


《计算机应用》唯一官方网站 ›› 2024, Vol. 44 ›› Issue (2): 331-343.DOI: 10.11772/j.issn.1001-9081.2023020166
所属专题: 人工智能
• 人工智能 • 下一篇
颜梦玫1,2,3, 杨冬平2,3( )
)
收稿日期:2023-02-23
修回日期:2023-04-17
接受日期:2023-04-20
发布日期:2023-08-14
出版日期:2024-02-10
通讯作者:
杨冬平
作者简介:颜梦玫(1997—),女,四川泸州人,硕士研究生,主要研究方向: 机器学习、动力学平均场;
基金资助:
Mengmei YAN1,2,3, Dongping YANG2,3()
Received:2023-02-23
Revised:2023-04-17
Accepted:2023-04-20
Online:2023-08-14
Published:2024-02-10
Contact:
Dongping YANG
About author:YAN Mengmei, born in 1997, M. S. candidate. Her research interests include machine learning, dynamical mean field.
Supported by:摘要:
平均场理论(MFT)为理解深度神经网络(DNN)的运行机制提供了非常深刻的见解,可以从理论上指导深度学习的工程设计。近年来,越来越多的研究人员开始投入DNN的理论研究,特别是基于MFT的一系列工作引起人们的广泛关注。为此,对深度神经网络平均场理论相关的研究内容进行综述,主要从初始化、训练过程和泛化性能这三个基本方面介绍最新的理论研究成果。在此基础上,介绍了混沌边缘和动力等距初始化的相关概念、相关特性和具体应用,分析了过参数网络以及相关等价网络的训练特性,并对不同网络架构的泛化性能进行理论分析,体现了平均场理论是理解深度神经网络机理的非常重要的基本理论方法。最后,总结了深度神经网络中初始、训练和泛化阶段的平均场理论面临的主要挑战和未来研究方向。
中图分类号:
颜梦玫, 杨冬平. 深度神经网络平均场理论综述[J]. 计算机应用, 2024, 44(2): 331-343.
Mengmei YAN, Dongping YANG. Review of mean field theory for deep neural network[J]. Journal of Computer Applications, 2024, 44(2): 331-343.
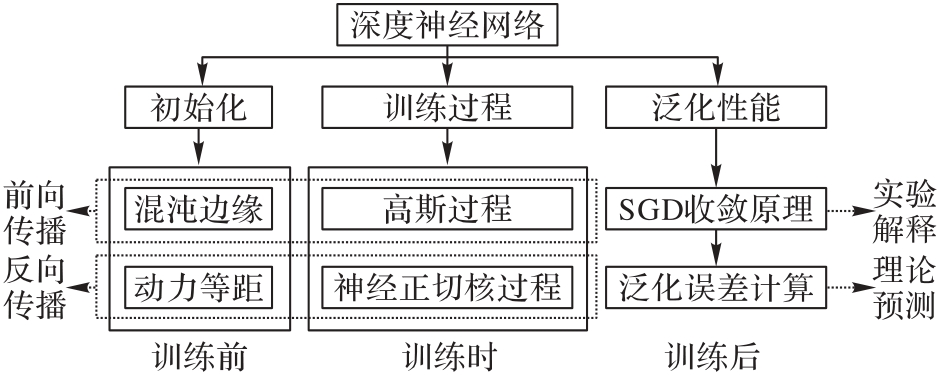
图1 MFT在理解DNN内在机理的研究框架
Fig. 1 Research framework of MFT in understanding intrinsic mechanisms of DNN
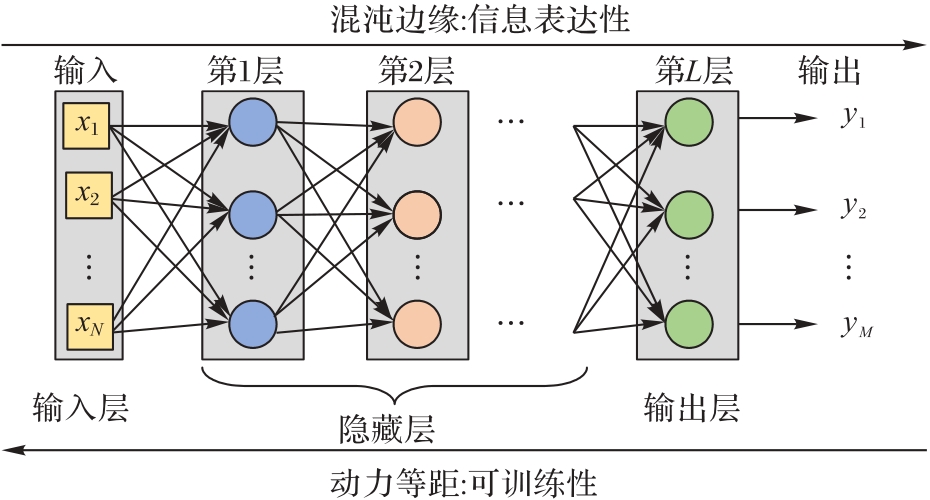
图2 DNN前向信息传播和反向梯度传播的两个特性
Fig. 2 Two characteristics of forward information propagation and backward gradient propagation in DNN
| 随机网络 | 深度神经网络 | ||||
|---|---|---|---|---|---|
| 变量 | 名称 | 范围 | 变量 | 名称 | 范围 |
| 时间 | 层数 | ||||
| 突触权重 | 权重矩阵元素 | ||||
| 外部噪声 | 偏置 | ||||
| 局域场 | 预激活 | ||||
| 神经元活动强度 | 后激活 | ||||
| 增益参数 | 权重方差 | ||||
| 噪声强度 | 偏置方差 | ||||
表1 相关变量定义与对比
Tab. 1 Definition and comparison of relevant variables
| 随机网络 | 深度神经网络 | ||||
|---|---|---|---|---|---|
| 变量 | 名称 | 范围 | 变量 | 名称 | 范围 |
| 时间 | 层数 | ||||
| 突触权重 | 权重矩阵元素 | ||||
| 外部噪声 | 偏置 | ||||
| 局域场 | 预激活 | ||||
| 神经元活动强度 | 后激活 | ||||
| 增益参数 | 权重方差 | ||||
| 噪声强度 | 偏置方差 | ||||
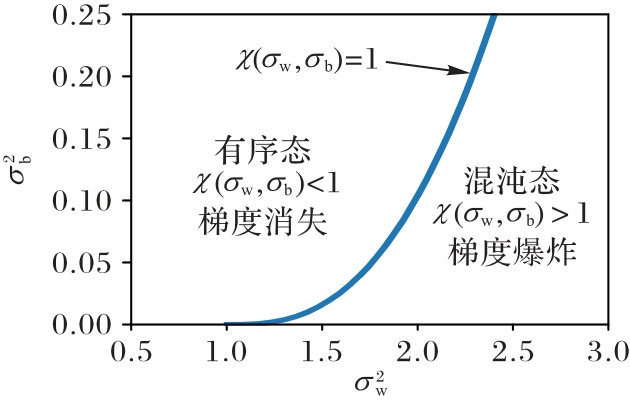
图3 有序态-混沌态的相变图
Fig. 3 Ordered state-chaotic state phase transition diagram
| 变量 | 名称 | 有序态 | EoC | 混沌态 |
|---|---|---|---|---|
| 增益 | ||||
| 传播深度 |
表2 控制相变的参数
Tab. 2 Parameters controlling phase transition
| 变量 | 名称 | 有序态 | EoC | 混沌态 |
|---|---|---|---|---|
| 增益 | ||||
| 传播深度 |
| 网络 | 数据集 | 目标 准确率/% | 迭代次数 | |
|---|---|---|---|---|
| 无EoC | 有EoC | |||
| FCN | MNIST | — | — | 1 |
| CNN | MNIST | 60 | 60 | 1 |
| 95 | — | 7 | ||
| RNN | MNIST | 90 | 82 | 4 |
| ResNet-56 | CIFAR-10 | 80 | 20 | 15 |
| ResNet-110 | CIFAR-10 | 80 | 23 | 14 |
表3 EoC在各种人工神经网络中的作用
Tab. 3 Roles of EoC in various ANNs
| 网络 | 数据集 | 目标 准确率/% | 迭代次数 | |
|---|---|---|---|---|
| 无EoC | 有EoC | |||
| FCN | MNIST | — | — | 1 |
| CNN | MNIST | 60 | 60 | 1 |
| 95 | — | 7 | ||
| RNN | MNIST | 90 | 82 | 4 |
| ResNet-56 | CIFAR-10 | 80 | 20 | 15 |
| ResNet-110 | CIFAR-10 | 80 | 23 | 14 |

图4 Jacobian矩阵谱计算流程
Fig. 4 Computing flow of Jacobian matrix spectrum
| 网络 | 参数设置 | 数据集 | 精度/% | |
|---|---|---|---|---|
| 无DI | 有DI | |||
| FCN | L=200 | CIFAR-10 | 53.40 | 54.20 |
| CNN | L=50 | CIFAR-10 | 89.82 | 89.90 |
| L=10 000 | MNIST | — | 82.00 | |
| CIFAR-10 | — | 99.00 | ||
| RNN | T=196 | MNIST | — | 98.00 |
| LSTM | N=600 | MNIST | 98.60 | 98.90 |
| CIFAR-10 | 58.80 | 61.80 | ||
| ResNets[ | L=56 | CIFAR-100 | 76.70 | 78.45 |
| Tiny ImageNet | 55.05 | 58.73 | ||
| ReZero[ | L=110 | CIFAR-10 | 93.76 | 94.07 |
表4 DI对各种人工神经网络测试精度的提升作用
Tab. 4 Role of DI in improvement of test accuracies for various ANNs
