


Journal of Computer Applications ›› 2024, Vol. 44 ›› Issue (8): 2334-2341.DOI: 10.11772/j.issn.1001-9081.2023081079
• Artificial intelligence • Previous Articles Next Articles
Yi ZHOU( ), Hua GAO, Yongshen TIAN
), Hua GAO, Yongshen TIAN
Received:2023-08-10
Revised:2023-10-15
Accepted:2023-10-24
Online:2023-12-18
Published:2024-08-10
Contact:
Yi ZHOU
About author:ZHOU Yi, born in 1983, Ph. D., associate professor. His researchinterests include swarm intelligence optimization, deep reinforcementlearning.Supported by:
周毅(), 高华, 田永谌
通讯作者:
周毅
作者简介:周毅(1983—),男,湖北汉川人,副教授,博士,CCF会员,主要研究方向:群体智能优化、深度强化学习 zhouyi83@wust.edu.cn基金资助:CLC Number:
Yi ZHOU, Hua GAO, Yongshen TIAN. Proximal policy optimization algorithm based on clipping optimization and policy guidance[J]. Journal of Computer Applications, 2024, 44(8): 2334-2341.
周毅, 高华, 田永谌. 基于裁剪优化和策略指导的近端策略优化算法[J]. 《计算机应用》唯一官方网站, 2024, 44(8): 2334-2341.
Add to citation manager EndNote|Ris|BibTeX
URL: https://www.joca.cn/EN/10.11772/j.issn.1001-9081.2023081079

Fig. 1 Policy guidance process based on simulated annealing
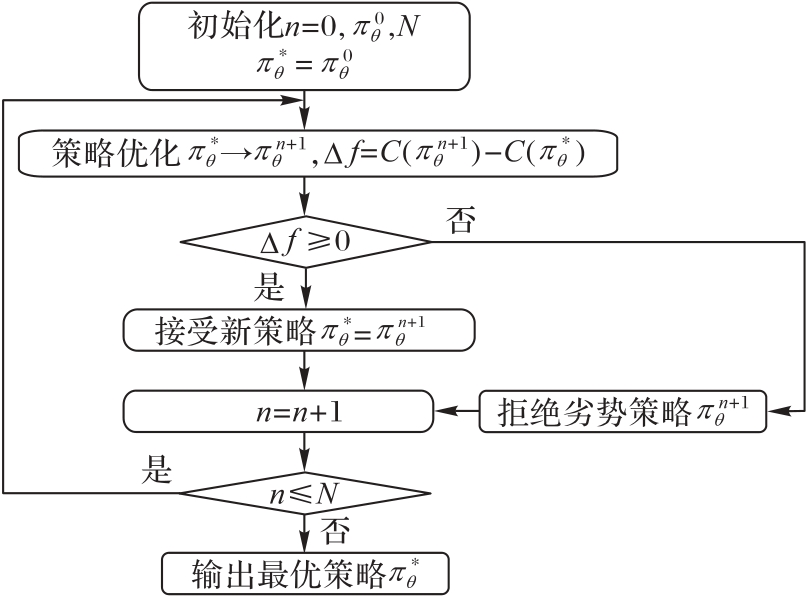
Fig. 2 Policy guidance process based on greedy algorithm

Fig. 3 Exploration and exploitation balance in tasks of different dimensions

Fig. 4 Model architecture of COAPG-PPO algorithm
| 任务 | 状态 维度 | 动作 维度 | 任务 | 状态 维度 | 动作 维度 |
|---|---|---|---|---|---|
| Swimmer-v2 | 8 | 2 | Humanoid-v2 | 376 | 17 |
| Reacher-v2 | 11 | 2 | HumanoidStandup-v2 | 376 | 17 |
| Walker2d-v2 | 17 | 6 |
Tab. 1 State dimensions and action dimensions of experimental tasks
| 任务 | 状态 维度 | 动作 维度 | 任务 | 状态 维度 | 动作 维度 |
|---|---|---|---|---|---|
| Swimmer-v2 | 8 | 2 | Humanoid-v2 | 376 | 17 |
| Reacher-v2 | 11 | 2 | HumanoidStandup-v2 | 376 | 17 |
| Walker2d-v2 | 17 | 6 |
| 任务 | 初始 阈值 | 衰减 系数 | 任务 | 初始 阈值 | 衰减 系数 |
|---|---|---|---|---|---|
| Swimmer-v2 | 0.10 | 0.010 | Humanoid-v2 | 0.14 | 0.010 |
