


Journal of Computer Applications ›› 2026, Vol. 46 ›› Issue (3): 750-757.DOI: 10.11772/j.issn.1001-9081.2025030320
• Artificial intelligence • Previous Articles Next Articles
Huihui CHEN1( ), Hongtao SUN1, Boliang GUAN1, Zhongqing HENG2
), Hongtao SUN1, Boliang GUAN1, Zhongqing HENG2
Received:2025-03-28
Revised:2025-06-07
Accepted:2025-06-10
Online:2025-07-01
Published:2026-03-10
Contact:
Huihui CHEN
About author:SUN Hongtao, born in 2002, M. S. candidate. His research interests include multi-modal data fusion, image recognition.Supported by:
陈荟慧1(), 孙洪韬1, 关柏良1, 衡中青2
通讯作者:
陈荟慧
作者简介:孙洪韬(2002—),男,广东南雄人,硕士研究生,主要研究方向:多模态数据融合、图像识别基金资助:CLC Number:
Huihui CHEN, Hongtao SUN, Boliang GUAN, Zhongqing HENG. Chinese character image retrieval algorithm in ancient books based on NetVLAD feature encoding[J]. Journal of Computer Applications, 2026, 46(3): 750-757.
陈荟慧, 孙洪韬, 关柏良, 衡中青. 基于NetVLAD特征编码的古籍汉字图像检索算法[J]. 《计算机应用》唯一官方网站, 2026, 46(3): 750-757.
Add to citation manager EndNote|Ris|BibTeX
URL: https://www.joca.cn/EN/10.11772/j.issn.1001-9081.2025030320

Fig. 1 Samples of Chinese character images in ancient books
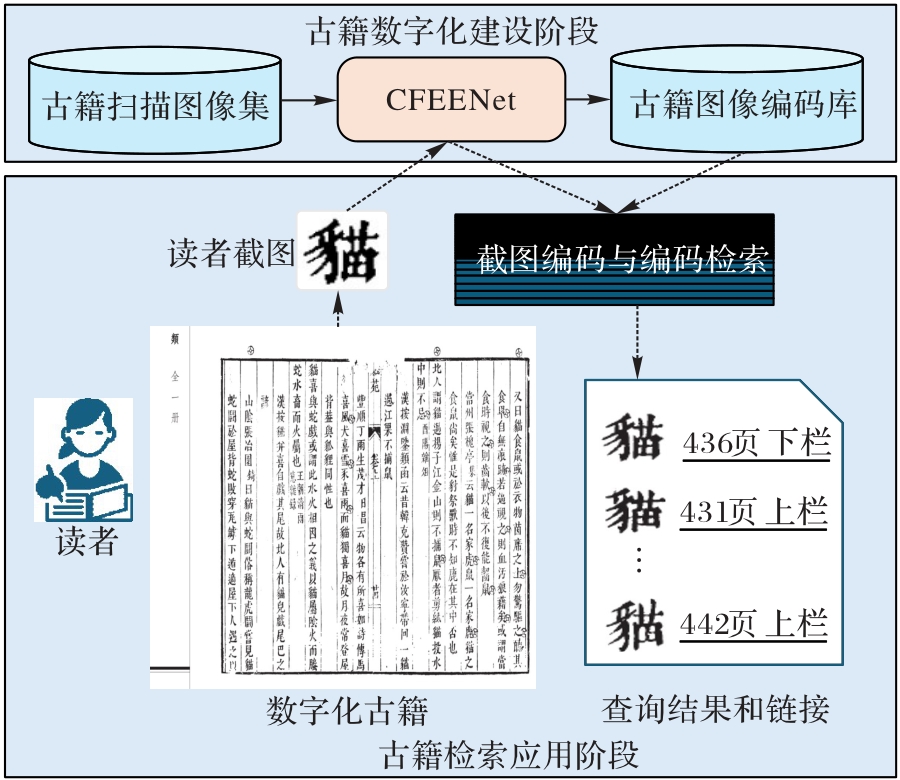
Fig. 2 Framework of Chinese character retrieval system in ancient books
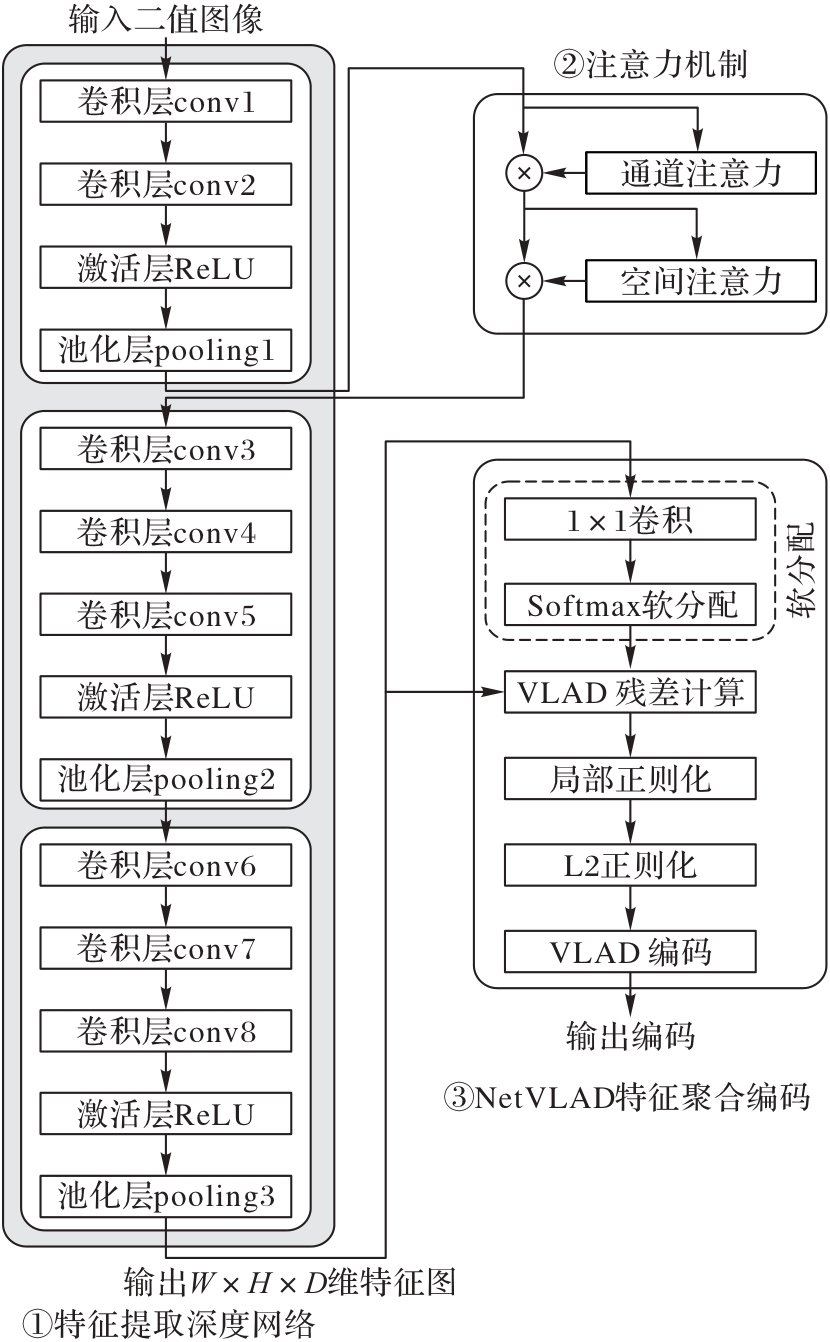
Fig. 3 Architecture of CFEENet
| 序号 | 层 | 输入尺寸 ( | 输出尺寸 ( | 说明 |
|---|---|---|---|---|
| 1 | conv1 | 50×50×1 | 64×64×64 | 卷积核尺寸 3×3 |
| 2 | conv2 | 64×64×64 | 64×64×64 | |
| 3 | ReLU | — | — | 激活函数 |
| 4 | pooling1 | 64×64×64 | 32×32×64 | 最大池化 |
| 5 | conv3 | 32×32×64 | 32×32×128 | 卷积核尺寸 3×3 |
| 6 | conv4 | 32×32×128 | 32×32×128 | |
| 7 | conv5 | 32×32×128 | 32×32×128 | |
| 8 | ReLU | — | — | 激活函数 |
| 9 | pooling2 | 32×32×128 | 16×16×128 | 最大池化 |
| 10 | conv6 | 16×16×128 | 16×16×256 | 卷积核尺寸 3×3 |
| 11 | conv7 | 16×16×256 | 16×16×256 | |
| 12 | conv8 | 16×16×256 | 16×16×256 | |
| 13 | ReLU | — | — | 激活函数 |
| 14 | pooling3 | 16×16×256 | 8×8×256 | 最大池化 |
Tab. 1 Detailed parameters of feature extraction network in CFEENet
| 序号 | 层 | 输入尺寸 ( | 输出尺寸 ( | 说明 |
|---|---|---|---|---|
