


Journal of Computer Applications ›› 2025, Vol. 45 ›› Issue (12): 3771-3778.DOI: 10.11772/j.issn.1001-9081.2024111694
• Artificial intelligence • Previous Articles Next Articles
Yuqi ZHANG1,2,3,4, Ying SHA1,2,3,4( )
)
Received:2024-12-02
Revised:2025-04-16
Accepted:2025-04-23
Online:2025-04-27
Published:2025-12-10
Contact:
Ying SHA
About author:ZHANG Yuqi, born in 1998, M. S. candidate. His research interests include natural language processing.
Supported by:
张瑜琦1,2,3,4, 沙灜1,2,3,4()
通讯作者:
沙灜
作者简介:张瑜琦(1998—),男,山西太原人,硕士研究生,主要研究方向:自然语言处理基金资助:CLC Number:
Yuqi ZHANG, Ying SHA. Chinese semantic error recognition model based on hierarchical information enhancement[J]. Journal of Computer Applications, 2025, 45(12): 3771-3778.
张瑜琦, 沙灜. 基于层次信息增强的中文语义错误识别模型[J]. 《计算机应用》唯一官方网站, 2025, 45(12): 3771-3778.
Add to citation manager EndNote|Ris|BibTeX
URL: https://www.joca.cn/EN/10.11772/j.issn.1001-9081.2024111694
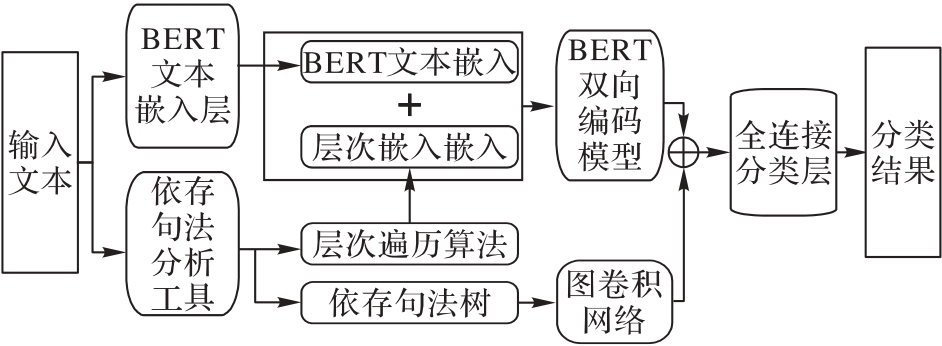
Fig. 1 Overall framework of HIE-GCN model
| 数据集 | 模型 | 单分类错误识别 | 多分类错误识别 | ||||||
|---|---|---|---|---|---|---|---|---|---|
| Acc | P | R | F1 | Acc | P | R | F1 | ||
| FCGEC | BERT-base | 78.00 | 78.12 | 77.86 | 77.90 | 65.90 | 58.28 | 59.88 | 58.96 |
| BERT-base+HIE-GCN | 78.10 | 78.36 | 78.07 | 78.03 | 67.20 | 57.47 | 62.27 | 59.49 | |
| RoBERTa | 80.40 | 80.77 | 80.45 | 80.35 | 70.40 | 60.12 | 64.43 | 61.95 | |
| RoBERTa+HIE-GCN | 81.20 | 81.35 | 81.06 | 81.11 | 71.45 | 61.93 | 66.25 | 63.45 | |
| StructBERT | 81.15 | 81.28 | 81.07 | 81.08 | 69.45 | 57.90 | 65.27 | 60.93 | |
| StructBERT+HIE-GCN | 82.16 | 81.94 | 81.96 | 81.95 | 71.95 | 63.10 | 66.78 | 64.66 | |
| NaCGEC | BERT-base | 72.95 | 72.95 | 73.93 | 72.67 | 65.80 | 55.22 | 53.43 | 53.57 |
| BERT-base+HIE-GCN | 74.65 | 74.66 | 74.75 | 74.62 | 68.50 | 55.75 | 55.64 | 55.52 | |
| RoBERTa | 77.45 | 77.44 | 77.99 | 77.34 | 68.20 | 59.02 | 54.91 | 56.39 | |
| RoBERTa+HIE-GCN | 77.75 | 78.37 | 77.74 | 77.82 | 71.35 | 58.45 | 58.12 | 58.14 | |
| StructBERT | 77.35 | 77.35 | 77.53 | 77.31 | 68.30 | 57.56 | 55.76 | 56.14 | |
| StructBERT+HIE-GCN | 78.89 | 79.51 | 78.90 | 78.96 | 73.60 | 58.38 | 61.08 | 59.56 | |
Tab.1 Comparison of model results on FCGEC and NaCGEC datasets
| 数据集 | 模型 | 单分类错误识别 | 多分类错误识别 | ||||||
|---|---|---|---|---|---|---|---|---|---|
| Acc | P | R | F1 | Acc | P | R | F1 | ||
| FCGEC | BERT-base | 78.00 | 78.12 | 77.86 | 77.90 | 65.90 | 58.28 | 59.88 | 58.96 |
| BERT-base+HIE-GCN | 78.10 | 78.36 | 78.07 | 78.03 | 67.20 | 57.47 | 62.27 | 59.49 | |
| RoBERTa | 80.40 | 80.77 | 80.45 | 80.35 | 70.40 | 60.12 | 64.43 | 61.95 | |
| RoBERTa+HIE-GCN | 81.20 | 81.35 | 81.06 | 81.11 | 71.45 | 61.93 | 66.25 | 63.45 | |
| StructBERT | 81.15 | 81.28 | 81.07 | 81.08 | 69.45 | 57.90 | 65.27 | 60.93 | |
| StructBERT+HIE-GCN | 82.16 | 81.94 | 81.96 | 81.95 | 71.95 | 63.10 | 66.78 | 64.66 | |
| NaCGEC | BERT-base | 72.95 | 72.95 | 73.93 | 72.67 | 65.80 | 55.22 | 53.43 | 53.57 |
| BERT-base+HIE-GCN | 74.65 | 74.66 | 74.75 | 74.62 | 68.50 | 55.75 | 55.64 | 55.52 | |
| RoBERTa | 77.45 | 77.44 | 77.99 | 77.34 | 68.20 | 59.02 | 54.91 | 56.39 | |
| RoBERTa+HIE-GCN | 77.75 | 78.37 | 77.74 | 77.82 | 71.35 | 58.45 | 58.12 | 58.14 | |
