


《计算机应用》唯一官方网站 ›› 2025, Vol. 45 ›› Issue (12): 3820-3828.DOI: 10.11772/j.issn.1001-9081.2024121751
赵红燕, 郭力华, 刘春霞( ), 王日云
), 王日云
收稿日期:2024-12-12
修回日期:2025-03-02
接受日期:2025-03-04
发布日期:2025-03-13
出版日期:2025-12-10
通讯作者:
刘春霞
作者简介:赵红燕(1977—),女,山西运城人,副教授,博士,CCF会员,主要研究方向:自然语言处理、智能信息处理
Hongyan ZHAO, Lihua GUO, Chunxia LIU(), Riyun WANG
Received:2024-12-12
Revised:2025-03-02
Accepted:2025-03-04
Online:2025-03-13
Published:2025-12-10
Contact:
Chunxia LIU
About author:ZHAO Hongyan, born in 1977, Ph. D., associate professor. Her research interests include natural language processing, intelligent information processing.Supported by:摘要:
长文档摘要生成面临句间关系的捕捉、长距离依赖及文档信息的高效编码与提取等难题,一直是自然语言处理领域的一个难点任务。同时,科学文献通常包含多个章节和段落,具有复杂的层次结构,使科学文献的摘要生成任务更具挑战性。针对以上问题,提出一种基于多图神经网络(GNN)和图对比学习(GCL)的科学文献摘要模型(MGCSum)。首先,对于输入的文档,通过同构GNN和异构GNN分别建模句内与句间关系,以生成初始句子表示;其次,将这些句子表示馈送到一个多头超图注意网络(HGAT),并在其中利用自注意机制充分捕捉节点和边之间的关系,从而进一步更新和学习句间的表示;再次,引入GCL模块增强全局主题感知,从而提升句子表示的语义一致性和区分度;最后,采用多层感知器(MLP)和归一化层计算一个得分,用于判断句子是否应被选为摘要。在PubMed和ArXiv数据集上的实验结果表明,MGCSum模型的表现优于多数基线模型。具体地,在PubMed数据集上,MGCSum模型的ROUGE-1、ROUGE-2和ROUGE-L分别达到了48.97%、23.15%和44.09%,相比现有的先进模型HAESum (Hierarchical Attention graph for Extractive document Summarization)分别提高了0.20、0.71和0.26个百分点。可见,通过结合多GNN和GCL,MGCSum模型能够更有效地捕捉文献的层次结构信息和句间关系,提升了摘要生成的准确性和语义一致性,展现了它在科学文献摘要生成任务中的优势。
中图分类号:
赵红燕, 郭力华, 刘春霞, 王日云. 基于多图神经网络和图对比学习的科学文献摘要模型[J]. 计算机应用, 2025, 45(12): 3820-3828.
Hongyan ZHAO, Lihua GUO, Chunxia LIU, Riyun WANG. Scientific document summarization model based on multi-graph neural network and graph contrastive learning[J]. Journal of Computer Applications, 2025, 45(12): 3820-3828.
