


《计算机应用》唯一官方网站 ›› 2025, Vol. 45 ›› Issue (6): 2034-2042.DOI: 10.11772/j.issn.1001-9081.2024060748
• 多媒体计算与计算机仿真 • 上一篇
孙林嘉, 秦磊, 康美金, 王莹琳
收稿日期:2024-06-06
修回日期:2024-09-25
接受日期:2024-09-27
发布日期:2024-10-12
出版日期:2025-06-10
通讯作者:
孙林嘉
作者简介:孙林嘉(1983—),男,山西朔州人,助理研究员,博士,主要研究方向:语言资源建设、语音处理 sunlinjia@Blcu.edu.cn基金资助:Linjia SUN, Lei QIN, Meijin KANG, Yinglin WANG
Received:2024-06-06
Revised:2024-09-25
Accepted:2024-09-27
Online:2024-10-12
Published:2025-06-10
Contact:
Linjia SUN
About author:SUN Linjia, born in 1983, Ph. D., assistant research fellow. His research interests include language resource construction, speech processing.Supported by:摘要:
基于边界检测的方法侧重利用时域和频域的突变来将语音数据切分成音节单元,较少关注语言知识在分割中发挥的作用。同时,此类方法通常需要设置各项参数以获得满意的分割结果,致使这些方法在大数据量和跨语言的环境下存在稳定性差、调整参数难和泛化能力弱的缺点。针对上述问题,提出一种基于音节类型识别的自动语音分割算法。该算法的特点在于所要识别的对象是语音数据中的音节类型,而非具体的音节内容。首先,利用语言学研究成果和音节构成规律获得不同语言在自然发音下较通用的音节类型;其次,采用经典的高斯混合模型(GMM)和隐马尔可夫模型(HMM)为每种音节类型构建声学模型;另外,为了更好地描述音节属性,提出一种基于多频带分析和显著信息融合的特征提取通道;最后,在所识别音节类型序列的基础上,使用维特比算法确定对应音节起止点的语音帧。在实验阶段利用3种常见语言的语音数据训练得到音节类型的声学模型,再在6种语言和方言上进行识别实验。实验结果表明,所提算法的平均识别准确率至少达到了91.93%;与使用梅尔频率倒谱系数(MFCC)相比,使用所提特征获得的平均识别准确率至少提升了27.16个百分点;当容差阈值为20 ms时,在6种语言和方言上依然可以取得90.70%以上的平均分割准确率;相较于近年来有代表性的4种算法,所提算法的平均分割准确率至少提升了5.73个百分点。以上说明所提算法具有较强的泛化能力、较好的稳定性和较高的分割准确率。
中图分类号:
孙林嘉, 秦磊, 康美金, 王莹琳. 基于音节类型识别的自动语音分割算法[J]. 计算机应用, 2025, 45(6): 2034-2042.
Linjia SUN, Lei QIN, Meijin KANG, Yinglin WANG. Automatic speech segmentation algorithm based on syllable type recognition[J]. Journal of Computer Applications, 2025, 45(6): 2034-2042.