| 1 | conv1 | 50×50×1 | 64×64×64 | 卷积核尺寸 3×3 |
| 2 | conv2 | 64×64×64 | 64×64×64 | |
| 3 | ReLU | — | — | 激活函数 |
| 4 | pooling1 | 64×64×64 | 32×32×64 | 最大池化 |
| 5 | conv3 | 32×32×64 | 32×32×128 | 卷积核尺寸 3×3 |
| 6 | conv4 | 32×32×128 | 32×32×128 | |
| 7 | conv5 | 32×32×128 | 32×32×128 | |
| 8 | ReLU | — | — | 激活函数 |
| 9 | pooling2 | 32×32×128 | 16×16×128 | 最大池化 |
| 10 | conv6 | 16×16×128 | 16×16×256 | 卷积核尺寸 3×3 |
| 11 | conv7 | 16×16×256 | 16×16×256 | |
| 12 | conv8 | 16×16×256 | 16×16×256 | |
| 13 | ReLU | — | — | 激活函数 |
| 14 | pooling3 | 16×16×256 | 8×8×256 | 最大池化 |

Fig. 4 Schematic diagram of CBAM
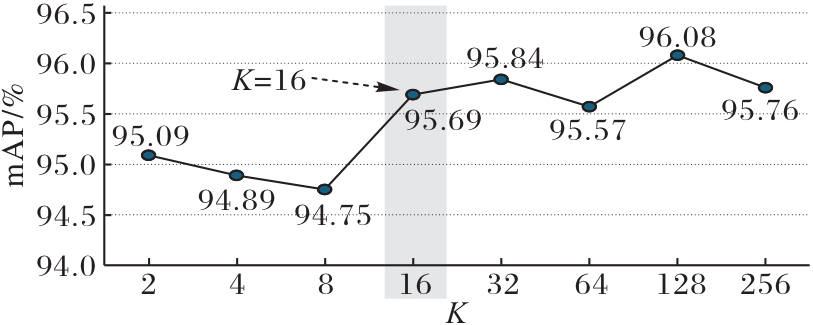
Fig. 5 Selection of number of visual words
| 注意力机制 | mAP/% |
|---|---|
| 未使用CBAM | 95.69 |
| 使用CBAM | 95.93 |
Tab. 2 Comparison of mAP before and after using attention mechanism
| 注意力机制 | mAP/% |
|---|---|
| 未使用CBAM | 95.69 |
| 使用CBAM | 95.93 |
| 方法 | mAP/% | F1分数/% | QpS |
|---|---|---|---|
| SIFT+VLAD | 44.86 | 25 | 17.00 |
| VGG16+NetVLAD | 86.29 | 79 | 8.23 |
| ResNet50+NetVLAD | 89.29 | 83 | 2.17 |
| DenseNet161+NetVLAD | 91.17 | 81 | 2.07 |
| CFEENet | 95.93 | 92 | 15.84 |
Tab. 3 Retrieval performance comparison of different feature extraction backbones
| 方法 | mAP/% | F1分数/% | QpS |
|---|---|---|---|
| SIFT+VLAD | 44.86 | 25 | 17.00 |
| VGG16+NetVLAD | 86.29 | 79 | 8.23 |
| ResNet50+NetVLAD | 89.29 | 83 | 2.17 |
| DenseNet161+NetVLAD | 91.17 | 81 | 2.07 |
| CFEENet | 95.93 | 92 | 15.84 |
| 方法 | mAP/% | F1分数/% | QpS |
|---|---|---|---|
| M1 | 81.50 | 63 | 4.22 |
| M2 | 84.93 | 70 | 15.79 |
| CFEENet | 95.93 | 92 | 15.84 |
Tab. 4 Results of ablation study
| 方法 | mAP/% | F1分数/% | QpS |
|---|---|---|---|
| M1 | 81.50 | 63 | 4.22 |
| M2 | 84.93 | 70 | 15.79 |
| CFEENet | 95.93 | 92 | 15.84 |
| 数据集 | mAP | F1分数 | ||||||
|---|---|---|---|---|---|---|---|---|
| ACCINet | ResNeSt-final | CFEENet | ACCINet | ResNeSt-final | CFEENet | |||
| 中文古籍数据集 | 《猫苑》(测试集) | 90.44 | 96.52 | 95.93 | 80 | 92 | 92 | |
| 《唐诗选玄集》 | 70.31 | 86.77 | 81.32 | 47 | 63 | 63 | ||
| 《漢書古字類一卷第一册》 | 89.60 | 90.94 | 93.11 | 79 | 80 | 86 | ||
