


《计算机应用》唯一官方网站 ›› 2022, Vol. 42 ›› Issue (1): 230-238.DOI: 10.11772/j.issn.1001-9081.2021010137
杨贞, 彭小宝( ), 朱强强, 殷志坚
), 朱强强, 殷志坚
收稿日期:2021-01-25
修回日期:2021-04-22
接受日期:2021-05-10
发布日期:2021-06-04
出版日期:2022-01-10
通讯作者:
彭小宝
作者简介:杨贞(1985—),男,山东菏泽人,讲师,博士,CCF会员,主要研究方向:目标检测、图像分割
Zhen YANG, Xiaobao PENG(), Qiangqiang ZHU, Zhijian YIN
Received:2021-01-25
Revised:2021-04-22
Accepted:2021-05-10
Online:2021-06-04
Published:2022-01-10
Contact:
Xiaobao PENG
About author:YANG Zhen, born in 1985, Ph. D., lecturer. His research interests include object detection, image segmentation.Supported by:摘要:
针对Deeplab V3 Plus在下采样操作中图像细节信息和小目标信息过早丢失的问题,提出了一种基于Deeplab V3 Plus网络架构的自适应注意力机制图像语义分割算法。首先,在Deeplab V3 Plus主干网络的输入层、中间层和输出层均嵌入注意力机制模块,并且引入一个权重值与每个注意力机制模块相乘,以达到约束注意力机制模块的目的;其次,在PASCAL VOC2012 公共分割数据集上训练嵌入注意力模块的Deeplab V3 Plus,以此手动获取注意力机制模块权重值(经验值);然后,探索输入层、中间层和输出层中注意力机制模块的多种融合方式;最后,将注意力机制模块的权重值更改为反向传播自动更新,从而得到注意力机制模块的最优权值和最优分割模型。实验结果表明,与原始Deeplab V3 Plus网络结构相比,引入自适应注意力机制的Deeplab V3 Plus网络结构在PASCAL VOC2012公共分割据集和植物虫害数据集上的平均交并比(MIOU)分别提高了1.4个百分点和0.7个百分点。
中图分类号:
杨贞, 彭小宝, 朱强强, 殷志坚. 基于Deeplab V3 Plus的自适应注意力机制图像分割算法[J]. 计算机应用, 2022, 42(1): 230-238.
Zhen YANG, Xiaobao PENG, Qiangqiang ZHU, Zhijian YIN. Image segmentation algorithm with adaptive attention mechanism based on Deeplab V3 Plus[J]. Journal of Computer Applications, 2022, 42(1): 230-238.

图1 嵌入自适应注意力机制模块的Deeplab V3 Plus网络结构示意图
Fig. 1 Structure schematic diagram of Deeplab V3 Plus network embedded with adaptive attention mechanism module

图2 标准卷积与带空洞的深度可分离卷积
Fig. 2 Standard convolution and atrous depthwise separable convolution
| 模型训练的现象 | |
|---|---|
| 1 | 梯度消失较早,训练终止 |
| 5 | 梯度消失,训练终止 |
| 10 | 训练较为平稳 |
表1 不同α值对应模型训练的现象
Tab. 1 Phenomena of different α values corresponding to model training
| 模型训练的现象 | |
|---|---|
| 1 | 梯度消失较早,训练终止 |
| 5 | 梯度消失,训练终止 |
| 10 | 训练较为平稳 |
| MIOU | MIOU | ||
|---|---|---|---|
| -15.0 | 0.735 | 7.5 | 0.714 |
| -12.5 | 0.740 | 10.0 | 0.726 |
| -10.0 | 0.732 | 12.5 | 0.731 |
| 5.0 | 0.686 | 15.0 | 0.728 |
表2 测试模型时改变α的值对应的分割精度
Tab. 2 Segmentation accuracy corresponding to changing α value when testing model
| MIOU | MIOU | ||
|---|---|---|---|
| -15.0 | 0.735 | 7.5 | 0.714 |
| -12.5 | 0.740 | 10.0 | 0.726 |
| -10.0 | 0.732 | 12.5 | 0.731 |
| 5.0 | 0.686 | 15.0 | 0.728 |
| MIOU | |
|---|---|
| -10.0 | 0.735 |
| -12.5 | 0.752 |
| -15.0 | 0.743 |
