


《计算机应用》唯一官方网站 ›› 2025, Vol. 45 ›› Issue (6): 1712-1723.DOI: 10.11772/j.issn.1001-9081.2024070943
• 第十二届CCF大数据学术会议 • 上一篇
何玉林1,2, 李旭1( ), 贺颖婷2, 崔来中1,2, 黄哲学1,2
), 贺颖婷2, 崔来中1,2, 黄哲学1,2
收稿日期:2024-07-08
修回日期:2024-08-02
接受日期:2024-08-22
发布日期:2024-09-02
出版日期:2025-06-10
通讯作者:
李旭
作者简介:何玉林(1982—),男,河北衡水人,研究员,博士,CCF会员,主要研究方向:大数据近似计算、多样本统计、数据挖掘、机器学习基金资助:
Yulin HE1,2, Xu LI1(), Yingting HE2, Laizhong CUI1,2, Zhexue HUANG1,2
Received:2024-07-08
Revised:2024-08-02
Accepted:2024-08-22
Online:2024-09-02
Published:2025-06-10
Contact:
Xu LI
About author:HE Yulin, born in 1982, Ph. D., research fellow. His research interests include approximate computation of big data, multi-sample statistics, data mining, machine learning.Supported by:摘要:
针对高斯混合模型(GMM)聚类算法在处理大规模高维数据聚类时出现的性能受限和参数敏感的问题,提出一种基于最大均值差异(MMD)的子空间GMM聚类集成(SGMM-CE)算法。首先,对原始大规模高维数据集进行随机样本划分(RSP)以得到多个数据子集,从样本量的角度缩小聚类问题的规模;其次,根据特征对最优GMM构件数的影响,在每一个数据子集对应的高维特征空间中进行子空间学习,得到每个高维特征空间对应的多个低维特征子空间,并在各个子空间上进行GMM聚类,从而得到一系列异构的GMM;再次,利用所提出的平均共享隶属概率(ASAP),重标记与融合来自同一个数据子集的不同特征子空间上的聚类结果;最后,利用扩展的子空间MMD(SubMMD)作为不同数据子集的聚类结果中2个簇之间的分布一致性的度量准则,据此重标记并融合这些数据子集的聚类结果,进而得到原始数据集的最终聚类集成结果。通过详尽的实验验证SGMM-CE算法的有效性,实验结果显示,相较于对比算法中最好的元簇聚类算法(MCLA),SGMM-CE算法在选用的数据集上的平均标准化互信息(NMI)、聚类精度(CA)和调整兰德系数(ARI)值分别提升了19%,20%和52%。此外,可行性和合理性的实验结果证实了SGMM-CE算法的参数收敛性与时间高效性,表明该算法具备高效处理大规模高维数据聚类问题的能力。
中图分类号:
何玉林, 李旭, 贺颖婷, 崔来中, 黄哲学. 基于最大均值差异的子空间高斯混合模型聚类集成算法[J]. 计算机应用, 2025, 45(6): 1712-1723.
Yulin HE, Xu LI, Yingting HE, Laizhong CUI, Zhexue HUANG. Subspace Gaussian mixture model clustering ensemble algorithm based on maximum mean discrepancy[J]. Journal of Computer Applications, 2025, 45(6): 1712-1723.
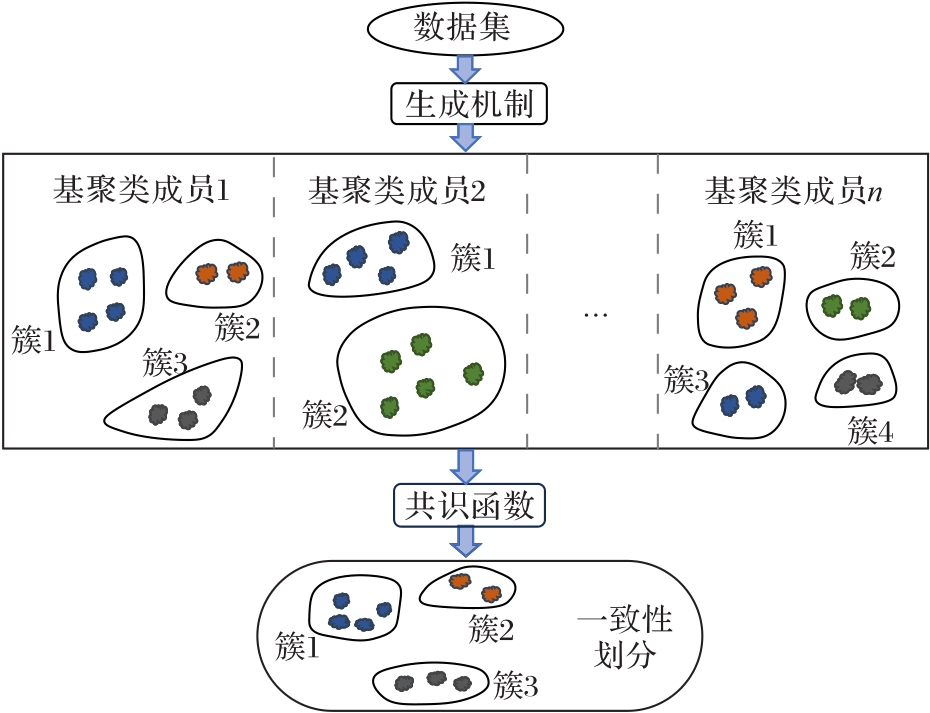
图1 聚类集成的示意图
Fig.1 Schematic diagram of clustering ensemble
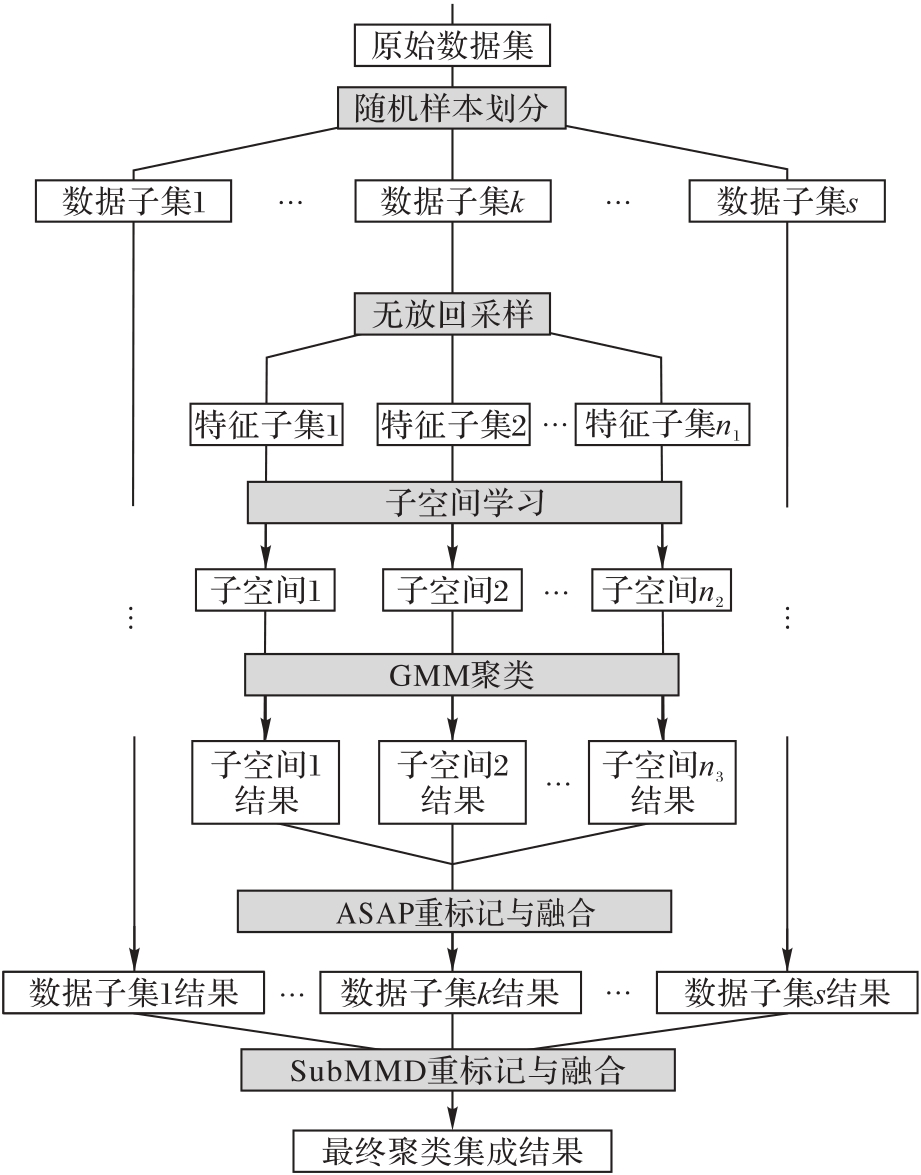
图2 SGMM-CE算法的流程
Fig.2 Flowchart of SGMM-CE algorithm
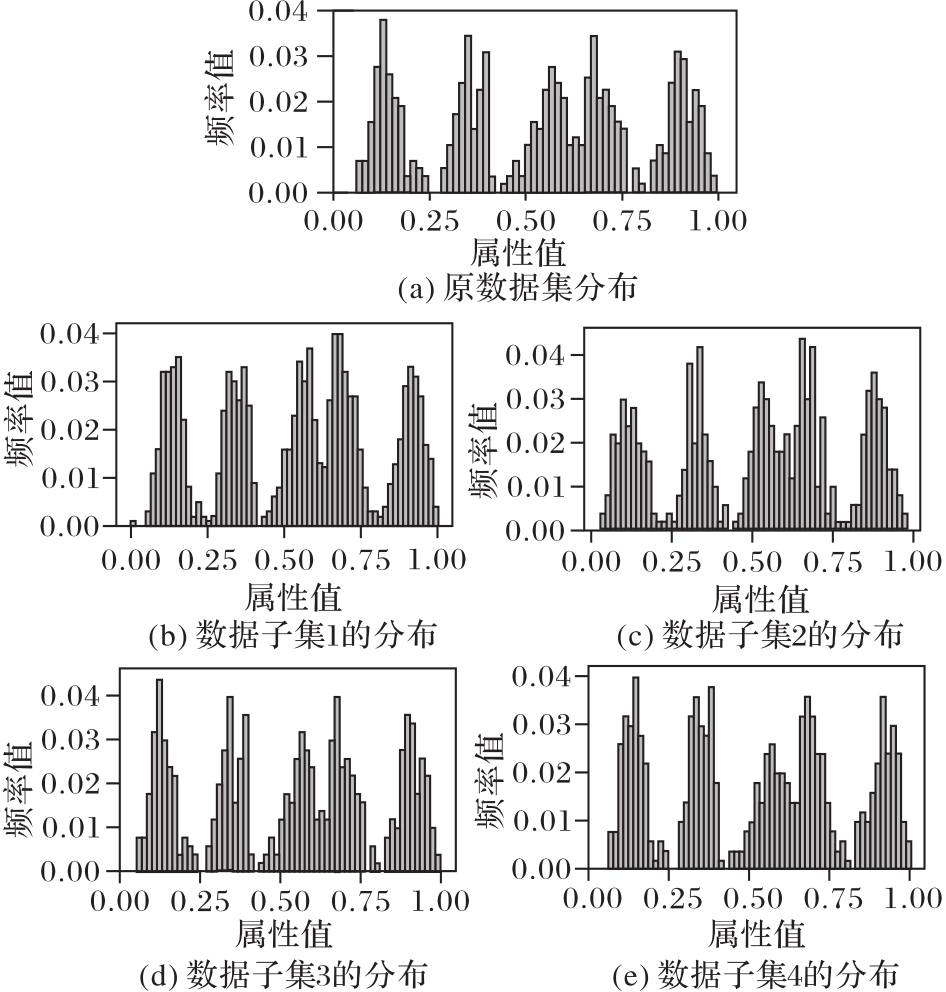
图3 RSP数据子集分布一致的示意图
Fig. 3 Schematic diagram of distribution consistency of RSP subsets of data
| 数据集 | 样本量 | 特征数 | 类别数 |
|---|---|---|---|
| Coil20 | 1 440 | 1 024 | 20 |
| MF | 2 000 | 649 | 10 |
| Lung | 203 | 3 312 | 5 |
| TOX | 171 | 5 748 | 4 |
| Semeion | 1 593 | 256 | 10 |
| Covertype | 581 012 | 54 | 7 |
| MNIST | 70 000 | 784 | 10 |
| syn_1 | 10 000 | 100 | 4 |
| syn_2 | 100 000 | 100 | 5 |
表1 数据集信息
Tab. 1 Information of datasets
| 数据集 | 样本量 | 特征数 | 类别数 |
|---|---|---|---|
| Coil20 | 1 440 | 1 024 | 20 |
| MF | 2 000 | 649 | 10 |
| Lung | 203 | 3 312 | 5 |
| TOX | 171 | 5 748 | 4 |
| Semeion | 1 593 | 256 | 10 |
| Covertype | 581 012 | 54 | 7 |
| MNIST | 70 000 | 784 | 10 |
| syn_1 | 10 000 | 100 | 4 |
| syn_2 | 100 000 | 100 | 5 |

图4 MNIST数据集上SGMM-CE算法的参数收敛性
Fig. 4 Parameter convergence of SGMM-CE algorithm on MNIST dataset

图5 聚类集成结果随参与融合数据子集组数变化的情况
Fig. 5 Clustering ensemble results varying with increasing number of subsets of data
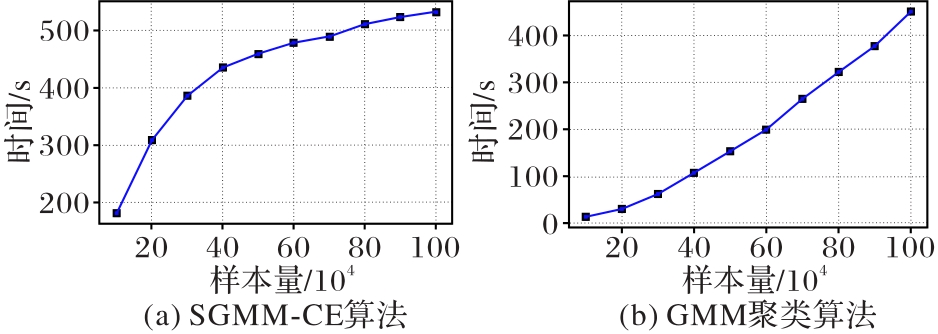
图6 样本量对算法运行时间的影响
Fig. 6 Influence of sample size on running time
| 数据集 | 数据子集组数 | 特征子集组数 | 组内特征数 |
|---|---|---|---|
| Coil20 | 3 | 10 | 150 |
| MF | 4 | 10 | 100 |
| Lung | 2 | 15 | 200 |
