


Journal of Computer Applications ›› 2024, Vol. 44 ›› Issue (4): 1035-1048.DOI: 10.11772/j.issn.1001-9081.2023040537
• Artificial intelligence • Previous Articles Next Articles
Xiawuji1,2, Heming HUANG1,2( ), Gengzangcuomao1,2, Yutao FAN1,2
), Gengzangcuomao1,2, Yutao FAN1,2
Received:2023-05-06
Revised:2023-07-19
Accepted:2023-07-25
Online:2023-12-04
Published:2024-04-10
Contact:
Heming HUANG
About author:Xiawuji, born in 1982, Ph. D. candidate, associate professor. Her research interests include pattern recognition and intelligent systems, Tibetan intelligent information processing.Supported by:
夏吾吉1,2, 黄鹤鸣1,2(), 更藏措毛1,2, 范玉涛1,2
通讯作者:
黄鹤鸣
作者简介:夏吾吉(1982—),女(藏族),青海尖扎人,副教授,博士研究生,CCF会员,主要研究方向:模式识别与智能系统、藏语智能信息处理基金资助:CLC Number:
Xiawuji, Heming HUANG, Gengzangcuomao, Yutao FAN. Survey of extractive text summarization based on unsupervised learning and supervised learning[J]. Journal of Computer Applications, 2024, 44(4): 1035-1048.
夏吾吉, 黄鹤鸣, 更藏措毛, 范玉涛. 基于无监督学习和监督学习的抽取式文本摘要综述[J]. 《计算机应用》唯一官方网站, 2024, 44(4): 1035-1048.
Add to citation manager EndNote|Ris|BibTeX
URL: https://www.joca.cn/EN/10.11772/j.issn.1001-9081.2023040537
| 技术 | 方法 | 方法描述 | 优势 | 劣势 |
|---|---|---|---|---|
| 无监督 | 规则[ | 使用简单的启发式定义函数特征 进行线性组合,并评价文本句子的 重要程度 | 规则较简单,运行速度高, 对数据要求低,易实现 | 数据覆盖范围窄,难以处理大规模数据, 对语义特征和词义关系的 挖掘具有局限性 |
词频-逆文件 频率[ | 通过词频与逆文件频率共同评估 某个词在原始文本中的重要程度 | 注重保留重要词语,过滤常见词语 | 当数据规模增加时,无法增量更新, 需要重新计算;词语的位置特征对 文本的区分度考虑不够 | |
| 中心性[ | 将原始文本中的词或句子用图的 形式表示 | 通常以图的形式展现, 能刻画重要节点 | 计算复杂度高, 难以在大规模网络上实现 | |
| 潜在语义[ | 分析大量的文本数据,提取词或 句子之间潜在语义结构和相似性 | 通过分解文档表示矩阵去除 同义词影响、消除冗余信息 | 难以控制词义聚类效果, 空间与时间复杂度较高 | |
| 深度学习[ | 通过计算目标函数值完成筛选 句子,并将它作为摘要 | 对人工依赖度较低,学习能力强, 善于处理复杂非线性函数,并能找出 输入之间的依赖关系 | 对数据要求高、参数多,由于引入 多种神经网络模型,运行速度慢, 对硬件要求高 | |
| 图排序[ | 在图上利用全局信息的不断迭代 计算句子的重要程度 | 充分考虑词组之间、词汇之间和句子 之间的全局关系,无需处理大量数据 | 依赖句子节点间的相似度,未充分利用 数据,时间复杂度高,未考虑冗余信息 | |
| 监督 | 特征工程[ | 通过提取文本的词频特征、位置 特征和句子长度特征抽取摘要 | 能够从原始数据中筛选更好的特征 | 模型对数据样本不均衡问题不敏感 |
| 二分类[ | 通过“是”和“否”二分类方法判断 文本中的句子是否在摘要中 | 能够利用贝叶斯、支持向量机、决策树 等模型判断当前句子是否隶属摘要 | 容易忽略句子之间的相关性 | |
| 深度学习[ | 针对句子的回归框架建立的词、 句子和文本的特征模型 | 生成摘要的准确度高,训练高效且 能够与多种模型结合使用 | 需要大量人工标注的数据,参数多, 易出现梯度爆炸或梯度消失现象 |
Tab. 1 Classification of extractive summarization generation techniques
| 技术 | 方法 | 方法描述 | 优势 | 劣势 |
|---|---|---|---|---|
| 无监督 | 规则[ | 使用简单的启发式定义函数特征 进行线性组合,并评价文本句子的 重要程度 | 规则较简单,运行速度高, 对数据要求低,易实现 | 数据覆盖范围窄,难以处理大规模数据, 对语义特征和词义关系的 挖掘具有局限性 |
词频-逆文件 频率[ | 通过词频与逆文件频率共同评估 某个词在原始文本中的重要程度 | 注重保留重要词语,过滤常见词语 | 当数据规模增加时,无法增量更新, 需要重新计算;词语的位置特征对 文本的区分度考虑不够 | |
| 中心性[ | 将原始文本中的词或句子用图的 形式表示 | 通常以图的形式展现, 能刻画重要节点 | 计算复杂度高, 难以在大规模网络上实现 | |
| 潜在语义[ | 分析大量的文本数据,提取词或 句子之间潜在语义结构和相似性 | 通过分解文档表示矩阵去除 同义词影响、消除冗余信息 | 难以控制词义聚类效果, 空间与时间复杂度较高 | |
| 深度学习[ | 通过计算目标函数值完成筛选 句子,并将它作为摘要 | 对人工依赖度较低,学习能力强, 善于处理复杂非线性函数,并能找出 输入之间的依赖关系 | 对数据要求高、参数多,由于引入 多种神经网络模型,运行速度慢, 对硬件要求高 | |
| 图排序[ | 在图上利用全局信息的不断迭代 计算句子的重要程度 | 充分考虑词组之间、词汇之间和句子 之间的全局关系,无需处理大量数据 | 依赖句子节点间的相似度,未充分利用 数据,时间复杂度高,未考虑冗余信息 | |
| 监督 | 特征工程[ | 通过提取文本的词频特征、位置 特征和句子长度特征抽取摘要 | 能够从原始数据中筛选更好的特征 | 模型对数据样本不均衡问题不敏感 |
| 二分类[ | 通过“是”和“否”二分类方法判断 文本中的句子是否在摘要中 | 能够利用贝叶斯、支持向量机、决策树 等模型判断当前句子是否隶属摘要 | 容易忽略句子之间的相关性 | |
| 深度学习[ | 针对句子的回归框架建立的词、 句子和文本的特征模型 | 生成摘要的准确度高,训练高效且 能够与多种模型结合使用 | 需要大量人工标注的数据,参数多, 易出现梯度爆炸或梯度消失现象 |
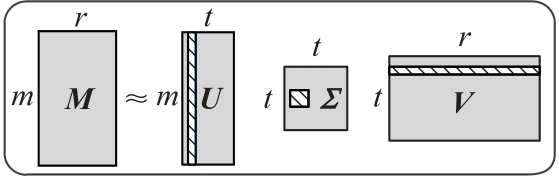
Fig. 1 Approximate description of singular value matrix
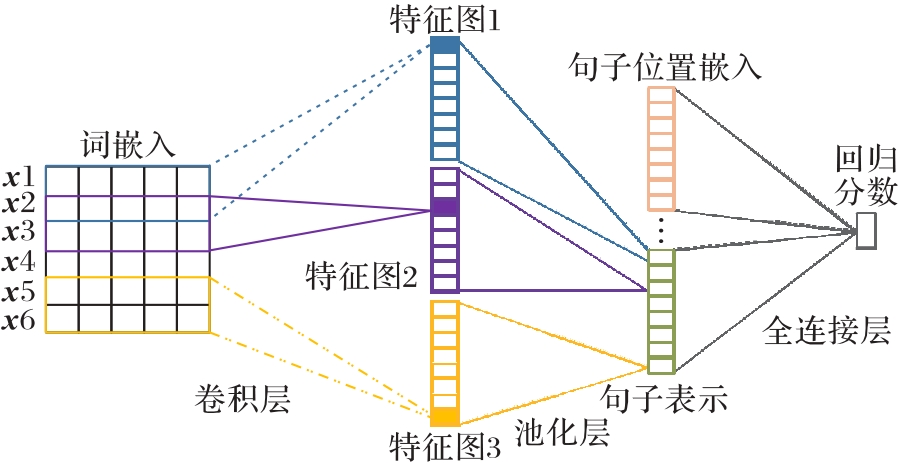
Fig. 2 Basic model of text summarization based on CNN
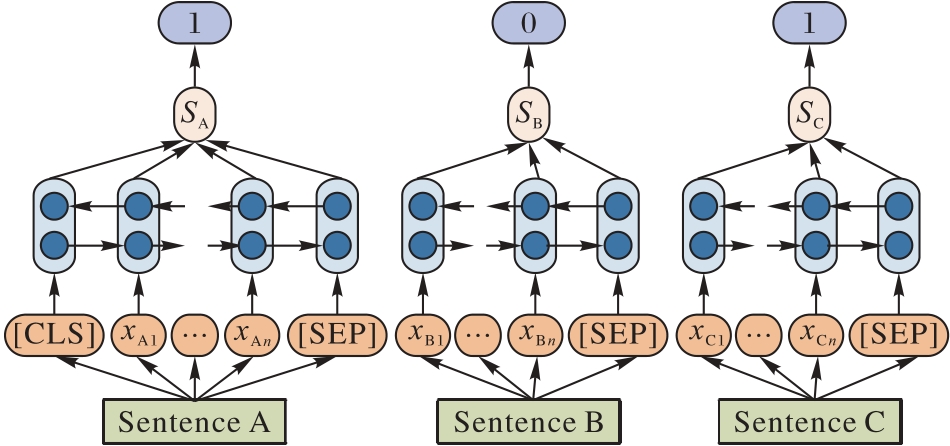
Fig. 3 Basic model of text summarization based on Bi-RNN
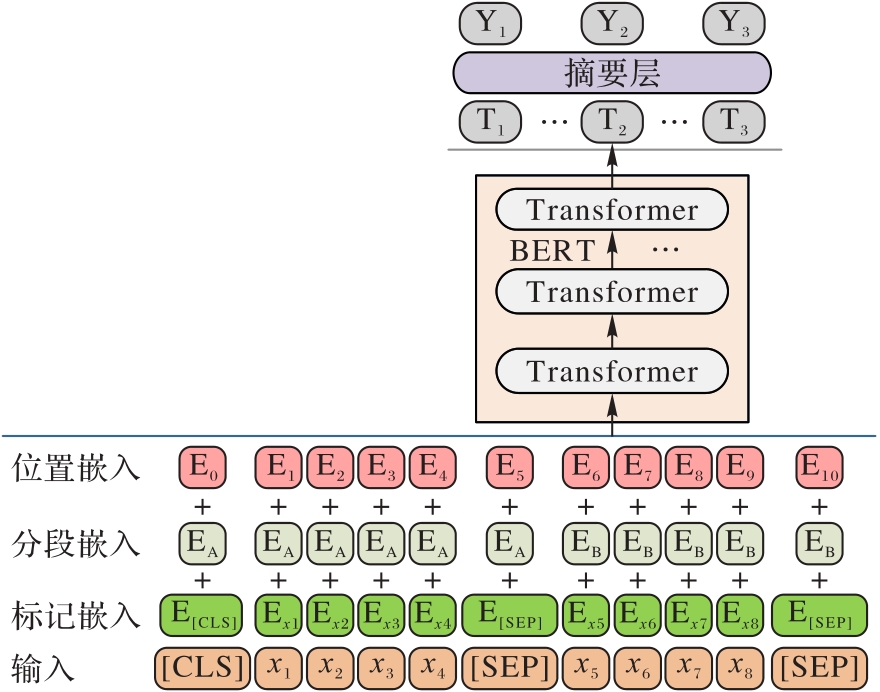
Fig. 4 Extractive text summarization architecture based on BERTSUM
| 基础 | 模型 | DUC‑2001 | DUC‑2002 | DUC‑2004 | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| ROUGE_1 | ROUGE_2 | ROUGE_L | ROUGE_1 | ROUGE_2 | ROUGE_L | ROUGE_1 | ROUGE_2 | ROUGE_L | ||
| CNN | DivSelect+CNNLM[ | — | — | — | 51.01 | 26.97 | 29.43 | 40.91 | 10.72 | 14.97 |
| PriorSum[ | 35.98 | 7.89 | — | 36.63 | 8.97 | — | 38.91 | 10.07 | — | |