| 赵孟頫行书集字《三字经》 | 93.13 | 85.14 | 94.91 | 83 | 67 | 87 | ||
| 均值 | 85.87 | 89.84 | 91.32 | 72 | 76 | 82 | ||
其他语言 字符数据集 | Omniglot | 日文(片假名) | 58.95 | 67.28 | 67.59 | 32 | 34 | 41 |
| 日文(平假名) | 61.50 | 68.62 | 67.68 | 33 | 35 | 43 | ||
| 韩文字母 | 66.47 | 69.58 | 71.85 | 38 | 36 | 47 | ||
| 均值 | 62.31 | 68.49 | 69.04 | 34 | 35 | 44 | ||
Tab. 5 Results of comparison experiments of different methods
| 数据集 | mAP | F1分数 | ||||||
|---|---|---|---|---|---|---|---|---|
| ACCINet | ResNeSt-final | CFEENet | ACCINet | ResNeSt-final | CFEENet | |||
| 中文古籍数据集 | 《猫苑》(测试集) | 90.44 | 96.52 | 95.93 | 80 | 92 | 92 | |
| 《唐诗选玄集》 | 70.31 | 86.77 | 81.32 | 47 | 63 | 63 | ||
| 《漢書古字類一卷第一册》 | 89.60 | 90.94 | 93.11 | 79 | 80 | 86 | ||
| 赵孟頫行书集字《三字经》 | 93.13 | 85.14 | 94.91 | 83 | 67 | 87 | ||
| 均值 | 85.87 | 89.84 | 91.32 | 72 | 76 | 82 | ||
其他语言 字符数据集 | Omniglot | 日文(片假名) | 58.95 | 67.28 | 67.59 | 32 | 34 | 41 |
| 日文(平假名) | 61.50 | 68.62 | 67.68 | 33 | 35 | 43 | ||
| 韩文字母 | 66.47 | 69.58 | 71.85 | 38 | 36 | 47 | ||
| 均值 | 62.31 | 68.49 | 69.04 | 34 | 35 | 44 | ||
| 方法 | 参数量/106 | 单样本推理总运算量/GFLOPs | 单样本平均推理时间/ms |
|---|---|---|---|
| ACCINet | 99.67 | 1.07 | 6.02 |
| ResNeSt-final | 118.68 | 7.95 | 74.42 |
| CFEENet | 15.69 | 0.96 | 2.28 |
Tab. 6 Results of comparison of model complexity and inference efficiency
| 方法 | 参数量/106 | 单样本推理总运算量/GFLOPs | 单样本平均推理时间/ms |
|---|---|---|---|
| ACCINet | 99.67 | 1.07 | 6.02 |
| ResNeSt-final | 118.68 | 7.95 | 74.42 |
| CFEENet | 15.69 | 0.96 | 2.28 |
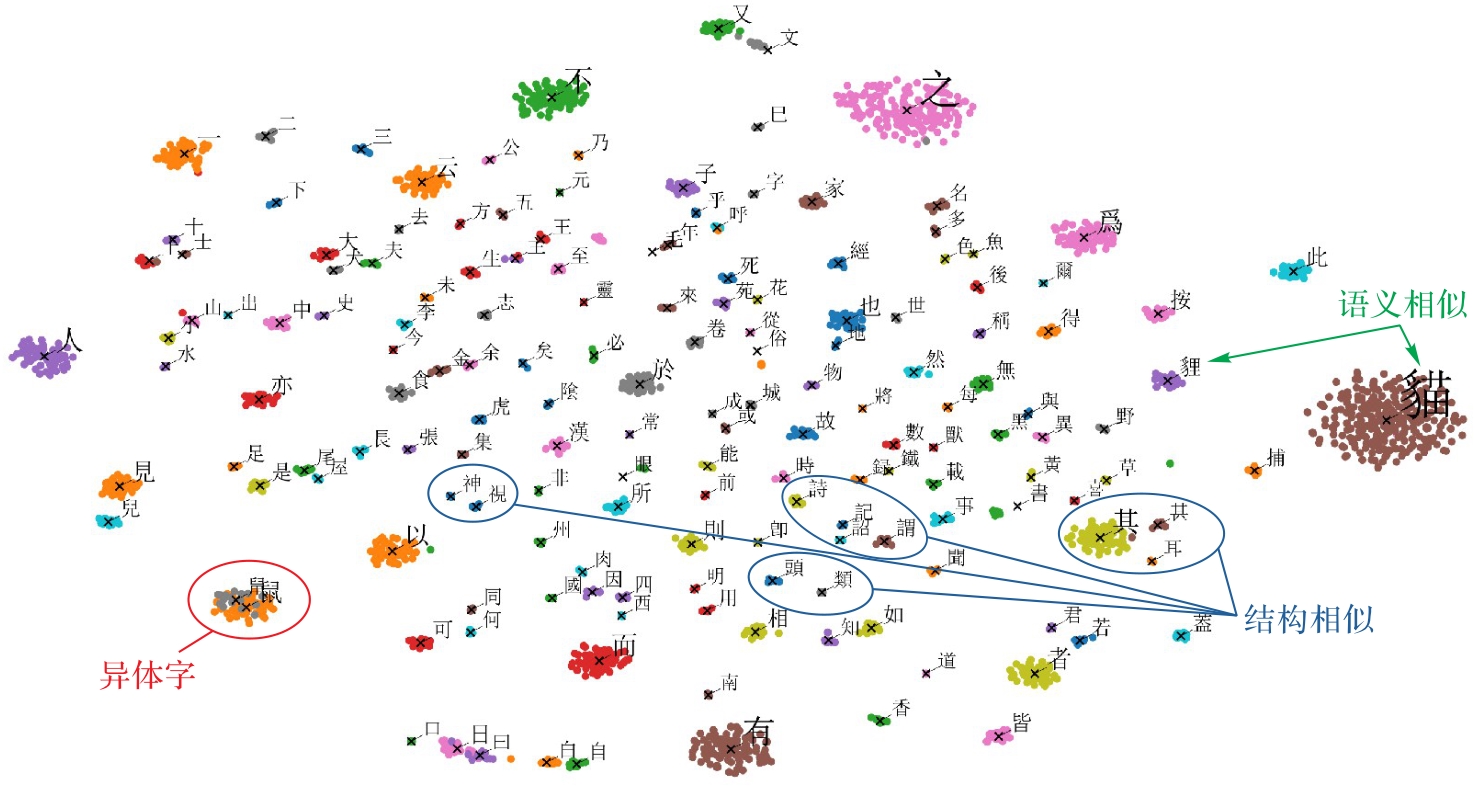
Fig. 6 Effect of partial clustering results of encoding

Fig. 7 Examples of retrieval performance

Fig. 8 Examples of retrieval performance for visually similar characters

Fig. 9 Examples of retrieval performance for damaged Chinese character images
| [1] | 李世钰,张向先,沈旺,等. 古籍数字化国内外研究现状分析与路径构建研究[J]. 现代情报, 2023, 43(11): 4-20. |
| LI S Y, ZHANG X X, SHEN W, et al. Research status and path construction of ancient book digitization in China and abroad [J]. Journal of Modern Information, 2023, 43(11): 4-20. | |
| [2] | 林泽柠,汪嘉鹏,金连文. 视觉信息抽取的深度学习方法综述[J]. 中国图象图形学报, 2023, 28(8): 2276-2297. |
