


《计算机应用》唯一官方网站 ›› 2025, Vol. 45 ›› Issue (9): 2764-2772.DOI: 10.11772/j.issn.1001-9081.2024091262
• 人工智能 • 上一篇
殷兵1, 凌震华2, 林垠1,2( ), 奚昌凤1, 刘颖1
), 奚昌凤1, 刘颖1
收稿日期:2024-09-06
修回日期:2024-11-25
接受日期:2024-11-26
发布日期:2024-12-20
出版日期:2025-09-10
通讯作者:
林垠
作者简介:殷兵(1983—),女,山东枣庄人,高级工程师,博士,CCF会员,主要研究方向:计算机视觉、多模态感知基金资助:
Bing YIN1, Zhenhua LING2, Yin LIN1,2(), Changfeng XI1, Ying LIU1
Received:2024-09-06
Revised:2024-11-25
Accepted:2024-11-26
Online:2024-12-20
Published:2025-09-10
Contact:
Yin LIN
About author:YIN Bing, born in 1983, Ph. D., senior engineer. Her research interests include computer vision, multimodal perception.Supported by:摘要:
针对真实复杂场景下模态缺失带来的模型兼容性问题,提出一种支持任意模态输入的情感识别方法。首先,在预训练和精调阶段,采用模态随机丢弃的训练策略保证模型在推理阶段的兼容性;其次,分别提出时空掩码策略和基于跨模态注意力机制的特征融合机制,以减少模型过拟合的风险并优化模型跨模态特征融合的效果;最后,为了解决多种模态情感标签不一致带来的噪声标签问题,提出一种基于多原型聚类的自适应去噪策略,该策略为多种模态分别设置类中心,并通过对比每种模态特征对应的聚类类别与标签的一致性去除噪声标签。实验结果表明:在自建数据集上,所提方法相比基线AV-HuBERT(Audio-Visual Hidden unit Bidirectional Encoder Representation from Transformers)在加权平均召回率(WAR)指标上,模态对齐推理、视频缺失推理和音频缺失推理分别提升了6.98、4.09和33.05个百分点;在视频公开数据集DFEW上,相较于AV-HuBERT,所提方法取得了最高的WAR指标,达到了68.94%。
中图分类号:
殷兵, 凌震华, 林垠, 奚昌凤, 刘颖. 兼容缺失模态推理的情感识别方法[J]. 计算机应用, 2025, 45(9): 2764-2772.
Bing YIN, Zhenhua LING, Yin LIN, Changfeng XI, Ying LIU. Emotion recognition method compatible with missing modal reasoning[J]. Journal of Computer Applications, 2025, 45(9): 2764-2772.
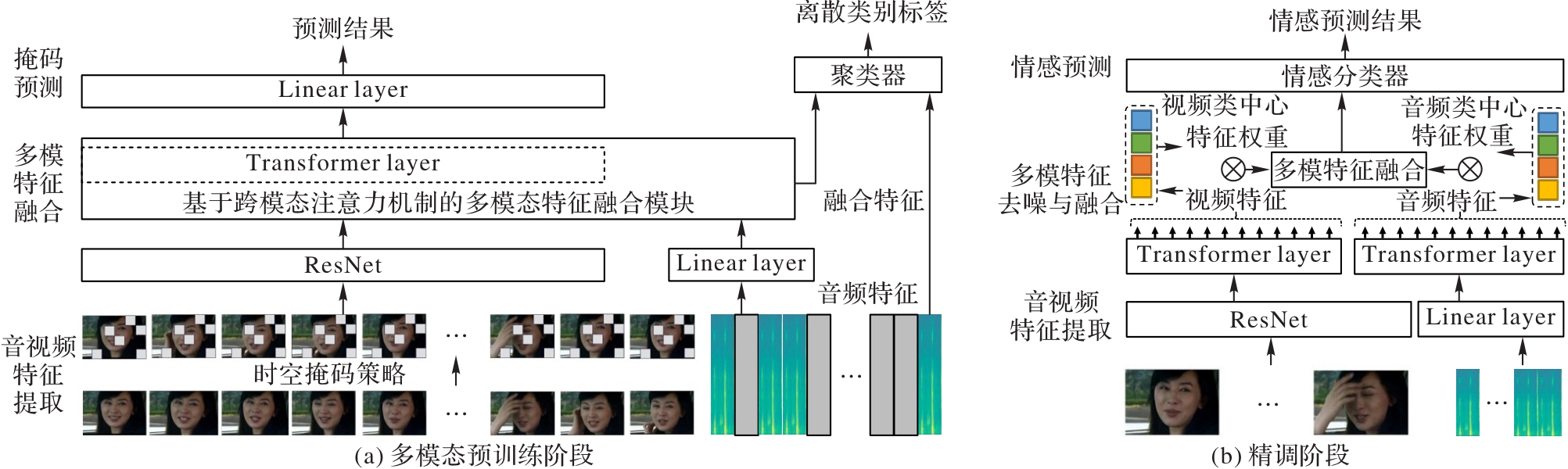
图1 本文方法的整体结构
Fig. 1 Overall structure of proposed method

图2 时空掩码策略的流程
Fig. 2 Flow of spatio-temporal masking strategy
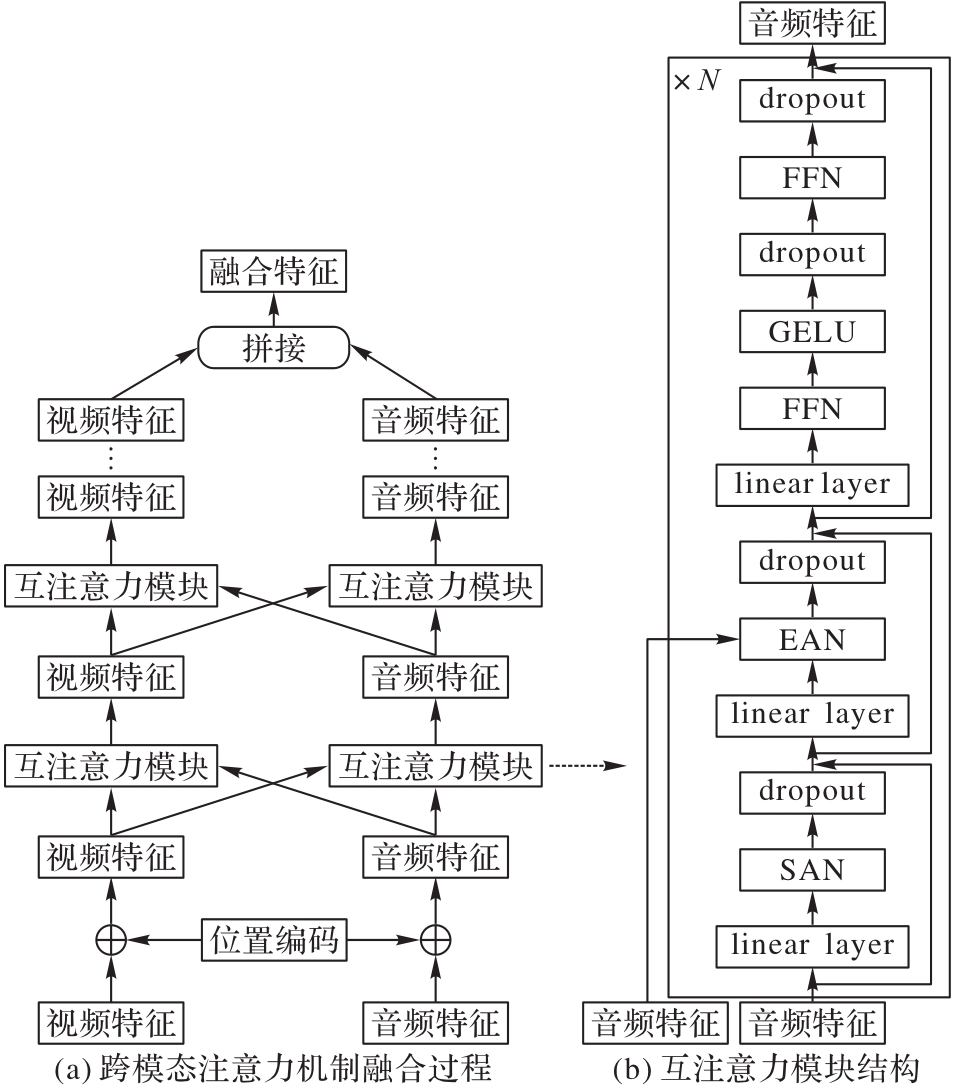
图3 多模态特征融合网络的结构
Fig. 3 Structure of multi-modal feature fusion network
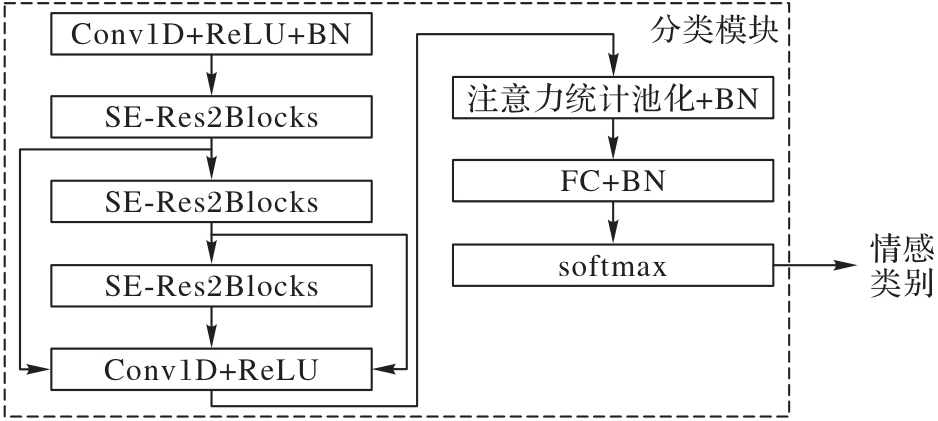
图4 情感分类模块的流程
Fig. 4 Flow of emotion classification module
| 模型 | 阶段 | 模态 | WAR | UAR | 召回率 | |||
|---|---|---|---|---|---|---|---|---|
| 悲伤 | 中性 | 生气 | 开心 | |||||
| AV-HuBERT-MA | 精调 | 音频-视频 | 93.11 | 92.52 | 89.24 | 93.83 | 89.13 | 97.90 |
| 推理 | 音频-视频 | |||||||
| 精调 | 音频 | 86.04 | 82.42 | 80.23 | 91.32 | 86.19 | 71.96 | |
| 推理 | 音频 | |||||||
