


《计算机应用》唯一官方网站 ›› 2025, Vol. 45 ›› Issue (12): 3896-3908.DOI: 10.11772/j.issn.1001-9081.2024121733
王诚熠1, 徐磊2( ), 陈晋音1,3, 邱洪君4
), 陈晋音1,3, 邱洪君4
收稿日期:2024-12-10
修回日期:2025-03-27
接受日期:2025-04-01
发布日期:2025-04-15
出版日期:2025-12-10
通讯作者:
徐磊
作者简介:王诚熠(2000—),男,浙江永康人,硕士研究生,主要研究方向:人工智能安全、深度学习、强化学习基金资助:
Chengyi WANG1, Lei XU2(), Jinyin CHEN1,3, Hongjun QIU4
Received:2024-12-10
Revised:2025-03-27
Accepted:2025-04-01
Online:2025-04-15
Published:2025-12-10
Contact:
Lei XU
About author:WANG Chengyi, born in 2000, M. S. candidate. His research interests include artificial intelligence security, deep learning, reinforcement learning.Supported by:摘要:
基于深度强化学习(DRL)的智能化网络测绘方法将网络测绘过程建模为马尔可夫决策过程(MDP),利用试错学习的方式训练攻击智能体以识别关键网络路径,获取网络拓扑信息。然而,传统的网络防测绘方法通常基于固定的规则,难以应对DRL智能体在测绘过程中不断变化的行为策略。因此,提出一种基于自适应扰动的网络防测绘方法,即AIP (Adaptive Interference Perturbation),旨在抵御智能化网络测绘攻击。首先,通过历史流量序列信息预测流量状况,根据预测的状况与真实流量数据的差异获取梯度信息,且使用梯度信息生成的对抗扰动返回原始流量样本中生成对抗样本;其次,采用融合流量态势-路由状态的特征重构方法通过迭代实现对稀疏字典的动态优化,进而完成对流量数据的稀疏变换;最后,将稀疏化后的对抗流量作为网络拓扑的可观测流量信息,并通过分析测绘智能体在网络拓扑链路权重分配上的变化和网络时延的差异评估AIP方法的防御性能。实验结果表明,与传统的扰动防御方法如快速梯度符号法(FGSM)和随机攻击(RA)相比,当网络中的流量强度大于25%时,AIP对攻击者的干扰效果更显著,从而导致网络拓扑中链路权重的变化幅度加大,并显而易见地影响网络时延;与静态蜜罐部署(SHD)和基于Q-Learning的动态蜜罐部署(DHD-Q)方法相比,根据延迟趋势对比结果,AIP可持续干扰攻击者,使攻击者难以发现网络中的关键路径,从而有效控制网络时延波动,在防御效率与稳定性方面具有更优的表现。
中图分类号:
王诚熠, 徐磊, 陈晋音, 邱洪君. 基于自适应扰动的网络防测绘方法[J]. 计算机应用, 2025, 45(12): 3896-3908.
Chengyi WANG, Lei XU, Jinyin CHEN, Hongjun QIU. Cyber anti-mapping method based on adaptive perturbation[J]. Journal of Computer Applications, 2025, 45(12): 3896-3908.
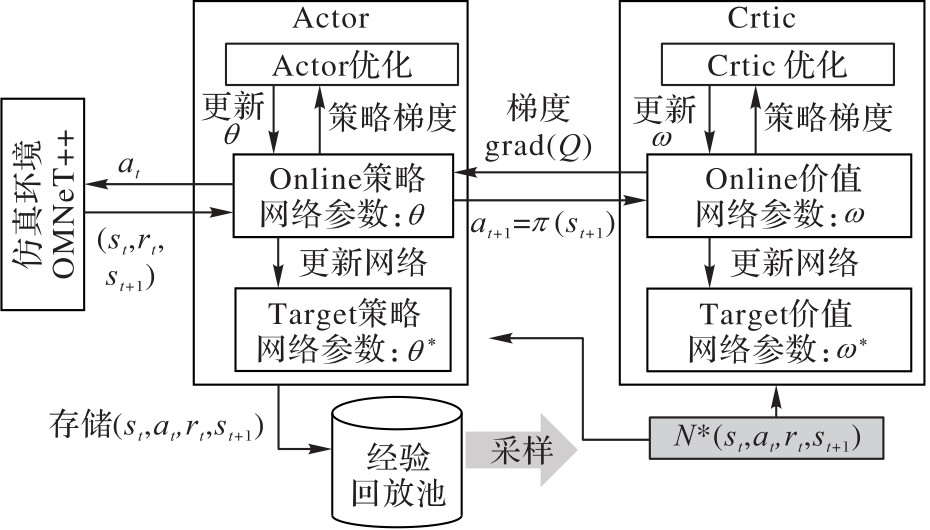
图1 DDPG算法逻辑框架
Fig. 1 DDPG algorithm logical framework
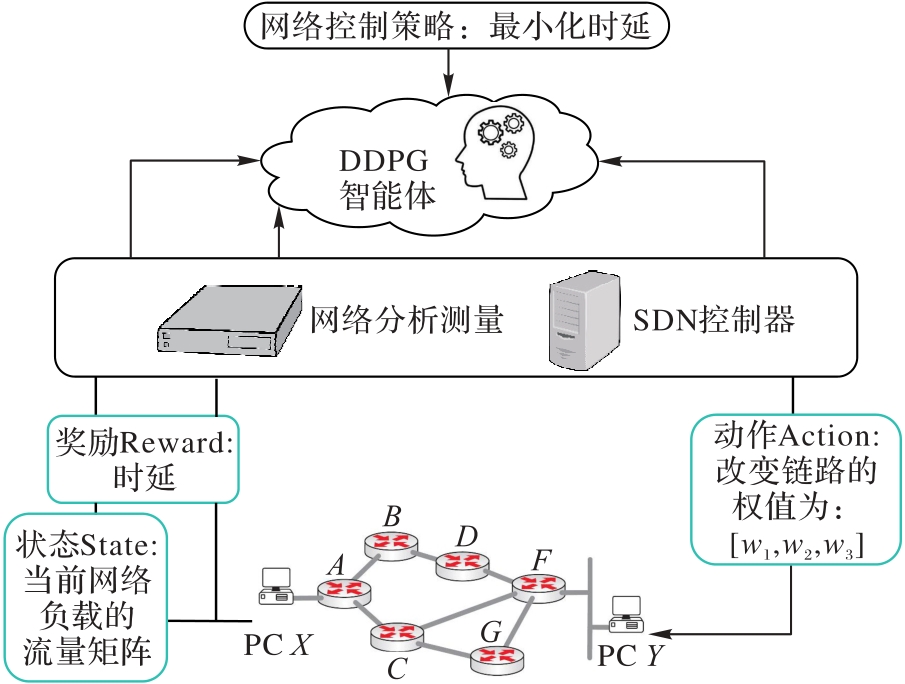
图2 基于OMNeT++的智能化网络测绘模型的组成
Fig. 2 Composition of intelligent cyber mapping model based on OMNeT++
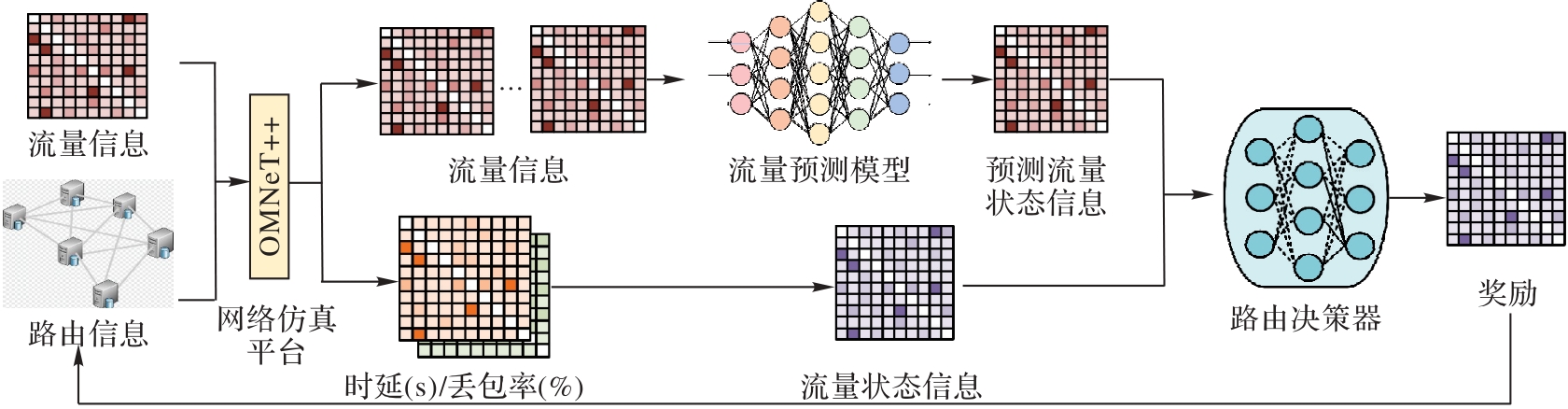
图3 AIP的框架
Fig. 3 Framework of AIP
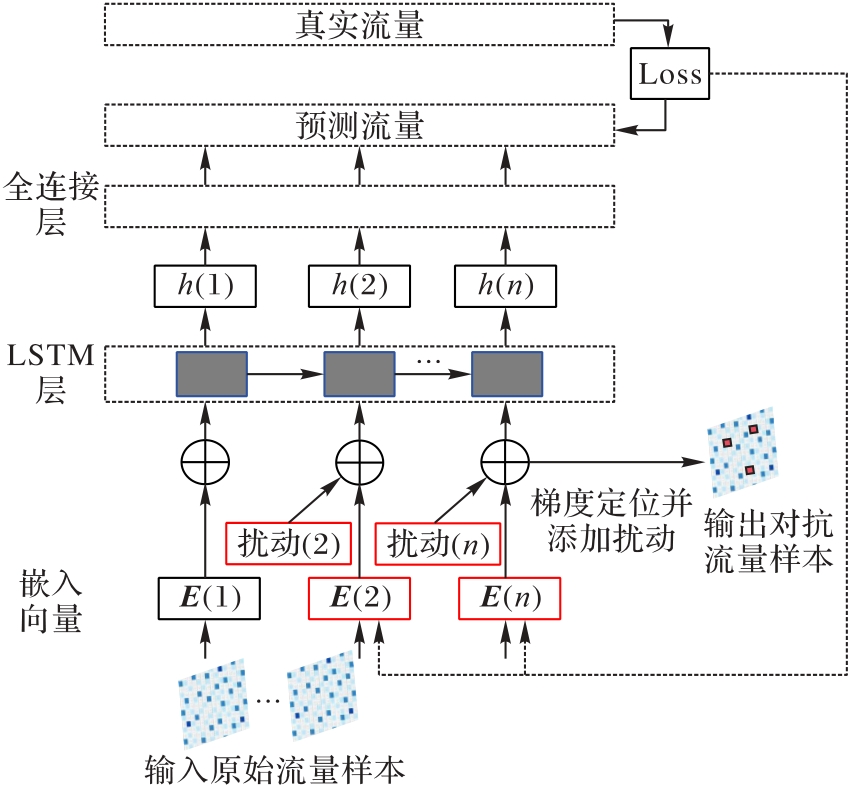
图4 自适应扰动注入机制
Fig. 4 Adaptive perturbation injection mechanism

图5 原始流量样本和对抗流量样本的对比
Fig. 5 Comparison of original traffic samples and adversarial traffic samples
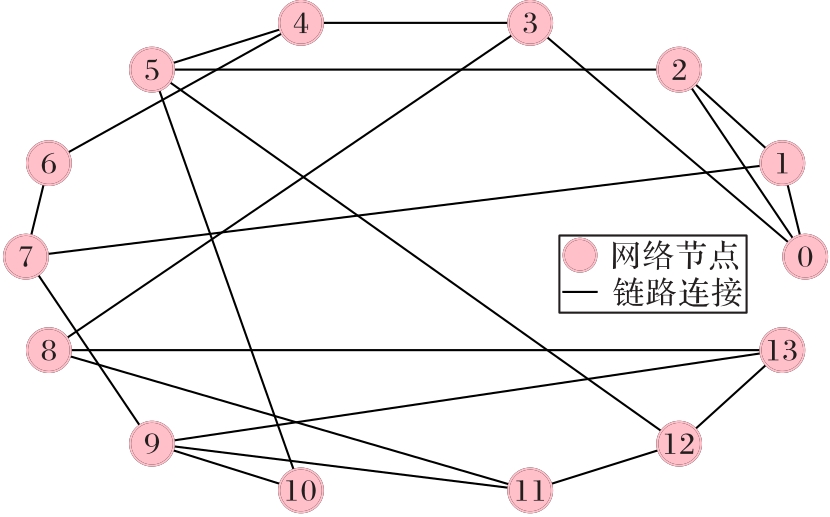
图6 网络拓扑结构
Fig. 6 Network topology
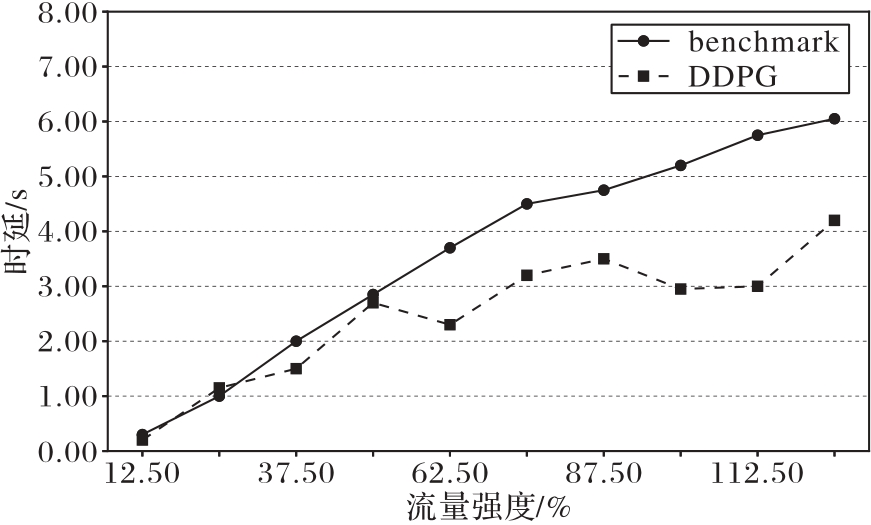
图7 不同流量强度下网络测绘时延变化趋势
