


《计算机应用》唯一官方网站 ›› 2025, Vol. 45 ›› Issue (4): 1069-1076.DOI: 10.11772/j.issn.1001-9081.2024040525
张李伟1,2, 梁泉1,2( ), 胡禹涛1,2, 朱乔乐1,2
), 胡禹涛1,2, 朱乔乐1,2
收稿日期:2024-04-28
修回日期:2024-08-05
接受日期:2024-08-08
发布日期:2025-04-08
出版日期:2025-04-10
通讯作者:
梁泉
作者简介:张李伟(2000—),男,湖北阳新人,硕士研究生,主要研究方向:目标检测基金资助:
Liwei ZHANG1,2, Quan LIANG1,2(), Yutao HU1,2, Qiaole ZHU1,2
Received:2024-04-28
Revised:2024-08-05
Accepted:2024-08-08
Online:2025-04-08
Published:2025-04-10
Contact:
Quan LIANG
About author:ZHANG Liwei, born in 2000, M. S. candidate. His research interests include object detection.Supported by:摘要:
注意力机制的引入使得主干网能够学习更具区分性的特征表示。然而,为了控制注意力的复杂度,传统的注意力机制采用的通道降维或减少通道数而增加批量大小的策略会导致过度减少通道数和损失重要特征信息的问题。为解决这一问题,提出通道重洗注意力(CSA)模块。首先,利用分组卷积学习注意力权重,以控制CSA的复杂度;其次,通过传统通道重洗和深层通道重洗(DCS)方法,增强不同组间的通道特征信息交流;再次,使用逆通道重洗恢复注意力权重的顺序;最后,将恢复后的注意力权重与原始特征图相乘,以获得更具表达能力的特征图。实验结果表明,在CIFAR-100数据集上,与添加CA(Coordinate Attention)的ResNet50相比,添加CSA的ResNet50的参数量降低了2.3%,Top-1准确率提升了0.57个百分点;与添加EMA(Efficient Multi-scale Attention)的ResNet50相比,添加CSA的ResNet50的计算量降低了18.4%,Top-1准确率提升了0.27个百分点。在COCO2017数据集上,添加CSA的YOLOv5s比添加CA和EMA的YOLOv5s在平均精度均值(mAP@50)上分别提升了0.5和0.2个百分点。可见,CSA达到了参数量和计算量的平衡,并能够同时提升图像分类任务的准确率和目标检测任务的定位能力。
中图分类号:
张李伟, 梁泉, 胡禹涛, 朱乔乐. 基于分组卷积的通道重洗注意力机制[J]. 计算机应用, 2025, 45(4): 1069-1076.
Liwei ZHANG, Quan LIANG, Yutao HU, Qiaole ZHU. Channel shuffle attention mechanism based on group convolution[J]. Journal of Computer Applications, 2025, 45(4): 1069-1076.
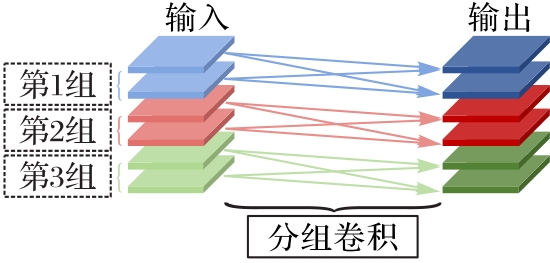
图1 分成3组的分组卷积操作
Fig. 1 Group convolution operation of dividing into three groups
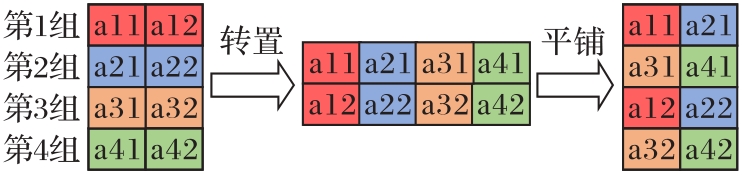
图2 m>n的通道重洗流程
Fig. 2 Channel shuffle flow of m>n
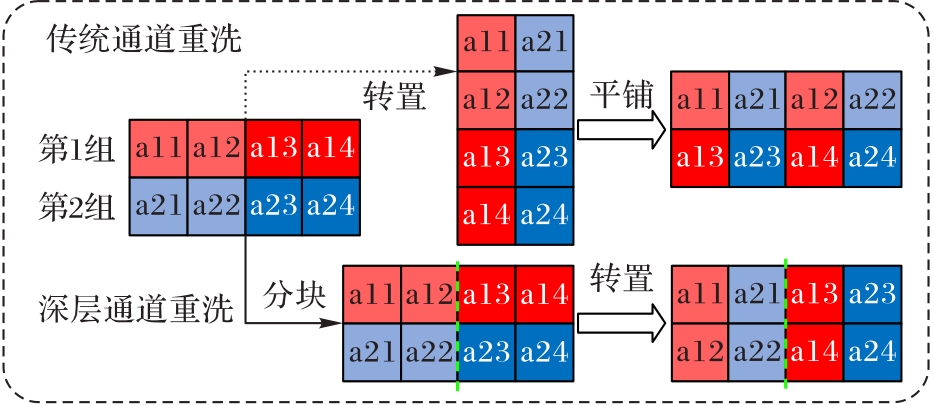
图3 传统通道重洗与深层通道重洗的流程
Fig. 3 Flows of traditional channel shuffle and deep channel shuffle
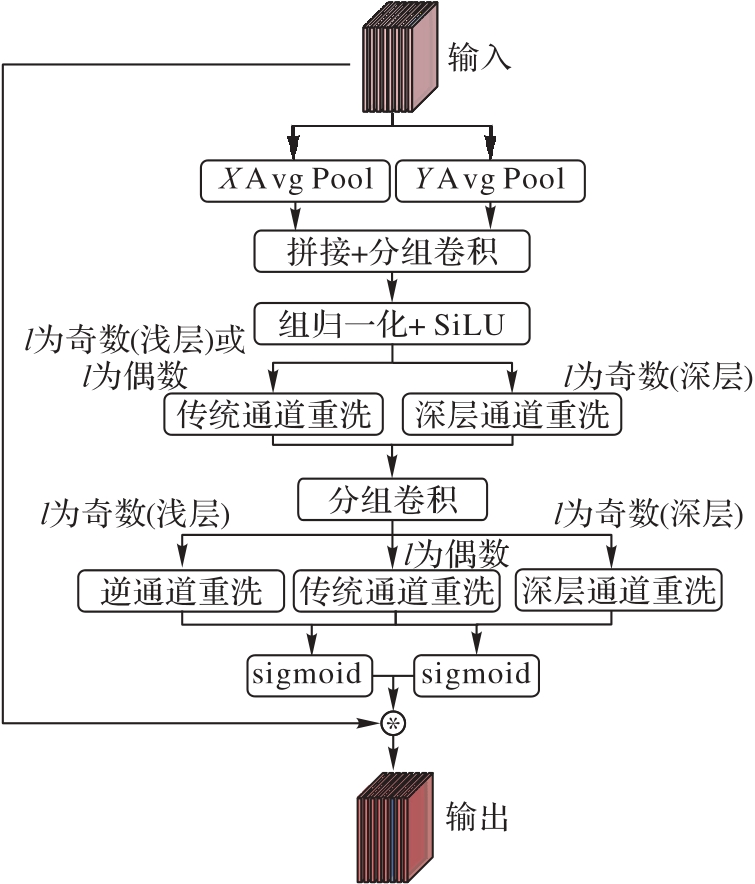
图4 CSA模块结构
Fig. 4 CSA module structure

