


Journal of Computer Applications ›› 2025, Vol. 45 ›› Issue (10): 3154-3160.DOI: 10.11772/j.issn.1001-9081.2024101478
• Artificial intelligence • Previous Articles
Ziyi WANG1, Weijun LI1,2( ), Xueyang LIU1, Jianping DING1, Shixia LIU1, Yilei SU1
), Xueyang LIU1, Jianping DING1, Shixia LIU1, Yilei SU1
Received:2024-10-22
Revised:2024-12-03
Accepted:2024-12-09
Online:2024-12-17
Published:2025-10-10
Contact:
Weijun LI
About author:WANG Ziyi, born in 2001, M. S. candidate. Her research interests include image caption, natural language processing.Supported by:
王子怡1, 李卫军1,2(), 刘雪洋1, 丁建平1, 刘世侠1, 苏易礌1
通讯作者:
李卫军
作者简介:王子怡(2001—),女,山东泰安人,硕士研究生,CCF会员,主要研究方向:图像描述、自然语言处理基金资助:CLC Number:
Ziyi WANG, Weijun LI, Xueyang LIU, Jianping DING, Shixia LIU, Yilei SU. Image caption method based on Swin Transformer and multi-scale feature fusion[J]. Journal of Computer Applications, 2025, 45(10): 3154-3160.
王子怡, 李卫军, 刘雪洋, 丁建平, 刘世侠, 苏易礌. 基于Swin Transformer与多尺度特征融合的图像描述方法[J]. 《计算机应用》唯一官方网站, 2025, 45(10): 3154-3160.
Add to citation manager EndNote|Ris|BibTeX
URL: https://www.joca.cn/EN/10.11772/j.issn.1001-9081.2024101478
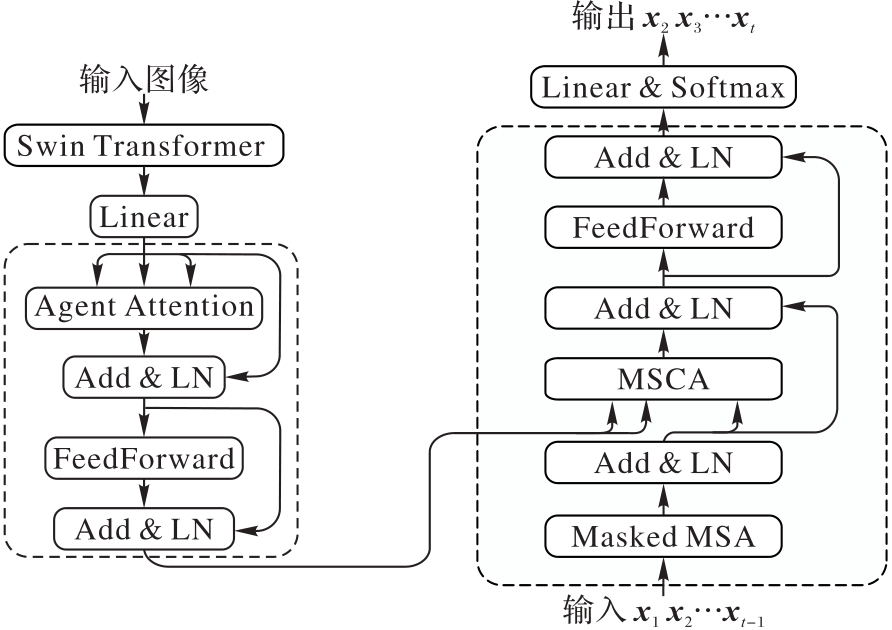
Fig. 1 Architecture of STMSF model
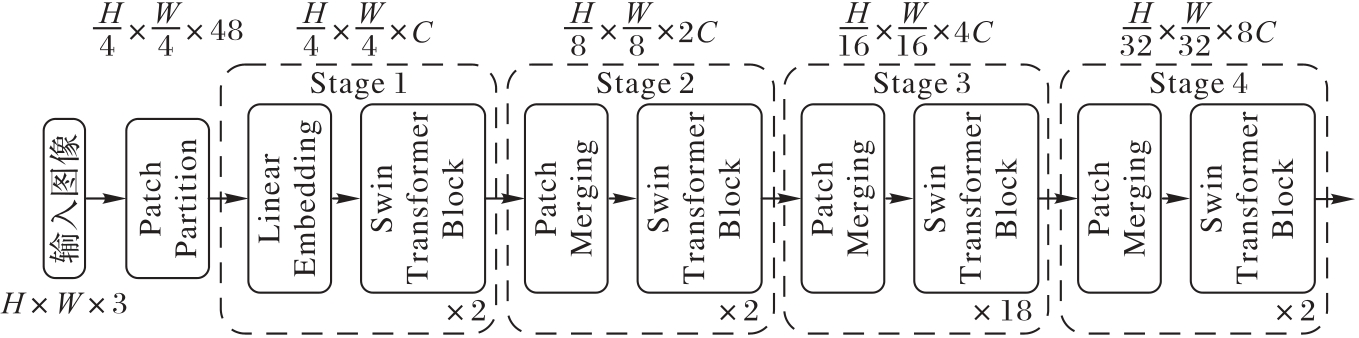
Fig. 2 Network structure of Swin Transformer
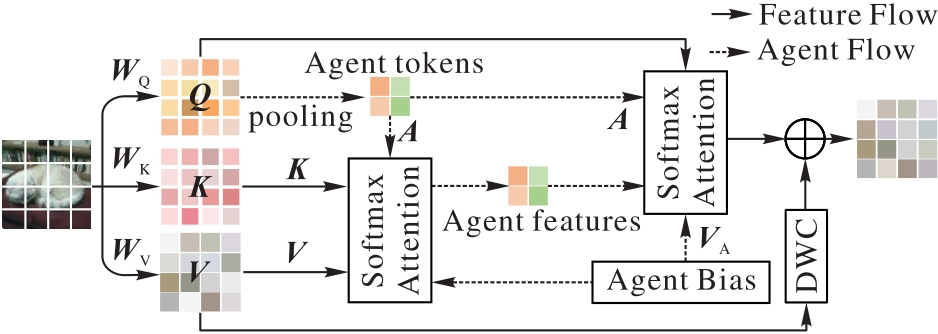
Fig. 3 Structure of Agent Attention
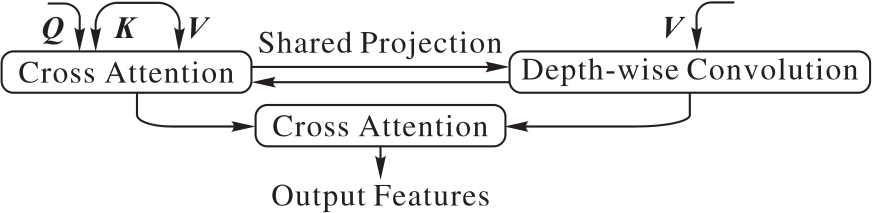
Fig. 4 Structure of MSCA
| 类别 | 方法 | B1 | B4 | M | R | C | S |
|---|---|---|---|---|---|---|---|
| CNN-RNN | SCST | — | 34.2 | 26.7 | 55.7 | 114.0 | — |
| Up-Down | 79.8 | 36.3 | 27.7 | 56.9 | 120.1 | 21.4 | |
| GCN-LSTM | 80.5 | 38.2 | 28.5 | 58.3 | 127.6 | 22.0 | |
| AoANet | 80.2 | 38.9 | 29.2 | 58.8 | 129.8 | 22.4 | |
| X-LAN | 80.8 | 39.5 | 29.5 | 59.2 | 132.0 | 23.4 | |
| VRCDA | 80.6 | 37.9 | 28.4 | 58.2 | 123.7 | 21.8 | |
| Transformer | X-Transformer | 80.9 | 39.7 | 29.5 | 59.1 | 132.8 | 23.4 |
| M2 Transformer | 80.8 | 39.1 | 29.2 | 58.6 | 131.2 | 22.6 | |
| RSTNet | 81.8 | 40.1 | 29.8 | 59.5 | 135.6 | 23.3 | |
| DLCT | 81.4 | 39.8 | 29.5 | 59.1 | 133.8 | 23.0 | |
| GAT | 80.8 | 39.7 | 29.1 | 59.0 | 130.5 | 22.9 | |
| A2 Transformer | 81.5 | 39.8 | 29.6 | 59.1 | 133.9 | 23.0 | |
| S2 Transformer | 81.1 | 39.6 | 29.6 | 59.1 | 133.5 | 23.2 | |
| LSTNet | 81.5 | 40.3 | 29.6 | 59.4 | 134.8 | 23.1 | |
| SCD-Net | 81.3 | 39.4 | 29.2 | 59.1 | 131.6 | 23.0 | |
