


Journal of Computer Applications ›› 2025, Vol. 45 ›› Issue (4): 1095-1103.DOI: 10.11772/j.issn.1001-9081.2023121852
• Artificial intelligence • Previous Articles Next Articles
Yiqin YAN1, Chuan LUO1( ), Tianrui LI2, Hongmei CHEN2
), Tianrui LI2, Hongmei CHEN2
Received:2024-01-09
Revised:2024-03-13
Accepted:2024-03-18
Online:2024-04-28
Published:2025-04-10
Contact:
Chuan LUO
About author:YAN Yiqin, born in 1998, M. S. candidate. His research interests include machine learning, computer vision.Supported by:
严一钦1, 罗川1(), 李天瑞2, 陈红梅2
通讯作者:
罗川
作者简介:严一钦(1998—),男,四川成都人,硕士研究生,主要研究方向:机器学习、计算机视觉基金资助:CLC Number:
Yiqin YAN, Chuan LUO, Tianrui LI, Hongmei CHEN. Cross-domain few-shot classification model based on relation network and Vision Transformer[J]. Journal of Computer Applications, 2025, 45(4): 1095-1103.
严一钦, 罗川, 李天瑞, 陈红梅. 基于关系网络和Vision Transformer的跨域小样本分类模型[J]. 《计算机应用》唯一官方网站, 2025, 45(4): 1095-1103.
Add to citation manager EndNote|Ris|BibTeX
URL: https://www.joca.cn/EN/10.11772/j.issn.1001-9081.2023121852
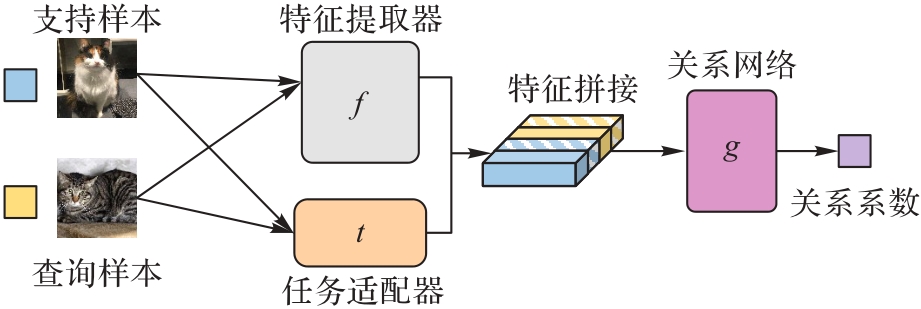
Fig. 1 Overall flow of ReViT
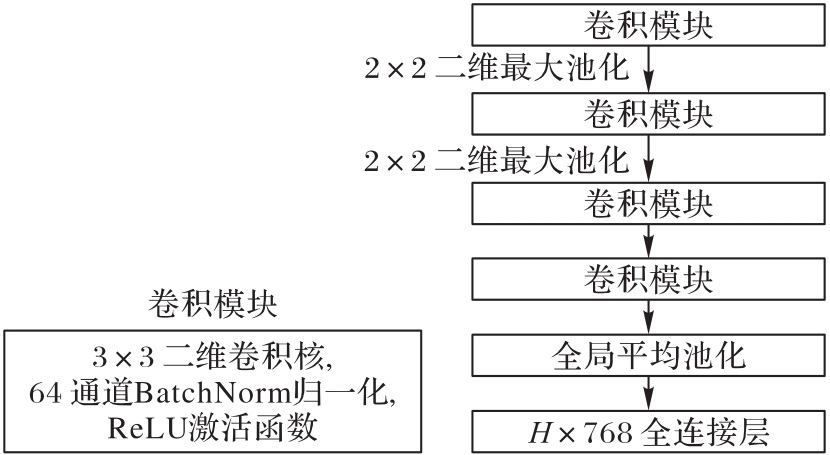
Fig. 2 Task adapter
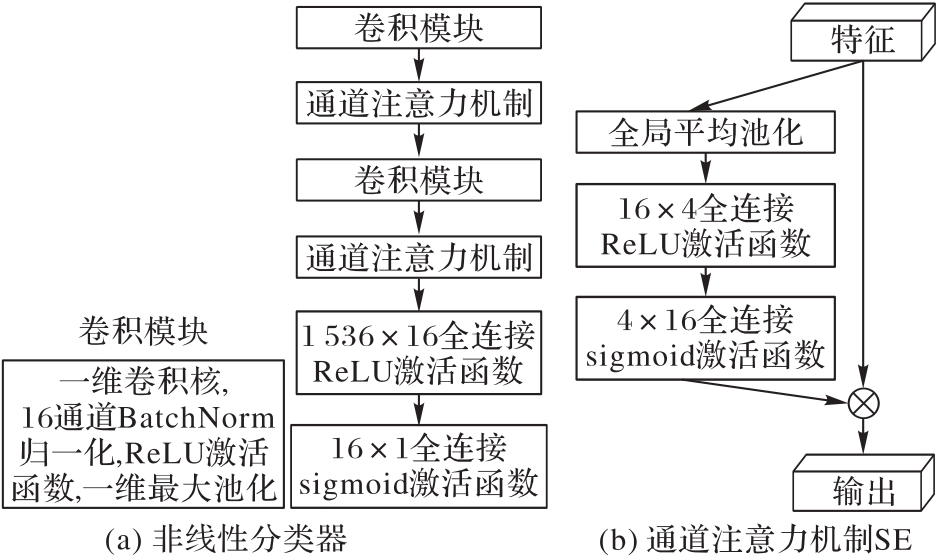
Fig. 3 Classifier module
| 模型 | ChestX | ISIC | EuroSAT | CropDisease | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 5way5shot | 5way20shot | 5way50shot | 5way5shot | 5way20shot | 5way50shot | 5way5shot | 5way20shot | 5way50shot | 5way5shot | 5way20shot | 5way50shot | |
| ProtoNet | 24.05 | 28.21 | 29.32 | 39.57 | 49.50 | 51.99 | 73.29 | 82.27 | 80.48 | 79.72 | 88.15 | 90.81 |
| SPFSL | 27.13 | 31.57 | 34.17 | 43.78 | 54.06 | 57.86 | 89.18 | 93.08 | 96.06 | 95.06 | 97.25 | 97.77 |
| STARTUP | 26.94 | 33.19 | 36.91 | 47.22 | 58.63 | 64.16 | 82.29 | 89.26 | 91.99 | 93.02 | 97.51 | 98.45 |
| CHEF | 24.72 | 29.71 | 31.25 | 41.26 | 54.30 | 60.86 | 74.15 | 83.31 | 86.55 | 86.87 | 94.78 | 96.77 |
| ReViT(B) | 25.05 | 27.64 | 31.33 | 48.38 | 58.34 | 62.29 | 81.95 | 88.04 | 89.12 | 96.32 | 97.66 | 98.06 |
| ReViT(A) | 23.87 | 26.13 | 28.43 | 48.28 | 59.21 | 61.16 | 83.01 | 87.23 | 88.49 | 96.60 | 98.48 | 98.81 |
| ReViT(D) | 25.54 | 31.29 | 33.60 | 49.65 | 62.03 | 63.04 | 90.18 | 93.21 | 93.94 | 94.38 | 97.76 | 98.16 |
Tab. 1 Average classification accuracy on BCDFSL dataset
| 模型 | ChestX | ISIC | EuroSAT | CropDisease | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 5way5shot | 5way20shot | 5way50shot | 5way5shot | 5way20shot | 5way50shot | 5way5shot | 5way20shot | 5way50shot | 5way5shot | 5way20shot | 5way50shot | |