Fig. 7 Time delay trend of cyber mapping under different traffic intensities
| 方法 | 不同流量强度的时延/s | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| 12.50% | 25.00% | 37.50% | 50.00% | 62.50% | 75.00% | 87.50% | 100.00% | 112.50% | 125.00% | |
| 基准线(benchmark) | 0.30 | 1.00 | 2.00 | 2.85 | 3.70 | 4.50 | 4.75 | 5.20 | 5.75 | 6.05 |
| DDPG | 0.20 | 1.15 | 1.50 | 2.70 | 2.30 | 3.20 | 3.50 | 2.95 | 3.00 | 4.20 |
表1 不同流量强度下网络测绘时延数值对比
Tab. 1 Numerical comparison of cyber mapping delay under different traffic intensities
| 方法 | 不同流量强度的时延/s | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| 12.50% | 25.00% | 37.50% | 50.00% | 62.50% | 75.00% | 87.50% | 100.00% | 112.50% | 125.00% | |
| 基准线(benchmark) | 0.30 | 1.00 | 2.00 | 2.85 | 3.70 | 4.50 | 4.75 | 5.20 | 5.75 | 6.05 |
| DDPG | 0.20 | 1.15 | 1.50 | 2.70 | 2.30 | 3.20 | 3.50 | 2.95 | 3.00 | 4.20 |
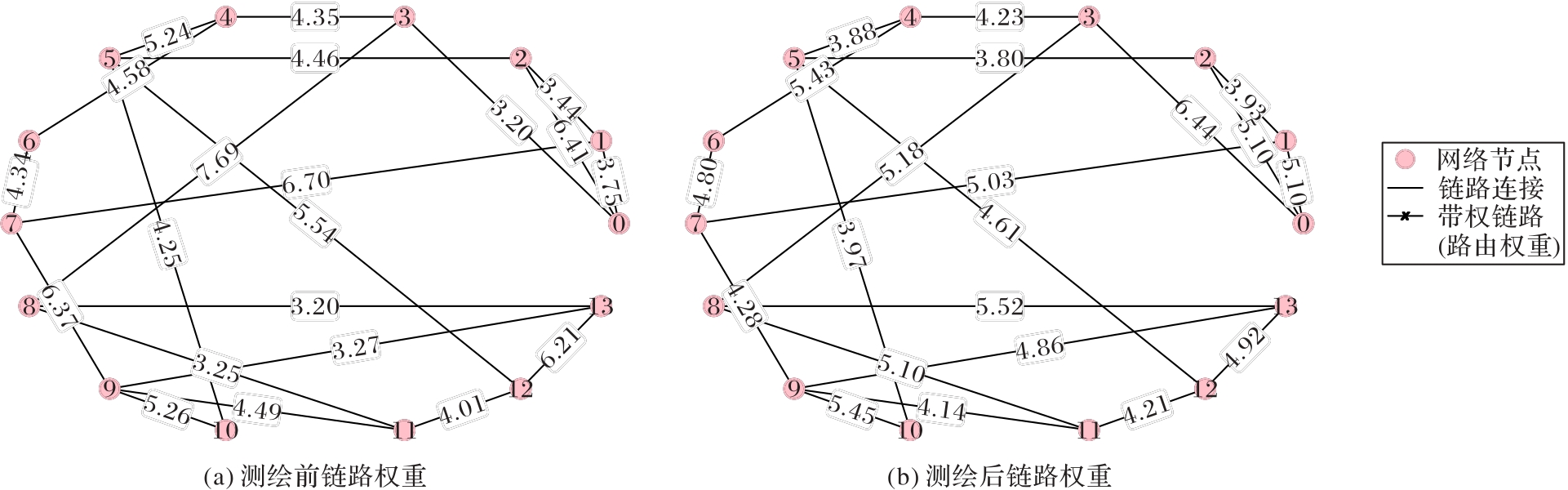
图8 测绘前后的网络权重对比
Fig. 8 Comparison of network weights before and after mapping
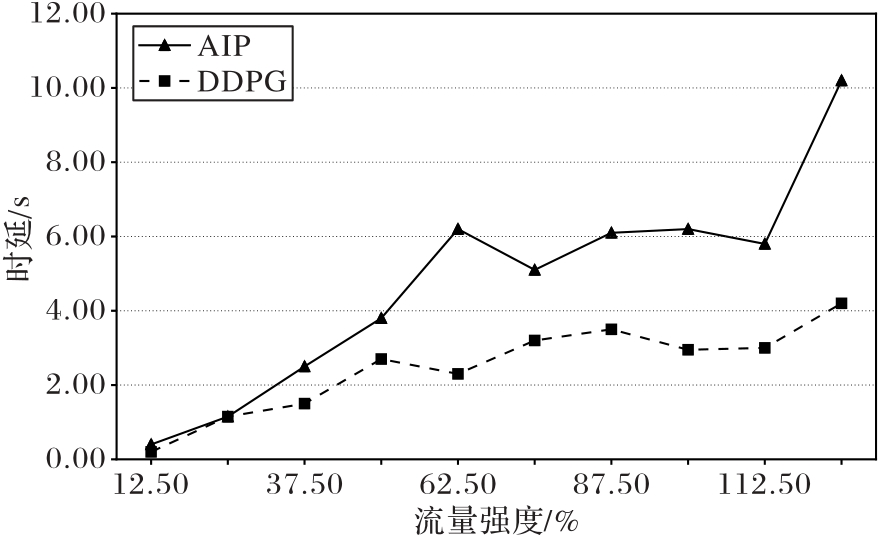
图9 不同流量强度下AIP防御效果变化趋势
Fig. 9 Trend of AIP defense performance under different traffic intensities
| 方法 | 扰动大小 | 不同流量强度的时延/s | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| 12.50% | 25.00% | 37.50% | 50.00% | 62.50% | 75.00% | 87.50% | 100.00% | 112.50% | 125.00% | ||
| DDPG | — | 0.20 | 1.15 | 1.50 | 2.70 | 2.30 | 3.20 | 3.50 | 2.95 | 3.00 | 4.20 |
| AIP | 0.1 | 0.40 | 1.15 | 2.50 | 3.80 | 6.20 | 5.10 | 6.10 | 6.20 | 5.80 | 10.20 |
表2 不同流量强度下AIP防御效果数值对比
Tab. 2 Numerical comparison of AIP defense performance under different traffic intensities
| 方法 | 扰动大小 | 不同流量强度的时延/s | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| 12.50% | 25.00% | 37.50% | 50.00% | 62.50% | 75.00% | 87.50% | 100.00% | 112.50% | 125.00% | ||
| DDPG | — | 0.20 | 1.15 | 1.50 | 2.70 | 2.30 | 3.20 | 3.50 | 2.95 | 3.00 | 4.20 |
| AIP | 0.1 | 0.40 | 1.15 | 2.50 | 3.80 | 6.20 | 5.10 | 6.10 | 6.20 | 5.80 | 10.20 |
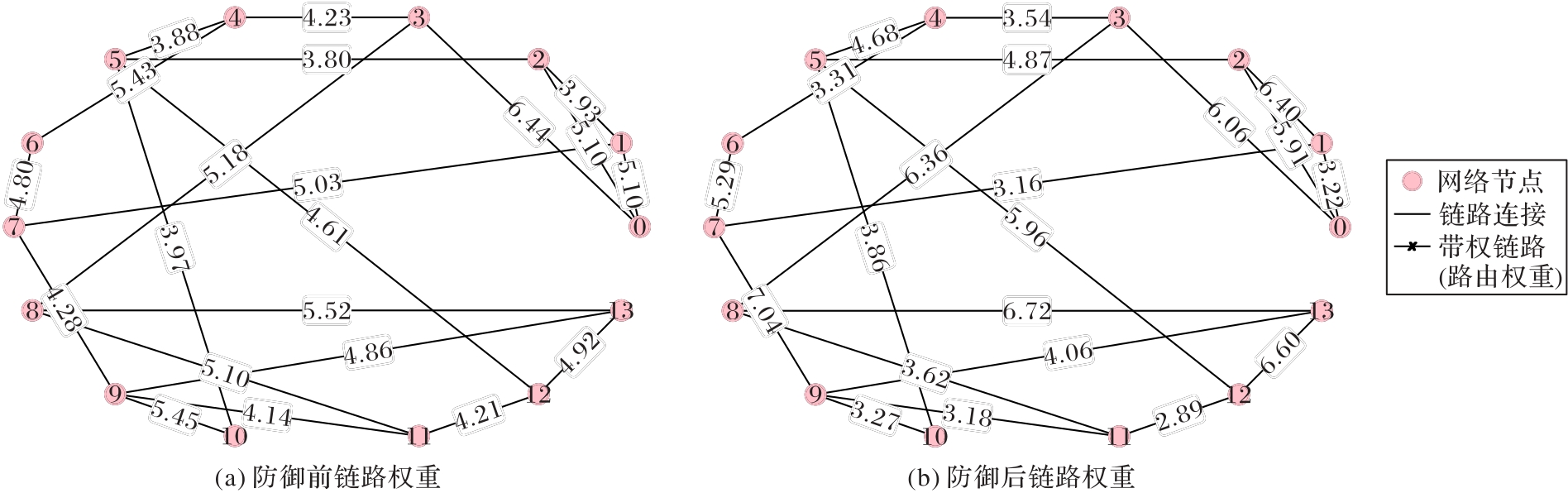
图10 AIP防御前后的网络路径权重对比
Fig. 10 Comparison of network path weights before and after AIP defense
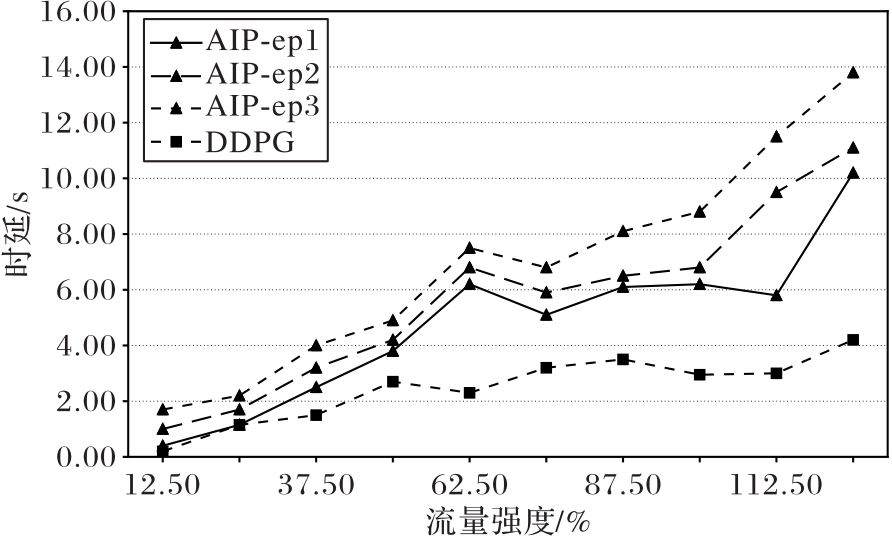
图11 不同流量强度与扰动大小下AIP防御效果变化趋势
Fig. 11 Trend of AIP defense performance under different traffic intensities and perturbation sizes
