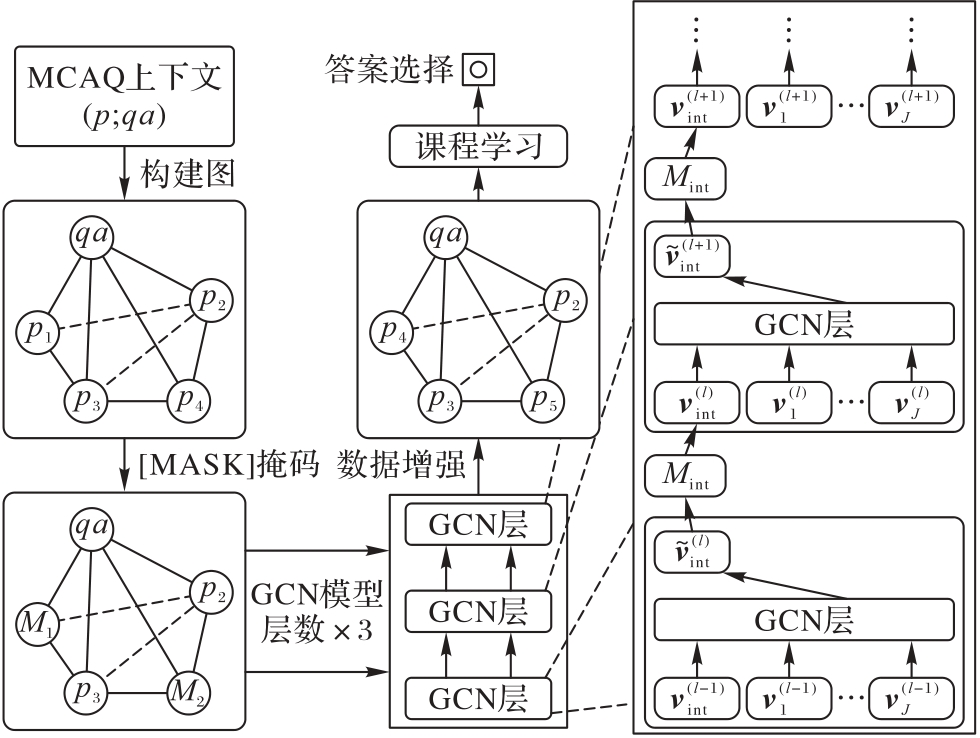
图2 GMDA增强样本生成示意图
Fig. 2 Schematic diagram of GMDA augmented sample generation
| 模型 | RACE-M | RACE-H | DREAM | |||
|---|---|---|---|---|---|---|
| BERT-Base | BERT-Large | BERT-Base | BERT-Large | BERT-Base | BERT-Large | |
| BERT | 71.1 | 76.6 | 62.3 | 70.1 | 63.2 | 66.8 |
| BERT+DCMN+ | 73.2 | 79.3 | 64.2 | 74.4 | 65.2 | 69.7 |
| BERT+DUMA | 73.3 | 64.1 | 64.8 | |||
| BERT+SG-Net | 78.8 | 72.2 | 68.1 | |||
| BERT+DS | 72.3 | 78.3 | 64.1 | 73.4 | 64.6 | 67.8 |
| BERT+QANet | 73.0 | 78.8 | 64.4 | 73.5 | 64.4 | 67.6 |
| BERT+STM | 69.2 | 78.7 | 62.6 | 73.6 | 65.8 | 69.1 |
| BERT+EAM | 73.5 | 79.2 | 65.0 | 74.4 | 64.9 | 68.1 |
| BERT+GenMC | 73.0 | 78.7 | 64.8 | 73.3 | 65.6 | 68.8 |
| BERT+GMDA | 73.7 | 80.5 | 65.4 | 74.7 | 67.4 | 70.3 |
| BERT+GMDA+DCMN+ | 75.3 | 81.6 | 67.5 | 76.7 | 69.0 | 71.9 |
| BERT+GMDA+DUMA | 74.9 | 67.1 | 68.8 | |||
| BERT+GMDA+SG-Net | 81.3 | 75.8 | 71.8 | |||
表1 GMDA模型和现有模型的准确率对比 ( %)
Tab. 1 Accuracy comparison between GMDA model and existing models
| 模型 | RACE-M | RACE-H | DREAM | |||
|---|---|---|---|---|---|---|
| BERT-Base | BERT-Large | BERT-Base | BERT-Large | BERT-Base | BERT-Large | |
| BERT | 71.1 | 76.6 | 62.3 | 70.1 | 63.2 | 66.8 |
| BERT+DCMN+ | 73.2 | 79.3 | 64.2 | 74.4 | 65.2 | 69.7 |
| BERT+DUMA | 73.3 | 64.1 | 64.8 | |||
| BERT+SG-Net | 78.8 | 72.2 | 68.1 | |||
| BERT+DS | 72.3 | 78.3 | 64.1 | 73.4 | 64.6 | 67.8 |
| BERT+QANet | 73.0 | 78.8 | 64.4 | 73.5 | 64.4 | 67.6 |
| BERT+STM | 69.2 | 78.7 | 62.6 | 73.6 | 65.8 | 69.1 |
| BERT+EAM | 73.5 | 79.2 | 65.0 | 74.4 | 64.9 | 68.1 |
| BERT+GenMC | 73.0 | 78.7 | 64.8 | 73.3 | 65.6 | 68.8 |
| BERT+GMDA | 73.7 | 80.5 | 65.4 | 74.7 | 67.4 | 70.3 |
| BERT+GMDA+DCMN+ | 75.3 | 81.6 | 67.5 | 76.7 | 69.0 | 71.9 |
| BERT+GMDA+DUMA | 74.9 | 67.1 | 68.8 | |||
| BERT+GMDA+SG-Net | 81.3 | 75.8 | 71.8 | |||
GCN 层数 | 准确率/% | GCN 层数 | 准确率/% | ||
|---|---|---|---|---|---|
| RACE-M | RACE-H | RACE-M | RACE-H | ||
| 2 | 73.0 | 64.5 | 5 | 70.6 | 59.4 |
| 3 | 73.7 | 65.3 | 6 | 68.4 | 54.5 |
| 4 | 71.9 | 62.5 | |||
表2 不同GCN层数对模型准确率的影响
Tab. 2 Influence of different numbers of GCN layers on model accuracy
GCN 层数 | 准确率/% | GCN 层数 | 准确率/% | ||
|---|---|---|---|---|---|
| RACE-M | RACE-H | RACE-M | RACE-H | ||
| 2 | 73.0 | 64.5 | 5 | 70.6 | 59.4 |
| 3 | 73.7 | 65.3 | 6 | 68.4 | 54.5 |
| 4 | 71.9 | 62.5 | |||