| LIN Z N, WANG J P, JIN L W. Visual information extraction deep learning method: a critical review [J]. Journal of Image and Graphics, 2023, 28(8): 2276-2297. | |
| [3] | 王晓玉,李斌. 基于CRFs和词典信息的中古汉语自动分词[J]. 数据分析与知识发现, 2017, 1(5): 62-70. |
| WANG X Y, LI B. Automatically segmenting middle ancient Chinese words with CRFs[J]. Data Analysis and Knowledge Discovery, 2017, 1(5): 62-70. | |
| [4] | 张晓冰,张佩. 古籍数字化出版的挑战与发展路径研究——以“识典古籍”为例[J]. 北京印刷学院学报, 2024, 32(9): 1-6. |
| ZHANG X B, ZHANG P. Research on the challenges and development paths of digital publishing of ancient books — taking “shi-dian Ancient Books” as an example [J]. Journal of Beijing Institute of Graphic Communication, 2024, 32(9): 1-6. | |
| [5] | 冉耕,黄山,何志辉,等. 重叠模糊规范化双弹性网格汉字特征提取[J]. 计算机工程与设计, 2016, 37(1): 211-215. |
| RAN G, HUANG S, HE Z H, et al. Standardized elastic dual-mesh Chinese character feature extraction based on overlap and fuzzy technology[J]. Computer Engineering and Design, 2016, 37(1): 211-215. | |
| [6] | 田学东,柴彦立,王海彬. 基于犹豫模糊特征的古籍汉字图像检索方法[J]. 计算机工程, 2019, 45(3): 217-224. |
| TIAN X D, CHAI Y L, WANG H B. Retrieval method of ancient Chinese character images based on hesitant fuzzy features [J]. Computer Engineering, 2019, 45(3): 217-224. | |
| [7] | 章夏芬,庄越挺,鲁伟明,等. 根据形状相似性的书法内容检索[J]. 计算机辅助设计与图形学学报, 2005, 17(11): 185-189. |
| ZHANG X F, ZHUANG Y T, LU W M, et al. Chinese calligraphic character retrieval based on shape similarity [J]. Journal of Computer-Aided Design and Computer Graphics, 2005, 17(11): 185-189. | |
| [8] | 施伯乐,张亮,王勇,等. 基于视觉相似性的中文古籍内容检索方法[J]. 软件学报, 2001, 12(9): 1336-1342. |
| SHI B L, ZHANG L, WANG Y, et al. Content-based Chinese antique books retrieval through visual similarity criteria [J]. Journal of Software, 2001, 12(9): 1336-1342. | |
| [9] | 俞凯,吴江琴. 书法字快速多层检索方法[J]. 计算机辅助设计与图形学学报, 2011, 23(8): 1415-1419. |
| YU K, WU J Q. Fast multi-level retrieval for calligraphic characters [J]. Journal of Computer-Aided Design and Computer Graphics, 2011, 23(8): 1415-1419. | |
| [10] | 白淑霞,鲍玉来. LDA单词图像表示的蒙古文古籍图像关键词检索方法[J]. 现代情报, 2017, 37(7): 51-54, 88. |
