


Journal of Computer Applications ›› 2025, Vol. 45 ›› Issue (8): 2600-2611.DOI: 10.11772/j.issn.1001-9081.2024070911
• Cyber security • Previous Articles
Yan YAN, Feifei LI( ), Yaqin LYU, Tao FENG
), Yaqin LYU, Tao FENG
Received:2024-06-30
Revised:2024-10-14
Accepted:2024-10-16
Online:2024-11-19
Published:2025-08-10
Contact:
Feifei LI
About author:YAN Yan, born in 1980, Ph. D., professor. Her research interests include privacy protection, information security.Supported by:
晏燕, 李飞飞(), 吕雅琴, 冯涛
通讯作者:
李飞飞
作者简介:晏燕(1980—),女,甘肃兰州人,教授,博士,CCF高级会员,主要研究方向:隐私保护、信息安全基金资助:CLC Number:
Yan YAN, Feifei LI, Yaqin LYU, Tao FENG. Secure and efficient frequency estimation method based on shuffled differential privacy[J]. Journal of Computer Applications, 2025, 45(8): 2600-2611.
晏燕, 李飞飞, 吕雅琴, 冯涛. 安全高效的混洗差分隐私频率估计方法[J]. 《计算机应用》唯一官方网站, 2025, 45(8): 2600-2611.
Add to citation manager EndNote|Ris|BibTeX
URL: https://www.joca.cn/EN/10.11772/j.issn.1001-9081.2024070911
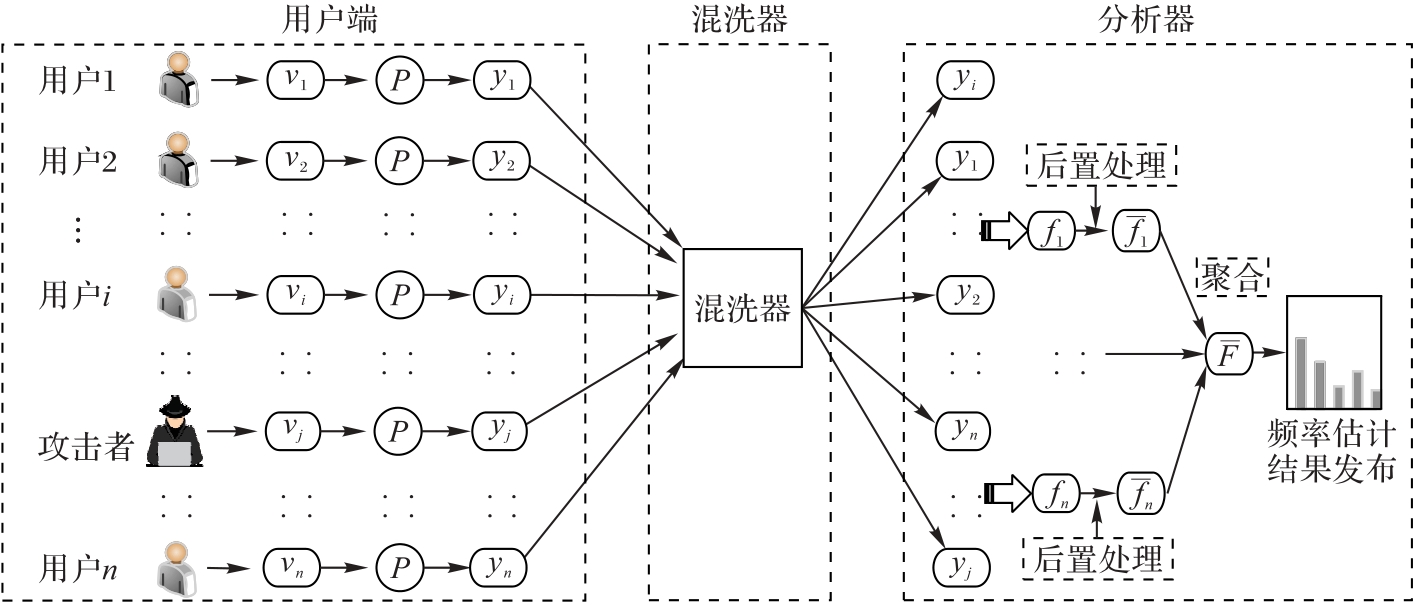
Fig. 1 Privacy protection framework for frequency estimation based on shuffled differential privacy
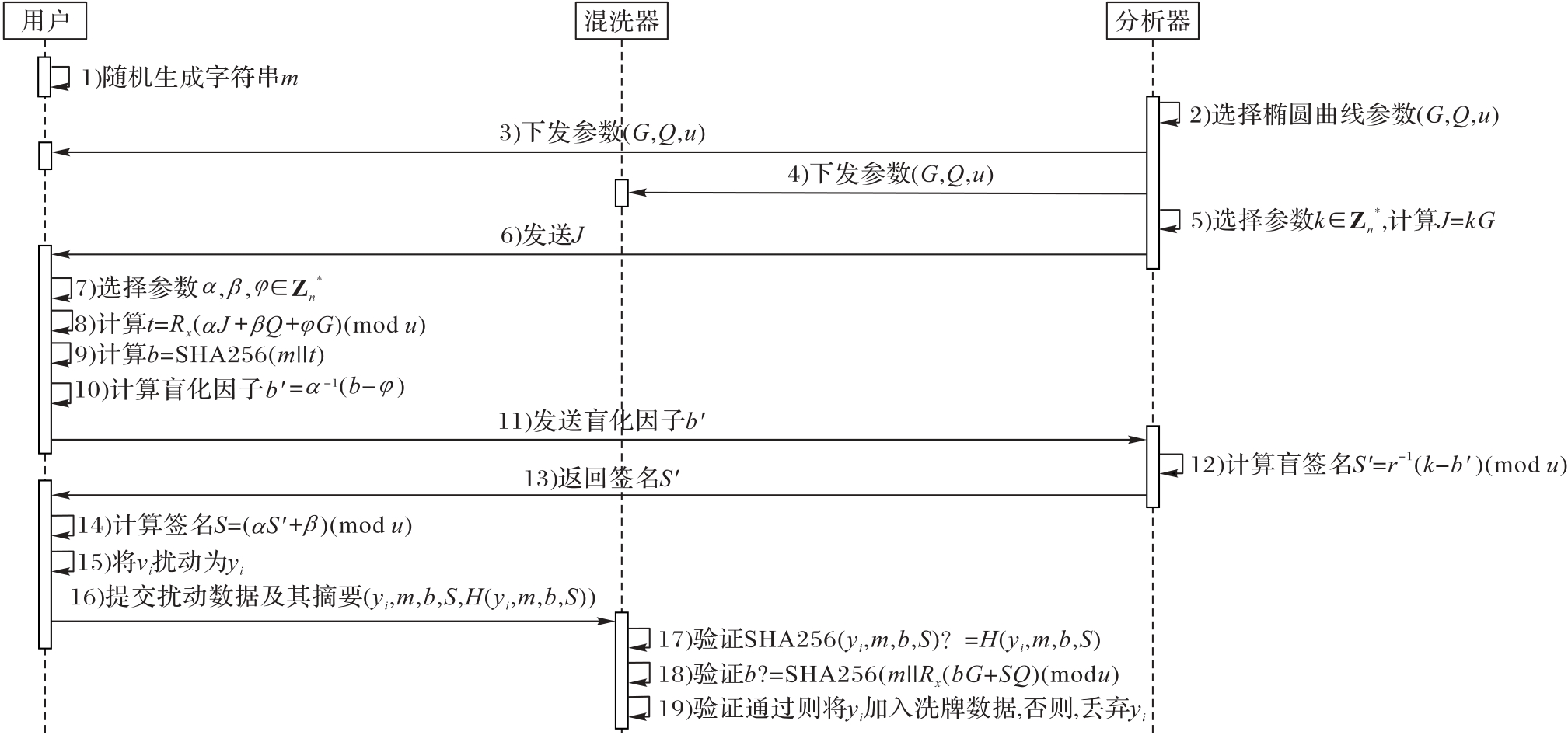
Fig. 2 Flow of SDPBSA
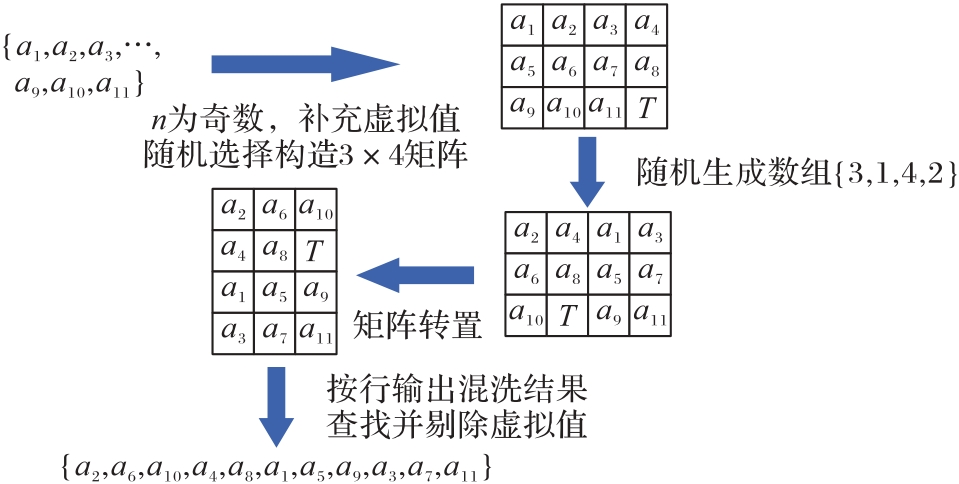
Fig. 3 Example diagram of MCRT method
| 数据集 | 用户数 | 用户数据最大取值 |
|---|---|---|
| Normal | 600 000 | 600 |
| Zipf | 600 000 | 600 |
| IPUMS | 602 325 | 915 |
| Kosarak | 990 002 | 41 270 |
Tab. 1 Experimental dataset information
| 数据集 | 用户数 | 用户数据最大取值 |
|---|---|---|
| Normal | 600 000 | 600 |
| Zipf | 600 000 | 600 |
| IPUMS | 602 325 | 915 |
| Kosarak | 990 002 | 41 270 |
| 洗牌方法 | 时间复杂度 |
|---|---|
| Fisher-Yates | |
| ORShuffle | |
| MRS | |
| MCRT |
Tab. 2 Time complexity of various shuffling methods
| 洗牌方法 | 时间复杂度 |
|---|---|
| Fisher-Yates | |
| ORShuffle | |
| MRS | |
| MCRT |
| 洗牌方法 | Normal | Zipf | IPUMS | Kosarak |
|---|---|---|---|---|
| Fisher-Yates | 55.599 681 | 56.246 354 | 65.479 238 | 539.611 728 |
| ORShuffle | 38.012 453 | 37.446 202 | 47.264 105 | 76.035 698 |
| MRS | 10.392 418 | 9.536 152 | 19.193 321 | 19.062 021 |
