


《计算机应用》唯一官方网站 ›› 2025, Vol. 45 ›› Issue (12): 4055-4063.DOI: 10.11772/j.issn.1001-9081.2024111670
陈晓娟, 张薇( )
)
收稿日期:2024-11-29
修回日期:2025-03-27
接受日期:2025-04-08
发布日期:2025-04-22
出版日期:2025-12-10
通讯作者:
张薇
作者简介:陈晓娟(2000—),女,山东泰安人,硕士研究生,CCF会员,主要研究方向:无人机物流配送、任务分配基金资助:Received:2024-11-29
Revised:2025-03-27
Accepted:2025-04-08
Online:2025-04-22
Published:2025-12-10
Contact:
Wei ZHANG
About author:CHEN Xiaojuan, born in 2000, M. S. candidate. Her research interests include UAV logistics delivery, task allocation.
Supported by:摘要:
农村“最后一公里”配送难、时间长和成本高的特点使高效精准的末端配送调度方案尤为重要。针对农村配送场景下的多物流无人机(UAV)的任务分配问题,综合考虑UAV的载重量和UAV的最大飞行距离,以最小化UAV的飞行距离、派遣数量和不违反时间窗为目标,建立多目标的UAV任务分配模型。首先,以强化学习为基础,针对任务分配维数过高的问题,引入编码器和注意力机制有效简化状态空间;其次,结合全局-局部搜索策略,在探索解空间的同时避免陷入局部最优解,从而提高求解质量;最后,进一步分析参数权重设置,并且经实验得出各子目标函数权重系数的最优组合。仿真结果表明,在得到的最终路径长度上相较于混合Q学习网络方法(HQM)、自适应大邻域搜索算法(ALNS)、Q学习算法(Q-learning)和遗传算法(GA),所提算法SG-HQM(Sine and Gaussian HQM)分别减少了8.35%、9.88%、10.29%和12.48%。
中图分类号:
陈晓娟, 张薇. 基于强化学习的无人机乡村末端配送任务分配[J]. 计算机应用, 2025, 45(12): 4055-4063.
Xiaojuan CHEN, Wei ZHANG. Task allocation of unmanned aerial vehicle for rural last-mile delivery based on reinforcement learning[J]. Journal of Computer Applications, 2025, 45(12): 4055-4063.
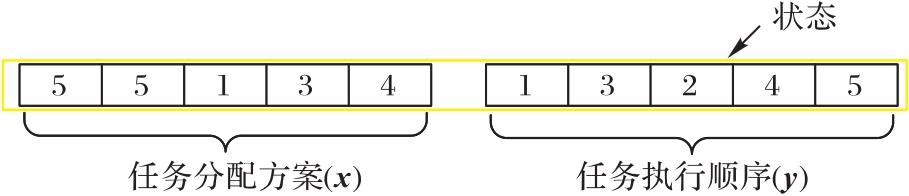
图1 状态示意图
Fig.1 State diagram
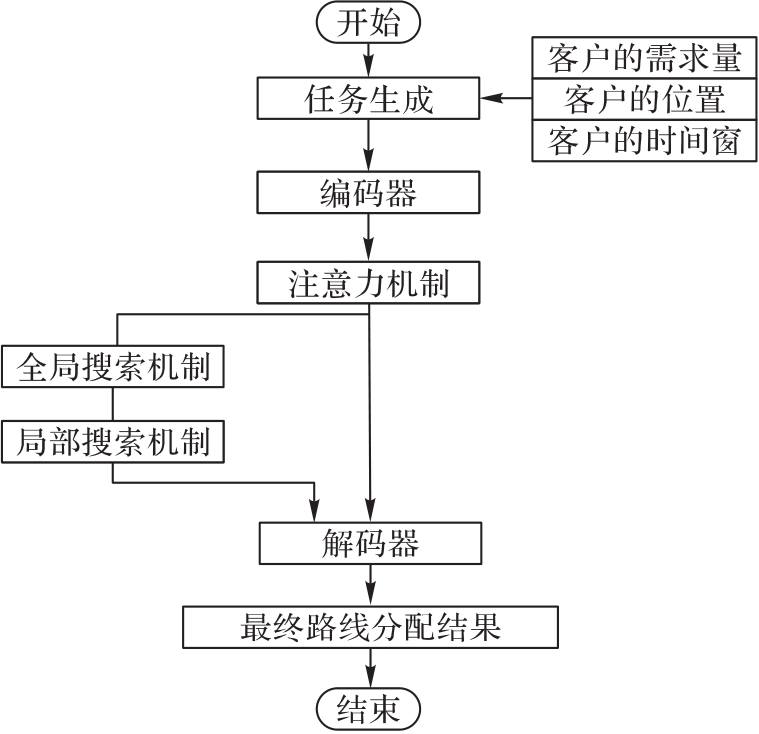
图2 本文算法的架构
Fig.2 Architecture of proposed algorithm
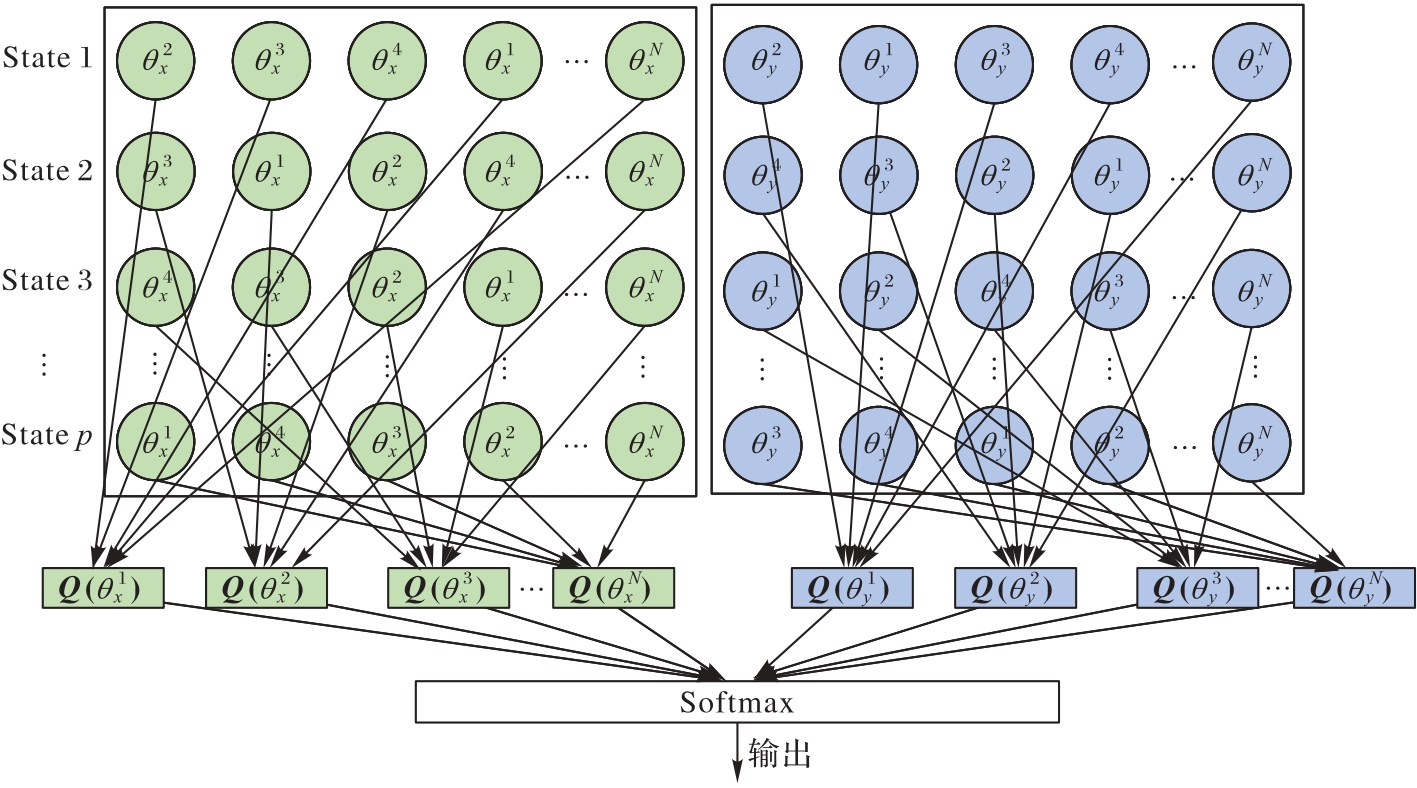
图3 注意力机制
Fig.3 Attention mechanism
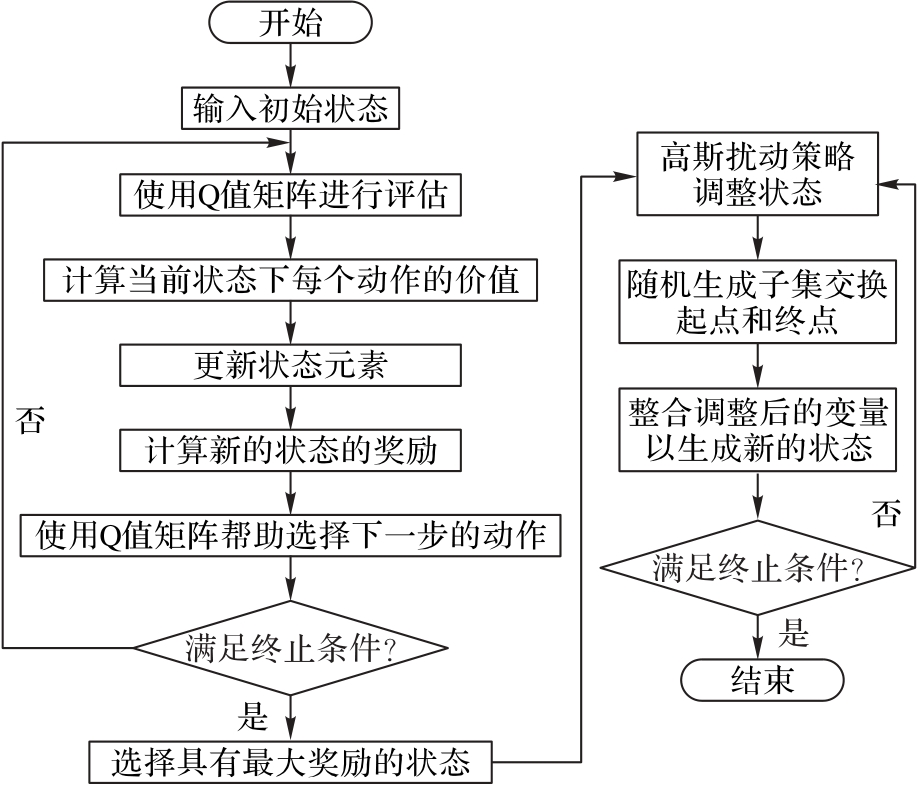
图4 全局-局部搜索策略的流程
Fig.4 Flow of global-local search strategy
| 参数含义 | 参数 | 值 |
|---|---|---|
| 最大容量 | Q | 5 kg |
| 飞行速度 | v | 10 m/s |
| 最远飞行距离 | D | 10 km |
| UAV数 | M | 10 |
表1 UAV参数
Tab.1 UAV parameters
| 参数含义 | 参数 | 值 |
|---|---|---|
| 最大容量 | Q | 5 kg |
| 飞行速度 | v | 10 m/s |
| 最远飞行距离 | D | 10 km |
| UAV数 | M | 10 |
| 客户ID | 时间窗 | 坐标点/km | 需货量/kg |
|---|---|---|---|
| 1 | [13:20, 14:05] | [0.99, 3.80] | 2.1 |
| 2 | [13:40, 15:02] | [4.06, 3.06] | 1.2 |
| 3 | [14:30, 15:55] | [0.45, 1.50] | 1.3 |