| 网络 | 参数设置 | 数据集 | 精度/% | |
|---|---|---|---|---|
| 无DI | 有DI | |||
| FCN | L=200 | CIFAR-10 | 53.40 | 54.20 |
| CNN | L=50 | CIFAR-10 | 89.82 | 89.90 |
| L=10 000 | MNIST | — | 82.00 | |
| CIFAR-10 | — | 99.00 | ||
| RNN | T=196 | MNIST | — | 98.00 |
| LSTM | N=600 | MNIST | 98.60 | 98.90 |
| CIFAR-10 | 58.80 | 61.80 | ||
| ResNets[ | L=56 | CIFAR-100 | 76.70 | 78.45 |
| Tiny ImageNet | 55.05 | 58.73 | ||
| ReZero[ | L=110 | CIFAR-10 | 93.76 | 94.07 |
| 网络 | Jacobian矩阵 | DI方法 | 正交化公式 | DI优点 |
|---|---|---|---|---|
| FCN[ | 随机权重矩阵正交化 | 测试精度明显优于高斯化 | ||
| CNN[ | — | Delta正交初始化 (卷积核正交) | — | 测试精度明显优于高斯化,可训练1万层CNN |
| RNN[ | 随机权重矩阵正交化 | 具有鲁棒的一维子空间 | ||
| LSTM和GRU[ | 控制Jacobian矩阵谱 | 记忆更长时间序列信息 | ||
| ResNets[ | RISOTTO[ (残差块初始化满足DI) | 无明显区别 | ||
| ReZero[ | α初始为0,通过训练改变α值满足DI | 测试性能比ResNets更优,且收敛更快 |
表5 各种人工神经网络中DI作用的总结
Tab. 5 Summary of roles of DI in various ANNs
| 网络 | Jacobian矩阵 | DI方法 | 正交化公式 | DI优点 |
|---|---|---|---|---|
| FCN[ | 随机权重矩阵正交化 | 测试精度明显优于高斯化 | ||
| CNN[ | — | Delta正交初始化 (卷积核正交) | — | 测试精度明显优于高斯化,可训练1万层CNN |
| RNN[ | 随机权重矩阵正交化 | 具有鲁棒的一维子空间 | ||
| LSTM和GRU[ | 控制Jacobian矩阵谱 | 记忆更长时间序列信息 | ||
| ResNets[ | RISOTTO[ (残差块初始化满足DI) | 无明显区别 | ||
| ReZero[ | α初始为0,通过训练改变α值满足DI | 测试性能比ResNets更优,且收敛更快 |
| 网络 | NNGP公式 |
|---|---|
| FCN | |
| CNN | |
| RNN | |
| Batch norm | |
| GRU |
表6 各种人工神经网络的NNGP公式
Tab. 6 NNGP formulas for various ANNs
| 网络 | NNGP公式 |
|---|---|
| FCN | |
| CNN | |
| RNN | |
| Batch norm | |
| GRU |
| 网络 | NTK核回归公式 |
|---|---|
| FCN | |
| CNN | |
| RNN | |
| Batch norm | |
| GNN |
表7 各种人工神经网络的NTK公式
Tab. 7 NTK formulas for various ANNs
| 网络 | NTK核回归公式 |
|---|---|
| FCN | |
| CNN | |
| RNN | |
| Batch norm | |
| GNN |
| 网络 | 核名称 | 数据集 | 精度/% | |
|---|---|---|---|---|
| 常规训练 | NTK训练 | |||
| FCN[ | NTK | MNIST | 97.50 | 97.40 |
| CNN[ | CNTK | CIFAR-10 | 63.81 | 70.47 |
| RNN[ | RNTK | Strawberry | 97.57 | 98.38 |
| ResNets[ | — | CIFAR-10 | 70.00 | 69.50 |
| GNN[ | GNTK | COLLAB | 79.00 | 83.60 |
表8 各种人工神经网络的NTK性能
Tab. 8 Performance of NTK in various ANNs
| 网络 | 核名称 | 数据集 | 精度/% | |
|---|---|---|---|---|
| 常规训练 | NTK训练 | |||
| FCN[ | NTK | MNIST | 97.50 | 97.40 |
| CNN[ | CNTK | CIFAR-10 | 63.81 | 70.47 |
| RNN[ | RNTK | Strawberry | 97.57 | 98.38 |
| ResNets[ | — | CIFAR-10 | 70.00 | 69.50 |
| GNN[ | GNTK | COLLAB | 79.00 | 83.60 |

图5 训练误差与泛化误差曲线示意图
Fig. 5 Schematic diagram of training error and generalization error curves
| 1 | HINTON G E, SALAKHUTDINOV R. Reducing the dimensionality of data with neural networks[J]. Science, 2006, 313(5786): 504-507. 10.1126/science.1127647 |
| 2 | KRIZHEVSKY A, SUTSKEVER I, HINTON G E. ImageNet classification with deep convolutional neural networks[J]. Communications of the ACM, 2017, 60(6): 84-90. 10.1145/3065386 |
| 3 | 杨强,范力欣,朱军,等. 可解释人工智能导论[M]. 北京:电子工业出版社, 2022: 105. |
| YANG Q, FAN L X, ZHU J, et al. Introduction to Explainable Artificial Intelligence[M]. Beijing: Publishing House of Electronics Industry, 2022: 105. | |
| 4 | POOLE B, LAHIRI S, RAGHU M, et al. Exponential expressivity in deep neural networks through transient chaos[C]// Proceedings of the 30th International Conference on Neural Information Processing Systems. Red Hook, NY: Curran Associates Inc., 2016: 3368-3376. |
| 5 | JACOT A, GABRIEL F, HONGLER C. Neural tangent kernel: convergence and generalization in neural networks[C]// Proceedings of the 32nd International Conference on Neural Information Processing Systems. Red Hook, NY: Curran Associates Inc., 2018: 8571-8580. |
