


《计算机应用》唯一官方网站 ›› 2022, Vol. 42 ›› Issue (2): 343-348.DOI: 10.11772/j.issn.1001-9081.2021071198
所属专题: 人工智能
李艳1,2,3( ), 郭劼1,2, 范斌1,2
), 郭劼1,2, 范斌1,2
收稿日期:2021-07-12
修回日期:2021-08-06
接受日期:2021-08-12
发布日期:2022-02-11
出版日期:2022-02-10
通讯作者:
李艳
作者简介:李艳(1976—),女,河北衡水人,教授,博士,CCF会员,主要研究方向:机器学习、不确定性信息处理;基金资助:
Yan LI1,2,3(), Jie GUO1,2, Bin FAN1,2
Received:2021-07-12
Revised:2021-08-06
Accepted:2021-08-12
Online:2022-02-11
Published:2022-02-10
Contact:
Yan LI
About author:LI Yan, born in 1976, Ph. D., professor. Her research interests include machine learning, uncertain information processing.Supported by:摘要:
元学习即应用机器学习的方法(元算法)寻求问题的特征(元特征)与算法相对性能测度间的映射,从而形成元知识的学习过程,如何构建和提取元特征是其重要的研究内容。针对目前相关研究所用到的元特征大部分是数据的统计特征的问题,提出不确定性建模并研究不确定性对于学习系统的影响。根据样本的不一致性、边界的复杂性、模型输出的不确定性、线性可分度、属性的重叠度以及特征空间的不确定性,建立了六种数据或模型的不确定性元特征;同时,从不同角度衡量学习问题本身的不确定性大小,并给出了具体的定义。在大量分类问题的人工数据和真实数据集上实验分析了这些元特征之间的相关性,并使用K最近邻(KNN)等多个分类算法对元特征与测试精度之间的相关度进行初步分析。结果表明相关度平均在0.8左右,可见这些元特征对学习性能具有显著影响。
中图分类号:
李艳, 郭劼, 范斌. 元学习的不确定性特征构建及初步分析[J]. 计算机应用, 2022, 42(2): 343-348.
Yan LI, Jie GUO, Bin FAN. Feature construction and preliminary analysis of uncertainty for meta-learning[J]. Journal of Computer Applications, 2022, 42(2): 343-348.
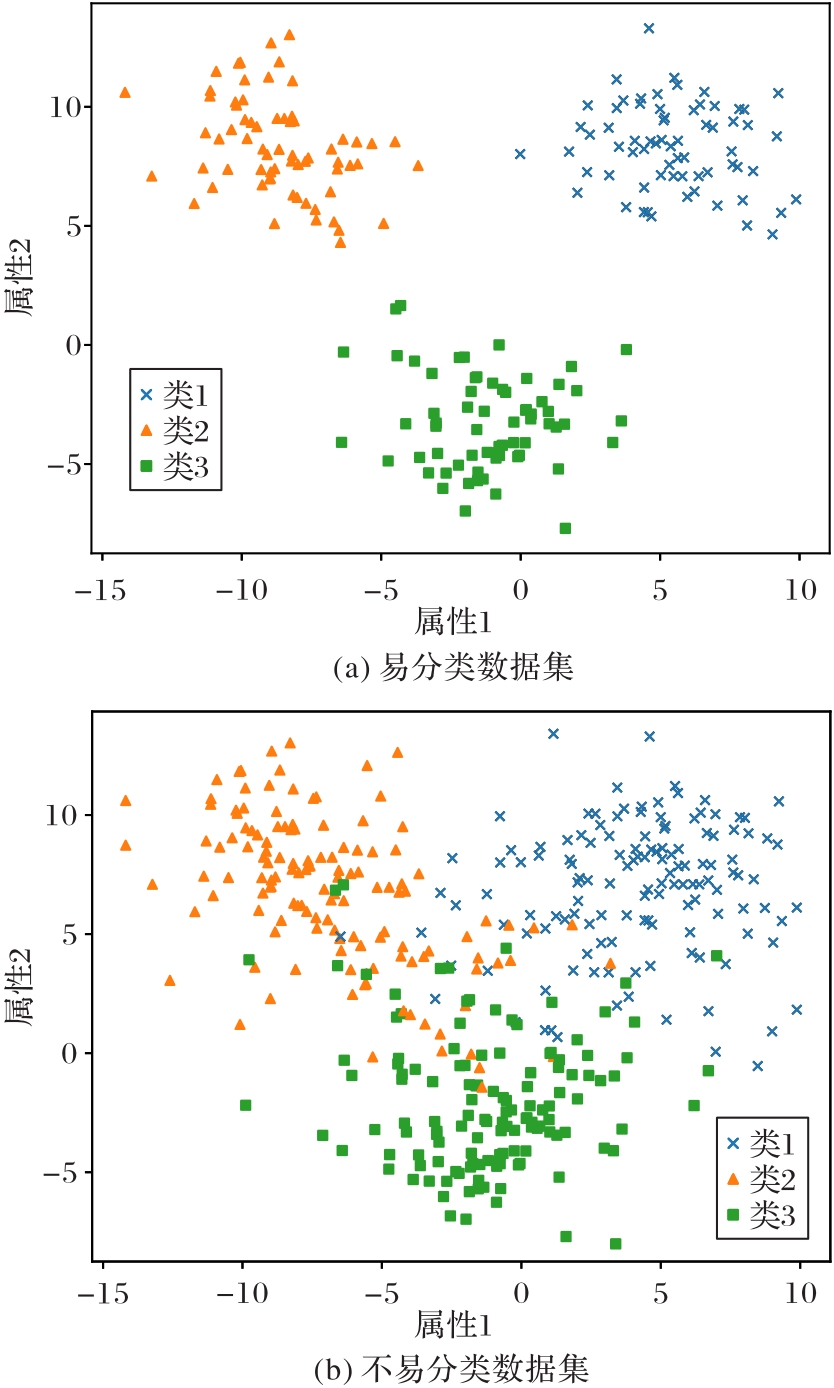
图1 不同参数生成的数据集
Fig. 1 Generated datasets with different parameters
| 数据集 | 不一致度 | 边界复杂度 | 输出不确定性 | 线性可分度 | 属性重叠度 | 特征空间不确定性 | 分类准确率 |
|---|---|---|---|---|---|---|---|
| 易分类数据集 | 0.020 | 0.040 | -0.015 | 0.998 | 0.130 | -0.190 | 0.998 |
| 不易分类数据集 | 0.257 | 0.214 | -0.414 | 0.778 | 0.416 | -0.534 | 0.808 |
表1 图1中两数据集的不确定性度量
Tab. 1 Uncertainty measures of easily and difficultly classified datasets
| 数据集 | 不一致度 | 边界复杂度 | 输出不确定性 | 线性可分度 | 属性重叠度 | 特征空间不确定性 | 分类准确率 |
|---|---|---|---|---|---|---|---|
| 易分类数据集 | 0.020 | 0.040 | -0.015 | 0.998 | 0.130 | -0.190 | 0.998 |
| 不易分类数据集 | 0.257 | 0.214 | -0.414 | 0.778 | 0.416 | -0.534 | 0.808 |
| 不确定性度量 | 与分类结果相关度 |
|---|---|
| 不一致度 | -0.70 |
| 边界复杂度 | -0.97 |
| 输出不确定性 | 0.97 |
| 线性分类准确率 | 0.69 |
| 属性重叠度 | -0.65 |
| 特征空间不确定性 | 0.72 |
表2 不确定性度量与平均分类结果的相关性
Tab. 2 Correlations between uncertainty measures and average classification results
| 不确定性度量 | 与分类结果相关度 |
|---|---|
| 不一致度 | -0.70 |
| 边界复杂度 | -0.97 |
| 输出不确定性 | 0.97 |
| 线性分类准确率 | 0.69 |
| 属性重叠度 | -0.65 |
| 特征空间不确定性 | 0.72 |