| ProtoNet | 24.05 | 28.21 | 29.32 | 39.57 | 49.50 | 51.99 | 73.29 | 82.27 | 80.48 | 79.72 | 88.15 | 90.81 |
| SPFSL | 27.13 | 31.57 | 34.17 | 43.78 | 54.06 | 57.86 | 89.18 | 93.08 | 96.06 | 95.06 | 97.25 | 97.77 |
| STARTUP | 26.94 | 33.19 | 36.91 | 47.22 | 58.63 | 64.16 | 82.29 | 89.26 | 91.99 | 93.02 | 97.51 | 98.45 |
| CHEF | 24.72 | 29.71 | 31.25 | 41.26 | 54.30 | 60.86 | 74.15 | 83.31 | 86.55 | 86.87 | 94.78 | 96.77 |
| ReViT(B) | 25.05 | 27.64 | 31.33 | 48.38 | 58.34 | 62.29 | 81.95 | 88.04 | 89.12 | 96.32 | 97.66 | 98.06 |
| ReViT(A) | 23.87 | 26.13 | 28.43 | 48.28 | 59.21 | 61.16 | 83.01 | 87.23 | 88.49 | 96.60 | 98.48 | 98.81 |
| ReViT(D) | 25.54 | 31.29 | 33.60 | 49.65 | 62.03 | 63.04 | 90.18 | 93.21 | 93.94 | 94.38 | 97.76 | 98.16 |
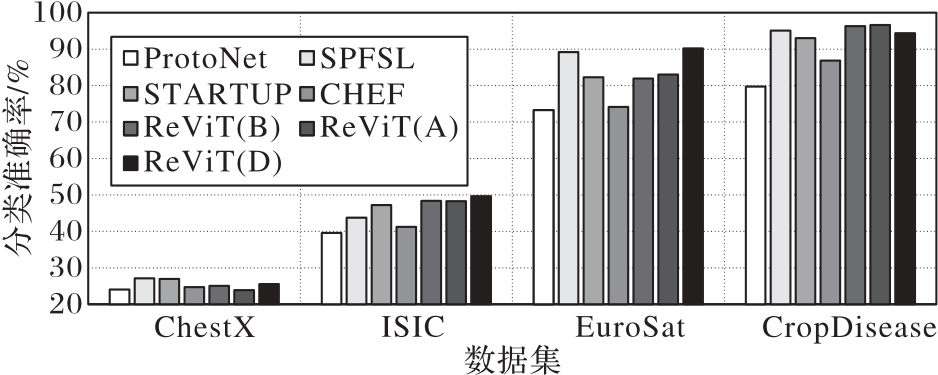
Fig. 4 Experimental results of 5-way 5-shot on BCDFSL dataset
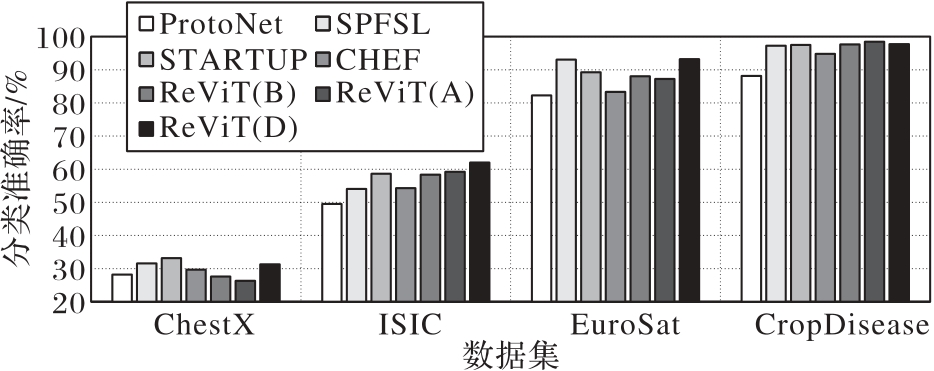
Fig. 5 Experimental results of 5-way 20-shot on BCDFSL dataset
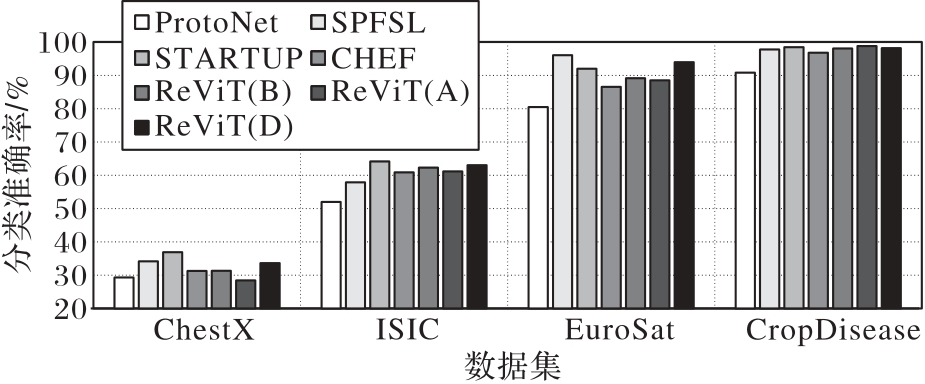
Fig. 6 Experimental results of 5-way 50-shot on BCDFSL dataset
| 模型 | 域内 | 域外 | 平均 | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| INet | Olt | AC | CUB | DT | QD | Fg | Flr | TS | MCC | ||
| ProtoNet | 67.01 | 44.50 | 79.56 | 71.14 | 67.01 | 65.18 | 64.88 | 40.26 | 86.85 | 46.48 | 63.29 |
| ITA | 57.35 | 94.96 | 87.91 | 85.91 | 76.74 | 82.01 | 67.40 | 92.18 | 83.55 | 55.75 | 78.07 |
| CTX | 60.30 | 87.91 | 85.58 | 93.93 | 73.15 | 71.73 | 65.89 | 91.50 | 73.98 | 63.11 | 76.71 |
| SPFSL | 67.51 | 85.91 | 80.30 | 81.67 | 87.80 | 72.84 | 60.03 | 94.69 | 87.17 | 58.92 | 77.61 |
| ReViT(B) | 79.14 | 91.21 | 91.43 | 93.95 | 87.96 | 80.17 | 76.90 | 93.86 | 74.38 | 69.93 | 83.89 |
| ReViT(A) | 78.17 | 92.95 | 88.77 | 93.77 | 86.28 | 79.24 | 77.07 | 94.30 | 75.74 | 78.17 | 83.23 |
| ReViT(D) | 71.46 | 91.44 | 77.67 | 89.21 | 84.57 | 76.28 | 74.25 | 95.21 | 68.37 | 64.95 | 79.34 |
Tab. 2 Average classification accuracy in multi-domain scenarios on Meta-Dataset
| 模型 | 域内 | 域外 | 平均 | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| INet | Olt | AC | CUB | DT | QD | Fg | Flr | TS | MCC | ||
| ProtoNet | 67.01 | 44.50 | 79.56 | 71.14 | 67.01 | 65.18 | 64.88 | 40.26 | 86.85 | 46.48 | 63.29 |
| ITA | 57.35 | 94.96 | 87.91 | 85.91 | 76.74 | 82.01 | 67.40 | 92.18 | 83.55 | 55.75 | 78.07 |
