


《计算机应用》唯一官方网站 ›› 2025, Vol. 45 ›› Issue (6): 1703-1711.DOI: 10.11772/j.issn.1001-9081.2024060883
• 第十二届CCF大数据学术会议 •
崔双双, 王宏志( ), 朱加昊, 吴昊
), 朱加昊, 吴昊
收稿日期:2024-06-28
修回日期:2024-08-16
接受日期:2024-08-20
发布日期:2024-11-08
出版日期:2025-06-10
通讯作者:
王宏志
作者简介:崔双双(1997—),女,黑龙江哈尔滨人,博士研究生,CCF会员,主要研究方向:数据库、查询优化基金资助:
Shuangshuang CUI, Hongzhi WANG(), Jiahao ZHU, Hao WU
Received:2024-06-28
Revised:2024-08-16
Accepted:2024-08-20
Online:2024-11-08
Published:2025-06-10
Contact:
Hongzhi WANG
About author:CUI Shuangshuang, born in 1997, Ph. D. candidate. Her research interests include database, query optimization.Supported by:摘要:
针对利用海量数据构建分类模型时训练数据规模大、训练时间长且碳排放量大的问题,提出面向低能耗高性能的分类器两阶段数据选择方法TSDS (Two-Stage Data Selection)。首先,通过修正余弦相似度确定聚类中心,并将样本数据进行基于不相似点的分裂层次聚类;其次,对聚类结果按数据分布自适应抽样以组成高质量的子样本集;最后,利用子样本集在分类模型上训练,在加速训练过程的同时提升模型精度。在Spambase、Bupa和Phoneme等6个数据集上构建支持向量机(SVM)和多层感知机(MLP)分类模型,验证TSDS的性能。实验结果表明在样本数据压缩比达到85.00%的情况下,TSDS能将分类模型准确率提升3~10个百分点,同时加速模型训练,使训练SVM分类器的能耗平均降低93.76%,训练MLP分类器的能耗平均降低75.41%。可见,TSDS在大数据场景的分类任务上既能缩短训练时间和减少能耗,又能提升分类器性能,从而助力实现“双碳”目标。
中图分类号:
崔双双, 王宏志, 朱加昊, 吴昊. 面向低能耗高性能的分类器两阶段数据选择方法[J]. 计算机应用, 2025, 45(6): 1703-1711.
Shuangshuang CUI, Hongzhi WANG, Jiahao ZHU, Hao WU. Two-stage data selection method for classifier with low energy consumption and high performance[J]. Journal of Computer Applications, 2025, 45(6): 1703-1711.

图1 TSDS的框架
Fig. 1 Framework of TSDS
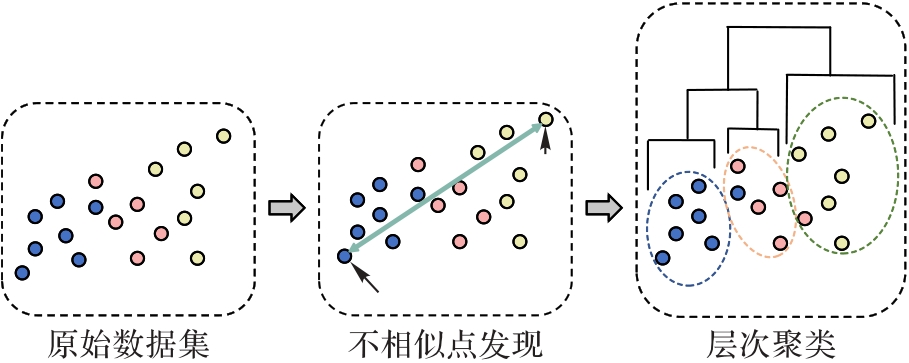
图2 基于不相似点的分裂层次聚类算法
Fig.2 Split hierarchical clustering algorithm based on dissimilar points
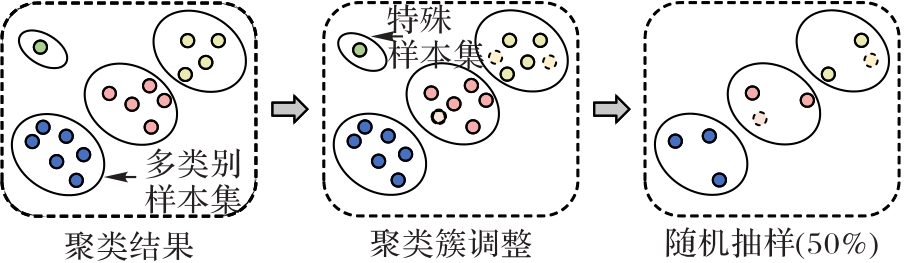
图3 自适应组合抽样算法
Fig. 3 Adaptive combined sampling algorithm
| 数据集 | 样本数 | 维度 | 类别数 |
|---|---|---|---|
| Sonar | 208 | 60 | 2 |
| Bupa | 345 | 7 | 2 |
| Breastcancer | 569 | 30 | 2 |
| Spambase | 4 601 | 57 | 2 |
| Phoneme | 5 404 | 5 | 2 |