| 不确定性度量 | 边界 复杂度 | 输出 不确定性 | 线性分类准确率 | 属性值重叠度 | 特征空间不确定性 |
|---|---|---|---|---|---|
| 不一致度 | 0.72 | -0.71 | -0.40 | 0.39 | -0.54 |
| 边界复杂度 | — | -0.98 | -0.55 | 0.41 | -0.65 |
| 输出不确定性 | — | — | 0.56 | -0.42 | 0.65 |
| 线性分类准确率 | — | — | — | -0.37 | 0.49 |
| 属性值重叠度 | — | — | — | — | -0.44 |
表3 不确定性度量互相之间的相关性
Tab. 3 Correlations between uncertainty measures
| 不确定性度量 | 边界 复杂度 | 输出 不确定性 | 线性分类准确率 | 属性值重叠度 | 特征空间不确定性 |
|---|---|---|---|---|---|
| 不一致度 | 0.72 | -0.71 | -0.40 | 0.39 | -0.54 |
| 边界复杂度 | — | -0.98 | -0.55 | 0.41 | -0.65 |
| 输出不确定性 | — | — | 0.56 | -0.42 | 0.65 |
| 线性分类准确率 | — | — | — | -0.37 | 0.49 |
| 属性值重叠度 | — | — | — | — | -0.44 |
| 数据集 | Nsample | Ncat | Ncon | Nclass |
|---|---|---|---|---|
| banknote | 1 372 | 0 | 4 | 2 |
| breastcancer | 569 | 0 | 30 | 2 |
| iris | 150 | 0 | 4 | 3 |
| Contraceptive Method Choice | 1 473 | 7 | 2 | 3 |
| housing | 1 032 | 1 | 7 | 5 |
| blood | 748 | 0 | 4 | 2 |
| diabetes | 520 | 15 | 1 | 2 |
| fertility | 100 | 5 | 4 | 2 |
| wine | 178 | 0 | 13 | 3 |
| mammographic masses | 961 | 3 | 2 | 3 |
| abalone | 4 118 | 1 | 7 | 28 |
| planning rest | 182 | 0 | 13 | 2 |
| seeds | 210 | 0 | 7 | 3 |
| teaching assistant evaluation | 150 | 2 | 3 | 3 |
| wifi localization | 2 000 | 0 | 7 | 4 |
表4 真实数据集
Tab. 4 Real datasets
| 数据集 | Nsample | Ncat | Ncon | Nclass |
|---|---|---|---|---|
| banknote | 1 372 | 0 | 4 | 2 |
| breastcancer | 569 | 0 | 30 | 2 |
| iris | 150 | 0 | 4 | 3 |
| Contraceptive Method Choice | 1 473 | 7 | 2 | 3 |
| housing | 1 032 | 1 | 7 | 5 |
| blood | 748 | 0 | 4 | 2 |
| diabetes | 520 | 15 | 1 | 2 |
| fertility | 100 | 5 | 4 | 2 |
| wine | 178 | 0 | 13 | 3 |
| mammographic masses | 961 | 3 | 2 | 3 |
| abalone | 4 118 | 1 | 7 | 28 |
| planning rest | 182 | 0 | 13 | 2 |
| seeds | 210 | 0 | 7 | 3 |
| teaching assistant evaluation | 150 | 2 | 3 | 3 |
| wifi localization | 2 000 | 0 | 7 | 4 |
| 数据集 | 不一致度 | 边界复杂度 | 输出不确定性 | 线性可分度 | 属性重叠度 | 特征空间不确定性 | 分类准确率 |
|---|---|---|---|---|---|---|---|
| abalone | 0.415 | 0.483 | -0.717 | 0.284 | 0.537 | -0.746 | 0.335 |
| Contraceptive Method Choice | 0.284 | 0.303 | -0.701 | 0.522 | 0.413 | -0.498 | 0.582 |
| housing | 0.002 | 0.257 | -0.350 | 0.669 | 0.316 | -0.274 | 0.651 |