| 方法 | 扰动大小 | 不同流量强度的时延/s | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| 12.50% | 25.00% | 37.50% | 50.00% | 62.50% | 75.00% | 87.50% | 100.00% | 112.50% | 125.00% | ||
| DDPG | — | 0.20 | 1.15 | 1.50 | 2.70 | 2.30 | 3.20 | 3.50 | 2.95 | 3.00 | 4.20 |
| AIP | 0.1 | 0.40 | 1.15 | 2.50 | 3.80 | 6.20 | 5.10 | 6.10 | 6.20 | 5.80 | 10.20 |
| 0.2 | 1.00 | 1.70 | 3.20 | 4.20 | 6.80 | 5.90 | 6.50 | 6.80 | 9.50 | 11.10 | |
| 0.3 | 1.70 | 2.20 | 4.00 | 4.90 | 7.50 | 6.80 | 8.10 | 8.80 | 11.50 | 13.80 | |
表3 不同扰动大小下AIP防御效果数值对比
Tab. 3 Numerical comparison of AIP defense performance under different perturbation sizes
| 方法 | 扰动大小 | 不同流量强度的时延/s | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| 12.50% | 25.00% | 37.50% | 50.00% | 62.50% | 75.00% | 87.50% | 100.00% | 112.50% | 125.00% | ||
| DDPG | — | 0.20 | 1.15 | 1.50 | 2.70 | 2.30 | 3.20 | 3.50 | 2.95 | 3.00 | 4.20 |
| AIP | 0.1 | 0.40 | 1.15 | 2.50 | 3.80 | 6.20 | 5.10 | 6.10 | 6.20 | 5.80 | 10.20 |
| 0.2 | 1.00 | 1.70 | 3.20 | 4.20 | 6.80 | 5.90 | 6.50 | 6.80 | 9.50 | 11.10 | |
| 0.3 | 1.70 | 2.20 | 4.00 | 4.90 | 7.50 | 6.80 | 8.10 | 8.80 | 11.50 | 13.80 | |
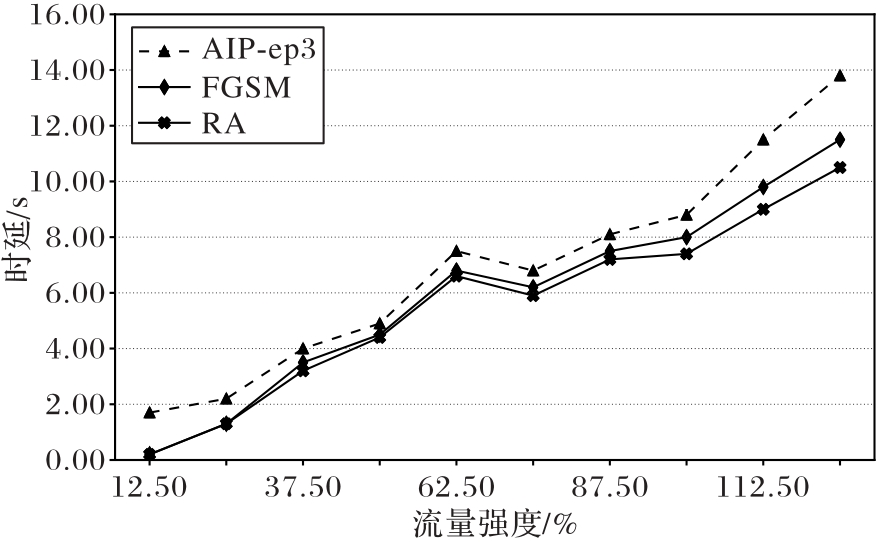
图12 不同流量强度下各防御方法效果变化趋势
Fig. 12 Trend of defense performance of different methods under different traffic intensities
| 方法 | 扰动大小 | 不同流量强度的时延/s | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| 12.50% | 25.00% | 37.50% | 50.00% | 62.50% | 75.00% | 87.50% | 100.00% | 112.50% | 125.00% | ||
| FGSM | 0.3 | 0.20 | 1.30 | 3.50 | 4.50 | 6.80 | 6.20 | 7.50 | 8.00 | 9.80 | 11.50 |
| RA | 0.3 | 0.20 | 1.30 | 3.20 | 4.40 | 6.60 | 5.90 | 7.20 | 7.40 | 9.00 | 10.50 |
| AIP | 0.3 | 1.70 | 2.20 | 4.00 | 4.90 | 7.50 | 6.80 | 8.10 | 8.80 | 11.50 | 13.80 |
表4 不同流量强度下各防御方法数值对比
Tab. 4 Numerical comparison of different defense methods under different traffic intensities
| 方法 | 扰动大小 | 不同流量强度的时延/s | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| 12.50% | 25.00% | 37.50% | 50.00% | 62.50% | 75.00% | 87.50% | 100.00% | 112.50% | 125.00% | ||
| FGSM | 0.3 | 0.20 | 1.30 | 3.50 | 4.50 | 6.80 | 6.20 | 7.50 | 8.00 | 9.80 | 11.50 |
| RA | 0.3 | 0.20 | 1.30 | 3.20 | 4.40 | 6.60 | 5.90 | 7.20 | 7.40 | 9.00 | 10.50 |
