


《计算机应用》唯一官方网站 ›› 2024, Vol. 44 ›› Issue (11): 3639-3646.DOI: 10.11772/j.issn.1001-9081.2023101379
• 前沿与综合应用 • 上一篇
梁睿衍, 杨慧( )
)
收稿日期:2023-10-13
修回日期:2024-01-16
接受日期:2024-01-18
发布日期:2024-11-13
出版日期:2024-11-10
通讯作者:
杨慧
作者简介:梁睿衍(1998—),男,广东佛山人,硕士研究生,主要研究方向:姿态估计、图卷积网络
基金资助:Received:2023-10-13
Revised:2024-01-16
Accepted:2024-01-18
Online:2024-11-13
Published:2024-11-10
Contact:
Hui YANG
About author:LIANG Ruiyan, born in 1998, M. S. candidate. His research interests include pose estimation, graph convolutional network.
Supported by:摘要:
传统的以ViT(Vision Transformer)模型为基准架构的关节点检测模型通常采用二维正弦位置编码,易丢失图像关键的二维形状信息,导致精度下降;而行为分类模型中,传统的时空图卷积网络(ST-GCN)在单标签分区策略中存在非物理连接的关节连接间关联度缺失问题。针对上述问题,设计一种轻量化实时跌倒检测算法框架,以快速准确地检测跌倒行为。该框架包含关节点检测模型RPEpose(Relative Position Encoding pose estimation)和行为分类模型XJ-GCN(Cross-Joint attention Graph Convolutional Network)。一方面,RPEpose模型采用相对位置编码克服原有位置编码的位置不敏感的缺陷,提升ViT架构在关节点检测中的性能;另一方面,提出X-Joint(Cross?Joint)注意力机制,将分区策略重构为XJL(X-Joint Labeling)分区策略后,对所有关节连接之间的依赖关系建模,能获得关节连接潜在相关性,具有分类性能优异且参数量小的优势。实验结果表明,在COCO 2017验证集上,对于分辨率为256×192的图像,RPEpose模型的计算开销仅为8.2 GFLOPs(Giga FLOating Point of operations),测试平均精度(AP)为74.3%;在以交叉目标(X?Sub)为划分标准的NTU RGB+D数据集上,XJ-GCN模型的测试Top-1准确率为89.6%,所提框架RPEpose+XJ-GCN的处理速度为30 frame/s,预测准确率为87.2%,具有较高的实时性和准确性。
中图分类号:
梁睿衍, 杨慧. 基于RPEpose和XJ-GCN的轻量级跌倒检测算法框架[J]. 计算机应用, 2024, 44(11): 3639-3646.
Ruiyan LIANG, Hui YANG. Lightweight fall detection algorithm framework based on RPEpose and XJ-GCN[J]. Journal of Computer Applications, 2024, 44(11): 3639-3646.
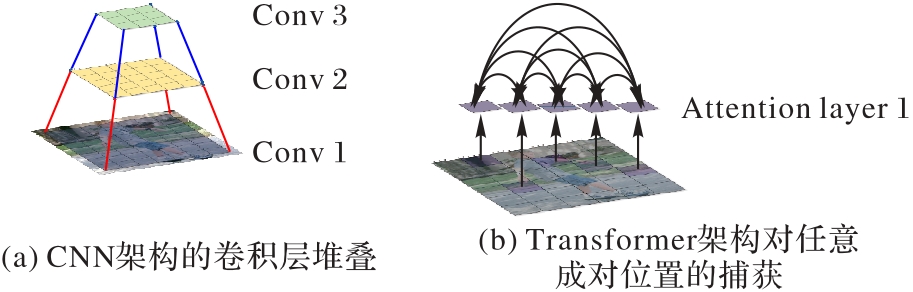
图1 CNN架构和Transformer架构对比
Fig. 1 Framework comparison between CNN and Transformer
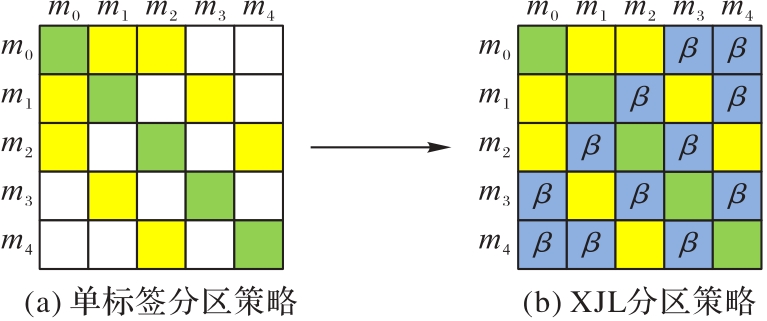
图2 加入注意力机制前后的分区策略对比
Fig. 2 Comparison of partitioning strategies with and without attention mechanism
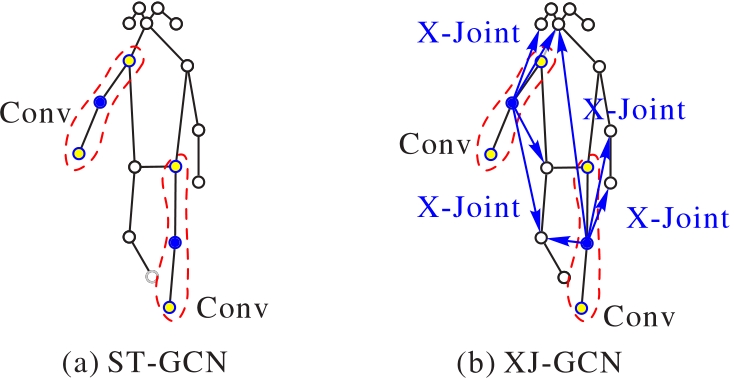
图3 ST-GCN和XJ-GCN效果对比
Fig. 3 Effect comparison of ST-GCN and XJ-GCN

图4 RPEpose+XJ-GCN跌倒检测算法框架的结构
Fig. 4 Structure of fall detection algorithm framework combining RPEpose and XJ-GCN
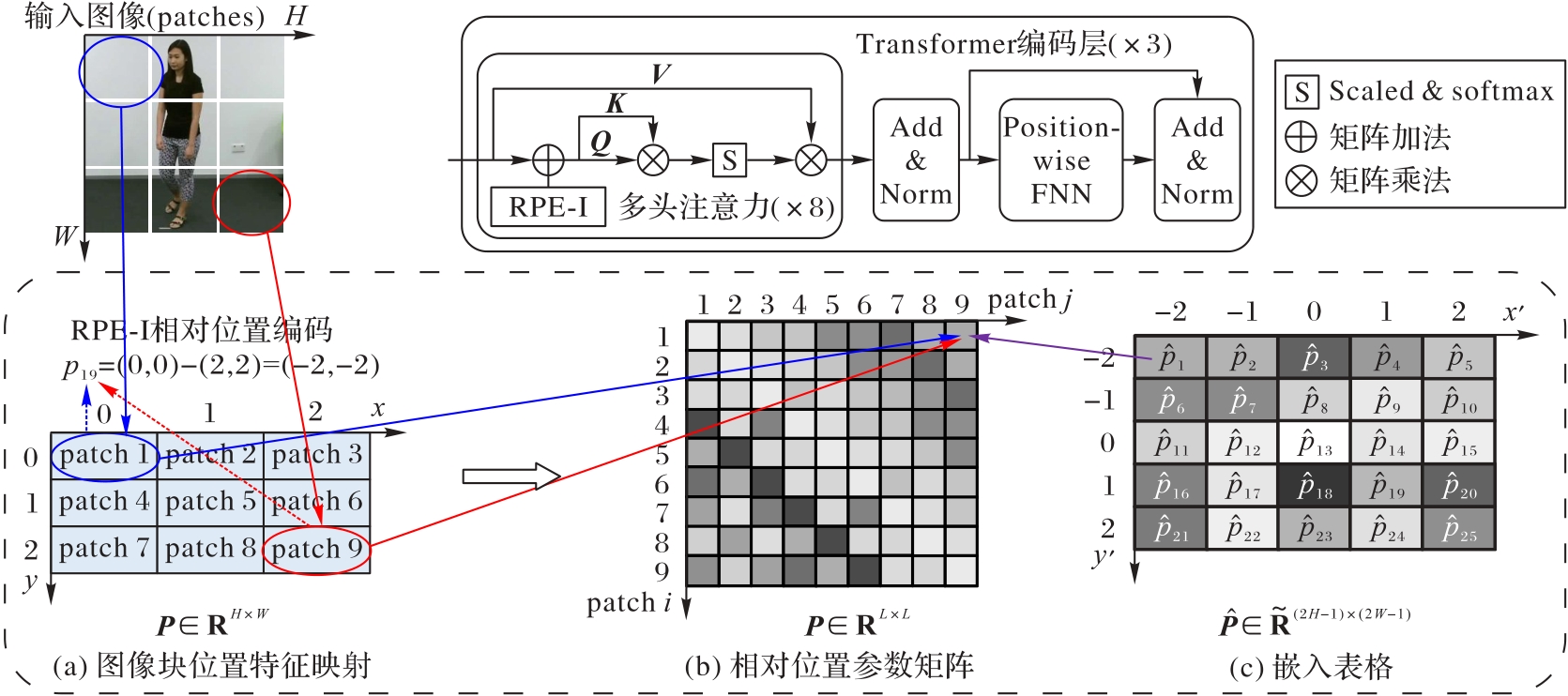
图5 基于RPE-I相对位置编码方式的Transformer编码器