| Reacher-v2 | 0.04 | 0.016 | HumanoidStandup-v2 | 0.13 | 0.004 |
| Walker2d-v2 | 0.10 | 0.008 |
Tab. 2 Initial threshold and attenuation parameter setting for CO-PPO algorithm
| 任务 | 初始 阈值 | 衰减 系数 | 任务 | 初始 阈值 | 衰减 系数 |
|---|---|---|---|---|---|
| Swimmer-v2 | 0.10 | 0.010 | Humanoid-v2 | 0.14 | 0.010 |
| Reacher-v2 | 0.04 | 0.016 | HumanoidStandup-v2 | 0.13 | 0.004 |
| Walker2d-v2 | 0.10 | 0.008 |
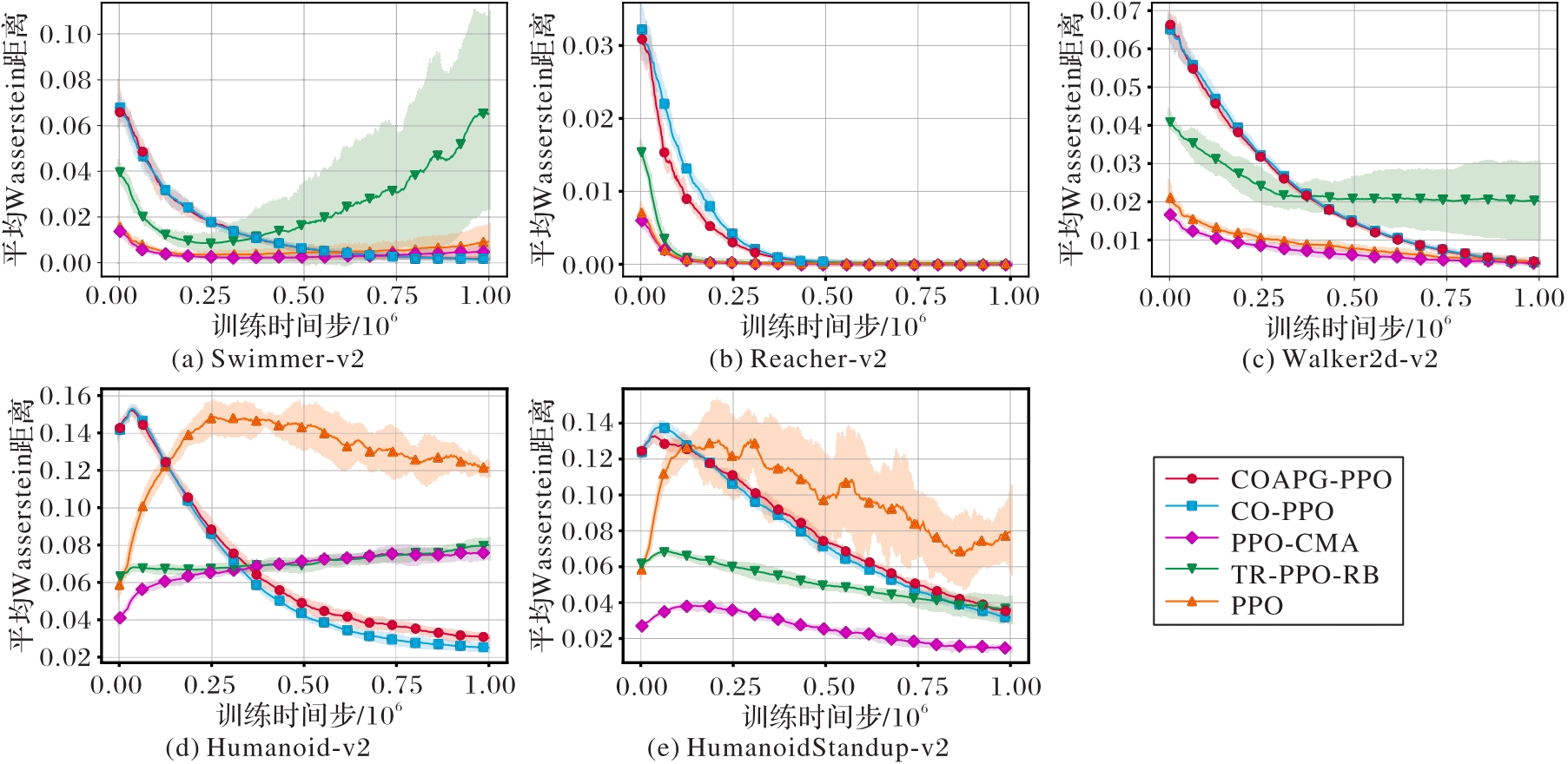
Fig. 5 Constraint comparison experiment results of various algorithms
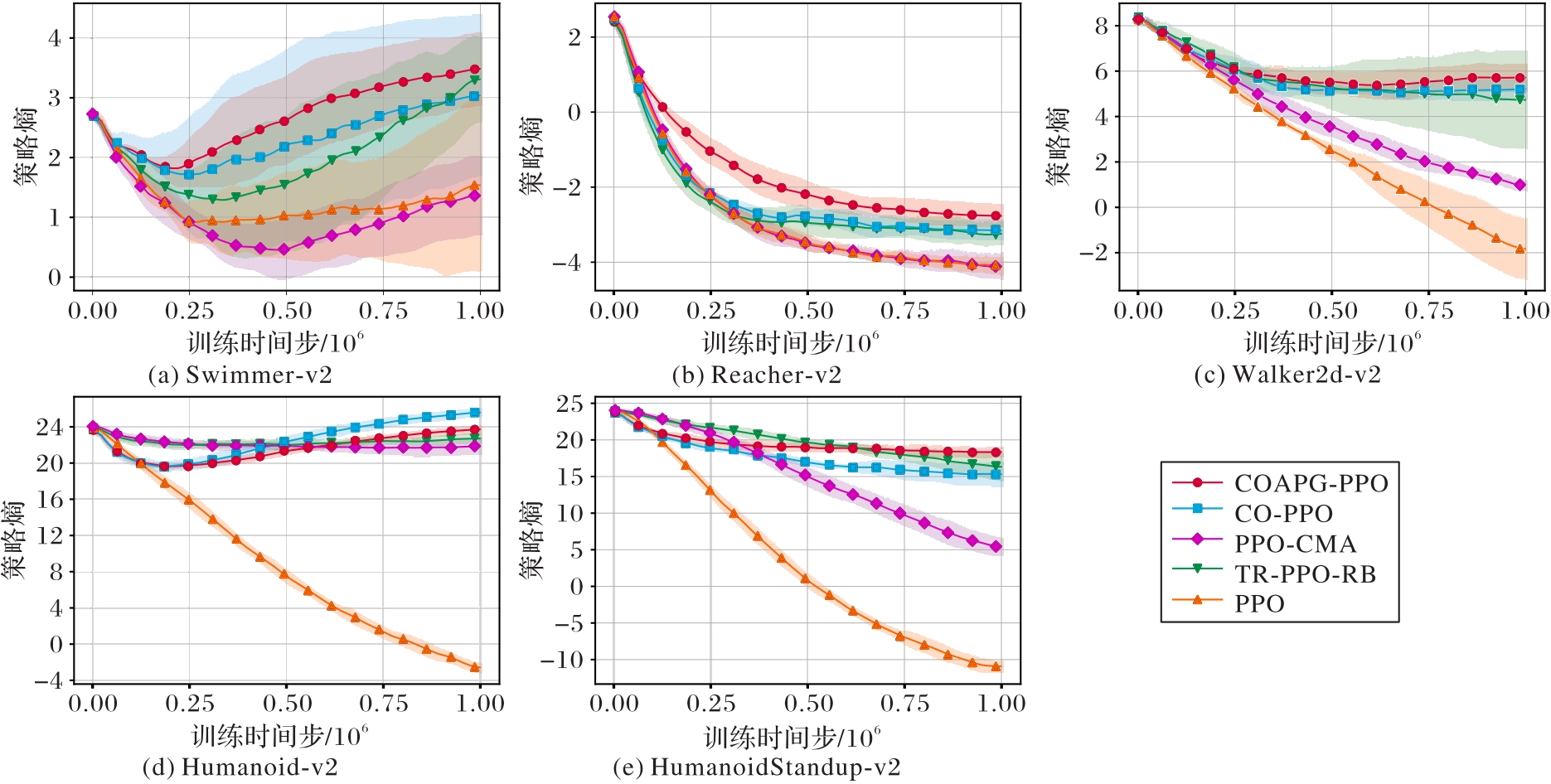
Fig. 6 Exploration comparison experiment results of various algorithms

Fig. 7 Performance comparison experiment results of various algorithms
| 算法 | Swimmer-v2 | Reacher-v2 | Walker2d-v2 | Humanoid-v2 | HumanoidStandup-v2 |
|---|---|---|---|---|---|
| PPO | 102.95 | -8.70 | 3 310.04 | 506.26 | 105 795.94 |
| TR-PPO-RB | 97.70 | -7.74 | 3 786.54 | 530.88 | 140 587.55 |
| PPO-CMA | 119.17 | -7.92 | 3 942.12 | 598.77 | 150 800.39 |
| CO-PPO | 86.51 | -7.05 | 4 294.67 | 539.33 | 143 369.69 |
| COAPG-PPO | 111.01 | -6.37 | 4670.17 | 638.98 | 162024.21 |
Tab. 3 Average rewards of various algorithms in last 40% episodes
| 算法 | Swimmer-v2 | Reacher-v2 | Walker2d-v2 | Humanoid-v2 | HumanoidStandup-v2 |
|---|---|---|---|---|---|
| PPO | 102.95 | -8.70 | 3 310.04 | 506.26 | 105 795.94 |
| TR-PPO-RB | 97.70 | -7.74 | 3 786.54 | 530.88 | 140 587.55 |
| PPO-CMA | 119.17 | -7.92 | 3 942.12 | 598.77 | 150 800.39 |
| CO-PPO | 86.51 | -7.05 | 4 294.67 | 539.33 | 143 369.69 |
| COAPG-PPO | 111.01 | -6.37 | 4670.17 | 638.98 | 162024.21 |
| 任务 | 奖励阈值 | 各算法达到奖励阈值的时间步/103 | ||||
|---|---|---|---|---|---|---|
| PPO | TR-PPO-RB | PPO-CMA | CO-PPO | COAPG-PPO | ||
| Swimmer-v2 | 80 | 370 | 558 | 434 | 260 | 276 |
| Reacher-v2 | -8 | 668 | 636 | 641 | 483 | 397 |
| Walker2d-v2 | 3 000 | 409 | 423 | 470 | 299 | 255 |