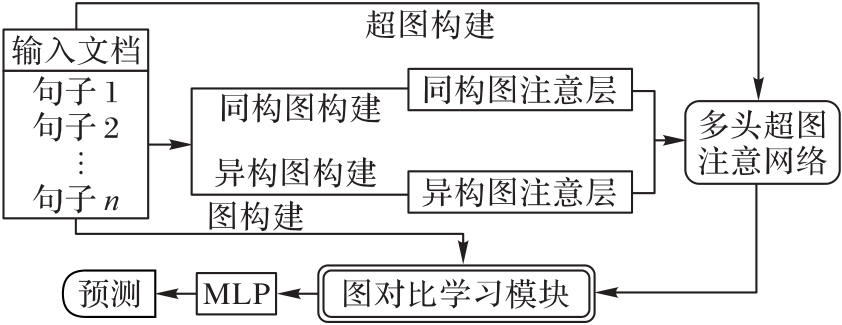
图1 MGCSum的总框架
Fig. 1 Overall framework of MGCSum
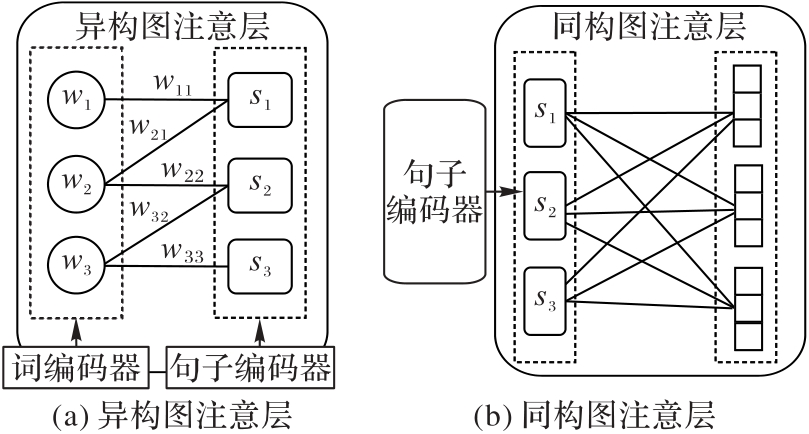
图2 异构图注意层和同构图注意层
Fig. 2 Heterogeneous graph attention layer and homogeneous graph attention layer
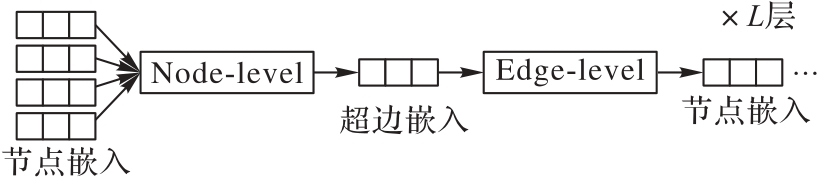
图3 多头HGAT
Fig. 3 Multi-head HGAT
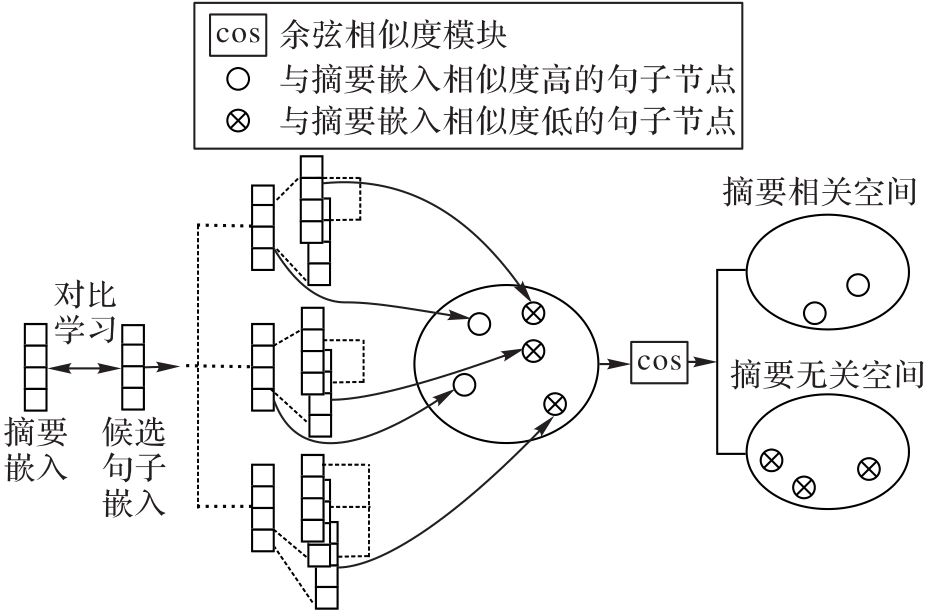
图4 GCL模块
Fig. 4 GCL module
| 数据集 | 文档(篇数) | 平均文档 长度(词数) | 平均摘要 长度(词数) | ||
|---|---|---|---|---|---|
| 训练集 | 验证集 | 测试集 | |||
| ArXiv | 202 703 | 6 436 | 6 439 | 4 938 | 220 |
| PubMed | 116 669 | 6 630 | 6 657 | 3 016 | 203 |
表1 ArXiv和PubMed数据集的统计信息
Tab.1 Statistics of ArXiv and PubMed datasets
| 数据集 | 文档(篇数) | 平均文档 长度(词数) | 平均摘要 长度(词数) | ||
|---|---|---|---|---|---|
| 训练集 | 验证集 | 测试集 | |||
| ArXiv | 202 703 | 6 436 | 6 439 | 4 938 | 220 |
| PubMed | 116 669 | 6 630 | 6 657 | 3 016 | 203 |
| 模型 | PubMed | ArXiv | ||||
|---|---|---|---|---|---|---|
| R-1 | R-2 | R-L | R-1 | R-2 | R-L | |
| Oracle | 55.05 | 27.48 | 49.11 | 53.89 | 23.07 | 46.54 |
| LexRank | 39.19 | 13.89 | 34.59 | 33.85 | 10.73 | 28.99 |
| PACSUM | 39.79 | 14.00 | 36.09 | 38.57 | 10.93 | 34.33 |
| HIPORANK | 43.58 | 17.00 | 39.31 | 39.34 | 12.56 | 34.89 |
| Cheng&Lapata | 43.89 | 18.53 | 30.17 | 42.24 | 15.97 | 27.88 |
| ExtSum-LG | 44.85 | 19.70 | 31.43 | 43.62 | 17.36 | 29.14 |
| HEGEL | 47.13 | 21.00 | 42.18 | 46.41 | 18.17 | 39.89 |
| CHANGES | 46.43 | 21.17 | 41.58 | 45.61 | 18.02 | 40.06 |
| MTGNN | 48.42 | 22.26 | 43.66 | 46.39 | 18.58 | 40.50 |
| HAESum | 48.77 | 22.44 | 43.83 | 47.24 | 19.44 | 41.34 |
| PEGASUS | 45.49 | 19.90 | 42.42 | 44.70 | 17.27 | 25.80 |
| BigBird | 46.32 | 20.65 | 42.33 | 46.63 | 19.02 | 41.77 |
| ChatGLM3-6B-32k | 40.95 | 15.79 | 37.09 | 39.81 | 14.14 | 35.36 |
| MGCSum | 48.97 | 23.15 | 44.09 | 47.65 | 19.71 | 41.63 |
表2 PubMed 和 ArXiv 数据集上的实验结果 (%)
Tab.2 Experimental results on PubMed and ArXiv datasets
| 模型 | PubMed | ArXiv | ||||
|---|---|---|---|---|---|---|
| R-1 | R-2 | R-L | R-1 | R-2 | R-L | |
| Oracle | 55.05 | 27.48 | 49.11 | 53.89 | 23.07 | 46.54 |
| LexRank | 39.19 | 13.89 | 34.59 | 33.85 | 10.73 | 28.99 |
| PACSUM | 39.79 | 14.00 | 36.09 | 38.57 | 10.93 | 34.33 |
| HIPORANK | 43.58 | 17.00 | 39.31 | 39.34 | 12.56 | 34.89 |
| Cheng&Lapata | 43.89 | 18.53 | 30.17 | 42.24 | 15.97 | 27.88 |
| ExtSum-LG | 44.85 | 19.70 | 31.43 | 43.62 | 17.36 | 29.14 |
| HEGEL | 47.13 | 21.00 | 42.18 | 46.41 | 18.17 | 39.89 |