| Wine | 1 599 | 11 | 11 |
表1 数据集详细信息
Tab. 1 Detailed information of datasets
| 数据集 | 样本数 | 维度 | 类别数 |
|---|---|---|---|
| Sonar | 208 | 60 | 2 |
| Bupa | 345 | 7 | 2 |
| Breastcancer | 569 | 30 | 2 |
| Spambase | 4 601 | 57 | 2 |
| Phoneme | 5 404 | 5 | 2 |
| Wine | 1 599 | 11 | 11 |
| 数据集 | SVM | MLP | ||||
|---|---|---|---|---|---|---|
| 2簇 | 4簇 | 8簇 | 2簇 | 4簇 | 8簇 | |
| 平均 | 85.99 | 86.68 | 89.10 | 80.03 | 80.76 | 82.25 |
| Sonar | 84.13 | 84.13 | 87.30 | 87.30 | 88.89 | 87.30 |
| Bupa | 73.08 | 72.12 | 82.69 | 76.92 | 79.81 | 75.96 |
| Breastcancer | 94.74 | 94.74 | 96.49 | 95.01 | 95.32 | 95.56 |
| Spambase | 84.07 | 88.25 | 88.12 | 94.20 | 93.56 | 93.92 |
| Phoneme | 84.65 | 85.08 | 84.96 | 85.08 | 85.51 | 84.71 |
| Wine | 95.25 | 95.73 | 95.04 | 41.67 | 41.45 | 56.04 |
表2 聚类数对SVM和MLP分类器准确率的影响 (%)
Tab. 2 Influence of the number of clusters on accuracies of SVM and MLP classifiers
| 数据集 | SVM | MLP | ||||
|---|---|---|---|---|---|---|
| 2簇 | 4簇 | 8簇 | 2簇 | 4簇 | 8簇 | |
| 平均 | 85.99 | 86.68 | 89.10 | 80.03 | 80.76 | 82.25 |
| Sonar | 84.13 | 84.13 | 87.30 | 87.30 | 88.89 | 87.30 |
| Bupa | 73.08 | 72.12 | 82.69 | 76.92 | 79.81 | 75.96 |
| Breastcancer | 94.74 | 94.74 | 96.49 | 95.01 | 95.32 | 95.56 |
| Spambase | 84.07 | 88.25 | 88.12 | 94.20 | 93.56 | 93.92 |
| Phoneme | 84.65 | 85.08 | 84.96 | 85.08 | 85.51 | 84.71 |
| Wine | 95.25 | 95.73 | 95.04 | 41.67 | 41.45 | 56.04 |
| 数据集 | SVM | MLP | ||||
|---|---|---|---|---|---|---|
原始 数据集 | 随机选择 算法 | TSDS | 原始 数据集 | 随机选择 算法 | TSDS | |
| Sonar | 84.12 | 84.12 | 87.30 | 80.95 | 85.71 | 87.30 |
| Bupa | 72.12 | 81.73 | 82.69 | 74.04 | 76.92 | 79.81 |
| Breastcancer | 90.64 | 94.39 | 94.74 | 92.40 | 92.40 | 94.15 |
| Spambase | 80.81 | 80.23 | 83.49 | 90.37 | 90.16 | 93.19 |
| Phoneme | 84.59 | 82.86 | 84.77 | 85.45 | 84.65 | 85.08 |