| MCRT | 0.445 108 | 0.466 110 | 0.516 073 | 1.508 853 |
Tab. 3 Comparison of running time of various shuffling methods
| 洗牌方法 | Normal | Zipf | IPUMS | Kosarak |
|---|---|---|---|---|
| Fisher-Yates | 55.599 681 | 56.246 354 | 65.479 238 | 539.611 728 |
| ORShuffle | 38.012 453 | 37.446 202 | 47.264 105 | 76.035 698 |
| MRS | 10.392 418 | 9.536 152 | 19.193 321 | 19.062 021 |
| MCRT | 0.445 108 | 0.466 110 | 0.516 073 | 1.508 853 |
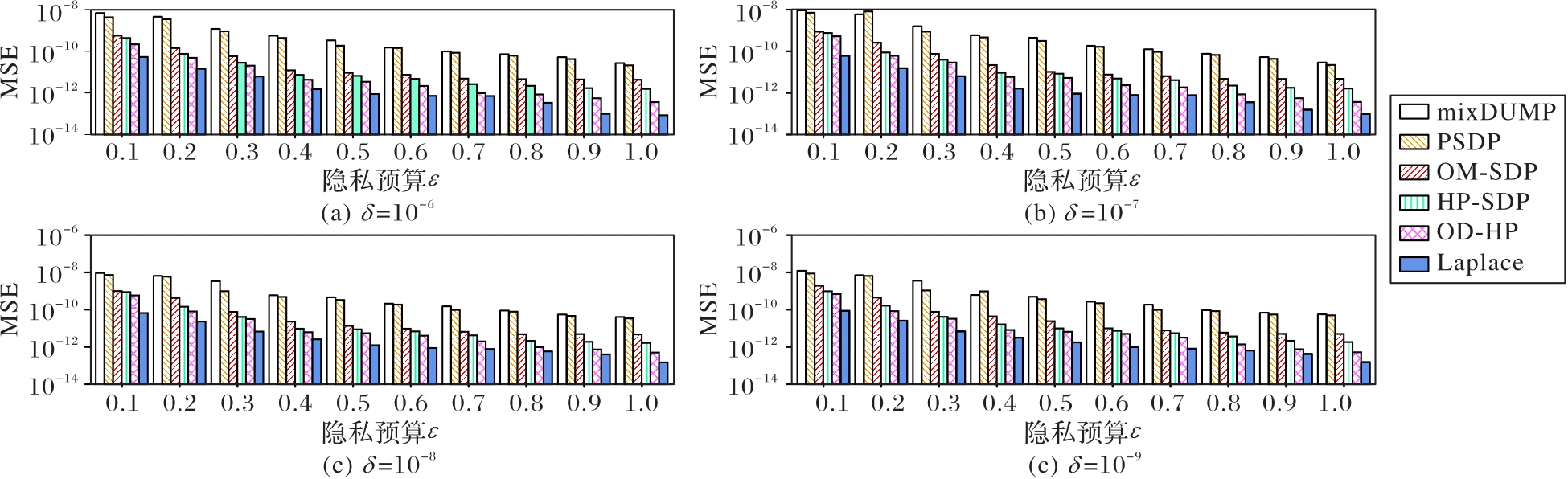
Fig. 4 MSE comparison of different methods on Normal dataset

Fig. 5 MSE comparison of different methods on Zipf dataset

Fig. 6 MSE comparison of different methods on IPUMS dataset
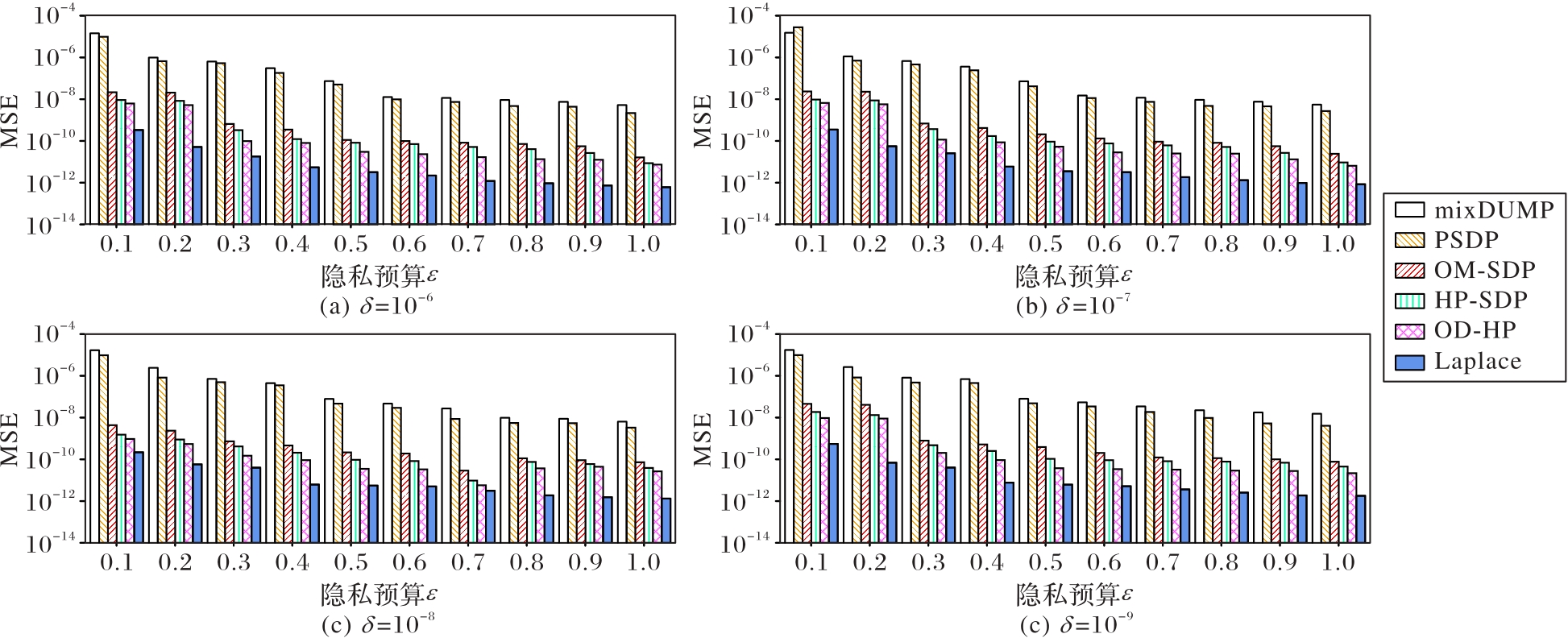
Fig. 7 MSE comparison of different methods on Kosarak dataset
| 方法 | 恶意数据比例/% | 隐私预算 | ||||
|---|---|---|---|---|---|---|
| mixDUMP | 10 | |||||
| 20 | ||||||
| 40 | ||||||
| PSDP | 10 | |||||
| 20 | ||||||
| 40 | ||||||
| HP-SDP | 10 | |||||
| 20 | ||||||
| 40 | ||||||
| OD-HP | 10 | |||||
| 20 | ||||||
| 40 | ||||||
| Laplace | 10 | |||||
| 20 | ||||||
| 40 | ||||||
| SM-SDP | 10 | |||||
| 20 | ||||||
| 40 | ||||||
Tab. 4 MSE comparison of different methods on Normal dataset when malicious data exist
| 方法 | 恶意数据比例/% | 隐私预算 | ||||
|---|---|---|---|---|---|---|
| mixDUMP | 10 | |||||
| 20 | ||||||
| 40 | ||||||
| PSDP | 10 | |||||
| 20 | ||||||
| 40 | ||||||
| HP-SDP | 10 | |||||
| 20 | ||||||
| 40 | ||||||
| OD-HP | 10 | |||||
| 20 | ||||||
| 40 | ||||||
| Laplace | 10 | |||||
| 20 | ||||||
| 40 | ||||||
| SM-SDP | 10 | |||||
| 20 | ||||||
| 40 | ||||||
| 方法 | 恶意数据比例/% | 隐私预算 | ||||
|---|---|---|---|---|---|---|
| mixDUMP | 10 | |||||
| 20 | ||||||
| 40 | ||||||
| PSDP | 10 | |||||
| 20 | ||||||
| 40 | ||||||
| HP-SDP | 10 | |||||
| 20 | ||||||
| 40 | ||||||
| OD-HP | 10 | |||||
| 20 | ||||||
| 40 | ||||||
| Laplace | 10 | |||||
| 20 | ||||||
| 40 | ||||||
| SM-SDP | 10 | |||||
| 20 | ||||||
| 40 | ||||||
Tab. 5 MSE comparison of different methods on Zipf dataset when malicious data exist
| 方法 | 恶意数据比例/% | 隐私预算 | ||||