| STMSF | 82.2 | 40.5 | 30.0 | 59.9 | 136.9 | 23.9 |
Tab. 1 Performance comparison on MSCOCO test set
| 类别 | 方法 | B1 | B4 | M | R | C | S |
|---|---|---|---|---|---|---|---|
| CNN-RNN | SCST | — | 34.2 | 26.7 | 55.7 | 114.0 | — |
| Up-Down | 79.8 | 36.3 | 27.7 | 56.9 | 120.1 | 21.4 | |
| GCN-LSTM | 80.5 | 38.2 | 28.5 | 58.3 | 127.6 | 22.0 | |
| AoANet | 80.2 | 38.9 | 29.2 | 58.8 | 129.8 | 22.4 | |
| X-LAN | 80.8 | 39.5 | 29.5 | 59.2 | 132.0 | 23.4 | |
| VRCDA | 80.6 | 37.9 | 28.4 | 58.2 | 123.7 | 21.8 | |
| Transformer | X-Transformer | 80.9 | 39.7 | 29.5 | 59.1 | 132.8 | 23.4 |
| M2 Transformer | 80.8 | 39.1 | 29.2 | 58.6 | 131.2 | 22.6 | |
| RSTNet | 81.8 | 40.1 | 29.8 | 59.5 | 135.6 | 23.3 | |
| DLCT | 81.4 | 39.8 | 29.5 | 59.1 | 133.8 | 23.0 | |
| GAT | 80.8 | 39.7 | 29.1 | 59.0 | 130.5 | 22.9 | |
| A2 Transformer | 81.5 | 39.8 | 29.6 | 59.1 | 133.9 | 23.0 | |
| S2 Transformer | 81.1 | 39.6 | 29.6 | 59.1 | 133.5 | 23.2 | |
| LSTNet | 81.5 | 40.3 | 29.6 | 59.4 | 134.8 | 23.1 | |
| SCD-Net | 81.3 | 39.4 | 29.2 | 59.1 | 131.6 | 23.0 | |
| STMSF | 82.2 | 40.5 | 30.0 | 59.9 | 136.9 | 23.9 |
| 方法 | B1 | B4 | M | R | C |
|---|---|---|---|---|---|
| Up-Down | 78.1 | 48.0 | 40.8 | 70.6 | 198.5 |
| BiGRU-RA | — | — | 41.3 | 70.9 | 192.0 |
| NICVATP2L | 75.9 | 44.3 | 36.5 | 61.9 | 130.8 |
| DenseNet-BiLSTM | 78.5 | 47.8 | 41.5 | 71.2 | 191.3 |
| I-GRUs | 68.8 | 26.8 | 23.9 | — | 85.6 |
| STMSF | 84.8 | 59.1 | 42.2 | 70.0 | 200.6 |
| STMSF* | 86.4 | 61.3 | 42.8 | 71.4 | 215.0 |
Tab. 2 Performance comparison on AI Challenger test set
| 方法 | B1 | B4 | M | R | C |
|---|---|---|---|---|---|
| Up-Down | 78.1 | 48.0 | 40.8 | 70.6 | 198.5 |
| BiGRU-RA | — | — | 41.3 | 70.9 | 192.0 |
| NICVATP2L | 75.9 | 44.3 | 36.5 | 61.9 | 130.8 |
| DenseNet-BiLSTM | 78.5 | 47.8 | 41.5 | 71.2 | 191.3 |
| I-GRUs | 68.8 | 26.8 | 23.9 | — | 85.6 |
| STMSF | 84.8 | 59.1 | 42.2 | 70.0 | 200.6 |
| STMSF* | 86.4 | 61.3 | 42.8 | 71.4 | 215.0 |
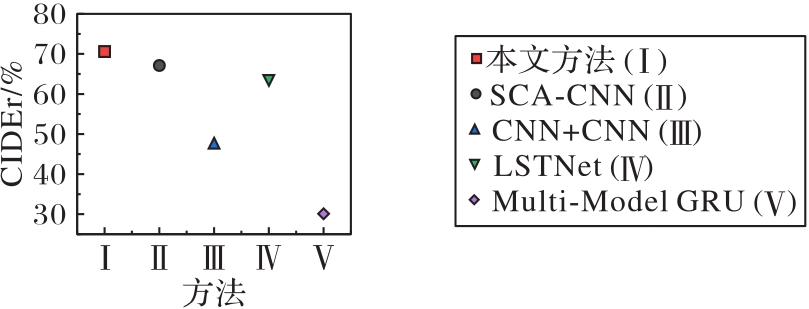
Fig. 5 CIDEr of different methods on Flickr8k dataset
| RL | B1 | B4 | M | R | C | S |
|---|---|---|---|---|---|---|
| N | 78.5 | 37.6 | 29.1 | 58.0 | 123.0 | 22.3 |
| Y | 82.2 | 40.5 | 30.0 | 59.9 | 136.9 | 23.9 |
Tab. 3 Performance comparison before and after incorporating reinforcement learning
| RL | B1 | B4 | M | R | C | S |
|---|---|---|---|---|---|---|
| N | 78.5 | 37.6 | 29.1 | 58.0 | 123.0 | 22.3 |