| CTX | 60.30 | 87.91 | 85.58 | 93.93 | 73.15 | 71.73 | 65.89 | 91.50 | 73.98 | 63.11 | 76.71 |
| SPFSL | 67.51 | 85.91 | 80.30 | 81.67 | 87.80 | 72.84 | 60.03 | 94.69 | 87.17 | 58.92 | 77.61 |
| ReViT(B) | 79.14 | 91.21 | 91.43 | 93.95 | 87.96 | 80.17 | 76.90 | 93.86 | 74.38 | 69.93 | 83.89 |
| ReViT(A) | 78.17 | 92.95 | 88.77 | 93.77 | 86.28 | 79.24 | 77.07 | 94.30 | 75.74 | 78.17 | 83.23 |
| ReViT(D) | 71.46 | 91.44 | 77.67 | 89.21 | 84.57 | 76.28 | 74.25 | 95.21 | 68.37 | 64.95 | 79.34 |
| 模型 | 域内 | 域外 | 平均 | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| INet | Olt | AC | CUB | DT | QD | Fg | Flr | TS | MCC | ||
| ProtoNet | 50.50 | 59.98 | 53.10 | 68.79 | 66.56 | 48.96 | 39.71 | 85.27 | 47.12 | 41.00 | 56.10 |
| ITA | 63.72 | 82.58 | 80.13 | 83.35 | 79.58 | 70.96 | 51.27 | 94.04 | 81.71 | 61.72 | 74.91 |
| CTX | 62.76 | 82.21 | 79.49 | 80.63 | 75.57 | 72.68 | 51.58 | 95.34 | 82.65 | 59.90 | 74.28 |
| SPFSL | 76.69 | 81.42 | 80.33 | 84.38 | 86.87 | 75.43 | 55.93 | 95.14 | 89.68 | 65.01 | 79.09 |
| ReViT(B) | 79.25 | 89.47 | 78.60 | 93.87 | 79.84 | 79.03 | 55.50 | 94.00 | 86.67 | 71.75 | 80.80 |
| ReViT(A) | 78.75 | 88.91 | 75.21 | 93.97 | 79.14 | 77.49 | 58.10 | 94.72 | 88.00 | 66.24 | 80.05 |
| ReViT(D) | 71.82 | 89.53 | 67.36 | 87.07 | 79.68 | 72.19 | 66.28 | 95.50 | 81.62 | 65.46 | 77.65 |
Tab. 3 Average classification accuracy in cross-domain scenarios on Meta-Dataset
| 模型 | 域内 | 域外 | 平均 | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| INet | Olt | AC | CUB | DT | QD | Fg | Flr | TS | MCC | ||
| ProtoNet | 50.50 | 59.98 | 53.10 | 68.79 | 66.56 | 48.96 | 39.71 | 85.27 | 47.12 | 41.00 | 56.10 |
| ITA | 63.72 | 82.58 | 80.13 | 83.35 | 79.58 | 70.96 | 51.27 | 94.04 | 81.71 | 61.72 | 74.91 |
| CTX | 62.76 | 82.21 | 79.49 | 80.63 | 75.57 | 72.68 | 51.58 | 95.34 | 82.65 | 59.90 | 74.28 |
| SPFSL | 76.69 | 81.42 | 80.33 | 84.38 | 86.87 | 75.43 | 55.93 | 95.14 | 89.68 | 65.01 | 79.09 |
| ReViT(B) | 79.25 | 89.47 | 78.60 | 93.87 | 79.84 | 79.03 | 55.50 | 94.00 | 86.67 | 71.75 | 80.80 |
| ReViT(A) | 78.75 | 88.91 | 75.21 | 93.97 | 79.14 | 77.49 | 58.10 | 94.72 | 88.00 | 66.24 | 80.05 |
| ReViT(D) | 71.82 | 89.53 | 67.36 | 87.07 | 79.68 | 72.19 | 66.28 | 95.50 | 81.62 | 65.46 | 77.65 |
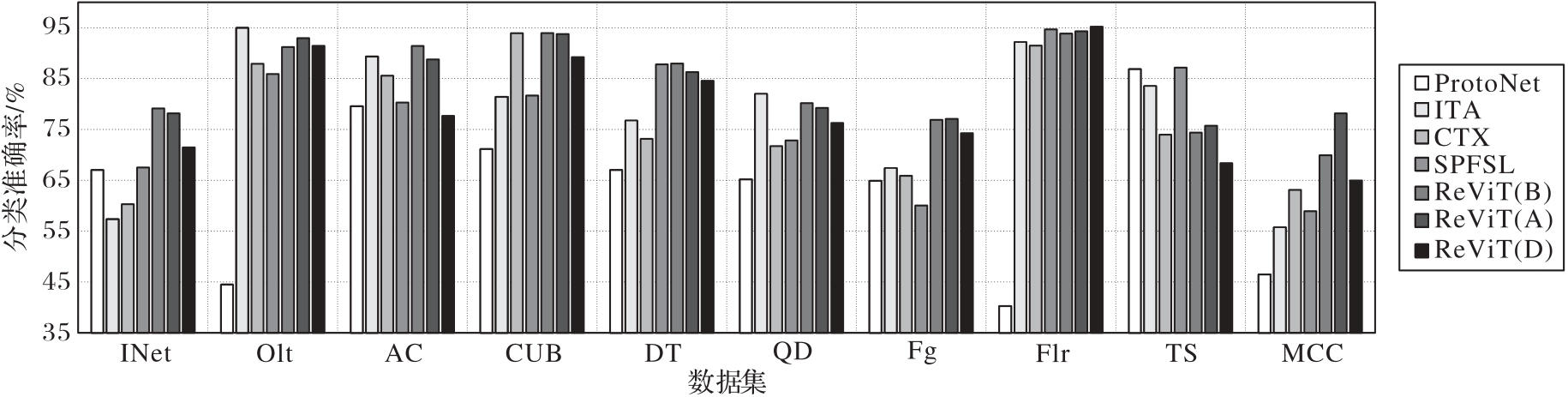
Fig. 7 Multi-domain experimental results on Meta-Dataset
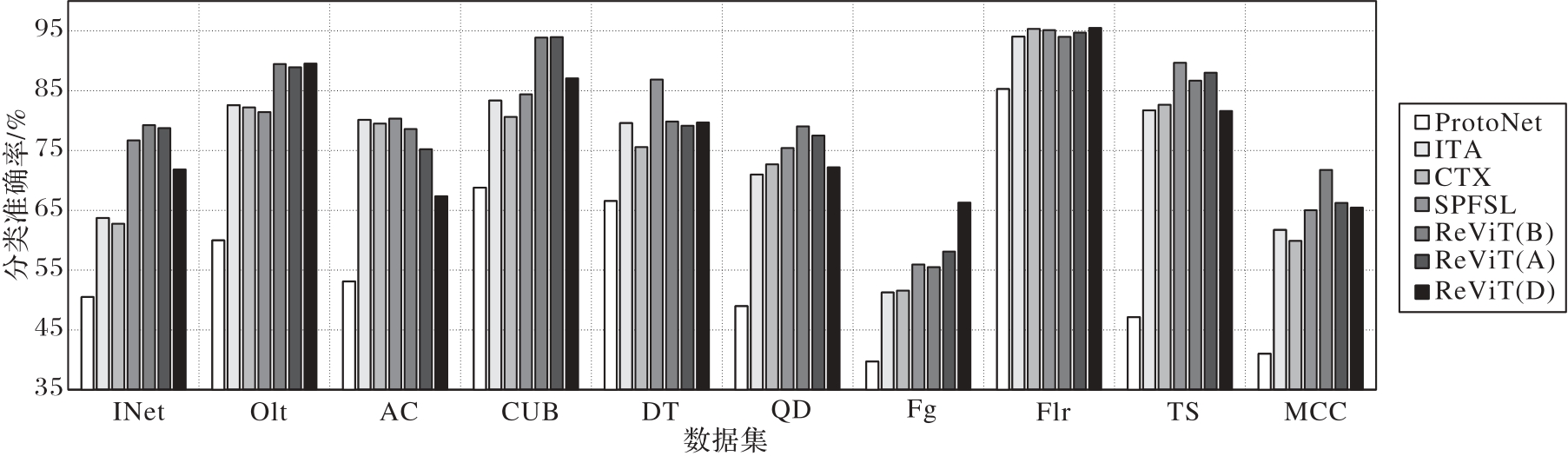
Fig. 8 Cross-domain experimental results on Meta-Dataset
| 学习率 | 分类准确率/% | ||
|---|---|---|---|