| mammographic_masses(原始) | 0.344 | 0.133 | -0.511 | 0.235 | 0.277 | -0.362 | 0.824 |
| mammographic_masses(noise) | 0.168 | 0.170 | -0.614 | 0.728 | 0.439 | -0.307 | 0.772 |
| teaching assistant evaluation | 0.319 | 0.245 | -0.760 | 0.576 | 0.440 | -0.529 | 0.543 |
| Blood(原始) | 0.107 | 0.166 | -0.605 | 0.762 | 0.271 | -0.415 | 0.803 |
| Blood(noise) | 0.187 | 0.207 | -0.455 | 0.712 | 0.379 | -0.392 | 0.745 |
| breastcancer | 0.110 | 0.019 | -0.162 | 0.996 | 0.109 | -0.088 | 0.967 |
| banknote(原始) | 0.000 | 0.001 | -0.008 | 0.988 | 0.202 | -0.138 | 0.999 |
| banknote(noise) | 0.095 | 0.069 | -0.214 | 0.863 | 0.331 | -0.363 | 0.883 |
| diabetes | 0.104 | 0.013 | -0.203 | 0.948 | 0.139 | -0.169 | 0.910 |
| iris(原始) | 0.013 | 0.040 | -0.100 | 0.980 | 0.046 | -0.563 | 0.980 |
| iris(noise) | 0.155 | 0.135 | -0.269 | 0.845 | 0.227 | -0.342 | 0.825 |
| fertility | 0.190 | 0.090 | -0.428 | 0.880 | 0.284 | -0.300 | 0.880 |
| planning rest | 0.280 | 0.176 | -0.505 | 0.714 | 0.373 | -0.325 | 0.714 |
| seeds | 0.229 | 0.024 | -0.166 | 0.976 | 0.231 | -0.254 | 0.929 |
| wifi localization(原始) | 0.000 | 0.008 | -0.539 | 0.988 | 0.445 | -0.273 | 0.982 |
| wifi localization(noise) | 0.130 | 0.122 | -0.257 | 0.890 | 0.144 | -0.176 | 0.848 |
| wine | 0.012 | 0.039 | -0.132 | 1.000 | 0.004 | -0.203 | 0.978 |
表5 真实数据集上的不确定性度量与分类准确率
Tab. 5 Uncertainty measures and classification results on real datasets
| 数据集 | 不一致度 | 边界复杂度 | 输出不确定性 | 线性可分度 | 属性重叠度 | 特征空间不确定性 | 分类准确率 |
|---|---|---|---|---|---|---|---|
| abalone | 0.415 | 0.483 | -0.717 | 0.284 | 0.537 | -0.746 | 0.335 |
| Contraceptive Method Choice | 0.284 | 0.303 | -0.701 | 0.522 | 0.413 | -0.498 | 0.582 |
| housing | 0.002 | 0.257 | -0.350 | 0.669 | 0.316 | -0.274 | 0.651 |
| mammographic_masses(原始) | 0.344 | 0.133 | -0.511 | 0.235 | 0.277 | -0.362 | 0.824 |
| mammographic_masses(noise) | 0.168 | 0.170 | -0.614 | 0.728 | 0.439 | -0.307 | 0.772 |
| teaching assistant evaluation | 0.319 | 0.245 | -0.760 | 0.576 | 0.440 | -0.529 | 0.543 |
| Blood(原始) | 0.107 | 0.166 | -0.605 | 0.762 | 0.271 | -0.415 | 0.803 |
| Blood(noise) | 0.187 | 0.207 | -0.455 | 0.712 | 0.379 | -0.392 | 0.745 |
| breastcancer | 0.110 | 0.019 | -0.162 | 0.996 | 0.109 | -0.088 | 0.967 |
| banknote(原始) | 0.000 | 0.001 | -0.008 | 0.988 | 0.202 | -0.138 | 0.999 |