| TOX | 2 | 15 | 200 |
| Semeion | 3 | 5 | 100 |
| Covertype | 60 | 10 | 30 |
| MNIST | 25 | 10 | 100 |
| syn_1 | 5 | 5 | 50 |
| syn_2 | 25 | 5 | 50 |
表2 SGMM-CE算法的参数选取
Tab. 2 Parameter selection of SGMM-CE algorithm
| 数据集 | 数据子集组数 | 特征子集组数 | 组内特征数 |
|---|---|---|---|
| Coil20 | 3 | 10 | 150 |
| MF | 4 | 10 | 100 |
| Lung | 2 | 15 | 200 |
| TOX | 2 | 15 | 200 |
| Semeion | 3 | 5 | 100 |
| Covertype | 60 | 10 | 30 |
| MNIST | 25 | 10 | 100 |
| syn_1 | 5 | 5 | 50 |
| syn_2 | 25 | 5 | 50 |
评估 指标 | 数据集 | 样本量 | GMM | EAC | MCLA | HGPA | CSPA | LWEA | LWGP | CEAAE | EC-CMS | SGMM-CE |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| NMI | Coil20 | 1 440 | 0.719 8 | 0.259 7 | 0.760 2 | 0.669 2 | 0.737 1 | 0.739 7 | 0.763 2 | 0.573 1 | 0.510 6 | 0.781 3 |
| MF | 2 000 | 0.656 8 | 0.578 5 | 0.653 8 | 0.639 4 | 0.621 5 | 0.680 0 | 0.709 1 | 0.680 5 | 0.623 2 | 0.715 0 | |
| Lung | 203 | 0.522 9 | 0.474 6 | 0.543 6 | 0.533 7 | 0.577 2 | 0.684 1 | 0.670 9 | 0.755 0 | 0.553 5 | 0.672 1 | |
| TOX | 171 | 0.281 5 | 0.234 1 | 0.234 5 | 0.208 2 | 0.244 1 | 0.295 9 | 0.284 7 | 0.303 9 | 0.264 6 | 0.306 6 | |
| Semeion | 1 593 | 0.628 6 | 0.517 5 | 0.589 2 | 0.601 3 | 0.533 3 | 0.643 4 | 0.642 8 | 0.603 7 | 0.581 2 | 0.642 0 | |
| Covertype | 35 000 | 0.174 8 | 0.144 7 | 0.110 3 | 0.092 4 | 0.073 4 | 0.168 2 | 0.172 9 | 0.148 2 | 0.139 8 | 0.186 2 | |
| 45 000 | 0.171 5 | 0.144 1 | 0.102 5 | 0.090 8 | N/A | N/A | N/A | 0.150 1 | 0.142 6 | 0.184 7 | ||
| 581 012 | 0.168 9 | N/A | 0.099 8 | 0.089 2 | N/A | N/A | N/A | N/A | N/A | 0.180 2 | ||
| MNIST | 35 000 | 0.687 9 | 0.541 1 | 0.574 9 | 0.663 9 | 0.585 1 | 0.691 4 | 0.685 7 | 0.673 2 | 0.625 7 | 0.696 0 | |
| 40 000 | 0.690 3 | 0.537 4 | 0.583 5 | 0.659 1 | 0.587 2 | N/A | N/A | 0.660 8 | 0.630 1 | 0.714 3 | ||
| 70 000 | 0.698 4 | N/A | 0.606 8 | 0.668 5 | N/A | N/A | N/A | N/A | N/A | 0.720 7 | ||
| syn_1 | 5 000 | 0.802 7 | 0.584 0 | 0.852 7 | 0.603 4 | 0.637 0 | 0.696 0 | 0.701 8 | 0.693 1 | 0.629 5 | 0.894 6 | |
| 10 000 | 0.814 3 | 0.647 0 | 0.683 5 | 0.542 0 | 0.573 9 | 0.703 0 | 0.809 3 | 0.695 7 | 0.634 8 | 0.849 3 | ||
| syn_2 | 50 000 | 0.819 4 | 0.648 5 | 0.689 0 | 0.537 6 | N/A | N/A | N/A | 0.719 1 | 0.784 0 | 0.851 0 | |
| 100 000 | 0.820 6 | 0.619 4 | 0.691 4 | 0.550 3 | N/A | N/A | N/A | N/A | N/A | 0.837 9 | ||
| CA | Coil20 | 1 440 | 0.539 5 | 0.100 0 | 0.655 4 | 0.549 2 | 0.637 9 | 0.594 1 | 0.648 8 | 0.503 5 | 0.518 4 | 0.656 1 |
| MF | 2 000 | 0.595 2 | 0.538 4 | 0.603 1 | 0.590 0 | 0.579 6 | 0.623 9 | 0.630 2 | 0.603 8 | 0.514 3 | 0.738 2 | |
| Lung | 203 | 0.596 0 | 0.523 2 | 0.678 5 | 0.585 0 | 0.612 3 | 0.703 2 | 0.699 0 | 0.924 6 | 0.663 6 | 0.767 3 | |
| TOX | 171 | 0.498 4 | 0.480 7 | 0.479 2 | 0.455 6 | 0.487 1 | 0.523 8 | 0.510 0 | 0.609 3 | 0.497 3 | 0.619 0 | |
| Semeion | 1 593 | 0.666 7 | 0.579 1 | 0.640 0 | 0.649 2 | 0.584 3 | 0.683 5 | 0.686 9 | 0.630 1 | 0.587 0 | 0.692 1 | |
| Covertype | 35 000 | 0.520 1 | 0.427 1 | 0.393 7 | 0.371 5 | 0.328 1 | 0.496 0 | 0.512 0 | 0.446 1 | 0.421 6 | 0.535 5 | |