|---|---|---|---|---|---|---|
| mixDUMP | 10 | |||||
| 20 | ||||||
| 40 | ||||||
| PSDP | 10 | |||||
| 20 | ||||||
| 40 | ||||||
| HP-SDP | 10 | |||||
| 20 | ||||||
| 40 | ||||||
| OD-HP | 10 | |||||
| 20 | ||||||
| 40 | ||||||
| Laplace | 10 | |||||
| 20 | ||||||
| 40 | ||||||
| SM-SDP | 10 | |||||
| 20 | ||||||
| 40 | ||||||
| 方法 | 恶意数据比例/% | 隐私预算 | ||||
|---|---|---|---|---|---|---|
| mixDUMP | 10 | |||||
| 20 | ||||||
| 40 | ||||||
| PSDP | 10 | |||||
| 20 | ||||||
| 40 | ||||||
| HP-SDP | 10 | |||||
| 20 | ||||||
| 40 | ||||||
| OD-HP | 10 | |||||
| 20 | ||||||
| 40 | ||||||
| Laplace | 10 | |||||
| 20 | ||||||
| 40 | ||||||
| SM-SDP | 10 | |||||
| 20 | ||||||
| 40 | ||||||
Tab. 6 MSE comparison of different methods on IPUMS dataset when malicious data exist
| 方法 | 恶意数据比例/% | 隐私预算 | ||||
|---|---|---|---|---|---|---|
| mixDUMP | 10 | |||||
| 20 | ||||||
| 40 | ||||||
| PSDP | 10 | |||||
| 20 | ||||||
| 40 | ||||||
| HP-SDP | 10 | |||||
| 20 | ||||||
| 40 | ||||||
| OD-HP | 10 | |||||
| 20 | ||||||
| 40 | ||||||
| Laplace | 10 | |||||
| 20 | ||||||
| 40 | ||||||
| SM-SDP | 10 | |||||
| 20 | ||||||
| 40 | ||||||
| 方法 | 恶意数据比例/% | 隐私预算 | ||||
|---|---|---|---|---|---|---|
| mixDUMP | 10 | |||||
| 20 | ||||||
| 40 | ||||||
| PSDP | 10 | |||||
| 20 | ||||||
| 40 | ||||||
| HP-SDP | 10 | |||||
| 20 | ||||||
| 40 | ||||||
| OD-HP | 10 | |||||
| 20 | ||||||
| 40 | ||||||
| Laplace | 10 | |||||
| 20 | ||||||
| 40 | ||||||
| SM-SDP | 10 | |||||
| 20 | ||||||
| 40 | ||||||
Tab. 7 MSE comparison of different methods on Kosarak dataset when malicious data exist
| 方法 | 恶意数据比例/% | 隐私预算 | ||||
|---|---|---|---|---|---|---|
| mixDUMP | 10 | |||||
| 20 | ||||||
| 40 | ||||||
| PSDP | 10 | |||||
| 20 | ||||||
| 40 | ||||||
| HP-SDP | 10 | |||||
| 20 | ||||||
| 40 | ||||||
| OD-HP | 10 | |||||
| 20 | ||||||
| 40 | ||||||
| Laplace | 10 | |||||
| 20 | ||||||
| 40 | ||||||
| SM-SDP | 10 | |||||
| 20 | ||||||
| 40 | ||||||
| [1] | 徐雅鑫.面向数据收集与分析的混洗差分隐私方法研究[D].郑州:河南财经政法大学,2022. |
