


Journal of Computer Applications ›› 2024, Vol. 44 ›› Issue (10): 3217-3222.DOI: 10.11772/j.issn.1001-9081.2023101458
• Multimedia computing and computer simulation • Previous Articles Next Articles
Han WANG, Lasheng ZHAO( ), Qiang ZHANG, Yinqing CHENG, Zepeng QIU
), Qiang ZHANG, Yinqing CHENG, Zepeng QIU
Received:2023-10-27
Revised:2024-02-22
Accepted:2024-02-26
Online:2024-10-15
Published:2024-10-10
Contact:
Lasheng ZHAO
About author:WANG Han, born in 1998, M. S. candidate. Her research interests include deep learning, spoof speech detection.Supported by:
王晗, 赵腊生(), 张强, 程银清, 邱泽鹏
通讯作者:
赵腊生
作者简介:王晗(1998—),女,辽宁铁岭人,硕士研究生,主要研究方向:深度学习、语音鉴伪基金资助:CLC Number:
Han WANG, Lasheng ZHAO, Qiang ZHANG, Yinqing CHENG, Zepeng QIU. Dual branch synthetic speech detection based on attention and squeeze-excitation inception[J]. Journal of Computer Applications, 2024, 44(10): 3217-3222.
王晗, 赵腊生, 张强, 程银清, 邱泽鹏. 基于注意力和挤压‒激励Inception的双分支合成语音检测[J]. 《计算机应用》唯一官方网站, 2024, 44(10): 3217-3222.
Add to citation manager EndNote|Ris|BibTeX
URL: https://www.joca.cn/EN/10.11772/j.issn.1001-9081.2023101458
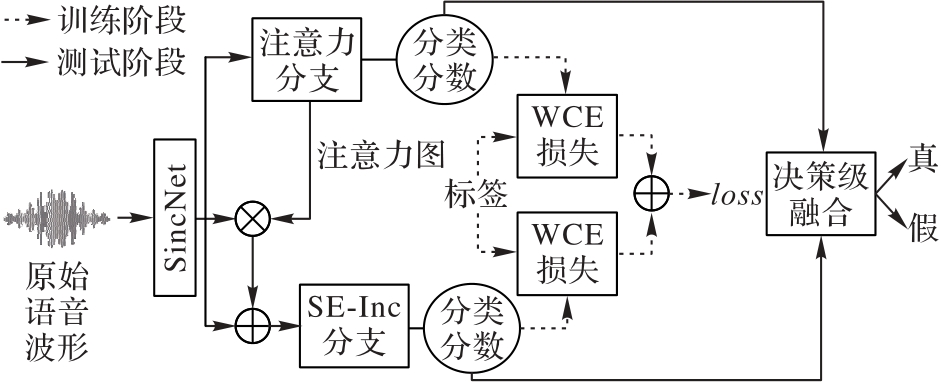
Fig. 1 Structure of Dual-ABIB model
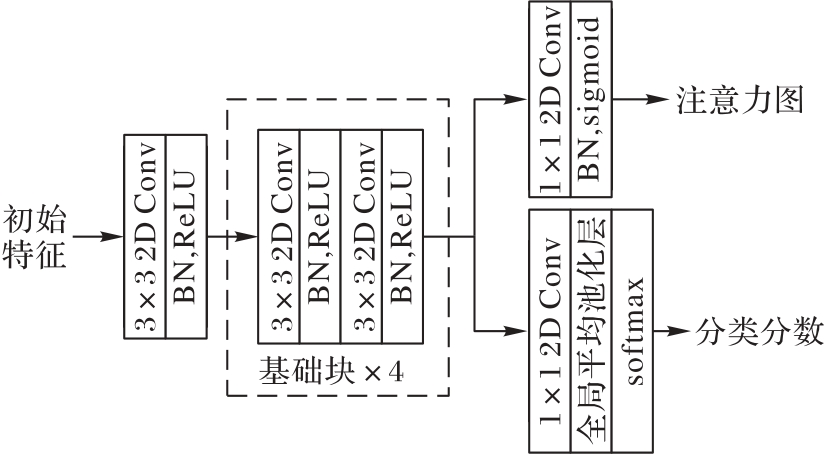
Fig. 2 Structure of attention branch network
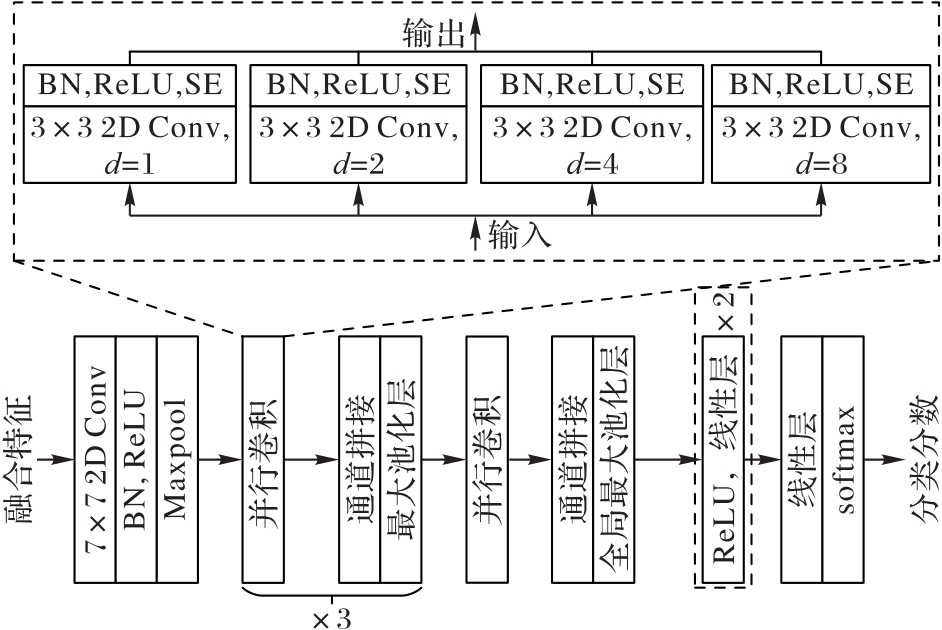
Fig. 3 Structure of SE-Inc branch network
| 子集 | 真实语音样本数 | 合成语音样本数 | 伪造种类 |
|---|---|---|---|
| 训练集 | 2 580 | 22 800 | A01~A06 |
| 开发集 | 2 548 | 22 296 | A01~A06 |
| 测试集 | 7 355 | 63 882 | A07~A19 |
Tab. 1 Details of ASVspoof2019LA dataset
| 子集 | 真实语音样本数 | 合成语音样本数 | 伪造种类 |
|---|---|---|---|
| 训练集 | 2 580 | 22 800 | A01~A06 |
| 开发集 | 2 548 | 22 296 | A01~A06 |
| 测试集 | 7 355 | 63 882 | A07~A19 |
| 模型 | EER |
|---|---|
| Inc-TSSDNet[ | 4.04 |
| Sinc-Attention | 3.89 |
| Sinc-Inception | 3.49 |
Tab. 2 Detection results of single-branch models
| 模型 | EER |
|---|---|
| Inc-TSSDNet[ | 4.04 |
| Sinc-Attention | 3.89 |
| Sinc-Inception | 3.49 |
| 测试模型 | EER |
|---|---|
| AB分支 | 1.81 |
| IB分支 | 1.63 |
| 加权融合 | 1.15 |
Tab. 3 Ablation experimental results of decision-level fusion
| 测试模型 | EER |
|---|---|
| AB分支 | 1.81 |
| IB分支 | 1.63 |
| 加权融合 | 1.15 |
| 方法 | EER/% | min t-DCF | 计算效率/ms | |
|---|---|---|---|---|
| Att | SE | |||
| × | × | 3.49 | 0.086 9 | 5.67 |
| × | √ | 2.13 | 0.066 2 | 7.17 |
| √ | × | 1.33 | 0.037 2 | 6.28 |
| √ | √ | 1.15 | 0.033 2 | 9.97 |
Tab. 4 Ablation experimental results of different modules