图5 在CIFAR-100和COCO2017数据集上的实验结果对比
Fig. 5 Comparison of experimental results on CIFAR-100 and COCO2017 datasets
| 模型 | 参数量/ | 计算量/GFLOPs | Top-1/% | Top-5/% |
|---|---|---|---|---|
| ResNet50 | 23.71 | 1.31 | 77.26 | 93.63 |
| +SE[ | 26.22 | 1.32 | 79.91+2.65 | 95.04+1.41 |
| +NAM[ | 23.71 | 1.31 | 78.89+1.63 | 95.09+1.46 |
| +SA[ | 23.71 | 1.31 | 79.92+2.66 | 95.00+1.37 |
| +CA[ | 25.62 | 1.33 | 79.91+2.65 | 95.23+1.60 |
| +EMA[ | 23.90 | 1.63 | 80.21+2.95 | 95.10+1.47 |
| +CSA | 25.04 | 1.33 | 80.48+3.22 | 95.19+1.56 |
表1 CIFAR-100数据集上不同注意力机制的对比结果
Tab. 1 Comparison results of different attention mechanisms on CIFAR-100 dataset
| 模型 | 参数量/ | 计算量/GFLOPs | Top-1/% | Top-5/% |
|---|---|---|---|---|
| ResNet50 | 23.71 | 1.31 | 77.26 | 93.63 |
| +SE[ | 26.22 | 1.32 | 79.91+2.65 | 95.04+1.41 |
| +NAM[ | 23.71 | 1.31 | 78.89+1.63 | 95.09+1.46 |
| +SA[ | 23.71 | 1.31 | 79.92+2.66 | 95.00+1.37 |
| +CA[ | 25.62 | 1.33 | 79.91+2.65 | 95.23+1.60 |
| +EMA[ | 23.90 | 1.63 | 80.21+2.95 | 95.10+1.47 |
| +CSA | 25.04 | 1.33 | 80.48+3.22 | 95.19+1.56 |
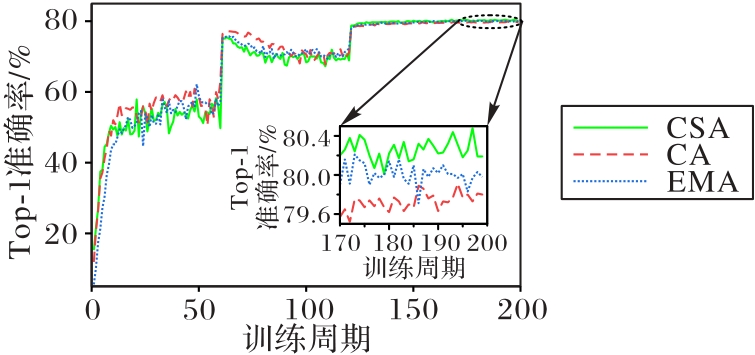
图6 ResNet50添加CA、EMA和CSA的训练过程对比
Fig. 6 Comparison of training processes for ResNet50 adding CA, EMA, and CSA
| 模型 | 参数量/ | 计算量/ GFLOPs | mAP@50/% | mAP@50:95/% |
|---|---|---|---|---|
| YOLOv5s(v6.0) | 7.24 | 16.6 | 56.0 | 37.2 |
| +CBAM | 7.56 | 16.9 | 57.1+1.1 | 37.7+0.5 |
| +SA | 7.24 | 16.6 | 56.8+0.8 | 37.4+0.2 |
| +CA | 7.27 | 16.7 | 57.5+1.5 | 38.1+0.9 |
| +EMA | 7.24 | 16.8 | 57.8+1.8 | 38.4+1.2 |
| +CSA | 7.28 | 16.7 | 58.0+2.0 | 38.0+0.8 |
表2 COCO2017数据集上不同注意力机制的对比结果
Tab. 2 Comparison results of different attention mechanisms on COCO2017 dataset
| 模型 | 参数量/ | 计算量/ GFLOPs | mAP@50/% | mAP@50:95/% |
|---|---|---|---|---|
| YOLOv5s(v6.0) | 7.24 | 16.6 | 56.0 | 37.2 |
| +CBAM | 7.56 | 16.9 | 57.1+1.1 | 37.7+0.5 |
| +SA | 7.24 | 16.6 | 56.8+0.8 | 37.4+0.2 |
