


《计算机应用》唯一官方网站 ›› 2025, Vol. 45 ›› Issue (8): 2464-2469.DOI: 10.11772/j.issn.1001-9081.2024081164
• 第21届CCF中国信息系统及应用大会 (WISA 2024) • 上一篇
蒋建涛, 宋宝燕, 单晓欢( )
)
收稿日期:2024-08-19
修回日期:2024-09-09
接受日期:2024-09-11
发布日期:2024-11-07
出版日期:2025-08-10
通讯作者:
单晓欢
作者简介:蒋建涛(1999—),男,山东东营人,硕士研究生,主要研究方向:图数据管理基金资助:
Jiantao JIANG, Baoyan SONG, Xiaohuan SHAN()
Received:2024-08-19
Revised:2024-09-09
Accepted:2024-09-11
Online:2024-11-07
Published:2025-08-10
Contact:
Xiaohuan SHAN
About author:JIANG Jiantao,born in 1999, M. S. candidate. His research interests include graph data management.Supported by:摘要:
知识图谱是揭示实体之间关系的语义网络,常以资源描述框架(RDF)的形式表示。面对爆炸式增长的海量信息,现有的RDF图上的语义查询算法忽略了多元化的语义查询需求,因此,充分考虑RDF图丰富的语义信息,提出一种分布式处理的多级邻域谓语标签树编码索引(NPLTE)的RDF图多元语义查询方法(DSQ-NPLTE)。首先,为了避免存储空间的浪费且辅助后续的并行查询,设计基于频度的谓语编码映射策略,从而将较长字符串表示的谓语映射为唯一的自然数表示;其次,将RDF图分割后,将得到的顶点按它的邻边特性进行分类,并给出相应的存储模式;再次,构建多级NPLTE,利用谓语特征信息过滤无效顶点及边;最后,针对谓语已知、主语(宾语)已知和混合已知的多元语义查询,给出相应的匹配策略,并提出基于公共点的优化连接以减少笛卡儿积的数量,从而降低连接代价。实验结果表明,相较于无预处理方式,通过利用构建的索引进行剪枝优化,所提方法的查询效率可提高5~9倍;在3个不同规模的LUBM标准合成数据集上,与查询性能较好的FAST方法相比,所提方法的查询效率平均提高了43%。可见,构建的索引及查询策略可有效处理大规模RDF图上的多元化语义查询。
中图分类号:
蒋建涛, 宋宝燕, 单晓欢. 多级邻域谓语标签树编码索引的资源描述框架图多元语义查询[J]. 计算机应用, 2025, 45(8): 2464-2469.
Jiantao JIANG, Baoyan SONG, Xiaohuan SHAN. Diversity semantic query on resource description framework graphs based on multi-level neighborhood predicate label tree encoding index[J]. Journal of Computer Applications, 2025, 45(8): 2464-2469.