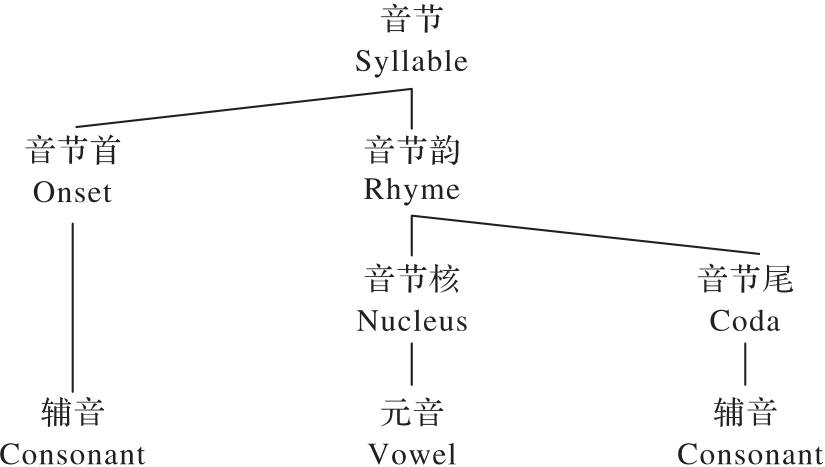
图1 音节结构
Fig. 1 Syllable structure
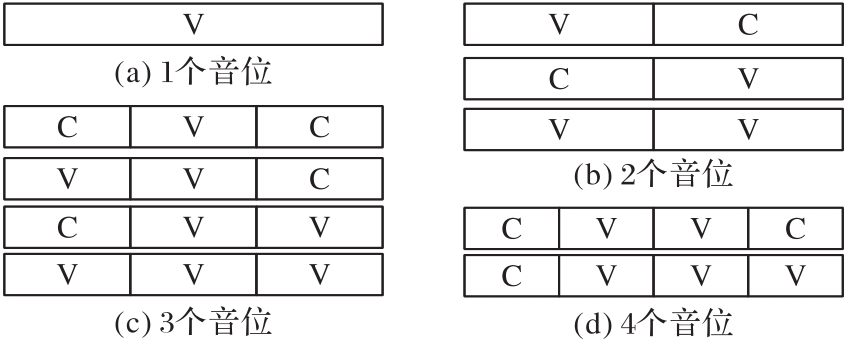
图2 音节类型示意图
Fig. 2 Schematic diagrams of syllable types
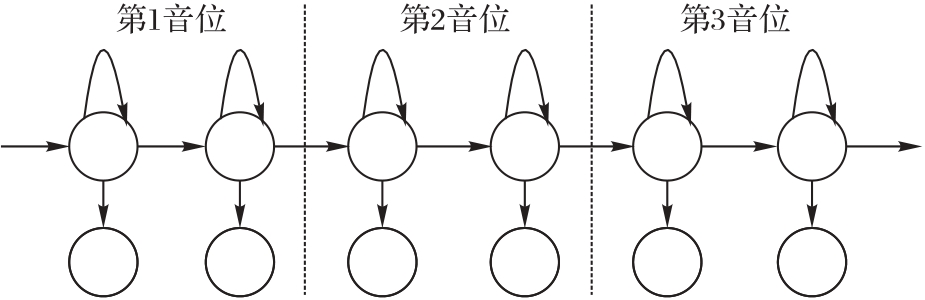
图3 3个音位2个状态音节类型的声学模型的示例
Fig.3 Example of acoustic model of syllable type with three phonemes, each containing two states
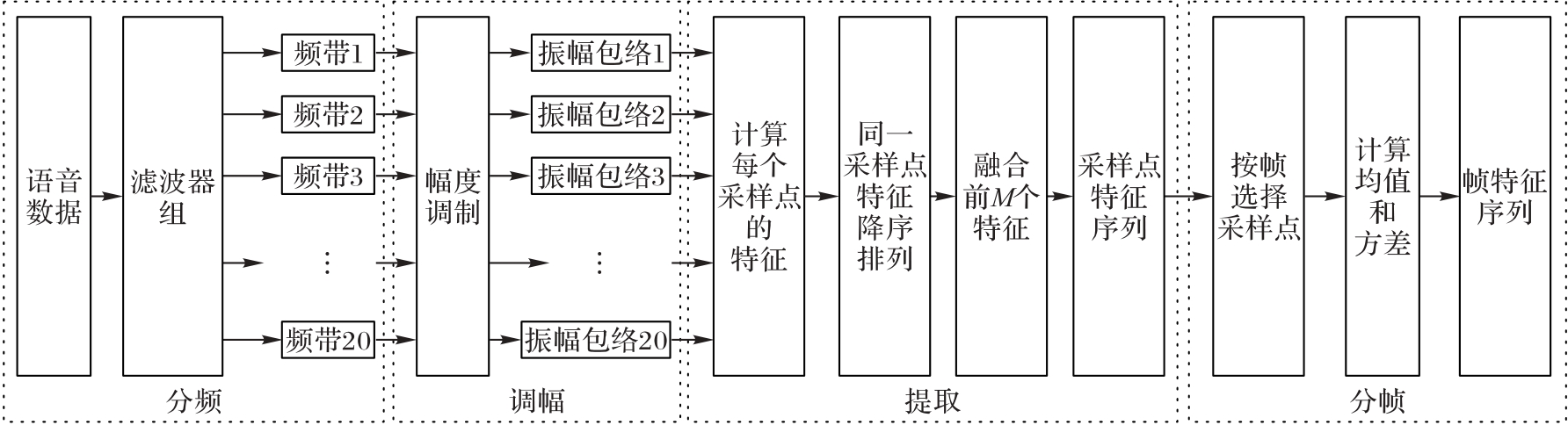
图4 可观测特征向量提取流程
Fig. 4 Flow of extracting visual feature vectors
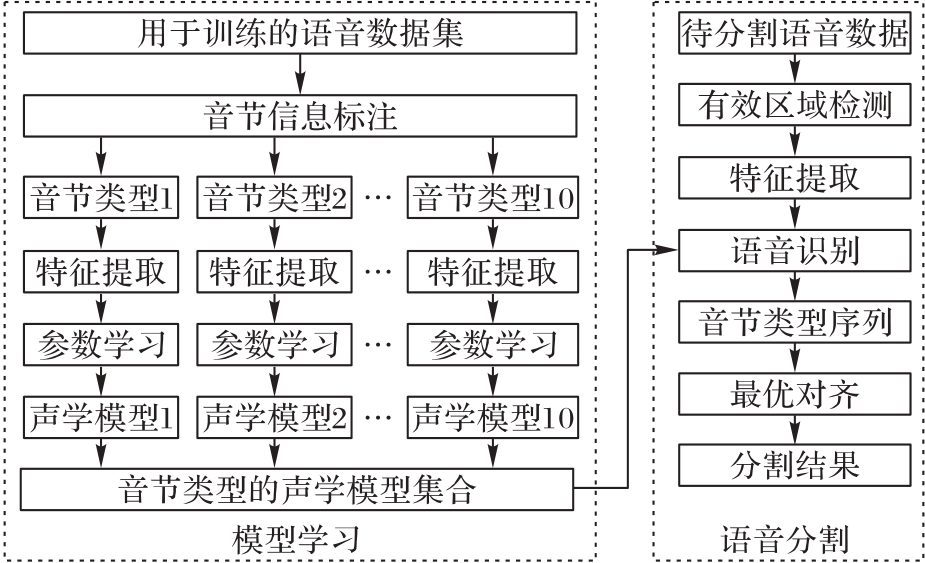
图5 本文算法框架
Fig. 5 Framework of proposed algorithm
语言和 方言 | 数据 来源 | 文件数 | 文件 时长/h | 分布占比/% | |
|---|---|---|---|---|---|
模型 学习 | 语音 分割 | ||||
| 英语 | TIMIT | 6 300 | 5 | 60 | 40 |
| 法语 | MediaSpeech | 2 498 | 10 | 60 | 40 |
| 西班牙语 | MediaSpeech | 2 507 | 10 | 0 | 100 |
| 汉语普通话 | THCHS | 10 000 | 40 | 60 | 40 |
| 汉语晋方言 | 调查采集 | 8 000 | 11 | 0 | 100 |
| 汉语吴方言 | 调查采集 | 8 000 | 11 | 0 | 100 |
表1 实验所用语音数据的概要信息及其分布情况
Tab. 1 Summary information of speech data used in experiments and its distribution
语言和 方言 | 数据 来源 | 文件数 | 文件 时长/h | 分布占比/% | |
|---|---|---|---|---|---|
模型 学习 | 语音 分割 | ||||
| 英语 | TIMIT | 6 300 | 5 | 60 | 40 |
| 法语 | MediaSpeech | 2 498 | 10 | 60 | 40 |
| 西班牙语 | MediaSpeech | 2 507 | 10 | 0 | 100 |
| 汉语普通话 | THCHS | 10 000 | 40 | 60 | 40 |
| 汉语晋方言 | 调查采集 | 8 000 | 11 | 0 | 100 |
| 汉语吴方言 | 调查采集 | 8 000 | 11 | 0 | 100 |
音节 类型 | 第1音位 状态数 | 第2音位 状态数 | 第3音位 状态数 | 第4音位 状态数 |
|---|---|---|---|---|
| V | 4 | 0 | 0 | 0 |
| CV | 5 | 4 | 0 | 0 |
| VC | 4 | 4 | 0 | 0 |
| VV | 3 | 3 | 0 | 0 |
| CVC | 5 | 4 | 4 | 0 |
| CVV | 5 | 3 | 3 | 0 |
| VVC | 3 | 3 | 4 | 0 |
| VVV | 3 | 3 | 3 | 0 |
| CVVC | 5 | 3 | 3 | 4 |
| CVVV | 5 | 3 | 3 | 3 |
表2 不同音节类型的声学模型的最佳状态结构
Tab.2 Optimal state structure of acoustic models for different syllable types
音节 类型 | 第1音位 状态数 | 第2音位 状态数 | 第3音位 状态数 | 第4音位 状态数 |
|---|---|---|---|---|
| V | 4 | 0 | 0 | 0 |
| CV | 5 | 4 | 0 | 0 |
| VC | 4 | 4 | 0 | 0 |
| VV | 3 | 3 | 0 | 0 |
| CVC | 5 | 4 | 4 | 0 |
| CVV | 5 | 3 | 3 | 0 |
| VVC | 3 | 3 | 4 | 0 |
| VVV | 3 | 3 | 3 | 0 |
| CVVC | 5 | 3 | 3 | 4 |
| CVVV | 5 | 3 | 3 | 3 |