| 4 | [17:50, 19:13] | [3.60, 1.45] | 2.1 |
| 5 | [17:10, 17:46] | [3.42, 4.76] | 1.2 |
| 6 | [16:40, 17:59] | [2.49, 1.12] | 1.7 |
| 7 | [14:30, 15:51] | [0.23, 3.13] | 1.2 |
| 8 | [15:20, 16:28] | [3.08, 2.56] | 2.3 |
| 9 | [13:00, 13:52] | [3.85, 0.10] | 3.0 |
| 10 | [13:20, 14:20] | [3.16, 3.74] | 1.3 |
| 11 | [14:00, 14:59] | [0.84, 0.44] | 2.6 |
| 12 | [15:40, 16:10] | [1.86, 3.36] | 2.2 |
| 13 | [17:00, 18:04] | [2.21, 2.17] | 1.5 |
| 14 | [12:10, 13:36] | [4.58, 3.57] | 3.8 |
| 15 | [16:10, 16:54] | [4.54, 1.59] | 1.1 |
| 16 | [16:10, 17:30] | [0.56, 4.14] | 2.7 |
| 17 | [17:20, 18:00] | [3.25, 3.00] | 2.4 |
| 18 | [9:30, 10:36] | [0.01, 2.56] | 2.8 |
| 19 | [14:30, 15:44] | [2.71, 0.71] | 1.7 |
| 20 | [13:50, 15:15] | [4.02, 2.60] | 0.6 |
表2 物流配送点任务参数
Tab.2 Logistics delivery point task parameters
| 客户ID | 时间窗 | 坐标点/km | 需货量/kg |
|---|---|---|---|
| 1 | [13:20, 14:05] | [0.99, 3.80] | 2.1 |
| 2 | [13:40, 15:02] | [4.06, 3.06] | 1.2 |
| 3 | [14:30, 15:55] | [0.45, 1.50] | 1.3 |
| 4 | [17:50, 19:13] | [3.60, 1.45] | 2.1 |
| 5 | [17:10, 17:46] | [3.42, 4.76] | 1.2 |
| 6 | [16:40, 17:59] | [2.49, 1.12] | 1.7 |
| 7 | [14:30, 15:51] | [0.23, 3.13] | 1.2 |
| 8 | [15:20, 16:28] | [3.08, 2.56] | 2.3 |
| 9 | [13:00, 13:52] | [3.85, 0.10] | 3.0 |
| 10 | [13:20, 14:20] | [3.16, 3.74] | 1.3 |
| 11 | [14:00, 14:59] | [0.84, 0.44] | 2.6 |
| 12 | [15:40, 16:10] | [1.86, 3.36] | 2.2 |
| 13 | [17:00, 18:04] | [2.21, 2.17] | 1.5 |
| 14 | [12:10, 13:36] | [4.58, 3.57] | 3.8 |
| 15 | [16:10, 16:54] | [4.54, 1.59] | 1.1 |
| 16 | [16:10, 17:30] | [0.56, 4.14] | 2.7 |
| 17 | [17:20, 18:00] | [3.25, 3.00] | 2.4 |
| 18 | [9:30, 10:36] | [0.01, 2.56] | 2.8 |
| 19 | [14:30, 15:44] | [2.71, 0.71] | 1.7 |
| 20 | [13:50, 15:15] | [4.02, 2.60] | 0.6 |
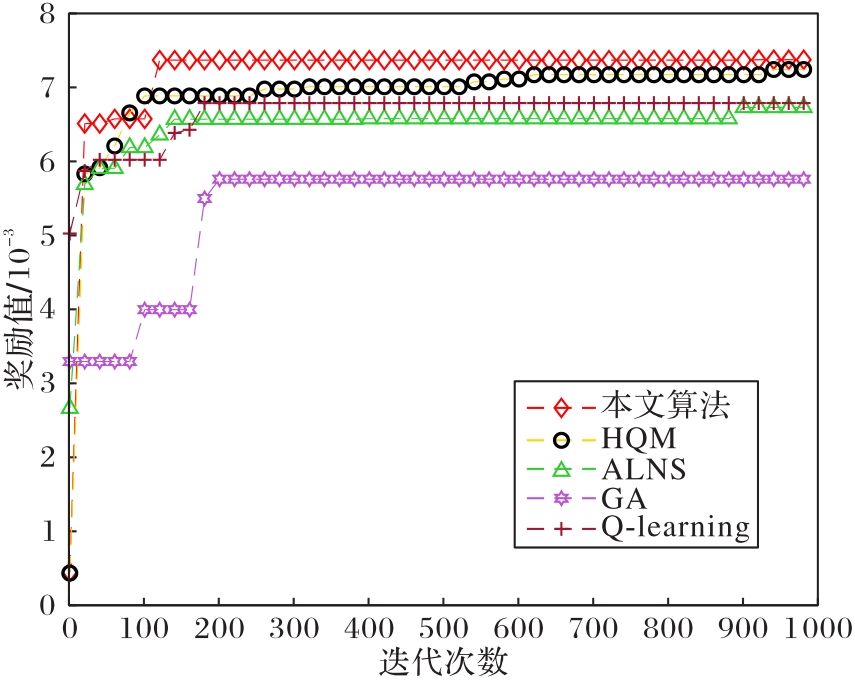
图5 奖励值曲线
Fig.5 Reward value curves
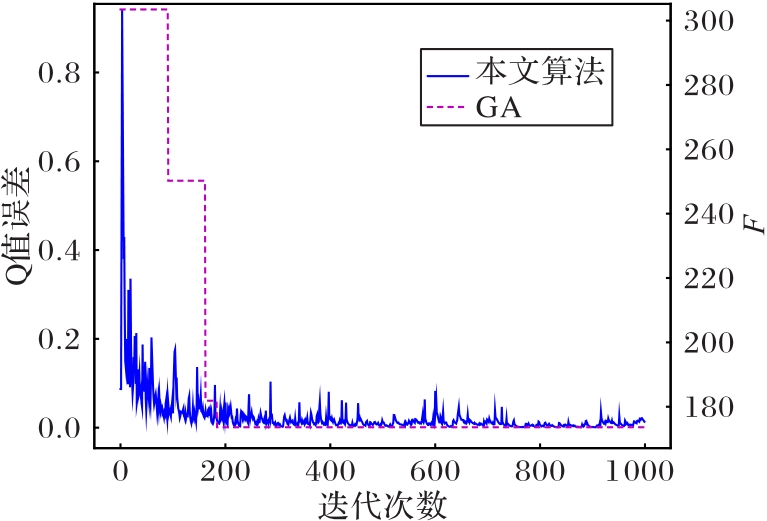
图6 Q值收敛曲线
Fig.6 Q-value convergence curves
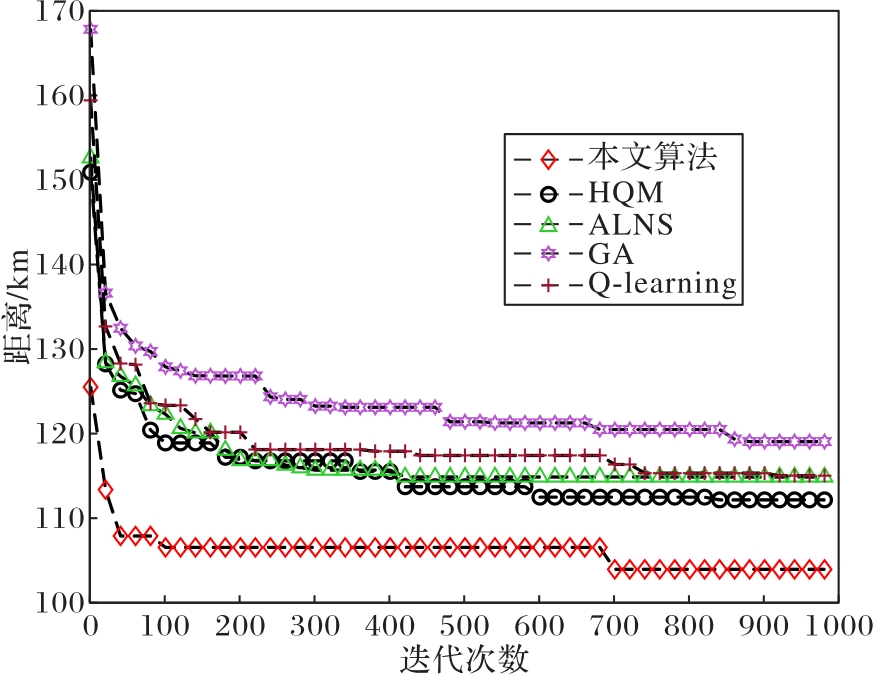
图7 路径长度曲线
Fig.7 Path length curves