| AIP | 0.3 | 1.70 | 2.20 | 4.00 | 4.90 | 7.50 | 6.80 | 8.10 | 8.80 | 11.50 | 13.80 |
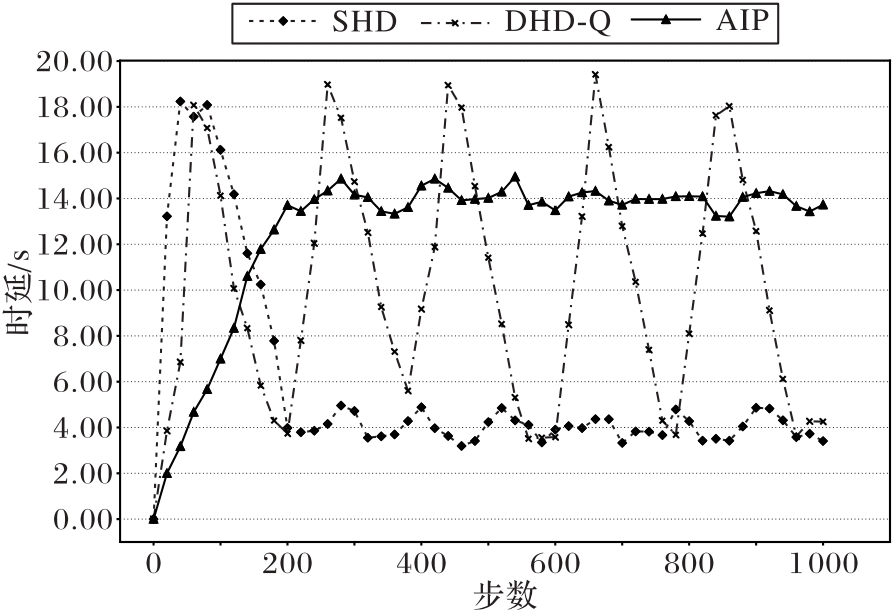
图13 不同防御方式的延迟趋势对比
Fig. 13 Comparison of latency trends for different defense methods
| 方法 | 超参数 | 不同交互步数的时延/s | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 扰动大小 | 流量强度/% | 100 | 200 | 300 | 400 | 500 | 600 | 700 | 800 | 900 | 1 000 | |
| SHD | 0.3 | 125 | 16.10 | 4.00 | 4.70 | 4.90 | 4.20 | 3.90 | 3.30 | 4.30 | 4.90 | 3.40 |
| DHD-Q | 0.3 | 125 | 14.10 | 3.70 | 14.70 | 9.20 | 11.40 | 3.60 | 12.80 | 8.10 | 12.60 | 4.30 |
| AIP | 0.3 | 125 | 7.10 | 13.80 | 14.20 | 14.60 | 14.00 | 13.40 | 13.70 | 14.10 | 14.20 | 13.70 |
表5 AIP与不同节点欺骗防御方法的效果对比
Tab. 5 Effect comparison of AIP and different node-cheating defense methods
| 方法 | 超参数 | 不同交互步数的时延/s | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 扰动大小 | 流量强度/% | 100 | 200 | 300 | 400 | 500 | 600 | 700 | 800 | 900 | 1 000 | |
| SHD | 0.3 | 125 | 16.10 | 4.00 | 4.70 | 4.90 | 4.20 | 3.90 | 3.30 | 4.30 | 4.90 | 3.40 |
| DHD-Q | 0.3 | 125 | 14.10 | 3.70 | 14.70 | 9.20 | 11.40 | 3.60 | 12.80 | 8.10 | 12.60 | 4.30 |
| AIP | 0.3 | 125 | 7.10 | 13.80 | 14.20 | 14.60 | 14.00 | 13.40 | 13.70 | 14.10 | 14.20 | 13.70 |
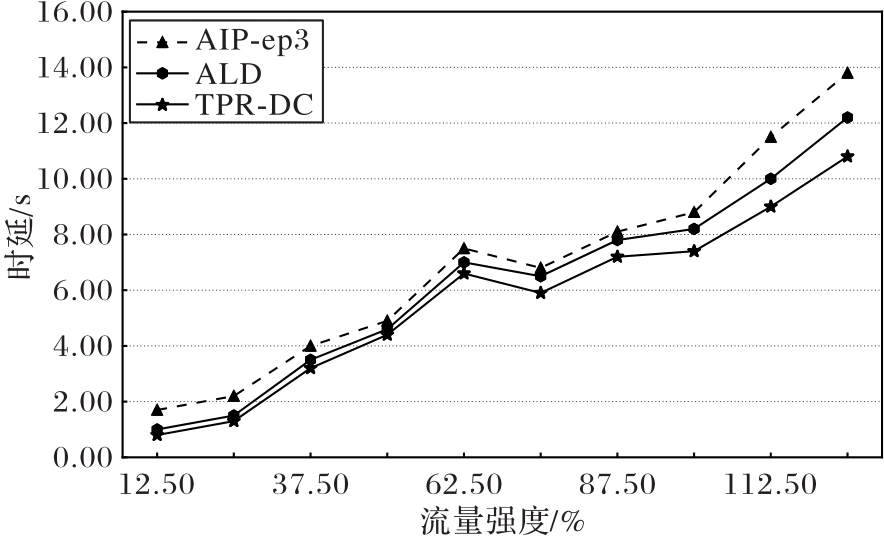
图14 AIP不同组件防御效果变化趋势
Fig. 14 Trend of defense performance of different components in AIP
| 方法 | 扰动大小 | 不同流量强度下的时延/s | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| 12.50% | 25.00% | 37.50% | 50.00% | 62.50% | 75.00% | 87.50% | 100.00% | 112.50% | 125.00% | ||
| ALD | 0.3 | 1.00 | 1.50 | 3.50 | 4.60 | 7.00 | 6.50 | 7.80 | 8.20 | 10.00 | 12.20 |
| TPR-DC | — | 0.80 | 1.30 | 3.20 | 4.40 | 6.60 | 5.90 | 7.20 | 7.40 | 9.00 | 10.80 |
| AIP | 0.3 | 1.70 | 2.20 | 4.00 | 4.90 | 7.50 | 6.80 | 8.10 | 8.80 | 11.50 | 13.80 |
表6 AIP不同组件防御效果数值对比
Tab. 6 Numerical comparison of defense performance of different components in AIP
| 方法 | 扰动大小 | 不同流量强度下的时延/s | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| 12.50% | 25.00% | 37.50% | 50.00% | 62.50% | 75.00% | 87.50% | 100.00% | 112.50% | 125.00% | ||
| ALD | 0.3 | 1.00 | 1.50 | 3.50 | 4.60 | 7.00 | 6.50 | 7.80 | 8.20 | 10.00 | 12.20 |