| 精调 | 视频 | 90.28 | 87.75 | 79.06 | 93.37 | 82.25 | 96.31 | |
| 推理 | 视频 | |||||||
| 精调 | 音频-视频 | 84.40 | 80.88 | 83.76 | 90.83 | 84.88 | 64.06 | |
| 推理 | 音频 | |||||||
| 精调 | 音频-视频 | 89.24 | 86.78 | 81.41 | 94.02 | 75.63 | 96.05 | |
| 推理 | 视频 | |||||||
| AV-HuBERT-MAT | 精调 | 音频-视频 | 93.73 | 93.80 | 92.37 | 93.72 | 90.69 | 98.40 |
| 推理 | 音频-视频 | |||||||
| 精调 | 音频-视频 | 84.75 | 85.16 | 88.45 | 85.18 | 83.63 | 83.38 | |
| 推理 | 音频 | |||||||
| 精调 | 音频-视频 | 90.64 | 90.35 | 87.67 | 91.34 | 84.81 | 97.57 | |
| 推理 | 视频 | |||||||
表1 模态对齐以及模态缺失下不同模型情感识别效果的对比 (%)
Tab. 1 Comparison of emotion recognition performance with modal alignment or modal absence of different models
| 模型 | 阶段 | 模态 | WAR | UAR | 召回率 | |||
|---|---|---|---|---|---|---|---|---|
| 悲伤 | 中性 | 生气 | 开心 | |||||
| AV-HuBERT-MA | 精调 | 音频-视频 | 93.11 | 92.52 | 89.24 | 93.83 | 89.13 | 97.90 |
| 推理 | 音频-视频 | |||||||
| 精调 | 音频 | 86.04 | 82.42 | 80.23 | 91.32 | 86.19 | 71.96 | |
| 推理 | 音频 | |||||||
| 精调 | 视频 | 90.28 | 87.75 | 79.06 | 93.37 | 82.25 | 96.31 | |
| 推理 | 视频 | |||||||
| 精调 | 音频-视频 | 84.40 | 80.88 | 83.76 | 90.83 | 84.88 | 64.06 | |
| 推理 | 音频 | |||||||
| 精调 | 音频-视频 | 89.24 | 86.78 | 81.41 | 94.02 | 75.63 | 96.05 | |
| 推理 | 视频 | |||||||
| AV-HuBERT-MAT | 精调 | 音频-视频 | 93.73 | 93.80 | 92.37 | 93.72 | 90.69 | 98.40 |
| 推理 | 音频-视频 | |||||||
| 精调 | 音频-视频 | 84.75 | 85.16 | 88.45 | 85.18 | 83.63 | 83.38 | |
| 推理 | 音频 | |||||||
| 精调 | 音频-视频 | 90.64 | 90.35 | 87.67 | 91.34 | 84.81 | 97.57 | |
| 推理 | 视频 | |||||||
| 方法 | WAR | UAR |
|---|---|---|
| ResNet18+GRU[ | 64.02 | 51.68 |
| Former-DFER[ | 65.70 | 53.69 |
| 3DRes+Center Loss[ | 55.48 | 44.91 |
| EC-STFL[ | 56.51 | 45.35 |
| AV-HuBERT-MA | 68.94 | 57.09 |
表2 不同方法在DFEW单视频模态数据上的对比结果 (%)
Tab. 2 Comparison results of different methods on single video modal data of DFEW
| 方法 | WAR | UAR |
|---|---|---|
| ResNet18+GRU[ | 64.02 | 51.68 |
| Former-DFER[ | 65.70 | 53.69 |
| 3DRes+Center Loss[ | 55.48 | 44.91 |
| EC-STFL[ | 56.51 | 45.35 |
| AV-HuBERT-MA | 68.94 | 57.09 |
| 层数 | WAR/% | UAR/% | 召回率/% | |||
|---|---|---|---|---|---|---|