| +CA | 7.27 | 16.7 | 57.5+1.5 | 38.1+0.9 |
| +EMA | 7.24 | 16.8 | 57.8+1.8 | 38.4+1.2 |
| +CSA | 7.28 | 16.7 | 58.0+2.0 | 38.0+0.8 |
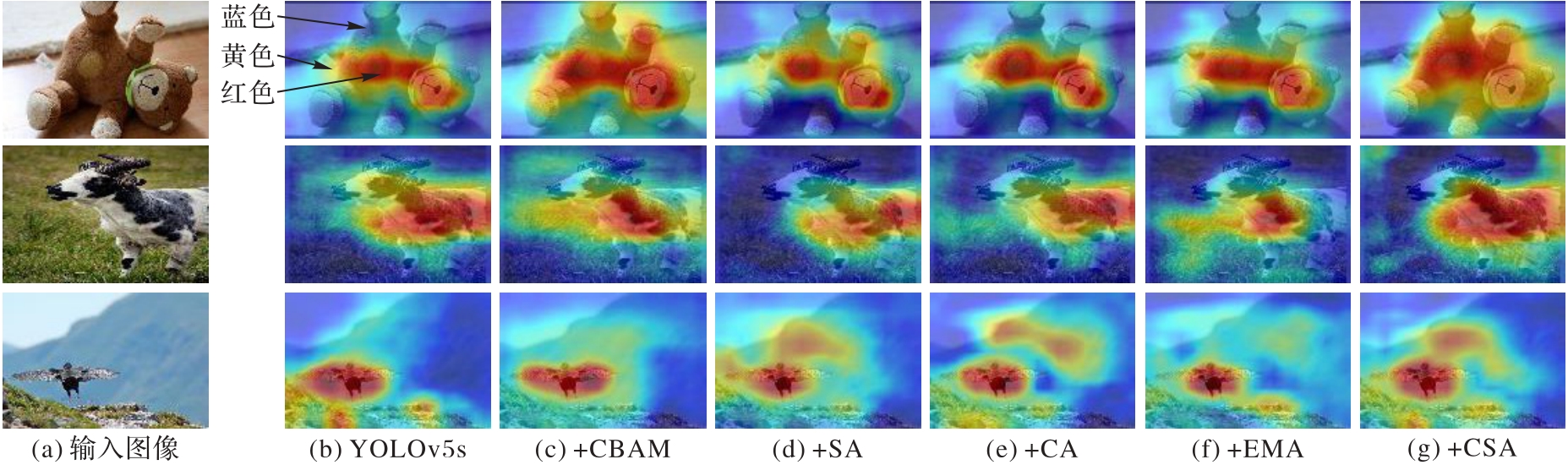
图7 单物体检测结果的可视化
Fig. 7 Visualization of single object detection results
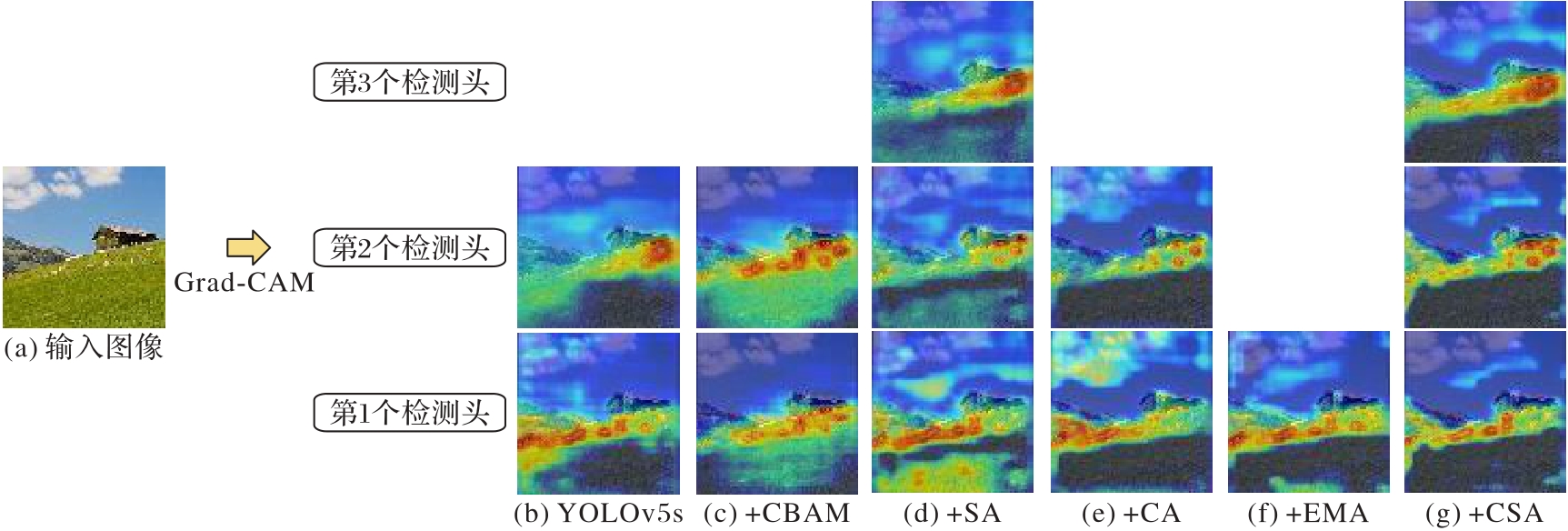
图8 多物体检测结果的可视化
Fig. 8 Visualization of multi-object detection results
| 模型 | 参数量/ | 计算量/GFLOPs | mAP@50/% | mAP@50:95/% |
|---|---|---|---|---|
| YOLOv8s | 11.17 | 28.8 | 95.4 | 65.8 |
| +SE | 11.19 | 28.8 | 95.4 | 65.9 |
| +CBAM | 11.38 | 29.0 | 95.6 | 66.2 |
| +CA | 11.20 | 28.9 | 95.3 | 66.0 |
| +EMA | 11.17 | 29.0 | 95.2 | 66.0 |
| +CSA | 11.20 | 28.9 | 95.5 | 66.3 |
表3 SHWD数据集上不同注意力机制的对比结果
Tab. 3 Comparison results of different attention mechanisms on SHWD dataset
| 模型 | 参数量/ | 计算量/GFLOPs | mAP@50/% | mAP@50:95/% |
|---|---|---|---|---|
| YOLOv8s | 11.17 | 28.8 | 95.4 | 65.8 |
| +SE | 11.19 | 28.8 | 95.4 | 65.9 |
| +CBAM | 11.38 | 29.0 | 95.6 | 66.2 |
| +CA | 11.20 | 28.9 | 95.3 | 66.0 |
| +EMA | 11.17 | 29.0 | 95.2 | 66.0 |
| +CSA | 11.20 | 28.9 | 95.5 | 66.3 |
| 模型 | 参数量/ | 计算量/GFLOPs | 帧率/(frame·s-1) |
|---|---|---|---|
| YOLOv5s+CA | 7.27 | 16.7 | 232 |
| YOLOv5s+EMA | 7.24 | 16.8 | 227 |
| YOLOv5s+CSA | 7.28 | 16.7 | 243 |
| YOLOv8s+CA | 11.20 | 28.9 | 215 |
| YOLOv8s+EMA | 11.17 | 29.0 | 178 |
| YOLOv8s+CSA | 11.20 | 28.9 | 238 |
表4 3种注意力的复杂度和速度比较
Tab. 4 Comparison of complexity and speeds among three types of attention
| 模型 | 参数量/ | 计算量/GFLOPs | 帧率/(frame·s-1) |
|---|---|---|---|
| YOLOv5s+CA | 7.27 | 16.7 | 232 |
| YOLOv5s+EMA | 7.24 | 16.8 | 227 |
| YOLOv5s+CSA | 7.28 | 16.7 | 243 |
| YOLOv8s+CA | 11.20 | 28.9 | 215 |
| YOLOv8s+EMA | 11.17 | 29.0 | 178 |
| YOLOv8s+CSA | 11.20 | 28.9 | 238 |
| 模型 | Top-1/% | Top-5/% | 帧率/(frame·s-1) |
|---|---|---|---|
| +CSA_11 | 79.97 | 94.87 | 95 |
