


《计算机应用》唯一官方网站 ›› 2025, Vol. 45 ›› Issue (1): 1-14.DOI: 10.11772/j.issn.1001-9081.2023121881
• 人工智能 • 下一篇
张淑芬1,2,3, 张宏扬1,2,4, 任志强1,2,4, 陈学斌1,2,4( )
)
收稿日期:2024-01-12
修回日期:2024-03-18
接受日期:2024-03-22
发布日期:2024-04-02
出版日期:2025-01-10
通讯作者:
陈学斌
作者简介:张淑芬(1972—),女,河北唐山人,教授,博士,CCF高级会员,主要研究方向:云计算、智能信息处理、数据安全、隐私保护;基金资助:
Shufen ZHANG1,2,3, Hongyang ZHANG1,2,4, Zhiqiang REN1,2,4, Xuebin CHEN1,2,4()
Received:2024-01-12
Revised:2024-03-18
Accepted:2024-03-22
Online:2024-04-02
Published:2025-01-10
Contact:
Xuebin CHEN
About author:ZHANG Shufen, born in 1972, Ph. D., professor. Her research interests include cloud computing, intelligent information processing, data security, privacy protection.Supported by:摘要:
联邦学习(FL)凭借分布式结构和隐私安全的优势快速发展,但大规模FL引发的公平性问题影响了FL系统的可持续性。针对FL的公平性问题,对近年FL公平性的研究工作进行了系统梳理和深度分析。首先,对FL的工作流程和定义进行了解释,总结了FL中的偏见和公平性概念;其次,详细归纳了FL公平性研究中常用的数据集,探讨了公平性研究所面临的挑战;最后,从数据源选择、模型优化、贡献评估和激励机制这4个方面归纳梳理了相关研究工作的优缺点、适用场景以及实验设置等,并展望了FL公平性未来的研究方向和趋势。
中图分类号:
张淑芬, 张宏扬, 任志强, 陈学斌. 联邦学习的公平性综述[J]. 计算机应用, 2025, 45(1): 1-14.
Shufen ZHANG, Hongyang ZHANG, Zhiqiang REN, Xuebin CHEN. Survey of fairness in federated learning[J]. Journal of Computer Applications, 2025, 45(1): 1-14.
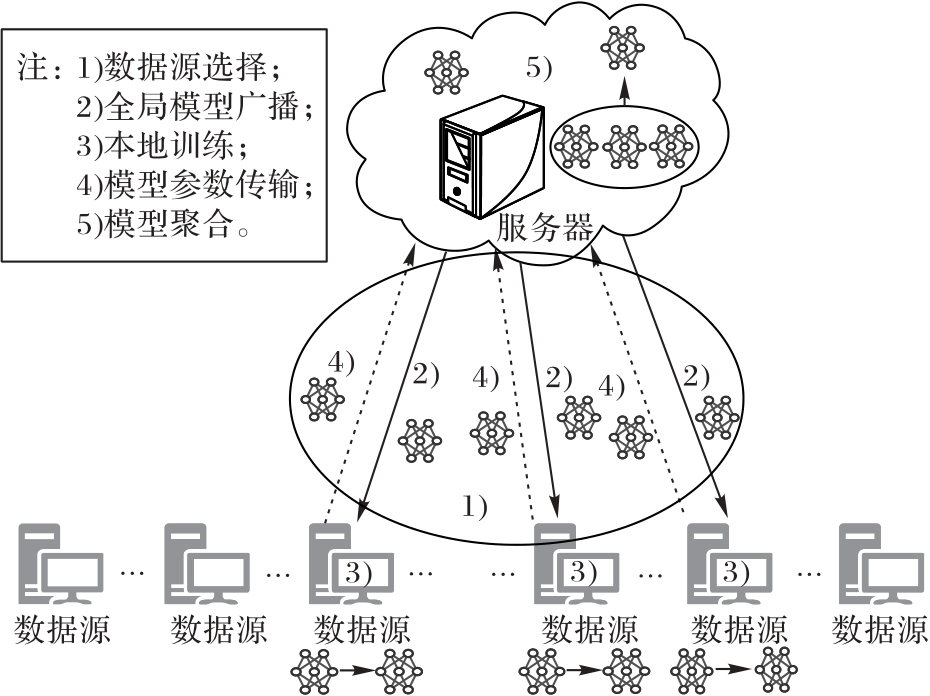
图1 联邦学习工作流程
Fig. 1 Federal learning workflow
| 方法 | 数据集 | 数据 源数 | 迭代 次数 | 评价指标及结果 | 说明 |
|---|---|---|---|---|---|
| TiFL[ | MNIST | 50 | 500 | 时间成本:相较于vanilla均明显减少; 准确率:除fast3因完全忽略最慢层导致准确率下降,其余均与vanilla类似 | TiFL与以下几种选择策略对比: vanilla:每一轮从数据源全体中随机选择5个; uniform:每一层被选择的概率均相等; random:每一层被选择的概率根据快慢递减; slow:每一轮选择最慢的层; fast:每一轮选择最快的层; fast1-fast3:最慢的层被选择概率依次为0.1、0.05、0,其余层被选择的概率相等 |
| FMNIST | 50 | 500 | |||
| CIFAR-10 | 50 | 500 | TiFL与vanilla准确率均达到最佳,但TiFL时间成本减少了50% | ||
| FEMNIST | 182 | 2 000 | 时间成本:相较于vanilla和uniform分别减少了85.7%和50%; 准确率:TiFL达到82.1%,相较于vanilla和uniform分别下降0.3和0.5个百分点 | ||
| ChFL[ | FEMNIST | — | 200 | 时间成本:减少66 s; 准确率:提升7.1个百分点 | 与FedAvg相比 |
| CIFAR-10 | — | 200 | 时间成本:减少279 s; 准确率:提升5个百分点 | ||
| MNIST | — | 200 | 时间成本:减少255 s; 准确率:提升5个百分点 | ||
| CINIC-10(CINIC-10 Is Not ImageNet or CIFAR-10)[ | — | 200 | 时间成本:减少607 s; 准确率:提升6.8个百分点 | ||
| EMNIST | — | 200 | 时间成本:减少172 s; 准确率:提升3.4个百分点 | ||
| RBCS-F[ | FMNIST | 40 | 200 | 训练时间:800 s; 准确率:约88% | 未提及准确率具体数值 |
| CIFAR-10 | 40 | 500 | 训练时间:2 000 s; 准确率:约65% | ||
| E3CS[ | CIFAR-10 | 100 | 2 500 | 准确率:提升0.42个百分点 | 与FedAvg相比 |
| EMNIST-Letter | 100 | 400 | 准确率:提升0.88个百分点 | ||
| CMAB-sample[ | CIFAR-10 | — | 3 000 | 准确率:提升2.08个百分点 | |
| FedGRA[ | MNIST | 50 | 200 | 2NN模型:达到80%准确率的迭代次数减少了69%,平均等待时间仅减少0.08 s; CNN模型:达到80%准确率的迭代次数减少了46%,平均等待时间减少了48.7% | 与FedAvg相比; 平均等待时间:每轮迭代结束时,最高算力数据源等待最低算力数据源的平均时间 |
| 文献[ | PAMAP2(Physical Activity Monitoring for Aging People 2)[ | 6 | — | 与基于DPSGD的FedAv相比g,准确率明显提升 | 未提及准确率具体数值 |
表1 各种数据源选择方法实验结果对比
Tab. 1 Experimental result comparison of various data source selection methods
| 方法 | 数据集 | 数据 源数 | 迭代 次数 | 评价指标及结果 | 说明 |
|---|---|---|---|---|---|
| TiFL[ | MNIST | 50 | 500 | 时间成本:相较于vanilla均明显减少; 准确率:除fast3因完全忽略最慢层导致准确率下降,其余均与vanilla类似 | TiFL与以下几种选择策略对比: vanilla:每一轮从数据源全体中随机选择5个; uniform:每一层被选择的概率均相等; random:每一层被选择的概率根据快慢递减; slow:每一轮选择最慢的层; fast:每一轮选择最快的层; fast1-fast3:最慢的层被选择概率依次为0.1、0.05、0,其余层被选择的概率相等 |
| FMNIST | 50 | 500 | |||
| CIFAR-10 | 50 | 500 | TiFL与vanilla准确率均达到最佳,但TiFL时间成本减少了50% | ||
| FEMNIST | 182 | 2 000 | 时间成本:相较于vanilla和uniform分别减少了85.7%和50%; 准确率:TiFL达到82.1%,相较于vanilla和uniform分别下降0.3和0.5个百分点 | ||
| ChFL[ | FEMNIST | — | 200 | 时间成本:减少66 s; 准确率:提升7.1个百分点 | 与FedAvg相比 |
| CIFAR-10 | — | 200 | 时间成本:减少279 s; 准确率:提升5个百分点 | ||
| MNIST | — | 200 | 时间成本:减少255 s; 准确率:提升5个百分点 | ||
| CINIC-10(CINIC-10 Is Not ImageNet or CIFAR-10)[ | — | 200 | 时间成本:减少607 s; 准确率:提升6.8个百分点 | ||
| EMNIST | — | 200 | 时间成本:减少172 s; 准确率:提升3.4个百分点 | ||
| RBCS-F[ | FMNIST | 40 | 200 | 训练时间:800 s; 准确率:约88% | 未提及准确率具体数值 |
| CIFAR-10 | 40 | 500 | 训练时间:2 000 s; 准确率:约65% | ||
| E3CS[ | CIFAR-10 | 100 | 2 500 | 准确率:提升0.42个百分点 | 与FedAvg相比 |
| EMNIST-Letter | 100 | 400 | 准确率:提升0.88个百分点 | ||
| CMAB-sample[ | CIFAR-10 | — | 3 000 | 准确率:提升2.08个百分点 | |
| FedGRA[ | MNIST | 50 | 200 | 2NN模型:达到80%准确率的迭代次数减少了69%,平均等待时间仅减少0.08 s; CNN模型:达到80%准确率的迭代次数减少了46%,平均等待时间减少了48.7% | 与FedAvg相比; 平均等待时间:每轮迭代结束时,最高算力数据源等待最低算力数据源的平均时间 |
| 文献[ | PAMAP2(Physical Activity Monitoring for Aging People 2)[ | 6 | — | 与基于DPSGD的FedAv相比g,准确率明显提升 | 未提及准确率具体数值 |
| 方法 | 研究动机 | 优势 | 局限性 | 适用场景 |
|---|---|---|---|---|
| TiFL[ | 解决异构性导致的训练时间延长和模型准确率下降问题 | 在资源与数据异构的场景下具备有效性 | 在处理大规模客户端情况下的可扩展性和容错性尚未得到验证 | 数据或算力异构 |
| ChFL[ | 解决随机选择策略无法反映全局特征的问题 | 算法具备可扩展性 | 在处理大规模客户端情况下的可扩展性和容错性尚未得到验证 | |
| RBCS-F[ | 解决服务器对数据源训练时间先验未知且容易忽略低性能数据源的问题 | 在客户端选择过程中具备公平保证 | 高公平性设置可能会导致训练时间延长和收敛速度下降 | 大规模协作或数据和算力异构 |
| E3CS[ | 解决不稳定环境下数据源选择的问题 | 能有效选择可靠的客户,并在选择过程中保持一定程度的公平性 | 需要进一步考虑本地更新操作和数据源选择决策的联合优化 | 数据源与服务器通信不稳定 |
| CMAB-sample[ | 解决全局和本地数据类别分布不平衡导致准确率下降的问题 | 组合后的数据源能达到类别平衡 | 数据长尾分布时性能下降严重 | 数据类别不平衡 |
| FedGRA[ | 解决异构性导致的数据源选择低效问题 | 算法收敛稳定且时间复杂度低 | 受限于特定环境和数据特征 | 数据和算力异构 |
| 文献[ | 解决联邦学习在人体活动识别领域安全和公平性的问题 | 满足隐私个性化,并平衡了隐私性与公平性 | 易受恶意客户端的攻击,并且在隐私和效用之间存在权衡 | 人体活动识别领域 |
表2 数据源选择方法的分析