| 6 | CANATAR A, BORDELON B, PEHLEVAN C. Spectral bias and task-model alignment explain generalization in kernel regression and infinitely wide neural networks[J]. Nature Communications, 2021, 12: No.2914. 10.1038/s41467-021-23103-1 |
| 7 | LEE J M. Riemannian Manifolds: An Introduction to Curvature, GTM 176[M]. New York: Springer, 1997. 10.1007/0-387-22726-1_7 |
| 8 | SOMPOLINSKY H, CRISANTI A, SOMMERS H J. Chaos in random neural networks[J]. Physical Review Letters, 1988, 61(3): No.259. 10.1103/physrevlett.61.259 |
| 9 | MOLGEDEY L, SCHUCHHARDT J, SCHUSTER H G. Suppressing chaos in neural networks by noise[J]. Physical Review Letters, 1992, 69(26): No.3717. 10.1103/physrevlett.69.3717 |
| 10 | SCHOENHOLZ S S, GILMER J, GANGULI S, et al. Deep information propagation[EB/OL]. (2017-04-04) [2022-12-23].. 10.48550/arXiv.1611.01232 |
| 11 | XIAO L, BAHRI Y, SOHL-DICKSTEIN J, et al. Dynamical isometry and a mean field theory of CNNs: how to train 10 000-layer vanilla convolutional neural networks[C]// Proceedings of the 35th International Conference on Machine Learning. New York: JMLR.org, 2018: 5393-5402. |
| 12 | CHEN M, PENNINGTON J, SCHOENHOLZ S S. Dynamical isometry and a mean field theory of RNNs: gating enables signal propagation in recurrent neural networks[C]// Proceedings of the 35th International Conference on Machine Learning. New York: JMLR.org, 2018: 873-882. 10.1109/mlsp.2018.8517074 |
| 13 | GADHIKAR A, BURKHOLZ R. Dynamical isometry for residual networks[EB/OL]. (2022-10-05) [2022-12-23].. |
| 14 | TARNOWSKI W, WARCHOŁ P, JASTRZĘBSKI S, et al. Dynamical isometry is achieved in residual networks in a universal way for any activation function[C]// Proceedings of the 22nd International Conference on Artificial Intelligence and Statistics. New York: JMLR.org, 2019: 2221-2230. |
| 15 | GILBOA D, CHANG B, CHEN M, et al. Dynamical isometry and a mean field theory of LSTMs and GRUs[EB/OL]. (2019-01-25) [2022-12-23].. 10.1007/978-3-030-64904-3_3 |
| 16 | PENNINGTON J, SCHOENHOLZ S S, GANGULI S. Resurrecting the sigmoid in deep learning through dynamical isometry: theory and practice[C]// Proceedings of the 31st International Conference on Neural Information Processing Systems. Red Hook, NY: Curran Associates Inc., 2017: 4788-4798. 10.7551/mitpress/11474.003.0014 |
| 17 | SAXE A M, McCLELLAND J L, GANGULI S. Exact solutions to the nonlinear dynamics of learning in deep linear neural networks[EB/OL]. (2014-02-19) [2022-12-23].. 10.1073/pnas.1820226116 |
| 18 | BACHLECHNER T, MAJUMDER B P, MAO H, et al. ReZero is all you need: fast convergence at large depth[C]// Proceedings of the 37th Conference on Uncertainty in Artificial Intelligence. New York: JMLR.org, 2021: 1352-1361. |
| 19 | NEAL R M. Priors for infinite networks[M]// Bayesian Learning for Neural Networks, LNS 118. New York: Springer, 1996: 29-53. 10.1007/978-1-4612-0745-0_2 |
| 20 | LEE J, BAHRI Y, NOVAK R, et al. Deep neural networks as Gaussian processes[EB/OL]. (2018-03-03) [2022-12-23].. |
| 21 | BELKIN M, HSU D, MA S, et al. Reconciling modern machine-learning practice and the classical bias-variance trade-off[J]. Proceedings of the National Academy of Sciences of Sciences of the United States of America, 2019, 116(32): 15849-15854. 10.1073/pnas.1903070116 |
| 22 | 张军阳, 王慧丽, 郭阳,等. 深度学习相关研究综述[J]. 计算机应用研究, 2018, 35(7): 1921-1928,1936. 10.3969/j.issn.1001-3695.2018.07.001 |
| ZHANG J Y, WANG H L, GUO Y, et al. Review of deep learning[J]. Application Research of Computers, 2018, 35(7): 1921-1928,1936. 10.3969/j.issn.1001-3695.2018.07.001 | |