| Humanoid-v2 | 500 | 179 | 500 | 385 | 292 | 247 |
| HumanoidStandup-v2 | 110 000 | 224 | 287 | 283 | 323 | 162 |
Tab. 4 Timesteps for various algorithms to reach reward thresholds
| 任务 | 奖励阈值 | 各算法达到奖励阈值的时间步/103 | ||||
|---|---|---|---|---|---|---|
| PPO | TR-PPO-RB | PPO-CMA | CO-PPO | COAPG-PPO | ||
| Swimmer-v2 | 80 | 370 | 558 | 434 | 260 | 276 |
| Reacher-v2 | -8 | 668 | 636 | 641 | 483 | 397 |
| Walker2d-v2 | 3 000 | 409 | 423 | 470 | 299 | 255 |
| Humanoid-v2 | 500 | 179 | 500 | 385 | 292 | 247 |
| HumanoidStandup-v2 | 110 000 | 224 | 287 | 283 | 323 | 162 |
| 1 | MNIH V, KAVUKCUOGLU K, SILVER D, et al. Human-level control through deep reinforcement learning [J]. Nature, 2015, 518(7540): 529-533. |
| 2 | LUONG N C, HOANG D T, GONG S, et al. Applications of deep reinforcement learning in communications and networking: a survey [J]. IEEE Communications Surveys & Tutorials, 2019, 21(4): 3133-3174. |
| 3 | 刘全,翟建伟,章宗长,等.深度强化学习综述[J]. 计算机学报,2018,41(1): 1-27. |
| LIU Q, ZHAI J W, ZHANG Z Z, et al. A survey on deep reinforcement learning [J]. Chinese Journal of Computers, 2018, 41(1): 1-27. | |
| 4 | AFSAR M M, CRUMP T, FAR B. Reinforcement learning based recommender systems: a survey [EB/OL]. (2022-06-08)[2023-08-01]. . |
| 5 | 王雪松,王荣荣,程玉虎.安全强化学习综述[J].自动化学报,2023,49(9): 1813-1835. |
| WANG X S, WANG R R, CHENG Y H. Safety reinforcement learning: a survey [J]. Acta Automatica Sinica, 2023, 49(9): 1813-1835. | |
| 6 | KOHL N, STONE P. Policy gradient reinforcement learning for fast quadrupedal locomotion [C]// Proceedings of the 2004 IEEE International Conference on Robotics and Automation. Piscataway: IEEE, 2004, 3: 2619-2624. |
| 7 | PETERS J, SCHAAL S. Reinforcement learning of motor skills with policy gradients [J]. Neural Networks, 2008, 21(4): 682-697. |