节点特征 空间维度 比例 | 准确率 | 节点特征 空间维度 比例 | 准确率 | ||
|---|---|---|---|---|---|
| RACE-M | RACE-H | RACE-M | RACE-H | ||
| 40 | 64.9 | 58.6 | 80 | 71.7 | 63.5 |
| 60 | 69.7 | 61.4 | 100 | 73.7 | 65.3 |
表3 减小节点特征空间维度对模型准确率的影响 ( %)
Tab. 3 Influence of reducing node feature space dimension on model accuracy
节点特征 空间维度 比例 | 准确率 | 节点特征 空间维度 比例 | 准确率 | ||
|---|---|---|---|---|---|
| RACE-M | RACE-H | RACE-M | RACE-H | ||
| 40 | 64.9 | 58.6 | 80 | 71.7 | 63.5 |
| 60 | 69.7 | 61.4 | 100 | 73.7 | 65.3 |
| 不同验证集比例 | 准确率/% | 不同验证集比例 | 准确率 | ||
|---|---|---|---|---|---|
| RACE-M | RACE-H | RACE-M | RACE-H | ||
| 30 | 72.4 | 64.3 | 70 | 73.3 | 65.2 |
| 50 | 72.7 | 64.6 | 100 | 73.7 | 65.3 |
表4 使用RACE测试集评估DVal规模的影响 ( %)
Tab. 4 Influence evaluation of DVal scale using RACE test sets
| 不同验证集比例 | 准确率/% | 不同验证集比例 | 准确率 | ||
|---|---|---|---|---|---|
| RACE-M | RACE-H | RACE-M | RACE-H | ||
| 30 | 72.4 | 64.3 | 70 | 73.3 | 65.2 |
| 50 | 72.7 | 64.6 | 100 | 73.7 | 65.3 |
| 可训练数据比例 | 准确率 | 可训练数据比例 | 准确率 | ||
|---|---|---|---|---|---|
| RACE-M | RACE-H | RACE-M | RACE-H | ||
| 33 | 66.4 | 57.5 | 67 | 69.4 | 61.7 |
| 50 | 67.8 | 59.8 | 75 | 71.6 | 62.8 |
表5 不同可训练数据比例下模型在RACE测试集上的实验结果 ( %)
Tab. 5 Experimental results of model on RACE test sets with different proportions of trainable data
| 可训练数据比例 | 准确率 | 可训练数据比例 | 准确率 | ||
|---|---|---|---|---|---|
| RACE-M | RACE-H | RACE-M | RACE-H | ||
| 33 | 66.4 | 57.5 | 67 | 69.4 | 61.7 |
| 50 | 67.8 | 59.8 | 75 | 71.6 | 62.8 |
增强样本 数量 | 准确率/% | 增强样本 数量 | 准确率/% | ||
|---|---|---|---|---|---|
| RACE-M | RACE-H | RACE-M | RACE-H | ||
| 2 | 72.4 | 64.9 | 5 | 73.7 | 65.3 |
| 3 | 72.8 | 65.2 | 7 | 73.5 | 65.5 |
表6 使用RACE测试集评估增强样本数量对模型准确率的影响
Tab. 6 Influence of number of augmented samples on model accuracy using RACE test set
增强样本 数量 | 准确率/% | 增强样本 数量 | 准确率/% | ||
|---|---|---|---|---|---|
| RACE-M | RACE-H | RACE-M | RACE-H | ||
| 2 | 72.4 | 64.9 | 5 | 73.7 | 65.3 |
| 3 | 72.8 | 65.2 | 7 | 73.5 | 65.5 |
滑动窗口 初始大小 | 准确率/% | 滑动窗口 初始大小 | 准确率/% | ||
|---|---|---|---|---|---|
| RACE-M | RACE-H | RACE-M | RACE-H | ||
| 0.1 | 73.5 | 65.2 | 0.3 | 73.2 | 65.1 |
| 0.2 | 73.7 | 65.4 | 0.4 | 73.0 | 64.8 |
表7 滑动窗口初始大小对模型准确率的影响
Tab. 7 Influence of initial size of sliding window on model accuracy
滑动窗口 初始大小 | 准确率/% | 滑动窗口 初始大小 | 准确率/% | ||
|---|---|---|---|---|---|
| RACE-M | RACE-H | RACE-M | RACE-H | ||