| 23 | MISHKIN D, MATAS J. All you need is a good init[EB/OL]. (2016-02-19) [2022-12-23].. |
| 24 | LILLICRAP T P, COWNDEN D, TWEED D B, et al. Random synaptic feedback weights support error backpropagation for deep learning[J]. Nature Communications, 2016, 7: No.13276. 10.1038/ncomms13276 |
| 25 | HUANG W, XU R Y D, DU W, et al. Mean field theory for deep dropout networks: digging up gradient backpropagation deeply[C]// Proceedings of the 24th European Conference on Artificial Intelligence. Amsterdam: IOS Press, 2020: 1215-1222. 10.24963/ijcai.2021/355 |
| 26 | YANG G, PENNINGTON J, RAO V, et al. A mean field theory of batch normalization[EB/OL]. (2019-03-05) [2022-12-23].. |
| 27 | SERRA T, TJANDRAATMADJA C, RAMALINGAM S. Bounding and counting linear regions of deep neural networks[C]// Proceedings of the 35th International Conference on Machine Learning. New York: JMLR.org, 2018: 4558-4566. |
| 28 | PENNINGTON J, WORAH P. Nonlinear random matrix theory for deep learning[C]// Proceedings of the 31st International Conference on Neural Information Processing Systems. Red Hook, NY: Curran Associates Inc., 2017: 2634-2643. 10.7551/mitpress/11474.003.0014 |
| 29 | YANG G, SCHOENHOLZ S S. Mean field residual networks: on the edge of chaos[C]// Proceedings of the 31st International Conference on Neural Information Processing Systems. Red Hook, NY: Curran Associates Inc., 2017: 2865-2873. 10.48550/arXiv.1712.08969 |
| 30 | HE K, ZHANG X, REN S, et al. Deep residual learning for image recognition[C]// Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2016: 770-778. 10.1109/cvpr.2016.90 |
| 31 | HAYOU S, DOUCET A, ROUSSEAU J. On the impact of the activation function on deep neural networks training[C]// Proceedings of the 36th International Conference on Machine Learning. New York: JMLR.org, 2019: 2672-2680. 10.1109/comitcon.2019.8862253 |
| 32 | PENNINGTON J, SCHOENHOLZ S S, GANGULI S. The emergence of spectral universality in deep networks[C]// Proceedings of the 21st International Conference on Artificial Intelligence and Statistics. New York: JMLR.org, 2018: 1924-1932. |
| 33 | GIRKO V L. Spectral theory of random matrices[J]. Russian Mathematical Surveys, 1985, 40(1): No.77. 10.1070/rm1985v040n01abeh003528 |
| 34 | WIGNER E P. Characteristic vectors of bordered matrices with infinite dimensions[J]. Annals of Mathematics, 1955, 62(3): 548-564. 10.2307/1970079 |
| 35 | LITTWIN E, GALANTI T, WOLF L, et al. Appendix: on infinite-width hypernetworks[C/OL]// Proceedings of the 34th Conference on Neural Information Processing Systems (2020) [2022-12-23].. |
| 36 | RODRÍGUEZ P, GONZALEZ J, CUCURULL G, et al. Regularizing CNNs with locally constrained decorrelations[EB/OL]. (2017-03-15) [2022-12-23].. |
| 37 | XIE D, XIONG J, PU S. All you need is beyond a good init: exploring better solution for training extremely deep convolutional neural networks with orthonormality and modulation[C]// Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2017: 5075-5084. 10.1109/cvpr.2017.539 |
| 38 | ARJOVSKY M, SHAH A, BENGIO Y. Unitary evolution recurrent neural networks[C]// Proceedings of the 33rd International Conference on Machine Learning. New York: JMLR.org, 2016: 1120-1128. |
| 39 | LE Q V, JAITLY N, HINTON G E. A simple way to initialize recurrent networks of rectified linear units[EB/OL]. (2015-04-07) [2022-12-23].. |