| +CSA_22 | 78.71 | 95.07 | 96 |
| +CSA_21 | 79.98 | 95.08 | 94 |
| +CSA(无顺序恢复) | 80.15 | 95.14 | 101 |
| +CSA( | 79.79 | 94.69 | 110 |
| +CSA | 80.48 | 95.19 | 96 |
表5 消融实验结果
Tab. 5 Ablation experimental results
| 模型 | Top-1/% | Top-5/% | 帧率/(frame·s-1) |
|---|---|---|---|
| +CSA_11 | 79.97 | 94.87 | 95 |
| +CSA_22 | 78.71 | 95.07 | 96 |
| +CSA_21 | 79.98 | 95.08 | 94 |
| +CSA(无顺序恢复) | 80.15 | 95.14 | 101 |
| +CSA( | 79.79 | 94.69 | 110 |
| +CSA | 80.48 | 95.19 | 96 |
| 1 | KRIZHEVSKY A, SUTSKEVER I, HINTON G E. ImageNet classification with deep convolutional neural networks[C]// Proceedings of the 25th International Conference on Neural Information Processing Systems — Volume 1. Red Hook: Curran Associates Inc., 2012: 1097-1105. |
| 2 | HE K, ZHANG X, REN S, et al. Deep residual learning for image recognition[C]// Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2016: 770-778. |
| 3 | SZEGEDY C, LIU W, JIA Y, et al. Going deeper with convolutions[C]// Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2015: 1-9. |
| 4 | SIMONYAN K, ZISSERMAN A. Very deep convolutional networks for large-scale image recognition [EB/OL]. [2024-04-26].. |
| 5 | HUANG G, LIU Z, VAN DER MAATEN L, et al. Densely connected convolutional networks[C]// Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2017: 2261-2269. |
| 6 | SZEGEDY C, VANHOUCKE V, IOFFE S, et al. Rethinking the inception architecture for computer vision[C]// Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2016: 2818-2826. |
| 7 | REDMON J, FARHADI A. YOLO9000: better, faster, stronger[C]// Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2017: 6517-6525. |
| 8 | HU J, SHEN L, SUN G. Squeeze-and-excitation networks[C]// Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2018: 7132-7141. |