| TCSum[ | 36.45 | 7.66 | — | 36.90 | 8.61 | — | 38.27 | 9.66 | — | |
| MV-CNN[ | 35.99 | 7.91 | — | 36.71 | 9.02 | — | 39.07 | 10.06 | — | |
| CNN+RNN | CRSum+SF[ | 36.54 | 8.75 | — | 38.90 | 10.28 | — | 39.53 | 10.60 | — |
| Transformer | PRIMERA[ | — | — | — | — | — | — | 35.10 | 7.20 | 17.90 |
| PRESUM+DRsup[ | — | — | — | — | — | — | 34.62 | 8.22 | 30.54 | |
Tab. 2 Comparison of ROUGE scores on DUC dataset
| 基础 | 模型 | DUC‑2001 | DUC‑2002 | DUC‑2004 | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| ROUGE_1 | ROUGE_2 | ROUGE_L | ROUGE_1 | ROUGE_2 | ROUGE_L | ROUGE_1 | ROUGE_2 | ROUGE_L | ||
| CNN | DivSelect+CNNLM[ | — | — | — | 51.01 | 26.97 | 29.43 | 40.91 | 10.72 | 14.97 |
| PriorSum[ | 35.98 | 7.89 | — | 36.63 | 8.97 | — | 38.91 | 10.07 | — | |
| TCSum[ | 36.45 | 7.66 | — | 36.90 | 8.61 | — | 38.27 | 9.66 | — | |
| MV-CNN[ | 35.99 | 7.91 | — | 36.71 | 9.02 | — | 39.07 | 10.06 | — | |
| CNN+RNN | CRSum+SF[ | 36.54 | 8.75 | — | 38.90 | 10.28 | — | 39.53 | 10.60 | — |
| Transformer | PRIMERA[ | — | — | — | — | — | — | 35.10 | 7.20 | 17.90 |
| PRESUM+DRsup[ | — | — | — | — | — | — | 34.62 | 8.22 | 30.54 | |
| 模型 | CNN/DM | Multi‑News | Xsum | ||||||
|---|---|---|---|---|---|---|---|---|---|
| ROUGE_1 | ROUGE_2 | ROUGE_L | ROUGE_1 | ROUGE_2 | ROUGE_L | ROUGE_1 | ROUGE_2 | ROUGE_L | |
| PEGASUS[ | 44.17 | 21.47 | 41.11 | — | — | — | 47.21 | 24.56 | 39.25 |
| SummaRuNNer[ | 39.60 | 16.20 | 35.30 | — | — | — | — | — | — |
| BERTSUM[ | 43.25 | 20.24 | 39.63 | — | — | — | — | — | — |
| HiStruct+BERT-base[ | 43.38 | 20.33 | 39.78 | — | — | — | — | — | — |
| HiStruct+RoBERTa-base[ | 43.65 | 20.54 | 40.03 | — | — | — | — | — | — |
| DISCOBERT[ | 43.77 | 20.85 | 40.67 | — | — | — | — | — | — |
| HETERSUMGRAPH[ | 42.95 | 19.76 | 39.23 | 45.15 | 15.78 | 41.29 | — | — | — |
| PRESUM+DRsup[ | — | — | — | 46.57 | 17.10 | 42.44 | — | — | — |
Tab. 3 Comparison of ROUGE scores on CNN/DM, Multi-News, and Xsum datasets
| 模型 | CNN/DM | Multi‑News | Xsum | ||||||
|---|---|---|---|---|---|---|---|---|---|
| ROUGE_1 | ROUGE_2 | ROUGE_L | ROUGE_1 | ROUGE_2 | ROUGE_L | ROUGE_1 | ROUGE_2 | ROUGE_L | |
| PEGASUS[ | 44.17 | 21.47 | 41.11 | — | — | — | 47.21 | 24.56 | 39.25 |
| SummaRuNNer[ | 39.60 | 16.20 | 35.30 | — | — | — | — | — | — |
| BERTSUM[ | 43.25 | 20.24 | 39.63 | — | — | — | — | — | — |
| HiStruct+BERT-base[ | 43.38 | 20.33 | 39.78 | — | — | — | — | — | — |
| HiStruct+RoBERTa-base[ | 43.65 | 20.54 | 40.03 | — | — | — | — | — | — |
| DISCOBERT[ | 43.77 | 20.85 | 40.67 | — | — | — | — | — | — |
| HETERSUMGRAPH[ | 42.95 | 19.76 | 39.23 | 45.15 | 15.78 | 41.29 | — | — | — |
| PRESUM+DRsup[ | — | — | — | 46.57 | 17.10 | 42.44 | — | — | — |
| 语言 | 数据集 | 摘要方式 | 规模(约) |
|---|---|---|---|
| 英文 | DUC/TAC | 抽取式/生成式 | 0.97万 |
| CNN/DM | 抽取式/生成式 | 30万 | |
| CNEWSROOMS | 抽取式/生成式 | 130万 | |
| RNSum | 抽取式/生成式 | 8.2万 | |
| QMSum | 抽取式/生成式 | 0.2万 | |
| Multi-News | 抽取式/生成式 | 5.6万 | |
| Xsum | 抽取式/生成式 | 22.6万 | |
| NYTAC | 抽取式 | 650万 | |
| ASNAPR | 生成式 | 3 500万 | |
| Gigaword[ | 生成式 | 400万 | |
| Byte Cup | 生成式 | 130万 | |
| 中文 | LCSTS[ | 生成式 | 240万 |
| NLPCC | 生成式 | 5万 | |
| 藏文 | Ti-SUM | 抽取式/生成式 | 0.1万 |
Tab. 4 Common datasets for text summarization
| 语言 | 数据集 | 摘要方式 | 规模(约) |
|---|---|---|---|
| 英文 | DUC/TAC | 抽取式/生成式 | 0.97万 |
| CNN/DM | 抽取式/生成式 | 30万 | |
| CNEWSROOMS | 抽取式/生成式 | 130万 | |
| RNSum | 抽取式/生成式 | 8.2万 | |
| QMSum | 抽取式/生成式 | 0.2万 | |
| Multi-News | 抽取式/生成式 | 5.6万 | |
| Xsum | 抽取式/生成式 | 22.6万 | |
| NYTAC | 抽取式 | 650万 | |
| ASNAPR | 生成式 | 3 500万 | |
| Gigaword[ | 生成式 | 400万 | |
| Byte Cup | 生成式 | 130万 | |
| 中文 | LCSTS[ | 生成式 | 240万 |
| NLPCC | 生成式 | 5万 | |
| 藏文 | Ti-SUM | 抽取式/生成式 | 0.1万 |
| 评价方式 | 评价指标 | 类别 | 适用范围 | 优点 | 缺点 |
|---|---|---|---|---|---|
| 自动评价 | SUPERT | 无监督 | 多文档摘要 | 不需要人工撰写参考摘要,方法简单有效 | 忽略了句子的位置信息 |
| Pyramid | 注释 | 单文档摘要 | 聚焦单词之间的关系, 捕获原文本的复杂性 | 忽略了内容单元之间的依赖关系 | |