| 40 | LI S, JIA K, WEN Y, et al. Orthogonal deep neural networks[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2021, 43(4): 1352-1368. 10.1109/tpami.2019.2948352 |
| 41 | WANG J, CHEN Y, CHAKRABORTY R, et al. Orthogonal convolutional neural networks[C]// Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2020: 11502-11512. 10.1109/cvpr42600.2020.01152 |
| 42 | GUO K, ZHOU K, HU X, et al. Orthogonal graph neural networks[C]// Proceedings of the 36th AAAI Conference on Artificial Intelligence. Palo Alto, CA: AAAI Press, 2022: 3996-4004. 10.1609/aaai.v36i4.20316 |
| 43 | QI H, YOU C, WANG X, et al. Deep isometric learning for visual recognition[C]// Proceedings of the 37th International Conference on Machine Learning. New York: JMLR.org, 2020: 7824-7835. |
| 44 | HUANG Y, CHENG Y, BAPNA A, et al. GPipe: efficient training of giant neural networks using pipeline parallelism[C]// Proceedings of the 33rd International Conference on Neural Information Processing Systems. Red Hook, NY: Curran Associates Inc., 2019: 103-112. |
| 45 | ARORA S, DU S S, HU W, et al. Fine-grained analysis of optimization and generalization for overparameterized two-layer neural networks[C]// Proceedings of the 36th International Conference on Machine Learning. New York: JMLR.org, 2019: 322-332. |
| 46 | DU S S, ZHAI X, POCZÓS B, et al. Gradient descent provably optimizes over-parameterized neural networks[EB/OL]. (2019-02-05) [2022-12-23].. |
| 47 | ZHANG C, BENGIO S, HARDT M, et al. Understanding deep learning (still) requires rethinking generalization[J]. Communications of the ACM, 2021, 64(3): 107-115. 10.1145/3446776 |
| 48 | ZOU D, GU Q. An improved analysis of training over-parameterized deep neural networks[C]// Proceedings of the 33rd International Conference on Neural Information Processing Systems. Red Hook, NY: Curran Associates Inc., 2019: 2055-2064. 10.1007/s10994-019-05839-6 |
| 49 | BISHOP C M. Pattern Recognition and Machine Learning, ISS[M]. New York: Springer, 2006. |
| 50 | DE G MATTHEWS A G, ROWLAND M, HRON J, et al. Gaussian process behaviour in wide deep neural networks[EB/OL]. (2018-08-16) [2022-12-23].. |
| 51 | GARRIGA-ALONSO A, RASMUSSEN C E, AITCHISON L. Deep convolutional networks as shallow gaussian processes[EB/OL]. (2019-05-05) [2022-12-23].. |
| 52 | NOVAK R, XIAO L, LEE J, et al. Bayesian deep convolutional networks with many channels are Gaussian processes[EB/OL]. (2020-08-21) [2022-12-23].. |
| 53 | AGRAWAL D, PAPAMARKOU T, HINKLE J. Wide neural networks with bottlenecks are deep Gaussian processes[J]. Journal of Machine Learning Research, 2020, 21: 1-66. |
| 54 | PRETORIUS A, KAMPER H, KROON S. On the expected behaviour of noise regularised deep neural networks as Gaussian processes[J]. Pattern Recognition Letters, 2020, 138: 75-81. 10.1016/j.patrec.2020.06.027 |
| 55 | LEE J, SCHOENHOLZ S S, PENNINGTON J, et al. Finite versus infinite neural networks: an empirical study[C]// Proceedings of the 34th International Conference on Neural Information Processing Systems. Red Hook, NY: Curran Associates Inc., 2020: 15156-15172. |
| 56 | NAVEH G, RINGEL Z. A self-consistent theory of Gaussian Processes captures feature learning effects in finite CNNs[C/OL]// Proceedings of the 35th Conference on Neural Information Processing Systems (2021) [2022-12-23].. 10.1093/oso/9780198530237.003.0007 |
| 57 | SEROUSSI I, NAVEH G, RINGEL Z. Separation of scales and a thermodynamic description of feature learning in some CNNs[J]. Nature Communications, 2023, 14: No.908. 10.1038/s41467-023-36361-y |