Fig. 5 Transformer encoder with RPE-I relative positional encoding

图6 XJ-GCN模型的架构
Fig. 6 Architecture of XJ-GCN model

图7 XJL-GCN的计算流程
Fig. 7 Calculation process of XJL-GCN model
| 位置编码 | AP | AR |
|---|---|---|
| 2D Sine Position Embedding | 71.7 | 77.1 |
| Bias Mode | 72.9 | 77.4 |
| Contextual Mode | 73.3 | 77.6 |
| RPE-I(本文) | 74.3 | 78.2 |
表1 不同位置编码对比 (%)
Tab. 1 Comparison of different position embeddings
| 位置编码 | AP | AR |
|---|---|---|
| 2D Sine Position Embedding | 71.7 | 77.1 |
| Bias Mode | 72.9 | 77.4 |
| Contextual Mode | 73.3 | 77.6 |
| RPE-I(本文) | 74.3 | 78.2 |
| 模型 | 分辨率 | 计算量/GFLOPs | AP/% | AR/% |
|---|---|---|---|---|
| TransPose-H-A4[ | 256×192 | 10.2 | 74.2 | 78.0 |
| CPN+[ | 384×288 | 29.2 | 73.0 | 79.0 |
| AlphaPose[ | 320×256 | 26.7 | 72.3 | — |
| Simple Baseline[ | 384×288 | 35.6 | 72.3 | 79.0 |
| OpenPose[ | — | — | 65.3 | — |
| YOLO-Pose[ | 960×960 | — | 68.5 | 75.0 |
| OpenPifPaf[ | — | — | 71.9 | — |
| RPEpose | 256×192 | 8.2 | 74.3 | 78.2 |
表2 不同关节点检测模型性能对比
Tab. 2 Performance comparison of different joint keypoint detection models
| 模型 | 分辨率 | 计算量/GFLOPs | AP/% | AR/% |
|---|---|---|---|---|
| TransPose-H-A4[ | 256×192 | 10.2 | 74.2 | 78.0 |
| CPN+[ | 384×288 | 29.2 | 73.0 | 79.0 |
| AlphaPose[ | 320×256 | 26.7 | 72.3 | — |
| Simple Baseline[ | 384×288 | 35.6 | 72.3 | 79.0 |
| OpenPose[ | — | — | 65.3 | — |
| YOLO-Pose[ | 960×960 | — | 68.5 | 75.0 |
| OpenPifPaf[ | — | — | 71.9 | — |
| RPEpose | 256×192 | 8.2 | 74.3 | 78.2 |
| 维度 | Top-1 Accuracy/% | |
|---|---|---|
| X-Sub | X-View | |
| 2D | 88.4 | 95.2 |
| 3D | 89.6 | 94.6 |
表3 XJ-GCN在不同维度数据集上的Top-1 Accuracy对比
Tab. 3 Top-1 Accuracy comparison of XJ-GCN on different dimensional datasets
| 维度 | Top-1 Accuracy/% | |
|---|---|---|
| X-Sub | X-View | |
| 2D | 88.4 | 95.2 |
| 3D | 89.6 | 94.6 |
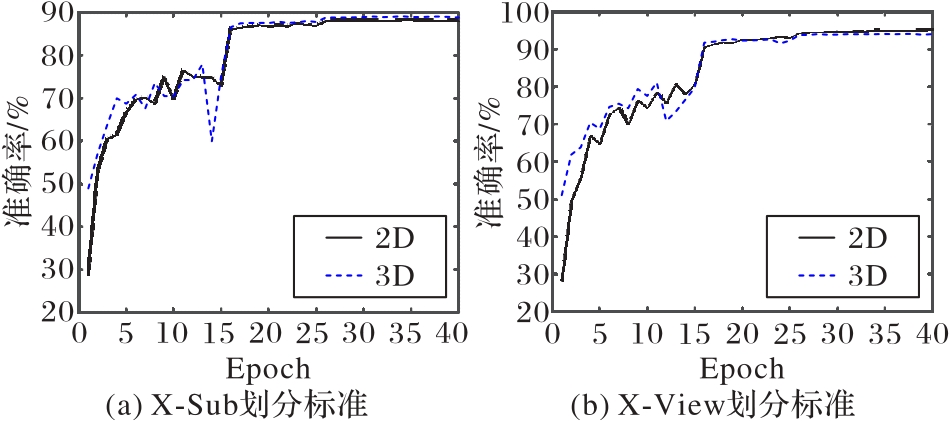
图8 XJ-GCN训练效果对比
Fig. 8 Comparison of XJ-GCN training effects
| 模型 | 参数量/MB | Top-1 Accuracy/% | |
|---|---|---|---|
| X-Sub | X-View | ||
| S-TR[ | 3.1 | 86.8 | 93.8 |
| HCN[ | 1.1 | 86.5 | 91.1 |
| ST-GCN[ | 3.1 | 81.5 | 88.3 |