| 8 | SCHULMAN J, LEVINE S, MORITZ P, et al. Trust region policy optimization [C]// Proceedings of the 32nd International Conference on Machine Learning. New York: JMLR.org, 2015: 1889-1897. |
| 9 | SCHULMAN J, WOLSKI F, DHARIWAL P, et al. Proximal policy optimization algorithms [EB/OL]. (2017-08-28) [2023-06-28]. . |
| 10 | WANG Y, HE H, TAN X. Truly proximal policy optimization [C]// Proceedings of the 35th Uncertainty in Artificial Intelligence Conference. New York: JMLR.org, 2020: 113-122. |
| 11 | CHENG Y, HUANG L, WANG X. Authentic boundary proximal policy optimization [J]. IEEE Transactions on Cybernetics, 2021, 52(9): 9428-9438. |
| 12 | ZHANG L, SHEN L, YANG L, et al. Penalized proximal policy optimization for safe reinforcement learning [EB/OL]. (2022-06-17) [2023-06-29]. . |
| 13 | GU Y, CHENG Y, CHEN C L P, et al. Proximal policy optimization with policy feedback [J]. IEEE Transactions on Systems, Man, and Cybernetics: Systems, 2021, 52(7): 4600-4610. |
| 14 | KOBAYASHI T. Proximal policy optimization with relative pearson divergence [C]// Proceedings of the 2021 IEEE International Conference on Robotics and Automation. Piscataway: IEEE, 2021: 8416-8421. |
| 15 | QUEENEY J, PASCHALIDIS Y, CASSANDRAS C G. Generalized proximal policy optimization with sample reuse [C]// Proceedings of the 35th Conference on Neural Information Processing Systems. La Jolla, CA: NIPS, 2021: 11909-11919. |
| 16 | 张峻伟, 吕帅, 张正昊,等.基于样本效率优化的深度强化学习方法综述[J]. 软件学报,2022,33(11): 4217-4238. |
| ZHANG J W, LYU S, ZHANG Z H, et al. Survey on deep reinforcement learning methods based on sample efficiency optimization [J]. Journal of Software, 2022, 33(11): 4217-4238. | |
| 17 | TODOROV E, EREZ T, TASSA Y. MuJoCo: a physics engine for model-based control [C]// Proceedings of the 2012 IEEE/RSJ International Conference on Intelligent Robots and Systems. Piscataway: IEEE, 2012: 5026-5033. |