| ReViT(B) | ReViT(D) | ReViT(A) | |
| 0.100 | 58.34 | 61.97 | 59.17 |
| 0.050 | 58.31 | 61.94 | 59.23 |
| 0.010 | 58.34 | 62.03 | 59.21 |
| 0.001 | 58.35 | 61.99 | 59.16 |
| 0.005 | 58.26 | 62.05 | 59.22 |
Tab. 4 Experimental results of learning rate sensitivity
| 学习率 | 分类准确率/% | ||
|---|---|---|---|
| ReViT(B) | ReViT(D) | ReViT(A) | |
| 0.100 | 58.34 | 61.97 | 59.17 |
| 0.050 | 58.31 | 61.94 | 59.23 |
| 0.010 | 58.34 | 62.03 | 59.21 |
| 0.001 | 58.35 | 61.99 | 59.16 |
| 0.005 | 58.26 | 62.05 | 59.22 |
| Transformer | 适配器 | 关系网络 | 微调 | 准确率/% |
|---|---|---|---|---|
| √ | √ | √ | 59.87 | |
| √ | √ | √ | 53.91 | |
| √ | √ | √ | 58.26 | |
| √ | √ | √ | 41.77 | |
| √ | √ | √ | √ | 62.03 |
Tab. 5 Ablation experimental results
| Transformer | 适配器 | 关系网络 | 微调 | 准确率/% |
|---|---|---|---|---|
| √ | √ | √ | 59.87 | |
| √ | √ | √ | 53.91 | |
| √ | √ | √ | 58.26 | |
| √ | √ | √ | 41.77 | |
| √ | √ | √ | √ | 62.03 |
| 1 | HE K, ZHANG X, REN S, et al. Deep residual learning for image recognition [C]// Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2016: 770-778. |
| 2 | DOSOVITSKIY A, BEYER L, KOLESNIKOV A, et al. An image is worth 16x16 words: Transformers for image recognition at scale [EB/OL]. [2023-10-05]. . |
| 3 | CHEN W Y, LIU Y C, KIRA Z, et al. A closer look at few-shot classification [EB/OL]. [2023-10-15]. . |
| 4 | HOSPEDALES T M, ANTONIOU A, MICAELLI P, et al. Meta-learning in neural networks: a survey [J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2022, 44(9): 5149-5169. |
| 5 | GUO Y, CODELLA N, KARLINSKY L, et al. A broader study of cross-domain few-shot learning [C]// Proceedings of the 2020 European Conference on Computer Vision, LNCS 12372. Cham: Springer, 2020: 124-141. |
| 6 | VINYALS O, BLUNDELL C, LILLICRAP T, et al. Matching networks for one shot learning [C]// Proceedings of the 30th International Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2016: 3637-3645. |
| 7 | HOCHREITER S, SCHMIDHUBER J. Long short-term memory [J]. Neural Computation, 1997, 9(8): 1735-1780. |
| 8 | FINN C, ABBEEL P, LEVINE S. Model-agnostic meta-learning for fast adaptation of deep networks [C]// Proceedings of the 34th International Conference on Machine Learning. New York: JMLR.org, 2017: 1126-1135. |
| 9 | 许仁杰,刘宝弟,张凯,等.基于贝叶斯权函数的模型无关元学习算法[J].计算机应用, 2022, 42(3): 708-712. |
| XU R J, LIU B D, ZHANG K, et al. Model agnostic meta learning algorithm based on Bayesian weight function [J]. Journal of Computer Applications, 2022, 42(3): 708-712. | |