Tab. 2 Analysis of data source selection methods
| 方法 | 研究动机 | 优势 | 局限性 | 适用场景 |
|---|---|---|---|---|
| TiFL[ | 解决异构性导致的训练时间延长和模型准确率下降问题 | 在资源与数据异构的场景下具备有效性 | 在处理大规模客户端情况下的可扩展性和容错性尚未得到验证 | 数据或算力异构 |
| ChFL[ | 解决随机选择策略无法反映全局特征的问题 | 算法具备可扩展性 | 在处理大规模客户端情况下的可扩展性和容错性尚未得到验证 | |
| RBCS-F[ | 解决服务器对数据源训练时间先验未知且容易忽略低性能数据源的问题 | 在客户端选择过程中具备公平保证 | 高公平性设置可能会导致训练时间延长和收敛速度下降 | 大规模协作或数据和算力异构 |
| E3CS[ | 解决不稳定环境下数据源选择的问题 | 能有效选择可靠的客户,并在选择过程中保持一定程度的公平性 | 需要进一步考虑本地更新操作和数据源选择决策的联合优化 | 数据源与服务器通信不稳定 |
| CMAB-sample[ | 解决全局和本地数据类别分布不平衡导致准确率下降的问题 | 组合后的数据源能达到类别平衡 | 数据长尾分布时性能下降严重 | 数据类别不平衡 |
| FedGRA[ | 解决异构性导致的数据源选择低效问题 | 算法收敛稳定且时间复杂度低 | 受限于特定环境和数据特征 | 数据和算力异构 |
| 文献[ | 解决联邦学习在人体活动识别领域安全和公平性的问题 | 满足隐私个性化,并平衡了隐私性与公平性 | 易受恶意客户端的攻击,并且在隐私和效用之间存在权衡 | 人体活动识别领域 |
| 方法 | 数据集 | 数据源数 | 迭代次数 | 评价指标及结果 | 说明 |
|---|---|---|---|---|---|
| ASO-Fed[ | FMNIST | 20 | — | 准确率:提升9.19个百分点 | 与FedAvg相比 |
| FedWPVA[ | MNIST | 8 | 20 | 损失值:降低14.45个百分点 | 与基于指数滑动平均的异步联邦学习相比 |
| CIFAR-10 | 8 | 60 | 损失值:降低7.26个百分点 | ||
| FNSGA-III[ | MNIST | 100 | 150 | 准确率:96.7% | 扩展至FedAvg的结果 |
| CIFAR-10 | 100 | 150 | 准确率:46.01% | ||
| AFL[ | Adult | — | — | 准确率:71.53% | 50次实验后的平均值 |
| FMNIST | — | — | 准确率:74.5% | ||
| q-FFL[ | Synthetic[ | 100 | 2 000 | 准确率:降低0.2个百分点; 方差:降低252 | 与FedAvg相比 |
| Vehicle | 23 | 100 | 准确率:提升0.4个百分点; 方差:降低243 | ||
| Sentiment140 | 1 101 | — | 准确率:提升1.4个百分点; 方差:降低188 | ||
| Shakespeare | 31 | — | 准确率:提升1个百分点; 方差:降低28 | ||
| Adult | — | — | 准确率:降低0.9个百分点 | ||
| FMNIST | 3 | 6 000 | 准确率:降低1.7个百分点 | ||
| AgnosticFair[ | Adult | — | — | 准确率:提升2.96个百分点; 风险差异:降低12.81个百分点 | |
| Dutch[ | — | — | 准确率:提升2.11个百分点; 风险差异:降低15.74个百分点 | ||
| α-FedAvg[ | MNIST | 100 | 100 | MLP模型:准确率提升0.99个百分点,方差降低26.17; CNN模型:准确率提升0.15个百分点,方差降低3.47 | |
| CIFAR-10 | 100 | 100 | MLP模型:准确率提升0.27个百分点,方差降低145.36; CNN模型:准确率提升1.39个百分点,方差降低70.08 | ||
| FCFL[ | eICU (emergency Intensive Care Unit)[ | — | — | 最差数据源的准确率:比q-FFL提升2.9个百分点,比AFL提升2.4个百分点 | 5次实验后的平均值 |
| Adult | — | — | 最差数据源的准确率:比q-FFL提升0.4个百分点,比AFL提升0.2个百分点 | ||
| FedMGDA+[ | CIFAR-10 | 100 | 2 000 | 准确率:比FedAvg提升1.04个百分点,比FedProx提升0.38个百分点,比q-FFL提升0.75个百分点 | 4次实验后的平均值 |
| Adult | 2 | 500 | 准确率:比q-FFL提升2.17个百分点,比AFL提升1.38个百分点 | 5次实验后的平均值 | |
| Ditto[ | Vehicle | 23 | 5 000 | 准确率:提升2.2个百分点 | 与FedMGDA+相比 |
| FEMNIST | 205 | 5 000 | 准确率:提升3.3个百分点 | ||
| CelebA (CelebFaces Attribute)[ | 515 | 5 000 | 准确率:提升0.5个百分点 | ||
| FMNIST | 500 | 5 000 | 准确率:提升3.1个百分点 | ||
| FedGini[ | Sythetic[ | 30 | 200 | 准确率:比q-FFL提升4.12个百分点,比FedAvg提升5.82个百分点 | 与q-FFL、FedAvg相比 |
| Sentiment140 | 1 101 | 400 | 准确率:比q-FFL提升6.04个百分点,比FedAvg提升3.39个百分点 | ||
| CIFAR-10 | 100 | 600 | 准确率:比q-FFL提升10.61个百分点,比FedAvg提升0.62个百分点 | ||
| FairFed[ | Adult | — | — | 准确率:降低0.6个百分点; 机会均等差:FairFed为-0.004,FedAvg为-0.180; 统计奇偶校验差:FairFed为-0.119,FedAvg为-0.177 | 与FedAvg相比; 机会均等差和统计奇偶校验差越接近0代表越公平 |
| ProPublica COMPAS | — | — | 准确率:降低1.4个百分点; 机会均等差:FairFed为-0.031,FedAvg为-0.078; 统计奇偶校验差:FairFed为-0.026,FedAvg为-0.149 | ||
| FedNova[ | Synthetic[ | — | 200 | 损失值:降低约0.25 | 与FedAvg相比 |
| CIFAR-10 | 16 | — | 准确率:提升5.63个百分点 | ||
| FedMinMax[ | FMNIST | 40 | — | Shirt的风险差异评分:比FedAvg降低15.4个百分点,比AFL提升0.2个百分点 | 每个数据源仅持有来自一个敏感组的数据 |
| 文献[ | Adult | 8 | — | 准确率:约80% F1分数:约0.7 | |
| ProPublica COMPAS | 5 | — | 准确率:约60%; F1分数:约0.6 | ||
| FEDFB[ | Synthetic[ | — | 10 | 机会均等差:降低35.5个百分点 | 与FedAvg相比 |
| Adult | — | 10 | 机会均等差:降低12.5个百分点 | ||
| ProPublica COMPAS | — | 10 | 机会均等差:降低8.1个百分点 | ||
| Bank | — | 10 | 机会均等差:降低2.6个百分点且为0 | ||
| 文献[ | Adult | — | — | 风险差异评分:0.15 | 越接近0风险越低 |
| DQFFL[ | Synthetic[ | 100 | — | 准确率:比FedAvg降低1.6个百分点,比q-FFL提升1个百分点 | 与FedAvg、q-FFL相比 |
| Vehicle | 23 | — | 准确率:比FedAvg提升1.6个百分点,比q-FFL提升0.2个百分点 | ||
| Sentiment140 | 1 101 | — | 准确率:比FedAvg提升0.8个百分点,比q-FFL提升1.8个百分点 | ||
| FMNIST | 60 | — | 准确率:比FedAvg降低0.1个百分点,比q-FFL提升0.4个百分点 | ||
| FedBoost[ | Synthetic[ | — | 600 | 损失值:降低约0.3 | 与FedAvg相比 |
| Shakespeare | — | 500 | 损失值:降低约0.03 |
表3 各种模型优化方法实验结果对比
Tab. 3 Experimental result comparison of various model optimization methods
| 方法 | 数据集 | 数据源数 | 迭代次数 | 评价指标及结果 | 说明 |
|---|---|---|---|---|---|
| ASO-Fed[ | FMNIST | 20 | — | 准确率:提升9.19个百分点 | 与FedAvg相比 |
| FedWPVA[ | MNIST | 8 | 20 | 损失值:降低14.45个百分点 | 与基于指数滑动平均的异步联邦学习相比 |
| CIFAR-10 | 8 | 60 | 损失值:降低7.26个百分点 | ||
| FNSGA-III[ | MNIST | 100 | 150 | 准确率:96.7% | 扩展至FedAvg的结果 |
| CIFAR-10 | 100 | 150 | 准确率:46.01% | ||
| AFL[ | Adult | — | — | 准确率:71.53% | 50次实验后的平均值 |
| FMNIST | — | — | 准确率:74.5% | ||
| q-FFL[ | Synthetic[ | 100 | 2 000 | 准确率:降低0.2个百分点; 方差:降低252 | 与FedAvg相比 |
| Vehicle | 23 | 100 | 准确率:提升0.4个百分点; 方差:降低243 | ||
| Sentiment140 | 1 101 | — | 准确率:提升1.4个百分点; 方差:降低188 | ||
| Shakespeare | 31 | — | 准确率:提升1个百分点; 方差:降低28 | ||
| Adult | — | — | 准确率:降低0.9个百分点 | ||
| FMNIST | 3 | 6 000 | 准确率:降低1.7个百分点 | ||
| AgnosticFair[ | Adult | — | — | 准确率:提升2.96个百分点; 风险差异:降低12.81个百分点 | |
| Dutch[ | — | — | 准确率:提升2.11个百分点; 风险差异:降低15.74个百分点 | ||
| α-FedAvg[ | MNIST | 100 | 100 | MLP模型:准确率提升0.99个百分点,方差降低26.17; CNN模型:准确率提升0.15个百分点,方差降低3.47 | |
| CIFAR-10 | 100 | 100 | MLP模型:准确率提升0.27个百分点,方差降低145.36; CNN模型:准确率提升1.39个百分点,方差降低70.08 | ||
