


《计算机应用》唯一官方网站 ›› 2022, Vol. 42 ›› Issue (3): 953-959.DOI: 10.11772/j.issn.1001-9081.2021030427
危德健, 王文明, 王全玉( ), 任好盼, 高彦彦, 王志
), 任好盼, 高彦彦, 王志
收稿日期:2021-03-22
修回日期:2021-05-26
接受日期:2021-05-31
发布日期:2022-04-09
出版日期:2022-03-10
通讯作者:
王全玉
作者简介:危德健(1996—),男,福建南平人,硕士研究生,主要研究方向:计算机视觉、深度学习基金资助:
Dejian WEI, Wenming WANG, Quanyu WANG(), Haopan REN, Yanyan GAO, Zhi WANG
Received:2021-03-22
Revised:2021-05-26
Accepted:2021-05-31
Online:2022-04-09
Published:2022-03-10
Contact:
Quanyu WANG
About author:WEI Dejian, born in 1996, M. S. candidate. His research interests include computer vision, deep learning.Supported by:摘要:
近年来基于锚点的三维手部姿态估计方法比较流行,A2J(Anchor-to-Joint)是比较有代表性的方法之一。A2J在深度图上密集地设置锚点,利用神经网络预测锚点到关键点的偏差以及每个锚点的权重。A2J使用预测的偏差和权重,以加权求和的方式计算关键点的坐标,降低了网络回归结果中的噪声。虽然A2J简单高效,但是不恰当的网络结构和损失函数影响了网络的准确度,因此提出改进的网络HigherA2J。首先,使用一个分支预测锚点到关键点的XYZ偏差,更好地利用深度图的3D特性;其次,简化A2J的网络分支结构从而降低网络参数量;最后,设计关键点估计损失函数,结合关键点估计损失和偏差估计损失,有效提高估计准确度。在三个数据集NYU、ICVL和HANDS 2017上的实验结果显示,手部姿态估计的平均误差比A2J都有所降低,分别降低了0.32 mm,0.35 mm和0.10 mm。
中图分类号:
危德健, 王文明, 王全玉, 任好盼, 高彦彦, 王志. 改进的基于锚点的三维手部姿态估计网络[J]. 计算机应用, 2022, 42(3): 953-959.
Dejian WEI, Wenming WANG, Quanyu WANG, Haopan REN, Yanyan GAO, Zhi WANG. Improved 3D hand pose estimation network based on anchor[J]. Journal of Computer Applications, 2022, 42(3): 953-959.

图1 A2J的网络结构
Fig. 1 Network structure of A2J
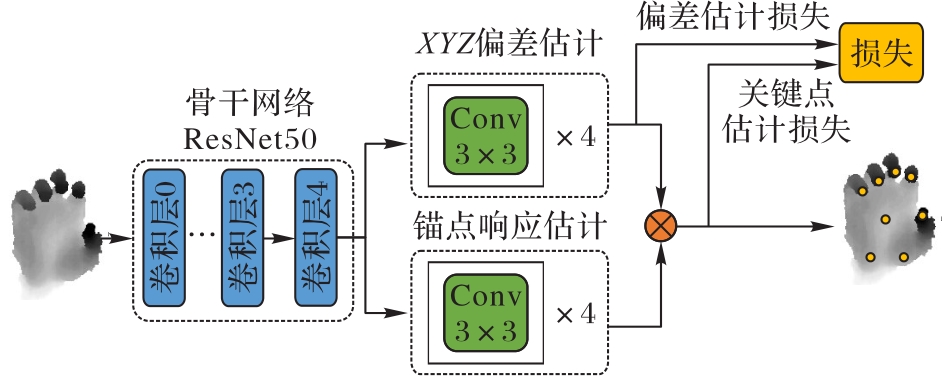
图2 HigherA2J的网络结构
Fig. 2 Network structure of HigherA2J
| 符号 | 定义 | 符号 | 定义 |
|---|---|---|---|
| 锚点集合 | 锚点 | ||
| 锚点 | 预测的锚点 | ||
| 关键点集合 | 预测的锚点 | ||
| 关键点 | 真实的锚点 | ||
| 关键点数量 |
表1 符号定义
Tab. 1 Symbol definition
| 符号 | 定义 | 符号 | 定义 |
|---|---|---|---|
| 锚点集合 | 锚点 | ||
| 锚点 | 预测的锚点 | ||
| 关键点集合 | 预测的锚点 | ||
| 关键点 | 真实的锚点 | ||
| 关键点数量 |