| 45 000 | 0.519 6 | 0.419 6 | 0.391 6 | 0.370 4 | N/A | N/A | N/A | 0.446 7 | 0.435 5 | 0.528 5 | ||
| 581 012 | 0.516 0 | N/A | 0.390 0 | 0.369 4 | N/A | N/A | N/A | N/A | N/A | 0.524 6 | ||
| MNIST | 35 000 | 0.865 8 | 0.769 3 | 0.752 8 | 0.538 5 | 0.760 0 | 0.876 1 | 0.874 0 | 0.873 8 | 0.805 4 | 0.876 4 | |
| 40 000 | 0.869 2 | 0.754 5 | 0.762 7 | 0.524 5 | 0.758 3 | N/A | N/A | 0.872 5 | 0.809 8 | 0.869 0 | ||
| 70 000 | 0.873 2 | N/A | 0.769 8 | 0.537 4 | N/A | N/A | N/A | N/A | N/A | 0.874 7 | ||
| syn_1 | 5 000 | 0.683 7 | 0.528 5 | 0.728 6 | 0.803 6 | 0.523 5 | 0.563 7 | 0.570 5 | 0.559 4 | 0.537 2 | 0.906 4 | |
| 10 000 | 0.696 3 | 0.611 7 | 0.657 4 | 0.469 3 | 0.579 4 | 0.710 3 | 0.701 7 | 0.560 0 | 0.54 | 0.861 9 | ||
| syn_2 | 50 000 | 0.701 4 | 0.610 0 | 0.658 3 | 0.468 0 | N/A | N/A | N/A | 0.679 3 | 0.693 2 | 0.819 4 | |
| 100 000 | 0.703 5 | 0.614 4 | 0.655 0 | 0.471 0 | N/A | N/A | N/A | N/A | N/A | 0.803 0 | ||
| ARI | Coil20 | 1 440 | 0.271 7 | 0.035 1 | 0.432 0 | 0.168 0 | 0.190 0 | 0.459 2 | 0.371 5 | 0.123 9 | 0.148 3 | 0.471 0 |
| MF | 2 000 | 0.418 9 | 0.311 9 | 0.433 5 | 0.323 0 | 0.417 6 | 0.327 0 | 0.455 2 | 0.346 0 | 0.367 0 | 0.445 9 | |
| Lung | 203 | 0.150 5 | 0.101 9 | 0.318 2 | 0.153 0 | 0.193 1 | 0.404 3 | 0.403 6 | 0.740 3 | 0.314 8 | 0.566 7 | |
| TOX | 171 | 0.206 2 | 0.164 6 | 0.162 4 | 0.158 3 | 0.168 5 | 0.209 8 | 0.217 7 | 0.220 6 | 0.181 0 | 0.223 2 | |
| Semeion | 1 593 | 0.466 7 | 0.345 5 | 0.461 8 | 0.348 7 | 0.413 5 | 0.542 0 | 0.537 1 | 0.404 5 | 0.353 1 | 0.550 8 | |
| Covertype | 35 000 | 0.614 7 | 0.564 2 | 0.448 5 | 0.441 6 | 0.414 7 | 0.599 8 | 0.610 1 | 0.570 3 | 0.567 7 | 0.632 5 | |
| 45 000 | 0.613 8 | 0.561 3 | 0.443 7 | 0.428 5 | N/A | N/A | N/A | 0.570 6 | 0.569 8 | 0.629 1 | ||
| 581 012 | 0.609 4 | N/A | 0.439 9 | 0.421 6 | N/A | N/A | N/A | N/A | N/A | 0.625 7 | ||
| MNIST | 35 000 | 0.747 5 | 0.118 7 | 0.124 9 | 0.158 4 | 0.119 4 | 0.754 0 | 0.749 5 | 0.745 0 | 0.671 9 | 0.763 6 | |
| 40 000 | 0.749 2 | 0.112 3 | 0.126 0 | 0.160 0 | 0.120 6 | N/A | N/A | 0.745 2 | 0.670 5 | 0.755 7 | ||
| 70 000 | 0.754 3 | N/A | 0.125 3 | 0.183 7 | N/A | N/A | N/A | N/A | N/A | 0.760 0 | ||
| syn_1 | 5 000 | 0.658 2 | 0.350 8 | 0.807 9 | 0.693 0 | 0.573 8 | 0.747 3 | 0.750 4 | 0.736 0 | 0.586 5 | 0.827 5 | |
| 10 000 | 0.653 7 | 0.642 9 | 0.677 0 | 0.338 6 | 0.424 7 | 0.641 3 | 0.649 2 | 0.735 8 | 0.591 3 | 0.809 4 | ||
| syn_2 | 50 000 | 0.655 0 | 0.651 0 | 0.673 2 | 0.340 0 | N/A | N/A | N/A | 0.663 7 | 0.653 9 | 0.809 3 | |
| 100 000 | 0.652 7 | 0.669 4 | 0.674 7 | 0.338 6 | N/A | N/A | N/A | N/A | N/A | 0.813 4 |
表3 聚类结果的对比
Tab.3 Comparison of clustering results
评估 指标 | 数据集 | 样本量 | GMM | EAC | MCLA | HGPA | CSPA | LWEA | LWGP | CEAAE | EC-CMS | SGMM-CE |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| NMI | Coil20 | 1 440 | 0.719 8 | 0.259 7 | 0.760 2 | 0.669 2 | 0.737 1 | 0.739 7 | 0.763 2 | 0.573 1 | 0.510 6 | 0.781 3 |
| MF | 2 000 | 0.656 8 | 0.578 5 | 0.653 8 | 0.639 4 | 0.621 5 | 0.680 0 | 0.709 1 | 0.680 5 | 0.623 2 | 0.715 0 | |