语言和 方言 | 不同时长 | 引入 噪声 | 使用MFCC | ||
|---|---|---|---|---|---|
| 1.5 s | 4.0 s | 7.0 s | |||
| 英语 | 94.02 | 93.69 | 93.28 | 92.86 | 70.21 |
| 法语 | 94.17 | 94.06 | 94.23 | 92.37 | 72.35 |
| 汉语普通话 | 93.89 | 93.17 | 93.54 | 92.63 | 70.36 |
| 均值1 | 94.03 | 93.64 | 93.68 | 92.62 | 70.97 |
| 西班牙语 | 89.61 | 89.75 | 89.27 | 87.29 | 54.89 |
| 汉语吴方言 | 90.98 | 90.24 | 90.36 | 88.08 | 56.03 |
| 汉语晋方言 | 90.23 | 90.71 | 90.92 | 88.85 | 55.27 |
| 均值2 | 90.27 | 90.23 | 90.18 | 88.07 | 55.40 |
| 均值3 | 92.15 | 91.94 | 91.93 | 90.35 | 63.19 |
表3 不同时长、引入噪声和使用MFCC情况下的平均识别准确率 (%)
Tab. 3 Average recognition accuracies under different durations, added noise, and MFCC
语言和 方言 | 不同时长 | 引入 噪声 | 使用MFCC | ||
|---|---|---|---|---|---|
| 1.5 s | 4.0 s | 7.0 s | |||
| 英语 | 94.02 | 93.69 | 93.28 | 92.86 | 70.21 |
| 法语 | 94.17 | 94.06 | 94.23 | 92.37 | 72.35 |
| 汉语普通话 | 93.89 | 93.17 | 93.54 | 92.63 | 70.36 |
| 均值1 | 94.03 | 93.64 | 93.68 | 92.62 | 70.97 |
| 西班牙语 | 89.61 | 89.75 | 89.27 | 87.29 | 54.89 |
| 汉语吴方言 | 90.98 | 90.24 | 90.36 | 88.08 | 56.03 |
| 汉语晋方言 | 90.23 | 90.71 | 90.92 | 88.85 | 55.27 |
| 均值2 | 90.27 | 90.23 | 90.18 | 88.07 | 55.40 |
| 均值3 | 92.15 | 91.94 | 91.93 | 90.35 | 63.19 |
语言和 方言 | 不同容差阈值 | 不同先验知识 (容差阈值=20 ms) | |||
|---|---|---|---|---|---|
| 20 ms | 30 ms | 40 ms | 音节数 | 类型序列 | |
| 均值 | 90.70 | 91.12 | 91.55 | 91.20 | 91.43 |
| 英语 | 92.54 | 92.96 | 93.35 | 93.06 | 93.13 |
| 法语 | 91.71 | 92.44 | 93.27 | 92.56 | 92.87 |
| 汉语普通话 | 93.03 | 93.76 | 94.15 | 93.47 | 93.84 |
| 西班牙语 | 88.14 | 88.34 | 88.77 | 88.57 | 88.82 |
| 汉语吴方言 | 89.32 | 89.51 | 89.92 | 89.72 | 89.96 |
| 汉语晋方言 | 89.48 | 89.68 | 89.85 | 89.81 | 89.93 |
表4 不同容差阈值和先验知识情况下的平均分割准确率 (%)
Tab. 4 Average segmentation accuracies under different tolerance thresholds and prior knowledge
语言和 方言 | 不同容差阈值 | 不同先验知识 (容差阈值=20 ms) | |||
|---|---|---|---|---|---|
| 20 ms | 30 ms | 40 ms | 音节数 | 类型序列 | |
| 均值 | 90.70 | 91.12 | 91.55 | 91.20 | 91.43 |
| 英语 | 92.54 | 92.96 | 93.35 | 93.06 | 93.13 |
| 法语 | 91.71 | 92.44 | 93.27 | 92.56 | 92.87 |
| 汉语普通话 | 93.03 | 93.76 | 94.15 | 93.47 | 93.84 |