| CHANGES | 46.43 | 21.17 | 41.58 | 45.61 | 18.02 | 40.06 |
| MTGNN | 48.42 | 22.26 | 43.66 | 46.39 | 18.58 | 40.50 |
| HAESum | 48.77 | 22.44 | 43.83 | 47.24 | 19.44 | 41.34 |
| PEGASUS | 45.49 | 19.90 | 42.42 | 44.70 | 17.27 | 25.80 |
| BigBird | 46.32 | 20.65 | 42.33 | 46.63 | 19.02 | 41.77 |
| ChatGLM3-6B-32k | 40.95 | 15.79 | 37.09 | 39.81 | 14.14 | 35.36 |
| MGCSum | 48.97 | 23.15 | 44.09 | 47.65 | 19.71 | 41.63 |
| 模型 | PubMed | ArXiv | ||||
|---|---|---|---|---|---|---|
| R-1 | R-2 | R-L | R-1 | R-2 | R-L | |
| MGCSum | 48.97 | 23.15 | 44.09 | 47.65 | 19.71 | 41.63 |
| w/o Homograph | 48.01 | 22.15 | 42.93 | 46.54 | 19.13 | 41.21 |
| w/o Hetergraph | 47.31 | 21.76 | 42.64 | 46.41 | 19.02 | 41.17 |
| w/o Hypergraph | 47.62 | 22.04 | 42.71 | 46.03 | 18.94 | 40.92 |
| w/o GCL | 47.53 | 21.85 | 42.69 | 46.17 | 19.05 | 40.95 |
表3 PubMed和ArXiv数据集上的消融研究结果 (%)
Tab.3 Ablation study results on PubMed and ArXiv datasets
| 模型 | PubMed | ArXiv | ||||
|---|---|---|---|---|---|---|
| R-1 | R-2 | R-L | R-1 | R-2 | R-L | |
| MGCSum | 48.97 | 23.15 | 44.09 | 47.65 | 19.71 | 41.63 |
| w/o Homograph | 48.01 | 22.15 | 42.93 | 46.54 | 19.13 | 41.21 |
| w/o Hetergraph | 47.31 | 21.76 | 42.64 | 46.41 | 19.02 | 41.17 |
| w/o Hypergraph | 47.62 | 22.04 | 42.71 | 46.03 | 18.94 | 40.92 |
| w/o GCL | 47.53 | 21.85 | 42.69 | 46.17 | 19.05 | 40.95 |
| 句子数 | PubMed | ArXiv | ||||
|---|---|---|---|---|---|---|
| R-1/% | R-2/% | R-L/% | R-1/% | R-2/% | R-L/% | |
| 50 | 46.25 | 21.07 | 41.82 | 45.47 | 17.24 | 39.41 |
| 100 | 47.94 | 22.35 | 43.47 | 46.87 | 18.82 | 40.95 |
| 150 | 48.69 | 22.97 | 43.75 | 47.43 | 19.44 | 41.37 |
| 200 | 48.97 | 23.15 | 44.09 | 47.65 | 19.71 | 41.63 |
表4 MGCSum在不同最大句子数下的实验结果
Tab.4 Experimental results of MGCSum with different largest sentence counts
| 句子数 | PubMed | ArXiv | ||||
|---|---|---|---|---|---|---|
| R-1/% | R-2/% | R-L/% | R-1/% | R-2/% | R-L/% | |
| 50 | 46.25 | 21.07 | 41.82 | 45.47 | 17.24 | 39.41 |
| 100 | 47.94 | 22.35 | 43.47 | 46.87 | 18.82 | 40.95 |
| 150 | 48.69 | 22.97 | 43.75 | 47.43 | 19.44 | 41.37 |
| 200 | 48.97 | 23.15 | 44.09 | 47.65 | 19.71 | 41.63 |
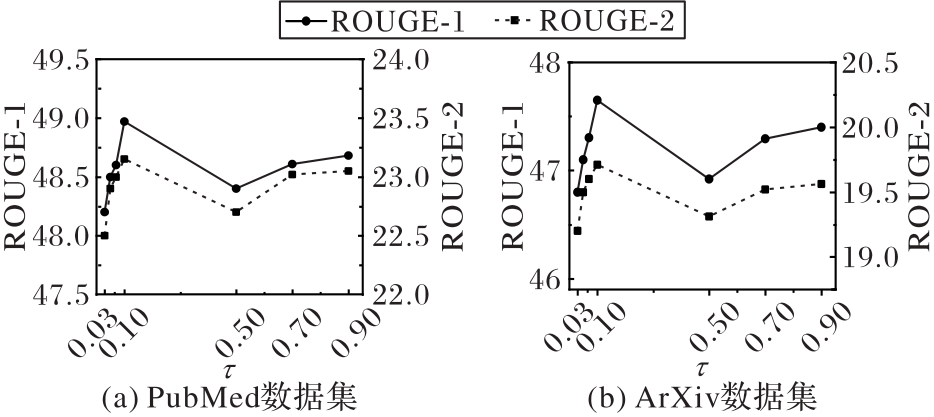
图5 不同温度因子下的ROUGE-1和ROUGE-2
Fig. 5 ROUGE-1 and ROUGE-2 under different temperature factors
| [1] | 李金鹏,张闯,陈小军,等. 自动文本摘要研究综述[J]. 计算机研究与发展, 2021, 58(1): 1-21. |