| 悲伤 | 中性 | 生气 | 开心 | |||
| 4 | 95.27 | 85.19 | 97.31 | |||
| 8 | 92.58 | 90.39 | 85.91 | 85.94 | 93.70 | |
| 12 | 84.83 | 80.04 | 73.19 | 91.48 | 80.44 | 75.06 |
| {2,4,6,8} | 93.66 | 91.68 | 86.89 | 96.65 | 87.06 | |
| {6,8,10,12} | 90.91 | 87.33 | 80.63 | 95.78 | 85.75 | 87.15 |
| {1,2,…,12} | 92.31 | 89.85 | 84.15 | 95.65 | 92.61 | |
表3 特征选取策略对情感识别性能的影响
Tab. 3 Influence of feature selection strategy on emotion recognition performance
| 层数 | WAR/% | UAR/% | 召回率/% | |||
|---|---|---|---|---|---|---|
| 悲伤 | 中性 | 生气 | 开心 | |||
| 4 | 95.27 | 85.19 | 97.31 | |||
| 8 | 92.58 | 90.39 | 85.91 | 85.94 | 93.70 | |
| 12 | 84.83 | 80.04 | 73.19 | 91.48 | 80.44 | 75.06 |
| {2,4,6,8} | 93.66 | 91.68 | 86.89 | 96.65 | 87.06 | |
| {6,8,10,12} | 90.91 | 87.33 | 80.63 | 95.78 | 85.75 | 87.15 |
| {1,2,…,12} | 92.31 | 89.85 | 84.15 | 95.65 | 92.61 | |
| 模型 | 阶段 | 模态 | WAR | UAR | 召回率 | |||
|---|---|---|---|---|---|---|---|---|
| 悲伤 | 中性 | 生气 | 开心 | |||||
| AV-HuBERT | 精调 | 音频-视频 | 86.75 | 85.42 | 84.51 | 89.83 | 79.69 | 87.66 |
| 推理 | 音频-视频 | |||||||
| 精调 | 音频-视频 | 80.66 | 81.02 | 81.41 | 80.42 | 79.13 | 83.12 | |
| 推理 | 音频 | |||||||
| 精调 | 音频-视频 | 57.59 | 63.94 | 80.63 | 54.43 | 41.19 | 79.51 | |
| 推理 | 视频 | |||||||
| AV-HuBERT-M | 精调 | 音频-视频 | 91.30 | 92.20 | 93.14 | 90.48 | 88.88 | 96.31 |
| 推理 | 音频-视频 | |||||||
| 精调 | 音频-视频 | 83.57 | 81.02 | 88.85 | 89.83 | 83.69 | 61.71 | |
| 推理 | 音频 | |||||||
| 精调 | 音频-视频 | 81.83 | 82.98 | 92.56 | 86.40 | 58.31 | 94.63 | |
| 推理 | 视频 | |||||||
| AV-HuBERT-MA | 精调 | 音频-视频 | 93.11 | 92.52 | 89.24 | 93.83 | 89.13 | 97.90 |
| 推理 | 音频-视频 | |||||||
| 精调 | 音频-视频 | 84.40 | 80.88 | 83.76 | 90.83 | 84.88 | 64.06 | |
| 推理 | 音频 | |||||||
| 精调 | 音频-视频 | 89.24 | 86.78 | 81.41 | 94.02 | 75.63 | 96.05 | |
| 推理 | 视频 | |||||||
| AV-HuBERT-MAT | 精调 | 音频-视频 | 93.73 | 93.80 | 92.37 | 93.72 | 90.69 | 98.40 |
| 推理 | 音频-视频 | |||||||
| 精调 | 音频-视频 | 84.75 | 85.16 | 88.45 | 85.18 | 83.63 | 83.38 | |
| 推理 | 音频 | |||||||
| 精调 | 音频-视频 | 90.64 | 90.35 | 87.67 | 91.34 | 84.81 | 97.57 | |
| 推理 | 视频 | |||||||
表4 在自建数据集上的消融实验结果 (%)