| 西班牙语 | 88.14 | 88.34 | 88.77 | 88.57 | 88.82 |
| 汉语吴方言 | 89.32 | 89.51 | 89.92 | 89.72 | 89.96 |
| 汉语晋方言 | 89.48 | 89.68 | 89.85 | 89.81 | 89.93 |
| 语言和方言 | 本文 算法 | 峰值分类 算法 | 振荡调幅 算法 | 迭代优化 算法 | 多级切分 算法 |
|---|---|---|---|---|---|
| 均值 | 90.70 | 84.97 | 83.36 | 82.45 | 77.62 |
| 英语 | 92.54 | 88.38 | 86.03 | 84.67 | 72.44 |
| 法语 | 91.71 | 87.65 | 85.84 | 83.58 | 71.86 |
| 汉语普通话 | 93.03 | 82.27 | 80.69 | 81.82 | 85.46 |
| 西班牙语 | 88.14 | 87.39 | 85.62 | 83.28 | 71.39 |
| 汉语吴方言 | 89.32 | 81.86 | 80.72 | 80.43 | 81.75 |
| 汉语晋方言 | 89.48 | 82.26 | 81.24 | 80.94 | 82.81 |
表5 所提算法和4种不同算法在容差阈值为20 ms下的平均分割准确率对比 (%)
Tab. 5 Comparison of average segmentation accuracy between proposed algorithm and four different algorithms with tolerance threshold of 20 ms
| 语言和方言 | 本文 算法 | 峰值分类 算法 | 振荡调幅 算法 | 迭代优化 算法 | 多级切分 算法 |
|---|---|---|---|---|---|
| 均值 | 90.70 | 84.97 | 83.36 | 82.45 | 77.62 |
| 英语 | 92.54 | 88.38 | 86.03 | 84.67 | 72.44 |
| 法语 | 91.71 | 87.65 | 85.84 | 83.58 | 71.86 |
| 汉语普通话 | 93.03 | 82.27 | 80.69 | 81.82 | 85.46 |
| 西班牙语 | 88.14 | 87.39 | 85.62 | 83.28 | 71.39 |
| 汉语吴方言 | 89.32 | 81.86 | 80.72 | 80.43 | 81.75 |
| 汉语晋方言 | 89.48 | 82.26 | 81.24 | 80.94 | 82.81 |
| 1 | 林佳庆,李涓子,张鹏. 中国语言资源采录展示平台的关键技术及其应用[J]. 语言文字应用, 2019(4):26-34. |
| LIN J Q, LI J Z, ZHANG P. The key technologies and the applications for China language resources collection and service platform[J]. Applied Linguistics, 2019(4): 26-34. | |
| 2 | ARDILA R, BRANSON M, DAVIS K, et al. Common voice: a massively-multilingual speech corpus[C]// Proceedings of the 12th Language Resources and Evaluation Conference. Paris: European Language Resources Association, 2020: 3118-4222. |
| 3 | 杨健,李振鹏,苏鹏. 语音分割与端点检测研究综述[J]. 计算机应用, 2020, 40(1):1-7. |
| YANG J, LI Z P, SU P. Review of speech segmentation and endpoint detection[J]. Journal of Computer Applications, 2020, 40(1):1-7. | |
| 4 | BOERSMA P, WEENINK D. Praat: doing phonetics by computer[EB/OL]. [2024-05-02].. |
| 5 | GOLDMAN J P. EasyAlign: an automatic phonetic alignment tool under Praat[C]// Proceedings of the INTERSPEECH 2011. [S.l.]: International Speech Communication Association, 2011: 3233-3236. |