| 方法 | EER/% | min t-DCF | 计算效率/ms | |
|---|---|---|---|---|
| Att | SE | |||
| × | × | 3.49 | 0.086 9 | 5.67 |
| × | √ | 2.13 | 0.066 2 | 7.17 |
| √ | × | 1.33 | 0.037 2 | 6.28 |
| √ | √ | 1.15 | 0.033 2 | 9.97 |
| 模型 | 前端特征 | 测试集 | 参数量/103 | |
|---|---|---|---|---|
| EER/% | min t-DCF | |||
| RawNet2[ | Waveform | 4.66 | 0.129 4 | 25 430 |
| Inc-TSSDNet[ | Waveform | 4.04 | 0.097 6 | 92 |
| CapsNet[ | LFCC | 1.97 | 0.053 8 | — |
| LCNN-LSTM[ | LFCC | 1.92 | 0.052 4 | — |
| SE-ResABNet[ | LFCC | 1.89 | 0.050 7 | 964 |
| Raw PC-DARTS[ | Waveform | 1.77 | 0.051 7 | 24 480 |
| FPM+EM-Softmax[ | LFCC | 1.65 | 0.047 0 | — |
| LGF[ | Wav2Vec2.0 | 1.28 | 0.100 0 | — |
| Dual-ABIB | Waveform | 1.15 | 0.033 2 | 539 |
Tab. 5 Comparison of different models on ASVspoof2019LA test set
| 模型 | 前端特征 | 测试集 | 参数量/103 | |
|---|---|---|---|---|
| EER/% | min t-DCF | |||
| RawNet2[ | Waveform | 4.66 | 0.129 4 | 25 430 |
| Inc-TSSDNet[ | Waveform | 4.04 | 0.097 6 | 92 |
| CapsNet[ | LFCC | 1.97 | 0.053 8 | — |
| LCNN-LSTM[ | LFCC | 1.92 | 0.052 4 | — |
| SE-ResABNet[ | LFCC | 1.89 | 0.050 7 | 964 |
| Raw PC-DARTS[ | Waveform | 1.77 | 0.051 7 | 24 480 |
| FPM+EM-Softmax[ | LFCC | 1.65 | 0.047 0 | — |
| LGF[ | Wav2Vec2.0 | 1.28 | 0.100 0 | — |
| Dual-ABIB | Waveform | 1.15 | 0.033 2 | 539 |
| 模型 | EER | ||
|---|---|---|---|
| 19LA | 15LA | 21LA | |
| LFCC-GMM[ | 9.57 | 14.87 | 19.30 |
| CQCC-GMM[ | 8.09 | 36.31 | 15.62 |
| Inc-TSSDNet[ | 4.04 | 3.29 | 17.56 |
| AASIST[ | 1.13 | 3.22 | 10.90 |
| Dual-ABIB | 1.15 | 2.29 | 10.43 |
Tab. 6 Cross-dataset test results
| 模型 | EER | ||
|---|---|---|---|
| 19LA | 15LA | 21LA | |
| LFCC-GMM[ | 9.57 | 14.87 | 19.30 |
| CQCC-GMM[ | 8.09 | 36.31 | 15.62 |
| Inc-TSSDNet[ | 4.04 | 3.29 | 17.56 |
| AASIST[ | 1.13 | 3.22 | 10.90 |
| Dual-ABIB | 1.15 | 2.29 | 10.43 |
| 1 | SNYDER D, GARCIA-ROMERO D, SELL G, et al. X-vectors: robust DNN embeddings for speaker recognition[C]// Proceedings of the 2018 IEEE International Conference on Acoustics, Speech and Signal Processing. Piscataway: IEEE, 2018: 5329-5333. |
| 2 | KAUR N, SINGH P. Conventional and contemporary approaches used in text to speech synthesis: a review[J]. Artificial Intelligence Review, 2022, 56(7): 5837-5880. |
| 3 | SISMAN B, YAMAGISHI J, KING S, et al. An overview of voice conversion and its challenges: from statistical modeling to deep learning[J]. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 2021, 29: 132-157. |