| XU Y X. Research on shuffled differential privacy method for data collection and analysis [D]. Zhengzhou: Henan University of Economics and Law, 2022. | |
| [2] | 刘艺菲,王宁,王志刚,等.混洗差分隐私下的多维类别数据的收集与分析[J].软件学报,2022, 33(3): 1093-1110. |
| LIU Y F, WANG N, WANG Z G, et al. Collecting and analyzing multidimensional categorical data under shuffled differential privacy [J]. Journal of Software, 2022, 33(3): 1093-1110. | |
| [3] | PAUL S, MISHRA S. ARA: aggregated RAPPOR and analysis for centralized differential privacy [J]. SN Computer Science, 2020, 1: No.22. |
| [4] | 张可铧.基于差分隐私保护的数据发布与挖掘方法[D].南京:南京邮电大学,2021. |
| ZHANG K H. Research on data publishing and mining method based on differential privacy [D]. Nanjing: Nanjing University of Posts and Telecommunications, 2021. | |
| [5] | 王超迁.基于差分隐私的直方图发布技术研究[D].南京:东南大学,2021. |
| WANG C Q. Research on histogram publishing technology based on differential privacy [D]. Nanjing: Southeast University, 2021. | |
| [6] | WANG T, ZHANG X, FENG J, et al. A comprehensive survey on local differential privacy toward data statistics and analysis [J]. Sensors, 2020, 20(24): No.7030. |
| [7] | VARMA G. Local hashing and fake data for privacy-aware frequency estimation [C]// Proceedings of the 17th International Conference on Ubiquitous Information Management and Communication. Piscataway: IEEE, 2023: 1-4. |
| [8] | YANG M, GUO T, ZHU T, et al. Local differential privacy and its applications: a comprehensive survey [J]. Computer Standards and Interfaces, 2023: No.103827. |
| [9] | BITTAU A, ERLINGSSON Ú, MANIATIS P, et al. Prochlo: strong privacy for analytics in the crowd [C]// Proceedings of the 26th Symposium on Operating Systems Principles. New York: ACM, 2017: 441-459. |
| [10] | ERLINGSSON Ú, FELDMAN V, MIRONOV I, et al. Amplification by shuffling: from local to central differential privacy via anonymity [C]// Proceedings of the 30th Annual ACM-SIAM Symposium on Discrete Algorithms. Philadelphia: SIAM, 2019: 2468-2479. |