| 6 | 张扬,赵晓群,王缔罡. 基于时频二维能量特征的汉语音节切分方法[J]. 计算机应用, 2016, 36(11):3222-3228. |
| ZHANG Y, ZHAO X Q, WANG D G. Chinese speech segmentation into syllables based on energies in different times and frequencies [J]. Journal of Computer Applications, 2016, 36(11): 3222-3228. | |
| 7 | BROGNAUX S, DRUGMAN T. HMM-based speech segmentation: improvements of fully automatic approaches[J]. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 2016, 24(1): 5-15. |
| 8 | McAULIFFE M, SOCOLOF M, MIHUC S, et al. Montreal forced aligner: trainable text-speech alignment using Kaldi[C]// Proceedings of the INTERSPEECH 2017. [S.l.]: International Speech Communication Association, 2017: 498-502. |
| 9 | TEYTAUT Y, ROEBEL A. Phoneme-to-audio alignment with recurrent neural networks for speaking and singing voice[C]// Proceedings of the INTERSPEECH 2021. [S.l.]: International Speech Communication Association, 2021: 61-65. |
| 10 | LANDSIEDEL C, EDLUND J, EYBEN F, et al. Syllabification of conversational speech using bidirectional long-short-term memory neural networks [C]// Proceedings of the 2011 IEEE International Conference on Acoustics, Speech and Signal Processing. Piscataway: IEEE, 2011: 5256-5259. |
| 11 | PANDIA K, MURTHY H A. Acoustic unit discovery using transient and steady-state regions in speech and its applications[J]. Journal of Phonetics, 2021, 88: No.101081. |
| 12 | HYAFIL A, CERNAK M. Neuromorphic based oscillatory device for incremental syllable boundary detection[C]// Proceedings of the INTERSPEECH 2015. [S.l.]: International Speech Communication Association, 2015: 1191-1195. |
| 13 | KREUK F, SHEENA Y, KESHET J, et al. Phoneme boundary detection using learnable segmental features [C]// Proceedings of the 2020 IEEE International Conference on Acoustics, Speech and Signal Processing. Piscataway: IEEE, 2020: 8089-8093. |
| 14 | WANG D, NARAYANAN S S. Robust speech rate estimation for spontaneous speech[J]. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 2007, 15(8): 2190-2201. |