| 9 | WOO S, PARK J, LEE J Y, et al. CBAM: convolutional block attention module[C]// Proceedings of the 2018 European Conference on Computer Vision, LNCS 11211. Cham: Springer, 2018: 3-19. |
| 10 | 肖斌,甘昀,汪敏,等. 基于端口注意力与通道空间注意力的网络异常流量检测[J]. 计算机应用, 2024, 44(4): 1027-1034. |
| XIAO B, GAN Y, WANG M, et al. Network abnormal traffic detection based on port attention and convolutional block attention module[J]. Journal of Computer Applications, 2024, 44(4): 1027-1034. | |
| 11 | HOU Q, ZHOU D, FENG J. Coordinate attention for efficient mobile network design[C]// Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2021: 13713-13722. |
| 12 | YANG W, WU J, ZHANG J, et al. Deformable convolution and coordinate attention for fast cattle detection[J]. Computers and Electronics in Agriculture, 2023, 211: No.108006. |
| 13 | ZHAO D, CAI W, CUI L. Adaptive thresholding and coordinate attention-based tree-inspired network for aero-engine bearing health monitoring under strong noise[J]. Advanced Engineering Informatics, 2024, 61: No.102559. |
| 14 | ZHANG Q L, YANG Y B. SA-Net: shuffle attention for deep convolutional neural networks[C]// Proceedings of the 2021 IEEE International Conference on Acoustics, Speech and Signal Processing. Piscataway: IEEE, 2021: 2235-2239. |
| 15 | OUYANG D, HE S, ZHANG G, et al. Efficient multi-scale attention module with cross-spatial learning[C]// Proceedings of the 2023 IEEE International Conference on Acoustics, Speech and Signal Processing. Piscataway: IEEE, 2023: 1-5. |
| 16 | WU T, DONG Y. YOLO-SE: improved YOLOv8 for remote sensing object detection and recognition[J]. Applied Sciences, 2023, 13(24): No.12977. |
| 17 | CHEN S, LI Y, ZHANG Y, et al. Soft X-ray image recognition and classification of maize seed cracks based on image enhancement and optimized YOLOv8 model[J]. Computers and Electronics in Agriculture, 2024, 216: No.108475. |