| 2s-AGCN[ | 7.1 | 88.5 | 95.1 |
| AS-GCN[ | 7.6 | 86.8 | 94.2 |
| SR-TSL[ | 19.2 | 84.8 | 92.4 |
| AGC-LSTM[ | 23.4 | 87.5 | 93.5 |
| VA-CNN[ | 24.1 | 88.7 | 94.3 |
| CoST-GCN[ | 3.1 | 86.0 | 93.4 |
| XJ-GCN | 1.4 | 89.6 | 94.6 |
表4 各模型在NTU RGB+D数据集上的性能对比
Tab. 4 Performance comparison of different models on NTU RGB+D dataset
| 模型 | 参数量/MB | Top-1 Accuracy/% | |
|---|---|---|---|
| X-Sub | X-View | ||
| S-TR[ | 3.1 | 86.8 | 93.8 |
| HCN[ | 1.1 | 86.5 | 91.1 |
| ST-GCN[ | 3.1 | 81.5 | 88.3 |
| 2s-AGCN[ | 7.1 | 88.5 | 95.1 |
| AS-GCN[ | 7.6 | 86.8 | 94.2 |
| SR-TSL[ | 19.2 | 84.8 | 92.4 |
| AGC-LSTM[ | 23.4 | 87.5 | 93.5 |
| VA-CNN[ | 24.1 | 88.7 | 94.3 |
| CoST-GCN[ | 3.1 | 86.0 | 93.4 |
| XJ-GCN | 1.4 | 89.6 | 94.6 |

图9 模型性能与模型规模关系的对比
Fig. 9 Comparison of model performance in relation to model size
| 跌倒检测算法框架 | 准确率 |
|---|---|
| OpenPose+CoST-GCN | 85.1 |
| OpenPose+XJ-GCN | 85.9 |
| OpenPifPaf+CoST-GCN | 85.8 |
| OpenPifPaf+XJ-GCN | 86.3 |
| RPEpose+CoST-GCN | 86.4 |
| RPEpose+XJ-GCN | 87.2 |
表5 不同跌倒检测算法框架准确率对比 (%)
Tab. 5 Accuracy comparison of different fall detection algorithm frameworks
| 跌倒检测算法框架 | 准确率 |
|---|---|
| OpenPose+CoST-GCN | 85.1 |
| OpenPose+XJ-GCN | 85.9 |
| OpenPifPaf+CoST-GCN | 85.8 |
| OpenPifPaf+XJ-GCN | 86.3 |
| RPEpose+CoST-GCN | 86.4 |
| RPEpose+XJ-GCN | 87.2 |
| 1 | PIERLEONI P, BELLI A, PALMA L, et al. A high reliability wearable device for elderly fall detection [J]. IEEE Sensors Journal, 2015, 15(8): 4544-4553. |
| 2 | CAO Z, HIDALGO G, SIMON T, et al. OpenPose: realtime multi-person 2D pose estimation using part affinity fields[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2021, 43(1): 172-186. |
| 3 | MAJI D, NAGORI S, MATHEW M, et al. YOLO-Pose: enhancing YOLO for multi person pose estimation using object keypoint similarity loss[C]// Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2022: 2636-2645. |
| 4 | CHEN Y, WANG Z, PENG Y, et al. Cascaded pyramid network for multi-person pose estimation[C]// Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2018: 7103-7112. |