| [11] | CHEU A, SMITH A, ULLMAN J, et al. Distributed differential privacy via shuffling [C]// Proceedings of the 2019 Annual International Conference on the Theory and Applications of Cryptographic Techniques, LNCS 11476. Cham: Springer, 2019: 375-403. |
| [12] | LUO Q, WANG Y, YI K. Frequency estimation in the shuffle model with almost a single message [C]// Proceedings of the 2022 ACM SIGSAC Conference on Computer and Communications Security. New York: ACM, 2022: 2219-2232. |
| [13] | GHAZI B, GOLOWICH N, KUMAR R, et al. On the power of multiple anonymous messages: frequency estimation and selection in the shuffle model of differential privacy [C]// Proceedings of the 2021 Annual International Conference on the Theory and Applications of Cryptographic Techniques, LNCS 12698. Cham: Springer, 2021: 463-488. |
| [14] | SCOTT M, CORMODE G, MAPLE C. Applying the shuffle model of differential privacy to vector aggregation [C]// Proceedings of the 2021 British International Conference on Databases. Aachen: CEUR-WS.org, 2022: 50-59. |
| [15] | BALLE B, BELL J, GASCÓN A, et al. The privacy blanket of the shuffle model [C]// Proceedings of the 2019 Annual International Cryptology Conference, LNCS 11693. Berlin: Springer, 2019: 638-667. |
| [16] | LI X, LIU W, CHEN Z, et al. DUMP: a dummy-point-based framework for histogram estimation in shuffle model [EB/OL]. [2024-06-22]. . |
| [17] | BALCER V, CHEU A. Separating local & shuffled differential privacy via histograms [EB/OL]. [2024-06-22]. . |
| [18] | WANG T, XU M, DING B, et al. MURS: practical and robust privacy amplification with multi-party differential privacy [C]// Proceedings of the 2020 Annual Network and Distributed Systems Security Symposium — Posters. Reston, VA: Internet Society, 2020: 1-3. |
| [19] | CHEN W N, SONG D, ÖZGÜR A, et al. Privacy amplification via compression: achieving the optimal privacy-accuracy-communication trade-off in distributed mean estimation [C]// Proceedings of the 37th International Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2023: 69202-69227. |