| BLEU | 监督 | 单文档摘要、机器翻译 | 易于计算,速度快,应用范围广 | 不考虑语义、句子结构,不能较好地 处理形态丰富的语句,偏向较短的摘要 | |
| ROUGR_N | 监督 | 单文档摘要、多文档摘要和 短摘要提取等 | 简洁且有词序 | 区分度不高,随着n‑gram的增大, 值变小 | |
| ROUGR_L | 监督 | 单文档摘要、多文档摘要和 短摘要提取等 | 反映句子级别的顺序,不需要制定 n‑gram的长度 | 仅考虑了最长公共子序列的长度 | |
| 人工评价 | 单文档、长文档、多文档和 短摘要提取等 | 评价结果更精确,更符合实际 | 耗时耗力,容易受外界因素的干扰 |
Tab. 5 Comparison of advantages and disadvantages among different evaluation metrics
| 评价方式 | 评价指标 | 类别 | 适用范围 | 优点 | 缺点 |
|---|---|---|---|---|---|
| 自动评价 | SUPERT | 无监督 | 多文档摘要 | 不需要人工撰写参考摘要,方法简单有效 | 忽略了句子的位置信息 |
| Pyramid | 注释 | 单文档摘要 | 聚焦单词之间的关系, 捕获原文本的复杂性 | 忽略了内容单元之间的依赖关系 | |
| BLEU | 监督 | 单文档摘要、机器翻译 | 易于计算,速度快,应用范围广 | 不考虑语义、句子结构,不能较好地 处理形态丰富的语句,偏向较短的摘要 | |
| ROUGR_N | 监督 | 单文档摘要、多文档摘要和 短摘要提取等 | 简洁且有词序 | 区分度不高,随着n‑gram的增大, 值变小 | |
| ROUGR_L | 监督 | 单文档摘要、多文档摘要和 短摘要提取等 | 反映句子级别的顺序,不需要制定 n‑gram的长度 | 仅考虑了最长公共子序列的长度 | |
| 人工评价 | 单文档、长文档、多文档和 短摘要提取等 | 评价结果更精确,更符合实际 | 耗时耗力,容易受外界因素的干扰 |
| 1 | GAMBHIR M, GUPTA V. Recent automatic text summarization techniques: a survey [J]. Artificial Intelligence Review, 2017, 47(1): 1-66. 10.1007/s10462-016-9475-9 |
| 2 | ABDELALEEM N M, KADER H M A, SALEM R. A brief survey on text summarization techniques [J]. International Journal of Electronics and Information Engineering, 2019, 10(2): 76-89. |
| 3 | 侯圣峦,张书涵,费超群.文本摘要常用数据集和方法研究综述[J].中文信息学报,2019,33(5):1-16. 10.3969/j.issn.1003-0077.2019.05.001 |
| HOU S L, ZHANG S H, FEI C Q. A survey to text summarization: popular datasets and methods [J]. Journal of Chinese Information Processing, 2019,33(5):1-16. 10.3969/j.issn.1003-0077.2019.05.001 | |
| 4 | LUHN H P. The automatic creation of literature abstracts [J]. IBM Journal of Research and Development, 1958, 2(2): 159-165. 10.1147/rd.22.0159 |
| 5 | EDMUNDSON H P. New methods in automatic extracting [J]. Journal of the ACM, 1969, 16(2): 264-285. 10.1145/321510.321519 |
| 6 | MILLER G A. WordNet: a lexical database for English [J]. Communications of the ACM, 1995, 38(11): 39-41. 10.1145/219717.219748 |
| 7 | HOU S, HUANG Y, FEI C, et al. Holographic lexical chain and its application in Chinese text summarization [C]// Proceedings of the 1st Asia-Pacific Web and Web-Age Information Management Joint International Conference on Web and Big Data. Cham: Springer, 2017: 266-281. 10.1007/978-3-319-63579-8_21 |
| 8 | LYNN H M, CHOI C, KIM P. An improved method of automatic text summarization for Web contents using lexical chain with semantic-related terms [J]. Soft Computing, 2018, 22(12): 4013-4023. 10.1007/s00500-017-2612-9 |
| 9 | GARCÍA-HERNÁNDEZ R A, LEDENEVA Y. Word sequence models for single text summarization [C]// Proceedings of the 2009 2nd International Conferences on Advances in Computer-Human Interactions. Washington, DC: IEEE Computer Society, 2009: 44-48. 10.1109/achi.2009.58 |
| 10 | SARKAR K. An approach to summarizing Bengali news documents [C]// Proceedings of the 2012 International Conference on Advances in Computing, Communications and Informatics. New York: ACM, 2012: 857-862. 10.1145/2345396.2345535 |
| 11 | EL-BELTAGY S R, REFEA A. KP-Miner: participation in SemeVal-2 [C]// Proceedings of the 5th International Workshop on Semantic Evaluation. Stroudsburg: ACL, 2010: 190-193. |
| 12 | VANDERWENDE L, SUZUKI H, BROCKETT C, et al. Beyond SumBasic: task-focused summarization with sentence simplification and lexical expansion [J]. Information Processing & Management, 2007, 43(6): 1606-1618. 10.1016/j.ipm.2007.01.023 |
| 13 | MANI I, BLOEDORN E. Multi-document summarization by graph search and matching [C]// Proceedings of the 14th National Conference on Artificial Intelligence and 9th Conference on Innovative Applications of Artificial Intelligence Conference. Palo Alto: AAAI Press, 1997: 622-628. |
| 14 | RADEV D R, JING H, STYŚ M, et al. Centroid-based summarization of multiple documents [J]. Information Processing & Management, 2004, 40(6): 919-938. 10.1016/j.ipm.2003.10.006 |