| 10 | SNELL J, SWERSKY K, ZEMEL R. Prototypical networks for few-shot learning [C]// Proceedings of the 31st International Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2017: 4080-4090. |
| 11 | SUNG F, YANG Y, ZHANG L, et al. Learning to compare: relation network for few-shot learning [C]// Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2018: 1199-1208. |
| 12 | LEE K, MAJI S, RAVICHANDRAN A, et al. Meta-learning with differentiable convex optimization [C]// Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2019: 10649-10657. |
| 13 | LIM J Y, LIM K M, OOI S Y, et al. Efficient-PrototypicalNet with self knowledge distillation for few-shot learning [J]. Neurocomputing, 2021, 459: 327-337. |
| 14 | SUN Q, LIU Y, CHEN Z, et al. Meta-transfer learning through hard tasks [J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2022, 44(3): 1443-1456. |
| 15 | BENDOU Y, HU Y, LAFARGUE R, et al. EASY — ensemble augmented-shot-Y-shaped learning: state of the art few-shot classification with simple components [J]. Journal of Imaging, 2022, 8(7): No.179. |
| 16 | DVORNIK N, SCHMID C, MAIRAL J. Selecting relevant features from a multi-domain representation for few-shot classification [C]// Proceedings of the 2020 European Conference on Computer Vision, LNCS 12355. Cham: Springer, 2020: 769-786. |
| 17 | LIU L, HAMITON W, LONG G, et al. A universal representation transformer layer for few-shot image classification [EB/OL]. [2023-12-09]. . |
| 18 | LIU Y, LEE J, PARK M, et al. Learning to propagate labels: transductive propagation network for few-shot learning [EB/OL]. [2023-01-10]. . |
| 19 | REQUEIMA J, GORDON J, BRONSKILL J, et al. Fast and flexible multi-task classification using conditional neural adaptive processes [C]// Proceedings of the 33rd International Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2019: 7959-7970. |
| 20 | BATENI P, GOYAL R, MASRANI V, et al. Improved few-shot visual classification [C]// Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2020: 14481-14490. |
| 21 | BATENI P, BARBER J, VAN DE MEENT J W, et al. Enhancing few-shot image classification with unlabeled examples [C]// Proceedings of the 2022 IEEE/CVF Winter Conference on Applications of Computer Vision. Piscataway: IEEE, 2022: 1597-1606. |
| 22 | HU S X, LI D, STÜHMER J, et al. Pushing the limits of simple pipelines for few-shot learning: external data and fine-tuning make a difference [C]// Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2022: 9058-9067. |