| Lung | 203 | 0.522 9 | 0.474 6 | 0.543 6 | 0.533 7 | 0.577 2 | 0.684 1 | 0.670 9 | 0.755 0 | 0.553 5 | 0.672 1 | |
| TOX | 171 | 0.281 5 | 0.234 1 | 0.234 5 | 0.208 2 | 0.244 1 | 0.295 9 | 0.284 7 | 0.303 9 | 0.264 6 | 0.306 6 | |
| Semeion | 1 593 | 0.628 6 | 0.517 5 | 0.589 2 | 0.601 3 | 0.533 3 | 0.643 4 | 0.642 8 | 0.603 7 | 0.581 2 | 0.642 0 | |
| Covertype | 35 000 | 0.174 8 | 0.144 7 | 0.110 3 | 0.092 4 | 0.073 4 | 0.168 2 | 0.172 9 | 0.148 2 | 0.139 8 | 0.186 2 | |
| 45 000 | 0.171 5 | 0.144 1 | 0.102 5 | 0.090 8 | N/A | N/A | N/A | 0.150 1 | 0.142 6 | 0.184 7 | ||
| 581 012 | 0.168 9 | N/A | 0.099 8 | 0.089 2 | N/A | N/A | N/A | N/A | N/A | 0.180 2 | ||
| MNIST | 35 000 | 0.687 9 | 0.541 1 | 0.574 9 | 0.663 9 | 0.585 1 | 0.691 4 | 0.685 7 | 0.673 2 | 0.625 7 | 0.696 0 | |
| 40 000 | 0.690 3 | 0.537 4 | 0.583 5 | 0.659 1 | 0.587 2 | N/A | N/A | 0.660 8 | 0.630 1 | 0.714 3 | ||
| 70 000 | 0.698 4 | N/A | 0.606 8 | 0.668 5 | N/A | N/A | N/A | N/A | N/A | 0.720 7 | ||
| syn_1 | 5 000 | 0.802 7 | 0.584 0 | 0.852 7 | 0.603 4 | 0.637 0 | 0.696 0 | 0.701 8 | 0.693 1 | 0.629 5 | 0.894 6 | |
| 10 000 | 0.814 3 | 0.647 0 | 0.683 5 | 0.542 0 | 0.573 9 | 0.703 0 | 0.809 3 | 0.695 7 | 0.634 8 | 0.849 3 | ||
| syn_2 | 50 000 | 0.819 4 | 0.648 5 | 0.689 0 | 0.537 6 | N/A | N/A | N/A | 0.719 1 | 0.784 0 | 0.851 0 | |
| 100 000 | 0.820 6 | 0.619 4 | 0.691 4 | 0.550 3 | N/A | N/A | N/A | N/A | N/A | 0.837 9 | ||
| CA | Coil20 | 1 440 | 0.539 5 | 0.100 0 | 0.655 4 | 0.549 2 | 0.637 9 | 0.594 1 | 0.648 8 | 0.503 5 | 0.518 4 | 0.656 1 |
| MF | 2 000 | 0.595 2 | 0.538 4 | 0.603 1 | 0.590 0 | 0.579 6 | 0.623 9 | 0.630 2 | 0.603 8 | 0.514 3 | 0.738 2 | |
| Lung | 203 | 0.596 0 | 0.523 2 | 0.678 5 | 0.585 0 | 0.612 3 | 0.703 2 | 0.699 0 | 0.924 6 | 0.663 6 | 0.767 3 | |
| TOX | 171 | 0.498 4 | 0.480 7 | 0.479 2 | 0.455 6 | 0.487 1 | 0.523 8 | 0.510 0 | 0.609 3 | 0.497 3 | 0.619 0 | |
| Semeion | 1 593 | 0.666 7 | 0.579 1 | 0.640 0 | 0.649 2 | 0.584 3 | 0.683 5 | 0.686 9 | 0.630 1 | 0.587 0 | 0.692 1 | |
| Covertype | 35 000 | 0.520 1 | 0.427 1 | 0.393 7 | 0.371 5 | 0.328 1 | 0.496 0 | 0.512 0 | 0.446 1 | 0.421 6 | 0.535 5 | |
| 45 000 | 0.519 6 | 0.419 6 | 0.391 6 | 0.370 4 | N/A | N/A | N/A | 0.446 7 | 0.435 5 | 0.528 5 | ||
| 581 012 | 0.516 0 | N/A | 0.390 0 | 0.369 4 | N/A | N/A | N/A | N/A | N/A | 0.524 6 | ||
| MNIST | 35 000 | 0.865 8 | 0.769 3 | 0.752 8 | 0.538 5 | 0.760 0 | 0.876 1 | 0.874 0 | 0.873 8 | 0.805 4 | 0.876 4 | |
| 40 000 | 0.869 2 | 0.754 5 | 0.762 7 | 0.524 5 | 0.758 3 | N/A | N/A | 0.872 5 | 0.809 8 | 0.869 0 | ||
| 70 000 | 0.873 2 | N/A | 0.769 8 | 0.537 4 | N/A | N/A | N/A | N/A | N/A | 0.874 7 | ||
| syn_1 | 5 000 | 0.683 7 | 0.528 5 | 0.728 6 | 0.803 6 | 0.523 5 | 0.563 7 | 0.570 5 | 0.559 4 | 0.537 2 | 0.906 4 | |
| 10 000 | 0.696 3 | 0.611 7 | 0.657 4 | 0.469 3 | 0.579 4 | 0.710 3 | 0.701 7 | 0.560 0 | 0.54 | 0.861 9 | ||
| syn_2 | 50 000 | 0.701 4 | 0.610 0 | 0.658 3 | 0.468 0 | N/A | N/A | N/A | 0.679 3 | 0.693 2 | 0.819 4 | |
