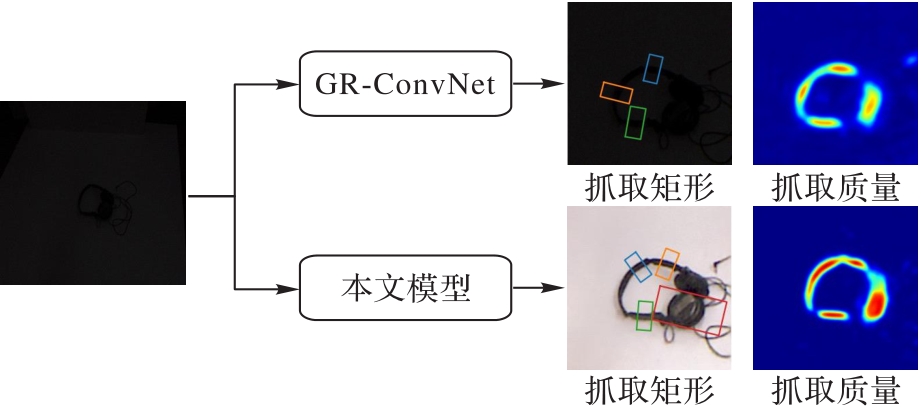
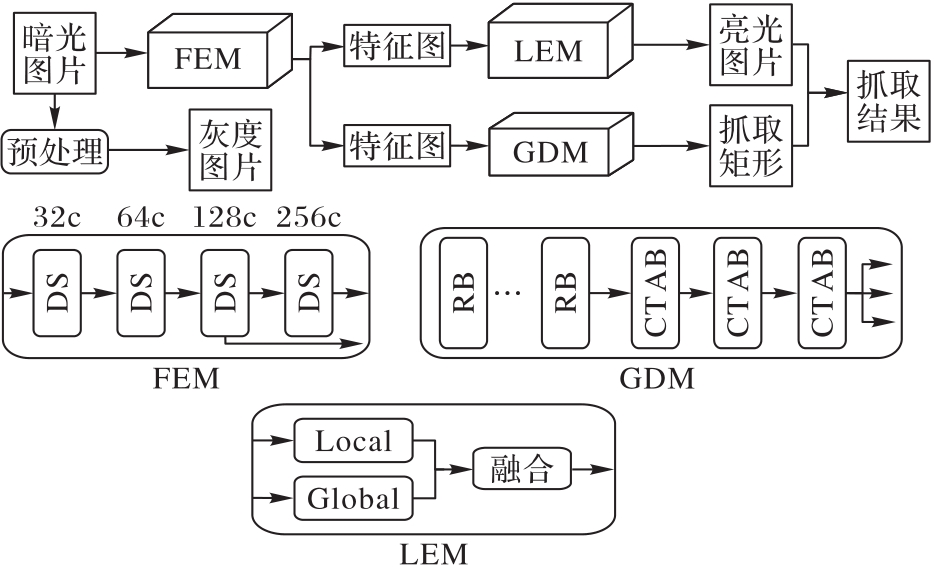
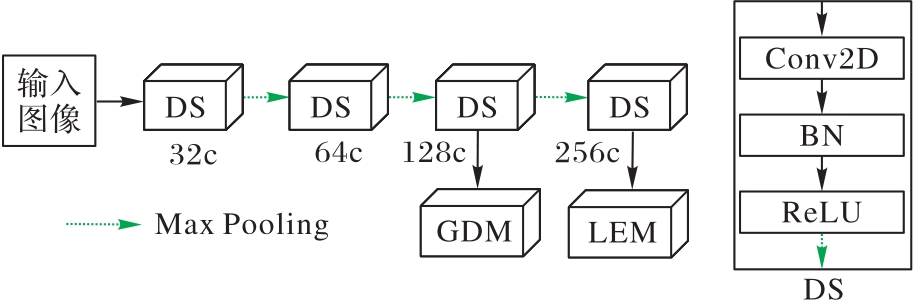
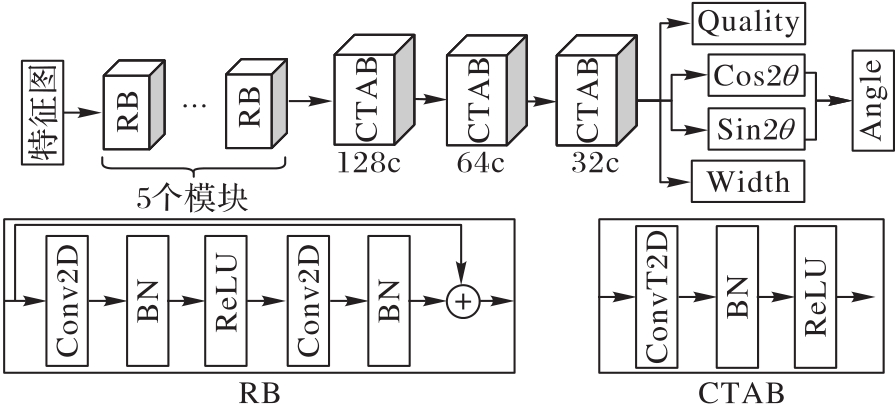
| 1 |
王耀南,江一鸣,姜娇,等. 机器人感知与控制关键技术及其智能制造应用[J]. 自动化学报, 2023, 49(3): 494-513.