| TPR-DC | — | 0.80 | 1.30 | 3.20 | 4.40 | 6.60 | 5.90 | 7.20 | 7.40 | 9.00 | 10.80 |
| AIP | 0.3 | 1.70 | 2.20 | 4.00 | 4.90 | 7.50 | 6.80 | 8.10 | 8.80 | 11.50 | 13.80 |
| [1] | JIANG B, ORMELING F. Mapping cyberspace: visualizing, analysing and exploring virtual worlds[J]. The Cartographic Journal, 2000, 37(2): 117-122. |
| [2] | 刘红,姚旺君,孙彻,等. 网络空间测绘系统分类及应用综述[J]. 信息技术与网络安全, 2021, 40(10): 16-21, 28. |
| LIU H, YAO W J, SUN C, et al. Classification and application of cyberspace surveying and mapping system[J]. Information Technology and Network Security, 2021, 40(10): 16-21, 28. | |
| [3] | AGHDAM H H, GONZALEZ-GARCIA A, LOPEZ A, et al. Active learning for deep detection neural networks[C]// Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision. Piscataway: IEEE, 2019: 3671-3679. |
| [4] | 赵静静,衷璐洁. 基于排队时延主动探测的多路传输拥塞控制[J]. 计算机工程与设计, 2021, 42(3): 628-635. |
| ZHAO J J, ZHONG L J. Congestion control of multipath transmission based on proactive RTT probing[J]. Computer Engineering and Design, 2021, 42(3): 628-635. | |
| [5] | RANJANI H G, PUTHENNURAKEL S P, BRISEBOIS A, et al. Time series based approach for detecting passive intermodulation occurrences in cellular network[C]// Proceedings of the 14th International Conference on Communication Systems and Networks. Piscataway: IEEE, 2022: 630-638. |
| [6] | 王永霞. 计量实验室内部网络资产主被动协同探测技术的研究与分析[J]. 实验与分析, 2023, 1(2): 47-52. |
| WANG Y X. Internal network assets of active and passive collaborative detection technology research and analysis of measurement laboratory[J]. Labor Praxis, 2023, 1(2): 47-52. | |
| [7] | HUANG X, ALI S, WANG C, et al. Deep domain adaptation based cloud type detection using active and passive satellite data[C]// Proceedings of the 2020 IEEE International Conference on Big Data. Piscataway: IEEE, 2020: 1330-1337. |
| [8] | ANJUM N, LATIF Z, LEE C, et al. MIND: a multi-source data fusion scheme for intrusion detection in networks[J]. Sensors, 2021, 21(14): No.4941. |
| [9] | ZABALA L, DONCEL J, FERRO A. Optimality of a network monitoring agent and validation in a real probe[J]. Mathematics, 2023, 11(3): No.610. |