| 58 | 王梅,许传海,刘勇. 基于神经正切核的多核学习方法[J]. 计算机应用, 2021, 41(12): 3462-3467. 10.11772/j.issn.1001-9081.2021060998 |
| WANG M, XU C H, LIU Y. Multi-kernel learning method based on neural tangent kernel[J]. Journal of Computer Applications, 2021, 41(12): 3462-3467. 10.11772/j.issn.1001-9081.2021060998 | |
| 59 | LEE J, XIAO L, SCHOENHOLZ S, et al. Wide neural networks of any depth evolve as linear models under gradient descent[C]// Proceedings of the 32nd International Conference on Neural Information Processing Systems. Red Hook, NY: Curran Associates Inc., 2019: 8572-8583. 10.1088/1742-5468/abc62b |
| 60 | ARORA S, DU S S, HU W, et al. On exact computation with an infinitely wide neural net[C]// Proceedings of the 32nd International Conference on Neural Information Processing Systems. Red Hook, NY: Curran Associates Inc., 2019: 8751-8760. |
| 61 | LI Z, WANG R, YU D, et al. Enhanced convolutional neural tangent kernels[EB/OL]. (2019-11-03) [2022-12-23].. |
| 62 | HAYOU S, DOUCET A, ROUSSEAU J. The curse of depth in kernel regime[C]// Proceedings of the "I (Still) Can’t Believe It’s Not Better!" at NeurIPS 2021 Workshops. New York: JMLR.org, 2022: 41-47. |
| 63 | DU S S, HOU K, PÓCZOS B, et al. Graph neural tangent kernel: fusing graph neural networks with graph kernels[C]// Proceedings of the 33rd International Conference on Neural Information Processing Systems. Red Hook, NY: Curran Associates Inc., 2019: 5723-5733. |
| 64 | YANG G. Tensor programs II: neural tangent kernel for any architecture[EB/OL]. (2020-11-30) [2022-12-23].. |
| 65 | HUANG W, DU W, XU R Y D. On the neural tangent kernel of deep networks with orthogonal initialization[EB/OL]. (2021-07-21) [2022-12-23].. 10.24963/ijcai.2021/355 |
| 66 | ALEMOHAMMAD S, WANG Z, BALESTRIERO R, et al. The recurrent neural tangent kernel[EB/OL]. (2021-06-15) [2022-12-23].. 10.1109/icassp39728.2021.9413450 |
| 67 | NOVAK R, XIAO L, HRON J, et al. Neural Tangents: fast and easy infinite neural networks in python[EB/OL]. (2019-12-05) [2022-12-23].. |
| 68 | Google. JAX: composable transformations of Python+ NumPy programs: differentiate, vectorize, JIT to GPU/TPU, and more[EB/OL]. [2022-12-23].. |
| 69 | NOVAK R, SOHL-DICKSTEIN J, SCHOENHOLZ S S. Fast finite width neural tangent kernel[C]// Proceedings of the 39th International Conference on Machine Learning. New York: JMLR.org, 2022: 17018-17044. |
| 70 | YANG G. Scaling limits of wide neural networks with weight sharing: Gaussian process behavior, gradient independence, and neural tangent kernel derivation[EB/OL]. (2020-04-04) [2022-12-23].. 10.1109/tmc.2023.3271715/mm1 |
| 71 | YANG G. Wide feedforward or recurrent neural networks of any architecture are Gaussian processes[C]// Proceedings of the 33rd International Conference on Neural Information Processing Systems. Red Hook, NY: Curran Associates Inc., 2019: 9951-9960. |
| 72 | YANG G, LITTWIN E. Tensor programs IIb: architectural universality of neural tangent kernel training dynamics[C]// Proceedings of the 38th International Conference on Machine Learning. New York: JMLR.org, 2021: 11762-11772. |
| 73 | YANG G, HU E J. Tensor programs IV: feature learning in infinite-width neural networks[C]// Proceedings of the 38th International Conference on Machine Learning. New York: JMLR.org, 2021: 11727-11737. |