| 100 000 | 0.703 5 | 0.614 4 | 0.655 0 | 0.471 0 | N/A | N/A | N/A | N/A | N/A | 0.803 0 | ||
| ARI | Coil20 | 1 440 | 0.271 7 | 0.035 1 | 0.432 0 | 0.168 0 | 0.190 0 | 0.459 2 | 0.371 5 | 0.123 9 | 0.148 3 | 0.471 0 |
| MF | 2 000 | 0.418 9 | 0.311 9 | 0.433 5 | 0.323 0 | 0.417 6 | 0.327 0 | 0.455 2 | 0.346 0 | 0.367 0 | 0.445 9 | |
| Lung | 203 | 0.150 5 | 0.101 9 | 0.318 2 | 0.153 0 | 0.193 1 | 0.404 3 | 0.403 6 | 0.740 3 | 0.314 8 | 0.566 7 | |
| TOX | 171 | 0.206 2 | 0.164 6 | 0.162 4 | 0.158 3 | 0.168 5 | 0.209 8 | 0.217 7 | 0.220 6 | 0.181 0 | 0.223 2 | |
| Semeion | 1 593 | 0.466 7 | 0.345 5 | 0.461 8 | 0.348 7 | 0.413 5 | 0.542 0 | 0.537 1 | 0.404 5 | 0.353 1 | 0.550 8 | |
| Covertype | 35 000 | 0.614 7 | 0.564 2 | 0.448 5 | 0.441 6 | 0.414 7 | 0.599 8 | 0.610 1 | 0.570 3 | 0.567 7 | 0.632 5 | |
| 45 000 | 0.613 8 | 0.561 3 | 0.443 7 | 0.428 5 | N/A | N/A | N/A | 0.570 6 | 0.569 8 | 0.629 1 | ||
| 581 012 | 0.609 4 | N/A | 0.439 9 | 0.421 6 | N/A | N/A | N/A | N/A | N/A | 0.625 7 | ||
| MNIST | 35 000 | 0.747 5 | 0.118 7 | 0.124 9 | 0.158 4 | 0.119 4 | 0.754 0 | 0.749 5 | 0.745 0 | 0.671 9 | 0.763 6 | |
| 40 000 | 0.749 2 | 0.112 3 | 0.126 0 | 0.160 0 | 0.120 6 | N/A | N/A | 0.745 2 | 0.670 5 | 0.755 7 | ||
| 70 000 | 0.754 3 | N/A | 0.125 3 | 0.183 7 | N/A | N/A | N/A | N/A | N/A | 0.760 0 | ||
| syn_1 | 5 000 | 0.658 2 | 0.350 8 | 0.807 9 | 0.693 0 | 0.573 8 | 0.747 3 | 0.750 4 | 0.736 0 | 0.586 5 | 0.827 5 | |
| 10 000 | 0.653 7 | 0.642 9 | 0.677 0 | 0.338 6 | 0.424 7 | 0.641 3 | 0.649 2 | 0.735 8 | 0.591 3 | 0.809 4 | ||
| syn_2 | 50 000 | 0.655 0 | 0.651 0 | 0.673 2 | 0.340 0 | N/A | N/A | N/A | 0.663 7 | 0.653 9 | 0.809 3 | |
| 100 000 | 0.652 7 | 0.669 4 | 0.674 7 | 0.338 6 | N/A | N/A | N/A | N/A | N/A | 0.813 4 |
| 1 | SAXENA A, PRASAD M, GUPTA A, et al. A review of clustering techniques and developments[J]. Neurocomputing, 2017, 267: 664-681. |
| 2 | GOLALIPOUR K, AKBARI E, HAMIDI S S, et al. From clustering to clustering ensemble selection: a review[J]. Engineering Applications of Artificial Intelligence, 2021, 104: No.104388. |
| 3 | AHMED M, SERAJ R, ISLAM S M S. The k-means algorithm: a comprehensive survey and performance evaluation[J]. Electronics, 2020, 9(8): No.1295. |
| 4 | McLACHLAN G L, BASFORD K E. Mixture models: inference and applications to clustering [M]. New York: Marcel Dekker, 1988: 337-338. |
| 5 | BOUKERCHE A, ZHENG L, ALFANDI O. Outlier detection: methods, models, and classification [J]. ACM Computing Survey, 2021, 53(3): No.55. |
| 6 | CHADDAD A. Automated feature extraction in brain tumor by magnetic resonance imaging using Gaussian mixture models[J]. International Journal of Biomedical Imaging, 2015, 2015: No.868031. |
| 7 | VIROLI C, McLACHLAN G J. Deep Gaussian mixture models [J]. Statistics and Computing, 2019, 29: 43-51. |
| 8 | 章永来,周耀鉴. 聚类算法综述[J]. 计算机应用, 2019, 39(7): 1869-1882. |
| ZHANG Y L, ZHOU Y J. Review of clustering algorithms [J]. Journal of Computer Applications, 2019, 39(7): 1869-1882. | |
| 9 | ZHU X, GOLDBERG A B. Introduction to semi-supervised learning, SLAIML [M]. Cham: Springer, 2009. |