| FCFL[ | eICU (emergency Intensive Care Unit)[ | — | — | 最差数据源的准确率:比q-FFL提升2.9个百分点,比AFL提升2.4个百分点 | 5次实验后的平均值 |
| Adult | — | — | 最差数据源的准确率:比q-FFL提升0.4个百分点,比AFL提升0.2个百分点 | ||
| FedMGDA+[ | CIFAR-10 | 100 | 2 000 | 准确率:比FedAvg提升1.04个百分点,比FedProx提升0.38个百分点,比q-FFL提升0.75个百分点 | 4次实验后的平均值 |
| Adult | 2 | 500 | 准确率:比q-FFL提升2.17个百分点,比AFL提升1.38个百分点 | 5次实验后的平均值 | |
| Ditto[ | Vehicle | 23 | 5 000 | 准确率:提升2.2个百分点 | 与FedMGDA+相比 |
| FEMNIST | 205 | 5 000 | 准确率:提升3.3个百分点 | ||
| CelebA (CelebFaces Attribute)[ | 515 | 5 000 | 准确率:提升0.5个百分点 | ||
| FMNIST | 500 | 5 000 | 准确率:提升3.1个百分点 | ||
| FedGini[ | Sythetic[ | 30 | 200 | 准确率:比q-FFL提升4.12个百分点,比FedAvg提升5.82个百分点 | 与q-FFL、FedAvg相比 |
| Sentiment140 | 1 101 | 400 | 准确率:比q-FFL提升6.04个百分点,比FedAvg提升3.39个百分点 | ||
| CIFAR-10 | 100 | 600 | 准确率:比q-FFL提升10.61个百分点,比FedAvg提升0.62个百分点 | ||
| FairFed[ | Adult | — | — | 准确率:降低0.6个百分点; 机会均等差:FairFed为-0.004,FedAvg为-0.180; 统计奇偶校验差:FairFed为-0.119,FedAvg为-0.177 | 与FedAvg相比; 机会均等差和统计奇偶校验差越接近0代表越公平 |
| ProPublica COMPAS | — | — | 准确率:降低1.4个百分点; 机会均等差:FairFed为-0.031,FedAvg为-0.078; 统计奇偶校验差:FairFed为-0.026,FedAvg为-0.149 | ||
| FedNova[ | Synthetic[ | — | 200 | 损失值:降低约0.25 | 与FedAvg相比 |
| CIFAR-10 | 16 | — | 准确率:提升5.63个百分点 | ||
| FedMinMax[ | FMNIST | 40 | — | Shirt的风险差异评分:比FedAvg降低15.4个百分点,比AFL提升0.2个百分点 | 每个数据源仅持有来自一个敏感组的数据 |
| 文献[ | Adult | 8 | — | 准确率:约80% F1分数:约0.7 | |
| ProPublica COMPAS | 5 | — | 准确率:约60%; F1分数:约0.6 | ||
| FEDFB[ | Synthetic[ | — | 10 | 机会均等差:降低35.5个百分点 | 与FedAvg相比 |
| Adult | — | 10 | 机会均等差:降低12.5个百分点 | ||
| ProPublica COMPAS | — | 10 | 机会均等差:降低8.1个百分点 | ||
| Bank | — | 10 | 机会均等差:降低2.6个百分点且为0 | ||
| 文献[ | Adult | — | — | 风险差异评分:0.15 | 越接近0风险越低 |
| DQFFL[ | Synthetic[ | 100 | — | 准确率:比FedAvg降低1.6个百分点,比q-FFL提升1个百分点 | 与FedAvg、q-FFL相比 |
| Vehicle | 23 | — | 准确率:比FedAvg提升1.6个百分点,比q-FFL提升0.2个百分点 | ||
| Sentiment140 | 1 101 | — | 准确率:比FedAvg提升0.8个百分点,比q-FFL提升1.8个百分点 | ||
| FMNIST | 60 | — | 准确率:比FedAvg降低0.1个百分点,比q-FFL提升0.4个百分点 | ||
| FedBoost[ | Synthetic[ | — | 600 | 损失值:降低约0.3 | 与FedAvg相比 |
| Shakespeare | — | 500 | 损失值:降低约0.03 |
| 方法 | 研究动机 | 优势 | 局限性 | 适用场景 |
|---|---|---|---|---|
| ASO-Fed[ | 解决边缘设备异构性和连续流式数据的问题 | 缓解了由于延迟导致的模型更新不一致 | 高延迟下模型易产生偏移 | 算力或通信能力异构 |
| FedWPVA[ | 解决异构性导致的模型偏差问题 | 缓解了由于延迟导致的模型更新不一致,并保证了模型有效性 | 低延迟的数据源利益可能无法保证 | |
| FNSGA-III[ | 解决通信受限和异构性问题 | 在公平性、有效性和通信成本三者间取得平衡 | 大规模场景下可能会产生较高的计算开销 | 通信能力受限 |
| AFL[ | 解决模型偏差问题 | 优化收敛性保证仅适用于凸函数和随机梯度下降,对于非凸函数和其他变体的收敛性保证有限 | 需要在多个领域中进行模型训练 | 数据或算力异构 |
| q-FFL[ | 解决联邦学习的公平资源分配问题 | 缓解了本地模型之间的性能差异 | q值缺乏理论推导,且可能会导致某些设备准确率降低 | 需要实现公平资源分配 |
| AgnosticFair[ | 解决未知测试数据的公平性问题 | 维持了公平性和有效性的平衡 | 模型性能可能因协作规模扩大而受限 | 小规模协作 |
| α-FedAvg[ | 解决异构性和数据量差异导致模型偏差的问题 | 根据理论推导得到α值 | 优化可能会导致某些设备准确率降低 | 算力或通信能力异构 |
| FCFL[ | 解决公平性和有效性的问题 | 算法具备较少的超参数,且保证了低损失模型的利益 | 缺乏对恶意攻击的鲁棒性 | |
| FedMGDA+[ | 解决公平性、有效性和鲁棒性的问题 | 在公平性、有效性和鲁棒性三者间取得平衡 | 对后门攻击可能无法完全防御,并且在异构环境下可能会产生不公平的模型 | 存在训练时间攻击和模型中毒攻击 |
| Ditto[ | 解决公平性、有效性和鲁棒性的问题 | Gini系数可以调整每一轮协作的公平程度 | 缺乏对隐私性与安全性的考虑 | 数据异构 |
| FedGini[ | 解决准确率方差无法定量评估公平性的问题 | 平衡了隐私性与公平性 | 缺乏关于可扩展性以及可行性的讨论 | |
| FairFed[ | 解决群体公平性问题 | 在分布偏移情况下能实现公平预测 | 只考虑了二分类问题,对于多分类问题的适用性有待进一步研究 | |
| FedNova[ | 解决异构性导致的优化算法中目标不一致的问题 | 缓解了本地模型之间的性能差异 | 收敛速度可能会因受到近端项的影响而变慢 | |
| FedMinMax[ | 解决群体公平性问题 | 能在分布式环境下实现群体公平性,同时具备集中式算法相同的性能 | 随着数据不平衡程度加深可能会影响模型有效性 | |
| 文献[ | 解决异构性导致的模型偏差问题,以及数据隐私保护问题 | 缓解了联邦学习过程中的模型偏见 | 存在不合作数据源的偏见缓解存在挑战 | |
| FedFB[ | 解决提高模型有效性的问题 | 平衡了有效性与公平性 | 有效性可能受到数据异构程度的影响 | |
| 文献[ | 解决城市社区发展补助金的公平分配问题 | 可以实现公平的拨款金额分配 | 在增加公平性的同时,可能会增加未满足需求的情况 | 社区需求和公平性之间需要权衡 |
| DQFFL[ | 解决异构性导致的模型差异问题 | 该算法对参数的敏感性较低,有利于强化学习的收敛 | 本地计算模型差异时可能导致隐私泄露 | 数据异构 |
| FedBoost[ | 解决数据源本地算力和存储空间有限的问题 | 通信效率高,可以提高对特定损失函数的收敛结果 | 密度估计问题或多源域适应问题 |
表4 模型优化方法的分析
Tab. 4 Analysis of model optimization methods
| 方法 | 研究动机 | 优势 | 局限性 | 适用场景 |
|---|---|---|---|---|
| ASO-Fed[ | 解决边缘设备异构性和连续流式数据的问题 | 缓解了由于延迟导致的模型更新不一致 | 高延迟下模型易产生偏移 | 算力或通信能力异构 |
| FedWPVA[ | 解决异构性导致的模型偏差问题 | 缓解了由于延迟导致的模型更新不一致,并保证了模型有效性 | 低延迟的数据源利益可能无法保证 | |
| FNSGA-III[ | 解决通信受限和异构性问题 | 在公平性、有效性和通信成本三者间取得平衡 | 大规模场景下可能会产生较高的计算开销 | 通信能力受限 |
| AFL[ | 解决模型偏差问题 | 优化收敛性保证仅适用于凸函数和随机梯度下降,对于非凸函数和其他变体的收敛性保证有限 | 需要在多个领域中进行模型训练 | 数据或算力异构 |
| q-FFL[ | 解决联邦学习的公平资源分配问题 | 缓解了本地模型之间的性能差异 | q值缺乏理论推导,且可能会导致某些设备准确率降低 | 需要实现公平资源分配 |
| AgnosticFair[ | 解决未知测试数据的公平性问题 | 维持了公平性和有效性的平衡 | 模型性能可能因协作规模扩大而受限 | 小规模协作 |
| α-FedAvg[ | 解决异构性和数据量差异导致模型偏差的问题 | 根据理论推导得到α值 | 优化可能会导致某些设备准确率降低 | 算力或通信能力异构 |
| FCFL[ | 解决公平性和有效性的问题 | 算法具备较少的超参数,且保证了低损失模型的利益 | 缺乏对恶意攻击的鲁棒性 | |
| FedMGDA+[ | 解决公平性、有效性和鲁棒性的问题 | 在公平性、有效性和鲁棒性三者间取得平衡 | 对后门攻击可能无法完全防御,并且在异构环境下可能会产生不公平的模型 | 存在训练时间攻击和模型中毒攻击 |
| Ditto[ | 解决公平性、有效性和鲁棒性的问题 | Gini系数可以调整每一轮协作的公平程度 | 缺乏对隐私性与安全性的考虑 | 数据异构 |
| FedGini[ | 解决准确率方差无法定量评估公平性的问题 | 平衡了隐私性与公平性 | 缺乏关于可扩展性以及可行性的讨论 | |
| FairFed[ | 解决群体公平性问题 | 在分布偏移情况下能实现公平预测 | 只考虑了二分类问题,对于多分类问题的适用性有待进一步研究 | |
| FedNova[ | 解决异构性导致的优化算法中目标不一致的问题 | 缓解了本地模型之间的性能差异 | 收敛速度可能会因受到近端项的影响而变慢 | |
| FedMinMax[ | 解决群体公平性问题 | 能在分布式环境下实现群体公平性,同时具备集中式算法相同的性能 | 随着数据不平衡程度加深可能会影响模型有效性 | |
| 文献[ | 解决异构性导致的模型偏差问题,以及数据隐私保护问题 | 缓解了联邦学习过程中的模型偏见 | 存在不合作数据源的偏见缓解存在挑战 | |