Tab. 4 Ablation study results on self-built dataset
| 模型 | 阶段 | 模态 | WAR | UAR | 召回率 | |||
|---|---|---|---|---|---|---|---|---|
| 悲伤 | 中性 | 生气 | 开心 | |||||
| AV-HuBERT | 精调 | 音频-视频 | 86.75 | 85.42 | 84.51 | 89.83 | 79.69 | 87.66 |
| 推理 | 音频-视频 | |||||||
| 精调 | 音频-视频 | 80.66 | 81.02 | 81.41 | 80.42 | 79.13 | 83.12 | |
| 推理 | 音频 | |||||||
| 精调 | 音频-视频 | 57.59 | 63.94 | 80.63 | 54.43 | 41.19 | 79.51 | |
| 推理 | 视频 | |||||||
| AV-HuBERT-M | 精调 | 音频-视频 | 91.30 | 92.20 | 93.14 | 90.48 | 88.88 | 96.31 |
| 推理 | 音频-视频 | |||||||
| 精调 | 音频-视频 | 83.57 | 81.02 | 88.85 | 89.83 | 83.69 | 61.71 | |
| 推理 | 音频 | |||||||
| 精调 | 音频-视频 | 81.83 | 82.98 | 92.56 | 86.40 | 58.31 | 94.63 | |
| 推理 | 视频 | |||||||
| AV-HuBERT-MA | 精调 | 音频-视频 | 93.11 | 92.52 | 89.24 | 93.83 | 89.13 | 97.90 |
| 推理 | 音频-视频 | |||||||
| 精调 | 音频-视频 | 84.40 | 80.88 | 83.76 | 90.83 | 84.88 | 64.06 | |
| 推理 | 音频 | |||||||
| 精调 | 音频-视频 | 89.24 | 86.78 | 81.41 | 94.02 | 75.63 | 96.05 | |
| 推理 | 视频 | |||||||
| AV-HuBERT-MAT | 精调 | 音频-视频 | 93.73 | 93.80 | 92.37 | 93.72 | 90.69 | 98.40 |
| 推理 | 音频-视频 | |||||||
| 精调 | 音频-视频 | 84.75 | 85.16 | 88.45 | 85.18 | 83.63 | 83.38 | |
| 推理 | 音频 | |||||||
| 精调 | 音频-视频 | 90.64 | 90.35 | 87.67 | 91.34 | 84.81 | 97.57 | |
| 推理 | 视频 | |||||||
| [1] | HE K, ZHANG X, REN S, et al. Deep residual learning for image recognition [C]// Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2016: 770-778. |
| [2] | CHUNG J, GULCEHRE C, CHO K, et al. Empirical evaluation of gated recurrent neural networks on sequence modeling [EB/OL]. [2024-07-11]. . |
| [3] | ZHAO Z, LIU Q. Former-DFER: dynamic facial expression recognition Transformer [C]// Proceedings of the 29th ACM International Conference on Multimedia. New York: ACM, 2021: 1553-1561. |
| [4] | HARA K, KATAOKA H, SATOH Y. Learning spatio-temporal features with 3D residual networks for action recognition [C]// Proceedings of the 2017 IEEE International Conference on Computer Vision Workshops. Piscataway: IEEE, 2017:3154-3160. |