| Y | 82.2 | 40.5 | 30.0 | 59.9 | 136.9 | 23.9 |
| Agent Attention | MSCA | B4 | M | R | C | S |
|---|---|---|---|---|---|---|
| × | × | 36.8 | 28.9 | 57.7 | 122.8 | 22.2 |
| √ | × | 37.2 | 29.1 | 57.9 | 123.0 | 22.1 |
| × | √ | 37.3 | 29.0 | 58.0 | 122.8 | 22.1 |
| √ | √ | 37.6 | 29.1 | 58.0 | 123.0 | 22.3 |
Tab. 4 Comparison of ablation results for each module
| Agent Attention | MSCA | B4 | M | R | C | S |
|---|---|---|---|---|---|---|
| × | × | 36.8 | 28.9 | 57.7 | 122.8 | 22.2 |
| √ | × | 37.2 | 29.1 | 57.9 | 123.0 | 22.1 |
| × | √ | 37.3 | 29.0 | 58.0 | 122.8 | 22.1 |
| √ | √ | 37.6 | 29.1 | 58.0 | 123.0 | 22.3 |
| 层数 | B1/% | B4/% | M/% | R/% | C/% | S/% |
|---|---|---|---|---|---|---|
| 1 | 76.3 | 37.7 | 28.0 | 57.8 | 120.1 | 21.2 |
| 2 | 78.3 | 37.6 | 28.9 | 57.8 | 123.1 | 21.9 |
| 3 | 78.5 | 37.6 | 29.1 | 58.0 | 123.0 | 22.3 |
| 4 | 77.3 | 36.9 | 28.9 | 57.5 | 122.9 | 22.1 |
Tab. 5 Performance comparison of different encoder-decoder layers
| 层数 | B1/% | B4/% | M/% | R/% | C/% | S/% |
|---|---|---|---|---|---|---|
| 1 | 76.3 | 37.7 | 28.0 | 57.8 | 120.1 | 21.2 |
| 2 | 78.3 | 37.6 | 28.9 | 57.8 | 123.1 | 21.9 |
| 3 | 78.5 | 37.6 | 29.1 | 58.0 | 123.0 | 22.3 |
| 4 | 77.3 | 36.9 | 28.9 | 57.5 | 122.9 | 22.1 |
| 骨干网络 | 图像大小 | B1/% | B4/% | M/% | R/% | C/% | S/% |
|---|---|---|---|---|---|---|---|
| Swin-B | 384×384 | 76.7 | 36.4 | 28.8 | 57.2 | 121.4 | 21.8 |
| Swin-L | 384×384 | 78.5 | 37.6 | 29.1 | 58.0 | 123.0 | 22.3 |
Tab. 6 Performance comparison of different backbone networks
| 骨干网络 | 图像大小 | B1/% | B4/% | M/% | R/% | C/% | S/% |
|---|---|---|---|---|---|---|---|
| Swin-B | 384×384 | 76.7 | 36.4 | 28.8 | 57.2 | 121.4 | 21.8 |
| Swin-L | 384×384 | 78.5 | 37.6 | 29.1 | 58.0 | 123.0 | 22.3 |
| DWC模块 | B1 | B4 | M | R | C | S |
|---|---|---|---|---|---|---|
| × | 77.1 | 36.1 | 28.5 | 57.0 | 120.2 | 21.6 |
| √ | 78.5 | 37.6 | 29.1 | 58.0 | 123.0 | 22.3 |
Tab. 7 Performance verification of encoder DWC module
| DWC模块 | B1 | B4 | M | R | C | S |
|---|---|---|---|---|---|---|
| × | 77.1 | 36.1 | 28.5 | 57.0 | 120.2 | 21.6 |
| √ | 78.5 | 37.6 | 29.1 | 58.0 | 123.0 | 22.3 |

Fig. 6 Instance analysis of captions generated by STMSF and reference captions
| [1] | VASWANI A, SHAZEER N, PARMAR N, et al. Attention is all you need[C]// Proceedings of the 31st International Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2017: 6000-6010. |