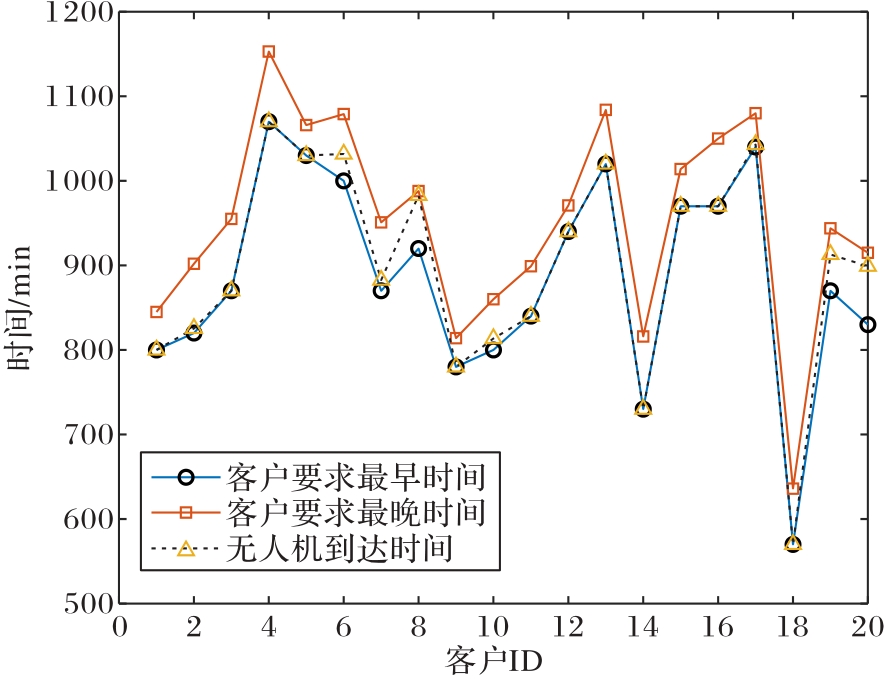
图8 UAV到达时间
Fig.8 Arrival time of UAV
| UAV_ID | 客户ID送达顺序 |
|---|---|
| 1 | 0 → 3 → 7 → 20 → 19 → 0 |
| 2 | 0 → 16 → 0 → 4 → 0 |
| 3 | 0 → 14 → 0 → 12 → 0 → 13 → 6 → 0 |
| 4 | 0 → 18 → 0 → 1 → 10 → 2 → 0 |
| 5 | 0 → 11 → 0 |
| 6 | 0 → 15 → 8 → 0 |
| 7 | 0 → 9 → 0 → 5 → 17 → 0 |
表3 UAV送达包裹的顺序
Tab.3 Task execution sequence of UAVs
| UAV_ID | 客户ID送达顺序 |
|---|---|
| 1 | 0 → 3 → 7 → 20 → 19 → 0 |
| 2 | 0 → 16 → 0 → 4 → 0 |
| 3 | 0 → 14 → 0 → 12 → 0 → 13 → 6 → 0 |
| 4 | 0 → 18 → 0 → 1 → 10 → 2 → 0 |
| 5 | 0 → 11 → 0 |
| 6 | 0 → 15 → 8 → 0 |
| 7 | 0 → 9 → 0 → 5 → 17 → 0 |
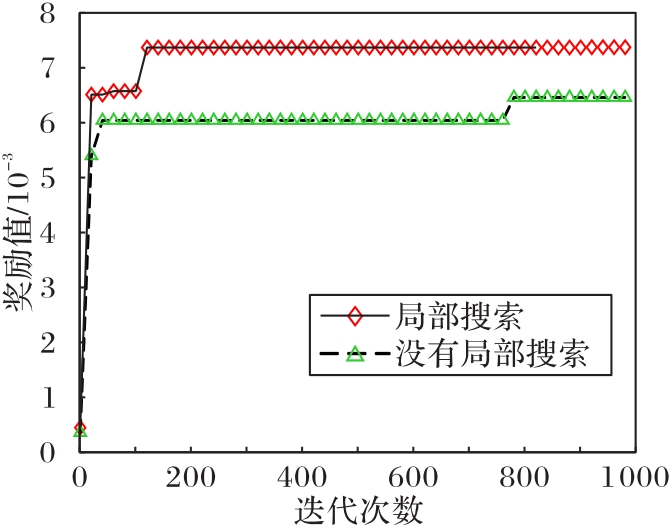
图9 有无局部搜索的实验结果
Fig.9 Experimental results with and without local search
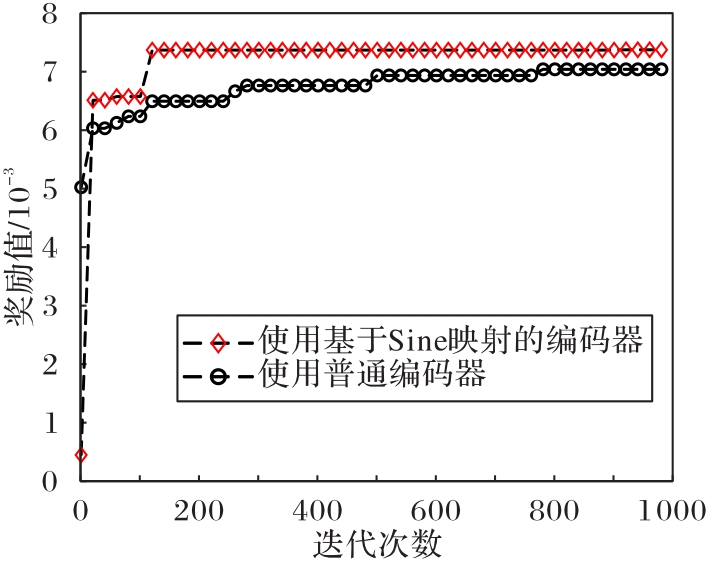
图10 不同编码器对奖励值的影响
Fig.10 Impact of different encoders on reward value
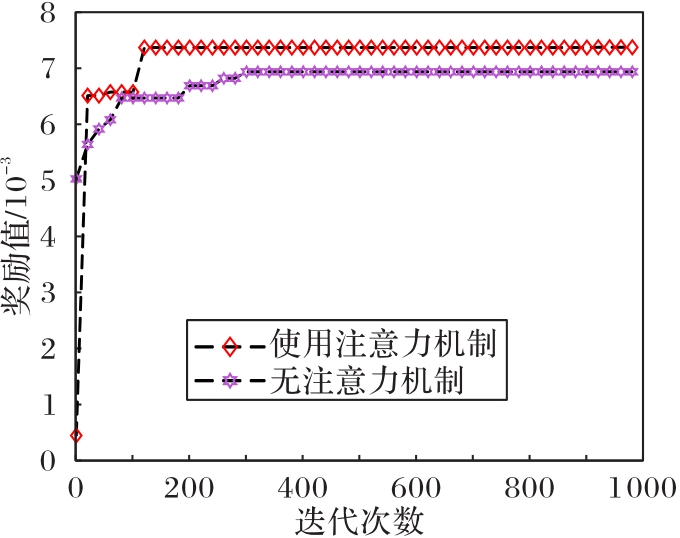
图11 注意力机制对奖励值的影响
Fig.11 Impact of attention mechanism on reward value
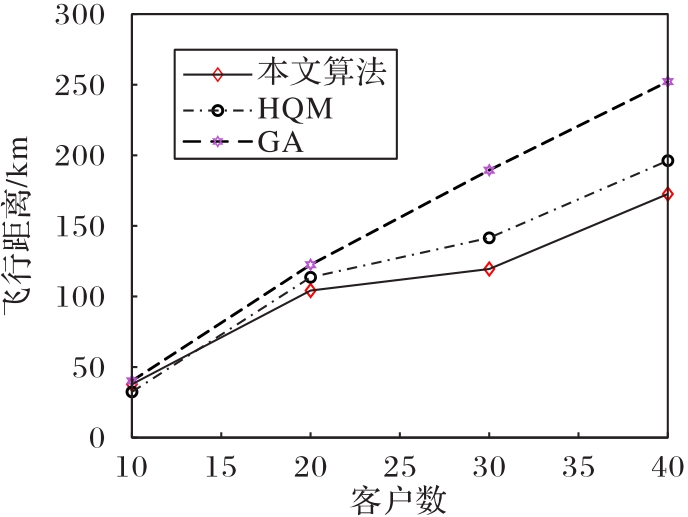
图12 不同客户规模下的UAV飞行路径长度曲线
Fig.12 Flight path length curves of UAVs at different customer scales
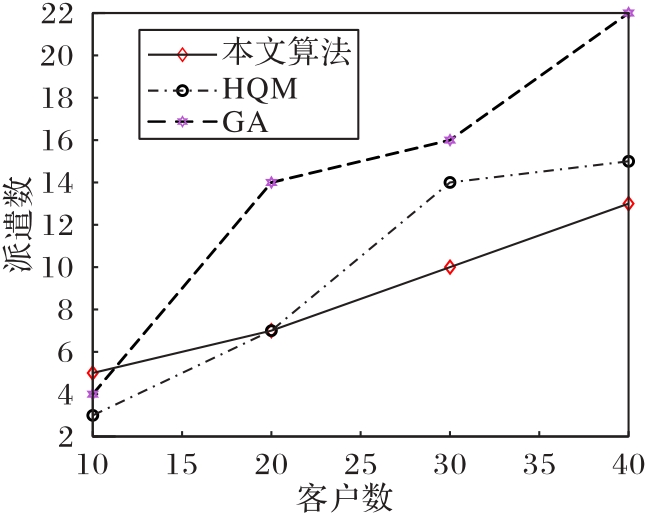
图13 不同客户规模下的UAV派遣数
Fig.13 Number of dispatched UAVs for different customer sizes
| 客户ID | 时间窗 | UAV 到达时间 | 客户ID | 时间窗 | UAV 到达时间 |
|---|---|---|---|---|---|
| 1 | [16:30,17:15] | 16:38 | 11 | [17:50,18:20] | 17:50 |
| 2 | [14:30,15:55] | 15:14 | 12 | [10:20,11:25] | 10:20 |
| 3 | [15:40,17:02] | 17:00 | 13 | [15:40,17:06] | 16:27 |
| 4 | [15:30,16:06] | 15:30 | 14 | [16:10,16:55] | 16:10 |
| 5 | [10:30,11:50] | 10:30 | 15 | [16:10,17:30] | 16:10 |
| 6 | [14:30,15:50] | 14:30 | 16 | [13:50,14:55] | 14:41 |
| 7 | [15:40,16:50] | 16:23 | 17 | [17:50,18:30] | 18:02 |
| 8 | [13:00,13:30] | 13:00 | 18 | [16:20,17:35] | 17:12 |
| 9 | [16:50,17:50] | 16:50 | 19 | [13:50,15:15] | 14:58 |
| 10 | [11:20,12:10] | 11:20 | 20 | [17:00,17:30] | 17:08 |
表4 客户的时间窗要求和UAV到达时间
Tab.4 Customers’ time window requirements and UAV arrival time
| 客户ID | 时间窗 | UAV 到达时间 | 客户ID | 时间窗 | UAV 到达时间 |