| StructBERT | 77.35 | 77.35 | 77.53 | 77.31 | 68.30 | 57.56 | 55.76 | 56.14 | |
| StructBERT+HIE-GCN | 78.89 | 79.51 | 78.90 | 78.96 | 73.60 | 58.38 | 61.08 | 59.56 | |
| 模型 | 单分类错误识别 | 多分类错误识别 | ||||||
|---|---|---|---|---|---|---|---|---|
| Acc | P | R | F1 | Acc | P | R | F1 | |
| StructBERT | 81.15 | 81.28 | 81.07 | 81.08 | 69.45 | 57.90 | 65.27 | 60.93 |
StructBERT+ GCN | 81.25 | 81.38 | 81.10 | 81.15 | 71.00 | 59.77 | 67.19 | 62.87 |
StructBERT+ HIE-GCN | 82.16 | 81.94 | 81.96 | 81.95 | 71.95 | 63.10 | 66.78 | 64.66 |
Tab.2 Ablation study results of StructBERT model on FCGEC dataset
| 模型 | 单分类错误识别 | 多分类错误识别 | ||||||
|---|---|---|---|---|---|---|---|---|
| Acc | P | R | F1 | Acc | P | R | F1 | |
| StructBERT | 81.15 | 81.28 | 81.07 | 81.08 | 69.45 | 57.90 | 65.27 | 60.93 |
StructBERT+ GCN | 81.25 | 81.38 | 81.10 | 81.15 | 71.00 | 59.77 | 67.19 | 62.87 |
StructBERT+ HIE-GCN | 82.16 | 81.94 | 81.96 | 81.95 | 71.95 | 63.10 | 66.78 | 64.66 |
| 队伍 | 单分类错误识别 | 多分类错误识别 | ||
|---|---|---|---|---|
| Acc | F1 | Acc | F1 | |
| hcjiang | 78.73 | 78.69 | — | — |
| grin | 78.70 | 78.62 | — | — |
| YuX | 77.37 | 77.24 | — | — |
| kausal | 78.77 | 78.69 | — | — |
| sxs | — | — | 60.22 | 61.28 |
| luamaker | 76.67 | 76.12 | 54.47 | 58.56 |
| zyq79434(HIE-GCN) | 79.07 | 79.06 | 56.29 | 63.52 |
Tab.3 Model performance on FCGEC open test set
| 队伍 | 单分类错误识别 | 多分类错误识别 | ||
|---|---|---|---|---|
| Acc | F1 | Acc | F1 | |
| hcjiang | 78.73 | 78.69 | — | — |
| grin | 78.70 | 78.62 | — | — |
| YuX | 77.37 | 77.24 | — | — |
| kausal | 78.77 | 78.69 | — | — |
| sxs | — | — | 60.22 | 61.28 |
| luamaker | 76.67 | 76.12 | 54.47 | 58.56 |
| zyq79434(HIE-GCN) | 79.07 | 79.06 | 56.29 | 63.52 |
| 模型 | P | R | F0.5 |
|---|---|---|---|
| 模型仅纠正错误句子 | 46.31 | 35.92 | 43.78 |
| 模型对所有句子纠正 | 36.03 | 35.97 | 36.02 |
| 模型采用流水线进行纠正 | 44.04 | 34.48 | 41.73 |
Tab.5 Pipeline experimental results
| 模型 | P | R | F0.5 |
|---|---|---|---|
| 模型仅纠正错误句子 | 46.31 | 35.92 | 43.78 |
| 模型对所有句子纠正 | 36.03 | 35.97 | 36.02 |
| 模型采用流水线进行纠正 | 44.04 | 34.48 | 41.73 |
| 模型 | 单分类错误识别 | 多分类错误识别 | ||||||
|---|---|---|---|---|---|---|---|---|
| Acc | P | R | F1 | Acc | P | R | F1 | |
| StructBERT+HIE-GCN | 82.16 | 81.94 | 81.96 | 81.95 | 71.95 | 63.10 | 66.78 | 64.66 |
| GPT-3.5-turbo | 51.75 | 53.29 | 53.10 | 51.45 | 20.60 | 23.25 | 20.61 | 18.52 |
| GLM4 | 68.85 | 72.88 | 70.71 | 68.46 | 49.70 | 43.93 | 39.85 | 38.55 |
| Qwen | 59.85 | 69.10 | 62.92 | 57.47 | 48.80 | 35.89 | 24.45 | 25.35 |
| ERNIE | 72.05 | 73.75 | 73.21 | 72.01 | 56.70 | 40.86 | 38.34 | 38.47 |
Tab.5 Experimental results of LLMs on semantic error recognition
| 模型 | 单分类错误识别 | 多分类错误识别 | ||||||
|---|---|---|---|---|---|---|---|---|
| Acc | P | R | F1 | Acc | P | R | F1 | |
| StructBERT+HIE-GCN | 82.16 | 81.94 | 81.96 | 81.95 | 71.95 | 63.10 | 66.78 | 64.66 |
| GPT-3.5-turbo | 51.75 | 53.29 | 53.10 | 51.45 | 20.60 | 23.25 | 20.61 | 18.52 |
| GLM4 | 68.85 | 72.88 | 70.71 | 68.46 | 49.70 | 43.93 | 39.85 | 38.55 |
| Qwen | 59.85 | 69.10 | 62.92 | 57.47 | 48.80 | 35.89 | 24.45 | 25.35 |
| ERNIE | 72.05 | 73.75 | 73.21 | 72.01 | 56.70 | 40.86 | 38.34 | 38.47 |