| [2] | DOSOVITSKIY A, BEYER L, KOLESNIKOV A, et al. An image is worth 16x16 words: Transformers for image recognition at scale[EB/OL]. [2024-11-28].. |
| [3] | LIU Z, LIN Y, CAO Y, et al. Swin Transformer: hierarchical vision Transformer using shifted windows[C]// Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision. Piscataway: IEEE, 2021: 9992-10002. |
| [4] | HAN D, YE T, HAN Y, et al. Agent attention: on the integration of Softmax and linear attention[C]// Proceedings of the 2024 European Conference on Computer Vision, LNCS 15108. Cham: Springer, 2025: 124-140. |
| [5] | CHEN L, ZHANG H, XIAO J, et al. SCA-CNN: spatial and channel-wise attention in convolutional networks for image captioning[C]// Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2017: 6298-6306. |
| [6] | ANDERSON P, HE X, BUEHLER C, et al. Bottom-up and top-down attention for image captioning and visual question answering[C]// Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2018: 6077-6086. |
| [7] | PAN Y, YAO T, LI Y, et al. X-linear attention networks for image captioning[C]// Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2020: 10971-10980. |
| [8] | CORNIA M, STEFANINI M, BARALDI L, et al. Meshed-memory Transformer for image captioning[C]// Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2020: 10575-10584. |
| [9] | LUO Y, JI J, SUN X, et al. Dual-level collaborative Transformer for image captioning[C]// Proceedings of the 35th AAAI Conference on Artificial Intelligence. Palo Alto: AAAI Press, 2021: 2286-2293. |
| [10] | CHEN X, FANG H, LIN T Y, et al. Microsoft COCO captions: data collection and evaluation server[EB/OL]. [2024-11-28].. |
| [11] | WU J, ZHENG H, ZHAO B, et al. Large-scale datasets for going deeper in image understanding[C]// Proceedings of the 2019 IEEE International Conference on Multimedia and Expo. Piscataway: IEEE, 2019: 1480-1485. |
| [12] | KARPATHY A, LI F F. Deep visual-semantic alignments for generating image descriptions[C]// Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2015: 3128-3137. |
| [13] | PAPINENI K, ROUKOS S, WARD T, et al. BLEU: a method for automatic evaluation of machine translation[C]// Proceedings of the 40th Annual Meeting of the Association for Computational Linguistics. Stroudsburg: ACL, 2002: 311-318. |