| BAI S X, BAO Y L. LDA-based word image representation for keyword spotting on historical Mongolian documents [J]. Journal of Modern Information, 2017, 37(7): 51-54, 88. | |
| [11] | 杨慧,施水才. 基于内容的图像检索技术研究综述[J]. 软件导刊, 2023, 22(4): 229-244. |
| YANG H, SHI S C. Survey of research on content-based image retrieval technology [J]. Software Guide, 2023, 22(4): 229-244. | |
| [12] | 刘虹,王烈. 结合余弦相关性的卷积网络识别汉字的方法[J]. 计算机工程与应用, 2020, 56(8): 130-135. |
| LIU H, WANG L. Method of combining convolutional neural network with cosine similarity algorithm to recognize Chinese characters [J]. Computer Engineering and Applications, 2020, 56(8): 130-135. | |
| [13] | 毛晓波,程志远,周晓东. 基于特征图叠加的脱机手写体汉字识别[J]. 郑州大学学报(理学版), 2018, 50(3): 78-82. |
| MAO X B, CHENG Z Y, ZHOU X D. Offline handwritten Chinese character recognition based on concatenated feature maps [J]. Journal of Zhengzhou University (Natural Science Edition), 2018, 50(3): 78-82. | |
| [14] | 田学东,王志红,左丽娜. 古籍汉字图像的可变形卷积网络检索模型[J]. 中国科技论文, 2020, 15(4): 461-468. |
| TIAN X D, WANG Z H, ZUO L N. Deformable convolutional network retrieval model for ancient Chinese character images [J]. Chinese Sciencepaper, 2020, 15(4): 461-468. | |
| [15] | 田学东,杨琼,杨芳. 融合空间及通道注意网络的古籍汉字图像检索[J]. 河北大学学报(自然科学版), 2021, 41(5): 623-632. |
| TIAN X D, YANG Q, YANG F. Ancient Chinese character image retrieval based on space and channel attention fusion network [J]. Journal of Hebei University (Natural Science Edition), 2021, 41(5): 623-632. | |
| [16] | 毛亚菲,毕晓君. 改进ResNeSt网络的拓片甲骨文字识别[J]. 智能系统学报, 2023, 18(3): 450-458. |
| MAO Y F, BI X J. Rubbing oracle bone character recognition based on improved ResNeSt network [J]. CAAI Transactions on Intelligent Systems, 2023, 18(3): 450-458. | |
| [17] | GRAUMAN K. Efficiently searching for similar images [J]. Communications of the ACM, 2010, 53(6): 84-94. |
| [18] | SHEKHAR R, JAWAHAR C V. Word image retrieval using bag of visual words [C]// Proceedings of the 10th IAPR International Workshop on Document Analysis Systems. Piscataway: IEEE, 2012: 297-301. |