表3 验证不同α值对应的分割精度
Tab. 3 Verification of segmentation accuracy of different α values
| MIOU | |
|---|---|
| -10.0 | 0.735 |
| -12.5 | 0.752 |
| -15.0 | 0.743 |
| 注意力机制模块融合方式 | MIOU |
|---|---|
| 方 | 0.755 |
| 方 | 0.754 |
| 方 | 0.752 |
表4 三种注意力机制模块融合策略对应的分割精度
Tab. 4 Segmentation accuracies of three attention mechanism module fusion strategies
| 注意力机制模块融合方式 | MIOU |
|---|---|
| 方 | 0.755 |
| 方 | 0.754 |
| 方 | 0.752 |
| 注意力机制模块 | 对应 |
|---|---|
| S1 | -12.2 |
| S2 | -12.3 |
| S3 | -12.6 |
| S4 | / |
| S5 | -11.8 |
表5 模型最优时各注意力机制模块的α值
Tab. 5 α value of each attention mechanism module when model is optimal
| 注意力机制模块 | 对应 |
|---|---|
| S1 | -12.2 |
| S2 | -12.3 |
| S3 | -12.6 |
| S4 | / |
| S5 | -11.8 |
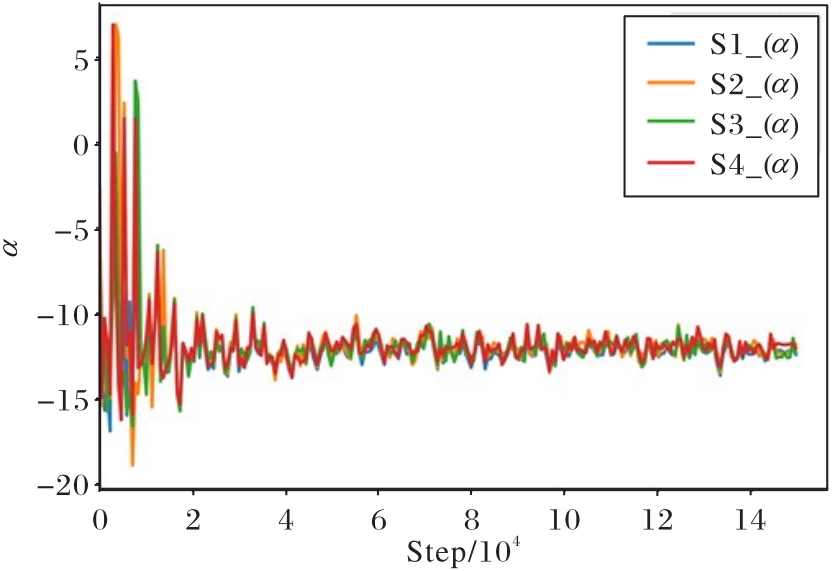
图3 S1、S2、S3、S5模块α值的收敛曲线
Fig. 3 Convergence curve of α value of S1, S2, S3 and S5 modules

图4 五种不同方式在训练过程中损失函数的收敛曲线
Fig. 4 Convergence curves of loss function in training process of five different methods
| 方式 | MIOU | 背景 | 飞机 | 自行车 | 鸟 | 船 | 瓶子 | 公共汽车 | 小汽车 | 猫 | 椅子 | 牛 | 桌子 | 狗 | 马 | 摩托 | 人 | 植物 | 羊 | 沙发 | 火车 | 电视 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 0.745 | 0.942 | 0.891 | 0.619 | 0.902 | 0.711 | 0.739 | 0.883 | 0.856 | 0.896 | 0.335 | 0.817 | 0.486 | 0.829 | 0.798 | 0.828 | 0.844 | 0.475 | 0.850 | 0.498 | 0.732 | 0.787 |
| 2 | 0.755 | 0.945 | 0.894 | 0.648 | 0.901 | 0.695 | 0.786 | 0.877 | 0.836 | 0.883 | 0.335 | 0.837 | 0.520 | 0.820 | 0.806 | 0.813 | 0.860 | 0.507 | 0.851 | 0.520 | 0.746 | 0.774 |
| 3 | 0.754 | 0.946 | 0.900 | 0.636 | 0.896 | 0.678 | 0.776 | 0.876 | 0.842 | 0.897 | 0.326 | 0.819 | 0.546 | 0.837 | 0.801 | 0.849 | 0.859 | 0.518 | 0.850 | 0.504 | 0.728 | 0.753 |
| 4 | 0.752 | 0.945 | 0.893 | 0.644 | 0.880 | 0.677 | 0.755 | 0.890 | 0.830 | 0.881 | 0.348 | 0.826 | 0.544 | 0.794 | 0.800 | 0.832 | 0.860 | 0.508 | 0.834 | 0.528 | 0.771 | 0.762 |
| 5 | 0.759 | 0.945 | 0.899 | 0.638 | 0.889 | 0.692 | 0.761 | 0.898 | 0.848 | 0.903 | 0.345 | 0.842 | 0.576 | 0.838 | 0.818 | 0.831 | 0.852 | 0.525 | 0.830 | 0.499 | 0.751 | 0.763 |
表6 五种不同方式在VOC2012分割数据集上的分割精度
Tab. 6 Segmentation accuracies of five different methods on VOC2012 segmentation dataset
| 方式 | MIOU | 背景 | 飞机 | 自行车 | 鸟 | 船 | 瓶子 | 公共汽车 | 小汽车 | 猫 | 椅子 | 牛 | 桌子 | 狗 | 马 | 摩托 | 人 | 植物 | 羊 | 沙发 | 火车 | 电视 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 0.745 | 0.942 | 0.891 | 0.619 | 0.902 | 0.711 | 0.739 | 0.883 | 0.856 | 0.896 | 0.335 | 0.817 | 0.486 | 0.829 | 0.798 | 0.828 | 0.844 | 0.475 | 0.850 | 0.498 | 0.732 | 0.787 |