| banknote(noise) | 0.095 | 0.069 | -0.214 | 0.863 | 0.331 | -0.363 | 0.883 |
| diabetes | 0.104 | 0.013 | -0.203 | 0.948 | 0.139 | -0.169 | 0.910 |
| iris(原始) | 0.013 | 0.040 | -0.100 | 0.980 | 0.046 | -0.563 | 0.980 |
| iris(noise) | 0.155 | 0.135 | -0.269 | 0.845 | 0.227 | -0.342 | 0.825 |
| fertility | 0.190 | 0.090 | -0.428 | 0.880 | 0.284 | -0.300 | 0.880 |
| planning rest | 0.280 | 0.176 | -0.505 | 0.714 | 0.373 | -0.325 | 0.714 |
| seeds | 0.229 | 0.024 | -0.166 | 0.976 | 0.231 | -0.254 | 0.929 |
| wifi localization(原始) | 0.000 | 0.008 | -0.539 | 0.988 | 0.445 | -0.273 | 0.982 |
| wifi localization(noise) | 0.130 | 0.122 | -0.257 | 0.890 | 0.144 | -0.176 | 0.848 |
| wine | 0.012 | 0.039 | -0.132 | 1.000 | 0.004 | -0.203 | 0.978 |
| 不确定性度量 | 与分类结果的相关度 |
|---|---|
| 不一致度 | -0.717 |
| 输出的不确定性 | 0.975 |
| 边界复杂度 | 0.871 |
| 线性可分度 | 0.752 |
| 属性重叠度 | -0.723 |
| 特征空间不确定性 | 0.720 |
表6 真实数据集上的不确定性度量与分类准确率的相关度
Tab. 6 Correlation between uncertainty measures and classification accuracy on real datasets
| 不确定性度量 | 与分类结果的相关度 |
|---|---|
| 不一致度 | -0.717 |
| 输出的不确定性 | 0.975 |
| 边界复杂度 | 0.871 |
| 线性可分度 | 0.752 |
| 属性重叠度 | -0.723 |
| 特征空间不确定性 | 0.720 |
| 1 | 曾子林,张宏军,张睿,等.基于元学习思想的算法选择问题综述[J].控制与决策, 2014, 29(6): 961-968. 10.13195/j.kzyjc.2013.1297 |
| ZENG Z L, ZHANG H J, ZHANG R, et al. Summary of algorithm selection problem based on meta-learning[J]. Control and Decision, 2014, 29(6): 961-968. 10.13195/j.kzyjc.2013.1297 | |
| 2 | AHA D W. Generalizing from case studies: a case study[M]// Machine Learning Proceedings 1992. San Francisco: Morgan Kaufmann, 1992: 1-10. 10.1016/b978-1-55860-247-2.50006-1 |
| 3 | TATTI N. Distances between data sets based on summary statistics[J]. Journal of Machine Learning Research, 2007, 8: 131-154. |
| 4 | GNANADESIKAN R. Methods for Statistical Data Analysis of Multivariate Observations[M]. 2nd ed. New York: Wiley & Sons, Inc., 1997: 139-220. 10.1002/9781118032671 |
| 5 | HO T K, BASU M. Complexity measures of supervised classification problems[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2002, 24(3): 289-300. 10.1109/34.990132 |
| 6 | BASU M, HO T K. Data Complexity in Pattern Recognition[M]. London: Springer, 2006: 48-66. |