| 4 | HU C, ZHOU R, YUAN Q. Replay speech detection based on dual-input hierarchical fusion network[J]. Applied Sciences, 2023, 13(9): No.5350. |
| 5 | 任延珍,刘晨雨,刘武洋,等. 语音伪造及检测技术研究综述[J]. 信号处理, 2021, 37(12): 2412-2439. |
| REN Y Z, LIU C Y, LIU W Y, et al. A survey on speech forgery and detection[J]. Journal of Signal Processing, 2021, 37(12): 2412-2439. | |
| 6 | WEI L, LONG Y, WEI H, et al. New acoustic features for synthetic and replay spoofing attack detection[J]. Symmetry, 2022, 14(2): No.274. |
| 7 | TODISCO M, DELGADO H, EVANS N. Constant Q cepstral coefficients: a spoofing countermeasure for automatic speaker verification[J]. Computer Speech and Language, 2017, 45: 516-535. |
| 8 | PATEL T B, PATIL H A. Combining evidences from mel cepstral, cochlear filter cepstral and instantaneous frequency features for detection of natural vs. spoofed speech[C]// Proceedings of the INTERSPEECH 2015. [S.l.]: International Speech Communication Association, 2015: 2062-2066. |
| 9 | CUI S, HUANG B, HUANG J, et al. Synthetic speech detection based on local autoregression and variance statistics[J]. IEEE Signal Processing Letters, 2022, 29: 1462-1466. |
| 10 | RAVANELLI M, BENGIO Y. Speaker recognition from raw waveform with SincNet[C]// Proceedings of the 2018 IEEE Spoken Language Technology Workshop. Piscataway: IEEE, 2018: 1021-1028. |
| 11 | DINKEL H, CHEN N, QIAN Y, et al. End-to-end spoofing detection with raw waveform CLDNNS[C]// Proceedings of the 2017 IEEE International Conference on Acoustics, Speech and Signal Processing. Piscataway: IEEE, 2017: 4860-4864. |
| 12 | MA Y, REN Z, XU S. RW-ResNet: a novel speech anti-spoofing model using raw waveform[C]// Proceedings of the INTERSPEECH 2021. [S.l.]: International Speech Communication Association, 2021: 4144-4148. |
| 13 | TAK H, PATINO J, TODISCO M, et al. End-to-end anti-spoofing with RawNet2[C]// Proceedings of the 2021 IEEE International Conference on Acoustics, Speech and Signal Processing. Piscataway: IEEE, 2021: 6369-6373. |
| 14 | JUNG J W, HEO H S, TAK H, et al. AASIST: audio anti-spoofing using integrated spectro-temporal graph attention networks[C]// Proceedings of the 2022 IEEE International Conference on Acoustics, Speech and Signal Processing. Piscataway: IEEE, 2022: 6367-6371. |
| 15 | ALZANTOT M, WANG Z, SRIVASTAVA M B. Deep residual neural networks for audio spoofing detection[C]// Proceedings of the INTERSPEECH 2019. [S.l.]: International Speech Communication Association, 2019: 1078-1082. |