| 2 | 0.755 | 0.945 | 0.894 | 0.648 | 0.901 | 0.695 | 0.786 | 0.877 | 0.836 | 0.883 | 0.335 | 0.837 | 0.520 | 0.820 | 0.806 | 0.813 | 0.860 | 0.507 | 0.851 | 0.520 | 0.746 | 0.774 |
| 3 | 0.754 | 0.946 | 0.900 | 0.636 | 0.896 | 0.678 | 0.776 | 0.876 | 0.842 | 0.897 | 0.326 | 0.819 | 0.546 | 0.837 | 0.801 | 0.849 | 0.859 | 0.518 | 0.850 | 0.504 | 0.728 | 0.753 |
| 4 | 0.752 | 0.945 | 0.893 | 0.644 | 0.880 | 0.677 | 0.755 | 0.890 | 0.830 | 0.881 | 0.348 | 0.826 | 0.544 | 0.794 | 0.800 | 0.832 | 0.860 | 0.508 | 0.834 | 0.528 | 0.771 | 0.762 |
| 5 | 0.759 | 0.945 | 0.899 | 0.638 | 0.889 | 0.692 | 0.761 | 0.898 | 0.848 | 0.903 | 0.345 | 0.842 | 0.576 | 0.838 | 0.818 | 0.831 | 0.852 | 0.525 | 0.830 | 0.499 | 0.751 | 0.763 |

图5 五种不同方式在VOC2012分割数据集上的分割效果
Fig. 5 Segmentation effect of five different methods on VOC2012 segmentation dataset
| 分割网络 | MIOU |
|---|---|
| FCN-8S | 0.627 |
| Deeplab-MSc-CRF-LargeFOV | 0.687 |
| Deeplab V2 | 0.733 |
| 本文方法 | 0.759 |
表7 四种不同分割网络在VOC2012 val数据集上的分割结果
Tab. 7 Segmentation results of four different segmentation networks on VOC2012 val dataset
| 分割网络 | MIOU |
|---|---|
| FCN-8S | 0.627 |
| Deeplab-MSc-CRF-LargeFOV | 0.687 |
| Deeplab V2 | 0.733 |
| 本文方法 | 0.759 |
| 方式 | MIOU | 背景 | 害虫 |
|---|---|---|---|
| 1 | 0.908 | 0.988 | 0.828 |
| 2 | 0.913 | 0.988 | 0.838 |
| 3 | 0.912 | 0.988 | 0.835 |
| 4 | 0.911 | 0.988 | 0.833 |
| 5 | 0.915 | 0.989 | 0.842 |
表8 五种不同方式在自建植物虫害数据集上的分割精度
Tab. 8 Segmentation accuracy of five different methods on self-built plant pest dataset
| 方式 | MIOU | 背景 | 害虫 |
|---|---|---|---|
| 1 | 0.908 | 0.988 | 0.828 |
| 2 | 0.913 | 0.988 | 0.838 |
| 3 | 0.912 | 0.988 | 0.835 |
| 4 | 0.911 | 0.988 | 0.833 |
| 5 | 0.915 | 0.989 | 0.842 |

图6 五种不同方式在自建植物虫害数据集上的分割效果
Fig. 6 Segmentation effect of five different methods on self-built plant pest dataset
| 1 | 白傑,郝培涵,陈思汉. 用轻量化卷积神经网络图像语义分割的交通场景理解[J]. 汽车安全与节能学报, 2018, 9(4):433-440. 10.3969/j.issn.1674-8484.2018.04.010 |
| BAI J, HAO P H, CHEN S H. Traffic scene understanding using image semantic segmentation with an improved lightweight convolutional-neural-network[J]. Journal of Automotive Safety and Energy, 2018, 9(4):433-440. 10.3969/j.issn.1674-8484.2018.04.010 | |