| FedFB[ | 解决提高模型有效性的问题 | 平衡了有效性与公平性 | 有效性可能受到数据异构程度的影响 | |
| 文献[ | 解决城市社区发展补助金的公平分配问题 | 可以实现公平的拨款金额分配 | 在增加公平性的同时,可能会增加未满足需求的情况 | 社区需求和公平性之间需要权衡 |
| DQFFL[ | 解决异构性导致的模型差异问题 | 该算法对参数的敏感性较低,有利于强化学习的收敛 | 本地计算模型差异时可能导致隐私泄露 | 数据异构 |
| FedBoost[ | 解决数据源本地算力和存储空间有限的问题 | 通信效率高,可以提高对特定损失函数的收敛结果 | 密度估计问题或多源域适应问题 |
| 方法 | 数据集 | 数据源数 | 迭代次数 | 评价指标及结果 | 说明 |
|---|---|---|---|---|---|
| TMC-Shapley, G-Shapley[ | Dog vs. Fish[ | — | — | Shapley值:随噪声增大而降低 | |
| HAM10000 (Human Against Machine with 10 000 training images)[ | — | — | 准确率:提升8.2个百分点 | 去除Shapley值为负的数据后,与保留Shapley值为负的数据的训练结果相比 | |
| UK Biobank[ | — | — | Shapley值:其中一个健康中心数据集(14-Nottingham)被分配了明显负值 | 对数据来源进行估值 | |
| CelebA[ | — | — | 准确率:比保留Shapley值为负的数据点的模型训练结果提升7.4个百分点 | 在Celeb A上训练模型,LFW+A上进行自适应任务训练,并在PPB上测试,去除Shapley值为负的数据后,与保留Shapley值为负的数据的训练结果相比 | |
| LFW-A (Labeled Faces in the Wild-A)[ | — | — | |||
| PPB (Pilot Parliaments Benchmark)[ | — | — | |||
| MNIST | — | — | — | 在MNIST上训练模型,USPS digits上测试 | |
| USPS digits (United States Postal Service digits)[ | — | — | — | ||
| SMS spam (Short Message Service spam)[ | — | — | — | 在SMS spam上训练模型,Email spam detection上测试 | |
| Email spam[ | — | — | — | ||
| GTG-Shapley[ | MNIST | 10 | — | Shapley估计值与真实值相差低于0.01,准确率和时间开销均优于TMC-Shapley | 与TMC-Shapley相比,未提及具体数值 |
| 联邦Shapley[ | MNIST | 100 | 60 | 准确率:92% | |
| CIFAR-10 | — | 200 | 准确率:70% | ||
| RFFL[ | MNIST | — | 60 | 准确率:比FedAvg提升20个百分点,比q-FFL提升29个百分点 | 与FedAvg、q-FFL相比 |
| CIFAR-10 | — | 200 | 准确率:比FedAvg提升4个百分点,比q-FFL提升13个百分点 | ||
| Movie review[ | — | — | 准确率:比FedAvg提升6个百分点,比q-FFL提升45个百分点 | ||
| Stanford sentiment treebank[ | — | — | 准确率:比FedAvg提升2个百分点,比q-FFL提升12个百分点 | ||
| PoT共识机制[ | MNIST | 10 | 700 | 准确率:提高约30个百分点 | 与FedAvg相比 |
| CIFAR-10 | 10 | 100 | 准确率:提高约15个百分点 | ||
| PPFLChain[ | MNIST | 10 | 150 | 准确率:提高约0.4个百分点 | 与独立训练相比 |
表5 各种贡献评估方法实验结果对比
Tab. 5 Experimental results comparison of various contribution evaluation methods
| 方法 | 数据集 | 数据源数 | 迭代次数 | 评价指标及结果 | 说明 |
|---|---|---|---|---|---|
| TMC-Shapley, G-Shapley[ | Dog vs. Fish[ | — | — | Shapley值:随噪声增大而降低 | |
| HAM10000 (Human Against Machine with 10 000 training images)[ | — | — | 准确率:提升8.2个百分点 | 去除Shapley值为负的数据后,与保留Shapley值为负的数据的训练结果相比 | |
| UK Biobank[ | — | — | Shapley值:其中一个健康中心数据集(14-Nottingham)被分配了明显负值 | 对数据来源进行估值 | |
| CelebA[ | — | — | 准确率:比保留Shapley值为负的数据点的模型训练结果提升7.4个百分点 | 在Celeb A上训练模型,LFW+A上进行自适应任务训练,并在PPB上测试,去除Shapley值为负的数据后,与保留Shapley值为负的数据的训练结果相比 | |
| LFW-A (Labeled Faces in the Wild-A)[ | — | — | |||
| PPB (Pilot Parliaments Benchmark)[ | — | — | |||
| MNIST | — | — | — | 在MNIST上训练模型,USPS digits上测试 | |
| USPS digits (United States Postal Service digits)[ | — | — | — | ||
| SMS spam (Short Message Service spam)[ | — | — | — | 在SMS spam上训练模型,Email spam detection上测试 | |
| Email spam[ | — | — | — | ||
| GTG-Shapley[ | MNIST | 10 | — | Shapley估计值与真实值相差低于0.01,准确率和时间开销均优于TMC-Shapley | 与TMC-Shapley相比,未提及具体数值 |
| 联邦Shapley[ | MNIST | 100 | 60 | 准确率:92% | |
| CIFAR-10 | — | 200 | 准确率:70% | ||
| RFFL[ | MNIST | — | 60 | 准确率:比FedAvg提升20个百分点,比q-FFL提升29个百分点 | 与FedAvg、q-FFL相比 |
| CIFAR-10 | — | 200 | 准确率:比FedAvg提升4个百分点,比q-FFL提升13个百分点 | ||
| Movie review[ | — | — | 准确率:比FedAvg提升6个百分点,比q-FFL提升45个百分点 | ||
| Stanford sentiment treebank[ | — | — | 准确率:比FedAvg提升2个百分点,比q-FFL提升12个百分点 | ||
| PoT共识机制[ | MNIST | 10 | 700 | 准确率:提高约30个百分点 | 与FedAvg相比 |
| CIFAR-10 | 10 | 100 | 准确率:提高约15个百分点 | ||
| PPFLChain[ | MNIST | 10 | 150 | 准确率:提高约0.4个百分点 | 与独立训练相比 |
| 方法 | 研究动机 | 优势 | 局限性 | 适用场景 |
|---|---|---|---|---|
| TMC-Shapley, G-Shapley[ | 解决数据估值的公平性问题 | 与真实Shapley值的皮尔逊相关系数接近1 | 计算开销容易受到训练规模的影响 | 小规模协作 |
| GTG-Shapley[ | 解决Shapley值计算效率问题 | 具备良好的收敛速度和准确率 | 有效性受到数据异构影响 | 数据或算力异构 |
| 联邦Shapley[ | 解决传统Shapley值通信成本高的问题,以及忽略数据源训练顺序的问题 | 能在参与者数量较大时进行高效计算 | 有效性受到数据异构影响 | 大规模协作 |
| RFFL[ | 解决公平性和鲁棒性的问题 | 可以识别和隔离未定向毒化对手和搭便车者 | 在有目标的毒化攻击中,对手可能不会完全被识别。在无目标的毒化攻击中,某些方法对于重新缩放攻击不具有鲁棒性 | 数据异构或提高鲁棒性 |
| PoT共识机制[ | 解决数据异构导致的模型公平性问题 | 降低通信开销,并可以防止中间参数传输信息泄露 | 数据异构程度可能影响审计结果公平性 | 数据异构 |
| PPFLChain[ | 解决去中心化、安全和公平性问题 | 具备隐私保护、数据安全以及可扩展性 | 数据异构程度可能会影响有效性 |
表6 贡献评估方法的分析
Tab. 6 Analysis of contribution evaluation methods
| 方法 | 研究动机 | 优势 | 局限性 | 适用场景 |
|---|---|---|---|---|
| TMC-Shapley, G-Shapley[ | 解决数据估值的公平性问题 | 与真实Shapley值的皮尔逊相关系数接近1 | 计算开销容易受到训练规模的影响 | 小规模协作 |
| GTG-Shapley[ | 解决Shapley值计算效率问题 | 具备良好的收敛速度和准确率 | 有效性受到数据异构影响 | 数据或算力异构 |
| 联邦Shapley[ | 解决传统Shapley值通信成本高的问题,以及忽略数据源训练顺序的问题 | 能在参与者数量较大时进行高效计算 | 有效性受到数据异构影响 | 大规模协作 |
| RFFL[ | 解决公平性和鲁棒性的问题 | 可以识别和隔离未定向毒化对手和搭便车者 | 在有目标的毒化攻击中,对手可能不会完全被识别。在无目标的毒化攻击中,某些方法对于重新缩放攻击不具有鲁棒性 | 数据异构或提高鲁棒性 |
| PoT共识机制[ | 解决数据异构导致的模型公平性问题 | 降低通信开销,并可以防止中间参数传输信息泄露 | 数据异构程度可能影响审计结果公平性 | 数据异构 |
| PPFLChain[ | 解决去中心化、安全和公平性问题 | 具备隐私保护、数据安全以及可扩展性 | 数据异构程度可能会影响有效性 |
| 方法 | 数据集 | 数据源数 | 迭代次数 | 评价指标及结果 | 说明 |
|---|---|---|---|---|---|
| FLI[ | — | 100 | 1 000 | 准确率:比第二名的Shapley方案高7个百分点 | 10次实验后的平均值 |
| FPPDL[ | MNIST | 50 | 100 | CNN模型:准确率为98%; MLP模型:准确率为96% | |
| SVHN(Street View House Numbers)[ | — | — | CNN模型:准确率为97%; MLP模型:准确率为93% | ||