| Wine | 95.83 | 94.29 | 96.04 | 48.75 | 50.57 | 61.25 |
表3 SVM和MLP分类器在不同数据集上的训练准确率对比 (%)
Tab.3 Comparison of training accuracy between SVM and MLP classifiers on different datasets
| 数据集 | SVM | MLP | ||||
|---|---|---|---|---|---|---|
原始 数据集 | 随机选择 算法 | TSDS | 原始 数据集 | 随机选择 算法 | TSDS | |
| Sonar | 84.12 | 84.12 | 87.30 | 80.95 | 85.71 | 87.30 |
| Bupa | 72.12 | 81.73 | 82.69 | 74.04 | 76.92 | 79.81 |
| Breastcancer | 90.64 | 94.39 | 94.74 | 92.40 | 92.40 | 94.15 |
| Spambase | 80.81 | 80.23 | 83.49 | 90.37 | 90.16 | 93.19 |
| Phoneme | 84.59 | 82.86 | 84.77 | 85.45 | 84.65 | 85.08 |
| Wine | 95.83 | 94.29 | 96.04 | 48.75 | 50.57 | 61.25 |
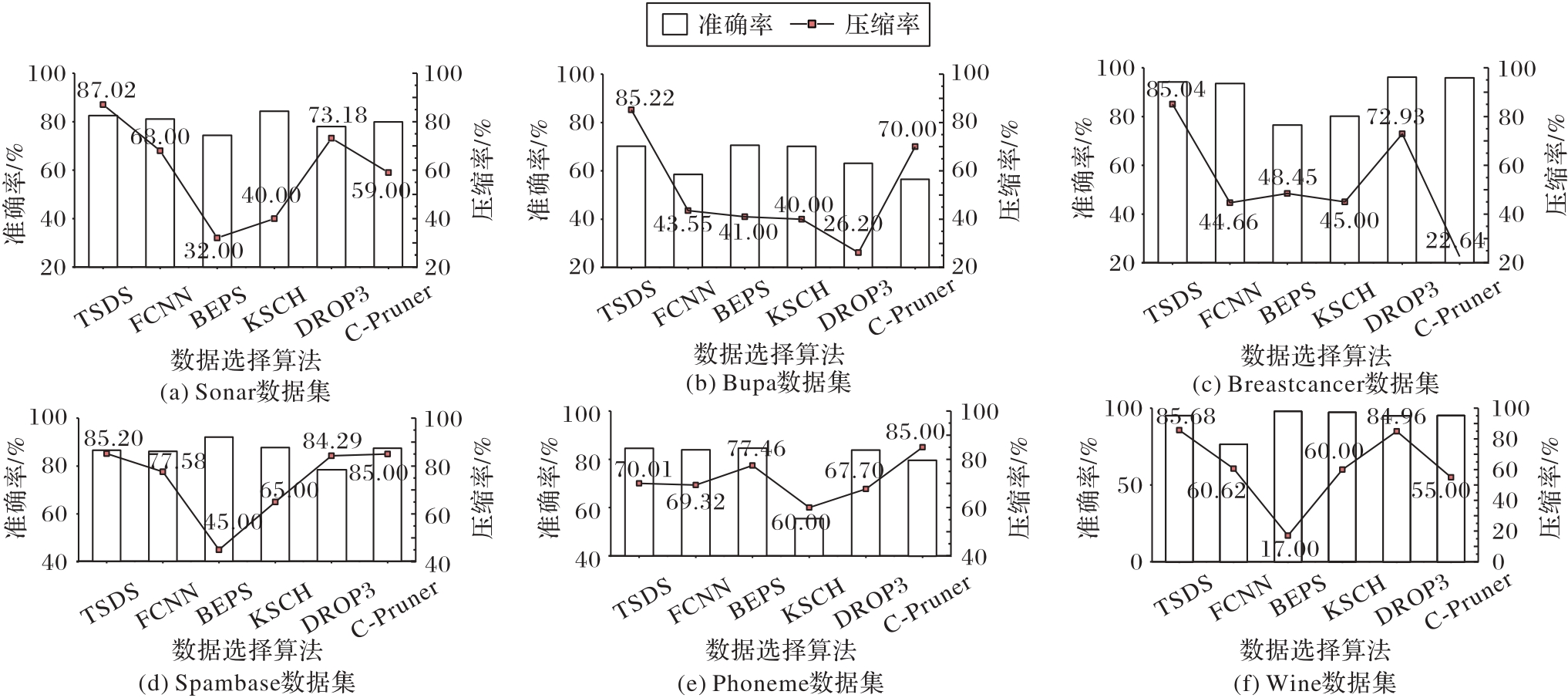
图4 不同数据集上不同数据选择算法下的SVM分类器准确率和压缩率对比
Fig. 4 Comparison of accuracy and compression ratio of SVM classifier under different data selection algorithms on different datasets
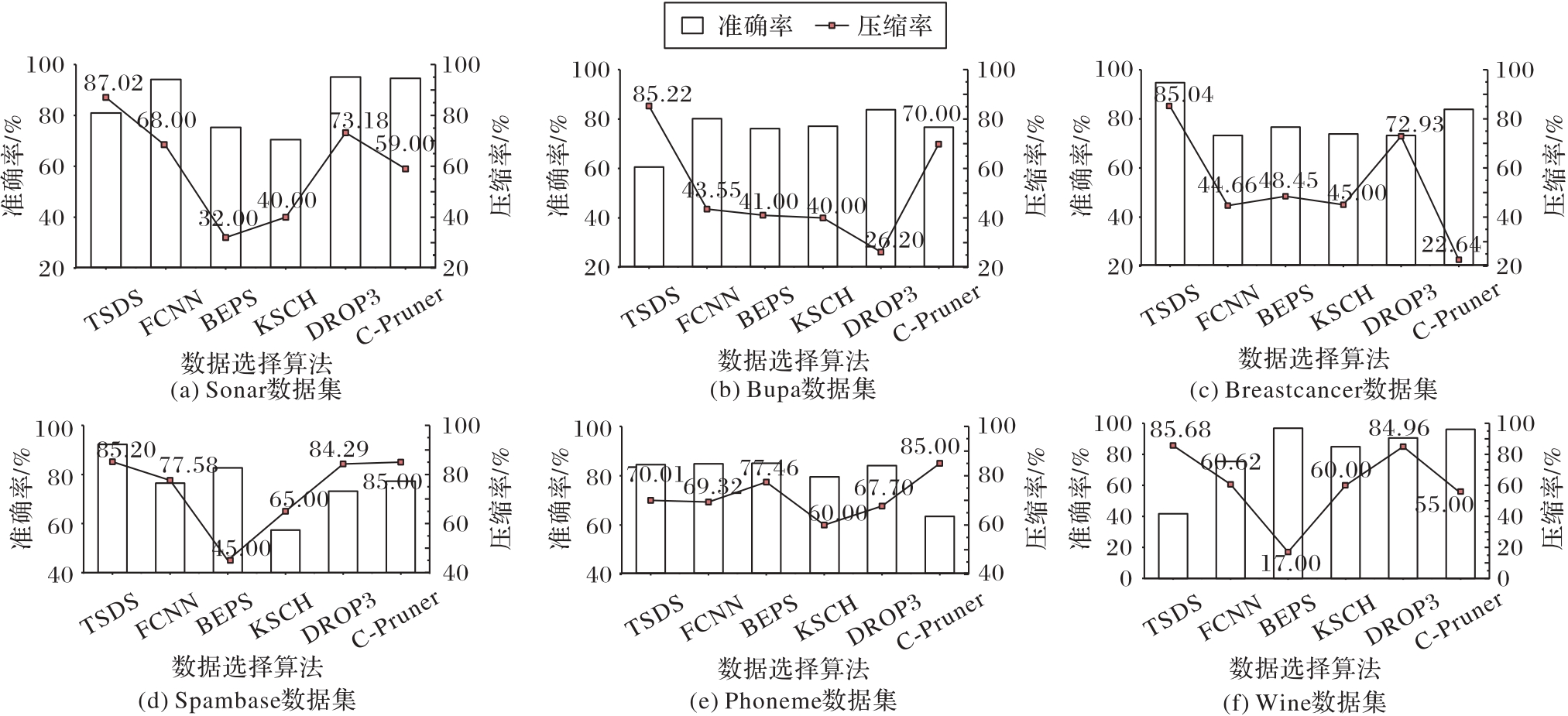
图5 不同数据集上不同数据选择算法下的MLP分类器准确率和压缩率对比
Fig. 5 Comparison of accuracy and compression ratio of MLP classifier under different data selection algorithms on different datasets
| 数据集 | SVM(完整数据集) | SVM(TSDS) | TSDS对比完整数据集的能耗变化/% | ||||
|---|---|---|---|---|---|---|---|
| 训练时长/ms | 处理器平均功率/W | 能耗/Wh | 训练时长/ms | 处理器平均功率/W | 能耗/Wh | ||
| Sonar | 8.40 | 31.71 | 0.40 | 27.01 | -95.94 | ||
| Bupa | 4.70 | 28.71 | 0.50 | 28.50 | -89.44 | ||
| Breastcancer | 4.90 | 29.01 | 0.60 | 27.81 | -88.26 | ||
| Spambase | 797.30 | 29.88 | 20.00 | 30.19 | -97.47 | ||
| Phoneme | 631.20 | 26.45 | 41.70 | 27.43 | -93.15 | ||
| Wine | 417.90 | 29.03 | 8.50 | 24.02 | -98.32 | ||
表4 SVM分类器应用TSDS前后的训练能耗对比
Tab. 4 Comparison of training energy consumption of SVM classifier before and after applying TSDS
| 数据集 | SVM(完整数据集) | SVM(TSDS) | TSDS对比完整数据集的能耗变化/% | ||||
|---|---|---|---|---|---|---|---|