| 23 | DOERSCH C, GUPTA A, ZISSERMAN A. CrossTransformers: spatially-aware few-shot transfer [C]// Proceedings of the 34th International Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2020: 21981-21993. |
| 24 | ADLER T, BRANDSTETTER J, WIDRICH M, et al. Cross-domain few-shot learning by representation fusion [EB/OL]. [2023-12-15]. . |
| 25 | LI W H, LIU X, BILEN H. Cross-domain few-shot learning with task-specific adapters [C]// Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2022: 7151-7160. |
| 26 | PHOO C P, HARIHARAN B. Self-training for few-shot transfer across extreme task differences [EB/OL]. [2023-12-10]. . |
| 27 | CARON M, TOUVRON H, MISRA I, et al. Emerging properties in self-supervised Vision Transformers [C]// Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision. Piscataway: IEEE, 2021: 9630-9640. |
| 28 | BAO H, DONG L, PIAO S, et al. BEiT: BERT pre-training of image transformers [EB/OL]. [2023-12-11]. . |
| 29 | STEINER A, KOLESNIKOV A, ZHAI X, et al. How to train your ViT? data, augmentation, and regularization in vision transformers [EB/OL]. [2023-11-08]. . |
| 30 | VASWANI A, SHAZEER N, PARMAR N, et al. Attention is all you need [C]// Proceedings of the 31st International Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2017: 6000-6010. |
| 31 | HU J, SHEN L, ALBANIE S, et al. Squeeze-and-excitation networks [J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2020, 42(8): 2011-2023. |
| 32 | TRIANTAFILLOU E, ZHU T, DUMOULIN V, et al. Meta-Dataset: a dataset of datasets for learning to learn from few examples [EB/OL]. [2023-11-08]. . |
| 33 | RUSSAKOVSKY O, DENG J, SU H, et al. ImageNet large scale visual recognition challenge [J]. International Journal of Computer Vision, 2015, 115(3): 211-252. |
| 34 | LAKE B M, SALAKHUTDINOV R, TENENBAUM J B. Human-level concept learning through probabilistic program induction [J]. Science, 2015, 350(6266): 1332-1338. |
| 35 | MAJI S, RAHTU E, KANNALA J, et al. Fine-grained visual classification of aircraft [EB/OL]. [2023-12-15]. . |
| 36 | WAH C, BRANSON S, WELINDER P, et al. The Caltech-UCSD Birds-200-2011 dataset [EB/OL]. [2023-03-02]. . |
| 37 | CIMPOI M, MAJI S, KOKKINOS I, et al. Describing textures in the wild [C]// Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2014: 3606-3613. |