| 模型 | 直接纠错 | 分类纠错 | ||||
|---|---|---|---|---|---|---|
| P | R | F0.5 | P | R | F0.5 | |
| gpt-3.5-turbo | 12.28 | 11.70 | 12.16 | 13.94 | 12.17 | 13.54 |
| GLM4 | 24.80 | 33.52 | 26.16 | 29.42 | 38.75 | 30.90 |
| Qwen | 16.95 | 31.44 | 18.67 | 21.43 | 35.17 | 23.25 |
| ERNIE | 23.82 | 39.66 | 25.89 | 26.01 | 41.07 | 28.07 |
Tab.6 Experimental results of LLMs on semantic error correction
| 模型 | 直接纠错 | 分类纠错 | ||||
|---|---|---|---|---|---|---|
| P | R | F0.5 | P | R | F0.5 | |
| gpt-3.5-turbo | 12.28 | 11.70 | 12.16 | 13.94 | 12.17 | 13.54 |
| GLM4 | 24.80 | 33.52 | 26.16 | 29.42 | 38.75 | 30.90 |
| Qwen | 16.95 | 31.44 | 18.67 | 21.43 | 35.17 | 23.25 |
| ERNIE | 23.82 | 39.66 | 25.89 | 26.01 | 41.07 | 28.07 |
| [1] | 李云汉,施运梅,李宁,等. 中文文本自动校对综述[J]. 中文信息学报, 2022, 36(9): 1-18, 27. |
| LI Y H, SHI Y M, LI N, et al. A survey of automatic error correction of Chinese text[J]. Journal of Chinese Information Processing, 2022, 36(9): 1-18, 27. | |
| [2] | 王天极,陈柏霖,黄瑞章,等. 基于Electra和门控双线性神经网络的中文语法错误检测模型[J]. 中文信息学报, 2023, 37(8): 169-178. |
| WANG T J, CHEN B L, HUANG R Z, et al. Chinese grammatical error diagnosis model based on Electra and gated-bilinear neural network[J]. Journal of Chinese Information Processing, 2023, 37(8): 169-178. | |
| [3] | QIU Z, QU Y. A two-stage model for Chinese grammatical error correction[J]. IEEE Access, 2019, 7: 146772-146777. |
| [4] | WU H, ZHANG H, XUAN R, et al. Bi-DCSpell: a bi-directional detector-corrector interactive framework for Chinese spelling check[C]// Findings of the Association for Computational Linguistics: EMNLP 2024. Stroudsburg: ACL, 2024: 3974-3984. |
| [5] | HUANG H, YE J, ZHOU Q, et al. A frustratingly easy plug-and-play detection-and-reasoning module for Chinese spelling check[C]// Findings of the Association for Computational Linguistics: EMNLP 2023. Stroudsburg: ACL, 2023: 11514-11525. |
| [6] | LI Y, LIU X, WANG S, et al. TemplateGEC: improving grammatical error correction with detection template[C]// Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Stroudsburg: ACL, 2023: 6878-6892. |
| [7] | LI W, WANG H. Detection-correction structure via general language model for grammatical error correction[C]// Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Stroudsburg: ACL, 2024: 1748-1763. |
| [8] | HUANG W, DONG X, WANG M X, et al. CSEC: a Chinese semantic error correction dataset for written correction[C]// Proceedings of the 2023 International Conference on Neural Information Processing, LNCS 14451. Singapore: Springer, 2024: 383-398. |
| [9] | CHEN B, OUYANG Q, LUO Y, et al. S2GSL: incorporating segment to syntactic enhanced graph structure learning for aspect-based sentiment analysis[C]// Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Stroudsburg: ACL, 2024: 13366-13379. |
| [10] | ZHANG M, LI Z, FU G, et al. Syntax-enhanced neural machine translation with syntax-aware word representations[C]// Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers). Stroudsburg: ACL, 2019: 1151-1161. |
| [11] | SUN B, WANG B, CHE W, et al. Improving pre-trained language models with syntactic dependency prediction task for Chinese semantic error recognition[EB/OL]. [2024-11-20].. |