| [10] | CASAS-VELASCO D M, RENDON O M C, FONSECA N L S DA. Intelligent routing based on reinforcement learning for software-defined networking[J]. IEEE Transactions on Network and Service Management, 2021, 18(1): 870-881. |
| [11] | DING R, XU Y, GAO F, et al. Deep reinforcement learning for router selection in network with heavy traffic[J]. IEEE Access, 2019, 7: 37109-37120. |
| [12] | XU C, ZHUANG W, ZHANG H. A deep-reinforcement learning approach for SDN routing optimization[C]// Proceedings of the 4th International Conference on Computer Science and Application Engineering. New York: ACM, 2020: No.26. |
| [13] | PAN W, LIU S Q. Deep reinforcement learning for the dynamic and uncertain vehicle routing problem[J]. Applied Intelligence, 2023, 53(1): 405-422. |
| [14] | LILLICRAP T P, HUNT J J, PRITZEL A, et al. Continuous control with deep reinforcement learning [EB/OL]. [2024-11-25] . |
| [15] | YOUNG G. Hype cycle for threat-facing technologies, 2017[R/OL]. [2024-11-19]. . |
| [16] | HORÁK K, ZHU Q, BOŠANSKÝ B. Manipulating adversary’s belief: a dynamic game approach to deception by design for proactive network security[C]// Proceedings of the 2017 International Conference on Decision and Game Theory for Security, LNCS 10575. Cham: Springer, 2017: 273-294. |
| [17] | SAYED M A, ANWAR A H, KIEKINTVELD C, et al. Honeypot allocation for cyber deception in dynamic tactical networks: a game theoretic approach[C]// Proceedings of the 2023 International Conference on Decision and Game Theory for Security, LNCS 14167. Cham: Springer, 2023: 195-214. |
| [18] | WANG S, PEI Q, WANG J, et al. An intelligent deployment policy for deception resources based on reinforcement learning[J]. IEEE Access, 2020, 8: 35792-35804. |
| [19] | 胡永进,马骏,郭渊博,等. 基于多阶段网络欺骗博弈的主动防御研究[J]. 通信学报, 2020, 41(8): 32-42. |
| HU Y J, MA J, GUO Y B, et al. Research on active defense based on multi-stage cyber deception game[J]. Journal on Communications, 2020, 41(8): 32-42. | |
| [20] | LI H, GUO Y, HUO S, et al. Defensive deception framework against reconnaissance attacks in the cloud with deep reinforcement learning[J]. SCIENCE CHINA Information Sciences, 2022, 65(7): No.170305. |
| [21] | 刘小虎,张恒巍,张玉臣,等. 欺骗谋略在网络空间防御行动中运用[J]. 指挥与控制学报, 2024, 10(1): 117-121. |