| [5] | IQBAL M, SAMEEM M S I, NAQVI N, et al. A deep learning approach for face recognition based on angularly discriminative features [J]. Pattern Recognition Letters, 2019, 128: 414-419. |
| [6] | JIANG X, ZONG Y, ZHENG W, et al. DFEW: a large-scale database for recognizing dynamic facial expressions in the wild [C]// Proceedings of the 28th ACM International Conference on Multimedia. New York: ACM, 2020:2881-2889. |
| [7] | ZHANG S, ZHAO X, CHUANG Y, et al. Feature learning via deep belief network for Chinese speech emotion recognition [C]// Proceedings of the 2016 Chinese Conference on Pattern Recognition, CCIS 663. Singapore: Springer, 2016:645-651. |
| [8] | 陈婧,李海峰,马琳,等. 多粒度特征融合的维度语音情感识别方法[J]. 信号处理, 2017, 33(3):374-382. |
| CHEN J, LI H F, MA L, et al. Multi-granularity feature fusion for dimensional speech emotion recognition [J]. Journal of Signal Processing, 2017, 33(3): 374-382. | |
| [9] | AREZZO A, BERRETTI S. Speaker VGG CCT: cross-corpus speech emotion recognition with speaker embedding and Vision Transformers [C]// Proceedings of the 4th ACM International Conference on Multimedia in Asia. New York: ACM, 2022: No.7. |
| [10] | 龙英潮,丁美荣,林桂锦,等. 基于视听觉感知系统的多模态情感识别[J]. 计算机系统应用, 2021, 30(12):218-225. |
| LONG Y C, DING M R, LIN G J, et al. Emotion recognition based on visual and audiovisual perception system [J]. Computer Systems and Applications, 2021, 30(12):218-225. | |
| [11] | ZADEH A, CHEN M, PORIA S, et al. Tensor fusion network for multimodal sentiment analysis [C]// Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing. Stroudsburg: ACL, 2017: 1103-1114. |
| [12] | ZENG Z, TU J, PIANFETTI B, et al. Audio-visual affect recognition through multi-stream fused HMM for HCI [C]// Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition — Volume 2. Piscataway: IEEE, 2005: 967-972. |
| [13] | 刘菁菁,吴晓峰. 基于长短时记忆网络的多模态情感识别和空间标注[J]. 复旦学报(自然科学版), 2020, 59(5):565-574. |
| LIU J J, WU X F. Real-time multimodal emotion recognition and emotion space labeling using LSTM networks [J]. Journal of Fudan University (Natural Science), 2020, 59(5):565-574. | |