| EBFLIM[ | MNIST | 10 | 70 | 收益占比:诚实数据源85%,虚报数据源15% | 收益占比:数据源获得的激励占总激励的比值 |
| FMore[ | MNIST | 100 | 20 | 准确率:95% | |
| FMNIST | 100 | 20 | 准确率:84% | ||
| CIFAR-10 | 100 | 20 | 准确率:50% | ||
| EMD-FLIM[ | MNIST | 20 | 1 000 | 准确率:提升4.5个百分点 | 与FMore相比 |
| CIFAR-10 | 20 | 1 000 | 准确率:提升6.2个百分点 | ||
| 文献[ | — | 50 | — | 数据源总效用及委托方效用均优于FedAvg | 未提及具体数值 |
| PPBG-AC[ | MNIST | 10 | 100 | 准确率:提升4.73个百分点 | 与AsyFL相比 |
表7 各种激励机制实验结果对比
Tab. 7 Experimental comparison result of various incentive mechanisms
| 方法 | 数据集 | 数据源数 | 迭代次数 | 评价指标及结果 | 说明 |
|---|---|---|---|---|---|
| FLI[ | — | 100 | 1 000 | 准确率:比第二名的Shapley方案高7个百分点 | 10次实验后的平均值 |
| FPPDL[ | MNIST | 50 | 100 | CNN模型:准确率为98%; MLP模型:准确率为96% | |
| SVHN(Street View House Numbers)[ | — | — | CNN模型:准确率为97%; MLP模型:准确率为93% | ||
| EBFLIM[ | MNIST | 10 | 70 | 收益占比:诚实数据源85%,虚报数据源15% | 收益占比:数据源获得的激励占总激励的比值 |
| FMore[ | MNIST | 100 | 20 | 准确率:95% | |
| FMNIST | 100 | 20 | 准确率:84% | ||
| CIFAR-10 | 100 | 20 | 准确率:50% | ||
| EMD-FLIM[ | MNIST | 20 | 1 000 | 准确率:提升4.5个百分点 | 与FMore相比 |
| CIFAR-10 | 20 | 1 000 | 准确率:提升6.2个百分点 | ||
| 文献[ | — | 50 | — | 数据源总效用及委托方效用均优于FedAvg | 未提及具体数值 |
| PPBG-AC[ | MNIST | 10 | 100 | 准确率:提升4.73个百分点 | 与AsyFL相比 |
| 方法 | 研究动机 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|---|
| FLI[ | 解决企业数据所有者参与联邦学习的动机问题 | 能吸引高质量数据源并最小化数据源之间的不平等 | 奖励延迟方法可能导致贡献与奖励不匹配 | 数据异构 |
| FPPDL[ | 解决“搭便车现象”对训练造成影响的问题 | 平衡了隐私性、公平性和有效性 | 收敛速度较慢,较小的本地计算量可能会提高收敛速度,但会增加计算成本 | |
| EBFLIM[ | 解决数据源虚报训练成本导致激励不匹配的问题 | 可以评估数据源提交的模型质量并量化数据源成本 | 在解决激励不匹配问题时,仍然需要参与者提供准确的训练成本信息,存在一定的信任度要求 | 激励与贡献不匹配 |
| FMore[ | 解决边缘节点协作问题 | 轻量且具有激励兼容性,实际部署中计算开销和通信成本可忽略不计 | 假设边缘节点可信且数据源具备相同私有价值,但实际情况中可能存在合谋攻击或虚假身份攻击等问题,且大多数节点私有价值是不同的 | 数据或算力异构 |
| EMD-FLIM[ | 解决异构性降低模型有效性的问题 | 平衡了贡献评估合理性、数据源理性和总预算可行性 | 收敛速度可能受到数据或算力异构程度影响 | 数据异构 |
| 文献[ | 解决不完全信息场景下利用激励机制对数据源进行资源分配的问题 | 最小化预算与成本 | 缺乏针对算力异构的资源分配方案 | |
| PPBG-AC[ | 解决不完全信息场景下激励机制的公平性和有效性问题 | 能考虑数据源的异构性和隐私保护需求 | 在完全信息场景下假设交易市场已知数据供给方的真实模型训练信息 |
表8 激励机制的分析
Tab. 8 Incentive mechanism analysis
| 方法 | 研究动机 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|---|
| FLI[ | 解决企业数据所有者参与联邦学习的动机问题 | 能吸引高质量数据源并最小化数据源之间的不平等 | 奖励延迟方法可能导致贡献与奖励不匹配 | 数据异构 |
| FPPDL[ | 解决“搭便车现象”对训练造成影响的问题 | 平衡了隐私性、公平性和有效性 | 收敛速度较慢,较小的本地计算量可能会提高收敛速度,但会增加计算成本 | |
| EBFLIM[ | 解决数据源虚报训练成本导致激励不匹配的问题 | 可以评估数据源提交的模型质量并量化数据源成本 | 在解决激励不匹配问题时,仍然需要参与者提供准确的训练成本信息,存在一定的信任度要求 | 激励与贡献不匹配 |
| FMore[ | 解决边缘节点协作问题 | 轻量且具有激励兼容性,实际部署中计算开销和通信成本可忽略不计 | 假设边缘节点可信且数据源具备相同私有价值,但实际情况中可能存在合谋攻击或虚假身份攻击等问题,且大多数节点私有价值是不同的 | 数据或算力异构 |
| EMD-FLIM[ | 解决异构性降低模型有效性的问题 | 平衡了贡献评估合理性、数据源理性和总预算可行性 | 收敛速度可能受到数据或算力异构程度影响 | 数据异构 |
| 文献[ | 解决不完全信息场景下利用激励机制对数据源进行资源分配的问题 | 最小化预算与成本 | 缺乏针对算力异构的资源分配方案 | |
| PPBG-AC[ | 解决不完全信息场景下激励机制的公平性和有效性问题 | 能考虑数据源的异构性和隐私保护需求 | 在完全信息场景下假设交易市场已知数据供给方的真实模型训练信息 |
| 1 | ANONYMOUS. Consumer data privacy in a networked world: a framework for protecting privacy and promoting innovation in the global digital economy [J]. Journal of Privacy and Confidentiality, 2013, 4(2): No.623. |
| 2 | KONEČNÝ J, McMAHAN H B, RAMAGE D, et al. Federated optimization: distributed machine learning for on-device intelligence [EB/OL]. [2023-03-06]. . |
| 3 | KONEČNÝ J, McMAHAN H B, YU F X, et al. Federated learning: strategies for improving communication efficiency [EB/OL]. [2023-09-06]. . |
| 4 | McMAHAN H B, MOORE E, RAMAGE D, et al. Communication-efficient learning of deep networks from decentralized data [C]// Proceedings of the 20th International Conference on Artificial Intelligence and Statistics. New York: JMLR.org, 2017: 1273-1282. |
| 5 | KAIROUZ P, McMAHAN H B, AVENT B, et al. Advances and open problems in federated learning [J]. Foundations and Trends in Machine Learning, 2021, 14(1/2): 1-210. |
| 6 | PESSACH D, SHMUELI E. A review on fairness in machine learning [J]. ACM Computing Surveys, 2023, 55(3): No.51. |
| 7 | ZHOU P, FANG P, HUI P. Loss tolerant federated learning [EB/OL]. [2023-01-31]. . |
| 8 | DU W, XU D, WU X, et al. Fairness-aware agnostic federated learning [C]// Proceedings of the 2021 SIAM International Conference on Data Mining. Philadelphia, PA: SIAM, 2021: 181-189. |
| 9 | MOHRI M, SIVEK G, SURESH A T. Agnostic federated learning [C]// Proceedings of the 36th International Conference on Machine Learning. New York: JMLR.org, 2019: 4615-4625. |
| 10 | NELSON W R, Jr. Incorporating fairness into game theory and economics: comment [J]. American Economic Review, 2001, 91(4): 1180-1183. |
| 11 | CONG M, YU H, WENG X, et al. A game-theoretic framework for incentive mechanism design in federated learning [M]// YANG Q, FAN L, YU H. Federated learning: privacy and incentive, LNCS 12500. Cham: Springer, 2020: 205-222. |
| 12 | YU H, LIU Z, LIU Y, et al. A fairness-aware incentive scheme for federated learning [C]// Proceedings of the 2020 AAAI/ACM Conference on AI, Ethics, and Society. New York: ACM, 2020: 393-399. |
| 13 | LeCUN Y, BOTTOU L, BENGIO Y, et al. Gradient-based learning applied to document recognition [J]. Proceedings of the IEEE, 1998, 86(11): 2278-2324. |