| [14] | DENKOWSKI M, LAVIE A. Meteor universal: language specific translation evaluation for any target language[C]// Proceedings of the 9th Workshop on Statistical Machine Translation. Stroudsburg: ACL, 2014: 376-380. |
| [15] | LIN C Y. ROUGE: a package for automatic evaluation of summaries[C]// Proceedings of the ACL-04 Workshop: Text Summarization Branches Out. Stroudsburg: ACL, 2004: 74-81. |
| [16] | VEDANTAM R, ZITNICK C L, PARIKH D. CIDEr: consensus-based image description evaluation[C]// Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2015: 4566-4575. |
| [17] | ANDERSON P, FERNANDO B, JOHNSON M, et al. SPICE: semantic propositional image caption evaluation[C]// Proceedings of the 2016 European Conference on Computer Vision, LNCS 9909. Cham: Springer, 2016: 382-398. |
| [18] | RENNIE S J, MARCHERET E, MROUEH Y, et al. Self-critical sequence training for image captioning[C]// Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2017: 1179-1195. |
| [19] | YAO T, PAN Y, LI Y, et al. Exploring visual relationship for image captioning[C]// Proceedings of the 2018 European Conference on Computer Vision, LNCS 11218. Cham: Springer, 2018: 711-727. |
| [20] | HUANG L, WANG W, CHEN J, et al. Attention on attention for image captioning[C]// Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision. Piscataway: IEEE, 2019: 4633-4642. |
| [21] | 刘茂福,施琦,聂礼强. 基于视觉关联与上下文双注意力的图像描述生成方法[J]. 软件学报, 2022, 33(9):3210-3222. |
| LIU M F, SHI Q, NIE L Q. Image captioning based on visual relevance and context dual attention[J]. Journal of Software, 2022, 33(9): 3210-3222. | |
| [22] | ZHANG X, SUN X, LUO Y, et al. RSTNet: captioning with adaptive attention on visual and non-visual words[C]// Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2021: 15460-15469. |
| [23] | WANG C, SHEN Y, JI L. Geometry attention Transformer with position-aware LSTMs for image captioning[J]. Expert Systems with Applications, 2022, 201: No.117174. |
| [24] | FEI Z. Attention-aligned Transformer for image captioning[C]// Proceedings of the 36th AAAI Conference on Artificial Intelligence. Palo Alto: AAAI Press, 2022: 607-615. |
| [25] | ZENG P, ZHANG H, SONG J, et al. S2 Transformer for image captioning[C]// Proceedings of the 31st International Joint Conference on Artificial Intelligence. California: ijcai.org, 2022: 1608-1614. |
| [26] | MA Y, JI J, SUN X, et al. Towards local visual modeling for image captioning[J]. Pattern Recognition, 2023, 138: No.109420. |