| 15 | WAN X, YANG J. Multi-document summarization using cluster-based link analysis [C]// Proceedings of the 31st Annual International ACM SIGIR Conference on Research and Development in Information Retrieval. New York: ACM, 2008: 299-306. 10.1145/1390334.1390386 |
| 16 | WAN X. Using bilingual information for cross-language document summarization [C]// Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics: Human Language Technologies. Stroudsburg: ACL, 2011: 1546-1555. |
| 17 | ZHANG Y, CHU C-H, JI X, et al. Correlating summarization of multi-source news with k-way graph bi-clustering [J]. ACM SIGKDD Explorations Newsletter, 2004, 6(2): 34-42. 10.1145/1046456.1046461 |
| 18 | WAN X, XIAO J. Graph-based multi-modality learning for topic-focused multi-document summarization [C]// Proceedings of the 21st International Joint Conference on Artificial Intelligence. San Francisco: Morgan Kaufmann Publishers Inc, 2009: 1586-1591. 10.1145/1645953.1646184 |
| 19 | GONG Y, LIU X. Generic text summarization using relevance measure and latent semantic analysis [C]// Proceedings of the 24th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval. New York: ACM, 2001: 19-25. 10.1145/383952.383955 |
| 20 | MURRAY G, RENALS S, CARLETTA J. Extractive summarization of meeting recordings [C]// Proceedings of the 9th European Conference on Speech Communication and Technology. [S.l.]: International Speech Communication Association, 2005: 593-596. 10.21437/interspeech.2005-59 |
| 21 | STEINBERGER J, KABADJOV M A, POESIO M, et al. Improving LSA-based summarization with anaphora resolution [C]// Proceedings of the 2005 Conference on Human Language Technology and Empirical Methods in Natural Language Processing. Stroudsburg: ACL, 2005: 1-8. 10.3115/1220575.1220576 |
| 22 | GEETHA J K, DEEPAMALA N. Kannada text summarization using latent semantic analysis [C]// Proceedings of the 2015 International Conference on Advances in Computing, Communications and Informatics. Piscataway: IEEE, 2015: 1508-1512. 10.1109/icacci.2015.7275826 |
| 23 | LIU Y, ZHONG S-H, LI W J. Query-oriented multi-document summarization via unsupervised deep learning [C]// Proceedings of the 26th AAAI Conference on Artificial Intelligence. Palo Alto: AAAI Press, 2012: 1699-1705. |
| 24 | HE Z, CHEN C, BU J, et al. Document summarization based on data reconstruction [C]// Proceedings of the 26th AAAI Conference on Artificial Intelligence. Palo Alto: AAAI Press, 2012: 620-626. |
| 25 | KOBAYASHI H, NOGUCHI M, YATSUKA T. Summarization based on embedding distributions [C]// Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing. Stroudsburg: ACL, 2015: 1984-1989. 10.18653/v1/d15-1232 |
| 26 | 王佳松.基于深度学习的多文档自动文摘研究[D].长春:吉林大学,2017:25-29. |
| WANG J S. Research on automatic multi-document summarization based on deep learning [D]. Changchun: Jilin University, 2017: 25-29. | |
| 27 | SONG H, REN Z, LIANG S, et al. Summarizing answer in non-factoid community question-answering [C]// Proceeding of the 10th ACM International Conference on Web Search and Data Mining. New York: ACM, 2017: 405-414. 10.1145/3018661.3018704 |
| 28 | LI P, WANG Z, LAM W, et al. Salience Estimation via variational auto-encoders for multi-document summarization [C]// Proceedings of the 31st AAAI Conference on Artificial Intelligence. Palo Alto: AAAI Press, 2017: 3497-3503. 10.1609/aaai.v31i1.11007 |
| 29 | REN Z, SONG H, LI P, et al. Using sparse coding for answer summarization in non-factoid community question-answering [C/OL]// Proceedings of the 2nd WebQA Workshop. Waterloo: University of Waterloo [2023-04-01]. . 10.1145/3018661.3018704 |
| 30 | HAVELIWALA T H. Topic-sensitive PageRank: a context-sensitive ranking algorithm for Web search [J]. IEEE Transactions on Knowledge and Data Engineering, 2003, 15(4): 784-796. 10.1109/tkde.2003.1208999 |