| 14 | XIAO H, RASUL K, VOLLGRAF R. Fashion-MNIST: a novel image dataset for benchmarking machine learning algorithms [EB/OL]. [2023-02-02]. . |
| 15 | COHEN G, AFSHAR S, TAPSON J, et al. EMNIST: an extension of MNIST to handwritten letters [EB/OL]. [2023-04-06]. . |
| 16 | CALDAS S, DUDDU S M K, WU P, et al. LEAF: a benchmark for federated settings [EB/OL]. [2023-01-31]. . |
| 17 | DUARTE M F, HU Y H. Vehicle classification in distributed sensor networks [J]. Journal of Parallel and Distributed Computing, 2004, 64(7): 826-838. |
| 18 | KRIZHEVSKY A. Learning multiple layers of features from tiny images [R/OL]. [2023-02-02]. . |
| 19 | GO A, BHAVANI R, HUANG L. Twitter sentiment classification using distant supervision [EB/OL]. [2023-03-06]. . |
| 20 | DUA D, GRAFF C. UCI machine learning repository [DB/OL]. [2023-02-03]. . |
| 21 | MORO S, CORTEZ P, RITA P. A data-driven approach to predict the success of bank telemarketing [J]. Decision Support Systems, 2014, 62: 22-31. |
| 22 | LARSON J, MATTU S, KIRCHNER L, et al. How we analyzed the COMPAS recidivism algorithm [EB/OL]. [2023-03-06]. . |
| 23 | WANG H, KAPLAN Z, NIU D, et al. Optimizing federated learning on non-IID data with reinforcement learning [C]// Proceedings of the 2020 IEEE Conference on Computer Communications. Piscataway: IEEE, 2020: 1698-1707. |
| 24 | YOSHIDA N, NISHIO T, MORIKURA M, et al. Hybrid-FL for wireless networks: cooperative learning mechanism using non-IID data[EB/OL]. [2023-02-04]. . |
| 25 | NISHIO T, YONETANI R. Client selection for federated learning with heterogeneous resources in mobile edge [C]// Proceedings of the 2019 IEEE International Conference on Communications. Piscataway: IEEE, 2019: 1-7. |
| 26 | ZHANG J, LI C, ROBLES-KELLY A, et al. Hierarchically fair federated learning [EB/OL]. [2023-03-06]. . |
| 27 | KANG J, XIONG Z, NIYATO D, et al. Incentive design for efficient federated learning in mobile networks: a contract theory approach [C]// Proceedings of the 2019 IEEE VTS Asia Pacific Wireless Communications Symposium. Piscataway: IEEE, 2019: 1-5. |
| 28 | SONG T, TONG Y, WEI S. Profit allocation for federated learning [C]// Proceedings of the 2019 IEEE International Conference on Big Data. Piscataway: IEEE, 2019: 2577-2586. |
| 29 | ZHANG X, LI F, ZHANG Z, et al. Enabling execution assurance of federated learning at untrusted participants [C]// Proceedings of the 2020 IEEE Conference on Computer Communications. Piscataway: IEEE, 2020: 1877-1886. |
| 30 | CHAI Z, ALI A, ZAWAD S, et al. TiFL: a tier-based federated learning system [C]// Proceedings of the 29th International Symposium on High-Performance Parallel and Distributed Computing. New York: ACM, 2015: 125-126. |
| 31 | 温依霖,赵乃良,曾艳,等.基于本地模型质量的客户端选择方法[J].计算机工程, 2023, 49(6): 131-143. |
| WEN Y L, ZHAO N L, ZENG Y, et al. Client selection method based on local model quality [J]. Computer Engineering, 2023, 49(6): 131-143. | |
| 32 | HUANG T, LIN W, WU W, et al. An efficiency-boosting client selection scheme for federated learning with fairness guarantee [J]. IEEE Transactions on Parallel and Distributed Systems, 2021, 32(7): 1552-1564. |
| 33 | HUANG T, LIN W, SHEN L, et al. Stochastic client selection for federated learning with volatile clients [J]. IEEE Internet of Things Journal, 2022, 9(20): 20055-20070. |
| 34 | LI X, HUANG K, YANG W, et al. On the convergence of FedAvg on non-iid data [EB/OL]. [2023-03-01]. . |
| 35 | 王惜民,范睿.基于类别不平衡数据联邦学习的设备选择算法[J].计算机应用研究, 2021, 38(10): 2968-2973. |
| WANG X M, FAN R. Device selection in federated learning under class imbalance [J]. Application Research of Computers, 2021, 38(10): 2968-2973. | |
| 36 | CHEN S, TAVALLAIE O, HAMBALI M H, et al. Optimization of federated learning’s client selection for non-IID data based on Grey relational analysis [EB/OL]. [2023-03-06]. . |
| 37 | ROY D, LEKASSAYS A, GIRDZIJAUSKAS Š, et al. Private, fair and secure collaborative learning framework for human activity recognition [C]// Adjunct Proceedings of the 2023 ACM International Joint Conference on Pervasive and Ubiquitous Computing/ 2023 ACM International Symposium on Wearable Computing. New York: ACM, 2023: 352-358. |
| 38 | DARLOW L N, CROWLEY E J, ANTONIOU A, et al. CINIC-10 is not ImageNet or CIFAR-10: EDI-INF-ANC-1802 [R/OL]. [2023-02-23]. . |
| 39 | REISS A, STRICKER D. Introducing a new benchmarked dataset for activity monitoring [C]// Proceedings of the 16th International Symposium on Wearable Computers. Piscataway: IEEE, 2012: 108-109. |
| 40 | CHEN Y, NING Y, SLAWSKI M, et al. Asynchronous online federated learning for edge devices with non-IID data [C]// Proceedings of the 2020 IEEE International Conference on Big Data. Piscataway: IEEE, 2020: 15-24. |
| 41 | 陈瑞锋,谢在鹏,朱晓瑞,等.一种异步联邦学习聚合更新算法[J].小型微型计算机系统, 2021, 42(12): 2473-2478. |
| CHEN R F, XIE Z P, ZHU X R, et al. Asynchronous federated learning aggregation update algorithm [J]. Journal of Chinese Computer Systems, 2021, 42(12): 2473-2478. | |