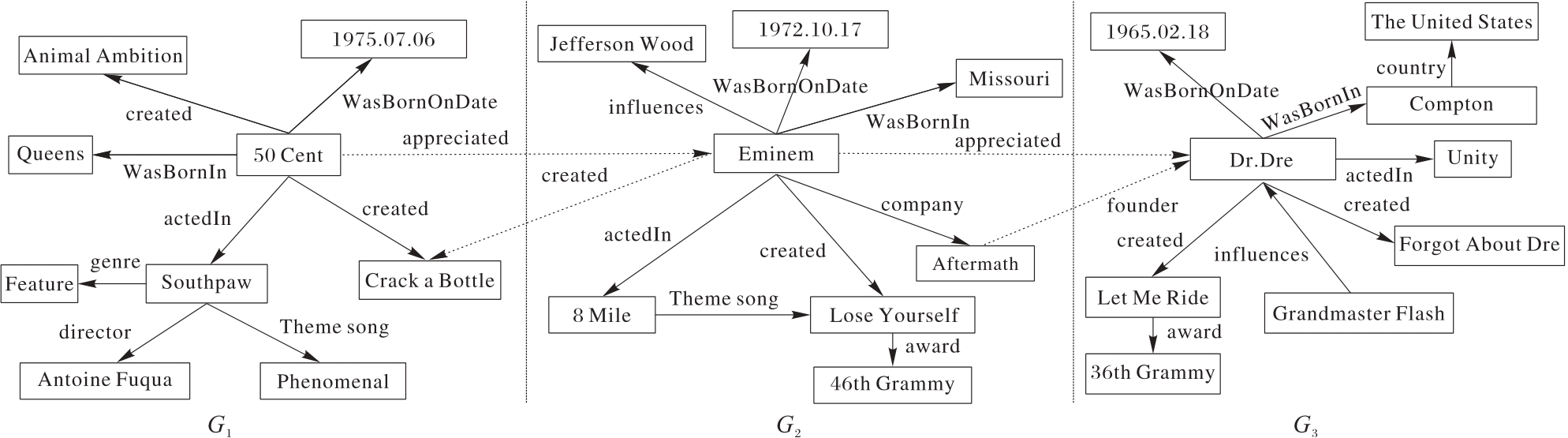
图1 RDF图的示例
Fig. 1 Example of RDF graph
| v | N_info |
|---|---|
| Eminem | (7,Jefferson Wood)(5,Dr.Dre)(5,50 Cent)… |
| Lose Yourself | (6,46th Grammy)(1,Eminem)(8,8 Mile) |
| … | … |
表1 G2中C类顶点的邻边信息
Tab. 1 Adjacent edge information of C vertices in G2
| v | N_info |
|---|---|
| Eminem | (7,Jefferson Wood)(5,Dr.Dre)(5,50 Cent)… |
| Lose Yourself | (6,46th Grammy)(1,Eminem)(8,8 Mile) |
| … | … |
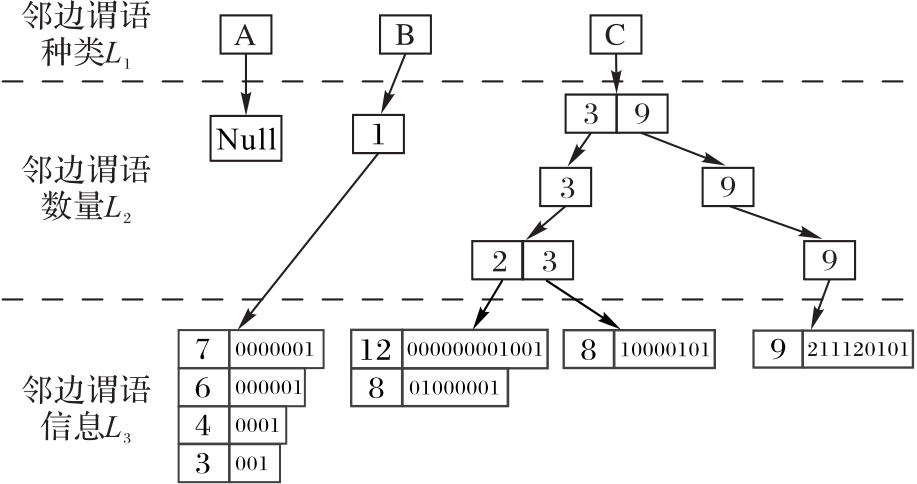
图2 G2的NPLTE
Fig. 2 NPLTE of G2
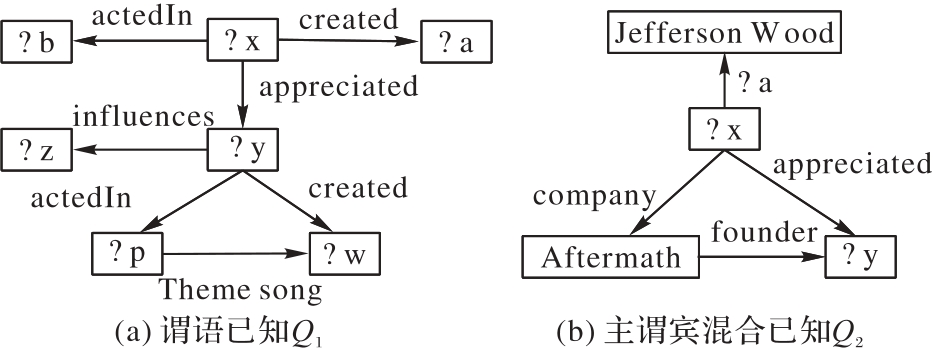
图3 多元化查询图示例
Fig. 3 Examples of diversity query graph
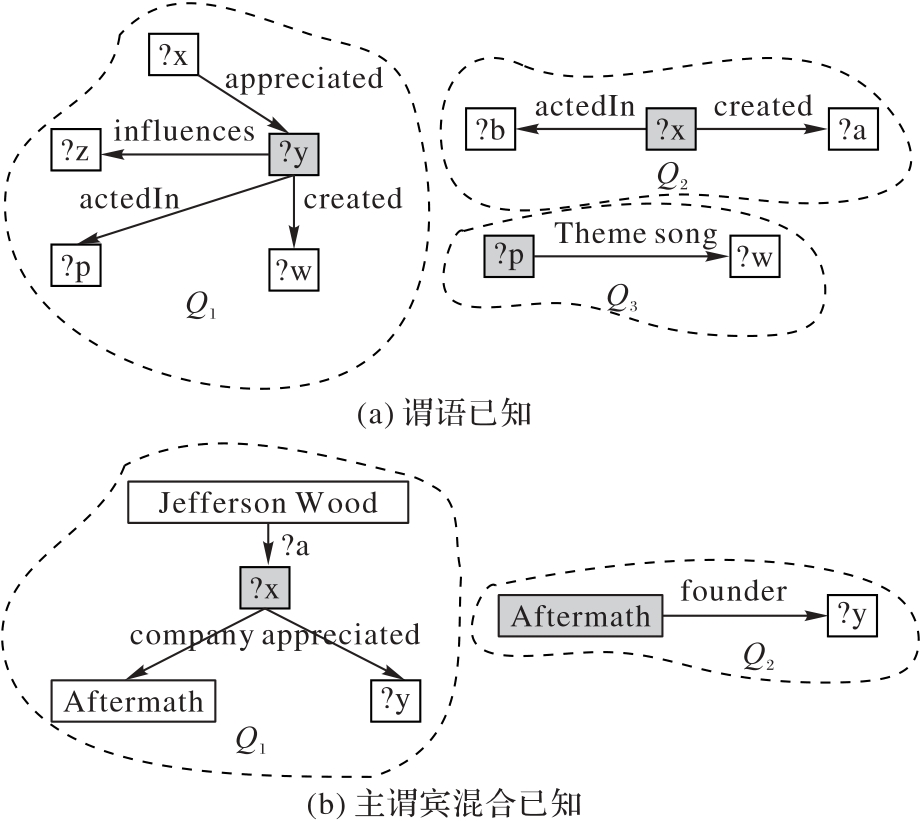
图4 查询图分解示例
Fig. 4 Examples of query graph decomposition
| 数据集 | 简称 | 三元组数/106 | 数据集大小/MB |
|---|---|---|---|
| Yago | Ya | 12.43 | 972 |
| DBpedia | DB | 15.68 | 2 079 |
| LUBM10 | L10 | 1.33 | 165 |
| LUBM50 | L50 | 7.05 | 876 |
| LUBM200 | L200 | 26.78 | 3 332 |
表2 实验数据集
Tab. 2 Experimental datasets
| 数据集 | 简称 | 三元组数/106 | 数据集大小/MB |
|---|---|---|---|
| Yago | Ya | 12.43 | 972 |
| DBpedia | DB | 15.68 | 2 079 |
| LUBM10 | L10 | 1.33 | 165 |
| LUBM50 | L50 | 7.05 | 876 |
| LUBM200 | L200 | 26.78 | 3 332 |
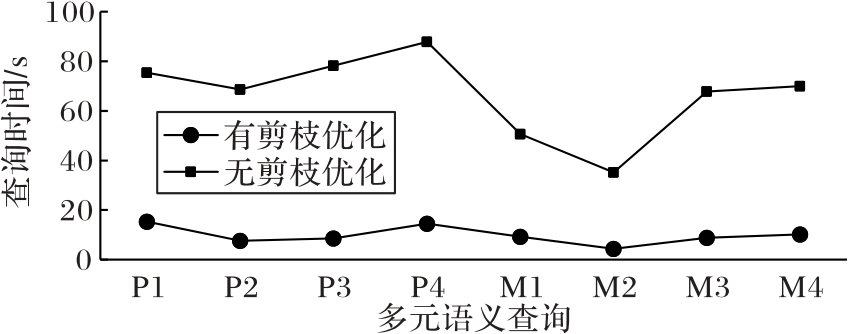
图5 索引对查询效率的影响
Fig. 5 Influence of index on query efficiency
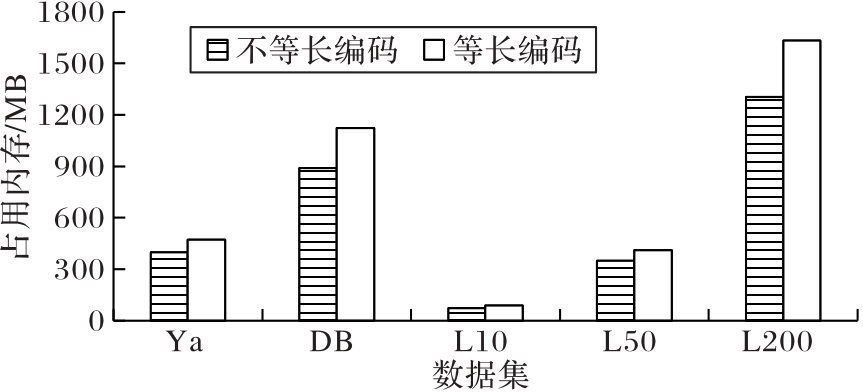