| 31 | BADRINATH R, VENKATASUBRAMANIYAN S, MADHAVAN C E V. Improving query focused summarization using look-ahead strategy [C]// Proceedings of the 33rd European Conference on Advances in Information Retrieval. Berlin: Springer, 2011: 641-652. 10.1007/978-3-642-20161-5_64 |
| 32 | WEI F, LI W, LU Q, et al. A document-sensitive graph model for multi-document summarization [J]. Knowledge and Information Systems, 2010, 22(2): 245-259. 10.1007/s10115-009-0194-2 |
| 33 | 李伟,闫晓东,解晓庆.基于改进 TextRank 的藏文抽取式摘要[J].中文信息学报,2020,34(9):36-43. |
| LI W, YAN X D, XIE X Q. An improved TextRank for Tibetan summarization [J]. Journal of Chinese Information Processing, 2020, 34(9): 36-43. | |
| 34 | GARG N, FAVRE B, RIEDHAMMER K, et al. ClusterRank: a graph based method for meeting summarization [C]// Proceedings of the 10th Annual Conference of the International Speech Communication Association. [S.l.]: International Speech Communication Association, 2009: 1499-1502. 10.21437/interspeech.2009-456 |
| 35 | PARVEEN D, STRUBE M. Integrating importance, non-redundancy and coherence in graph-based extractive summarization [C]// Proceedings of the 24th International Joint Conference on Artificial Intelligence. Palo Alto: AAAI Press, 2015: 1298-1304. 10.18653/v1/d15-1226 |
| 36 | THU H N T, NGOC D V T. Improve Bayesian network to generating Vietnamese sentence reduction [J]. IERI Procedia, 2014, 10: 190-195. 10.1016/j.ieri.2014.09.076 |
| 37 | CONROY J M, O’LEARY D P. Text summarization via hidden Markov models [C]// Proceedings of the 24th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval. New York: ACM, 2001: 406-407. 10.1145/383952.384042 |
| 38 | GILLICK D, FAVRE B. A scalable global model for summarization [C]// Proceedings of the 2009 NAACL HLT Workshop on Integer Linear Programming for Natural Language Processing. Stroudsburg: ACL, 2009: 10-18. 10.3115/1611638.1611640 |
| 39 | WAN X, CAO Z, WEI F, et al. Multi-document summarization via discriminative summary reranking [EB/OL]. (2015-07-08)[2023-04-01]. . |
| 40 | SHEN D, SUN J-T, LI H, et al. Document summarization using conditional random fields [C]// Proceedings of the 20th International Joint Conference on Artificial Intelligence. San Francisco: Morgan Kaufmann Publishers Inc., 2007: 2862-2867. |
| 41 | ITTI L, BALDI P. Bayesian surprise attracts human attention [J]. Vision Research, 2009, 49(10): 1295-1306. 10.1016/j.visres.2008.09.007 |
| 42 | LOUIS A. A Bayesian method to incorporate background knowledge during automatic text summarization [C]// Proceedings of the 52nd Annual Meeting of the Association for Computational Linguistics. Stroudsburg: ACL, 2014: 333-338. 10.3115/v1/p14-2055 |
| 43 | ABDI A, SHAMSUDDIN S M, HASAN S, et al. Machine learning-based multi-documents sentiment-oriented summarization using linguistic treatment [J]. Expert Systems with Application, 2018, 109: 66-85. 10.1016/j.eswa.2018.05.010 |
| 44 | SHEN Y, HE X, GAO J, et al. Learning semantic representations using convolutional neural networks for web search [C]// Proceedings of the 23rd International Conference on World Wide Web. New York: ACM, 2014: 373-374. 10.1145/2567948.2577348 |
| 45 | YIN W, PEI Y. Optimizing sentence modeling and selection for document summarization [C]// Proceedings of the 24th International Joint Conference on Artificial Intelligence. Palo Alto: AAAI Press, 2015: 1383-1389. |
| 46 | CAO Z, WEI F, LI S, et al. Learning summary prior representation for extractive summarization [C]// Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural Language Processing (Volume 2: Short Papers). Stroudsburg: ACL, 2015: 829-833. 10.3115/v1/p15-2136 |
| 47 | CAO Z, LI W, LI S, et al. AttSum: joint learning of focusing and summarization with neural attention [C]// Proceedings of the 26th International Conference on Computational Linguistics: Technical Papers. Stroudsburg: ACL, 2016: 547-556. 10.3115/v1/p15-2136 |