| LI J P, ZHANG C, CHEN X J, et al. Survey on automatic text summarization[J]. Journal of Computer Research and Development, 2021, 58(1): 1-21. | |
| [2] | LIU Y, LAPATA M. Text summarization with pretrained encoders[EB/OL]. [2024-10-01].. |
| [3] | DEVLIN J, CHANG M W, LEE K, et al. BERT: pre-training of deep bidirectional transformers for language understanding [EB/OL]. [2024-10-01].. |
| [4] | WANG D Q, LIU P F, ZHENG Y N, et al. Heterogeneous graph neural networks for extractive document summarization[C]// Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics. Stroudsburg: ACL, 2020: 6209-6219. |
| [5] | LIU N F, LIN K, HEWITT J, et al. Lost in the middle: how language models use long contexts[EB/OL]. [2024-10-01].. |
| [6] | RAVAUT M, JOTY S, SUN A, et al. On position bias in summarization with large language models[EB/OL]. [2024-10-01].. |
| [7] | ZHENG H, LAPATA M. Sentence centrality revisited for unsupervised summarization[EB/OL]. [2024-10-01].. |
| [8] | ERKAN G, RADEV D R. LexRank: graph-based lexical centrality as salience in text summarization[J]. Journal of Artificial Intelligence Research, 2004, 22: 457-479. |
| [9] | PHAN T A, NGUYEN N D N, BUI K H N. HeterGraphLongSum: heterogeneous graph neural network with passage aggregation for extractive long document summarization[C]// Proceedings of the 29th International Conference on Computational Linguistics. Stroudsburg: ACL, 2022: 6248-6258. |
| [10] | DING K, WANG J, LI J, et al. Be more with less: hypergraph attention networks for inductive text classification[EB/OL]. [2024-11-10].. |
| [11] | SANDHAUS E. The New York Times annotated corpus[DS/OL]. [2024-11-10].. |
| [12] | 侯丽微,胡珀,曹雯琳. 主题关键词信息融合的中文生成式自动摘要研究[J]. 自动化学报, 2019, 45(3): 530-539. |
| HOU L W, HU P, CAO W L. Automatic Chinese abstractive summarization with topical keywords fusion[J]. Acta Automatica Sinica, 2019, 45(3): 530-539. | |
| [13] | MIHALCEA R, TARAU P. TextRank: bringing order into text[C]// Proceedings of the 2004 Conference on Empirical Methods in Natural Language Processing. Stroudsburg: ACL, 2004: 404-411. |
| [14] | TIXIER A J P, HALLOWELL M R, RAJAGOPALAN B. Construction safety risk modeling and simulation[J]. Risk Analysis, 2017, 37(10): 1917-1935. |
| [15] | CHENG J, LAPATA M. Neural summarization by extracting sentences and words[C]// Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Stroudsburg: ACL, 2016: 484-494. |