| 42 | ZHU H, JIN Y. Multi-objective evolutionary federated learning [J]. IEEE Transactions on Neural Networks and Learning Systems, 2020, 31(4): 1310-1322. |
| 43 | 钟佳淋,吴亚辉,邓苏,等.基于改进NSGA-III的多目标联邦学习进化算法[J].计算机科学, 2023, 50(4): 333-342. |
| ZHONG J L, WU Y H, DENG S, et al. Multi-objective federated learning evolutionary algorithm based on improved NSGA-III [J]. Computer Science, 2023, 50(4): 333-342. | |
| 44 | LI T, SANJABI M, BEIRAMI A, et al. Fair resource allocation in federated learning [EB/OL]. [2023-02-25]. . |
| 45 | SHI H, PRASAD R V, ONUR E, et al. Fairness in wireless networks: issues, measures and challenges [J]. IEEE Communications Surveys and Tutorials, 2014, 16(1): 5-24. |
| 46 | 田家会,吕锡香,邹仁朋,等.一种联邦学习中的公平资源分配方案[J].计算机研究与发展, 2022, 59(6): 1240-1254. |
| TIAN J H, LYU X X, ZOU R P, et al. A fair resource allocation scheme in federated learning [J]. Journal of Computer Research and Development, 2022, 59(6): 1240-1254. | |
| 47 | CUI S, PAN W, LIANG J, et al. Addressing algorithmic disparity and performance inconsistency in federated learning [C]// Proceedings of the 35th International Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2021: 26091-26102. |
| 48 | HU Z, SHALOUDEGI K, ZHANG G, et al. Federated learning meets multi-objective optimization [J]. IEEE Transactions on Network Science and Engineering, 2022, 9(4): 2039-2051. |
| 49 | LI T, HU S, BEIRAMI A, et al. Ditto: fair and robust federated learning through personalization [C]// Proceedings of the 38th International Conference on Machine Learning. New York: JMLR.org, 2021: 6357-6368. |
| 50 | LI X, ZHAO S, CHEN C, et al. Heterogeneity-aware fair federated learning [J]. Information Sciences, 2023, 619: 968-986. |
| 51 | EZZELDIN Y H, YAN S, HE C, et al. FairFed: enabling group fairness in federated learning [C]// Proceedings of the 37th AAAI Conference on Artificial Intelligence. Palo Alto: AAAI Press, 2023: 7494-7502. |
| 52 | WANG J, LIU Q, LIANG H, et al. Tackling the objective inconsistency problem in heterogeneous federated optimization [C]// Proceedings of the 34th International Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2020: 7611-7623. |
| 53 | PAPADAKI A, MARTINEZ N, BERTRAN M, et al. Federating for learning group fair models [EB/OL]. [2024-02-24]. . |
| 54 | ABAY A, ZHOU Y, BARACALDO N, et al. Mitigating bias in federated learning [EB/OL]. [2024-03-01]. . |
| 55 | ZENG Y, CHEN H, LEE K. Improving fairness via federated learning [EB/OL]. [2024-02-28]. . |
| 56 | DUAN Y, LEMMON M. Fair federated learning for deciding community improvement grants [EB/OL]. [2024-03-02]. . |
| 57 | CHEN W, DU J, SHAO Y, et al. Dynamic fair federated learning based on reinforcement learning [EB/OL]. [2024-03-01]. . |
| 58 | HAMER J, MOHRI M, SURESH A T. FedBoost: a communication-efficient algorithm for federated learning [C]// Proceedings of the 37th International Conference on Machine Learning. New York: JMLR.org, 2020: 3973-3983. |
| 59 | ŽLIOBAITE I, KAMIRAN F, CALDERS T. Handling conditional discrimination [C]// Proceedings of the IEEE 11th International Conference on Data Mining. Piscataway: IEEE, 2011: 992-1001. |
| 60 | POLLARD T J, JOHNSON A E W, RAFFA J D, et al. The eICU collaborative research database, a freely available multi-center database for critical care research [J]. Scientific Data, 2018, 5: No.180178. |
| 61 | LIU Z, LUO P, WANG X, et al. Deep learning face attributes in the wild [C]// Proceedings of the 2015 IEEE International Conference on Computer Vision. Piscataway: IEEE, 2015: 3730-3738. |
| 62 | GHORBANI A, ZOU J. Data Shapley: equitable valuation of data for machine learning [C]// Proceedings of the 36th International Conference on Machine Learning. New York: JMLR.org, 2019: 2242-2251. |
| 63 | LIU Z, CHEN Y, YU H, et al. GTG-Shapley: efficient and accurate participant contribution evaluation in federated learning [J]. ACM Transactions on Intelligent Systems and Technology, 2022, 13(4): No.60. |
| 64 | WANG T, RAUSCH J, ZHANG C, et al. A principled approach to data valuation for federated learning [M]// YANG Q, FAN L, YU H. Federated learning: privacy and incentive, LNCS 12500. Cham: Springer, 2020: 153-167. |
| 65 | XU X, LYU L. A reputation mechanism is all you need: collaborative fairness and adversarial robustness in federated learning [EB/OL]. [2023-03-06]. . |
| 66 | FAROUK A, ALAHMADI A, GHOSE S, et al. Blockchain platform for industrial healthcare: vision and future opportunities [J]. Computer Communications, 2020, 154: 223-235. |
| 67 | 陈乃月,金一,李浥东,等.基于区块链的公平性联邦学习模型[J].计算机工程, 2022, 48(6): 33-41. |
| CHEN N Y, JIN Y, LI Y D, et al. Federated learning model with fairness based on blockchain [J]. Computer Engineering, 2022, 48(6): 33-41. | |
| 68 | 周炜,王超,徐剑,等.基于区块链的隐私保护去中心化联邦学习模型[J].计算机研究与发展, 2022, 59(11): 2423-2436. |
| ZHOU W, WANG C, XU J, et al. Privacy-preserving and decentralized federated learning model based on the blockchain [J]. Journal of Computer Research and Development, 2022, 59(11): 2423-2436. | |