|---|---|---|---|---|---|
| 1 | [16:30,17:15] | 16:38 | 11 | [17:50,18:20] | 17:50 |
| 2 | [14:30,15:55] | 15:14 | 12 | [10:20,11:25] | 10:20 |
| 3 | [15:40,17:02] | 17:00 | 13 | [15:40,17:06] | 16:27 |
| 4 | [15:30,16:06] | 15:30 | 14 | [16:10,16:55] | 16:10 |
| 5 | [10:30,11:50] | 10:30 | 15 | [16:10,17:30] | 16:10 |
| 6 | [14:30,15:50] | 14:30 | 16 | [13:50,14:55] | 14:41 |
| 7 | [15:40,16:50] | 16:23 | 17 | [17:50,18:30] | 18:02 |
| 8 | [13:00,13:30] | 13:00 | 18 | [16:20,17:35] | 17:12 |
| 9 | [16:50,17:50] | 16:50 | 19 | [13:50,15:15] | 14:58 |
| 10 | [11:20,12:10] | 11:20 | 20 | [17:00,17:30] | 17:08 |
| UAV_ID | 客户ID送达顺序 |
|---|---|
| 1 | 0 → 6 → 19 → 2 → 0 → 15 → 13 → 1 → 0 |
| 2 | 0 → 5 → 0 → 16 → 0 |
| 3 | 0 → 12 → 0 → 4 → 0 |
| 4 | 0 → 14 → 7 → 0 → 3 → 18 → 0 |
| 5 | 0 → 11 → 17 → 0 |
| 6 | 0 → 9 → 20 → 0 |
| 7 | 0 → 10 → 0 → 8 → 0 |
表5 改变时间窗后UAV的任务送达顺序
Tab.5 Task execution sequence of UAVs after changing time window
| UAV_ID | 客户ID送达顺序 |
|---|---|
| 1 | 0 → 6 → 19 → 2 → 0 → 15 → 13 → 1 → 0 |
| 2 | 0 → 5 → 0 → 16 → 0 |
| 3 | 0 → 12 → 0 → 4 → 0 |
| 4 | 0 → 14 → 7 → 0 → 3 → 18 → 0 |
| 5 | 0 → 11 → 17 → 0 |
| 6 | 0 → 9 → 20 → 0 |
| 7 | 0 → 10 → 0 → 8 → 0 |
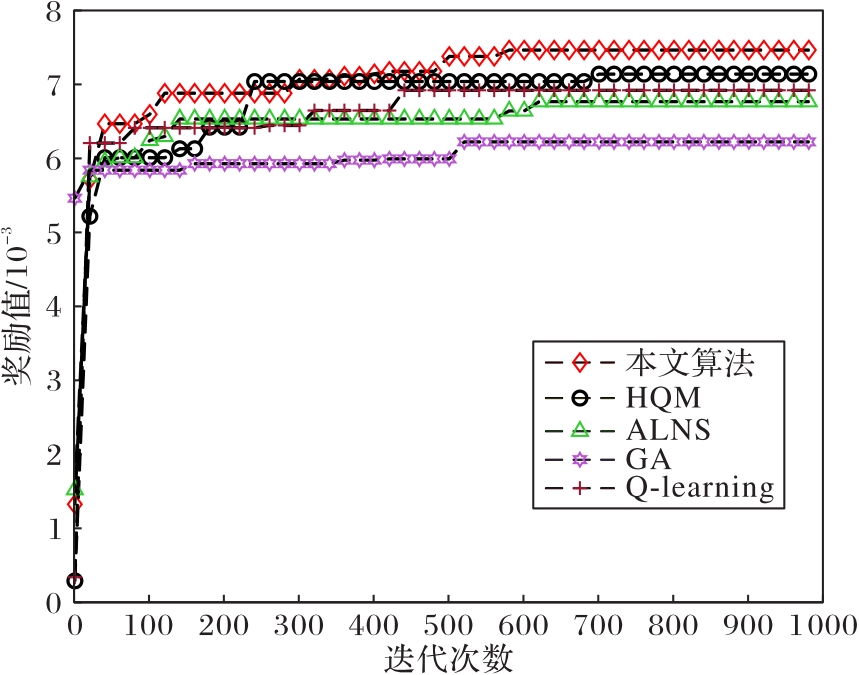
图14 改变时间窗后的奖励值曲线
Fig.14 Reward value curves after changing time window
| 组序 | 奖励值 | 距离/km | 算法时长/s | 组序 | 奖励值 | 距离/km | 算法时长/s | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 0.025 | 0.475 | 0.500 | 0.005 8 | 107.115 | 648.00 | 11 | 0.275 | 0.225 | 0.500 | 0.007 3 | 104.740 | 623.05 |
| 2 | 0.050 | 0.450 | 0.500 | 0.006 3 | 107.480 | 628.00 | 12 | 0.300 | 0.200 | 0.500 | 0.007 4 | 103.950 | 598.22 |
| 3 | 0.075 | 0.425 | 0.500 | 0.006 1 | 106.750 | 633.32 | 13 | 0.325 | 0.175 | 0.500 | 0.003 3 | 104.340 | 615.14 |
| 4 | 0.100 | 0.400 | 0.500 | 0.006 4 | 106.320 | 757.59 | 14 | 0.350 | 0.150 | 0.500 | 0.003 0 | 105.140 | 613.58 |
| 5 | 0.125 | 0.375 | 0.500 | 0.005 9 | 106.970 | 700.83 | 15 | 0.375 | 0.125 | 0.500 | 0.002 3 | 106.730 | 613.10 |