| 10 | 王爱平,张功营,刘方. EM算法研究与应用[J].计算机技术与发展, 2009, 19(9): 108-110. |
| WANG A P, ZHANG G Y, LIU F. Research and application of EM algorithm[J]. Computer Technology and Development, 2009, 19(9): 108-110. | |
| 11 | BOUVEYRON C, BRUNET-SAUMARD C. Model-based clustering of high-dimensional data: a review [J]. Computational Statistics and Data Analysis, 2014, 71: 52-78. |
| 12 | WANG D, GUO X, LI S, et al. Robust high dimensional expectation maximization algorithm via trimmed hard thresholding[J]. Machine Learning, 2020, 109(12): 2283-2311. |
| 13 | PRZYBOROWSKI M, ŚLĘZAK D. Approximation of the expectation-maximization algorithm for Gaussian mixture models on big data[C]// Proceedings of the 2022 IEEE International Conference on Big Data. Piscataway: IEEE, 2022: 6256-6260. |
| 14 | GRETTON A, BORGWARDT K M, RASCH M J, et al. A kernel two-sample test[J]. Journal of Machine Learning Research, 2012, 13: 723-773. |
| 15 | HE Y, HE Y, ZHAN Z, et al. A novel subspace-based GMM clustering ensemble algorithm for high-dimensional data[J]. Chinese Journal of Electronics, 2025, 34(2): 612-629. |
| 16 | SALLOUM S, HUANG J Z, HE Y. Random sample partition: a distributed data model for big data analysis [J]. IEEE Transactions on Industrial Informatics, 2019, 15(11): 5846-5854. |
| 17 | HUANG D, WANG C D, LAI J H. Locally weighted ensemble clustering [J]. IEEE Transactions on Cybernetics, 2018, 48(5): 1460-1473. |
| 18 | YANG W, ZHANG Y, WANG H, et al. Hybrid genetic model for clustering ensemble [J]. Knowledge-Based Systems, 2021, 231: No.107457. |
| 19 | BAGHERINIA A, MINAEI-BIDGOLI B, HOSSEINZADEH M, et al. Reliability-based fuzzy clustering ensemble [J]. Fuzzy Sets and Systems, 2021, 413: 1-28. |
| 20 | DU X, HE Y, HUANG J Z. Random sample partition-based clustering ensemble algorithm for big data [C]// Proceedings of the 2021 IEEE International Conference on Big Data. Piscataway: IEEE, 2021: 5885-5887. |
| 21 | JI S, XING R. Clustering ensemble of massive data based on trusted region[C]// Proceedings of the 3rd International Conference on Machine Learning, Big Data and Business Intelligence. Piscataway: IEEE, 2021: 337-340. |
| 22 | HE S, LI H, GUO Q, et al. Feature weighted dual random sampling cluster ensemble[C]// Proceedings of the 5th International Conference on Machine Learning and Soft Computing. New York: ACM, 2021: 54-59. |
| 23 | ANDERLUCCI L, FORTUNATO F, MONTANARI A. High-dimensional clustering via random projections [J]. Journal of Classification, 2022, 39(1): 191-216. |
| 24 | FRED A L N, JAIN A K. Combining multiple clusterings using evidence accumulation [J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2005, 27(6): 835-850. |
| 25 | LIU H, WU J, LIU T, et al. Spectral ensemble clustering via weighted K-means: theoretical and practical evidence[J]. IEEE Transactions on Knowledge and Data Engineering, 2017, 29(5): 1129-1143. |
| 26 | JI X, LIU S, YANG L, et al. Clustering ensemble based on approximate accuracy of the equivalence granularity [J]. Applied Soft Computing, 2022, 129: No.109492. |