| [12] | WAN Z, WAN X. A syntax-guided grammatical error correction model with dependency tree correction[EB/OL]. [2024-11-20].. |
| [13] | LI Z, PARNOW K, ZHAO H. Incorporating rich syntax information in grammatical error correction[J]. Information Processing and Management, 2022, 59(3): No.102891. |
| [14] | DEVLIN J, CHANG M W, LEE K, et al. BERT: pre-training of deep bidirectional transformers for language understanding[C]// Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers). Stroudsburg: ACL, 2019: 4171-4186. |
| [15] | XU L, WU J, PENG J, et al. FCGEC: fine-grained corpus for Chinese grammatical error correction[C]// Findings of the Association for Computational Linguistics: EMNLP 2022. Stroudsburg: ACL, 2022: 1900-1918. |
| [16] | MA S, LI Y, SUN R, et al. Linguistic rules-based corpus generation for native Chinese grammatical error correction[C]// Findings of the Association for Computational Linguistics: EMNLP 2022. Stroudsburg: ACL, 2022: 576-589. |
| [17] | YEH J F, CHANG L T, LIU C Y, et al. Chinese spelling check based on N-gram and string matching algorithm[C]// Proceedings of the 4th Workshop on Natural Language Processing Techniques for Educational Applications. Stroudsburg: ACL, 2017: 35-38. |
| [18] | YUAN Z, BRISCOE T. Grammatical error correction using neural machine translation[C]// Proceedings of the 2016 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. Stroudsburg: ACL, 2016: 380-386. |
| [19] | LIANG D, ZHENG C, GUO L, et al. BERT enhanced neural machine translation and sequence tagging model for Chinese grammatical error diagnosis[C]// Proceedings of the 6th Workshop on Natural Language Processing Techniques for Educational Applications. Stroudsburg: ACL, 2020: 57-66. |
| [20] | REN H, YANG L, XUN E. A sequence to sequence learning for Chinese grammatical error correction[C]// Proceedings of the 2018 CCF International Conference on Natural Language Processing and Chinese Computing, LNCS 11109. Cham: Springer, 2018: 401-410. |
| [21] | SUN B, WANG B, WANG Y, et al. CSED: a Chinese semantic error diagnosis corpus[EB/OL]. [2024-11-20].. |
| [22] | LI Y, HUANG H, MA S, et al. On the (in)effectiveness of large language models for Chinese text correction[EB/OL]. [2024-11-21].. |
| [23] | QU F, WU Y. Evaluating the capability of large-scale language models on Chinese grammatical error correction task[EB/OL]. [2024-11-21].. |
| [24] | WANG Y, WANG B, LIU Y, et al. LM-Combiner: a contextual rewriting model for Chinese grammatical error correction[C]// Proceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation. [S.l.]: ELRA and ICCL, 2024: 10675-10685. |
| [25] | YANG H, QUAN X. Alirector: alignment-enhanced Chinese grammatical error corrector[C]// Findings of the Association for Computational Linguistics: ACL 2024. Stroudsburg: ACL, 2024: 2531-2546. |
| [26] | PENG H, LI J, HE Y, et al. Large-scale hierarchical text classification with recursively regularized deep graph-CNN[C]// Proceedings of the 2018 World Wide Web Conference. Republic and Canton of Geneva: International World Wide Web Conferences Steering Committee, 2018: 1063-1072. |