| 7 | MACIÀ N, BERNADÓ-MANSILLA E, ORRIOLS-PUIG A, et al. Learner excellence biased by data set selection: a case for data characterisation and artificial data sets[J]. Pattern Recognition, 2013, 46(3): 1054-1066. 10.1016/j.patcog.2012.09.022 |
| 8 | BERNHARD P, HILAN B. Meta-learning by landmarking various learning algorithms [C]// Proceedings of the 17th International Conference on Machine Learning. San Francisco: Morgan Kaufmann, 2000: 743-750. |
| 9 | WU X D, KUMAR V, QUINLAN J R, et al. Top 10 algorithms in data mining[J]. Knowledge and Information Systems, 2008, 14(1): 1-37. 10.1007/s10115-007-0114-2 |
| 10 | SUN M X, LIU K H, WU Q Q, et al. A novel ECOC algorithm for multiclass microarray data classification based on data complexity analysis[J]. Pattern Recognition, 2019, 90: 346-362. 10.1016/j.patcog.2019.01.047 |
| 11 | VILALTA R, DRISSI Y. A perspective view and survey of meta-learning[J]. Artificial Intelligence Review, 2002, 18(2): 77-95. 10.1023/a:1019956318069 |
| 12 | GIRAUD-CARRIER C, VILALTA R, BRAZDIL P. Introduction to the special issue on meta-learning[J] Machine Learning, 2004, 54(3): 187-193. 10.1023/b:mach.0000015878.60765.42 |
| 13 | BRAZDIL P, GIRAUD-CARRIER C. Metalearning and algorithm selection: progress, state of the art and introduction to the 2018 special issue[J] Machine Learning, 2018, 107(1): 1-14. 10.1007/s10994-017-5692-y |
| 14 | SMITH M R, MARTINEZ T, GIRAUD-CARRIER C. An instance level analysis of data complexity[J]. Machine Learning, 2014, 95(2): 225-256. 10.1007/s10994-013-5422-z |
| 15 | HO T K. A data complexity analysis of comparative advantages of decision forest constructors[J]. Pattern Analysis and Applications, 2002, 5(2): 102-112. 10.1007/s100440200009 |
| 16 | BRODLEY C E. Recursive automatic bias selection for classifier construction[J]. Machine Learning, 1995, 20(1/2): 63-94. 10.1007/bf00993475 |
| 17 | SCHAFFER C. Technical Note: selecting a classification method by cross-validation[J]. Machine Learning, 1993, 13(1): 135-143. 10.1007/bf00993106 |
| 18 | GARCÍA S, LUENGO J, HERRERA F. Tutorial on practical tips of the most influential data preprocessing algorithms in data mining[J]. Knowledge-Based Systems, 2016, 98: 1-29. 10.1016/j.knosys.2015.12.006 |