|
|
WANG Y N, JIANG Y M, JIANG J, et al. Key technologies of robot perception and control and its intelligent manufacturing applications[J]. Acta Automatica Sinica, 2023, 49(3): 494-513.
|
| 2 |
韩鑫,余永维,杜柳青. 基于改进单次多框检测算法的机器人抓取系统[J]. 计算机应用, 2020, 40(8): 2434-2440.
|
|
HAN X, YU Y W, DU L Q. Robotic grasping system based on improved single shot multibox detector algorithm[J]. Journal of Computer Applications, 2020, 40(8): 2434-2440.
|
| 3 |
姚日辉,陈雯柏,陈启丽,等. 家庭服务机器人知识图谱的构建与应用[J]. 北京邮电大学学报, 2022, 45(5):72-78.
|
|
YAO R H, CHEN W B, CHEN Q L, et al. Construction and application of knowledge graph for home service robot[J]. Journal of Beijing University of Posts and Telecommunications, 2022, 45(5): 72-78.
|
| 4 |
韩非,张道辉,赵新刚,等. 面向水下抓取作业的复合腔体仿生软体手设计[J]. 机器人, 2023, 45(2):207-217. 10.13973/j.cnki.robot.210473
|
|
HAN F, ZHANG D H, ZHAO X G, et al. Design of a bionic soft hand with compound cavity for underwater grasping[J]. Robot, 2023, 45(2): 207-217. 10.13973/j.cnki.robot.210473
|
| 5 |
REDMON J, ANGELOVA A. Real-time grasp detection using convolutional neural networks[C]// Proceedings of the 2015 IEEE International Conference on Robotics and Automation. Piscataway: IEEE, 2015: 1316-1322. 10.1109/icra.2015.7139361
|
| 6 |
ASIF U, TANG J B, HARRER S. GraspNet: an efficient convolutional neural network for real-time grasp detection for low-powered devices[C]// Proceedings of the 27th International Joint Conference on Artificial Intelligence. California: ijcai.org, 2018: 4875-4882. 10.24963/ijcai.2018/677
|
| 7 |
WU Y X, ZHANG F H, FU Y L. Real-time robotic multigrasp detection using anchor-free fully convolutional grasp detector[J]. IEEE Transactions on Industrial Electronics, 2022, 69(12): 13171-13181. 10.1109/tie.2021.3135629
|
| 8 |
YU S, ZHAI D H, XIA Y Q, et al. SE-ResUNet: a novel robotic grasp detection method[J]. IEEE Robotics and Automation Letters, 2022, 7(2): 5238-5245. 10.1109/lra.2022.3145064
|
| 9 |
KUMRA S, JOSHI S, SAHIN F. Antipodal robotic grasping using generative residual convolutional neural network[C]// Proceedings of the 2020 IEEE/RSJ International Conference on Intelligent Robots and Systems. Piscataway: IEEE, 2020: 9626-9633. 10.1109/iros45743.2020.9340777
|
| 10 |
IGNATOV A, KOBYSHEV N, TIMOFTE R, et al. DSLR-quality photos on mobile devices with deep convolutional networks[C]// Proceedings of the 2017 IEEE International Conference on Computer Vision. Piscataway: IEEE, 2017: 3297-3305. 10.1109/iccv.2017.355
|
| 11 |
GOODFELLOW I, POUGET-ABADIE J, MIRZA M, et al. Generative adversarial networks[J]. Communications of the ACM, 2020, 63(11): 139-144. 10.1145/3422622
|
| 12 |
SHARMA V, DIBA A, NEVEN D, et al. Classification-driven dynamic image enhancement[C]// Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2018: 4033-4041. 10.1109/cvpr.2018.00424
|
| 13 |
LIU W Y, REN G F, YU R S, et al. Image-adaptive YOLO for object detection in adverse weather conditions[C]// Proceedings of the 36th AAAI Conference on Artificial Intelligence. Palo Alto, CA: AAAI Press, 2022: 1792-1800. 10.1609/aaai.v36i2.20072
|
| 14 |
JIANG Y, MOSESON S, SAXENA A. Efficient grasping from RGBD images: learning using a new rectangle representation[C]// Proceedings of the 2011 IEEE International Conference on Robotics and Automation. Piscataway: IEEE, 2011: 3304-3311. 10.1109/icra.2011.5980145
|
| 15 |
PINTO L, GUPTA A. Supersizing self-supervision: learning to grasp from 50K tries and 700 robot hours[C]// Proceedings of the 2016 IEEE International Conference on Robotics and Automation. Piscataway: IEEE, 2016: 3406-3413. 10.1109/icra.2016.7487517
|
| 16 |
AINETTER S, FRAUNDORFER F. End-to-end trainable deep neural network for robotic grasp detection and semantic segmentation from RGB[C]// Proceedings of the 2021 IEEE International Conference on Robotics and Automation. Piscataway: IEEE, 2021: 13452-13458. 10.1109/icra48506.2021.9561398
|
| 17 |
SATISH V, MAHLER J, GOLDBERG K. On-policy dataset synthesis for learning robot grasping policies using fully convolutional deep networks[J]. IEEE Robotics and Automation Letters, 2019, 4(2): 1357-1364. 10.1109/lra.2019.2895878
|
| 18 |
CAO H, CHEN G, LI Z J, et al. Lightweight convolutional neural network with Gaussian-based grasping representation for robotic grasping detection[EB/OL]. (2021-01-25) [2023-06-07]..