图6 等长编码与不等长编码的内存占用对比
Fig. 6 Comparison of memory occupied by equal-length encoding and variable length encoding
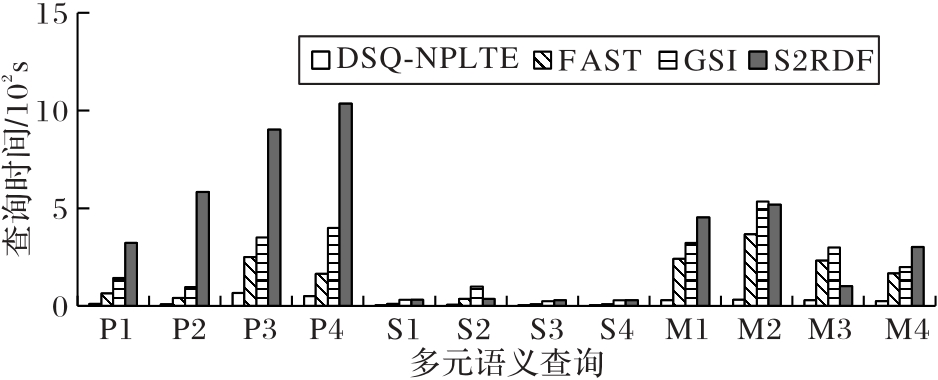
图7 DBpdeia数据集上不同语义的查询时间对比
Fig. 7 Query time comparison of different semantics on DBpedia dataset
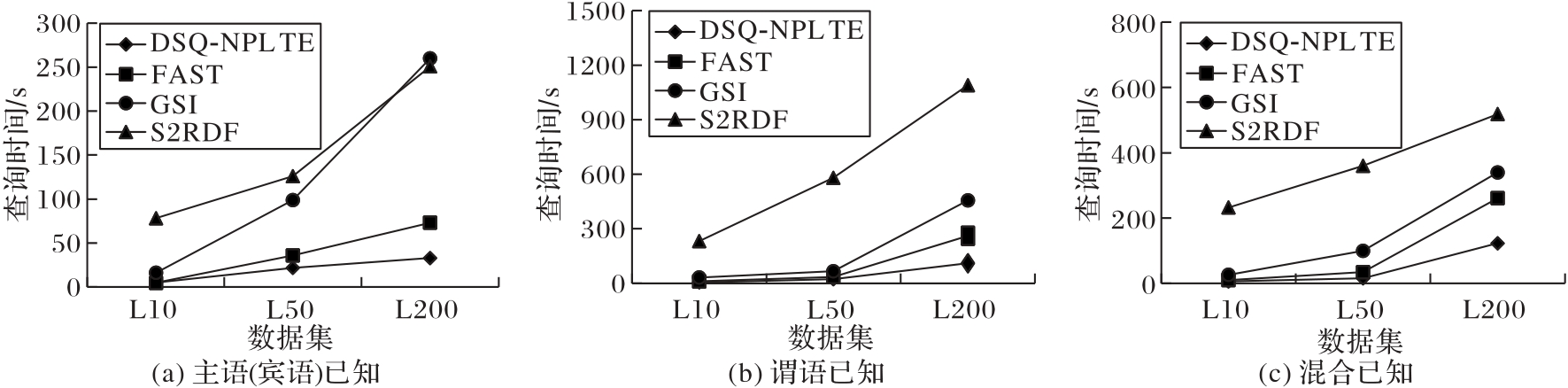
图8 不同语义在不同规模数据集上的查询时间对比
Fig. 8 Comparison of query time of different semantics on datasets with different sizes
| [1] | ZHU J, ZHENG Z, YANG M, et al. A semi-supervised model for knowledge graph embedding[J]. Data Mining and Knowledge Discovery, 2020, 34(1): 1-20. |
| [2] | 王鑫,陈蔚雪,杨雅君,等. 知识图谱划分算法研究综述[J]. 计算机学报, 2021, 44(1): 235-260. |
| WANG X, CHEN W X, YANG Y J, et al. Research on knowledge graph partitioning algorithms: a survey[J]. Chinese Journal of Computers, 2021, 44(1): 235-260. | |
| [3] | 王鑫,邹磊,王朝坤,等. 知识图谱数据管理研究综述[J]. 软件学报, 2019, 30(7): 2139-2174. |
| WANG X, ZOU L, WANG C K, et al. Research on knowledge graph data management: a survey[J]. Journal of Software, 2019, 30(7): 2139-2174. | |
| [4] | KIM H, CHOI Y, PARK K, et al. Versatile equivalences: speeding up subgraph query processing and subgraph matching[C]// Proceedings of the 2021 International Conference on Management of Data. New York: ACM, 2021: 925-937. |
| [5] | YAN D, GUO G, KHALIL J, et al. G-thinker: a general distributed framework for finding qualified subgraphs in a big graph with load balancing[J]. The VLDB Journal, 2022, 31(2):287-320. |