| 0.1 | 73.5 | 65.2 | 0.3 | 73.2 | 65.1 |
| 0.2 | 73.7 | 65.4 | 0.4 | 73.0 | 64.8 |
| 消融条件 | 设置 |
|---|---|
对图卷积神经 网络消融 | 使用KMSQA、DRAGON提出的两种GCN模型替换本文中的GCN消融 |
| 模型解构 | 考虑4种变体:+t、+r、+m和+s对模型进行解构 |
对课程学习和 打分器进行消融 | 不使用自主评估,仅使用增强方法进行对比 |
| 对课程学习消融 | 不使用课程学习,观察实验结果 |
表8 消融实验设置
Tab. 8 Experimental settings for ablation
| 消融条件 | 设置 |
|---|---|
对图卷积神经 网络消融 | 使用KMSQA、DRAGON提出的两种GCN模型替换本文中的GCN消融 |
| 模型解构 | 考虑4种变体:+t、+r、+m和+s对模型进行解构 |
对课程学习和 打分器进行消融 | 不使用自主评估,仅使用增强方法进行对比 |
| 对课程学习消融 | 不使用课程学习,观察实验结果 |
图卷积 神经网络 | 准确率/% | 图卷积 神经网络 | 准确率 | ||
|---|---|---|---|---|---|
| RACE-M | RACE-H | RACE-M | RACE-H | ||
| KMSQA | 72.7 | 64.1 | GCN(本文) | 73.7 | 65.4 |
| DRAGON | 73.1 | 64.6 | |||
表9 图卷积神经网络对模型准确率的影响 ( %)
Tab. 9 Influence of different GCNs on model accuracy
图卷积 神经网络 | 准确率/% | 图卷积 神经网络 | 准确率 | ||
|---|---|---|---|---|---|
| RACE-M | RACE-H | RACE-M | RACE-H | ||
| KMSQA | 72.7 | 64.1 | GCN(本文) | 73.7 | 65.4 |
| DRAGON | 73.1 | 64.6 | |||
| 数据集 | 准确率/% | 数据集 | 准确率/% |
|---|---|---|---|
| RACE-M (v) | 71.1 | RACE-H (v) | 62.3 |
| RACE-M (+t) | 71.4 | RACE-H (+t) | 62.7 |
| RACE-M (+r) | 71.9 | RACE-H (+r) | 63.3 |
| RACE-M (+m) | 72.9 | RACE-H (+m) | 64.7 |
| RACE-M (+s) | 73.7 | RACE-H (+s) | 65.4 |
表10 基于[MASK]的节点数据增强和自主评估对模型准确率的影响
Tab. 10 Influence evaluation of [MASK]-based node data augmentation and self-assessment on model accuracy
| 数据集 | 准确率/% | 数据集 | 准确率/% |
|---|---|---|---|
| RACE-M (v) | 71.1 | RACE-H (v) | 62.3 |
| RACE-M (+t) | 71.4 | RACE-H (+t) | 62.7 |
| RACE-M (+r) | 71.9 | RACE-H (+r) | 63.3 |
| RACE-M (+m) | 72.9 | RACE-H (+m) | 64.7 |
| RACE-M (+s) | 73.7 | RACE-H (+s) | 65.4 |
| 模型 | 准确率 | |
|---|---|---|
| RACE-M | RACE-H | |
| BERT+DS(-B) | 72.3 | 64.1 |
| BERT+QANet(-B) | 73.0 | 64.4 |
| BERT+GMDA(-B) w/o (+s) | 72.9 | 64.7 |
| BERT+DS(-B) w/ (+s) | 72.6 | 64.3 |
| BERT+QANet(-B) w/ (+s) | 73.2 | 64.8 |
| BERT+GMDA(-B) w/ (+s) | 73.7 | 65.4 |
表11 课程学习和打分器对模型准确率的影响 ( %)
Tab. 11 Influence of curriculum learning and scorer on model accuracy
| 模型 | 准确率 | |
|---|---|---|
| RACE-M | RACE-H | |
| BERT+DS(-B) | 72.3 | 64.1 |
| BERT+QANet(-B) | 73.0 | 64.4 |
| BERT+GMDA(-B) w/o (+s) | 72.9 | 64.7 |
| BERT+DS(-B) w/ (+s) | 72.6 | 64.3 |
| BERT+QANet(-B) w/ (+s) | 73.2 | 64.8 |
| BERT+GMDA(-B) w/ (+s) | 73.7 | 65.4 |
| 模型 | 准确率 | |
|---|---|---|
| RACE-M | RACE-H | |
| GMDA | 73.7 | 65.4 |
