《计算机应用》唯一官方网站 ›› 2023, Vol. 43 ›› Issue (10): 3290-3296.DOI: 10.11772/j.issn.1001-9081.2022091464
所属专题: 前沿与综合应用
刘晨1,2, 陈洋1,2( ), 符浩3
), 符浩3
Chen LIU1,2, Yang CHEN1,2(), Hao FU3
摘要:
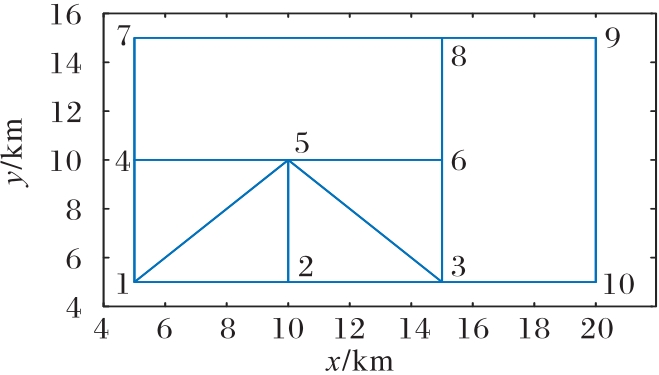
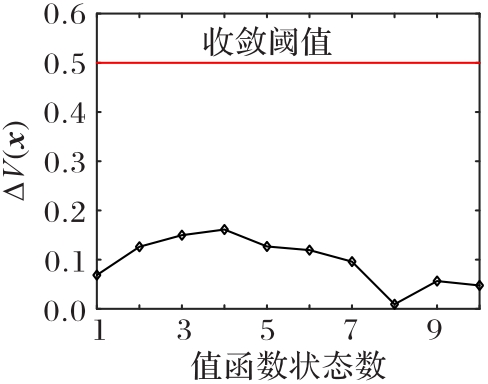
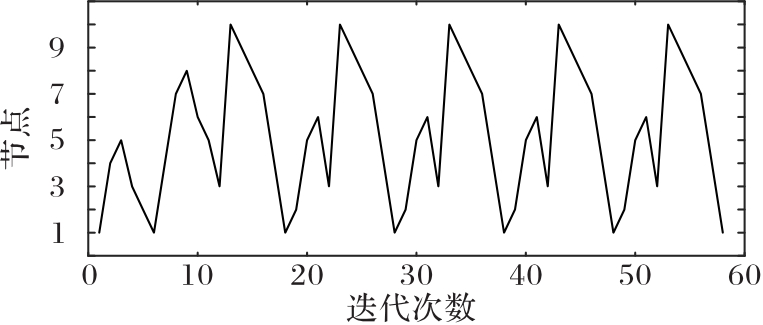
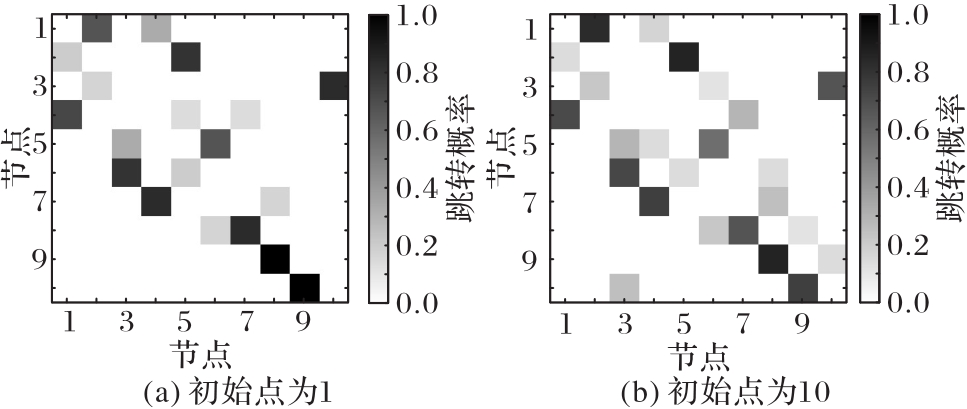
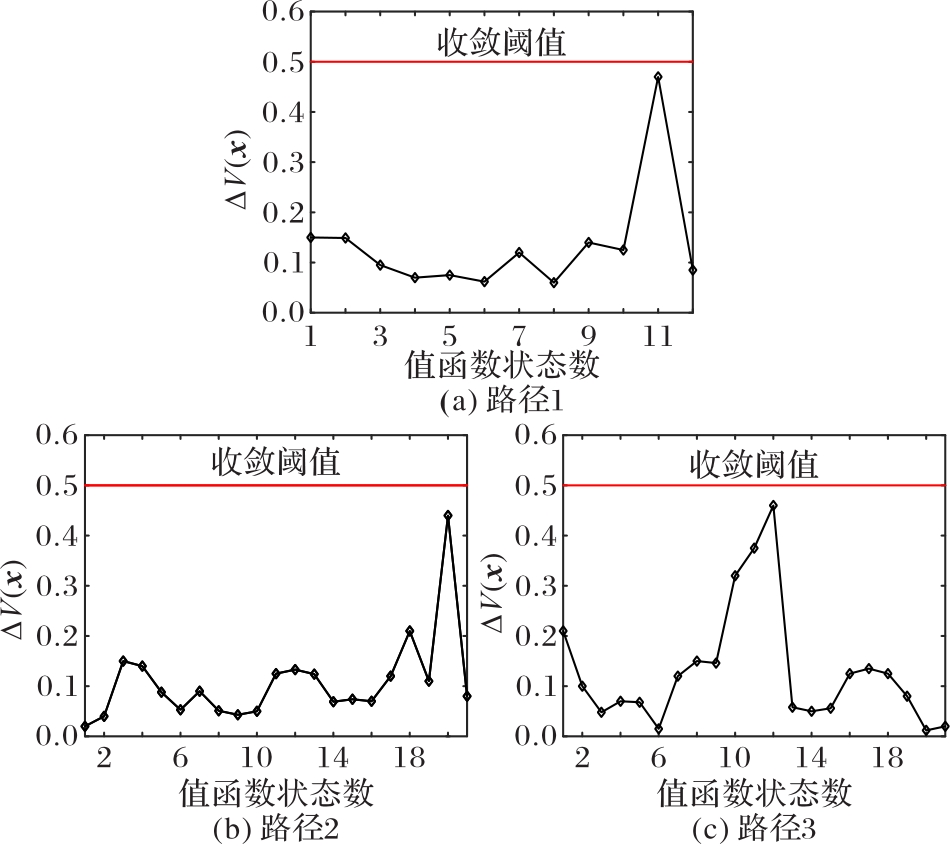
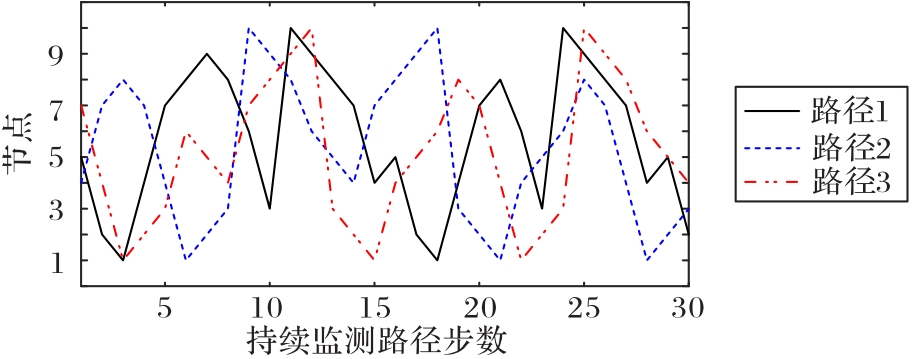