| [16] | COHAN A, DERNONCOURT F, KIM D S, et al. A discourse-aware attention model for abstractive summarization of long documents[C]// Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 2 (Short Papers). Stroudsburg: ACL, 2018: 615-621. |
| [17] | XIAO W, CARENINI G. Extractive summarization of long documents by combining global and local context[C]// Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing. Stroudsburg: ACL, 2019: 3011-3021. |
| [18] | DONG Y, MIRCEA A, CHEUNG J C K. Discourse-aware unsupervised summarization of long scientific documents[C]// Proceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics: Main Volume. Stroudsburg: ACL, 2021: 1089-1102. |
| [19] | JU J, LIU M, KOH H Y, et al. Leveraging information bottleneck for scientific document summarization[C]// Findings of the Association for Computational Linguistics: EMNLP 2021. Stroudsburg: ACL, 2021: 4091-4098. |
| [20] | BELTAGY I, PETERS M E, COHAN A. Longformer: the long-document Transformer [EB/OL]. [2020-04-10]. . |
| [21] | RUAN Q, OSTENDORFF M, REHM G. HiStruct+: improving extractive text summarization with hierarchical structure information[C]// Findings of the Association for Computational Linguistics: ACL 2022. Stroudsburg: ACL, 2022: 1292-1308. |
| [22] | CHO S, SONG K, WANG X, et al. Toward unifying text segmentation and long document summarization[C]// Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing. Stroudsburg: ACL, 2022: 106-118. |
| [23] | CUI P, HU L, LIU Y. Enhancing extractive text summarization with topic-aware graph neural networks[C]// Proceedings of the 28th International Conference on Computational Linguistics. [S.l.]: International Committee on Computational Linguistics, 2020: 5360-5371. |
| [24] | YASUNAGA M, ZHANG R, MEELU K, et al. Graph-based neural multi-document summarization[C]// Proceedings of the 21st Conference on Computational Natural Language Learning. Stroudsburg: ACL, 2017: 452-462. |
| [25] | XU J, GAN Z, CHENG Y, et al. Discourse-aware neural extractive model for text summarization[C]// Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics. Stroudsburg: ACL, 2020: 5021-5031. |
| [26] | ZHANG H, LIU X, ZHANG J. HEGEL: hypergraph transformer for long document summarization[C]// Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing. Stroudsburg: ACL, 2022: 10167-10176. |