| GMDA w/o CL | 73.3 | 64.8 |
表12 课程学习对模型准确率的影响 ( %)
Tab. 12 Influence of curriculum learning on model accuracy
| 模型 | 准确率 | |
|---|---|---|
| RACE-M | RACE-H | |
| GMDA | 73.7 | 65.4 |
| GMDA w/o CL | 73.3 | 64.8 |
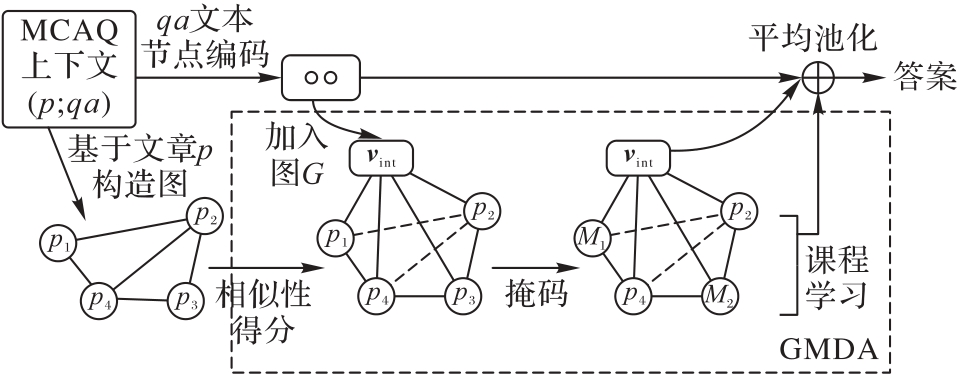
图3 模型可解释性示例
Fig. 3 Example of model interpretability
| 1 | ZHANG S, ZHAO H, WU Y, et al. DCMN+: dual co-matching network for multi-choice reading comprehension[C]// Proceedings of the 34th AAAI Conference on Artificial Intelligence. Palo Alto, CA: AAAI Press, 2020: 9563-9570. |
| 2 | MALMAUD J, LEVY R, BERZAK Y. Bridging information seeking human gaze and machine reading comprehension[C]// Proceedings of the 24th Conference on Computational Natural Language Learning. Stroudsburg, PA: ACL, 2020: 142-152. |
| 3 | DUAN Q, HUANG J, WU H. Contextual and semantic fusion network for multiple-choice reading comprehension[J]. IEEE Access, 2021, 9: 51669-51678. |
| 4 | KWON S, LEE Y. Explainability-based mix-up approach for text data augmentation[J]. ACM Transactions on Knowledge Discovery from Data, 2023, 17(1): No.13. |
| 5 | SUN L, XIA C, YIN W, et al. Mixup-transformer: dynamic data augmentation for NLP tasks[C]// Proceedings of the 28th International Conference on Computational Linguistics. [S.l.]: International Committee on Computational Linguistics, 2020: 3436-3440. |
| 6 | GUO D, KIM Y, RUSH A M. Sequence-level mixed sample data augmentation[C]// Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing. Stroudsburg, PA: ACL, 2020: 5547-5552. |
| 7 | WEI J, ZOU K. EDA: easy data augmentation techniques for boosting performance on text classification tasks[C]// Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing. Stroudsburg, PA: ACL, 2019: 6382-6388. |
| 8 | MINERVINI P, RIEDEL S. Adversarially regularising neural NLI models to integrate logical background knowledge[C]// Proceedings of the 22nd Conference on Computational Natural Language Learning. Stroudsburg, PA: ACL, 2018: 65-74. |
| 9 | McCOY T, PAVLICK E, LINZEN T. Right for the wrong reasons: diagnosing syntactic heuristics in natural language inference[C]// Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics. Stroudsburg, PA: ACL, 2019: 3428-3448. |
| 10 | ANDREAS J. Good-enough compositional data augmentation[C]// Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics. Stroudsburg, PA: ACL, 2020: 7556-7566. |