| 训练时长/ms | 处理器平均功率/W | 能耗/Wh | 训练时长/ms | 处理器平均功率/W | 能耗/Wh | ||
| Sonar | 8.40 | 31.71 | 0.40 | 27.01 | -95.94 | ||
| Bupa | 4.70 | 28.71 | 0.50 | 28.50 | -89.44 | ||
| Breastcancer | 4.90 | 29.01 | 0.60 | 27.81 | -88.26 | ||
| Spambase | 797.30 | 29.88 | 20.00 | 30.19 | -97.47 | ||
| Phoneme | 631.20 | 26.45 | 41.70 | 27.43 | -93.15 | ||
| Wine | 417.90 | 29.03 | 8.50 | 24.02 | -98.32 | ||
| 数据集 | MLP(完整数据集) | MLP(TSDS) | TSDS对比完整数据集的 能耗变化/% | ||||
|---|---|---|---|---|---|---|---|
| 训练时长/ms | 处理器平均功率/W | 能耗/Wh | 训练时长/ms | 处理器平均功率/W | 能耗/Wh | ||
| Sonar | 537.00 | 40.18 | 183.30 | 36.82 | 1.97 × 10-3 | -68.72 | |
| Bupa | 175.60 | 31.27 | 9.00 | 29.48 | 7.74 × 10-5 | -95.17 | |
| Breastcancer | 316.90 | 36.12 | 11.20 | 34.71 | 11.34 × 10-4 | -96.60 | |
| Spambase | 802.70 | 38.11 | 170.50 | 39.05 | 1.94 × 10-3 | -78.24 | |
| Phoneme | 3 167.40 | 34.61 | 1 349.30 | 34.43 | 1.35 × 10-2 | -57.62 | |
| Wine | 1 146.70 | 28.66 | 524.10 | 27.52 | 4.21 × 10-3 | -56.11 | |
表5 MLP分类器应用TSDS前后的训练能耗对比
Tab. 5 Comparison of training energy consumption of MLP classifier before and after applying TSDS
| 数据集 | MLP(完整数据集) | MLP(TSDS) | TSDS对比完整数据集的 能耗变化/% | ||||
|---|---|---|---|---|---|---|---|
| 训练时长/ms | 处理器平均功率/W | 能耗/Wh | 训练时长/ms | 处理器平均功率/W | 能耗/Wh | ||
| Sonar | 537.00 | 40.18 | 183.30 | 36.82 | 1.97 × 10-3 | -68.72 | |
| Bupa | 175.60 | 31.27 | 9.00 | 29.48 | 7.74 × 10-5 | -95.17 | |
| Breastcancer | 316.90 | 36.12 | 11.20 | 34.71 | 11.34 × 10-4 | -96.60 | |
| Spambase | 802.70 | 38.11 | 170.50 | 39.05 | 1.94 × 10-3 | -78.24 | |
| Phoneme | 3 167.40 | 34.61 | 1 349.30 | 34.43 | 1.35 × 10-2 | -57.62 | |
| Wine | 1 146.70 | 28.66 | 524.10 | 27.52 | 4.21 × 10-3 | -56.11 | |
| 1 | FRIEDMAN J H. Greedy function approximation: a gradient boosting machine[J]. The Annals of Statistics, 2001, 29(5):1189-1232. |