| 16 | WU Z, DAS R K, YANG J, et al. Light convolutional neural network with feature genuinization for detection of synthetic speech attacks[C]// Proceedings of the INTERSPEECH 2020. [S.l.]: International Speech Communication Association, 2020: 1101-1105. |
| 17 | LUO A, LI E, LIU Y, et al. A capsule network based approach for detection of audio spoofing attacks[C]// Proceedings of the 2021 IEEE International Conference on Acoustics, Speech and Signal Processing. Piscataway: IEEE, 2021: 6359-6363. |
| 18 | HUA G, TEOH A B J, ZHANG H. Towards end-to-end synthetic speech detection[J]. IEEE Signal Processing Letters, 2021, 28: 1265-1269. |
| 19 | SZEGEDY C, LIU W, JIA Y, et al. Going deeper with convolutions[C]// Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2015: 1-9. |
| 20 | LIU X, LIU M, WANG L, et al. Leveraging positional-related local-global dependency for synthetic speech detection[C]// Proceedings of the 2023 IEEE International Conference on Acoustics, Speech and Signal Processing. Piscataway: IEEE, 2023: 1-5. |
| 21 | FUKUI H, HIRAKAWA T, YAMASHITA T, et al. Attention branch network: learning of attention mechanism for visual explanation[C]// Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2019: 10697-10706. |
| 22 | 张秋余,王煜坤. 基于改进Inception网络的语音分类模型[J]. 计算机应用, 2023, 43(3): 909-915. |
| ZHANG Q Y, WANG Y K. Speech classification model based on improved Inception network[J]. Journal of Computer Applications, 2023, 43(3):909-915. | |
| 23 | HU J, SHEN L, SUN G. Squeeze-and-excitation networks[C]// Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2018: 7132-7141. |
| 24 | WANG X, YAMAGISHI J, TODISCO M, et al. ASVspoof 2019: a large-scale public database of synthesized, converted and replayed speech[J]. Computer Speech and Language, 2020, 64: No.101114 . |
| 25 | WU Z, KINNUNEN T, EVANS N, et al. ASVspoof 2015: the first automatic speaker verification spoofing and countermeasures challenge[C]// Proceedings of the INTERSPEECH 2015. [S.l.]: International Speech Communication Association, 2015: 2037-2041. |
| 26 | LIU X, WANG X, SAHIDULLAH M, et al. ASVspoof 2021: towards spoofed and deepfake speech detection in the wild[J]. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 2023, 31: 2507-2522. |