| [6] | NEUMANN T, WEIKUM G. The RDF-3X engine for scalable management of RDF data[J]. The VLDB Journal, 2010, 19(1):91-113. |
| [7] | ASILER M, YAZICI A, GEORGE R. HyGraph: a subgraph isomorphism algorithm for efficiently querying big graph databases[J]. Journal of Big Data, 2022, 9: No.40. |
| [8] | DHARAVATH R, ARORA N S. Spark’s GraphX-based link prediction for social communication using triangle counting[J]. Social Network Analysis and Mining, 2019, 9: No.28. |
| [9] | SCHÄTZLE A, PRZYJACIEL-ZABLOCKI M, SKILEVIC S, et al. S2RDF: RDF querying with SPARQL on Spark[J]. Proceedings of the VLDB Endowment, 2016, 9(10): 804-815. |
| [10] | WANG X, CHAI L, XU Q, et al. Efficient subgraph matching on large RDF graphs using MapReduce[J]. Data Science and Engineering, 2019, 4(1):24-43. |
| [11] | NIKITOPOULOS P, VLACHOU A, DOULKERIDIS C, et al. Parallel and scalable processing of spatiotemporal RDF queries using Spark[J]. Geoinformatica, 2021, 25(4): 623-653. |
| [12] | RANICHANDRA C, TRIPATHY B K. Architecture for distributed query processing using the RDF data in cloud environment[J]. Evolutionary Intelligence, 2021, 14(2): 567-575. |
| [13] | ZENG L, ZOU L, ÖZSU M T, et al. GSI: GPU-friendly subgraph isomorphism[C]// Proceedings of the IEEE 36th International Conference on Data Engineering. Piscataway: IEEE, 2020:1249-1260. |