| 48 | CAO Z, LI W, LI S, et al. Improving multi-document summarization via text classification [C]// Proceedings of the 31st AAAI Conference on Artificial Intelligence. Palo Alto: AAAI Press, 2017: 3053-3059. 10.1609/aaai.v31i1.10955 |
| 49 | ZHANG Y, ER M J, ZHAO R, et al. Multiview convolutional neural networks for multi-document extractive summarization [J]. IEEE Transactions on Cybernetics, 2017, 47(10): 3230-3242. 10.1109/tcyb.2016.2628402 |
| 50 | NALLAPATI R, ZHAI F, ZHOU B. SummaRuNNer: a recurrent neural network based sequence model for extractive summarization of documents [C]// Proceedings of the 31st AAAI Conference on Artificial Intelligence. Palo Alto: AAAI Press, 2017: 3075-3081. 10.1609/aaai.v31i1.10958 |
| 51 | FILIPPOVA K, ALFONSECA E, COLMENARES C A, et al. Sentence compression by deletion with LSTMs [C]// Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing. Stroudsburg: ACL, 2015: 360-368. 10.18653/v1/d15-1042 |
| 52 | REN P, CHEN Z, REN Z, et al. Leveraging contextual sentence relations for extractive summarization using a neural attention model [C]// Proceedings of the 40th International ACM SIGIR Conference on Research and Development in Information Retrieval. New York: ACM, 2017: 95-104. 10.1145/3077136.3080792 |
| 53 | CHENG J, LAPATA M. Neural summarization by extracting sentences and words [C]// Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics. Stroudsburg: ACL, 2016: 484-494. 10.18653/v1/p16-1046 |
| 54 | SINGH A K, GUPTA M, VARMA V. Unity in diversity: learning distributed heterogeneous sentence representation for extractive summarization [C]// Proceedings of the 2018 AAAI Conference on Artificial Intelligence. Palo Alto: AAAI Press, 2018: 5473-5480. 10.1609/aaai.v32i1.11994 |
| 55 | WANG D, LIU P, ZHENG Y, et al. Heterogeneous graph neural networks for extractive document summarization [C]// Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics. Stroudsburg: ACL, 2020: 6209-6219. 10.18653/v1/2020.acl-main.553 |
| 56 | LIU Y. Fine-tune BERT for extractive summarization [EB/OL]. (2019-09-05)[2023-04-01]. . |
| 57 | XU J, GAN Z, CHENG Y, et al. Discourse-aware neural extractive text summarization [C]// Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics. Stroudsburg: ACL, 2020: 5021-5031. 10.18653/v1/2020.acl-main.451 |
| 58 | LIU Y, LAPATA M. Text summarization with pre-trained Encoders [C]// Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing. Stroudsburg: ACL, 2019: 3730-3740. 10.18653/v1/d19-1387 |
| 59 | BELTAGY I, LO K, COHAN A. SciBERT: a pretrained language model for scientific text [C]// Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing. Stroudsburg: ACL, 2019: 3615-3620. 10.18653/v1/d19-1371 |
| 60 | LEWIS M, LIU Y H, GOYAL N,et al. BART: denoising sequence-to-sequence pre-training for natural language generation,translation,and comprehension [C]// Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics. Stroudsburg: ACL, 2020: 7871-7880. 10.18653/v1/2020.acl-main.703 |
| 61 | BELTAGY I, PETERS M E, COHAN A. Longformer: the long-document transformer [EB/OL]. (2020-12-02)[2023-04-01]. . |
| 62 | ZHANG J, ZHAO Y, SALAH M, et al. PEGASUS: pre-training with extracted gap-sentences for abstractive summarization [EB/OL]. (2020-07-10)[2023-04-01]. . |
| 63 | RUAN Q, OSTENDORFF M, REHM G. HiStruct+: improving extractive text summarization with hierarchical structure information [C]// Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics. Stroudsburg: ACL, 2022: 1292-1308. 10.18653/v1/2022.findings-acl.102 |
| 64 | PUGOY R A, H-Y KAO. Unsupervised extractive summarization-based representations for accurate and explainable collaborative filtering [C]// Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing. Stroudsburg: ACL, 2021: 2981-2990. 10.18653/v1/2021.acl-long.232 |
| 65 | XIAO W, BELTAGY I, CARENINI G, et al. PRIMERA: pyramid-based masked sentence pre-training for multi-document summarization [C]// Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics. Stroudsburg: ACL, 2022: 5245-5263. 10.18653/v1/2022.acl-long.360 |