| 18 | LIU Y, SHAO Z, TENG Y, et al. NAM: normalization-based attention module[EB/OL]. [2024-04-26].. |
| 19 | WANG C Y, LIAO H Y M, WU Y H, et al. CSPNet: a new backbone that can enhance learning capability of CNN[C]// Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops. Piscataway: IEEE, 2020: 1571-1580. |
| 20 | HOWARD A G, ZHU M, CHEN B, et al. MobileNets: efficient convolutional neural networks for mobile vision applications[EB/OL]. [2024-04-26].. |
| 21 | SANDLER M, HOWARD A, ZHU M, et al. MobileNetV2: inverted residuals and linear bottlenecks[C]// Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2018: 4510-4520. |
| 22 | HOWARD A, SANDLER M, CHEN B, et al. Searching for MobileNetV3[C]// Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision. Piscataway: IEEE, 2019: 1314-1324. |
| 23 | ZHANG X, ZHOU X, LIN M, et al. ShuffleNet: an extremely efficient convolutional neural network for mobile devices[C]// Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2018: 6848-6856. |
| 24 | MA N, ZHANG X, ZHENG H T, et al. ShuffleNet V2: practical guidelines for efficient CNN architecture design[C]// Proceedings of the 2018 European Conference on Computer Vision, LNCS 11218. Cham: Springer, 2018: 122-138. |
| 25 | LI X, HU X, YANG J. Spatial group-wise enhance: improving semantic feature learning in convolutional networks[EB/OL]. [2024-04-26].. |
| 26 | YANG K, CHANG S, TIAN Z, et al. Automatic polyp detection and segmentation using shuffle efficient channel attention network[J]. Alexandria Engineering Journal, 2022, 61(1): 917-926. |
| 27 | WANG Q, WU B, ZHU P, et al. ECA-Net: efficient channel attention for deep convolutional neural networks[C]// Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2020: 11531-11539. |
| 28 | GAO X, XU L, WANG F, et al. Multi-branch aware module with channel shuffle pixel-wise attention for lightweight image super-resolution[J]. Multimedia Systems, 2023, 29: 289-303. |