| 5 | YANG S, QUAN Z, NIE M, et al. TransPose: keypoint localization via Transformer[C]// Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision. Piscataway: IEEE, 2021: 11782-11792. |
| 6 | RAMACHANDRAN P, PARMAR N, VASWANI A, et al. Stand-alone self-attention in vision models[C]// Proceedings of the 33rd International Conference on Neural Information Processing Systems. Red Hook, NY: Curran Associates Inc., 2019: 68-80. |
| 7 | DOSOVITSKIY A, BEYER L, KOLESNIKOV A, et al. An image is worth 16x16 words: Transformers for image recognition at scale [EB/OL]. [2023-10-11]. . |
| 8 | LIN T-Y, MAIRE M, BELONGIE S, et al. Microsoft COCO: common objects in context[C]// Proceedings of the 13th European Conference on Computer Vision. Cham: Springer, 2014: 740-755. |
| 9 | YAN S, XIONG Y, LIN D. Spatial temporal graph convolutional networks for skeleton-based action recognition[C]// Proceedings of the 32nd AAAI Conference on Artificial Intelligence. Palo Alto: AAAI Press, 2018: 7444-7452. |
| 10 | LI M, CHEN S, CHEN X, et al. Actional-structural graph convolutional networks for skeleton-based action recognition[C]// Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2019: 3590-3598. |
| 11 | HEDEGAARD L, HEIDARI N, IOSIFIDIS A. Continual spatio-temporal graph convolutional networks[J]. Pattern Recognition, 2023, 140: 109528. |
| 12 | SHAHROUDY A, LIU J, T-T NG, et al. NTU RGB+ D: a large scale dataset for 3D human activity analysis[C]// Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2016: 1010-1019. |
| 13 | XU Y, ZHANG J, ZHANG Q, et al. ViTPose: simple vision Transformer baselines for human pose estimation[C]// Proceedings of the 36th International Conference on Neural Information Processing Systems. Red Hook, NY: Curran Associates Inc., 2022: 38571-38584. |
| 14 | YUAN Y, FU R, HUANG L, et al. HRFormer: high-resolution vision Transformer for dense predict[C]// Proceedings of the 35th International Conference on Neural Information Processing Systems. Red Hook, NY: Curran Associates Inc., 2021: 7281-7293. |
| 15 | 曹建荣,吕俊杰,武欣莹,等.融合运动特征和深度学习的跌倒检测算法[J].计算机应用,2021,41(2):583-589. |