| 15 | SHANKAR R, VENKATARAMAN A. Weakly supervised syllable segmentation by vowel-consonant peak classification[C]// Proceedings of the INTERSPEECH 2019. [S.l.]: International Speech Communication Association, 2019: 644-648. |
| 16 | OBIN N, LAMARE F, ROEBEL A. Syll-O-Matic: an adaptive time-frequency representation for the automatic segmentation of speech into syllables[C]// Proceedings of the 2013 IEEE International Conference on Acoustics, Speech and Signal Processing. Piscataway: IEEE, 2013: 6699-6703. |
| 17 | RÄSÄNEN O, DOYLE G, FRANK M C. Pre-linguistic segmentation of speech into syllable-like units[J]. Cognition, 2018, 171: 130-150. |
| 18 | 李洺宇,金小峰. 朝鲜语语音音节自动切分算法的研究[J]. 延边大学学报(自然科学版), 2019, 45(2): 128-135. |
| LI M Y, JIN X F. Research on automatic segmentation algorithm of Korean speech syllable[J]. Journal of Yanbian University (Natural Science Edition), 2019, 45(2): 128-135. | |
| 19 | 王彤,易绵竹. 基于元音检测的俄语语音音节端点检测[J]. 郑州大学学报(理学版), 2017, 49(4):34-39. |
| WANG T, YI M Z. Syllable endpoint detection in Russian speech based on vowel segmentation[J]. Journal of Zhengzhou University (Natural Science Edition), 2017, 49(4):34-39. | |
| 20 | KUMARI R, DEV A, KUMAR A. An efficient syllable-based speech segmentation model using fuzzy and threshold-based boundary detection[J]. International Journal of Computational Intelligence and Applications, 2022, 21(2): No.2250007. |
| 21 | 李琦,张二华. 连续汉语语音的自动切分研究[J]. 计算机与数字工程, 2023, 51(4):959-964. |
| LI Q, ZHANG E H. Research on automatic segmentation of continuous Chinese speech[J]. Computer and Digital Engineering, 2023, 51(4):959-964. | |
| 22 | LALEYE F A A, EZIN E C, MOTAMED C. Automatic text-independent syllable segmentation using singularity exponents and Rényi entropy[J]. Journal of Signal Processing Systems, 2017, 88(3): 439-451. |
| 23 | LALEYE F A A, EZIN E C, MOTAMED C. Automatic boundary detection based on entropy measures for text-independent syllable segmentation[J]. Multimedia Tools and Applications, 2017, 76(15): 16347-16368. |