| 2 | BALCÁZAR, J, DAI Y, WATANABE O. A random sampling technique for training support vector machines[C]// Proceeding of the 12th Annual Conference on Algorithmic Learning Theory, LNCS 2225. Berlin: Springer, 2001: 119-134. |
| 3 | 张莉,郭军. 基于边界样本的训练样本选择方法[J]. 北京邮电大学学报, 2006, 29(4):77-80. |
| ZHANG L, GUO J. A method for the selection of training samples based on boundary samples[J]. Journal of Beijing University of Posts and Telecommunications, 2006, 29(4):77-80. | |
| 4 | 于光华. 基于样本选择的复杂分类问题研究[D]. 天津:天津大学, 2017: 17-29. |
| YU G H. Instance selection for complex classification [D]. Tianjin: Tianjin University, 2017: 17-29. | |
| 5 | FERRAGUT E M, LASKA J. Randomized sampling for large data applications of SVM[C]// Proceeding of the 11th International Conference on Machine Learning and Applications. Piscataway: IEEE, 2012: 350-355. |
| 6 | GUAN D, YUAN W, LEE Y K, et al. Improving supervised learning performance by using fuzzy clustering method to select training data[J]. Journal of Intelligent and Fuzzy Systems, 2008, 19(4/5):321-334. |
| 7 | 周玉,朱安福,周林,等. 一种神经网络分类器样本数据选择方法[J].华中科技大学学报(自然科学版), 2012, 40(6):39-43. |
| ZHOU Y, ZHU A F, ZHOU L, et al. Sample data selection method for neural network classifiers[J]. Journal of Huazhong University of Science and Technology (Natural Science Edition), 2012, 40(6):39-43. | |
| 8 | CHEN J, ZHANG C, XUE X, et al. Fast instance selection for speeding up support vector machines[J]. Knowledge-Based Systems, 2013, 45:1-7. |
| 9 | OLVERA-LÓPEZ J A, CARRASCO-OCHOA J A, MARTÍNEZ-TRINIDAD J F. A new fast prototype selection method based on clustering[J]. Pattern Analysis and Applications, 2010, 13(2):131-141. |