| 27 | BRÜMMER N, DE VILLIERS E. The BOSARIS Toolkit user guide: theory, algorithms and code for binary classifier score processing[EB/OL]. (2013-04-10) [2023-08-10]. . |
| 28 | KINNUNEN T, DELGADO H, EVANS N, et al. Tandem assessment of spoofing countermeasures and automatic speaker verification: fundamentals[J]. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 2020, 28: 2195-2210. |
| 29 | WANG X, YAMAGISHI J. A comparative study on recent neural spoofing countermeasures for synthetic speech detection[C]// Proceedings of the INTERSPEECH 2021. [S.l.]: International Speech Communication Association, 2021: 4259-4263. |
| 30 | ROSTAMI A M, HOMAYOUNPOUR M M, NICKABADI A. Efficient attention branch network with combined loss function for automatic speaker verification spoof detection[J]. Circuits, Systems, and Signal Processing, 2023, 42(7): 4252-4270. |
| 31 | GE W, PATINO J, TODISCO M, et al. Raw differentiable architecture Search for speech deepfake and spoofing detection[C]// Proceedings of the 2021 Edition of the Automatic Speaker Verification and Spoofing Countermeasures Challenge. [S.l.]: International Speech Communication Association, 2021: 22-28. |
| 32 | GONG J, CHEN N. Synthetic voice spoofing detection based on feature pyramid conformer[C]// Proceedings of the INTERSPEECH 2023. [S.l.]: International Speech Communication Association, 2023: 2803-2807. |
| 33 | WANG X, YAMAGISHI J. Investigating self-supervised front ends for speech spoofing countermeasures[C]// Proceedings of the 2021 Speaker and Language Recognition Workshop. [S.l.]: International Speech Communication Association, 2022: 100-106. |
| [1] | Zhiqiang ZHAO, Peihong MA, Xinhong HEI. Crowd counting method based on dual attention mechanism [J]. Journal of Computer Applications, 2024, 44(9): 2886-2892. |
| [2] | Jing QIN, Zhiguang QIN, Fali LI, Yueheng PENG. Diagnosis of major depressive disorder based on probabilistic sparse self-attention neural network [J]. Journal of Computer Applications, 2024, 44(9): 2970-2974. |
| [3] | Liting LI, Bei HUA, Ruozhou HE, Kuang XU. Multivariate time series prediction model based on decoupled attention mechanism [J]. Journal of Computer Applications, 2024, 44(9): 2732-2738. |
| [4] | Kaipeng XUE, Tao XU, Chunjie LIAO. Multimodal sentiment analysis network with self-supervision and multi-layer cross attention [J]. Journal of Computer Applications, 2024, 44(8): 2387-2392. |