| 38 | GUO K, WoMA J, XU E. Quick, draw! doodle recognition [EB/OL]. [2023-02-05]. . |
| 39 | SULC M, PICEK L, MATAS J, et al. Fungi recognition: a practical use case [C]// Proceedings of the 2020 IEEE Winter Conference on Applications of Computer Vision. Piscataway: IEEE, 2020: 2305-2313. |
| 40 | PATEL I, PATEL S. Flower identification and classification using computer vision and machine learning techniques [J]. International Journal of Engineering and Advanced Technology, 2019, 8(6): 277-285. |
| 41 | HOUBEN S, STALLKAMP J, SALMEN J, et al. Detection of traffic signs in real-world images: the German traffic sign detection benchmark [C]// Proceedings of the 2013 International Joint Conference on Neural Networks. Piscataway: IEEE, 2013: 1-8. |
| 42 | LIN T Y, MAIRE M, BELONGIE S, et al. Microsoft COCO: common objects in context [C]// Proceedings of the 2014 European Conference on Computer Vision, LNCS 8693. Cham: Springer, 2014: 740-755. |
| 43 | WANG X, PENG Y, LU L, et al. ChestX-Ray8: hospital scale chest X-ray database and benchmarks on weakly-supervised classification and localization of common thorax diseases [C]// Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2017: 3462-3471. |
| 44 | CODELLA N, ROTEMBERG V, TSCHANDL P, et al. Skin lesion analysis toward melanoma detection 2018: a challenge hosted by the International Skin Imaging Collaboration (ISIC) [EB/OL]. [2023-11-02]. . |
| 45 | HELBER P, BISCHKE B, DENGEL A, et al. EuroSAT: a novel dataset and deep learning benchmark for land use and land cover classification [J]. IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing, 2019, 12(7): 2217-2226. |
| 46 | MOHANTY S P, HUGHES D P, SLATHÉ M. Using deep learning for image-based plant disease detection [J]. Frontiers in Plant Science, 2016, 7: No.1419. |
| [1] | Liwei ZHANG, Quan LIANG, Yutao HU, Qiaole ZHU. Channel shuffle attention mechanism based on group convolution [J]. Journal of Computer Applications, 2025, 45(4): 1069-1076. |
| [2] | Meirong DING, Jinxin ZHUO, Yuwu LU, Qinglong LIU, Jicong LANG. Domain adaptation integrating environment label smoothing and nuclear norm discrepancy [J]. Journal of Computer Applications, 2025, 45(4): 1130-1138. |
| [3] | Xuewen YAN, Zhangjin HUANG. Few-shot image classification method based on contrast learning [J]. Journal of Computer Applications, 2025, 45(2): 383-391. |
| [4] | Danni DING, Bo PENG, Xi WU. VPNet: fatty liver ultrasound image classification method inspired by ventral pathway [J]. Journal of Computer Applications, 2025, 45(2): 662-669. |