| 18 | HÄMÄLÄINEN P, BABADI A, MA X, et al. PPO-CMA: proximal policy optimization with covariance matrix adaptation [C]// Proceedings of the 2020 IEEE 30th International Workshop on Machine Learning for Signal Processing. Piscataway: IEEE, 2020: 1-6. |
| 19 | PANARETOS V M, ZEMEL Y. Statistical aspects of Wasserstein distances [J]. Annual Review of Statistics and Its Application, 2019, 6: 405-431. |
| 20 | BERTSIMAS D, TSITSIKLIS J. Simulated annealing [J]. Statistical Science, 1993, 8(1): 10-15. |
| 21 | VINCE A. A framework for the greedy algorithm [J]. Discrete Applied Mathematics, 2002, 121(1/2/3): 247-260. |
| [1] | Tian MA, Runtao XI, Jiahao LYU, Yijie ZENG, Jiayi YANG, Jiehui ZHANG. Mobile robot 3D space path planning method based on deep reinforcement learning [J]. Journal of Computer Applications, 2024, 44(7): 2055-2064. |
| [2] | Yan LI, Dazhi PAN, Siqing ZHENG. Improved adaptive large neighborhood search algorithm for multi-depot vehicle routing problem with time window [J]. Journal of Computer Applications, 2024, 44(6): 1897-1904. |
| [3] | Xiaoyan ZHAO, Wei HAN, Junna ZHANG, Peiyan YUAN. Collaborative offloading strategy in internet of vehicles based on asynchronous deep reinforcement learning [J]. Journal of Computer Applications, 2024, 44(5): 1501-1510. |
| [4] | Rui TANG, Chuanlin PANG, Ruizhi ZHANG, Chuan LIU, Shibo YUE. DDPG-based resource allocation in D2D communication-empowered cellular network [J]. Journal of Computer Applications, 2024, 44(5): 1562-1569. |
| [5] | Xintong QIN, Zhengyu SONG, Tianwei HOU, Feiyue WANG, Xin SUN, Wei LI. Channel access and resource allocation algorithm for adaptive p-persistent mobile ad hoc network [J]. Journal of Computer Applications, 2024, 44(3): 863-868. |
| [6] | Fuqin DENG, Huifeng GUAN, Chaoen TAN, Lanhui FU, Hongmin WANG, Tinlun LAM, Jianmin ZHANG. Multi-robot reinforcement learning path planning method based on request-response communication mechanism and local attention mechanism [J]. Journal of Computer Applications, 2024, 44(2): 432-438. |