| 2 | 苏健民,杨岚心,景维鹏. 基于U-Net的高分辨率遥感图像语义分割方法[J]. 计算机工程与应用, 2019, 55(7):207-213. 10.1109/igarss.2019.8898198 |
| SU J M, YANG L X, JING W P. U-Net based semantic segmentation method for high resolution remote sensing image[J]. Computer Engineering and Applications, 2019, 55(7):207-213. 10.1109/igarss.2019.8898198 | |
| 3 | 宫进昌,赵尚义,王远军. 基于深度学习的医学图像分割研究进展[J]. 中国医学物理学杂志, 2019, 36(4):420-424. 10.3969/j.issn.1005-202X.2019.04.010 |
| GONG J C, ZHAO S Y, WANG Y J. Research progress on deep learning-based medical image segmentation[J]. Chinese Journal of Medical Physics, 2019, 36(4):420-424. 10.3969/j.issn.1005-202X.2019.04.010 | |
| 4 | 何其伟,赵宇坤,宗兆翔. 基于Yolov3算法的视觉检测系统设计与实现[J]. 数字技术与应用, 2020, 38(8):128-131. |
| HE Q W, ZHAO Y K, ZONG Z X. Design and implementation of visual inspection system based on Yolov3 algorithm[J]. Digital Technology and Application, 2020, 38(8):128-131. | |
| 5 | 张文彬,朱敏,张宁,等. 基于卷积神经网络的偏色光下植物图像分割方法[J]. 计算机应用, 2019, 39(12):3665-3672. 10.11772/j.issn.1001-9081.2019040637 |
| ZHANG W B, ZHU M, ZHANG N, et al. Plant image segmentation method under bias light based on convolutional neural network[J]. Journal of Computer Applications, 2019, 39(12): 3665-3672. 10.11772/j.issn.1001-9081.2019040637 | |
| 6 | 孟楚楚,赵立宏. 结合梯度边缘信息改进的全局阈值法与GVF Snake模型的宫颈细胞图像分割[J]. 智能计算机与应用, 2019, 9(2):28-32. 10.3969/j.issn.2095-2163.2019.02.006 |
| MENG C C, ZHAO L H. Segmentation of cervical cell image using improved global thresholding method with gradient edge information and GVF Snake model[J]. Intelligent Computer and Applications, 2019, 9(2):28-32. 10.3969/j.issn.2095-2163.2019.02.006 | |
| 7 | 刘舸,邓兴升. 结合深度学习和图割法的遥感影像建筑物检测[J]. 测绘通报, 2019(11):69-73. 10.1109/igarss.2019.8898155 |
| LIU G, DENG X S. Remote sensing image building extraction based on deep learning and graph cut[J]. Bulletin of Surveying and Mapping, 2019(11): 69-73. 10.1109/igarss.2019.8898155 | |
| 8 | 张长江,汪晓东,吴建斌,等. 图像对比度增强的小波变换法[J]. 仪器仪表学报, 2005(S1):630-631. 10.3321/j.issn:0254-3087.2005.08.290 |
| ZHANG C J, WANG X D, WU J B, et al. An algorithm to enhance contrast for image with wavelet transform[J]. Chinese Journal of Scientific Instrument, 2005(S1):630-631. 10.3321/j.issn:0254-3087.2005.08.290 | |
| 9 | 蒋晓悦,赵荣椿,江泽涛. 基于小波包框架及主成份分析的纹理图像分割[J]. 计算机工程与应用, 2004(4):32-36. 10.3321/j.issn:1002-8331.2004.04.011 |