| [27] | LUO J, LI Y, PAN Y, et al. Semantic-conditional diffusion networks for image captioning[C]// Proceedings of the 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2023: 23359-23368. |
| [28] | 邓珍荣,张永林,杨睿,等. 结合全局和局部特征的BiGRU-RA图像中文描述模型[J]. 计算机辅助设计与图形学学报, 2021, 33(1):49-58. |
| DENG Z R, ZHANG Y L, YANG R, et al. BiGRU-RA model for image Chinese captioning via global and local features[J]. Journal of Computer-Aided Design and Computer Graphics, 2021, 33(1): 49-58. | |
| [29] | LIU M, HU H, LI L, et al. Chinese image caption generation via visual attention and topic modeling[J]. IEEE Transactions on Cybernetics, 2022, 52(2): 1247-1257. |
| [30] | LU H, YANG R, DENG Z, et al. Chinese image captioning via fuzzy attention-based DenseNet-BiLSTM[J]. ACM Transactions on Multimedia Computing, Communications, and Applications, 2021, 17(1s): No.14. |
| [31] | PAN Y, WANG L, DUAN S, et al. Chinese image caption of Inceptionv4 and double-layer GRUs based on attention mechanism[J]. Journal of Physics: Conference Series, 2021, 1861: No.012044. |
| [32] | HODOSH M, YOUNG P, HOCKENMAIER J. Framing image description as a ranking task: data, models and evaluation metrics[J]. Journal of Artificial Intelligence Research, 2013, 47: 853-899. |
| [33] | KATIYAR S, BORGOHAIN S K. Analysis of convolutional decoder for image caption generation[EB/OL]. [2024-11-28].. |
| [34] | LI X, YUAN A, LU X. Multi-modal gated recurrent units for image description[J]. Multimedia Tools and Applications, 2018, 77(22): 29847-29869. |
| [1] | Weigang LI, Jiale SHAO, Zhiqiang TIAN. Point cloud classification and segmentation network based on dual attention mechanism and multi-scale fusion [J]. Journal of Computer Applications, 2025, 45(9): 3003-3010. |
| [2] | Xiang WANG, Zhixiang CHEN, Guojun MAO. Multivariate time series prediction method combining local and global correlation [J]. Journal of Computer Applications, 2025, 45(9): 2806-2816. |
| [3] | Zhixiong XU, Bo LI, Xiaoyong BIAN, Qiren HU. Adversarial sample embedded attention U-Net for 3D medical image segmentation [J]. Journal of Computer Applications, 2025, 45(9): 3011-3016. |
| [4] | Fang WANG, Jing HU, Rui ZHANG, Wenting FAN. Medical image segmentation network with content-guided multi-angle feature fusion [J]. Journal of Computer Applications, 2025, 45(9): 3017-3025. |