| [7] | Yuanchao LI, Chongben TAO, Chen WANG. Gait control method based on maximum entropy deep reinforcement learning for biped robot [J]. Journal of Computer Applications, 2024, 44(2): 445-451. |
| [8] | Jiachen YU, Ye YANG. Irregular object grasping by soft robotic arm based on clipped proximal policy optimization algorithm [J]. Journal of Computer Applications, 2024, 44(11): 3629-3638. |
| [9] | Jie LONG, Liang XIE, Haijiao XU. Integrated deep reinforcement learning portfolio model [J]. Journal of Computer Applications, 2024, 44(1): 300-310. |
| [10] | Yu WANG, Tianjun REN, Zilin FAN. Air combat maneuver decision-making of unmanned aerial vehicle based on guided Minimax-DDQN [J]. Journal of Computer Applications, 2023, 43(8): 2636-2643. |
| [11] | Ziteng WANG, Yaxin YU, Zifang XIA, Jiaqi QIAO. Sparse reward exploration mechanism fusing curiosity and policy distillation [J]. Journal of Computer Applications, 2023, 43(7): 2082-2090. |
| [12] | Heping FANG, Shuguang LIU, Yongyi RAN, Kunhua ZHONG. Integrated scheduling optimization of multiple data centers based on deep reinforcement learning [J]. Journal of Computer Applications, 2023, 43(6): 1884-1892. |
| [13] | Xiaolin LI, Yusang JIANG. Task offloading algorithm for UAV-assisted mobile edge computing [J]. Journal of Computer Applications, 2023, 43(6): 1893-1899. |
| [14] | Xiaohui HUANG, Kaiming YANG, Jiahao LING. Order dispatching by multi-agent reinforcement learning based on shared attention [J]. Journal of Computer Applications, 2023, 43(5): 1620-1624. |
| [15] | Tengfei CAO, Yanliang LIU, Xiaoying WANG. Edge computing and service offloading algorithm based on improved deep reinforcement learning [J]. Journal of Computer Applications, 2023, 43(5): 1543-1550. |
| Viewed | ||||||
|
Full text |
|
|||||
|
Abstract |
|
|||||