| [14] | 王传昱,李为相,陈震环. 基于语音和视频图像的多模态情感识别研究[J]. 计算机工程与应用, 2021, 57(23):163-170. |
| WANG C Y, LI W X, CHEN Z H. Research of multi-modal emotion recognition based on voice and video images [J]. Computer Engineering and Applications, 2021, 57(23):163-170. | |
| [15] | CHEN S, JIN Q. Multi-modal conditional attention fusion for dimensional emotion prediction [C]// Proceedings of the 24th ACM International Conference on Multimedia. New York: ACM, 2016:571-575. |
| [16] | HUANG J, TAO J, LIU B, et al. Multimodal Transformer fusion for continuous emotion recognition [C]// Proceedings of the 2020 IEEE International Conference on Acoustics, Speech and Signal Processing. Piscataway: IEEE, 2020: 3507-3511. |
| [17] | ZADEH A B, LIANG P P, PORIA S, et al. Multimodal language analysis in the wild: CMU-MOSEI dataset and interpretable dynamic fusion graph [C]// Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Stroudsburg: ACL, 2018: 2236-2246. |
| [18] | ALWASSEL H, MAHAJAN D, KORBAR B, et al. Self-supervised learning by cross-modal audio-video clustering [C]// Proceedings of the 34th International Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2020: 9758-9770. |
| [19] | ASANO Y M, PATRICK M, RUPPRECHT C, et al. Labelling unlabelled videos from scratch with multi-modal self-supervision[C]// Proceedings of the 34th International Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2020: 4660-4671. |
| [20] | SHI B, HSU W N, LAKHOTIA K, et al. Learning audio-visual speech representation by masked multimodal cluster prediction[EB/OL]. [2022-03-13]. . |
| [21] | AKBARI H, YUAN L, QIAN R, et al. VATT: Transformers for multimodal self-supervised learning from raw video, audio and text[C]// Proceedings of the 35th International Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2021: 24206-24221. |
| [22] | LIU J, ZHU X, LIU F, et al. OPT: omni-perception pre-trainer for cross-modal understanding and generation [EB/OL]. [2024-03-12].. |
| [23] | PARTHASARATHY S, SUNDARAM S. Training strategies to handle missing modalities for audio-visual expression recognition[C]// Companion Publication of the 2020 International Conference on Multimodal Interaction. New York: ACM, 2020: 400-404. |