| 69 | KOH P W, LIANG P. Understanding black-box predictions via influence functions [C]// Proceedings of the 34th International Conference on Machine Learning. New York: JMLR.org, 2017: 1885-1894. |
| 70 | TSCHANDL P, ROSENDAHL C, KITTLER H. The HAM10000 dataset, a large collection of multi-source dermatoscopic images of common pigmented skin lesions [J]. Scientific Data, 2018, 5: No.180161. |
| 71 | SUDLOW C, GALLACHER J, ALLEN N, et al. UK Biobank: an open access resource for identifying the causes of a wide range of complex diseases of middle and old age [J]. PLoS Medicine, 2015, 12(3): No.e1001779. |
| 72 | WOLF L, HASSNER T, TAIGMAN Y. Effective unconstrained face recognition by combining multiple descriptors and learned background statistics [J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2011, 33(10): 1978-1990. |
| 73 | BUOLAMWINI J, GEBRU T. Gender shades: intersectional accuracy disparities in commercial gender classification [C]// Proceedings of the 1st Conference on Fairness, Accountability and Transparency. New York: JMLR.org, 2018: 77-91. |
| 74 | HULL J J. A database for handwritten text recognition research [J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 1994, 16(5): 550-554. |
| 75 | ALMEIDA T A, GÓMEZ HIDALGO J M, SILVA T P. Towards SMS spam filtering: results under a new dataset [J]. International Journal of Information Security Science, 2013, 2(1): 1-18. |
| 76 | METSIS V, ANDROUTSOPOULOS I, PALIOURAS G. Spam filtering with Naive Bayes — which Naive Bayes? [EB/OL]. [2023-10-06]. |
| 77 | PANG B, LEE L. Seeing stars: exploiting class relationships for sentiment categorization with respect to rating scales [C]// Proceedings of the 43rd Annual Meeting of the Association for Computational Linguistics. Stroudsburg: ACL, 2005: 115-124. |
| 78 | KIM Y. Convolutional neural networks for sentence classification [C]// Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing. Stroudsburg: ACL, 2014: 1746-1751. |
| 79 | LYU L, YU J, NANDAKUMAR K, et al. Towards fair and privacy-preserving federated deep models [J]. IEEE Transactions on Parallel and Distributed Systems, 2020, 31(11): 2524-2541. |
| 80 | 孙跃杰,赵国生,廖祎玮.面向联邦学习激励优化的演化博弈模型[J].小型微型计算机系统, 2024, 45(3): 718-725. |
| SUN Y J, ZHAO G S, LIAO Y W. Evolutionary game model for federated learning incentive optimization [J]. Journal of Chinese Computer Systems, 2024, 45(3): 718-725. | |
| 81 | ZENG R, ZHANG S, WANG J, et al. FMore: an incentive scheme of multi-dimensional auction for federated learning in MEC [C]// Proceedings of the IEEE 40th International Conference on Distributed Computing Systems. Piscataway: IEEE, 2020: 278-288. |
| 82 | 顾永跟,钟浩天,吴小红,等.不平衡数据下预算限制的联邦学习激励机制[J].计算机应用研究, 2022, 39(11): 3385-3389. |
| GU Y G, ZHONG H T, WU X H, et al. Incentive mechanism for federated learning with budget constraints under unbalanced data [J]. Application Research of Computers, 2022, 39(11): 3385-3389. | |
| 83 | WANG Z, HU Q, LI R, et al. Incentive mechanism design for joint resource allocation in blockchain-based federated learning [J]. IEEE Transactions on Parallel and Distributed Systems, 2023, 34(5): 1536-1547. |
| 84 | 张沁楠,朱建明,高胜,等.基于区块链和贝叶斯博弈的联邦学习激励机制[J].中国科学:信息科学, 2022, 52(6): 971-991. |
| ZHANG Q N, ZHU J M, GAO S, et al. Incentive mechanism for federated learning based on blockchain and Bayesian game [J]. SCIENTIA SINICA Informationis, 2022, 52(6): 971-991. | |
| 85 | NETZER Y, WANG T, COATES A, et al. Reading digits in natural images with unsupervised feature learning [EB/OL]. [2024-03-06]. . |
| [1] | 朱亮, 慕京哲, 左洪强, 谷晶中, 朱付保. 基于联邦图神经网络的位置隐私保护推荐方案[J]. 《计算机应用》唯一官方网站, 2025, 45(1): 136-143. |
| [2] | 晏燕, 钱星颖, 闫鹏斌, 杨杰. 位置大数据的联邦学习统计预测与差分隐私保护方法[J]. 《计算机应用》唯一官方网站, 2025, 45(1): 127-135. |
| [3] | 陈廷伟, 张嘉诚, 王俊陆. 面向联邦学习的随机验证区块链构建[J]. 《计算机应用》唯一官方网站, 2024, 44(9): 2770-2776. |
| [4] | 沈哲远, 杨珂珂, 李京. 基于双流神经网络的个性化联邦学习方法[J]. 《计算机应用》唯一官方网站, 2024, 44(8): 2319-2325. |
| [5] | 罗玮, 刘金全, 张铮. 融合秘密分享技术的双重纵向联邦学习框架[J]. 《计算机应用》唯一官方网站, 2024, 44(6): 1872-1879. |
| [6] | 陈学斌, 任志强, 张宏扬. 联邦学习中的安全威胁与防御措施综述[J]. 《计算机应用》唯一官方网站, 2024, 44(6): 1663-1672. |
| [7] | 余孙婕, 曾辉, 熊诗雨, 史红周. 基于生成式对抗网络的联邦学习激励机制[J]. 《计算机应用》唯一官方网站, 2024, 44(2): 344-352. |
| [8] | 张祖篡, 陈学斌, 高瑞, 邹元怀. 基于标签分类的联邦学习客户端选择方法[J]. 《计算机应用》唯一官方网站, 2024, 44(12): 3759-3765. |
| [9] | 巫婕, 钱雪忠, 宋威. 基于相似度聚类和正则化的个性化联邦学习[J]. 《计算机应用》唯一官方网站, 2024, 44(11): 3345-3353. |
| [10] | 陈学斌, 屈昌盛. 面向联邦学习的后门攻击与防御综述[J]. 《计算机应用》唯一官方网站, 2024, 44(11): 3459-3469. |
| [11] | 张帅华, 张淑芬, 周明川, 徐超, 陈学斌. 基于半监督联邦学习的恶意流量检测模型[J]. 《计算机应用》唯一官方网站, 2024, 44(11): 3487-3494. |
| [12] | 张睿, 潘俊铭, 白晓露, 胡静, 张荣国, 张鹏云. 面向深度分类模型超参数自优化的代理模型[J]. 《计算机应用》唯一官方网站, 2024, 44(10): 3021-3031. |
| [13] | 尹春勇, 周永成. 双端聚类的自动调整聚类联邦学习[J]. 《计算机应用》唯一官方网站, 2024, 44(10): 3011-3020. |
| [14] | 张佩瑶, 付晓东. 防恶意竞价的众包多任务分配激励机制[J]. 《计算机应用》唯一官方网站, 2024, 44(1): 261-268. |
| [15] | 周辉, 陈玉玲, 王学伟, 张洋文, 何建江. 基于生成对抗网络的联邦学习深度影子防御方案[J]. 《计算机应用》唯一官方网站, 2024, 44(1): 223-232. |
| 阅读次数 | ||||||
|
全文 |
|
|||||
|
摘要 |
|
|||||