|
| 19 |
SONG Y X, WEN J, LIU D F, et al. Deep robotic grasping prediction with hierarchical RGB-D fusion[J]. International Journal of Control, Automation and Systems, 2022, 20(1): 243-254. 10.1007/s12555-020-0197-z
|
| 20 |
SHUKLA P, PRAMANIK N, MEHTA D, et al. Generative model based robotic grasp pose prediction with limited dataset[J]. Applied Intelligence, 2022, 52(9): 9952-9966. 10.1007/s10489-021-03011-z
|
| 21 |
WEI C, WANG W J, YANG W H, et al. Deep Retinex decomposition for low-light enhancement[C]// Proceedings of the 2018 British Machine Vision Conference. Durham: BMVA Press, 2018: No.451. 10.48550/arXiv.1808.04560
|
| 22 |
WANG Y, CAO Y, ZHA Z J, et al. Progressive Retinex: mutually reinforced illumination-noise perception network for low-light image enhancement[C]// Proceedings of the 27th ACM International Conference on Multimedia. New York: ACM, 2019: 2015-2023. 10.1145/3343031.3350983
|
| 23 |
LIU R S, MA L, ZHANG J A, et al. Retinex-inspired unrolling with cooperative prior architecture search for low-light image enhancement[C]// Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2021: 10556-10565. 10.1109/cvpr46437.2021.01042
|
| 24 |
GUO C L, LI C Y, GUO J C, et al. Zero-reference deep curve estimation for low-light image enhancement[C]// Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2020: 1777-1786. 10.1109/cvpr42600.2020.00185
|
| 25 |
JIANG Y F, GONG X Y, LIU D, et al. EnlightenGAN: deep light enhancement without paired supervision[J]. IEEE Transactions on Image Processing, 2021, 30: 2340-2349. 10.1109/tip.2021.3051462
|
| 26 |
CUI Z T, LI K C, GU L, et al. You only need 90k parameters to adapt light: a light weight transformer for image enhancement and exposure correction[C]// Proceedings of the 2022 British Machine Vision Conference. Durham: BMVA Press, 2022: No.238.
|
| 27 |
MORRISON D, CORKE P, LEITNER J. Learning robust, real-time, reactive robotic grasping[J]. The International Journal of Robotics Research, 2020, 39(2/3): 183-201. 10.1177/0278364919859066
|
| 28 |
RONNEBERGER O, FISCHER P, BROX T. U-Net: convolutional networks for biomedical image segmentation[C]// Proceedings of the 2015 Medical Image Computing and Computer-Assisted Intervention, LNCS 9351. Cham: Springer, 2015: 234-241.
|
| 29 |
DEPIERRE A, DELLANDRÉA E, CHEN L M. Jacquard: a large scale dataset for robotic grasp detection[C]// Proceedings of the 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems. Piscataway: IEEE, 2018: 3511-3516. 10.1109/iros.2018.8593950
|
| 30 |
IANDOLA F N, HAN S, MOSKEWICZ M W, et al. SqueezeNet: AlexNet-level accuracy with 50x fewer parameters and <0.5 MB model size[EB/OL]. (2016-11-04) [2023-06-07]..
|
| 31 |
HE K M, ZHANG X Y, REN S Q, et al. Deep residual learning for image recognition[C]// Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2016: 770-778. 10.1109/cvpr.2016.90
|
| 32 |
WANG S C, ZHOU Z L, KAN Z. When transformer meets robotic grasping: exploits context for efficient grasp detection[J]. IEEE Robotics and Automation Letters, 2022, 7(3): 8170-8177. 10.1109/lra.2022.3187261
|


 ), 杨静4, 闫涛1,2, 陈斌5,6
), 杨静4, 闫涛1,2, 陈斌5,6