| [27] | DOAN X D, NGUYEN L M, BUI K H N. Multi graph neural network for extractive long document summarization[C]// Proceedings of the 29th International Conference on Computational Linguistics. [S.l.]: International Committee on Computational Linguistics, 2022: 5870-5875. |
| [28] | VELIČKOVIĆ P, CUCURULL G, CASANOVA A, et al. Graph attention networks[EB/OL]. [2024-10-01].. |
| [29] | PENNINGTON J, SOCHER R, MANNING C D. GloVe: global vectors for word representation[C]// Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing. Stroudsburg: ACL, 2014: 1532-1543. |
| [30] | LeCUN Y, BOTTOU L, BENGIO Y, et al. Gradient-based learning applied to document recognition[J]. Proceedings of the IEEE, 1998, 86(11): 2278-2324. |
| [31] | HOCHREITER S, SCHMIDHUBER J. Long short-term memory[J]. Neural Computation, 1997, 9(8): 1735-1780. |
| [32] | VASWANI A, SHAZEER N, PARMAR N, et al. Attention is all you need[C]// Proceedings of the 31st International Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2017: 6000-6010. |
| [33] | SUPPE F. The structure of a scientific paper[J]. Philosophy of Science, 1998, 65(3): 381-405. |
| [34] | MARELLI M, MENINI S, BARONI M, et al. A SICK cure for the evaluation of compositional distributional semantic models[C]// Proceedings of the 9th International Conference on Language Resources and Evaluation. Paris: European Language Resources Association, 2014: 216-223. |
| [35] | CHEN T, KORNBLITH S, NOROUZI M, et al. A simple framework for contrastive learning of visual representations[C]// Proceedings of the 37th International Conference on Machine Learning. New York: JMLR.org, 2020: 1597-1607. |
| [36] | GAO T, YAO X, CHEN D. SimCSE: simple contrastive learning of sentence embeddings[C]// Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing. Stroudsburg: ACL, 2021: 6894-6910. |
| [37] | LOSHCHILOV I, HUTTER F. Decoupled weight decay regularization[EB/OL]. [2024-10-01].. |
| [38] | NALLAPATI R, ZHAI F, ZHOU B. SummaRuNNer: a recurrent neural network based sequence model for extractive summarization of documents[C]// Proceedings of the 31st AAAI Conference on Artificial Intelligence. Palo Alto: AAAI Press, 2017: 3075-3081. |
| [39] | LIN C Y, HOVY E. Automatic evaluation of summaries using n-gram co-occurrence statistics[C]// Proceedings of the 2003 Human Language Technology Conference of the North American Chapter of the Association for Computational Linguistics. Stroudsburg: ACL, 2003: 150-157. |