| 24 | HE S, ZHAO H. Automatic syllable segmentation algorithm of Chinese speech based on MF-DFA[J]. Speech Communication, 2017, 92: 42-51. |
| 25 | PANDA S P, NAYAK A K. Automatic speech segmentation in syllable centric speech recognition system[J]. International Journal of Speech Technology, 2016, 19(1): 9-18. |
| 26 | GEETHA K, VADIVEL R. Syllable segmentation of Tamil speech signals using vowel onset point and spectral transition measure [J]. Automatic Control and Computer Sciences, 2018, 52(1):25-31. |
| 27 | KARIM R M, SUYANTO. Optimizing parameters of automatic speech segmentation into syllable units[J]. International Journal of Intelligent Systems and Applications, 2019, 11(5):9-17. |
| 28 | 北京语言大学. 一种无监督的音频与文本自动对齐方法及装置: 202310855904.1[P]. 2023-11-07. |
| Beijing Language and Culture University. An unsupervised method and device for automatic alignment of audio and text: 202310855904.1[P]. 2023-11-07. | |
| 29 | 张雪,袁佩君,王莹,等. 知觉相关的神经振荡-外界节律同步化现象[J]. 生物化学与生物物理进展, 2016, 43(4):308-315. |
| ZHANG X, YUAN P J, WANG Y, et al. Neural entrainment and perception[J]. Progress in Biochemistry and Biophysics, 2016, 43(4):308-315. | |
| 30 | 端木三. 英汉音节分析及数量对比[J]. 语言科学, 2021, 20(6):561-588. |
| DUANMU S. Syllable analysis and syllable inventories in English and Chinese[J]. Linguistic Sciences, 2021, 20(6):561-588. | |
| 31 | MADDIESON I. Syllable structure[EB/OL]. [2024-03-15].. |
| 32 | WESTER M. Syllable classification using articulatory-acoustic features[C]// Proceedings of the 8th European Conference on Speech Communication and Technology. [S.l.]: International Speech Communication Association, 2003: 233-236. |
| 33 | Team HTK. Hidden Markov model toolkit[EB/OL]. [2024-03-15].. |
| 34 | MA N. An efficient implementation of gammatone filters [EB/OL]. [2024-03-19].. |
| 35 | GROSS J, HOOGENBOOM N, THUT G, et al. Speech rhythms and multiplexed oscillatory sensory coding in the human brain [J]. PLoS Biology, 2013, 11(12): No.e1001752. |
| 36 | HYAFIL A, FONTOLAN L, KABDEBON C, et al. Speech encoding by coupled cortical theta and gamma oscillations[J]. eLife, 2015, 4: No.e06213. |