| [5] | Kun FU, Shicong YING, Tingting ZHENG, Jiajie QU, Jingyuan CUI, Jianwei LI. Graph data augmentation method for few-shot node classification [J]. Journal of Computer Applications, 2025, 45(2): 392-402. |
| [6] | Binhong XIE, Wanyin GAO, Wangdong LU, Yingjun ZHANG, Rui ZHANG. Dense object counting network with few-shot similarity matching feature enhancement [J]. Journal of Computer Applications, 2025, 45(2): 403-410. |
| [7] | Zongsheng ZHENG, Jia DU, Yuhe CHENG, Zecheng ZHAO, Yuewei ZHANG, Xulong WANG. Cross-modal dual-stream alternating interactive network for infrared-visible image classification [J]. Journal of Computer Applications, 2025, 45(1): 275-283. |
| [8] | Yunchuan HUANG, Yongquan JIANG, Juntao HUANG, Yan YANG. Molecular toxicity prediction based on meta graph isomorphism network [J]. Journal of Computer Applications, 2024, 44(9): 2964-2969. |
| [9] | Dongwei WANG, Baichen LIU, Zhi HAN, Yanmei WANG, Yandong TANG. Deep network compression method based on low-rank decomposition and vector quantization [J]. Journal of Computer Applications, 2024, 44(7): 1987-1994. |
| [10] | Feiyu ZHAI, Handa MA. Hybrid classical-quantum classification model based on DenseNet [J]. Journal of Computer Applications, 2024, 44(6): 1905-1910. |
| [11] | Xinyan YU, Cheng ZENG, Qian WANG, Peng HE, Xiaoyu DING. Few-shot news topic classification method based on knowledge enhancement and prompt learning [J]. Journal of Computer Applications, 2024, 44(6): 1767-1774. |
| [12] | Wangjun SHI, Jing WANG, Xiaojun NING, Youfang LIN. Sleep stage classification model by meta transfer learning in few-shot scenarios [J]. Journal of Computer Applications, 2024, 44(5): 1445-1451. |
| [13] | Bin XIAO, Mo YANG, Min WANG, Guangyuan QIN, Huan LI. Domain generalization method of phase-frequency fusion from independent perspective [J]. Journal of Computer Applications, 2024, 44(4): 1002-1009. |
| [14] | Xue LI, Guangle YAO, Honghui WANG, Jun LI, Haoran ZHOU, Shaoze YE. Remote sensing image classification based on sample incremental learning [J]. Journal of Computer Applications, 2024, 44(3): 732-736. |
| [15] | Yuxin HUANG, Yiwang HUANG, Hui HUANG. Meta label correction method based on shallow network predictions [J]. Journal of Computer Applications, 2024, 44(11): 3364-3370. |
| Viewed | ||||||
|
Full text |
|
|||||
|
Abstract |
|
|||||