| JIANG X Y, ZHAO R C, JIANG Z T. Texture segmentation based on wavelet packets frame and principal component analysis[J]. Computer Engineering and Applications, 2004(4):32-36. 10.3321/j.issn:1002-8331.2004.04.011 | |
| 10 | LONG J, SHELHAMER E, DARRELL T. Fully convolutional networks for semantic segmentation[C]// Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2015: 3431-3440. 10.1109/cvpr.2015.7298965 |
| 11 | RONNEBERGER O, FISCHER P, BROX T. U-net: convolutional networks for biomedical image segmentation[C]// Proceedings of the 2015 International Conference on Medical Image Computing and Computer-Assisted Intervention, LNCS9351. Cham: Springer, 2015: 234-241. |
| 12 | BADRINARAYANAN V, KENDALL A, CIPOLLA R. SegNet: a deep convolutional encoder-decoder architecture for image segmentation[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2017, 39(12): 2481-2495. 10.1109/tpami.2016.2644615 |
| 13 | ZHAO H S, SHI J P, QI X J, et al. Pyramid scene parsing network[C]// Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2017: 6230-6239. 10.1109/cvpr.2017.660 |
| 14 | CHEN L C, PAPANDREOU G, KOKKINOS I, et al. Semantic image segmentation with deep convolutional nets and fully connected CRFs[EB/OL]. (2016-06-07) [2020-11-16].. 10.1109/tpami.2017.2699184 |
| 15 | CHEN L C, PAPANDREOU G, KOKKINOS I, et al. DeepLab: semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected CRFs[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2018, 40(4):834-848. 10.1109/tpami.2017.2699184 |
| 16 | CHEN L C, PAPANDREOU G, SCHROFF F, et al. Rethinking atrous convolution for semantic image segmentation[EB/OL]. (2017-12-05) [2020-11-16].. 10.1007/978-3-030-01234-2_49 |
| 17 | CHEN L C, ZHU Y K, PAPANDREOU G, et al. Encoder-decoder with atrous separable convolution for semantic image segmentation[C]// Proceedings of the 2018 European Conference on Computer Vision, LNCS11211. Cham: Springer, 2018: 833-851. 10.1007/978-3-030-01234-2_49 |
| 18 | WANG P Q, CHEN P F, YUAN Y, et al. Understanding convolution for semantic segmentation[C]// Proceedings of the 2018 IEEE Winter Conference on Applications of Computer Vision. Piscataway: IEEE, 2018: 1451-1460. 10.1109/wacv.2018.00163 |
| 19 | YU C Q, WANG J B, PENG C, et al. Learning a discriminative feature network for semantic segmentation[C]// Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2018: 1857-1866. 10.1109/cvpr.2018.00199 |