| 6 | 0.150 | 0.350 | 0.500 | 0.005 0 | 106.440 | 596.80 | 16 | 0.400 | 0.100 | 0.500 | 0.002 3 | 106.600 | 581.15 |
| 7 | 0.175 | 0.325 | 0.500 | 0.004 8 | 105.670 | 636.85 | 17 | 0.425 | 0.075 | 0.500 | 0.002 2 | 105.210 | 608.78 |
| 8 | 0.200 | 0.300 | 0.500 | 0.004 2 | 105.240 | 612.48 | 18 | 0.450 | 0.050 | 0.500 | 0.002 1 | 106.900 | 606.85 |
| 9 | 0.225 | 0.275 | 0.500 | 0.005 9 | 105.120 | 616.10 | 19 | 0.475 | 0.025 | 0.500 | 0.002 0 | 105.460 | 623.10 |
| 10 | 0.250 | 0.250 | 0.500 | 0.006 5 | 105.140 | 598.00 |
表6 不同任务目标函数权重对于实验结果的影响
Tab.6 Influence of different task objective function weights on experimental results
| 组序 | 奖励值 | 距离/km | 算法时长/s | 组序 | 奖励值 | 距离/km | 算法时长/s | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 0.025 | 0.475 | 0.500 | 0.005 8 | 107.115 | 648.00 | 11 | 0.275 | 0.225 | 0.500 | 0.007 3 | 104.740 | 623.05 |
| 2 | 0.050 | 0.450 | 0.500 | 0.006 3 | 107.480 | 628.00 | 12 | 0.300 | 0.200 | 0.500 | 0.007 4 | 103.950 | 598.22 |
| 3 | 0.075 | 0.425 | 0.500 | 0.006 1 | 106.750 | 633.32 | 13 | 0.325 | 0.175 | 0.500 | 0.003 3 | 104.340 | 615.14 |
| 4 | 0.100 | 0.400 | 0.500 | 0.006 4 | 106.320 | 757.59 | 14 | 0.350 | 0.150 | 0.500 | 0.003 0 | 105.140 | 613.58 |
| 5 | 0.125 | 0.375 | 0.500 | 0.005 9 | 106.970 | 700.83 | 15 | 0.375 | 0.125 | 0.500 | 0.002 3 | 106.730 | 613.10 |
| 6 | 0.150 | 0.350 | 0.500 | 0.005 0 | 106.440 | 596.80 | 16 | 0.400 | 0.100 | 0.500 | 0.002 3 | 106.600 | 581.15 |
| 7 | 0.175 | 0.325 | 0.500 | 0.004 8 | 105.670 | 636.85 | 17 | 0.425 | 0.075 | 0.500 | 0.002 2 | 105.210 | 608.78 |
| 8 | 0.200 | 0.300 | 0.500 | 0.004 2 | 105.240 | 612.48 | 18 | 0.450 | 0.050 | 0.500 | 0.002 1 | 106.900 | 606.85 |
| 9 | 0.225 | 0.275 | 0.500 | 0.005 9 | 105.120 | 616.10 | 19 | 0.475 | 0.025 | 0.500 | 0.002 0 | 105.460 | 623.10 |
| 10 | 0.250 | 0.250 | 0.500 | 0.006 5 | 105.140 | 598.00 |
| [1] | 吕璐璐,侯庆丰. 西北农村物流“最后一公里”配送问题及对策研究[J]. 物流科技, 2024, 47(15): 40-42, 54. |