| [14] | JIN X, YANG Z, LIN X, et al. FAST: FPGA-based subgraph matching on massive graphs[C]// Proceedings of the IEEE 37th International Conference on Data Engineering. Piscataway: IEEE, 2021: 1452-1463. |
| [15] | YAO Z, CHEN R, ZANG B, et al. Wukong+G: fast and concurrent RDF query processing using RDMA-assisted GPU graph exploration[J]. IEEE Transactions on Parallel and Distributed Systems, 2022, 33(7): 1619-1635. |
| [16] | 王鑫,徐强,柴乐乐,等. 大规模RDF图数据上高效率分布式查询处理[J]. 软件学报, 2019, 30(3):498-514. |
| WANG X, XU Q, CHAI L L, et al. Efficient distributed query processing on large scale RDF graph data[J]. Journal of Software, 2019, 30(3): 498-514. | |
| [17] | SCHROEDER R, PENTEADO R R M, HARA C S. A data distribution model for RDF[J]. Distributed and Parallel Databases, 2021, 39(1): 129-167. |
| [18] | DHARMARAJ C R, TRIPATHY B K. Optimisation of SPARQL queries over the RDF data in the cloud environment[J]. International Journal of Advanced Intelligence Paradigms, 2023, 24(3/4): 428-441. |
| [19] | BOIŃSKI T, SZYMAŃSKI J, DUDEK B, et al. NLP questions answering using DBpedia and YAGO[J]. Vietnam Journal of Computer Science, 2020, 7(4): 339-354. |
| [20] | GUO Y, PAN Z, HEFLIN J. LUBM: a benchmark for OWL knowledge base systems[J]. Journal of Web Semantics, 2005, 3(2/3):158-182. |