| 20 | FU J, LIU J, TIAN H J, et al. Dual attention network for scene segmentation[C]// Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2019: 3141-3149. 10.1109/cvpr.2019.00326 |
| 21 | HUANG Z L, WANG X G, HUANG L C, et al. CCNet: criss-cross attention for semantic segmentation[C]// Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision. Piscataway: IEEE, 2019: 603-612. 10.1109/iccv.2019.00069 |
| 22 | YU C Q, WANG J B, GAO C X, et al. Context prior for scene segmentation[C]// Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2020: 12413-12422. 10.1109/cvpr42600.2020.01243 |
| 23 | FU C Y, LIU W, RANGA A, et al. DSSD: deconvolutional single shot detector[EB/OL]. (2017-01-23) [2020-11-16].. 10.1109/icip.2017.8296850 |
| 24 | FU J, LIU J, WANG Y H, et al. Stacked deconvolutional network for semantic segmentation[EB/OL]. (2017-08-16) [2020-11-16].. 10.1109/icip.2017.8296850 |
| 25 | NOH H, HONG S, HAN B. Learning deconvolution network for semantic segmentation[C]// Proceedings of the 2015 IEEE International Conference on Computer Vision. Piscataway: IEEE, 2015: 1520-1528. 10.1109/iccv.2015.178 |
| 26 | TIAN Z, HE T, SHEN C H, et al. Decoders matter for semantic segmentation: data-dependent decoding enables flexible feature aggregation[C]// Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2019: 3121-3130. 10.1109/cvpr.2019.00324 |
| 27 | WANG J Q, CHEN K, XU R, et al. CARAFE: content-aware reassembly of features[C]// Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision. Piscataway: IEEE, 2019: 3007-3016. 10.1109/iccv.2019.00310 |
| 28 | MNIH V, HEESS N, GRAVES A, et al. Recurrent models of visual attention[C]// Proceedings of the 27th International Conference on Neural Information Processing Systems. Cambridge: MIT Press, 2014: 2204-2212. |
| 29 | WANG F, JIANG M Q, QIAN C, et al. Residual attention network for image classification[C]// Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2017: 6450-6458. 10.1109/cvpr.2017.683 |
| 30 | HU J, SHEN L, SUN G. Squeeze-and-excitation networks[C]// Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2018: 7132-7141. 10.1109/cvpr.2018.00745 |
| 31 | ZHANG H, DANA K, SHI J P, et al. Context encoding for semantic segmentation[C]// Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2018: 7151-7160. 10.1109/cvpr.2018.00747 |