| LYU L L, HOU Q F. Research on the “last kilometer” distribution problems and countermeasures of rural logistics in Northwest China[J]. Logistics Sci-Tech, 2024, 47(15): 40-42, 54. | |
| [2] | ESKANDARIPOUR H, BOLDSAIKHAN E. Last-mile drone delivery: past, present, and future[J]. Drones, 2023, 7(2): No.77. |
| [3] | 李章萍,贺亚蒙. 基于GA-SA组合算法的山区复杂环境无人机起降点选址[J]. 科学技术与工程, 2024, 24(2): 850-857. |
| LI Z P, HE Y M. Site selection of unmanned aerial vehicle take-off and landing points in mountainous complex environments based on GA-SA combination algorithm[J]. Science Technology and Engineering, 2024, 24(2): 850-857. | |
| [4] | 陈希琼,王兴隆,胡大伟. 考虑等待成本的卡车与多无人机联合配送农村物流路径优化[J]. 运筹与管理, 2024, 33(8): 23-29. |
| CHEN X Q, WANG X L, HU D W. Rural e-commerce logistics route optimization by joint truck and multi-drone delivery considering waiting cost[J]. Operations Research and Management Science, 2024, 33(8): 23-29. | |
| [5] | 韩鹏,张冰玉. 基于改进蚁群算法的无人机安全航路规划研究[J]. 中国安全科学学报, 2021, 31(1): 24-29. |
| HAN P, ZHANG B Y. Safety route planning of UAV based on improved ant colony algorithm[J]. Chinese Safety Science Journal, 2021, 31(1): 24-29. | |
| [6] | 郭兴海,计明军,温都苏,等. “最后一公里”配送的分布式多无人机的任务分配和路径规划[J]. 系统工程理论与实践, 2021, 41(4): 946-961. |
| GUO X H, JI M J, WEN D S, et al. Task assignment and path planning for distributed multiple unmanned aerial vehicles in the “last mile” [J]. Systems Engineering — Theory and Practice, 2021, 41(4): 946-961. | |
| [7] | 伍国华,毛妮,徐彬杰,等. 基于自适应大规模邻域搜索算法的多车辆与多无人机协同配送方法[J]. 控制与决策, 2023, 38(1): 201-210. |
| WU G H, MAO N, XU B J, et al. The cooperative delivery of multiple vehicles and multiple drones based on adaptive large neighborhood search[J]. Control and Decision, 2023, 38(1): 201-210. | |
| [8] | 张歆悦,靳鹏,胡笑旋,等. 时间依赖型多配送中心带时间窗的开放式车辆路径问题研究[J]. 中国管理科学, 2024, 32(1): 146-157. |
| ZHANG X Y, JIN P, HU X X, et al. Research on the time-dependent multi-depot open vehicle routing problem with time windows[J]. Chinese Journal of Management Science, 2024, 32(1): 146-157. | |
| [9] | 苏欣欣,秦虎,王恺. 禁忌搜索算法求解带时间窗和多配送人员的车辆路径问题[J]. 重庆师范大学学报(自然科学版), 2020, 37(1): 22-30. |