| [5] | Yiming LIANG, Jing FAN, Wenze CHAI. Multi-scale feature fusion sentiment classification based on bidirectional cross attention [J]. Journal of Computer Applications, 2025, 45(9): 2773-2782. |
| [6] | Chengzhi YAN, Ying CHEN, Kai ZHONG, Han GAO. 3D object detection algorithm based on multi-scale network and axial attention [J]. Journal of Computer Applications, 2025, 45(8): 2537-2545. |
| [7] | Jinhao LIN, Chuan LUO, Tianrui LI, Hongmei CHEN. Thoracic disease classification method based on cross-scale attention network [J]. Journal of Computer Applications, 2025, 45(8): 2712-2719. |
| [8] | Yimeng XI, Zhen DENG, Qian LIU, Libo LIU. Cross-modal information fusion for video-text retrieval [J]. Journal of Computer Applications, 2025, 45(8): 2448-2456. |
| [9] | Liang CHEN, Xuan WANG, Kun LEI. Helmet wearing detection algorithm for complex scenarios based on cross-layer multi-scale feature fusion [J]. Journal of Computer Applications, 2025, 45(7): 2333-2341. |
| [10] | Xiang WANG, Qianqian CUI, Xiaoming ZHANG, Jianchao WANG, Zhenzhou WANG, Jialin SONG. Wireless capsule endoscopy image classification model based on improved ConvNeXt [J]. Journal of Computer Applications, 2025, 45(6): 2016-2024. |
| [11] | Zonghang WU, Dong ZHANG, Guanyu LI. Multimodal fusion recommendation algorithm based on joint self-supervised learning [J]. Journal of Computer Applications, 2025, 45(6): 1858-1868. |
| [12] | Linjia SUN, Lei QIN, Meijin KANG, Yinglin WANG. Automatic speech segmentation algorithm based on syllable type recognition [J]. Journal of Computer Applications, 2025, 45(6): 2034-2042. |
| [13] | Ying HUANG, Shengmei GAO, Guang CHEN, Su LIU. Low-light image enhancement network combining signal-to-noise ratio guided dual-branch structure and histogram equalization [J]. Journal of Computer Applications, 2025, 45(6): 1971-1979. |
| [14] | Junyan ZHANG, Yiming ZHAO, Bing LIN, Yunping WU. Chinese image captioning method based on multi-level visual and dynamic text-image interaction [J]. Journal of Computer Applications, 2025, 45(5): 1520-1527. |
| [15] | Hui LI, Bingzhi JIA, Chenxi WANG, Ziyu DONG, Jilong LI, Zhaoman ZHONG, Yanyan CHEN. Generative adversarial network underwater image enhancement model based on Swin Transformer [J]. Journal of Computer Applications, 2025, 45(5): 1439-1446. |
| Viewed | ||||||
|
Full text |
|
|||||
|
Abstract |
|
|||||