| 66 | MORO G, RAGAZZI L, VALGIMIGLI L, et al. Discriminative marginalized probabilistic neural method for multi-document summarization of medical literature [C]// Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics. Stroudsburg: ACL, 2022: 180-189. 10.18653/v1/2022.acl-long.15 |
| 67 | ZHAO C, HUANG T, CHOWDHURY S B R, et al. Read top news first: a document reordering approach for multi-document news summarization [C]// Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics. Stroudsburg: ACL, 2022: 613-621. 10.18653/v1/2022.findings-acl.51 |
| 68 | ZHANG Z, ELFARDY H, DREYER M. Enhancing multi-document summarization with cross-document graph-based information extraction [C]// Proceedings of the 17th Conference of the European Chapter of the Association for Computational Linguistics. Stroudsburg: ACL, 2023: 1696-1707. 10.18653/v1/2023.eacl-main.124 |
| 69 | GRAFF D, CIERI C. English gigaword — linguistic data consortium [EB/OL]. (2003-01-28)[2023-04-01]. . |
| 70 | HU B, CHEN Q, ZHU F. LCSTS: a large scale Chinese short text summarization dataset [C]// Proceeding of the 2015 Conference on Empirical Methods in Natural Language Processing. Stroudsburg: ACL, 2015: 1967-1972. 10.18653/v1/d15-1229 |
| 71 | NALLAPATI R, ZHOU B, DOS SANTOS C, et al. Abstractive text summarization using seq-to-seq RNNs and beyond [C]// Proceedings of the 20th SIGNLL Conference on Computational Natural Language Learning. Stroudsburg: ACL, 2016: 280-290. 10.18653/v1/k16-1028 |
| 72 | DURRETT G, BERG-KIRKPATRICK T, KLEIN D. Learning-based single-document summarization with compression and anaphoricity constraints [C]// Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Stroudsburg: ACL, 2016: 1998-2008. 10.18653/v1/p16-1188 |
| 73 | GRUSKY M, NAAMAN M, ARTZI Y. Newsroom: a dataset of 1.3 million summaries with diverse extractive strategies [C]// Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. Stroudsburg: ACL, 2018: 708-719. 10.18653/v1/n18-1065 |
| 74 | KAMEZAWA H, NISHIDA N, SHIMIZU N, et al. RNSum: a large-scale dataset for automatic release note generation via commit logs summarization [C]// Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics. Stroudsburg: ACL, 2022: 8718-8728. 10.18653/v1/2022.acl-long.597 |
| 75 | ZHONG M, YIN D, YU T, et al. QMSum: a new benchmark for query-based multi-domain meeting summarization [C]// Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics. Stroudsburg: ACL, 2021: 5905-5921. 10.18653/v1/2021.naacl-main.472 |
| 76 | ZHANG Y, NI A, MAO Z, et al. SUMM N : a multi-stage summarization framework for long input dialogues and documents [C]// Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Stroudsburg: ACL, 2022: 1592-1604. 10.18653/v1/2022.acl-long.112 |
| 77 | FABBRI A, LI I, SHE T, et al. Multi-News: a large-scale multi-document summarization dataset and abstractive hierarchical model [C]// Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics. Stroudsburg: ACL, 2019: 1074-1084. 10.18653/v1/p19-1102 |
| 78 | NARAYAN S, COHEN S B, LAPATA M. Don’t give me the details, just the summary! Topic-aware convolutional neural networks for extreme summarization [C]// Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing. Stroudsburg: ACL, 2018: 1797-1807. 10.18653/v1/d18-1206 |
| 79 | 闫晓东,王羿钦,黄硕,等.藏文多文本摘要数据集[J]. 中国科学数据(中英文网络版),2022, 7(2): 39-45. 10.11922/11-6035.csd.2021.0098.zh |
| YAN X D, WANG Y Q, HUANG S, et al. A dataset of Tibetan text summarization [J]. China Scientific Data, 2022, 7(2): 39-45. 10.11922/11-6035.csd.2021.0098.zh | |
| 80 | GAO Y, ZHAO W, EGER S. SUPERT: towards new frontiers in unsupervised evaluation metrics for multi-document summarization [C]// Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics. Stroudsburg: ACL, 2020: 1347-1354. 10.18653/v1/2020.acl-main.124 |