| LIU X H, ZHANG H W, ZHANG Y C, et al. Deception strategy in cyberspace defense actions[J]. Journal of Command and Control, 2024, 10(1): 117-121. | |
| [22] | 雷程,马多贺,张红旗,等. 基于最优路径跳变的网络移动目标防御技术[J]. 通信学报, 2017, 38(3): 133-143. |
| LEI C, MA D H, ZHANG H Q, et al. Network moving target defense technique based on optimal forwarding path migration[J]. Journal on Communications, 2017, 38(3): 133-143. | |
| [23] | QU Y, MA H, JIANG Y, et al. A network intrusion detection method based on domain confusion[J]. Electronics, 2023, 12(5): No.1255. |
| [24] | KIM J, NAM J, LEE S, et al. BottleNet: hiding network bottlenecks using SDN-based topology deception [J]. IEEE Transactions on Information Forensics and Security, 2021, 16: 3138-3153. |
| [25] | XU W, CHEN L, YANG H. A comprehensive discussion on deep reinforcement learning [C]// Proceedings of the 2021 International Conference on Communications, Information System and Computer Engineering. Piscataway: IEEE, 2021: 697-702. |
| [26] | SILVER D, LEVER G, HEESS N, et al. Deterministic policy gradient algorithms[C]// Proceedings of the 31st International Conference on Machine Learning. New York: JMLR.org, 2014: 387-395. |
| [27] | KAISER Ł, BABAEIZADEH M, MILOS P, et al. Model-based reinforcement learning for Atari [EB/OL]. [2024-11-19]. . |
| [28] | 杜智华,赖振清. 基于深度强化学习实时战略卡牌游戏对战设计[J]. 计算机仿真, 2022, 39(2): 260-265. |
| DU Z H, LAI Z Q. Design of real-time strategic card game based on deep reinforcement learning[J]. Computer Simulation, 2022, 39(2): 260-265. | |
| [29] | ZHOU M, YU Y, QU X. Development of an efficient driving strategy for connected and automated vehicles at signalized intersections: a reinforcement learning approach[J]. IEEE Transactions on Intelligent Transportation Systems, 2020, 21(1): 433-443. |
| [30] | 周恒恒,高松,王鹏伟,等. 基于深度强化学习的智能车辆行为决策研究[J]. 科学技术与工程, 2024, 24(12): 5194-5203. |
| ZHOU H H, GAO S, WANG P W, et al. Intelligent vehicles behavior decision-making based on deep reinforcement learning[J]. Science Technology and Engineering, 2024, 24(12): 5194-5203. | |
| [31] | YU L, XIE W, XIE D, et al. Deep reinforcement learning for smart home energy management[J]. IEEE Internet of Things Journal, 2020, 7(4): 2751-2762. |