| [40] | ZHANG H, LIU X, ZHANG J. Contrastive hierarchical discourse graph for scientific document summarization[C]// Proceedings of the 4th Workshop on Computational Approaches to Discourse. Stroudsburg: ACL, 2023: 37-47. |
| [41] | ZHAO C, ZHOU X, XIE X, et al. Hierarchical attention graph for scientific document summarization in global and local level[C]// Findings of the Association for Computational Linguistics: NAACL 2024. Stroudsburg: ACL, 2024: 714-726. |
| [42] | ZHANG J, ZHAO Y, SALEH M, et al. PEGASUS: pre-training with extracted gap-sentences for abstractive summarization[C]// Proceedings of the 37th International Conference on Machine Learning. New York: JMLR.org, 2020: 11328-11339. |
| [43] | ZAHEER M, GURUGANESH G, DUBEY A, et al. BigBird: Transformers for longer sequences[C]// Proceedings of the 34th International Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2020: 17283-17297. |
| [44] | ZENG A, LIU X, DU Z, et al. GLM-130B: an open bilingual pre-trained model[EB/OL]. [2024-10-01]. . |
| [1] | 何凡, 李理, 苑中旭, 杨秀, 韩东轩. 融合图注意力的概念关联记忆网络知识追踪模型[J]. 《计算机应用》唯一官方网站, 2026, 46(1): 43-51. |
| [2] | 李玟, 李开荣, 杨凯. 基于数据增强的子图感知对比学习[J]. 《计算机应用》唯一官方网站, 2026, 46(1): 1-9. |
| [3] | 杨兴耀, 齐正, 于炯, 张祖莲, 马帅, 沈洪涛. 时间感知和空间增强的双通道图神经网络会话推荐模型[J]. 《计算机应用》唯一官方网站, 2026, 46(1): 104-112. |
| [4] | 卢燕群, 赵奕奕. 基于层次图神经网络和差异化特征学习的客户流失预测模型[J]. 《计算机应用》唯一官方网站, 2025, 45(9): 3057-3066. |
| [5] | 梁永濠, 李金龙. 用于神经布尔可满足性问题求解器的新型消息传递网络[J]. 《计算机应用》唯一官方网站, 2025, 45(9): 2934-2940. |
| [6] | 刘超, 余岩化. 融合降噪策略与多视图对比学习的知识感知推荐模型[J]. 《计算机应用》唯一官方网站, 2025, 45(9): 2827-2837. |
| [7] | 涂银川, 郭勇, 毛恒, 任怡, 张建锋, 李宝. 基于分布式环境的图神经网络模型训练效率与训练性能评估[J]. 《计算机应用》唯一官方网站, 2025, 45(8): 2409-2420. |
| [8] | 蒋权, 黄文清, 苟志勇. 基于等变图神经网络的拉格朗日粒子流模拟[J]. 《计算机应用》唯一官方网站, 2025, 45(8): 2666-2671. |
| [9] | 赵彪, 秦玉华, 田荣坤, 胡月航, 陈芳锐. 依赖类型及距离增强的方面级情感分析模型[J]. 《计算机应用》唯一官方网站, 2025, 45(8): 2507-2514. |
| [10] | 王义, 马应龙. 基于项图动态适应性生成的多任务社交项推荐方法[J]. 《计算机应用》唯一官方网站, 2025, 45(8): 2592-2599. |
| [11] | 陈丹阳, 张长伦. 多尺度去相关的图卷积网络模型[J]. 《计算机应用》唯一官方网站, 2025, 45(7): 2180-2187. |
| [12] | 张悦岚, 苏静, 赵航宇, 杨白利. 基于知识感知与交互的多视图蒸馏推荐算法[J]. 《计算机应用》唯一官方网站, 2025, 45(7): 2211-2220. |
| [13] | 梁辰, 王奕森, 魏强, 杜江. 基于Transformer-GCN的源代码漏洞检测方法[J]. 《计算机应用》唯一官方网站, 2025, 45(7): 2296-2303. |
| [14] | 张子墨, 赵雪专. 多尺度稀疏图引导的视觉图神经网络[J]. 《计算机应用》唯一官方网站, 2025, 45(7): 2188-2194. |
| [15] | 姜超英, 李倩, 刘宁, 刘磊, 崔立真. 基于图对比学习的再入院预测模型[J]. 《计算机应用》唯一官方网站, 2025, 45(6): 1784-1792. |
| 阅读次数 | ||||||
|
全文 |
|
|||||
|
摘要 |
|
|||||