| SU X X, QIN H, WANG K. Tabu search algorithm for the vehicle routing problem with time windows and multiple deliverymen[J]. Journal of Chongqing Normal University (Natural Science), 2020, 37(1): 22-30. | |
| [10] | DELL’ AMICO M, MONTEMANNI R, NOVELLANI S. Matheuristic algorithms for the parallel drone scheduling traveling salesman problem[J]. Annals of Operations Research, 2020, 289(2): 211-226. |
| [11] | 王迪,金辉. 贪婪鲸鱼优化算法求解带时间窗的快递末端配送路径问题[J]. 计算机应用与软件, 2020, 37(6): 263-268. |
| WANG D, JIN H. Greedy whale optimization algorithm for solving the delivery path problem of express delivery with time window at the end[J]. Computer Applications and Software, 2020, 37(6): 263-268. | |
| [12] | AGRAWAL A, BEDI A S, MANOCHA D. RTAW: an attention inspired reinforcement learning method for multi-robot task allocation in warehouse environments[C]// Proceedings of the 2023 IEEE International Conference on Robotics and Automation. Piscataway: IEEE, 2023: 1393-1399. |
| [13] | SHIBATA K, JIMBO T, ODASHIMA T, et al. Learning locally, communicating globally: reinforcement learning of multi-robot task allocation for cooperative transport[J]. IFAC Papers OnLine, 2023, 56(2): 11436-11443. |
| [14] | HO T M, NGUYEN K K, CHERIET M. Federated deep reinforcement learning for task scheduling in heterogeneous autonomous robotic system[J]. IEEE Transactions on Automation Science and Engineering, 2022, 21(1): 528-540. |
| [15] | 张雪锋,卫凯莉,姜文. 一种n维组合混沌映射及性能分析[J]. 西安邮电大学学报, 2020, 25(6): 52-62. |
| ZHANG X F, WEI K L, JIANG W. An n-dimensional combined chaotic mapping and performance analysis[J]. Journal of Xi’an University of Posts and Telecommunications, 2020, 25(6): 52-62. | |
| [16] | 蒋伟进,张婉清,陈萍萍,等. 基于IWOA群智感知中数量敏感的任务分配方法[J]. 电子学报, 2022, 50(10): 2489-2502. |
| JIANG W J, ZHANG W Q, CHEN P P, et al. Quantity sensitive task allocation method based on IWOA swarm intelligence perception[J]. Acta Electronica Sinica, 2022, 50(10): 2489-2502. | |