| CAO J R, LYU J J, WU X Y, et al. Fall detection algorithm integrating motion features and deep learning[J]. Journal of Computer Applications, 2021, 41(2): 583-589. | |
| 16 | 马敬奇,雷欢,陈敏翼.基于AlphaPose优化模型的老人跌倒行为检测算法[J].计算机应用,2022,42(1):294-301. |
| MA J Q, LEI H, CHEN M Y. Fall behavior detection algorithm for the elderly based on AlphaPose optimization model[J]. Journal of Computer Applications, 2022, 42(1):294-301. | |
| 17 | DENG J, DONG W, SOCHER R, et al. ImageNet: a large-scale hierarchical image database[C]// Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2009: 248-255. |
| 18 | WU K, PENG H, CHEN M, et al. Rethinking and improving relative position encoding for vision Transformer[C]// Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision. Piscataway: IEEE, 2021: 10033-10041. |
| 19 | FANG H-S, XIE S, TAI Y-W, et al. RMPE: regional multi-person pose estimation[C]// Proceedings of the 2017 IEEE International Conference on Computer Vision. Piscataway: IEEE, 2017: 2353-2362. |
| 20 | XIAO B, WU H, WEI Y. Simple baselines for human pose estimation and tracking[C]// Proceedings of the 15th European Conference on Computer Vision.Cham: Springer, 2018: 472-487. |
| 21 | KREISS S, BERTONI L, ALAHI A. OpenPifPaf: composite fields for semantic keypoint detection and spatio-temporal association[J]. IEEE Transactions on Intelligent Transportation Systems, 2022, 23(8): 13498-13511. |
| 22 | PLIZZARI C, CANNICI M, MATTEUCCI M. Skeleton-based action recognition via spatial and temporal Transformer networks[J]. Computer Vision and Image Understanding, 2021, 208/209: 103219. |
| 23 | LI C, ZHONG Q, XIE D, et al. Co-occurrence feature learning from skeleton data for action recognition and detection with hierarchical aggregation [EB/OL]. [2023-08-22]. . |
| 24 | SHI L, ZHANG Y, CHENG J, et al. Two-stream adaptive graph convolutional networks for skeleton-based action recognition[C]// Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2019: 12018-12027. |