| [20] | ERLINGSSON Ú, FELDMAN V, MIRONOV I, et al. Encode, shuffle, analyze privacy revisited: formalizations and empirical evaluation [EB/OL]. [2024-06-20]. . |
| [21] | 曹来成,陈丽.基于OLH和虚拟数据的SDP直方图发布算法[J].计算机应用研究,2024, 41(12): 3829-3833. |
| CAO L C, CHEN L. SDP histogram publishing algorithm based on OLH and dummy points [J]. Application Research of Computers, 2024, 41(12): 3829-3833. | |
| [22] | WANG T, DING B, XU M, et al. Improving utility and security of the shuffler-based differential privacy [J]. Proceedings of the VLDB Endowment, 2020, 13(13): 3545-3558. |
| [23] | SENGUPTA P, PAUL S, MISHRA S. BUDS: balancing utility and differential privacy by shuffling [C]// Proceedings of the 11th International Conference on Computing, Communication and Networking Technologies. Piscataway: IEEE, 2020: 1-7. |
| [24] | LIEW S P, TAKAHASHI T, TAKAGI S, et al. Network shuffling: privacy amplification via random walks [C]// Proceedings of the 2022 International Conference on Management of Data. New York: ACM, 2022: 773-787. |
| [25] | 张啸剑,徐雅鑫,夏庆荣.基于混洗差分隐私的直方图发布方法[J].软件学报,2022, 33(6): 2348-2363. |
| ZHANG X J, XU Y X, XIA Q R. Histogram publication under shuffled differential privacy [J]. Journal of Software, 2022, 33(6): 2348-2363. | |
| [26] | SASY S, JOHNSON A, GOLDBERG I. Fast fully oblivious compaction and shuffling [C]// Proceedings of the 2022 ACM SIGSAC Conference on Computer and Communications Security. New York: ACM, 2022: 2565-2579. |
| [27] | GHAZI B, KAMATH P, KUMAR R, et al. Anonymized histograms in intermediate privacy models [C]// Proceedings of the 36th International Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2022: 8456-8468. |
| [28] | BISWAS S, JUNG K, PALAMIDESSI C. Tight differential privacy guarantees for the shuffle model with k-randomized response [C]// Proceedings of the 2023 International Symposium on Foundations and Practice of Security, LNCS 14551. Cham: Springer, 2024: 440-458. |
| [29] | YANG R, YANG H, FAN J, et al. Personalized differential privacy in the shuffle model [C]// Proceedings of the 2023 International Conference on Artificial Intelligence Security and Privacy, LNCS 14509. Singapore: Springer, 2024: 468-482. |