| 11 | YANG W, XIE Y, TAN L, et al. Data augmentation for BERT fine-tuning in open-domain question answering[EB/OL].[2023-07-14]. . |
| 12 | YU A W, DOHAN D, LUONG M T, et al. QANet: combining local convolution with global self-attention for reading comprehension[EB/OL]. [2023-10-09].. |
| 13 | PERGOLA G, KOCHKINA E, GUI L, et al. Boosting low-resource biomedical QA via entity-aware masking strategies[C]// Proceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics. Stroudsburg, PA: ACL, 2021:1977-1985. |
| 14 | BRUNA J, ZAREMBA W, SZLAM A, et al. Spectral networks and locally connected networks on graphs[EB/OL]. [2023-07-12]. . |
| 15 | ZHANG Z, BU J, ESTER M, et al. Hierarchical graph pooling with structure learning[EB/OL]. [2023-09-12].. |
| 16 | WANG X, JI H, SHI C, et al. Heterogeneous graph attention network[C]// Proceedings of the World Wide Web Conference 2019. New York: ACM, 2019: 2022-2032. |
| 17 | ZHOU Z, PEI W, LI X, et al. Saliency-associated object tracking[C]// Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision. Piscataway: IEEE, 2021: 9846-9855. |
| 18 | CHATURVEDI A, PANDIT O, GARAIN U. CNN for text-based multiple choice question answering[C]// Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers). Stroudsburg, PA: ACL, 2018: 272-277. |
| 19 | WANG S, YU M, CHANG S, et al. A co-matching model for multi-choice reading comprehension[C]// Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers). Stroudsburg, PA: ACL, 2018: 746-751. |
| 20 | ZHANG Z, WU Y, ZHOU J, et al. SG-Net: syntax-guided machine reading comprehension[C]// Proceedings of the 34th AAAI Conference on Artificial Intelligence. Palo Alto, CA: AAAI Pres, 2020: 9636-9643. |
| 21 | ZHU P, ZHANG Z, ZHAO H, et al. DUMA: reading comprehension with transposition thinking[J]. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 2022, 30: 269-279. |
| 22 | MARCHEGGIANI D, TITOV I.Encoding sentences with graph convolutional networks for semantic role labeling[C]// Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing. Stroudsburg, PA: ACL, 2017:1506-1515. |
| 23 | NIU Y, JIAO F, ZHOU M, et al. A self-training method for machine reading comprehension with soft evidence extraction[C]// Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics. Stroudsburg, PA: ACL, 2020: 3916-3927. |