| 27 | JIA Y, TAO S, WANG R, et al. Ensemble clustering via co-association matrix self-enhancement[J]. IEEE Transactions on Neural Networks and Learning Systems, 2024, 35(8): 11168-11179. |
| 28 | STREHL A, GHOSH J. Cluster ensembles — a knowledge reuse framework for combining multiple partitions[J]. Journal of Machine Learning Research, 2002, 3: 583-617. |
| 29 | HUANG D, WANG C D, LAI J H. LWMC: a locally weighted meta-clustering algorithm for ensemble clustering [C]// Proceedings of the 2017 International Conference on Neural Information Processing, LNCS 10638. Cham: Springer, 2017: 167-176. |
| 30 | HAMIDI S S, AKBARI E, MOTAMENI H. Consensus clustering algorithm based on the automatic partitioning similarity graph [J]. Data and Knowledge Engineering, 2019, 124: No.101754. |
| 31 | WANG L, LUO J, WANG H, et al. Markov clustering ensemble[J]. Knowledge-Based Systems, 2022, 251: No.109196. |
| 32 | ZHOU P, DU L, LI X. Self-paced consensus clustering with bipartite graph[C]// Proceedings of the 29th International Joint Conferences on Artificial Intelligence. California: ijcai.org, 2020: 2133-2139. |
| 33 | DUDOIT S, FRIDLYAND J. Bagging to improve the accuracy of a clustering procedure[J]. Bioinformatics, 2003, 19(9): 1090-1099. |
| 34 | KUHN H W. The Hungarian method for the assignment problem[J]. Naval Research Logistics Quarterly, 1955, 2(1/2): 83-97. |
| 35 | ZHOU Z H, TANG W. Clusterer ensemble [J]. Knowledge-Based Systems, 2006, 19(1): 77-83. |
| 36 | KHEDAIRIA S, KHADIR M T. A multiple clustering combination approach based on iterative voting process[J]. Journal of King Saud University — Computer and Information Sciences, 2022, 34(1): 1370-1380. |
| 37 | BURTON R J, CUFF S M, MORGAN M P, et al. GeoWaVe: geometric median clustering with weighted voting for ensemble clustering of cytometry data [J]. Bioinformatics, 2023, 39(1): No.btac751. |
| 38 | TOPCHY A, JAIN A K, PUNCH W. A mixture model for clustering ensembles[C]// Proceedings of the 2004 SIAM International Conference on Data Mining. Philadelphia, PA: SIAM, 2004: 379-390. |
| 39 | TUMER K, AGOGINO A K. Ensemble clustering with voting active clusters [J]. Pattern Recognition Letters, 2008, 29(14): 1947-1953. |
| 40 | ZHONG Y, WANG H, YANG W, et al. Multi-objective genetic model for co-clustering ensemble[J]. Applied Soft Computing, 2023, 135: No.110058. |
| 41 | RUAN L, YUAN M, ZOU H. Regularized parameter estimation in high-dimensional Gaussian mixture models[J]. Neural Computation, 2011, 23(6): 1605-1622. |
| 42 | ZHAO Y, SHRIVASTAVA A K, TSUI K L. Regularized Gaussian mixture model for high-dimensional clustering[J]. IEEE Transactions on Cybernetics, 2019, 49(10): 3677-3688. |
| 43 | BIERNACKI C, CELEUX G, GOVAERT G. Choosing starting values for the EM algorithm for getting the highest likelihood in multivariate Gaussian mixture models [J]. Computational Statistics and Data Analysis, 2003, 41(3/4): 561-575. |