| 37 | OBIN N. Cries and whispers classification of vocal effort in expressive speech[C]// Proceedings of the INTERSPEECH 2012. [S.l.]: International Speech Communication Association, 2012: 2234-2237. |
| 38 | GAROFOLO J S, LAMEL L F, FISHER W M, et al. TIMIT acoustic-phonetic continuous speech corpus[DS/OL]. [2024-02-17]. . |
| 39 | KOLOBOV R, OKHAPKINA O, OMELCHISHINA O, et al. MediaSpeech: multilanguage ASR benchmark and dataset[EB/OL]. [2024-03-18].. |
| 40 | WANG D, ZHANG X. THCHS-30: a free Chinese speech corpus[EB/OL]. [2024-03-20].. |
| [1] | 王向, 崔倩倩, 张晓明, 王建超, 王震洲, 宋佳霖. 改进ConvNeXt的无线胶囊内镜图像分类模型[J]. 《计算机应用》唯一官方网站, 2025, 45(6): 2016-2024. |
| [2] | 吴宗航, 张东, 李冠宇. 基于联合自监督学习的多模态融合推荐算法[J]. 《计算机应用》唯一官方网站, 2025, 45(6): 1858-1868. |
| [3] | 黄颖, 高胜美, 陈广, 刘苏. 结合信噪比引导的双分支结构和直方图均衡的低照度图像增强网络[J]. 《计算机应用》唯一官方网站, 2025, 45(6): 1971-1979. |
| [4] | 杨雅莉, 黎英, 章育涛, 宋佩华. 面向人脸识别的多模态研究方法综述[J]. 《计算机应用》唯一官方网站, 2025, 45(5): 1645-1657. |
| [5] | 周阳, 李辉. 基于语义和细节特征双促进的遥感影像建筑物提取网络[J]. 《计算机应用》唯一官方网站, 2025, 45(4): 1310-1316. |
| [6] | 郭诗月, 党建武, 王阳萍, 雍玖. 结合注意力机制和多尺度特征融合的三维手部姿态估计[J]. 《计算机应用》唯一官方网站, 2025, 45(4): 1293-1299. |
| [7] | 王一丁, 王泽浩, 李耀利, 蔡少青, 袁媛. 多尺度2D-Adaboost的中药材粉末显微图像识别算法[J]. 《计算机应用》唯一官方网站, 2025, 45(4): 1325-1332. |
| [8] | 周浩, 王超, 崔国恒, 罗廷金. 基于多语义关联与融合的视觉问答模型[J]. 《计算机应用》唯一官方网站, 2025, 45(3): 739-745. |
| [9] | 何秋润, 胡节, 彭博, 李天源. 基于上下文信息的多尺度特征融合织物疵点检测算法[J]. 《计算机应用》唯一官方网站, 2025, 45(2): 640-646. |
| [10] | 马汉达, 吴亚东. 多域时空层次图神经网络的空气质量预测[J]. 《计算机应用》唯一官方网站, 2025, 45(2): 444-452. |
| [11] | 张众维, 王俊, 刘树东, 王志恒. 多尺度特征融合与加权框融合的遥感图像目标检测[J]. 《计算机应用》唯一官方网站, 2025, 45(2): 633-639. |
| [12] | 李瑞, 李贯峰, 胡德洲, 高文馨. 融合路径与子图特征的知识图谱多跳推理模型[J]. 《计算机应用》唯一官方网站, 2025, 45(1): 32-39. |
| [13] | 宋鹏程, 郭立君, 张荣. 利用局部-全局时间依赖的弱监督视频异常检测[J]. 《计算机应用》唯一官方网站, 2025, 45(1): 240-246. |
| [14] | 刘赏, 周煜炜, 代娆, 董林芳, 刘猛. 融合注意力和上下文信息的遥感图像小目标检测算法[J]. 《计算机应用》唯一官方网站, 2025, 45(1): 292-300. |
| [15] | 潘烨新, 杨哲. 基于多级特征双向融合的小目标检测优化模型[J]. 《计算机应用》唯一官方网站, 2024, 44(9): 2871-2877. |
| 阅读次数 | ||||||
|
全文 |
|
|||||
|
摘要 |
|
|||||