| [1] | 陈浩轩 叶培昌 刘磊 刘承明 胡文华. 自动代码编辑推荐综述[J]. 《计算机应用》唯一官方网站, 0, (): 0-0. |
| [2] | 陈宇轩, 郑海彬, 关振宇, 苏泊衡, 王玉珏, 郭振纬. 基于HoneyBadgerBFT和DAG的异步网络区块链分片机制[J]. 《计算机应用》唯一官方网站, 2025, 45(7): 2092-2100. |
| [3] | 梁辰, 王奕森, 魏强, 杜江. 基于Tsransformer-GCN的源代码漏洞检测方法[J]. 《计算机应用》唯一官方网站, 2025, 45(7): 2296-2303. |
| [4] | 李昊 王磊 孙乐 武优西. 一次性条件下自适应间隙稀有序列模式挖掘方法[J]. 《计算机应用》唯一官方网站, 0, (): 0-0. |
| [5] | 吴定佳 崔喆. MG-SQL:增强模式链接与多生成器协同的SQL生成框架[J]. 《计算机应用》唯一官方网站, 0, (): 0-0. |
| [6] | 刘俊岭, 孙萌, 孙焕良, 许景科. 空间众包中支持周期性任务的在线匹配算法[J]. 《计算机应用》唯一官方网站, 2025, 45(6): 1934-1944. |
| [7] | 崔双双, 王宏志, 朱加昊, 吴昊. 面向低能耗高性能的分类器两阶段数据选择方法[J]. 《计算机应用》唯一官方网站, 2025, 45(6): 1703-1711. |
| [8] | 于巧 黄子睿 程圣懿 祝义 张淑涛. 基于边权重的软件漏洞检测方法[J]. 《计算机应用》唯一官方网站, 0, (): 0-0. |
| [9] | 张瑞阳 赵明洁 郭兵 江平洪. 基于混合索引的链上数据查询优化[J]. 《计算机应用》唯一官方网站, 0, (): 0-0. |
| [10] | 游兰, 张雨昂, 刘源, 陈智军, 王伟, 曾星, 何张玮. 基于协作贡献网络的开源项目开发者推荐[J]. 《计算机应用》唯一官方网站, 2025, 45(4): 1213-1222. |
| [11] | 孙鉴 张伟 马宝全 吴隹伟 杨晓焕 武涛. MATOS:无人机群辅助的移动感知自适应并行计算任务卸载系统[J]. 《计算机应用》唯一官方网站, 0, (): 0-0. |
| [12] | 彭宇琪 陈娇龙 颜嘉麒. 基于区块链的去中心化科学系统运行机制综述[J]. 《计算机应用》唯一官方网站, 0, (): 0-0. |
| [13] | 闫秋艳 蒋辉 姜竹郡 李博雪. 面向多维时间序列根因分析的概率生成图注意力网络方法[J]. 《计算机应用》唯一官方网站, 0, (): 0-0. |
| [14] | 高威 刘丽华 和斌涛 邓方安. 区块链共识机制与改进算法研究进展[J]. 《计算机应用》唯一官方网站, 0, (): 0-0. |
| [15] | 任虹, 赵凡. 智能合约安全漏洞检测技术综述[J]. 《计算机应用》唯一官方网站, 0, (): 95-100. |
| 阅读次数 | ||||||
|
全文 |
|
|||||
|
摘要 |
|
|||||