| [19] | SIVIC J, ZISSERMAN A. Video Google: a text retrieval approach to object matching in videos [C]// Proceedings 9th IEEE International Conference on Computer Vision — Volume 2. Piscataway: IEEE, 2003: 1470-1477. |
| [20] | PERRONNIN F, LIU Y, SÁNCHEZ J, et al. Large-scale image retrieval with compressed fisher vectors [C]// Proceedings of the 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2010: 3384-3391. |
| [21] | ARANDJELOVIĆ R, ZISSERMAN A. All about VLAD [C]// Proceedings of the 2013 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2013: 1578-1585. |
| [22] | JÉGOU H, PERRONNIN F, DOUZE M, et al. Aggregating local image descriptors into compact codes [J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2012, 34(9): 1704-1716. |
| [23] | 朱建清,林露馨,沈飞,等. 采用SIFT和VLAD特征编码的布匹检索算法[J]. 信号处理, 2019, 35(10): 1725-1731. |
| ZHU J Q, LIN L X, SHEN F, et al. Fabric retrieval algorithm using SIFT and VLAD feature coding [J]. Journal of Signal Processing, 2019, 35(10): 1725-1731. | |
| [24] | ZHANG D, LU G. Evaluation of similarity measurement for image retrieval [C]// Proceedings of the 2003 International Conference on Neural Networks and Signal Processing — Volume 2. Piscataway: IEEE, 2003: 928-931. |
| [25] | ARANDJELOVIĆ R, GRONAT P, TORII A, et al. NetVLAD: CNN architecture for weakly supervised place recognition [J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2018, 40(6): 1437-1451. |
| [26] | SIMONYAN K, ZISSERMAN A. Very deep convolutional networks for large-scale image recognition [EB/OL]. [2025-01-20].. |
| [27] | WOO S, PARK J, LEE J Y, et al. CBAM: convolutional block attention module [C]// Proceedings of the 2018 European Conference on Computer Vision, LNCS 11211. Cham: Springer, 2018: 3-19. |
| [28] | 薛朝辉,周逸飏,强永刚,等. 融合NetVLAD和全连接层的三元神经网络交叉视角场景图像定位[J]. 遥感学报, 2021, 25(5): 1095-1107. |
| XUE Z H, ZHOU Y Y, QIANG Y G, et al. Cross-view scene image localization with triplet network integrating NetVLAD and fully connected layers [J]. National Remote Sensing Bulletin, 2021, 25(5): 1095-1107. | |