| 24 | LUO D, ZHANG P, MA L, et al. Evidence augment for multiple-choice machine reading comprehension by weak supervision[C]// Proceedings of the 2021 International Conference on Artificial Neural Networks, LNCS 12895. Cham: Springer, 2021: 357-368. |
| 25 | HUANG Z, WU A, ZHOU J, et al. Clues before answers: generation-enhanced multiple-choice QA[C]// Proceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. Stroudsburg, PA: ACL, 2022: 3272-3287. |
| 26 | SILEO D, UMA K, MOENS M F. Generating multiple-choice questions for medical question answering with distractors and cue-masking[EB/OL]. [2023-11-12].. |
| 27 | WEINSHALL D, COHEN G, AMIR D. Curriculum learning by transfer learning: theory and experiments with deep networks[C]// Proceedings of the 35th International Conference on Machine Learning. New York: JMLR.org, 2018: 5238-5246. |
| 28 | WANG Y, GAN W, YANG J, et al. Dynamic curriculum learning for imbalanced data classification[C]// Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision. Piscataway: IEEE, 2019: 5016-5025. |
| 29 | LI Q, HUANG S, HONG Y, et al. A competence-aware curriculum for visual concepts learning via question answering[C]// Proceedings of the 2020 European Conference on Computer Vision, LNCS 12347. Cham: Springer, 2020: 141-157. |
| 30 | LIU X, LAI H, WONG D F, et al. Norm-based curriculum learning for neural machine translation[C]// Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics. Stroudsburg, PA: ACL, 2020: 427-436. |
| 31 | ZHANG M, MENG F, TONG Y, et al. Competence-based curriculum learning for multilingual machine translation[C]// Findings of the Association for Computational Linguistics: EMNLP 2021. Stroudsburg, PA: ACL, 2021: 2481-2493. |
| 32 | ZHANG S, BANSAL M. Addressing semantic drift in question generation for semi-supervised question answering[C]// Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing. Stroudsburg, PA: ACL, 2019: 2495-2509. |
| 33 | LIN T Y, GOYAL P, GIRSHICK R, et al. Focal loss for dense object detection[C]// Proceedings of the 8th IEEE International Conference on Computer Vision. Piscataway: IEEE, 2017: 2999-3007. |
| 34 | DEVLIN J, CHANG M W, LEE K, et al. BERT: pre-training of deep bidirectional Transformers for language understanding[C]// Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers). Stroudsburg, PA: ACL, 2019:4171-4186. |