| [32] | KIM G, KIM Y, LIM H. Deep reinforcement learning-based routing on software-defined networks[J]. IEEE Access, 2022, 10: 18121-18133. |
| [33] | HE Q, WANG Y, WANG X, et al. Routing optimization with deep reinforcement learning in knowledge defined networking[J]. IEEE Transactions on Mobile Computing, 2024, 23(2): 1444-1455. |
| [34] | 高陈强,朱向阳,喻敬海. 基于OMNeT++的大规模确定性网络仿真实践[J]. 电信科学, 2023, 39(11): 59-68. |
| GAO C Q, ZHU X Y, YU J H. Large-scale OMNeT++-based deterministic networking simulation practice[J]. Telecommunications Science, 2023, 39(11): 59-68. | |
| [35] | ROUGHAN M. Simplifying the synthesis of internet traffic matrices[J]. ACM SIGCOMM Computer Communication Review, 2005, 35(5): 93-96. |
| [1] | 薛天宇, 李爱萍, 段利国. 联合任务卸载和资源优化的车辆边缘计算方案[J]. 《计算机应用》唯一官方网站, 2025, 45(6): 1766-1775. |
| [2] | 许鹏程, 何磊, 李川, 钱炜祺, 赵暾. 基于Transformer的深度符号回归方法[J]. 《计算机应用》唯一官方网站, 2025, 45(5): 1455-1463. |
| [3] | 王华华, 黄梁, 陈甲杰, 方杰宁. 基于深度强化学习的低轨卫星多波束子载波动态分配算法[J]. 《计算机应用》唯一官方网站, 2025, 45(2): 571-577. |
| [4] | 王靖, 方旭明. Wi-Fi7多链路通感一体化的功率和信道联合智能分配算法[J]. 《计算机应用》唯一官方网站, 2025, 45(2): 563-570. |
| [5] | 卫琳, 张世豪, 和孟佯. 面向算力网络的工作流任务优化与节能卸载方法[J]. 《计算机应用》唯一官方网站, 2025, 45(12): 3916-3924. |
| [6] | 曾君, 童英华, 王得芳. 基于累积概率波动和自动化聚类的异常检测方法[J]. 《计算机应用》唯一官方网站, 2025, 45(12): 3864-3871. |
| [7] | 许浩翔, 余敦辉, 邓怡辰, 肖奎. 基于分层强化学习的知识图谱约束问答模型[J]. 《计算机应用》唯一官方网站, 2025, 45(12): 3764-3770. |
| [8] | 况翔, 马震, 朱万春, 张智, 崔云飞. 基于编解码结构强化学习的安全可靠服务功能链部署[J]. 《计算机应用》唯一官方网站, 2025, 45(12): 3947-3956. |
| [9] | 陈晓娟, 张薇. 基于强化学习的无人机乡村末端配送任务分配[J]. 《计算机应用》唯一官方网站, 2025, 45(12): 4055-4063. |
| [10] | 周帅, 符浩, 刘伟. 基于时空Transformer的混合回报隐式Q学习人群导航[J]. 《计算机应用》唯一官方网站, 2025, 45(11): 3666-3673. |
| [11] | 赵敬华, 张柱, 吕锡婷, 林慧丹. 基于超图神经网络的多尺度信息传播预测模型[J]. 《计算机应用》唯一官方网站, 2025, 45(11): 3529-3539. |
| [12] | 卫琳, 李金阳, 王亚杰, 和孟佯. 算力网络中基于多维资源度量和重调度的高可靠匹配方法[J]. 《计算机应用》唯一官方网站, 2025, 45(11): 3632-3641. |
| [13] | 张焱鹏, 赵于前, 张帆, 丘腾海, 桂瑰, 余伶俐. 基于改进MAML与GVAE的容量约束车辆路径问题求解方法[J]. 《计算机应用》唯一官方网站, 2025, 45(11): 3642-3648. |
| [14] | 王昱, 赵明月, 周小琳. 养老院场景下基于任务的辅助机器人路径规划[J]. 《计算机应用》唯一官方网站, 2025, 45(10): 3270-3276. |
| [15] | 缪孜珺, 罗飞, 丁炜超, 董文波. 基于全局状态预测与公平经验重放的交通信号控制算法[J]. 《计算机应用》唯一官方网站, 2025, 45(1): 337-344. |
| 阅读次数 | ||||||
|
全文 |
|
|||||
|
摘要 |
|
|||||