| [29] | 张舜尧,李华旺,张永合,等. 基于独立注意力机制的图像检索算法[J]. 计算机科学, 2023, 50(6A): No.220300092. |
| ZHANG S Y, LI H W, ZHANG Y H, et al. Image retrieval based on independent attention mechanism [J]. Computer Science, 2023, 50(6A): No.220300092. | |
| [30] | 衡中青. 《广州大典·猫苑》之“猫”主题索引[J]. 中国索引, 2020(1): 189-220. |
| HENG Z Q. Subject Index of A compilation of cat from The classic books of Canton [J]. Journal of the China Society of Indexers, 2020(1): 189-220. | |
| [31] | HE K, ZHANG X, REN S, et al. Deep residual learning for image recognition [C]// Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2016: 770-778. |
| [32] | HUANG G, LIU Z, VAN DER MAATEN L, et al. Densely connected convolutional networks [C]// Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2017: 2261-2269. |
| [33] | VAN DER MAATEN L, HINTON G. Visualizing data using t-SNE[J]. Journal of Machine Learning Research, 2008, 9: 2579-2605. |
| [1] | Yanan LI, Mengyang GUO, Guojun DENG, Yunfeng CHEN, Jianji REN, Yongliang YUAN. Method for life prediction of parallel branching engine based on multi-modal fusion features [J]. Journal of Computer Applications, 2026, 46(1): 305-313. |
| [2] | Hongjun ZHANG, Gaojun PAN, Hao YE, Yubin LU, Yiheng MIAO. Multi-source heterogeneous data analysis method combining deep learning and tensor decomposition [J]. Journal of Computer Applications, 2025, 45(9): 2838-2847. |
| [3] | Chao SHI, Yuxin ZHOU, Qian FU, Wanyu TANG, Ling HE, Yuanyuan LI. Action recognition algorithm for ADHD patients using skeleton and 3D heatmap [J]. Journal of Computer Applications, 2025, 45(9): 3036-3044. |
| [4] | Peng PENG, Ziting CAI, Wenling LIU, Caihua CHEN, Wei ZENG, Baolai HUANG. Speech emotion recognition method based on hybrid Siamese network with CNN and bidirectional GRU [J]. Journal of Computer Applications, 2025, 45(8): 2515-2521. |
| [5] | Jinhao LIN, Chuan LUO, Tianrui LI, Hongmei CHEN. Thoracic disease classification method based on cross-scale attention network [J]. Journal of Computer Applications, 2025, 45(8): 2712-2719. |