| 35 | LAI G, XIE Q, LIU H, et al. RACE: large-scale reading comprehension dataset from examinations[C]// Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing. Stroudsburg, PA: ACL, 2017: 785-794. |
| 36 | SUN K, YU D, CHEN J, et al. Dream: a challenge data set and models for dialogue-based reading comprehension[J]. Transactions of the Association for Computational Linguistics, 2019, 7: 217-231. |
| 37 | ZHANG Q, CHEN S, FANG M, et al. Joint reasoning with knowledge subgraphs for multiple choice question answering[J]. Information Processing and Management, 2023, 60(3): No.103297. |
| 38 | YASUNAGA M, BOSSELUT A, REN H, et al. Deep bidirectional language-knowledge graph pretraining[C]// Proceedings of the 36th International Conference on Neural Information Processing Systems. Red Hook, NY: Curran Associates Inc., 2022: 37309-37323. |
| [1] | 薛桂香, 王辉, 周卫峰, 刘瑜, 李岩. 基于知识图谱和时空扩散图卷积网络的港口交通流量预测[J]. 《计算机应用》唯一官方网站, 2024, 44(9): 2952-2957. |
| [2] | 庞川林, 唐睿, 张睿智, 刘川, 刘佳, 岳士博. D2D通信系统中基于图卷积网络的分布式功率控制算法[J]. 《计算机应用》唯一官方网站, 2024, 44(9): 2855-2862. |
| [3] | 杨莹, 郝晓燕, 于丹, 马垚, 陈永乐. 面向图神经网络模型提取攻击的图数据生成方法[J]. 《计算机应用》唯一官方网站, 2024, 44(8): 2483-2492. |
| [4] | 刘禹含, 吉根林, 张红苹. 基于骨架图与混合注意力的视频行人异常检测方法[J]. 《计算机应用》唯一官方网站, 2024, 44(8): 2551-2557. |
| [5] | 张英俊, 李牛牛, 谢斌红, 张睿, 陆望东. 课程学习指导下的半监督目标检测框架[J]. 《计算机应用》唯一官方网站, 2024, 44(8): 2326-2333. |
| [6] | 李欢欢, 黄添强, 丁雪梅, 罗海峰, 黄丽清. 基于多尺度时空图卷积网络的交通出行需求预测[J]. 《计算机应用》唯一官方网站, 2024, 44(7): 2065-2072. |
| [7] | 吕锡婷, 赵敬华, 荣海迎, 赵嘉乐. 基于Transformer和关系图卷积网络的信息传播预测模型[J]. 《计算机应用》唯一官方网站, 2024, 44(6): 1760-1766. |
| [8] | 黎施彬, 龚俊, 汤圣君. 基于Graph Transformer的半监督异配图表示学习模型[J]. 《计算机应用》唯一官方网站, 2024, 44(6): 1816-1823. |
| [9] | 汪炅, 唐韬韬, 贾彩燕. 无负采样的正样本增强图对比学习推荐方法PAGCL[J]. 《计算机应用》唯一官方网站, 2024, 44(5): 1485-1492. |
| [10] | 郭洁, 林佳瑜, 梁祖红, 罗孝波, 孙海涛. 基于知识感知和跨层次对比学习的推荐方法[J]. 《计算机应用》唯一官方网站, 2024, 44(4): 1121-1127. |
| [11] | 高龙涛, 李娜娜. 基于方面感知注意力增强的方面情感三元组抽取[J]. 《计算机应用》唯一官方网站, 2024, 44(4): 1049-1057. |
| [12] | 杨先凤, 汤依磊, 李自强. 基于交替注意力机制和图卷积网络的方面级情感分析模型[J]. 《计算机应用》唯一官方网站, 2024, 44(4): 1058-1064. |
| [13] | 郭安迪, 贾真, 李天瑞. 基于伪实体数据增强的高精准率医学领域实体关系抽取[J]. 《计算机应用》唯一官方网站, 2024, 44(2): 393-402. |
| [14] | 王楷天, 叶青, 程春雷. 基于异构图表示的中医电子病历分类方法[J]. 《计算机应用》唯一官方网站, 2024, 44(2): 411-417. |
| [15] | 宋逸飞, 柳毅. 基于数据增强和标签噪声的快速对抗训练方法[J]. 《计算机应用》唯一官方网站, 2024, 44(12): 3798-3807. |
| 阅读次数 | ||||||
|
全文 |
|
|||||
|
摘要 |
|
|||||