| [27] | YAO L, MAO C, LUO Y. Graph convolutional networks for text classification[C]// Proceedings of the 33rd AAAI Conference on Artificial Intelligence. Palo Alto: AAAI Press, 2019: 7370-7377. |
| [28] | LUO Y, BAO Z, LI C, et al. Chinese grammatical error diagnosis with graph convolution network and multi-task learning[C]// Proceedings of the 6th Workshop on Natural Language Processing Techniques for Educational Applications. Stroudsburg: ACL, 2020: 44-48. |
| [29] | ZHANG Y, ZHANG B, LI Z, et al. SynGEC: syntax-enhanced grammatical error correction with a tailored GEC-oriented parser[C]// Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing. Stroudsburg: ACL, 2022: 2518-2531. |
| [30] | WOLF T, DEBUT L, SANH V, et al. Transformers: state-of-the-art natural language processing[C]// Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing: System Demonstrations. Stroudsburg: ACL, 2020: 38-45. |
| [31] | CHE W, FENG Y, QIN L, et al. N-LTP: an open-source neural language technology platform for Chinese[C]// Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing: System Demonstrations. Stroudsburg: ACL, 2021: 42-49. |
| [32] | KINGMA D P, BA J L. Adam: a method for stochastic optimization[EB/OL]. [2024-11-22].. |
| [33] | WANG W, BI B, YAN M, et al. StructBERT: incorporating language structures into pre-training for deep language understanding[EB/OL]. [2024-11-22].. |
| [34] | ZHANG Y, LI Z, BAO Z, et al. MuCGEC: a multi-reference multi-source evaluation dataset for Chinese grammatical error correction[C]// Proceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. Stroudsburg: ACL, 2022: 3118-3130. |
| [35] | BRYANT C, FELICE M, BRISCOE E. Automatic annotation and evaluation of error types for grammatical error correction[C]// Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Stroudsburg: ACL, 2017: 793-805. |
| [36] | FELICE M, BRYANT C, BRISCOE T. Automatic extraction of learner errors in ESL sentences using linguistically enhanced alignments[C]// Proceedings of the 26th International Conference on Computational Linguistics: Technical Papers. [S.l.]: the COLING 2016 Organizing Committee, 2016: 825-835. |
| [37] | CUI Y, CHE W, LIU T, et al. Revisiting pre-trained models for Chinese natural language processing[C]// Findings of the Association for Computational Linguistics: EMNLP 2020. Stroudsburg: ACL, 2020: 657-668. |
| [38] | MINAEE S, MIKOLOV T, NIKZAD N, et al. Large language models: a survey[EB/OL]. [2024-11-22].. |
| [39] | Team GLM. ChatGLM: a family of large language models from GLM-130B to GLM-4 all tools[EB/OL]. [2024-11-22].. |
| [40] | Team Qwen. Qwen technical report[R/OL]. [2024-11-22].. |
| [41] | SUN Y, WANG S, FENG S, et al. ERNIE 3.0: large-scale knowledge enhanced pre-training for language understanding and generation[EB/OL]. [2024-11-22].. |
| [42] | BROWN T B, MANN B, RYDER N, et al. Language models are few-shot learners advances[C]// Proceedings of the 34th International Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2020: 1877-1901. |