| [30] | WANG T, BLOCKI J, LI N, et al. Locally differentially private protocols for frequency estimation [C]// Proceedings of the 26th USENIX Security Symposium. Berkeley: USENIX Association, 2017: 729-745. |
| [31] | 万丽,李方伟,闫少军.基于改进椭圆曲线数字签名的盲签名[J].计算机应用研究,2011, 28(3): 1152-1154. |
| WAN L, LI F W, YAN S J. Blind signature scheme based on improved elliptic curve digital signature algorithm [J]. Application Research of Computers, 2011, 28(3): 1152-1154. | |
| [32] | FLOOD S, KING M, RODGERS R, et al. Integrated public use microdata series: version 9.0 [DS/OL]. [2024-06-22]. . |
| [33] | BODON B. Frequent itemset mining dataset repository — Kosarak dataset [DS/OL]. [2024-06-22]. . |
| [34] | DWORK C. Differential privacy [C]// Proceedings of the 2006 International Colloquium on Automata, Languages, and Programming, LNCS 4052. Berlin: Springer, 2006: 1-12. |
| [1] | Jintao SU, Lina GE, Liguang XIAO, Jing ZOU, Zhe WANG. Detection and defense scheme for backdoor attacks in federated learning [J]. Journal of Computer Applications, 2025, 45(8): 2399-2408. |
| [2] | Lina GE, Mingyu WANG, Lei TIAN. Review of research on efficiency of federated learning [J]. Journal of Computer Applications, 2025, 45(8): 2387-2398. |
| [3] | Gaimei GAO, Miaolian DU, Chunxia LIU, Yuli YANG, Weichao DANG, Guoxia DI. Privacy protection method for consortium blockchain based on SM2 linkable ring signature [J]. Journal of Computer Applications, 2025, 45(5): 1564-1572. |
| [4] | Baoyin WANG, Hongmei XUE, Qilie LIU, Tao GUO. Privacy-preserving random consensus asset cross-chain scheme [J]. Journal of Computer Applications, 2025, 45(2): 497-505. |
| [5] | Xuebin CHEN, Zhiqiang REN, Hongyang ZHANG. Review on security threats and defense measures in federated learning [J]. Journal of Computer Applications, 2024, 44(6): 1663-1672. |
| [6] | Peiqian LIU, Shuilian WANG, Zihao SHEN, Hui WANG. Location privacy protection algorithm based on trajectory perturbation and road network matching [J]. Journal of Computer Applications, 2024, 44(5): 1546-1554. |