| 10 | ZHAO K P, ZHOU S G, GUAN J H, et al. C-Pruner: an improved instance pruning algorithm [C]// Proceeding of the 2003 International Conference on Machine Learning and Cybernetics — Volume 1. Piscataway: IEEE, 2003: 94-99. |
| 11 | HART P E. The condensed nearest neighbor rule (Corresp.)[J]. IEEE Transactions on Information Theory, 1968, 14(3): 515-516. |
| 12 | AHA D W, KIBLER D, ALBERT M K. Instance-based learning algorithms [J]. Machine Learning, 1991, 6(1):37-66. |
| 13 | WILSON D L. Asymptotic properties of nearest neighbor rules using edited data [J]. IEEE Transactions on Systems, Man, and Cybernetics, 1972, SMC-2(3):408-421. |
| 14 | SMYTH B, KEANE M T. Remembering to forget: a competence-preserving case deletion policy for case-based reasoning systems[C]// Proceedings of the 14th International Joint Conference on Artificial Intelligence — Volume 1. San Francisco: Morgan Kaufmann Publishers Inc., 1995: 377-382. |
| 15 | BRIGHTON H, MELLISH C. On the consistency of information filters for lazy learning algorithms[C]// Proceeding of the 1999 European Conference on Principles of Data Mining and Knowledge Discovery, LNCS 1704. Berlin: Springer, 1999: 283-288. |
| 16 | FAYED H A, ATIYA A F. A novel template reduction approach for the K-nearest neighbor method[J]. IEEE Transactions on Neural Networks, 2009, 20(5):890-896. |
| 17 | ANGIULLI F. Fast nearest neighbor condensation for large data sets classification[J]. IEEE Transactions on Knowledge and Data Engineering, 2007, 19(11):1450-1464. |
| 18 | LI Y, MAGUIRE L. Selecting critical patterns based on local geometrical and statistical information[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2011, 33(6):1189-1201. |
| 19 | 姜文瀚,周晓飞,杨静宇. 核子类凸包样本选择方法及其SVM应用[J]. 计算机工程, 2008, 34(16):212-214. |
| JIANG W H, ZHOU X F, YANG J Y. Kernel subclass convex hull sample selection method and its application on SVM[J]. Computer Engineering, 2008, 34(16):212-214. | |