| [1] | Yi LIN, Bing XIA, Yong WANG, Shunda MENG, Juchong LIU, Shuqin ZHANG. AI-Agent based method for hidden RESTful API discovery and vulnerability detection [J]. Journal of Computer Applications, 2026, 46(1): 135-143. |
| [2] | Xinran XIE, Zhe CUI, Rui CHEN, Tailai PENG, Dekun LIN. Zero-shot re-ranking method by large language model with hierarchical filtering and label semantic extension [J]. Journal of Computer Applications, 2026, 46(1): 60-68. |
| [3] | Binbin ZHANG, Yongbin QIN, Ruizhang HUANG, Yanping CHEN. Judgment document summarization method combining large language model and dynamic prompts [J]. Journal of Computer Applications, 2025, 45(9): 2783-2789. |
| [4] | Chao SHI, Yuxin ZHOU, Qian FU, Wanyu TANG, Ling HE, Yuanyuan LI. Action recognition algorithm for ADHD patients using skeleton and 3D heatmap [J]. Journal of Computer Applications, 2025, 45(9): 3036-3044. |
| [5] | Tao FENG, Chen LIU. Dual-stage prompt tuning method for automated preference alignment [J]. Journal of Computer Applications, 2025, 45(8): 2442-2447. |
| [6] | Wei ZHANG, Jiaxiang NIU, Jichao MA, Qiongxia SHEN. Chinese spelling correction model ReLM enhanced with deep semantic features [J]. Journal of Computer Applications, 2025, 45(8): 2484-2490. |
| [7] | Ziliang LI, Guangli ZHU, Yulei ZHANG, Jiajia LIU, Yixuan JIAO, Shunxiang ZHANG. Aspect-based sentiment analysis model integrating syntax and sentiment knowledge [J]. Journal of Computer Applications, 2025, 45(6): 1724-1731. |
| [8] | Quan WANG, Qixiang LU, Pei SHI. Multi-graph diffusion attention network for traffic flow prediction [J]. Journal of Computer Applications, 2025, 45(5): 1472-1479. |
| [9] | Man CHEN, Xiaojun YANG, Huimin YANG. Pedestrian trajectory prediction based on graph convolutional network and endpoint induction [J]. Journal of Computer Applications, 2025, 45(5): 1480-1487. |
| [10] | Yufei LONG, Yuchen MOU, Ye LIU. Multi-source data representation learning model based on tensorized graph convolutional network and contrastive learning [J]. Journal of Computer Applications, 2025, 45(5): 1372-1378. |
| [11] | Weichao DANG, Chujun SONG, Gaimei GAO, Chunxia LIU. Multi-behavior recommendation based on cascading residual graph convolutional network [J]. Journal of Computer Applications, 2025, 45(4): 1223-1231. |
| [12] | Yiheng SUN, Maofu LIU. Tender information extraction method based on prompt tuning of knowledge [J]. Journal of Computer Applications, 2025, 45(4): 1169-1176. |
| [13] | Jing HE, Yang SHEN, Runfeng XIE. Recognition and optimization of hallucination phenomena in large language models [J]. Journal of Computer Applications, 2025, 45(3): 709-714. |
| [14] | Peng CAO, Guangqi WEN, Jinzhu YANG, Gang CHEN, Xinyi LIU, Xuechun JI. Efficient fine-tuning method of large language models for test case generation [J]. Journal of Computer Applications, 2025, 45(3): 725-731. |
| [15] | Xuefei ZHANG, Liping ZHANG, Sheng YAN, Min HOU, Yubo ZHAO. Personalized learning recommendation in collaboration of knowledge graph and large language model [J]. Journal of Computer Applications, 2025, 45(3): 773-784. |
| Viewed | ||||||
|
Full text |
|
|||||
|
Abstract |
|
|||||