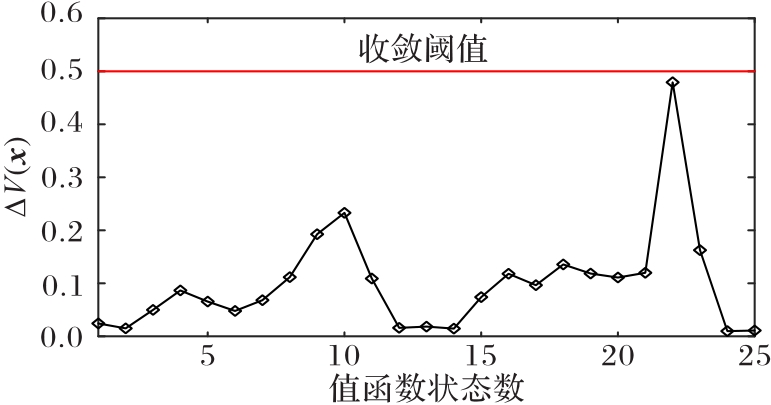
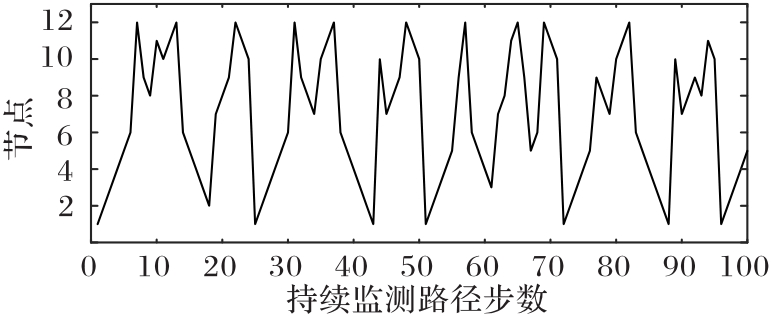
使用无人机(UAV)持续监测指定区域可以起到威慑入侵破坏、及时发现异常等作用,然而固定的监测规律容易被入侵者发现,因此需要设计UAV飞行路径的随机算法。针对以上问题,提出一种基于值函数迭代(VFI)的UAV持续监测路径规划算法。首先,合理选择监测目标点的状态,并分析各监测节点的剩余时间;其次,结合奖励/惩罚收益和路径安全性约束构建该监测目标点对应状态的值函数,在VFI算法过程中基于ε原则和轮盘选择随机选择下一节点;最后,以所有状态的值函数增长趋于饱和为目标,求解UAV持续监测路径。仿真实验结果表明,所提算法获得的信息熵为0.905 0,VFI运行时间为0.363 7 s,相较于传统蚁群算法(ACO),所提算法的信息熵提升了216%,运行时间降低了59%,随机性与快速性均有所提升,验证了具有随机性的UAV飞行路径对提高持续监测效率具有重要意义。
中图分类号: