


《计算机应用》唯一官方网站 ›› 2025, Vol. 45 ›› Issue (6): 2025-2033.DOI: 10.11772/j.issn.1001-9081.2024050724
• 多媒体计算与计算机仿真 • 上一篇
宋源1, 陈锌1, 李亚荣1, 李永伟2, 刘扬1, 赵振1
收稿日期:2024-06-03
修回日期:2025-01-08
接受日期:2025-01-10
发布日期:2025-01-14
出版日期:2025-06-10
通讯作者:
刘扬
作者简介:宋源(2000—),女,河南驻马店人,硕士研究生,主要研究方向:语音分离基金资助:Yuan SONG1, Xin CHEN1, Yarong LI1, Yongwei LI2, Yang LIU1, Zhen ZHAO1
Received:2024-06-03
Revised:2025-01-08
Accepted:2025-01-10
Online:2025-01-14
Published:2025-06-10
Contact:
Yang LIU
About author:SONG Yuan, born in 2000, M. S. candidate. Her research interests include speech separation.Supported by:摘要:
为了解决基于语谱图特征输入的单通道语音分离方法存在的不同说话人时频点重叠导致分离效果欠佳的问题,提出一种基于听觉调制孪生网络的单通道语音分离模型。首先,通过频带划分和包络检波计算调制信号,进而利用傅里叶变换提取调制幅度谱;其次,基于突变点检测和匹配的方法获取调制幅度谱特征与语音片段之间的映射关系,实现语音片段的有效划分;再次,设计融合协同注意力机制的孪生神经网络(FCMSNN)提取不同说话人语音片段的鉴别性特征;继次,提出基于邻域机制的自组织映射(N-SOM)网络,通过划定动态邻域范围实现无需预先指定说话人数量的特征聚类,以获得不同说话人的掩膜矩阵;最后,为了避免在调制域重构信号中产生伪影,设计时域滤波器将调制域掩膜转换为时域掩膜并结合相位信息重构语音信号。实验结果表明,所提模型在WSJ0-2mix和WSJ0-3mix数据集上的语音质量感知评价(PESQ)、信号失真比改进(SDRi)和尺度不变信号失真比改进(SI-SDRi)均优于双密度双树复小波变换(DDDTCWT)方法,分别提高了3.47%、6.91%和7.79%和3.08%、6.71%、7.51%。
中图分类号:
宋源, 陈锌, 李亚荣, 李永伟, 刘扬, 赵振. 基于听觉调制孪生网络的单通道语音分离模型[J]. 计算机应用, 2025, 45(6): 2025-2033.
Yuan SONG, Xin CHEN, Yarong LI, Yongwei LI, Yang LIU, Zhen ZHAO. Single-channel speech separation model based on auditory modulation Siamese network[J]. Journal of Computer Applications, 2025, 45(6): 2025-2033.

图1 基于听觉调制孪生网络的单通道语音分离模型的框架
Fig. 1 Framework of single-channel speech separation model based on auditory modulation Siamese network
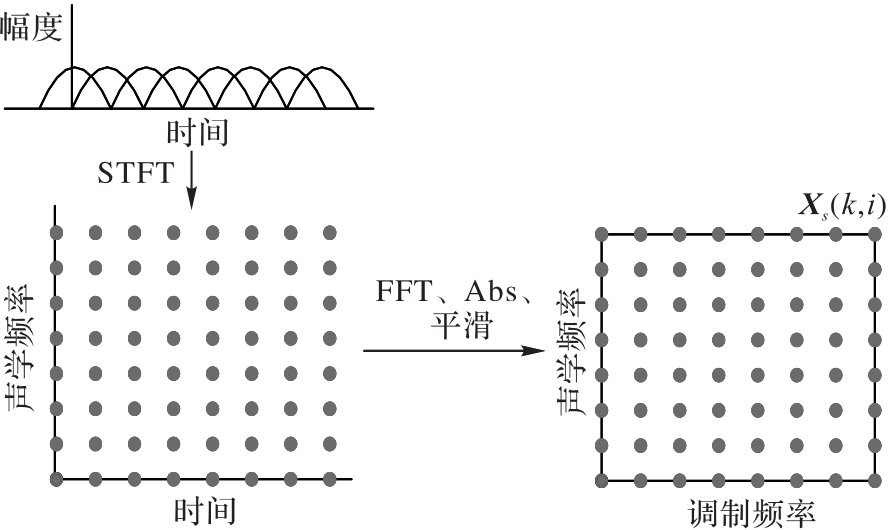
图2 调制幅度谱的计算过程
Fig. 2 Calculation process of modulation amplitude spectrum
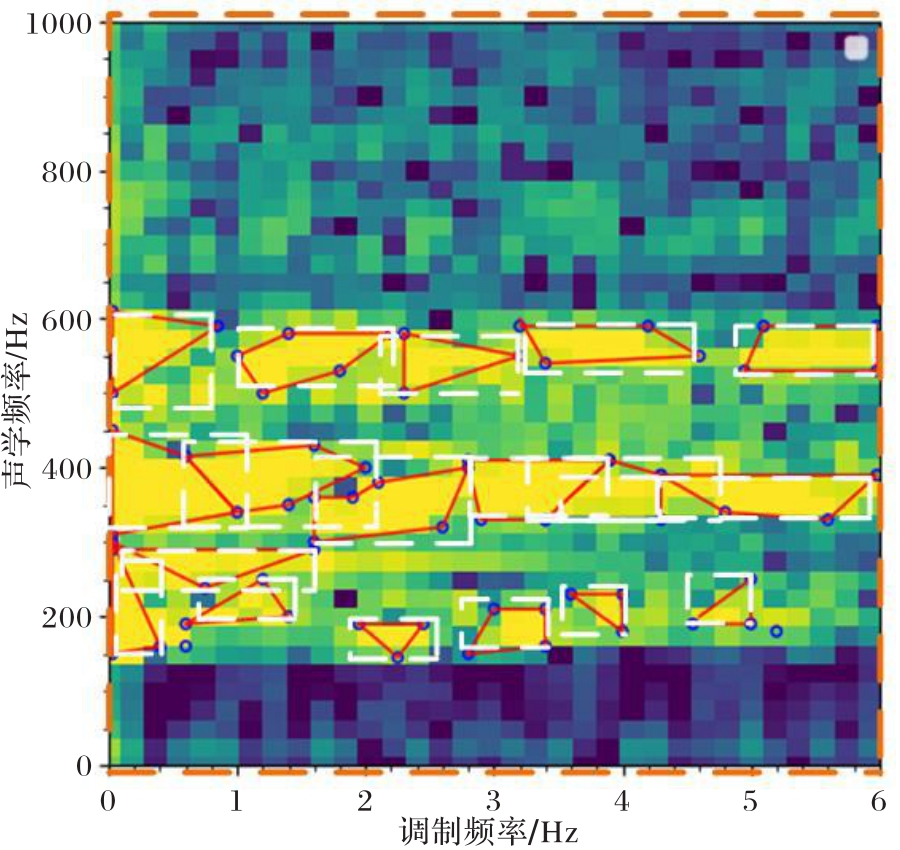
图3 调制幅度谱语音片段生成的结果
Fig. 3 Results of amplitude spectrum speech segment generation

图4 基于协同注意力机制的孪生神经网络
Fig. 4 Siamese neural network based on co-attention mechanism
| 数据集 | 语音分离模型 | PESQ | SDRi/dB | SI-SDRi/dB |
|---|---|---|---|---|
| WSJ0-2mix | NMF-LSTM | 2.08 | 6.34 | — |
| uPIT-LSTM | 2.11 | 7.00 | 7.43 | |
| TasNet-LSTM | 2.84 | 8.00 | 8.20 | |
| DPCL | 3.05 | 7.93 | 5.80 | |
| Chimera | 3.21 | 8.35 | 7.00 | |
| Wave-U-Net | 3.32 | 8.67 | 9.02 | |
| Wave-U-Net+SAM+ASPP | 3.42 | 9.16 | 9.25 | |
| Group+Conquer | 3.44 | 9.23 | 9.21 | |
| DDDTCWT | 3.46 | 9.25 | 9.24 | |
| 本文模型 | 3.58 | 9.89 | 9.96 | |
| WSJ0-3mix | NMF-LSTM | 1.93 | 4.31 | — |
| uPIT-LSTM | 2.01 | 5.05 | — | |
| TasNet-LSTM | 2.53 | 5.26 | 5.64 | |
| DPCL | 2.95 | 5.93 | 6.08 | |
| Chimera | 3.02 | 6.17 | 6.05 | |
| Wave-U-Net | 3.10 | 6.23 | 7.21 | |
| Wave-U-Net+SAM+ASPP | 3.24 | 6.30 | 7.45 | |
| Group+Conquer | 3.20 | 6.22 | 7.43 | |
| DDDTCWT | 3.25 | 6.41 | 7.46 | |
| 本文模型 | 3.35 | 6.84 | 8.02 |
表1 不同数据集上的对比实验结果
Tab. 1 Results of comparison experiments on different datasets
| 数据集 | 语音分离模型 | PESQ | SDRi/dB | SI-SDRi/dB |
|---|---|---|---|---|
| WSJ0-2mix | NMF-LSTM | 2.08 | 6.34 | — |
| uPIT-LSTM | 2.11 | 7.00 | 7.43 | |
| TasNet-LSTM | 2.84 | 8.00 | 8.20 | |
| DPCL | 3.05 | 7.93 | 5.80 | |
| Chimera | 3.21 | 8.35 | 7.00 | |
| Wave-U-Net | 3.32 | 8.67 | 9.02 | |
| Wave-U-Net+SAM+ASPP | 3.42 | 9.16 | 9.25 | |
| Group+Conquer | 3.44 | 9.23 | 9.21 | |
| DDDTCWT | 3.46 | 9.25 | 9.24 | |
| 本文模型 | 3.58 | 9.89 | 9.96 | |
| WSJ0-3mix | NMF-LSTM | 1.93 | 4.31 | — |
| uPIT-LSTM | 2.01 | 5.05 | — | |
| TasNet-LSTM | 2.53 | 5.26 | 5.64 | |
| DPCL | 2.95 | 5.93 | 6.08 | |
| Chimera | 3.02 | 6.17 | 6.05 | |
| Wave-U-Net | 3.10 | 6.23 | 7.21 | |
| Wave-U-Net+SAM+ASPP | 3.24 | 6.30 | 7.45 | |
| Group+Conquer | 3.20 | 6.22 | 7.43 | |
| DDDTCWT | 3.25 | 6.41 | 7.46 | |
| 本文模型 | 3.35 | 6.84 | 8.02 |
| 语音分离模型 | MOS | |||
|---|---|---|---|---|
| S1 | S2 | S3 | S4 | |
| NMF-LSTM | 3.41 | 3.53 | 3.32 | 3.40 |
| uPIT-LSTM | 3.32 | 3.53 | 3.41 | 3.32 |
| TasNet-LSTM | 3.40 | 3.44 | 3.30 | 3.52 |
| DPCL | 3.20 | 3.66 | 3.51 | 3.41 |
| Chimera | 3.63 | 3.81 | 3.70 | 3.83 |
| Wave-U-Net | 3.82 | 3.73 | 3.61 | 3.94 |
| Wave-U-Net+SAM+ASPP | 3.91 | 4.02 | 3.92 | 3.83 |
| Group+Conquer | 3.90 | 3.98 | 3.84 | 4.00 |
| DDDTCWT | 3.93 | 4.00 | 4.03 | 3.90 |
| 本文模型 | 4.18 | 4.25 | 4.33 | 4.05 |
表2 MOS评分
Tab.2 MOS scoring
| 语音分离模型 | MOS | |||
|---|---|---|---|---|
| S1 | S2 | S3 | S4 | |
| NMF-LSTM | 3.41 | 3.53 | 3.32 | 3.40 |
| uPIT-LSTM | 3.32 | 3.53 | 3.41 | 3.32 |
| TasNet-LSTM | 3.40 | 3.44 | 3.30 | 3.52 |
| DPCL | 3.20 | 3.66 | 3.51 | 3.41 |
| Chimera | 3.63 | 3.81 | 3.70 | 3.83 |
| Wave-U-Net | 3.82 | 3.73 | 3.61 | 3.94 |
| Wave-U-Net+SAM+ASPP | 3.91 | 4.02 | 3.92 | 3.83 |
| Group+Conquer | 3.90 | 3.98 | 3.84 | 4.00 |
| DDDTCWT | 3.93 | 4.00 | 4.03 | 3.90 |
| 本文模型 | 4.18 | 4.25 | 4.33 | 4.05 |
| 消融实验组 | PESQ | SDRi/dB | SI-SDRi/dB |
|---|---|---|---|
| A | 3.58 | 9.89 | 9.96 |
| B | 3.51 | 9.62 | 9.73 |
| C | 2.98 | 8.14 | 8.33 |
| D | 3.46 | 9.56 | 9.54 |
| E | 3.06 | 8.82 | 8.75 |
| F | 3.47 | 9.25 | 8.91 |
| G | 3.34 | 8.80 | 8.56 |
表3 消融实验结果
Tab.3 Results of ablation experiments
| 消融实验组 | PESQ | SDRi/dB | SI-SDRi/dB |
|---|---|---|---|
| A | 3.58 | 9.89 | 9.96 |
| B | 3.51 | 9.62 | 9.73 |
| C | 2.98 | 8.14 | 8.33 |
| D | 3.46 | 9.56 | 9.54 |
| E | 3.06 | 8.82 | 8.75 |
| F | 3.47 | 9.25 | 8.91 |
| G | 3.34 | 8.80 | 8.56 |
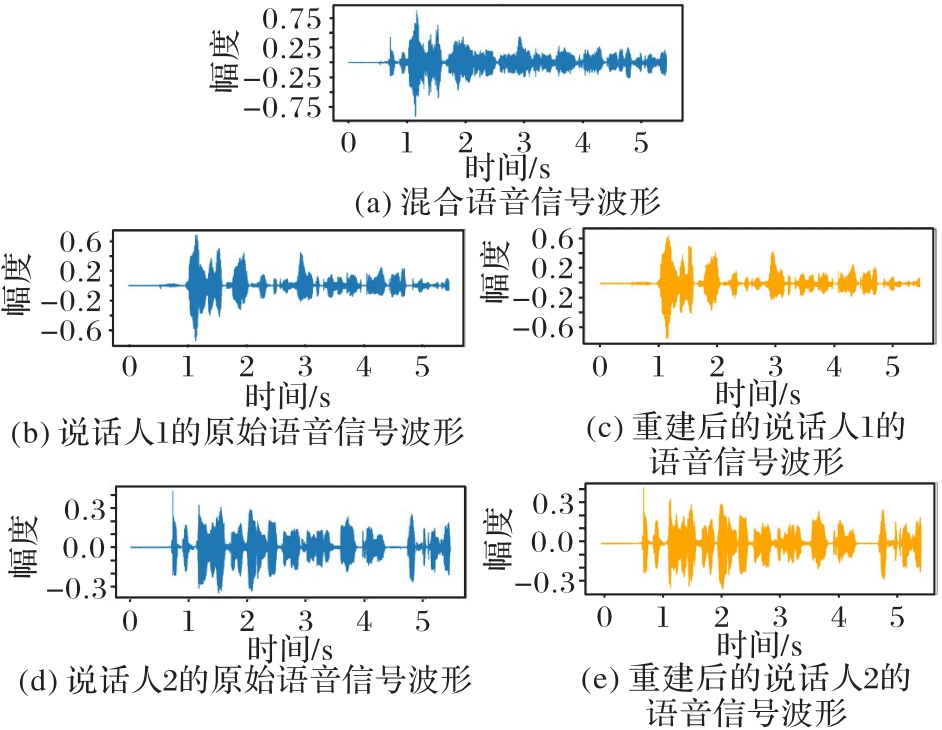
图5 语音分离前后的波形图对比
Fig. 5 Comparison of waveforms before and after speech separation

图6 语音分离前后的调制谱图对比
Fig. 6 Comparison of modulation spectrograms before and after speech separation
| 1 | SHAMMA S A. Speech processing in the auditory system Ⅱ: lateral inhibition and the central processing of speech evoked activity in the auditory nerve[J]. The Journal of the Acoustical Society of America, 1985, 78(5): 1622-1632. |
| 2 | ROUAT J. Computational auditory scene analysis: principles, algorithms, and applications (Wang, D. and Brown, G.J., Eds.; 2006) [Book review][J]. IEEE Transactions on Neural Networks, 2008, 19(1): 199-199. |
| 3 | ZEREMDINI J, MESSAOUD M A BEN, BOUZID A. A comparison of several Computational Auditory Scene Analysis (CASA) techniques for monaural speech segregation[J]. Brain Informatics, 2015, 2(3): 155-166. |
| 4 | SHAO Y, SRINIVASAN S, JIN Z, et al. A computational auditory scene analysis system for speech segregation and robust speech recognition[J]. Computer Speech and Language, 2010, 24(1): 77-93. |
| 5 | CARDOSO J F. Source separation using higher order moments[C]// Proceedings of the 1989 International Conference on Acoustics, Speech, and Signal Processing — Volume 4. Piscataway: IEEE, 1989: 2109-2112. |
| 6 | LEE D D, SEUNG H S. Learning the parts of objects by non-negative matrix factorization[J]. Nature, 1999, 401(6755): 788-791. |
| 7 | CHOI S, CICHOCKI A, PARK H M, et al. Blind source separation and independent component analysis: a review[J]. Neural Information Processing — Letters and Reviews, 2005, 6(1): 1-57. |
| 8 | STONE J V. Independent component analysis: a tutorial introduction[M]. Cambridge: MIT Press, 2004. |
| 9 | THARWAT A. Independent component analysis: an introduction[J]. Applied Computing and Informatics, 2021, 17(2): 222-249. |
| 10 | GANNOT S, VINCENT E, MARKOVICH-GOLAN S, et al. A consolidated perspective on multimicrophone speech enhancement and source separation[J]. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 2017, 25(4): 692-730. |
| 11 | EPHRAIM Y, MALAH D. Speech enhancement using a minimum-mean square error short-time spectral amplitude estimator[J]. IEEE Transactions on Acoustics, Speech, and Signal Processing, 1984, 32(6): 1109-1121. |
| 12 | SLOCK D T M. A survey of convergence results on the least mean square algorithm[J]. IEEE Transactions on Signal Processing, 1993, 41(12): 2960-2988. |
| 13 | BENESTY J, CHEN J, HUANG Y, et al. Pearson correlation coefficient-based adaptive noise cancellation algorithms for improved speech recognition[J]. IEEE Transactions on Audio, Speech, and Language Processing, 2018, 26(5): 984-998. |
| 14 | MINIPRIYA T M, RAJAVEL R. Review of ideal binary and ratio mask estimation techniques for monaural speech separation[C]// Proceedings of the 4th International Conference on Advances in Electrical, Electronics, Information, Communication and Bio-Informatics. Piscataway: IEEE, 2018: 1-5. |
| 15 | KOLBÆK M, YU D, TAN Z H, et al. Multitalker speech separation with utterance-level permutation invariant training of deep recurrent neural networks[J]. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 2017, 25(10): 1901-1913. |
| 16 | KOLBÆK M, YU D, TAN Z H, et al. Joint separation and denoising of noisy multi-talker speech using recurrent neural networks and permutation invariant training[C]// Proceedings of the IEEE 27th International Workshop on Machine Learning for Signal Processing. Piscataway: IEEE, 2017: 1-6. |
| 17 | YU D, KOLBÆK M, TAN Z H, et al. Permutation invariant training of deep models for speaker-independent multi-talker speech separation[C]// Proceedings of the 2017 IEEE International Conference on Acoustics, Speech and Signal Processing. Piscataway: IEEE, 2017: 241-245. |
| 18 | XU C, RAO W, XIAO X, et al. Single channel speech separation with constrained utterance level permutation invariant training using grid LSTM[C]// Proceedings of the 2018 IEEE International Conference on Acoustics, Speech and Signal Processing. Piscataway: IEEE, 2018: 6-10. |
| 19 | MIN E, GUO X, LIU Q, et al. A survey of clustering with deep learning: from the perspective of network architecture[J]. IEEE Access, 2018, 6: 39501-39514. |
| 20 | CHEN Z, LUO Y, MESGARANI N. Deep attractor network for single-microphone speaker separation[C]// Proceedings of the 2017 IEEE International Conference on Acoustics, Speech and Signal Processing. Piscataway: IEEE, 2017: 246-250. |
| 21 | LUO Y, CHEN Z, MESGARANI N. Speaker-independent speech separation with deep attractor network[J]. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 2018, 26(4): 787-796. |
| 22 | 关文博. 基于孪生神经网络与深度聚类融合的语音分离研究[D]. 青岛:青岛科技大学, 2023. |
| GUAN W B. Research on speech separation based on fusion of Siamese neural network and deep clustering[D]. Qingdao: Qingdao University of Science and Technology, 2023. | |
| 23 | KAMBLE M R, TAK H, PATIL H A. Amplitude and frequency modulation-based features for detection of replay spoof speech[J]. Speech Communication, 2020, 125: 114-127. |
| 24 | MSONDA P, UYMAZ S A, KARAAĞAÇ S S. Spatial pyramid pooling in deep convolutional networks for automatic tuberculosis diagnosis[J]. Traitement du Signal, 2020, 37(6): 1075-1084. |
| 25 | QIAN C, GAO J, SHAO X, et al. Bearing fault diagnosis method based on improved deep residual Siamese neural network[J]. Insight — Non-Destructive Testing and Condition Monitoring, 2024, 66(3): 174-181. |
| 26 | STÖTER F R, LIUTKUS A, ITO N. The 2018 signal separation evaluation campaign[C]// Proceedings of the 2018 International Conference on Latent Variable Analysis and Signal Separation LNCS 10891. Cham: Springer, 2018: 293-305. |
| 27 | 葛宛营. 基于非负矩阵分解和深度聚类的语音分离研究[D]. 重庆:重庆邮电大学, 2020. |
| GE W Y. Study on speech separation based on non-negative matrix factorization and deep clustering[D]. Chongqing: Chongqing University of Posts and Telecommunications, 2020. | |
| 28 | LUO Y, MESGARANI N. Conv-TasNet: surpassing ideal time-frequency magnitude masking for speech separation[J]. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 2019, 27(8): 1256-1266. |
| 29 | WANG Z Q, LE ROUX J, HERSHEY J R. Alternative objective functions for deep clustering[C]// Proceedings of the 2018 IEEE International Conference on Acoustics, Speech and Signal Processing. Piscataway: IEEE, 2018: 686-690. |
| 30 | LUO Y, CHEN Z, HERSHEY J R, et al. Deep clustering and conventional networks for music separation: stronger together[C]// Proceedings of the 2017 IEEE International Conference on Acoustics, Speech and Signal Processing. Piscataway: IEEE, 2017: 61-65. |
| 31 | STOLLER D, EWERT S, DIXON S. Wave-U-Net: a multi-scale neural network for end-to-end audio source separation[C]// Proceedings of the 19th International Society for Music Information Retrieval Conference. [S.l.]: International Society for Music Information Retrieval, 2018: 334-340. |
| 32 | LAN C, JIANG J, ZHANG L, et al. Blind source separation based on improved Wave-U-Net network[J]. IEEE Access, 2023, 11: 125951-125958. |
| 33 | YEN Y F, SHUAI H H. Group-and-conquer for multi-speaker single-channel speech separation[C]// Proceedings of the 33rd Wireless and Optical Communications Conference. Piscataway: IEEE, 2024: 165-169. |
| 34 | HOSSAIN M I, RAHIM M A, HOSSAIN M N. Single-channel speech separation based on double-density dual-tree CWT and SNMF[J]. Annals of Emerging Technologies in Computing, 2024, 8(1): 1-12. |
| 35 | FU J, XIE Q, MENG D, et al. Rotation equivariant proximal operator for deep unfolding methods in image restoration[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2024, 46(10): 6577-6593. |
| [1] | 熊武, 曹从军, 宋雪芳, 邵云龙, 王旭升. 基于多尺度混合域注意力机制的笔迹鉴别方法[J]. 《计算机应用》唯一官方网站, 2024, 44(7): 2225-2232. |
| [2] | 孙子文, 钱立志, 杨传栋, 高一博, 陆庆阳, 袁广林. 基于Transformer的视觉目标跟踪方法综述[J]. 《计算机应用》唯一官方网站, 2024, 44(5): 1644-1654. |
| [3] | 荆智文, 张屿佳, 孙伯廷, 郭浩. 二阶段孪生图卷积神经网络推荐算法[J]. 《计算机应用》唯一官方网站, 2024, 44(2): 469-476. |
| [4] | 崔晨辉, 蔺素珍, 李大威, 禄晓飞, 武杰. 基于孪生网络和Transformer的红外弱小目标跟踪方法[J]. 《计算机应用》唯一官方网站, 2024, 44(2): 563-571. |
| [5] | 姜钧舰, 刘达维, 刘逸凡, 任酉贵, 赵志滨. 基于孪生网络的小样本目标检测算法[J]. 《计算机应用》唯一官方网站, 2023, 43(8): 2325-2329. |
| [6] | 赵元龙, 单玉刚, 袁杰, 赵康迪. 基于实例分割与毕达哥拉斯模糊决策的目标跟踪[J]. 《计算机应用》唯一官方网站, 2023, 43(6): 1930-1937. |
| [7] | 王梦亭, 杨文忠, 武雍智. 基于孪生网络的单目标跟踪算法综述[J]. 《计算机应用》唯一官方网站, 2023, 43(3): 661-673. |
| [8] | 王奇, 雷航, 王旭鹏. 姿态干扰下的深度人脸验证[J]. 《计算机应用》唯一官方网站, 2023, 43(2): 595-600. |
| [9] | 公海涛, 陈志华, 盛斌, 祝冰艳. 基于孪生网络和Transformer的小目标跟踪算法SiamTrans[J]. 《计算机应用》唯一官方网站, 2023, 43(12): 3733-3739. |
| [10] | 庄屹, 赵海涛. 面向三维点云单目标跟踪的提案聚合网络[J]. 《计算机应用》唯一官方网站, 2022, 42(5): 1407-1416. |
| [11] | 朱文球, 邹广, 曾志高. 融合层次特征和混合注意力的目标跟踪算法[J]. 《计算机应用》唯一官方网站, 2022, 42(3): 833-843. |
| [12] | 姬张建, 任兴旺. 带旋转与尺度估计的全卷积孪生网络目标跟踪算法[J]. 计算机应用, 2021, 41(9): 2705-2711. |
| [13] | 钟莎, 黄玉清. 基于孪生区域候选网络的无人机指定目标跟踪[J]. 计算机应用, 2021, 41(2): 523-529. |
| [14] | 楼豪杰, 郑元林, 廖开阳, 雷浩, 李佳. 基于Siamese-YOLOv4的印刷品缺陷目标检测[J]. 《计算机应用》唯一官方网站, 2021, 41(11): 3206-3212. |
| [15] | 李自强, 王正勇, 陈洪刚, 李林怡, 何小海. 基于外观和动作特征双预测模型的视频异常行为检测[J]. 计算机应用, 2021, 41(10): 2997-3003. |
| 阅读次数 | ||||||
|
全文 |
|
|||||
|
摘要 |
|
|||||