| [6] | Yongpeng TAO, Shiqi BAI, Zhengwen ZHOU. Neural architecture search for multi-tissue segmentation using convolutional and transformer-based networks in glioma segmentation [J]. Journal of Computer Applications, 2025, 45(7): 2378-2386. |
| [7] | Yingjun ZHANG, Weiwei YAN, Binhong XIE, Rui ZHANG, Wangdong LU. Gradient-discriminative and feature norm-driven open-world object detection [J]. Journal of Computer Applications, 2025, 45(7): 2203-2210. |
| [8] | Dan WANG, Wenhao ZHANG, Lijuan PENG. Channel estimation of reconfigurable intelligent surface assisted communication system based on deep learning [J]. Journal of Computer Applications, 2025, 45(5): 1613-1618. |
| [9] | Junyan ZHANG, Yiming ZHAO, Bing LIN, Yunping WU. Chinese image captioning method based on multi-level visual and dynamic text-image interaction [J]. Journal of Computer Applications, 2025, 45(5): 1520-1527. |
| [10] | Baohua YUAN, Jialu CHEN, Huan WANG. Medical image segmentation network integrating multi-scale semantics and parallel double-branch [J]. Journal of Computer Applications, 2025, 45(3): 988-995. |
| [11] | Dixin WANG, Jiahao WANG, Min LI, Hao CHEN, Guangyao HU, Yu GONG. Abnormal attack detection for underwater acoustic communication network [J]. Journal of Computer Applications, 2025, 45(2): 526-533. |
| [12] | Yonghong FAN, Heming HUANG. CnnPRL: progressive representation learning method for speech emotion recognition [J]. Journal of Computer Applications, 2025, 45(12): 3804-3812. |
| [13] | Jianhua REN, Jiahui CAO, Di JIA. Hand pose estimation based on mask prompts and attention [J]. Journal of Computer Applications, 2025, 45(12): 4012-4020. |
| [14] | Lifang WANG, Jingshuang WU, Pengliang YIN, Lihua HU. Action recognition algorithm based on attention mechanism and energy function [J]. Journal of Computer Applications, 2025, 45(1): 234-239. |
| [15] | Xinran XU, Shaobing ZHANG, Miao CHENG, Yang ZHANG, Shang ZENG. Bearings fault diagnosis method based on multi-pathed hierarchical mixture-of-experts model [J]. Journal of Computer Applications, 2025, 45(1): 59-68. |
| Viewed | ||||||
|
Full text |
|
|||||
|
Abstract |
|
|||||