| 74 | XIAO L, PENNINGTON J, SCHOENHOLZ S S. Disentangling trainability and generalization in deep neural networks[C]// Proceedings of the 37th International Conference on Machine Learning. New York: JMLR.org, 2020: 10462-10472. |
| 75 | KESKAR N S, MUDIGERE D, NOCEDAL J, et al. On large-batch training for deep learning: generalization gap and sharp minima[EB/OL]. (2017-02-09) [2022-12-23].. |
| 76 | MEI S, MONTANARI A, NGUYEN P M. A mean field view of the landscape of two-layer neural networks[J]. Proceedings of the National Academy of Sciences of Sciences of the United States of America, 2018, 115(33): E7665-E7671. 10.1073/pnas.1806579115 |
| 77 | ZHANG Y, SAXE A M, ADVANI M S, et al. Energy-entropy competition and the effectiveness of stochastic gradient descent in machine learning[J]. Molecular Physics, 2018, 116(21/22): 3214-3223. 10.1080/00268976.2018.1483535 |
| 78 | 姜晓勇,李忠义,黄朗月,等. 神经网络剪枝技术研究综述[J]. 应用科学学报, 2022, 40(5): 838-849. 10.3969/j.issn.0255-8297.2022.05.013 |
| JIANG X Y, LI Z Y, HUANG L Y, et al. Review of neural network pruning techniques[J]. Journal of Applied Science, 2022, 40(5): 838-849. 10.3969/j.issn.0255-8297.2022.05.013 | |
| 79 | HE Z, XIE Z, ZHU Q, et al. Sparse double descent: where network pruning aggravates overfitting[C]// Proceedings of the 39th International Conference on Machine Learning. New York: JMLR.org, 2022: 8635-8659. |
| 80 | 胡铁松, 严铭, 赵萌. 基于领域知识的神经网络泛化性能研究进展[J]. 武汉大学学报(工学版), 2016, 49(3): 321-328. |
| HU T S, YAN M, ZHAO M. Research advances of neural network generalization performance based on domain knowledge[J]. Engineering Journal of Wuhan University, 2016, 49(3): 321-328. | |
| 81 | PARTRIDGE D. Network generation differences quantified[J]. Neural Networks, 1996, 9(2): 263-271. 10.1016/0893-6080(95)00110-7 |
| 82 | LIU J, JIANG G Q, BAI Y, et al. Understanding why neural networks generalize well through GSNR of parameters[EB/OL]. (2020-02-24) [2022-12-23].. 10.1109/ijcnn.2019.8852436 |
| 83 | JIANG Y, KRISHNAN D, MOBAHI H, et al. Predicting the generalization gap in deep networks with margin distributions[EB/OL]. (2019-06-12) [2022-12-23].. |
| 84 | HOLMSTROM L, KOISTINEN P. Using additive noise in back- propagation training[J]. IEEE Transactions on Neural Networks, 1992, 3(1): 24-38. 10.1109/72.105415 |
| 85 | VYAS N, BANSAL Y, NAKKIRAN P. Limitations of the NTK for understanding generalization in deep learning[EB/OL]. (2022-06-20) [2022-12-23].. |
| 86 | ZAVATONE-VETH J A, PEHLEVAN C. Learning curves for deep structured Gaussian feature models[C/OL]// Proceedings of the 37th Conference on Neural Information Processing Systems (2023) [2023-10-23].. 10.21468/scipostphyscore.6.2.026 |
| 87 | SRIVASTAVA N, HINTON G, KRIZHEVSKY A, et al. Dropout: a simple way to prevent neural networks from overfitting[J]. Journal of Machine Learning Research, 2014, 15(1): 1929-1958. |
| 88 | JASTRZĘBSKI S, KENTON Z, ARPIT D, et al. Three factors influencing minima in SGD[EB/OL]. (2018-09-13) [2022-12-23].. 10.1007/978-3-030-01424-7_39 |
| 89 | GE R, HUANG F, JIN C, et al. Escaping from saddle points-online stochastic gradient for tensor decomposition[C]// Proceedings of the 28th International Conference on Learning Theory. New York: JMLR.org, 2015: 797-842. |
| 90 | ANANDKUMAR A, GE R. Efficient approaches for escaping higher order saddle points in non-convex optimization[C]// Proceedings of the 29th International Conference on Learning Theory. New York: JMLR.org, 2016: 81-102. |
| 91 | SIMON J B, DICKENS M, KARKADA D, et al. The Eigenlearning framework: a conservation law perspective on Kernel regression and wide neural networks[EB/OL]. (2021-10-28) [2023-10-26]. . |