| [7] | Gaimei GAO, Jin ZHANG, Chunxia LIU, Weichao DANG, Shangwang BAI. Privacy protection scheme for crowdsourced testing tasks based on blockchain and CP-ABE policy hiding [J]. Journal of Computer Applications, 2024, 44(3): 811-818. |
| [8] | Haifeng MA, Yuxia LI, Qingshui XUE, Jiahai YANG, Yongfu GAO. Attribute-based encryption scheme for blockchain privacy protection [J]. Journal of Computer Applications, 2024, 44(2): 485-489. |
| [9] | Zhenhao ZHAO, Shibin ZHANG, Wunan WAN, Jinquan ZHANG, zhi QIN. Delegated proof of stake consensus algorithm based on reputation value and strong blind signature algorithm [J]. Journal of Computer Applications, 2024, 44(12): 3717-3722. |
| [10] | Yiting WANG, Wunan WAN, Shibin ZHANG, Jinquan ZHANG, Zhi QIN. Linkable ring signature scheme based on SM9 algorithm [J]. Journal of Computer Applications, 2024, 44(12): 3709-3716. |
| [11] | Jing LIANG, Wunan WAN, Shibin ZHANG, Jinquan ZHANG, Zhi QIN. Traceability storage model of charity system oriented to master-slave chain [J]. Journal of Computer Applications, 2024, 44(12): 3751-3758. |
| [12] | Rui GAO, Xuebin CHEN, Zucuan ZHANG. Dynamic social network privacy publishing method for partial graph updating [J]. Journal of Computer Applications, 2024, 44(12): 3831-3838. |
| [13] | Miao JIA, Zhongyuan YAO, Weihua ZHU, Tingting GAO, Xueming SI, Xiang DENG. Progress and prospect of zero-knowledge proof enabling blockchain [J]. Journal of Computer Applications, 2024, 44(12): 3669-3677. |
| [14] | Peng FANG, Fan ZHAO, Baoquan WANG, Yi WANG, Tonghai JIANG. Development, technologies and applications of blockchain 3.0 [J]. Journal of Computer Applications, 2024, 44(12): 3647-3657. |
| [15] | Yifan WANG, Shaofu LIN, Yunjiang LI. Highway free-flow tolling method based on blockchain and zero-knowledge proof [J]. Journal of Computer Applications, 2024, 44(12): 3741-3750. |
| Viewed | ||||||
|
Full text |
|
|||||
|
Abstract |
|
|||||