| [17] | LIU Y, YE Q, ESCRIBANO-MACIAS J, et al. Route planning for last-mile deliveries using mobile parcel lockers: a hybrid Q-learning network approach[J]. Transportation Research Part E: Logistics and Transportation Review, 2023, 177: No.103234. |
| [18] | YU Y, GAO S, CHENG S, et al. CBSO: a memetic brain storm optimization with chaotic local search[J]. Memetic Computing, 2018, 10(4): 353-367. |
| [19] | ROPKE S, PISINGER D.An adaptive large neighborhood search heuristic for the pickup and delivery problem with time windows[J]. Transportation Science, 2006,40(4): 455-472. |
| [1] | 冉敏, 潘大志. 融合变异策略与邻接信息的差分进化算法[J]. 《计算机应用》唯一官方网站, 2026, 46(1): 188-197. |
| [2] | 汤恒先, 姚远, 康浩翔. 基于容器的规模化无人机集群仿真引擎研究与实现[J]. 《计算机应用》唯一官方网站, 2025, 45(8): 2704-2711. |
| [3] | 袁志超, 杨磊, 田井林, 魏晓威, 李康顺. 面向复杂约束多目标优化问题的双种群双阶段进化算法[J]. 《计算机应用》唯一官方网站, 2025, 45(8): 2656-2665. |
| [4] | 刘哲旭, 张澳冰, 樊智勇. 飞机狭小空间虚拟维修姿态分层求解方法[J]. 《计算机应用》唯一官方网站, 2025, 45(8): 2694-2703. |
| [5] | 范博淦, 王淑青, 陈开元. 基于改进YOLOv8的航拍无人机小目标检测模型[J]. 《计算机应用》唯一官方网站, 2025, 45(7): 2342-2350. |
| [6] | 李姝, 刘国庆, 李思远, 秦耀昌. 大范围复杂环境下多无人机的快速全自主探索方法[J]. 《计算机应用》唯一官方网站, 2025, 45(7): 2317-2324. |
| [7] | 薛天宇, 李爱萍, 段利国. 联合任务卸载和资源优化的车辆边缘计算方案[J]. 《计算机应用》唯一官方网站, 2025, 45(6): 1766-1775. |
| [8] | 许鹏程, 何磊, 李川, 钱炜祺, 赵暾. 基于Transformer的深度符号回归方法[J]. 《计算机应用》唯一官方网站, 2025, 45(5): 1455-1463. |
| [9] | 谭瑛, 任新宇, 孙超利, 王思思. 两阶段填充采样的半监督昂贵多目标优化算法[J]. 《计算机应用》唯一官方网站, 2025, 45(5): 1605-1612. |
| [10] | 林柄权, 刘磊, 李华峰, 刘晨. DoS攻击下基于APF和DDPG算法的无人机安全集群控制[J]. 《计算机应用》唯一官方网站, 2025, 45(4): 1241-1248. |
| [11] | 王兴旺, 张清杨, 姜守勇, 董永权. 基于改进鲸鱼优化算法的动态无人机路径规划[J]. 《计算机应用》唯一官方网站, 2025, 45(3): 928-936. |
| [12] | 胡林波, 倪志伟, 程家乐, 刘文涛, 朱旭辉. 融合社区检测的协作众包任务分配方法[J]. 《计算机应用》唯一官方网站, 2025, 45(2): 534-545. |
| [13] | 王华华, 黄梁, 陈甲杰, 方杰宁. 基于深度强化学习的低轨卫星多波束子载波动态分配算法[J]. 《计算机应用》唯一官方网站, 2025, 45(2): 571-577. |
| [14] | 王靖, 方旭明. Wi-Fi7多链路通感一体化的功率和信道联合智能分配算法[J]. 《计算机应用》唯一官方网站, 2025, 45(2): 563-570. |
| [15] | 曾君, 童英华, 王得芳. 基于累积概率波动和自动化聚类的异常检测方法[J]. 《计算机应用》唯一官方网站, 2025, 45(12): 3864-3871. |
| 阅读次数 | ||||||
|
全文 |
|
|||||
|
摘要 |
|
|||||