| 44 | MAITRA R. Initializing partition-optimization algorithms[J]. IEEE/ACM Transactions on Computational Biology and Bioinformatics, 2009, 6(1): 144-157. |
| 45 | MICHAEL S, MELNYKOV V. An effective strategy for initializing the EM algorithm in finite mixture models [J]. Advances in Data Analysis and Classification, 2016, 10(4): 563-583. |
| 46 | MELNYKOV V, MELNYKOV I. Initializing the EM algorithm in Gaussian mixture models with an unknown number of components[J]. Computational Statistics and Data Analysis, 2012, 56(6): 1381-1395. |
| 47 | PANIĆ B, KLEMENC J, NAGODE M. Improved initialization of the EM algorithm for mixture model parameter estimation[J]. Mathematics, 2020, 8(3): No.373. |
| 48 | GIONIS A, MANNILA H, TSAPARAS P. Clustering aggregation[J]. ACM Transactions on Knowledge Discovery from Data, 2007, 1(1): No.4-es. |
| 49 | AGRAWAL R, GEHRKE J, GUNOPULOS D, et al. Automatic subspace clustering of high dimensional data for data mining applications[C]// Proceedings of the 1998 ACM SIGMOD International Conference on Management of Data. New York: ACM, 1998: 94-105. |
| 50 | LI T, DING C, JORDAN M I. Solving consensus and semi-supervised clustering problems using nonnegative matrix factorization[C]// Proceedings of the 7th IEEE International Conference on Data Mining. Piscataway: IEEE, 2007: 577-582. |
| 51 | YUAN C, YANG H. Research on K-value selection method of K-means clustering algorithm[J]. J — Multidisciplinary Scientific Journal, 2019, 2(2): 226-235. |
| 52 | IDRUS A, TARIHORAN N, SUPRIATNA U, et al. Distance analysis measuring for clustering using K-Means and Davies Bouldin Index algorithm [J]. TEM Journal, 2022, 11(4): 1871-1876. |
| [1] | 王文鹏, 秦寅畅, 师文轩. 工业缺陷检测无监督深度学习方法综述[J]. 《计算机应用》唯一官方网站, 2025, 45(5): 1658-1670. |
| [2] | 潘理虎, 彭守信, 张睿, 薛之洋, 毛旭珍. 面向运动前景区域的视频异常检测[J]. 《计算机应用》唯一官方网站, 2025, 45(4): 1300-1309. |
| [3] | 安俊秀, 杨林旺, 柳源. 基于邻近性语义感知的无监督文本风格迁移[J]. 《计算机应用》唯一官方网站, 2025, 45(4): 1139-1147. |
| [4] | 陈瑞龙, 胡涛, 卜佑军, 伊鹏, 胡先君, 乔伟. 面向加密恶意流量检测模型的堆叠集成对抗防御方法[J]. 《计算机应用》唯一官方网站, 2025, 45(3): 864-871. |
| [5] | 洪梓榕, 包广清. 基于集成学习的雷达自动目标识别综述[J]. 《计算机应用》唯一官方网站, 2025, 45(2): 371-382. |
| [6] | 贾洁茹, 杨建超, 张硕蕊, 闫涛, 陈斌. 基于自蒸馏视觉Transformer的无监督行人重识别[J]. 《计算机应用》唯一官方网站, 2024, 44(9): 2893-2902. |
| [7] | 夏吾吉, 黄鹤鸣, 更藏措毛, 范玉涛. 基于无监督学习和监督学习的抽取式文本摘要综述[J]. 《计算机应用》唯一官方网站, 2024, 44(4): 1035-1048. |
| [8] | 江锐, 刘威, 陈成, 卢涛. 非对称端到端的无监督图像去雨网络[J]. 《计算机应用》唯一官方网站, 2024, 44(3): 922-930. |
| [9] | 王星, 刘贵娟, 陈志豪. 高斯混合模型与文本图卷积网络结合的虚假评论识别算法[J]. 《计算机应用》唯一官方网站, 2024, 44(2): 360-368. |
| [10] | 胡能兵, 蔡彪, 李旭, 曹旦华. 基于图池化对比学习的图分类方法[J]. 《计算机应用》唯一官方网站, 2024, 44(11): 3327-3334. |
| [11] | 赵培, 乔焰, 胡荣耀, 袁新宇, 李敏悦, 张本初. 基于多域特征提取的多变量时间序列异常检测[J]. 《计算机应用》唯一官方网站, 2024, 44(11): 3419-3426. |
| [12] | 龙杰, 谢良, 徐海蛟. 集成的深度强化学习投资组合模型[J]. 《计算机应用》唯一官方网站, 2024, 44(1): 300-310. |
| [13] | 黄梦林, 段磊, 张袁昊, 王培妍, 李仁昊. 基于Prompt学习的无监督关系抽取模型[J]. 《计算机应用》唯一官方网站, 2023, 43(7): 2010-2016. |
| [14] | 许喆, 王志宏, 单存宇, 孙亚茹, 杨莹. 基于重构误差的无监督人脸伪造视频检测[J]. 《计算机应用》唯一官方网站, 2023, 43(5): 1571-1577. |
| [15] | 葛孟婷, 万鸣华. 基于近邻监督局部不变鲁棒主成分分析的特征提取模型[J]. 《计算机应用》唯一官方网站, 2023, 43(4): 1013-1020. |
| 阅读次数 | ||||||
|
全文 |
|
|||||
|
摘要 |
|
|||||