| 20 | WILSON D R, MARTINEZ T R. Reduction techniques for instance-based learning algorithms[J]. Machine Learning, 2000, 38(3): 257-286. |
| 21 | PATTERSON D, GONZALEZ J, LE Q, et al. Carbon emissions and large neural network training[EB/OL]. [2024-06-21].. |
| [1] | 曾碧卿, 钟广彬, 温志庆. 基于分解式模糊跨度的小样本命名实体识别[J]. 《计算机应用》唯一官方网站, 2025, 45(5): 1504-1510. |
| [2] | 严一钦, 罗川, 李天瑞, 陈红梅. 基于关系网络和Vision Transformer的跨域小样本分类模型[J]. 《计算机应用》唯一官方网站, 2025, 45(4): 1095-1103. |
| [3] | 严雪文, 黄章进. 基于对比学习的小样本图像分类方法[J]. 《计算机应用》唯一官方网站, 2025, 45(2): 383-391. |
| [4] | 富坤, 应世聪, 郑婷婷, 屈佳捷, 崔静远, 李建伟. 面向小样本节点分类的图数据增强方法[J]. 《计算机应用》唯一官方网站, 2025, 45(2): 392-402. |
| [5] | 谢斌红, 高婉银, 陆望东, 张英俊, 张睿. 小样本相似性匹配特征增强的密集目标计数网络[J]. 《计算机应用》唯一官方网站, 2025, 45(2): 403-410. |
| [6] | 张淑芬, 张宏扬, 任志强, 陈学斌. 联邦学习的公平性综述[J]. 《计算机应用》唯一官方网站, 2025, 45(1): 1-14. |
| [7] | 袁子璇, 翁小清, 戈宁振. 基于正交局部保持映射和成本优化的多变量时间序列早期分类模型[J]. 《计算机应用》唯一官方网站, 2024, 44(6): 1832-1841. |
| [8] | 李旭, 何玉林, 崔来中, 黄哲学, PHILIPPE Fournier‑Viger. 基于大数据随机样本划分的分布式观测点分类器[J]. 《计算机应用》唯一官方网站, 2024, 44(6): 1727-1733. |
| [9] | 余新言, 曾诚, 王乾, 何鹏, 丁晓玉. 基于知识增强和提示学习的小样本新闻主题分类方法[J]. 《计算机应用》唯一官方网站, 2024, 44(6): 1767-1774. |
| [10] | 付可意, 王高才, 邬满. 基于改进区域提议网络和特征聚合小样本目标检测方法[J]. 《计算机应用》唯一官方网站, 2024, 44(12): 3790-3797. |
| [11] | 谢莉, 舒卫平, 耿俊杰, 王琼, 杨海麟. 结合加权原型和自适应张量子空间的小样本宫颈细胞分类[J]. 《计算机应用》唯一官方网站, 2024, 44(10): 3200-3208. |
| [12] | 于碧辉, 蔡兴业, 魏靖烜. 基于提示学习的小样本文本分类方法[J]. 《计算机应用》唯一官方网站, 2023, 43(9): 2735-2740. |
| [13] | 姜钧舰, 刘达维, 刘逸凡, 任酉贵, 赵志滨. 基于孪生网络的小样本目标检测算法[J]. 《计算机应用》唯一官方网站, 2023, 43(8): 2325-2329. |
| [14] | 张济慈, 范纯龙, 李彩龙, 郑学东. 基于几何关系的跨模型通用扰动生成方法[J]. 《计算机应用》唯一官方网站, 2023, 43(11): 3428-3435. |
| [15] | 朱亮, 徐华, 成金海, 朱深. AdaBoost的样本权重与组合系数的分析及改进[J]. 《计算机应用》唯一官方网站, 2022, 42(7): 2022-2029. |
| 阅读次数 | ||||||
|
全文 |
|
|||||
|
摘要 |
|
|||||