| 29 | LIU K, CHEN K, GUO L, et al. ShuffleMix: improving representations via channel-wise shuffle of interpolated hidden states[EB/OL]. [2024-04-26].. |
| 30 | LYU J, ZHANG S, QI Y, et al. AutoShuffleNet: learning permutation matrices via an exact Lipschitz continuous penalty in deep convolutional neural networks[C]// Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. New York: ACM, 2020: 608-616. |
| 31 | WANG C Y, BOCHKOVSKIY A, LIAO H Y M. YOLOv7: trainable bag-of-freebies sets new state-of-the-art for real-time object detectors[C]// Proceedings of the 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2023: 7464-7475. |
| 32 | WANG C Y, LIAO H Y M, YEH I H. Designing network design strategies through gradient path analysis[J]. Journal of Information Science and Engineering, 2023, 39(4): 975-995. |
| 33 | CHEN Y, KALANTIDIS Y, LI J, et al. A2-Nets: double attention networks[C]// Proceedings of the 32nd International Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2018: 350-359. |
| 34 | YANG L, ZHANG R Y, LI L, et al. SimAM: a simple, parameter-free attention module for convolutional neural networks[C]// Proceedings of the 38th International Conference on Machine Learning. New York: JMLR.org, 2021: 11863-11874. |
| 35 | LI X, WANG W, HU X, et al. Selective kernel networks[C]// Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2019: 510-519. |
| 36 | DENG J, DONG W, SOCHER R, et al. ImageNet: a large-scale hierarchical image database[C]// Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2009: 248-255. |
| 37 | LIN T Y, MAIRE M, BELONGIE S, et al. Microsoft COCO: common objects in context[C]// Proceedings of the 2014 European Conference on Computer Vision, LNCS 8693. Cham: Springer, 2014: 740-755. |
| 38 | Ultralytics. YOLOv8[EB/OL]. [2024-04-26].. |