| 19 | XU X Z, LIANG T M, ZHU J, et al. Review of classical dimensionality reduction and sample selection methods for large-scale data processing[J]. Neurocomputing, 2019, 328: 5-15. 10.1016/j.neucom.2018.02.100 |
| 20 | WANG X Z, XING H J, LI Y, et al. A study on relationship between generalization abilities and fuzziness of base classifiers in ensemble learning[J]. IEEE Transactions on Fuzzy Systems, 2015, 23(5): 1638-1654. 10.1109/tfuzz.2014.2371479 |
| 21 | SÁEZ J A, LUENGO J, HERRERA F. Predicting noise filtering efficacy with data complexity measures for nearest neighbor classification[J]. Pattern Recognition, 2013, 46(1): 355-364. 10.1016/j.patcog.2012.07.009 |
| 22 | LUENGO J, FERNÁNDEZ A, GARCÍA S, et al. Addressing data complexity for imbalanced data sets: analysis of SMOTE-based oversampling and evolutionary undersampling[J]. Soft Computing, 2011, 15(10): 1909-1936. 10.1007/s00500-010-0625-8 |
| 23 | SÁNCHEZ J S, MOLLINEDA R A, SOTOCA J M. An analysis of how training data complexity affects the nearest neighbor classifiers[J]. Pattern Analysis and Applications, 2007, 10(3): 189-201. 10.1007/s10044-007-0061-2 |
| 24 | CANO J R. Analysis of data complexity measures for classification[J]. Expert Systems with Applications, 2013, 40(12): 4820-4831. 10.1016/j.eswa.2013.02.025 |
| 25 | BRUN A L, BRITTO A S, OLIVEIRA L S, et al. Contribution of data complexity features on dynamic classifier selection [C]// Proceedings of the 2016 International Joint Conference on Neural Networks. Piscataway: IEEE, 2016: 4396-4403. 10.1109/ijcnn.2016.7727774 |
| 26 | LIU B D. Uncertainty Theory (Studies in Fuzziness and Soft Computing)[M]. 2nd ed. Berlin: Springer, 2007: 205-234. |
| 27 | LAI H L, ZHANG D X. Fuzzy preorder and fuzzy topology[J]. Fuzzy Sets and Systems, 2006, 157(14): 1865-1885. 10.1016/j.fss.2006.02.013 |
| 28 | PAL M. Random forest classifier for remote sensing classification[J]. International Journal of Remote Sensing, 2005, 26(1): 217-222. 10.1080/01431160412331269698 |
| 29 | WANG X Z, WANG R, XU C. Discovering the relationship between generalization and uncertainty by incorporating complexity of classification[J]. IEEE Transactions on Cybernetics, 2017, 48(2): 703-715. 10.1109/tcyb.2017.2653223 |