| [5] | Pengqi GAO, Heming HUANG, Yonghong FAN. Fusion of coordinate and multi-head attention mechanisms for interactive speech emotion recognition [J]. Journal of Computer Applications, 2024, 44(8): 2400-2406. |
| [6] | Zhonghua LI, Yunqi BAI, Xuejin WANG, Leilei HUANG, Chujun LIN, Shiyu LIAO. Low illumination face detection based on image enhancement [J]. Journal of Computer Applications, 2024, 44(8): 2588-2594. |
| [7] | Shangbin MO, Wenjun WANG, Ling DONG, Shengxiang GAO, Zhengtao YU. Single-channel speech enhancement based on multi-channel information aggregation and collaborative decoding [J]. Journal of Computer Applications, 2024, 44(8): 2611-2617. |
| [8] | Wu XIONG, Congjun CAO, Xuefang SONG, Yunlong SHAO, Xusheng WANG. Handwriting identification method based on multi-scale mixed domain attention mechanism [J]. Journal of Computer Applications, 2024, 44(7): 2225-2232. |
| [9] | Huanhuan LI, Tianqiang HUANG, Xuemei DING, Haifeng LUO, Liqing HUANG. Public traffic demand prediction based on multi-scale spatial-temporal graph convolutional network [J]. Journal of Computer Applications, 2024, 44(7): 2065-2072. |
| [10] | Dianhui MAO, Xuebo LI, Junling LIU, Denghui ZHANG, Wenjing YAN. Chinese entity and relation extraction model based on parallel heterogeneous graph and sequential attention mechanism [J]. Journal of Computer Applications, 2024, 44(7): 2018-2025. |
| [11] | Li LIU, Haijin HOU, Anhong WANG, Tao ZHANG. Generative data hiding algorithm based on multi-scale attention [J]. Journal of Computer Applications, 2024, 44(7): 2102-2109. |
| [12] | Song XU, Wenbo ZHANG, Yifan WANG. Lightweight video salient object detection network based on spatiotemporal information [J]. Journal of Computer Applications, 2024, 44(7): 2192-2199. |
| [13] | Dahai LI, Zhonghua WANG, Zhendong WANG. Dual-branch low-light image enhancement network combining spatial and frequency domain information [J]. Journal of Computer Applications, 2024, 44(7): 2175-2182. |
| [14] | Wenliang WEI, Yangping WANG, Biao YUE, Anzheng WANG, Zhe ZHANG. Deep learning model for infrared and visible image fusion based on illumination weight allocation and attention [J]. Journal of Computer Applications, 2024, 44(7): 2183-2191. |
| [15] | Yan ZHOU, Yang LI. Rectified cross pseudo supervision method with attention mechanism for stroke lesion segmentation [J]. Journal of Computer Applications, 2024, 44(6): 1942-1948. |
| Viewed | ||||||
|
Full text |
|
|||||
|
Abstract |
|
|||||