| 39 | Ultralytics. YOLOv5[EB/OL]. [2024-04-26].. |
| 40 | SELVARAJU R R, COGSWELL M, DAS A, et al. Grad-CAM: visual explanations from deep networks via gradient-based localization[C]// Proceedings of the 2017 IEEE International Conference on Computer Vision. Piscataway: IEEE, 2017: 618-626. |
| [1] | 严一钦, 罗川, 李天瑞, 陈红梅. 基于关系网络和Vision Transformer的跨域小样本分类模型[J]. 《计算机应用》唯一官方网站, 2025, 45(4): 1095-1103. |
| [2] | 徐春, 吉双焱, 马欢, 孙恩威, 王萌萌, 苏明钰. 基于知识图谱和对话结构的问诊推荐方法[J]. 《计算机应用》唯一官方网站, 2025, 45(4): 1157-1168. |
| [3] | 赵轻轻, 胡滨. 不变性全局稀疏轮廓点表征的运动行人检测神经网络[J]. 《计算机应用》唯一官方网站, 2025, 45(4): 1271-1284. |
| [4] | 郭诗月, 党建武, 王阳萍, 雍玖. 结合注意力机制和多尺度特征融合的三维手部姿态估计[J]. 《计算机应用》唯一官方网站, 2025, 45(4): 1293-1299. |
| [5] | 胡婕, 郑启扬, 孙军, 张龑. 基于多标签关系图和局部动态重构学习的多标签分类模型[J]. 《计算机应用》唯一官方网站, 2025, 45(4): 1104-1112. |
| [6] | 王利琴, 耿智雷, 李英双, 董永峰, 边萌. 基于路径和增强三元组文本的开放世界知识推理模型[J]. 《计算机应用》唯一官方网站, 2025, 45(4): 1177-1183. |
| [7] | 侯阳, 张琼, 赵紫煊, 朱正宇, 张晓博. 基于YOLOv5s的复杂场景下高效烟火检测算法YOLOv5s-MRD[J]. 《计算机应用》唯一官方网站, 2025, 45(4): 1317-1324. |
| [8] | 姜坤元, 李小霞, 王利, 曹耀丹, 张晓强, 丁楠, 周颖玥. 引入解耦残差自注意力的边界交叉监督语义分割网络[J]. 《计算机应用》唯一官方网站, 2025, 45(4): 1120-1129. |
| [9] | 丁美荣, 卓金鑫, 陆玉武, 刘庆龙, 郎济聪. 融合环境标签平滑与核范数差异的领域自适应[J]. 《计算机应用》唯一官方网站, 2025, 45(4): 1130-1138. |
| [10] | 张传浩, 屠晓涵, 谷学汇, 轩波. 基于多模态信息相互引导补充的雷达-相机三维目标检测[J]. 《计算机应用》唯一官方网站, 2025, 45(3): 946-952. |
| [11] | 耿海军, 董赟, 胡治国, 池浩田, 杨静, 尹霞. 基于Attention-1DCNN-CE的加密流量分类方法[J]. 《计算机应用》唯一官方网站, 2025, 45(3): 872-882. |
| [12] | 余松森, 林智凡, 薛国鹏, 徐建宇. 基于改进YOLOv8的轻量级大幅面瓷砖缺陷检测算法[J]. 《计算机应用》唯一官方网站, 2025, 45(2): 647-654. |
| [13] | 丁丹妮, 彭博, 吴锡. 受腹侧通路启发的脂肪肝超声图像分类方法VPNet[J]. 《计算机应用》唯一官方网站, 2025, 45(2): 662-669. |
| [14] | 张天骐, 谭霜, 沈夕文, 唐娟. 融合注意力机制和多尺度特征的图像水印方法[J]. 《计算机应用》唯一官方网站, 2025, 45(2): 616-623. |
| [15] | 王地欣, 王佳昊, 李敏, 陈浩, 胡光耀, 龚宇. 面向水声通信网络的异常攻击检测[J]. 《计算机应用》唯一官方网站, 2025, 45(2): 526-533. |
| 阅读次数 | ||||||
|
全文 |
|
|||||
|
摘要 |
|
|||||