| 30 | SHARMA A, SINGH S K. Early classification of time series based on uncertainty measure [C]// Proceedings of the 2019 IEEE Conference on Information and Communication Technology. Piscataway: IEEE, 2019: 1-6. 10.1109/cict48419.2019.9066213 |
| 31 | SUN L, ZHANG X, QIAN Y, et al. Feature selection using neighborhood entropy-based uncertainty measures for gene expression data classification[J]. Information Sciences, 2019, 502: 18-41. 10.1016/j.ins.2019.05.072 |
| 32 | XIAO F. A distance measure for intuitionistic fuzzy sets and its application to pattern classification problems[J]. IEEE Transactions on Systems, Man, and Cybernetics: Systems, 2019, 51(6): 3980-3992. 10.1109/TSMC.2019.2958635 |
| 33 | DE WAAL A, STEYN C. Uncertainty measurements in neural network predictions for classification tasks [C]// Proceedings of the IEEE 23rd International Conference on Information Fusion. Piscataway: IEEE, 2020: 1-7. 10.23919/fusion45008.2020.9190221 |
| [1] | 黄云川, 江永全, 黄骏涛, 杨燕. 基于元图同构网络的分子毒性预测[J]. 《计算机应用》唯一官方网站, 2024, 44(9): 2964-2969. |
| [2] | 时旺军, 王晶, 宁晓军, 林友芳. 小样本场景下的元迁移学习睡眠分期模型[J]. 《计算机应用》唯一官方网站, 2024, 44(5): 1445-1451. |
| [3] | 吴郅昊, 迟子秋, 肖婷, 王喆. 基于元学习自适应的小样本语音合成[J]. 《计算机应用》唯一官方网站, 2024, 44(5): 1629-1635. |
| [4] | 黄雨鑫, 黄贻望, 黄辉. 基于浅层网络预测的元标签校正方法[J]. 《计算机应用》唯一官方网站, 2024, 44(11): 3364-3370. |
| [5] | 周晓敏, 滕飞, 张艺. 基于元网络的自动国际疾病分类编码模型[J]. 《计算机应用》唯一官方网站, 2023, 43(9): 2721-2726. |
| [6] | 王辉, 李建红. 基于Transformer的三维模型小样本识别方法[J]. 《计算机应用》唯一官方网站, 2023, 43(6): 1750-1758. |
| [7] | 蔡淳豪, 李建良. 小样本问题下培训弱教师网络的模型蒸馏模型[J]. 《计算机应用》唯一官方网站, 2022, 42(9): 2652-2658. |
| [8] | 韩亚茹, 闫连山, 姚涛. 基于元学习的深度哈希检索算法[J]. 《计算机应用》唯一官方网站, 2022, 42(7): 2015-2021. |
| [9] | 许仁杰, 刘宝弟, 张凯, 刘伟锋. 基于贝叶斯权函数的模型无关元学习算法[J]. 《计算机应用》唯一官方网站, 2022, 42(3): 708-712. |
| [10] | 谢鑫, 张贤勇, 王旋晔, 唐鹏飞. 变精度邻域等价粒的邻域决策树构造算法[J]. 《计算机应用》唯一官方网站, 2022, 42(2): 382-388. |
| [11] | 林润超, 黄荣, 董爱华. 基于注意力机制和元特征二次重加权的小样本目标检测[J]. 《计算机应用》唯一官方网站, 2022, 42(10): 3025-3032. |
| [12] | 魏淳武, 赵涓涓, 唐笑先, 强彦. 基于多时期蒸馏网络的随访数据知识提取方法[J]. 计算机应用, 2021, 41(10): 2871-2878. |
| [13] | 王磊. 改进粗糙集属性约简结合K-means聚类的网络入侵检测方法[J]. 计算机应用, 2020, 40(7): 1996-2002. |
| [14] | 曹堉, 王成, 王鑫, 高悦尔. 基于时空节点选择和深度学习的城市道路短时交通流预测[J]. 计算机应用, 2020, 40(5): 1488-1493. |
| [15] | 孙忠凡, 周正华, 赵建伟. 基于空间元学习的放大任意倍的超分辨率重建方法[J]. 计算机应用, 2020, 40(12): 3471-3477. |
| 阅读次数 | ||||||
|
全文 |
|
|||||
|
摘要 |
|
|||||