| 25 | SI C, JING Y, WANG W, et al. Skeleton-based action recognition with spatial reasoning and temporal stack learning[C]// Proceedings of the 15th European Conference on Computer Vision. Cham: Springer, 2018: 106-121. |
| 26 | SI C, CHEN W, WANG W, et al. An attention enhanced graph convolutional LSTM network for skeleton-based action recognition[C]// Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2019: 1227-1236. |
| 27 | ZHANG P, LAN C, XING J, et al. View adaptive neural networks for high performance skeleton-based human action recognition[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2019, 41(8): 1963-1978. |
| [1] | 秦璟, 秦志光, 李发礼, 彭悦恒. 基于概率稀疏自注意力神经网络的重性抑郁疾患诊断[J]. 《计算机应用》唯一官方网站, 2024, 44(9): 2970-2974. |
| [2] | 李力铤, 华蓓, 贺若舟, 徐况. 基于解耦注意力机制的多变量时序预测模型[J]. 《计算机应用》唯一官方网站, 2024, 44(9): 2732-2738. |
| [3] | 赵志强, 马培红, 黑新宏. 基于双重注意力机制的人群计数方法[J]. 《计算机应用》唯一官方网站, 2024, 44(9): 2886-2892. |
| [4] | 薛凯鹏, 徐涛, 廖春节. 融合自监督和多层交叉注意力的多模态情感分析网络[J]. 《计算机应用》唯一官方网站, 2024, 44(8): 2387-2392. |
| [5] | 汪雨晴, 朱广丽, 段文杰, 李书羽, 周若彤. 基于交互注意力机制的心理咨询文本情感分类模型[J]. 《计算机应用》唯一官方网站, 2024, 44(8): 2393-2399. |
| [6] | 高鹏淇, 黄鹤鸣, 樊永红. 融合坐标与多头注意力机制的交互语音情感识别[J]. 《计算机应用》唯一官方网站, 2024, 44(8): 2400-2406. |
| [7] | 李钟华, 白云起, 王雪津, 黄雷雷, 林初俊, 廖诗宇. 基于图像增强的低照度人脸检测[J]. 《计算机应用》唯一官方网站, 2024, 44(8): 2588-2594. |
| [8] | 莫尚斌, 王文君, 董凌, 高盛祥, 余正涛. 基于多路信息聚合协同解码的单通道语音增强[J]. 《计算机应用》唯一官方网站, 2024, 44(8): 2611-2617. |
| [9] | 刘丽, 侯海金, 王安红, 张涛. 基于多尺度注意力的生成式信息隐藏算法[J]. 《计算机应用》唯一官方网站, 2024, 44(7): 2102-2109. |
| [10] | 徐松, 张文博, 王一帆. 基于时空信息的轻量视频显著性目标检测网络[J]. 《计算机应用》唯一官方网站, 2024, 44(7): 2192-2199. |
| [11] | 李大海, 王忠华, 王振东. 结合空间域和频域信息的双分支低光照图像增强网络[J]. 《计算机应用》唯一官方网站, 2024, 44(7): 2175-2182. |
| [12] | 魏文亮, 王阳萍, 岳彪, 王安政, 张哲. 基于光照权重分配和注意力的红外与可见光图像融合深度学习模型[J]. 《计算机应用》唯一官方网站, 2024, 44(7): 2183-2191. |
| [13] | 熊武, 曹从军, 宋雪芳, 邵云龙, 王旭升. 基于多尺度混合域注意力机制的笔迹鉴别方法[J]. 《计算机应用》唯一官方网站, 2024, 44(7): 2225-2232. |
| [14] | 李欢欢, 黄添强, 丁雪梅, 罗海峰, 黄丽清. 基于多尺度时空图卷积网络的交通出行需求预测[J]. 《计算机应用》唯一官方网站, 2024, 44(7): 2065-2072. |
| [15] | 毛典辉, 李学博, 刘峻岭, 张登辉, 颜文婧. 基于并行异构图和序列注意力机制的中文实体关系抽取模型[J]. 《计算机应用》唯一官方网站, 2024, 44(7): 2018-2025. |
| 阅读次数 | ||||||
|
全文 |
|
|||||
|
摘要 |
|
|||||