| 81 | NENKOVA A, PASSONNEAU R. Evaluating content selection in summarization: the pyramid method [C]// Proceedings of the 2004 Human Language Technology Conference of the North American Chapter of the Association for Computational Linguistics. Stroudsburg: ACL, 2004: 145-152. |
| 82 | PAPINENI K, ROUKOS S, WARD T, et al. BLEU: a method for automatic evaluation of machine translation [C]// Proceedings of the 40th Annual Meeting of the Association for Computational Linguistics. Stroudsburg: ACL, 2002: 311-318. 10.3115/1073083.1073135 |
| 83 | LIN C-Y. ROUGE: a package for automatic evaluation of summaries [C]// Proceedings of the 2004 Workshop on Text Summarization Branches Out. Stroudsburg: ACL, 2004: 74-81. |
| [1] | Tingjie TANG, Jiajin HUANG, Jin QIN. Session-based recommendation with graph auxiliary learning [J]. Journal of Computer Applications, 2024, 44(9): 2711-2718. |
| [2] | Jieru JIA, Jianchao YANG, Shuorui ZHANG, Tao YAN, Bin CHEN. Unsupervised person re-identification based on self-distilled vision Transformer [J]. Journal of Computer Applications, 2024, 44(9): 2893-2902. |
| [3] | Yingjun ZHANG, Niuniu LI, Binhong XIE, Rui ZHANG, Wangdong LU. Semi-supervised object detection framework guided by curriculum learning [J]. Journal of Computer Applications, 2024, 44(8): 2326-2333. |
| [4] | Yan ZHOU, Yang LI. Rectified cross pseudo supervision method with attention mechanism for stroke lesion segmentation [J]. Journal of Computer Applications, 2024, 44(6): 1942-1948. |
| [5] | Jiong WANG, Taotao TANG, Caiyan JIA. PAGCL: positive augmentation graph contrastive learning recommendation method without negative sampling [J]. Journal of Computer Applications, 2024, 44(5): 1485-1492. |
| [6] | Zimeng ZHU, Zhixin LI, Zhan HUAN, Ying CHEN, Jiuzhen LIANG. Weakly supervised video anomaly detection based on triplet-centered guidance [J]. Journal of Computer Applications, 2024, 44(5): 1452-1457. |
| [7] | Guijin HAN, Xinyuan ZHANG, Wentao ZHANG, Ya HUANG. Self-supervised image registration algorithm based on multi-feature fusion [J]. Journal of Computer Applications, 2024, 44(5): 1597-1604. |
| [8] | Rong HUANG, Junjie SONG, Shubo ZHOU, Hao LIU. Image aesthetic quality evaluation method based on self-supervised vision Transformer [J]. Journal of Computer Applications, 2024, 44(4): 1269-1276. |
| [9] | Rui JIANG, Wei LIU, Cheng CHEN, Tao LU. Asymmetric unsupervised end-to-end image deraining network [J]. Journal of Computer Applications, 2024, 44(3): 922-930. |
| [10] | Nengbing HU, Biao CAI, Xu LI, Danhua CAO. Graph classification method based on graph pooling contrast learning [J]. Journal of Computer Applications, 2024, 44(11): 3327-3334. |
| [11] | Shuaihua ZHANG, Shufen ZHANG, Mingchuan ZHOU, Chao XU, Xuebin CHEN. Malicious traffic detection model based on semi-supervised federated learning [J]. Journal of Computer Applications, 2024, 44(11): 3487-3494. |
| [12] | Pei ZHAO, Yan QIAO, Rongyao HU, Xinyu YUAN, Minyue LI, Benchu ZHANG. Multivariate time series anomaly detection based on multi-domain feature extraction [J]. Journal of Computer Applications, 2024, 44(11): 3419-3426. |
| [13] | Shengyou ZHENG, Yanxiang CHEN, Zuxing ZHAO, Haiyang LIU. Construction and benchmark detection of multimodal partial forgery dataset [J]. Journal of Computer Applications, 2024, 44(10): 3134-3140. |
| [14] | Jian LIU, Chenchen YOU, Jinming CAO, Qiong ZENG, Changhe TU. Construction and application of 3D dataset of human grasping objects [J]. Journal of Computer Applications, 2024, 44(1): 278-284. |
| [15] | Yuning ZHANG, Abudukelimu ABULIZI, Tisheng MEI, Chun XU, Maierdana MAIMAITIREYIMU, Halidanmu ABUDUKELIMU, Yutao HOU. Anomaly detection method for skeletal X-ray images based on self-supervised feature extraction [J]. Journal of Computer Applications, 2024, 44(1): 175-181. |
| Viewed | ||||||
|
Full text |
|
|||||
|
Abstract |
|
|||||