| 92 | 李杏峰,黄玉清,任珍文. 联合低秩稀疏的多核子空间聚类算法[J]. 计算机应用, 2020, 40(6): 1648-1653. 10.11772/j.issn.1001-9081.2019111991 |
| LI X F, HUANG Y Q, REN Z W. Joint low-rank and sparse multiple kernel subspace clustering algorithm[J]. Journal of Computer Applications, 2020, 40(6): 1648-1653. 10.11772/j.issn.1001-9081.2019111991 | |
| 93 | BORDELON B, PEHLEVAN C. Population codes enable learning from few examples by shaping inductive bias[J]. eLife, 2022, 11: No.e78606. 10.7554/elife.78606 |
| 94 | MISIAKIEWICZ T, MEI S. Learning with convolution and pooling operations in kernel methods[C/OL]// Proceedings of the 36th Conference on Neural Information Processing Systems (2022) [2022-12-23].. |
| 95 | MARTIN C H, MAHONEY M W. Heavy-tailed universality predicts trends in test accuracies for very large pre-trained deep neural networks[C]// Proceedings of the 2020 SIAM International Conference on Data Mining. Philadelphia, PA: SIAM, 2020: 505-513. 10.1137/1.9781611976236.57 |
| 96 | BORDELON B, PEHLEVAN C. Self-consistent dynamical field theory of kernel evolution in wide neural networks[C/OL]// Proceedings of the 36th Conference on Neural Information Processing Systems (2022) [2022-12-23].. 10.1088/1742-5468/ad01b0 |
| 97 | BORDELON B, PEHLEVAN C. The influence of learning rule on representation dynamics in wide neural networks[EB/OL]. (2023-05-25) [2023-10-23].. 10.1088/1742-5468/ad01b0 |
| 98 | COHEN O, MALKA O, RINGEL Z. Learning curves for over- parametrized deep neural networks: a field theory perspective[J]. Physical Review Research, 2021, 3(2): No.023034. 10.1103/physrevresearch.3.023034 |
| 99 | CANATAR A, PEHLEVAN C. A kernel analysis of feature learning in deep neural networks[C]// Proceedings of the 58th Annual Allerton Conference on Communication, Control, and Computing. Piscataway: IEEE, 2022: 1-8. 10.1109/allerton49937.2022.9929375 |
| 100 | HELIAS M, DAHMEN D. Statistical Field Theory for Neural Networks, LNP 970[M]. Cham: Springer, 2020. 10.1007/978-3-030-46444-8 |
| [1] | 石锐, 李勇, 朱延晗. 基于特征梯度均值化的调制信号对抗样本攻击算法[J]. 《计算机应用》唯一官方网站, 2024, 44(8): 2521-2527. |
| [2] | 王美, 苏雪松, 刘佳, 殷若南, 黄珊. 时频域多尺度交叉注意力融合的时间序列分类方法[J]. 《计算机应用》唯一官方网站, 2024, 44(6): 1842-1847. |
| [3] | 肖斌, 杨模, 汪敏, 秦光源, 李欢. 独立性视角下的相频融合领域泛化方法[J]. 《计算机应用》唯一官方网站, 2024, 44(4): 1002-1009. |
| [4] | 柴汶泽, 范菁, 孙书魁, 梁一鸣, 刘竟锋. 深度度量学习综述[J]. 《计算机应用》唯一官方网站, 2024, 44(10): 2995-3010. |
| [5] | 赵旭剑, 李杭霖. 基于混合机制的深度神经网络压缩算法[J]. 《计算机应用》唯一官方网站, 2023, 43(9): 2686-2691. |
| [6] | 申云飞, 申飞, 李芳, 张俊. 基于张量虚拟机的深度神经网络模型加速方法[J]. 《计算机应用》唯一官方网站, 2023, 43(9): 2836-2844. |
| [7] | 李校林, 杨松佳. 基于深度学习的多用户毫米波中继网络混合波束赋形[J]. 《计算机应用》唯一官方网站, 2023, 43(8): 2511-2516. |
| [8] | 李淦, 牛洺第, 陈路, 杨静, 闫涛, 陈斌. 融合视觉特征增强机制的机器人弱光环境抓取检测[J]. 《计算机应用》唯一官方网站, 2023, 43(8): 2564-2571. |
| [9] | 杨海宇, 郭文普, 康凯. 基于卷积长短时深度神经网络的信号调制方式识别方法[J]. 《计算机应用》唯一官方网站, 2023, 43(4): 1318-1322. |
| [10] | 高媛媛, 余振华, 杜方, 宋丽娟. 基于贝叶斯优化的无标签网络剪枝算法[J]. 《计算机应用》唯一官方网站, 2023, 43(1): 30-36. |
| [11] | 廖发康, 周亚丽, 张奇志. 变长度柔性双足机器人行走控制及稳定性分析[J]. 《计算机应用》唯一官方网站, 2023, 43(1): 312-320. |
| [12] | 刘小宇, 陈怀新, 刘壁源, 林英, 马腾. 自适应置信度阈值的非限制场景车牌检测算法[J]. 《计算机应用》唯一官方网站, 2023, 43(1): 67-73. |
| [13] | 杨博, 张恒巍, 李哲铭, 徐开勇. 基于图像翻转变换的对抗样本生成方法[J]. 《计算机应用》唯一官方网站, 2022, 42(8): 2319-2325. |
| [14] | 玄英律, 万源, 陈嘉慧. 基于多尺度卷积和注意力机制的LSTM时间序列分类[J]. 《计算机应用》唯一官方网站, 2022, 42(8): 2343-2352. |
| [15] | 李坤, 侯庆. 基于注意力机制的轻量型人体姿态估计[J]. 《计算机应用》唯一官方网站, 2022, 42(8): 2407-2414. |
| 阅读次数 | ||||||
|
全文 |
|
|||||
|
摘要 |
|
|||||