| [24] | ZHAO J, LI R, JIN Q. Missing modality imagination network for emotion recognition with uncertain missing modalities [C]// Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers). Stroudsburg: ACL, 2021: 2608-2618. |
| [25] | DESPLANQUES B, THIENPONDT J, DEMUYNCK K. ECAPA-TDNN: emphasized channel attention, propagation and aggregation in TDNN based speaker verification [C]// Proceedings of the INTERSPEECH 2020. [S.l.]: International Speech Communication Association, 2020: 3830-3834. |
| [1] | 葛丽娜, 王明禹, 田蕾. 联邦学习的高效性研究综述[J]. 《计算机应用》唯一官方网站, 2025, 45(8): 2387-2398. |
| [2] | 彭鹏, 蔡子婷, 刘雯玲, 陈才华, 曾维, 黄宝来. 基于CNN和双向GRU混合孪生网络的语音情感识别方法[J]. 《计算机应用》唯一官方网站, 2025, 45(8): 2515-2521. |
| [3] | 张硕, 孙国凯, 庄园, 冯小雨, 王敬之. 面向区块链节点分析的eclipse攻击动态检测方法[J]. 《计算机应用》唯一官方网站, 2025, 45(8): 2428-2436. |
| [4] | 王祉苑, 彭涛, 杨捷. 分布外检测中训练与测试的内外数据整合[J]. 《计算机应用》唯一官方网站, 2025, 45(8): 2497-2506. |
| [5] | 杨青, 朱焱. 改进语言规则中的表示的隐喻识别[J]. 《计算机应用》唯一官方网站, 2025, 45(8): 2491-2496. |
| [6] | 廖炎华, 鄢元霞, 潘文林. 基于YOLOv9的交通路口图像的多目标检测算法[J]. 《计算机应用》唯一官方网站, 2025, 45(8): 2555-2565. |
| [7] | 张伟, 牛家祥, 马继超, 沈琼霞. 深层语义特征增强的ReLM中文拼写纠错模型[J]. 《计算机应用》唯一官方网站, 2025, 45(8): 2484-2490. |
| [8] | 索晋贤, 张丽萍, 闫盛, 王东奇, 张雅雯. 可解释的深度知识追踪方法综述[J]. 《计算机应用》唯一官方网站, 2025, 45(7): 2043-2055. |
| [9] | 王震洲, 郭方方, 宿景芳, 苏鹤, 王建超. 面向智能巡检的视觉模型鲁棒性优化方法[J]. 《计算机应用》唯一官方网站, 2025, 45(7): 2361-2368. |
| [10] | 齐巧玲, 王啸啸, 张茜茜, 汪鹏, 董永峰. 基于元学习的标签噪声自适应学习算法[J]. 《计算机应用》唯一官方网站, 2025, 45(7): 2113-2122. |
| [11] | 赵小阳, 许新征, 李仲年. 物联网应用中的可解释人工智能研究综述[J]. 《计算机应用》唯一官方网站, 2025, 45(7): 2169-2179. |
| [12] | 王艺涵, 路翀, 陈忠源. 跨模态文本信息增强的多模态情感分析模型[J]. 《计算机应用》唯一官方网站, 2025, 45(7): 2237-2244. |
| [13] | 花天辰, 马晓宁, 智慧. 基于浅层人工神经网络的可移植执行恶意软件静态检测模型[J]. 《计算机应用》唯一官方网站, 2025, 45(6): 1911-1921. |
| [14] | 吴宗航, 张东, 李冠宇. 基于联合自监督学习的多模态融合推荐算法[J]. 《计算机应用》唯一官方网站, 2025, 45(6): 1858-1868. |
| [15] | 李岚皓, 严皓钧, 周号益, 孙庆赟, 李建欣. 基于神经网络的多尺度信息融合时间序列长期预测模型[J]. 《计算机应用》唯一官方网站, 2025, 45(6): 1776-1783. |
| 阅读次数 | ||||||
|
全文 |
|
|||||
|
摘要 |
|
|||||