| 32 | VASWANI A, SHAZEER N, PARMAR N, et al. Attention is all you need[C]// Proceedings of the 31st International Conference on Neural Information Processing Systems. Red Hook, NY: Curran Associates Inc., 2017: 6000-6010. 10.1016/s0262-4079(17)32358-8 |
| 33 | ZHANG H, GOODFELLOW I, METAXAS D, et al. Self-attention generative adversarial networks[C]// Proceedings of the 36th International Conference on Machine Learning. New York: JMLR.org, 2019: 7354-7363. |
| 34 | CHOLLET F. Xception: deep learning with depthwise separable convolutions[C]// Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2017: 1800-1807. 10.1109/cvpr.2017.195 |
| 35 | EVERINGHAM M, GOOL L VAN, WILLIAMS C K I, et al. The PASCAL Visual Object Classes (VOC) challenge[J]. International Journal of Computer Vision, 2010, 88(2): 303-338. 10.1007/s11263-009-0275-4 |
| [1] | 李威, 陈玲, 徐修远, 朱敏, 郭际香, 周凯, 牛颢, 张煜宸, 易珊烨, 章毅, 罗凤鸣. 基于多任务学习的间质性肺病分割算法[J]. 《计算机应用》唯一官方网站, 2024, 44(4): 1285-1293. |
| [2] | 王铂越, 李英祥, 钟剑丹. 基于改进Res-UNet的昼夜地基云图分割网络[J]. 《计算机应用》唯一官方网站, 2024, 44(4): 1310-1316. |
| [3] | 张鹏飞, 韩李涛, 冯恒健, 李洪梅. 基于注意力机制和全局特征优化的点云语义分割[J]. 《计算机应用》唯一官方网站, 2024, 44(4): 1086-1092. |
| [4] | 吴宁, 罗杨洋, 许华杰. 基于多尺度特征融合的遥感图像语义分割方法[J]. 《计算机应用》唯一官方网站, 2024, 44(3): 737-744. |
| [5] | 刘永江, 陈斌. 基于多尺度记忆库的像素级无监督工业异常检测[J]. 《计算机应用》唯一官方网站, 2024, 44(11): 3587-3594. |
| [6] | 李子怡, 曲婷婷, 崇乾鹏, 徐金东. 基于模糊多尺度特征的遥感图像分割网络[J]. 《计算机应用》唯一官方网站, 2024, 44(11): 3581-3586. |
| [7] | 郑秋梅, 牛薇薇, 王风华, 赵丹. 基于细节增强的双分支实时语义分割网络[J]. 《计算机应用》唯一官方网站, 2024, 44(10): 3058-3066. |
| [8] | 周迪, 张自力, 陈佳, 胡新荣, 何儒汉, 张俊. 基于EfficientNetV2和物体上下文表示的胃癌图像分割方法[J]. 《计算机应用》唯一官方网站, 2023, 43(9): 2955-2962. |
| [9] | 郑帅, 张晓龙, 邓鹤, 任宏伟. 基于多尺度特征融合和网格注意力机制的三维肝脏影像分割方法[J]. 《计算机应用》唯一官方网站, 2023, 43(7): 2303-2310. |
| [10] | 鲁斌, 柳杰林. 基于特征增强的三维点云语义分割[J]. 《计算机应用》唯一官方网站, 2023, 43(6): 1818-1825. |
| [11] | 袁泉, 徐雲鹏, 唐成亮. 基于路径标签的文档级关系抽取方法[J]. 《计算机应用》唯一官方网站, 2023, 43(4): 1029-1035. |
| [12] | 何雪东, 宣士斌, 王款, 陈梦楠. 融合累积分布函数和通道注意力机制的DeepLabV3+图像分割算法[J]. 《计算机应用》唯一官方网站, 2023, 43(3): 936-942. |
| [13] | 廉飞宇, 张良, 王杰栋, 靳于康, 柴玉. 基于图模型与注意力机制的室外场景点云分割模型[J]. 《计算机应用》唯一官方网站, 2023, 43(12): 3911-3917. |
| [14] | 钟建华, 邱创一, 巢建树, 明瑞成, 钟剑锋. 基于语义引导自注意力网络的换衣行人重识别模型[J]. 《计算机应用》唯一官方网站, 2023, 43(12): 3719-3726. |
| [15] | 虞资兴, 瞿绍军, 何鑫, 王卓. 高低维特征引导的实时语义分割网络[J]. 《计算机应用》唯一官方网站, 2023, 43(10): 3077-3085. |
| 阅读次数 | ||||||
|
全文 |
|
|||||
|
摘要 |
|
|||||