


《计算机应用》唯一官方网站 ›› 2025, Vol. 45 ›› Issue (2): 345-353.DOI: 10.11772/j.issn.1001-9081.2024030281
• 人工智能 •
王雅伦, 张仰森( ), 朱思文
), 朱思文
收稿日期:2024-03-18
修回日期:2024-04-30
接受日期:2024-05-31
发布日期:2024-07-22
出版日期:2025-02-10
通讯作者:
张仰森
作者简介:王雅伦(2000—),女,北京人,硕士研究生,CCF会员,主要研究方向:自然语言处理;基金资助:
Yalun WANG, Yangsen ZHANG(), Siwen ZHU
Received:2024-03-18
Revised:2024-04-30
Accepted:2024-05-31
Online:2024-07-22
Published:2025-02-10
Contact:
Yangsen ZHANG
About author:WANG Yalun, born in 2000, M. S. candidate. Her research interests include natural language processing.Supported by:摘要:
义原作为最小的语义单位对于标题生成任务至关重要。尽管义原驱动的神经语言模型(SDLM)是主流模型之一,但它在处理长文本序列时编码能力有限,未充分考虑位置关系,易引入噪声知识进而影响生成标题的质量。针对上述问题,提出一种基于Transformer的生成式标题模型Tran-A-SDLM(Transformer Adaption based Sememe-Driven Language Model with positional embedding and knowledge reasoning)。该模型充分结合自适应位置编码和知识推理机制的优势。首先,引入Transformer模型以增强模型对文本序列的编码能力;其次,利用自适应位置编码机制增强模型的位置感知能力,从而增强对上下文义原知识的学习;此外,引入知识推理模块,用于表示义原知识,并指导模型生成准确标题;最后,为验证Tran-A-SDLM的优越性,在大规模中文短文本摘要(LCSTS)数据集上进行实验。实验结果表明,与RNN-context-SDLM相比,Tran-A-SDLM在ROUGE-1、ROUGE-2和ROUGE-L值上分别提升了0.2、0.7和0.5个百分点。消融实验结果进一步验证了所提模型的有效性。
中图分类号:
王雅伦, 张仰森, 朱思文. 面向知识推理的位置编码标题生成模型[J]. 计算机应用, 2025, 45(2): 345-353.
Yalun WANG, Yangsen ZHANG, Siwen ZHU. Headline generation model with position embedding for knowledge reasoning[J]. Journal of Computer Applications, 2025, 45(2): 345-353.
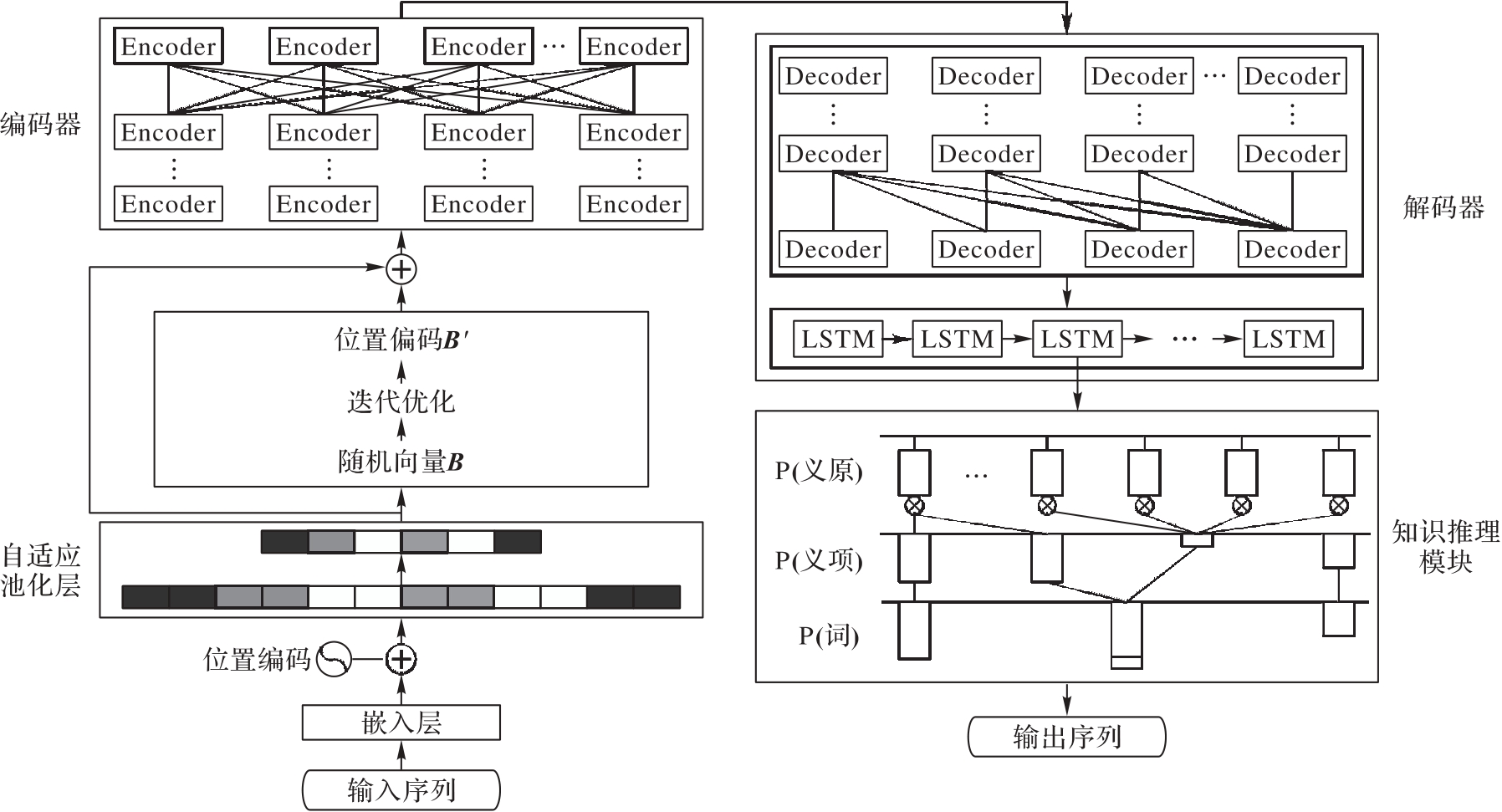
图1 Tran-A-SDLM的整体结构
Fig. 1 Overall structure of Tran-A-SDLM
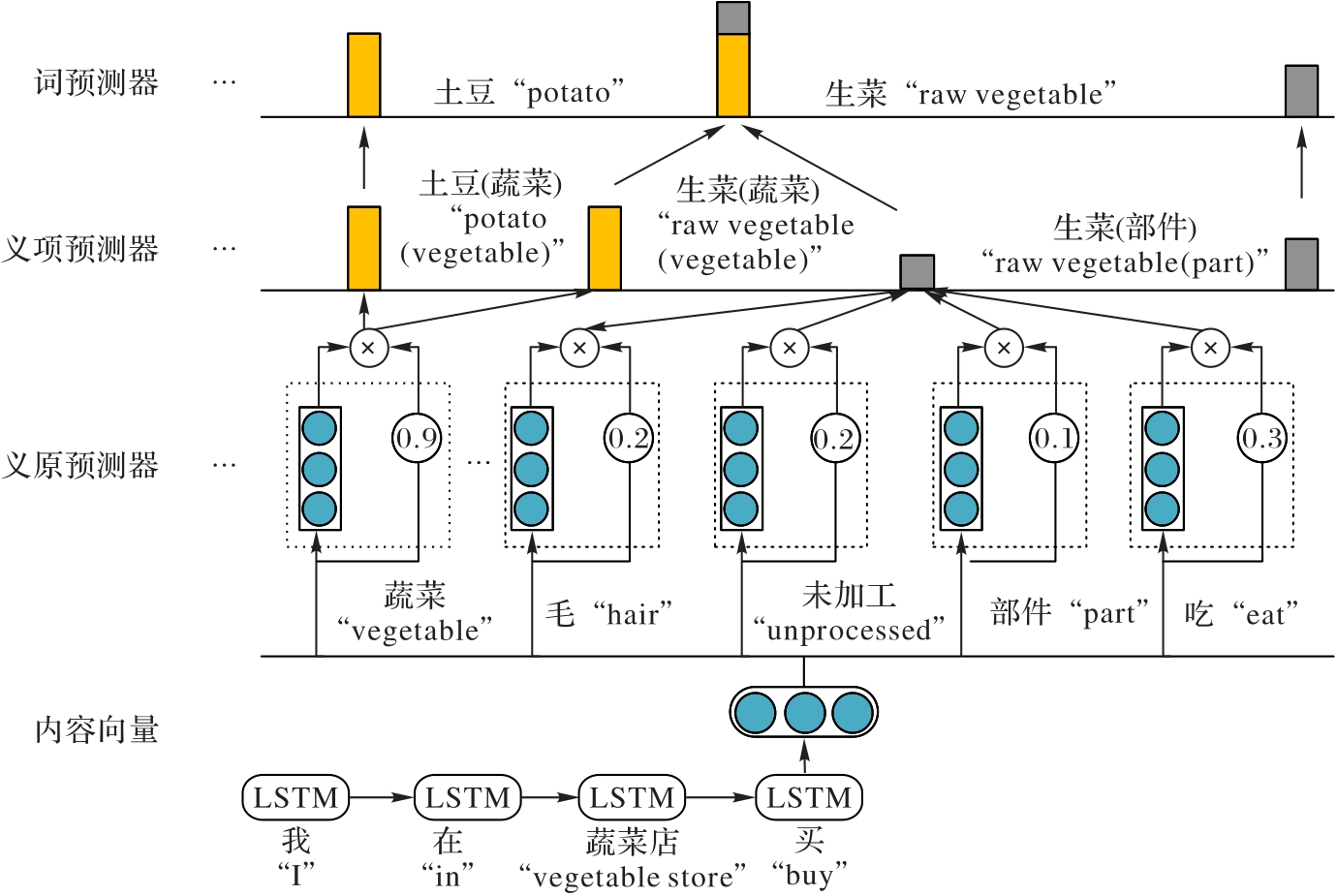
图2 SDLM的模型结构
Fig. 2 Model structure of SDLM
| 参数 | 值 | 参数 | 值 |
|---|---|---|---|
| 批次大小 | 128 | 丢弃率 | 0.15 |
| 训练轮次 | 15 | 梯度裁剪 | 5 |
| 学习率 | 0.001 | 优化器 | Adam |
表1 实验参数设置
Tab. 1 Experimental parameter setting
| 参数 | 值 | 参数 | 值 |
|---|---|---|---|
| 批次大小 | 128 | 丢弃率 | 0.15 |
| 训练轮次 | 15 | 梯度裁剪 | 5 |
| 学习率 | 0.001 | 优化器 | Adam |
| 模型 | ROUGE-1/% | ROUGE-2/% | ROUGE-L/% | 参数量/106 |
|---|---|---|---|---|
| RNN-context | 29.9 | 17.4 | 27.2 | 2.0 |
| ASPM | 32.8 | 16.8 | 32.8 | 2.0 |
| T5 PEGASUS | 34.1 | 22.2 | 31.7 | 275.0 |
| CopyNet | 34.4 | 21.6 | 31.3 | 5.0 |
| DQN | 35.7 | 22.6 | 32.8 | 62.0 |
| BERTSUM | 37.0 | 17.8 | 32.7 | 110.5 |
| Transformer-XL | 37.0 | 19.6 | 34.2 | 41.0 |
| CBART | 37.1 | 21.5 | 35.8 | 121.0 |
| PGN+2T+IF | 37.4 | 23.8 | 34.2 | 39.0 |
RNN-context- SDLM | 38.8 | 26.2 | 36.1 | 32.0 |
| Tran-A-SDLM | 39.0 | 26.9 | 36.6 | 46.0 |
表2 不同模型在LCSTS数据集上的实验结果对比
Tab. 2 Comparison of experimental results of different models on LCSTS dataset
| 模型 | ROUGE-1/% | ROUGE-2/% | ROUGE-L/% | 参数量/106 |
|---|---|---|---|---|
| RNN-context | 29.9 | 17.4 | 27.2 | 2.0 |
| ASPM | 32.8 | 16.8 | 32.8 | 2.0 |
| T5 PEGASUS | 34.1 | 22.2 | 31.7 | 275.0 |
| CopyNet | 34.4 | 21.6 | 31.3 | 5.0 |
| DQN | 35.7 | 22.6 | 32.8 | 62.0 |
| BERTSUM | 37.0 | 17.8 | 32.7 | 110.5 |
| Transformer-XL | 37.0 | 19.6 | 34.2 | 41.0 |
| CBART | 37.1 | 21.5 | 35.8 | 121.0 |
| PGN+2T+IF | 37.4 | 23.8 | 34.2 | 39.0 |
RNN-context- SDLM | 38.8 | 26.2 | 36.1 | 32.0 |
| Tran-A-SDLM | 39.0 | 26.9 | 36.6 | 46.0 |
| 模型 | ROUGE-1 | ROUGE-2 | ROUGE-L |
|---|---|---|---|
| Tran⁃A⁃SDLM | 39.0 | 26.9 | 36.6 |
| -A | 38.9 | 26.6 | 36.3 |
| -Tran | 38.8 | 26.2 | 36.1 |
| -SDLM | 38.2 | 25.7 | 35.4 |
表3 消融实验结果 ( %)
Tab. 3 Results of ablation study
| 模型 | ROUGE-1 | ROUGE-2 | ROUGE-L |
|---|---|---|---|
| Tran⁃A⁃SDLM | 39.0 | 26.9 | 36.6 |
| -A | 38.9 | 26.6 | 36.3 |
| -Tran | 38.8 | 26.2 | 36.1 |
| -SDLM | 38.2 | 25.7 | 35.4 |
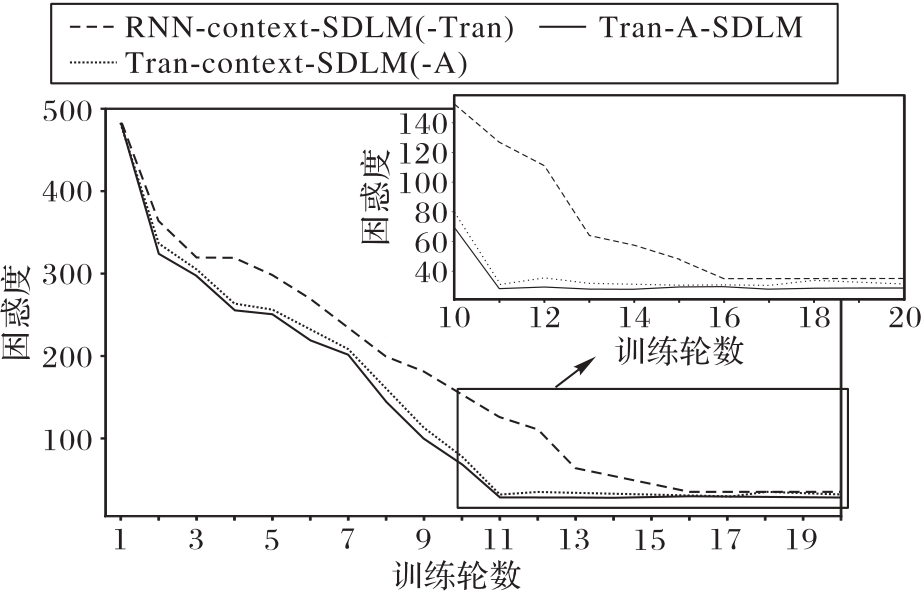
图3 训练趋势图
Fig. 3 Training trend chart
| 序号 | 参考标题 | 对比模型 | 生成标题 |
|---|---|---|---|
| 1 | 男生高考作弊追打监考老师: 你知道我爸是谁? | RNN-context | 高考作弊事件中男生动手伤害女监考官 |
| CopyNet | 男考生不满没收作弊手机,踹女监考老师 | ||
| BERTSUM | 阜新高考男生作弊被抓后攻击监考老师 | ||
| RNN-context-SDLM(-Tran) | 高考生作弊被抓:你知道我爸是谁啊? | ||
| Tran-A-SDLM | 高考生作弊被抓踹监考老师:你知道我爸是谁啊? | ||
| 2 | 教育部原发言人: 现在语文课至少一半不该学 | RNN-context | 教育部发言人:语文教材修订稿 |
| CopyNet | 前教育部发言人:语文课至少一半不该学,应增加传统文化的比例 | ||
| BERTSUM | 专家:语文课至少一半不该学,应修订 | ||
| RNN-context-SDLM(-Tran) | 教育部发言人:语文课至少一半不该学内容 | ||
| Tran-A-SDLM | 教育部原发言人:语文课至少一半不该学 |
表4 不同模型对同一文本生成的不同标题结果
Tab. 4 Results of different headlines generated by different models for same text
| 序号 | 参考标题 | 对比模型 | 生成标题 |
|---|---|---|---|
| 1 | 男生高考作弊追打监考老师: 你知道我爸是谁? | RNN-context | 高考作弊事件中男生动手伤害女监考官 |
| CopyNet | 男考生不满没收作弊手机,踹女监考老师 | ||
| BERTSUM | 阜新高考男生作弊被抓后攻击监考老师 | ||
| RNN-context-SDLM(-Tran) | 高考生作弊被抓:你知道我爸是谁啊? | ||
| Tran-A-SDLM | 高考生作弊被抓踹监考老师:你知道我爸是谁啊? | ||
| 2 | 教育部原发言人: 现在语文课至少一半不该学 | RNN-context | 教育部发言人:语文教材修订稿 |
| CopyNet | 前教育部发言人:语文课至少一半不该学,应增加传统文化的比例 | ||
| BERTSUM | 专家:语文课至少一半不该学,应修订 | ||
| RNN-context-SDLM(-Tran) | 教育部发言人:语文课至少一半不该学内容 | ||
| Tran-A-SDLM | 教育部原发言人:语文课至少一半不该学 |
| 1 | 夏吾吉,黄鹤鸣,更藏措毛,等. 基于无监督学习和监督学习的抽取式文本摘要综述[J]. 计算机应用, 2024, 44(4): 1035-1048. |
| XIA W J, HUANG H M, GENGZANGCUOMAO, et al. Survey of extractive text summarization based on unsupervised learning and supervised learning[J]. Journal of Computer Applications, 2024, 44(4): 1035-1048. | |
| 2 | 朱永清,赵鹏,赵菲菲,等. 基于深度学习的生成式文本摘要技术综述[J]. 计算机工程, 2021, 47(11):11-21, 28. |
| ZHU Y Q, ZHAO P, ZHAO F F, et al. Survey on abstractive text summarization technologies based on deep learning[J]. Computer Engineering, 2021, 47(11): 11-21, 28. | |
| 3 | ZHENG C, CAI Y, ZHANG G, et al. Controllable abstractive sentence summarization with guiding entities[C]// Proceedings of the 28th International Conference on Computational Linguistics. [S.l.]: International Committee on Computational Linguistics, 2020: 5668-5678. |
| 4 | XU P, ZHU X, CLIFTON D A. Multimodal learning with transformers: a survey[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2023, 45(10): 12113-12132. |
| 5 | DAI Z, YANG Z, YANG Y, et al. Transformer-XL: attentive language models beyond a fixed-length context[C]// Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics. Stroudsburg: ACL, 2019: 2978-2988. |
| 6 | YANG Z, DAI Z, YANG Y, et al. XLNet: generalized autoregressive pretraining for language understanding[C]// Proceedings of the 33rd International Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2019: 5753-5763. |
| 7 | 石磊,阮选敏,魏瑞斌,等. 基于序列到序列模型的生成式文本摘要研究综述[J]. 情报学报, 2019, 38(10):1102-1116. |
| SHI L, RUAN X M, WEI R B, et al. Abstractive summarization based on sequence to sequence models: a review[J]. Journal of the China Society for Scientific and Technical Information, 2019, 38(10): 1102-1116. | |
| 8 | RUSH A M, CHOPRA S, WESTON J. A neural attention model for abstractive sentence summarization[C]// Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing. Stroudsburg: ACL, 2015: 379-389. |
| 9 | NALLAPATI R, ZHOU B, DOS SANTOS C, et al. Abstractive text summarization using sequence-to-sequence RNNs and beyond[C]// Proceedings of the 20th SIGNLL Conference on Computational Natural Language Learning. Stroudsburg: ACL, 2016: 280-290. |
| 10 | CHOPRA S, AULI M, RUSH A M. Abstractive sentence summarization with attentive recurrent neural networks[C]// Proceedings of the 2016 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. Stroudsburg: ACL, 2016: 93-98. |
| 11 | GU J, LU Z, LI H, et al. Incorporating copying mechanism in sequence-to-sequence learning[C]// Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Stroudsburg: ACL, 2016: 1631-1640. |
| 12 | 毛兴静,魏勇,杨昱睿,等. 基于关键词异构图的生成式摘要研究[J]. 计算机科学, 2024, 51(7):278-286. |
| MAO X J, WEI Y, YANG Y R, et al. KHGAS: keywords guided heterogeneous graph for abstractive summarization[J]. Computer Science, 2024, 51(7):278-286. | |
| 13 | 张志远,肖芮. 融合全局编码与主题解码的文本摘要方法[J]. 计算机应用与软件, 2023, 40(4):134-140, 183. |
| ZHANG Z Y, XIAO R. Text summarization method combining global coding and subject decoding[J]. Computer Applications and Software, 2023, 40(4): 134-140, 183. | |
| 14 | 崔卓,李红莲,张乐,等. 一种融合义原的中文摘要生成方法[J]. 中文信息学报, 2022, 36(6): 146-154. |
| CUI Z, LI H L, ZHANG L, et al. A Chinese summary generation method incorporating sememes[J]. Journal of Chinese Information Processing, 2022, 36(6): 146-154. | |
| 15 | SUN G, WANG Z, ZHAO J. Automatic text summarization using deep reinforcement learning and beyond[J]. Information Technology and Control, 2021, 50(3): 458-469. |
| 16 | ZHANG Y, YANG C, ZHOU Z, et al. Enhancing Transformer with sememe knowledge[C]// Proceedings of the 5th Workshop on Representation Learning for NLP. Stroudsburg: ACL, 2020: 177-184. |
| 17 | GU Y, YAN J, ZHU H, et al. Language modeling with sparse product of sememe experts[C]// Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing. Stroudsburg: ACL, 2018: 4642-4651. |
| 18 | SU M H, WU C H, CHENG H T. A two-stage Transformer-based approach for variable-length abstractive summarization[J]. IEEE/ACM Transactions on Audio, Speech and Language Processing, 2020, 28: 2061-2072. |
| 19 | 李旭军,王珺,余孟. 融合预训练和注意力增强的中文自动摘要研究[J]. 计算机工程与应用, 2023, 59(14): 134-141. |
| LI X J, WANG J, YU M. Research on automatic Chinese summarization combining pre-training and attention enhancement[J]. Computer Engineering and Applications, 2023, 59(14): 134-141. | |
| 20 | VASWANI A, SHAZEER N, PARMAR N, et al. Attention is all you need[C]// Proceedings of the 31st International Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2017: 6000-6010. |
| 21 | SHAW P, USZKOREIT J, VASWANI A. Self-attention with relative position representations[C]// Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 2 (Short Papers). Stroudsburg: ACL, 2018: 464-468. |
| 22 | GEHRING J, AULI M, GRANGIER D, et al. Convolutional sequence to sequence learning[C]// Proceedings of the 34th International Conference on Machine Learning. New York: JMLR.org, 2017: 1243-1252. |
| 23 | DEVLIN J, CHANG M W, LEE K, et al. BERT: pre-training of deep bidirectional Transformers for language understanding[C]// Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers). Stroudsburg: ACL, 2019: 4171-4186. |
| 24 | LIU Y, OTT M, GOYAL N, et al. RoBERTa: a robustly optimized BERT pretraining approach[EB/OL]. [2023-12-07].. |
| 25 | 郑志超,陈进东,张健. 融合非负正弦位置编码和混合注意力机制的情感分析模型[J]. 计算机工程与应用, 2024, 60(15):101-110. |
| ZHENG Z C, CHEN J D, ZHANG J. Sentiment classification model based on non-negative sinusoidal positional encoding and hybrid attention mechanism[J]. Computer Engineering and Applications, 2024, 60(15):101-110. | |
| 26 | HE P, LIU X, GAO J, et al. DeBERTa: decoding-enhanced BERT with disentangled attention[EB/OL]. [2024-01-12].. |
| 27 | CHU X, TIAN Z, ZHANG B, et al. Conditional positional encodings for vision transformers[EB/OL]. [2023-10-24].. |
| 28 | ABDU-AGUYE M G, GOMAA W, MAKIHARA Y, et al. Adaptive pooling is all you need: an empirical study on hyperparameter-insensitive human action recognition using wearable sensors[C]// Proceedings of the 2020 International Joint Conference on Neural Networks. Piscataway: IEEE, 2020:1-6. |
| 29 | ZHAO S, ZHANG T, HU M, et al. AP-BERT: enhanced pre-trained model through average pooling[J]. Applied Intelligence, 2022, 52(14): 15929-15937. |
| 30 | LOCHTER J V, SILVA R M, ALMEIDA T A. Deep learning models for representing out-of-vocabulary words[C]// Proceedings of the 2020 Brazilian Conference on Intelligent Systems, LNCS 12319. Cham: Springer, 2020: 418-434. |
| 31 | BENAMAR A, GROUIN C, BOTHUA M, et al. Evaluating tokenizers impact on OOVs representation with Transformers models[C]// Proceedings of the 13th Language Resources and Evaluation Conference. Paris: European Language Resources Association, 2022: 4193-4204. |
| 32 | 孙茂松,陈新雄. 借重于人工知识库的词和义项的向量表示:以HowNet为例[J]. 中文信息学报, 2016, 30(6):1-6, 14. |
| SUN M S, CHEN X X. Embedding for words and word senses based on human annotated knowledge base: a case study on HowNet[J]. Journal of Chinese Information Processing, 2016, 30(6): 1-6, 14. | |
| 33 | HU B, CHEN Q, ZHU F. LCSTS: a large scale Chinese short text summarization dataset[C]// Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing. Stroudsburg: ACL, 2015: 1967-1972. |
| 34 | LIN C Y. ROUGE: a package for automatic evaluation of summaries[C]// Proceedings of the ACL-04 Workshop: Text Summarization Branches Out. Stroudsburg: ACL, 2004: 74-81. |
| 35 | XUE L, CONSTANT N, ROBERTS A, et al. mT5: a massively multilingual pre-trained text-to-text transformer[C]// Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. Stroudsburg: ACL, 2021: 483-498. |
| 36 | ZHANG J, ZHAO Y, SALEH M, et al. PEGASUS: pre-training with extracted gap-sentences for abstractive summarization[C]// Proceedings of the 37th International Conference on Machine Learning. New York: JMLR.org, 2020: 11328-11339. |
| 37 | HE X. Parallel refinements for lexically constrained text generation with BART[C]// Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing. Stroudsburg: ACL, 2021: 8653-8666. |
| [1] | 梁杰涛, 罗兵, 付兰慧, 常青玲, 李楠楠, 易宁波, 冯其, 何鑫, 邓辅秦. 基于坐标几何采样的点云配准方法[J]. 《计算机应用》唯一官方网站, 2025, 45(1): 214-222. |
| [2] | 吕学强, 王涛, 游新冬, 徐戈. 层次融合多元知识的命名实体识别框架——HTLR[J]. 《计算机应用》唯一官方网站, 2025, 45(1): 40-47. |
| [3] | 武杰, 张安思, 吴茂东, 张仪宗, 王从宝. 知识图谱在装备故障诊断领域的研究与应用综述[J]. 《计算机应用》唯一官方网站, 2024, 44(9): 2651-2659. |
| [4] | 任烈弘, 黄铝文, 田旭, 段飞. 基于DFT的频率敏感双分支Transformer多变量长时间序列预测方法[J]. 《计算机应用》唯一官方网站, 2024, 44(9): 2739-2746. |
| [5] | 贾洁茹, 杨建超, 张硕蕊, 闫涛, 陈斌. 基于自蒸馏视觉Transformer的无监督行人重识别[J]. 《计算机应用》唯一官方网站, 2024, 44(9): 2893-2902. |
| [6] | 方介泼, 陶重犇. 应对零日攻击的混合车联网入侵检测系统[J]. 《计算机应用》唯一官方网站, 2024, 44(9): 2763-2769. |
| [7] | 黄云川, 江永全, 黄骏涛, 杨燕. 基于元图同构网络的分子毒性预测[J]. 《计算机应用》唯一官方网站, 2024, 44(9): 2964-2969. |
| [8] | 杨鑫, 陈雪妮, 吴春江, 周世杰. 结合变种残差模型和Transformer的城市公路短时交通流预测[J]. 《计算机应用》唯一官方网站, 2024, 44(9): 2947-2951. |
| [9] | 帅奇, 王海瑞, 朱贵富. 基于双向对比训练的中文故事结尾生成模型[J]. 《计算机应用》唯一官方网站, 2024, 44(9): 2683-2688. |
| [10] | 李金金, 桑国明, 张益嘉. APK-CNN和Transformer增强的多域虚假新闻检测模型[J]. 《计算机应用》唯一官方网站, 2024, 44(9): 2674-2682. |
| [11] | 丁宇伟, 石洪波, 李杰, 梁敏. 基于局部和全局特征解耦的图像去噪网络[J]. 《计算机应用》唯一官方网站, 2024, 44(8): 2571-2579. |
| [12] | 邓凯丽, 魏伟波, 潘振宽. 改进掩码自编码器的工业缺陷检测方法[J]. 《计算机应用》唯一官方网站, 2024, 44(8): 2595-2603. |
| [13] | 杨帆, 邹窈, 朱明志, 马振伟, 程大伟, 蒋昌俊. 基于图注意力Transformer神经网络的信用卡欺诈检测模型[J]. 《计算机应用》唯一官方网站, 2024, 44(8): 2634-2642. |
| [14] | 张全梅, 黄润萍, 滕飞, 张海波, 周南. 融合异构信息的自动国际疾病分类编码方法[J]. 《计算机应用》唯一官方网站, 2024, 44(8): 2476-2482. |
| [15] | 李大海, 王忠华, 王振东. 结合空间域和频域信息的双分支低光照图像增强网络[J]. 《计算机应用》唯一官方网站, 2024, 44(7): 2175-2182. |
| 阅读次数 | ||||||
|
全文 |
|
|||||
|
摘要 |
|
|||||