图3 锚点与关键点的关系
Fig. 3 Relationship between anchor points and key points
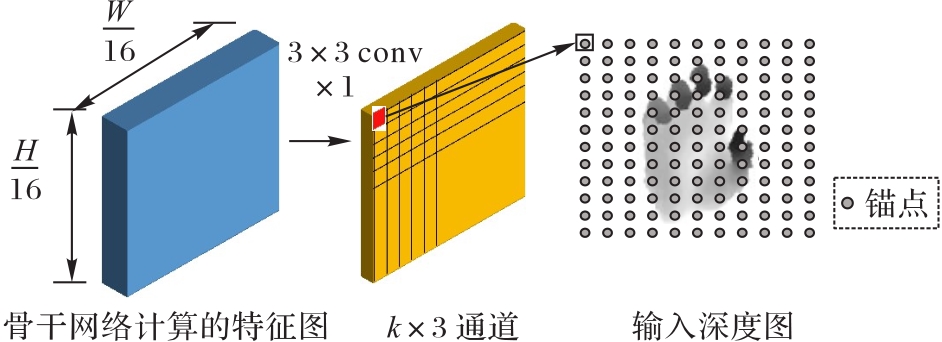
图4 偏差估计分支
Fig. 4 Offset estimation branch
| 方法 | AVG/mm | SEEN/mm | UNSEEN/mm | 帧速率/fps |
|---|---|---|---|---|
| Vanora[ | 11.91 | 9.55 | 13.89 | — |
| THU VCLab[ | 11.70 | 9.15 | 13.83 | — |
| Oasis[ | 11.30 | 8.86 | 13.33 | 48 |
| RCN-3D[ | 9.97 | 7.55 | 12.00 | — |
| V2V*[ | 9.95 | 6.97 | 12.43 | 4 |
| A2J[ | 8.57 | 6.92 | 9.95 | 105 |
| HigherA2J | 8.47 | 6.21 | 10.35 | 121 |
表2 在HANDS 2017数据集上的方法比较
Tab. 2 Method comparison on HANDS 2017 dataset
| 方法 | AVG/mm | SEEN/mm | UNSEEN/mm | 帧速率/fps |
|---|---|---|---|---|
| Vanora[ | 11.91 | 9.55 | 13.89 | — |
| THU VCLab[ | 11.70 | 9.15 | 13.83 | — |
| Oasis[ | 11.30 | 8.86 | 13.33 | 48 |
| RCN-3D[ | 9.97 | 7.55 | 12.00 | — |
| V2V*[ | 9.95 | 6.97 | 12.43 | 4 |
| A2J[ | 8.57 | 6.92 | 9.95 | 105 |
| HigherA2J | 8.47 | 6.21 | 10.35 | 121 |
| 方法 | 平均误差/mm | 帧速率/fps |
|---|---|---|
| Global-to-Local[ | 15.600 | — |
| Lie-X[ | 14.510 | — |
| REN-4×6×6[ | 13.390 | — |
| REN-9×6×6[ | 12.690 | — |
| DeepPrior++[ | 12.240 | 30 |
| Pose-REN[ | 11.810 | — |
| HandPointNet[ | 10.500 | 48 |
| DenseReg[ | 10.200 | 28 |
| V2V[ | 9.220 | 35 |
| P2P[ | 9.045 | 42 |
| A2J[ | 8.610 | 105 |
| HigherA2J | 8.290 | 121 |
表3 在NYU数据集上的方法比较
Tab. 3 Method comparison on NYU dataset
| 方法 | 平均误差/mm | 帧速率/fps |
|---|---|---|
| Global-to-Local[ | 15.600 | — |
| Lie-X[ | 14.510 | — |
| REN-4×6×6[ | 13.390 | — |
| REN-9×6×6[ | 12.690 | — |
| DeepPrior++[ | 12.240 | 30 |
| Pose-REN[ | 11.810 | — |
| HandPointNet[ | 10.500 | 48 |
| DenseReg[ | 10.200 | 28 |
| V2V[ | 9.220 | 35 |
| P2P[ | 9.045 | 42 |
| A2J[ | 8.610 | 105 |
| HigherA2J | 8.290 | 121 |
| 方法 | 平均误差/mm | 帧速率/fps |
|---|---|---|
| JTSC[ | 9.160 | — |
| DeepPrior++[ | 8.100 | 30 |
| REN-4×6×6[ | 7.630 | 30 |
| REN-9×6×6[ | 7.310 | — |
| DenseReg[ | 7.300 | 28 |
| Pose-REN[ | 6.790 | — |
| HandPointNet[ | 6.935 | 48 |
| P2P[ | 6.328 | 42 |
| V2V*[ | 6.286 | 4 |
| A2J[ | 6.461 | 105 |
| HigherA2J | 6.110 | 121 |
表4 在ICVL数据集上的不同方法比较
Tab. 4 Method comparison on ICVL dataset
| 方法 | 平均误差/mm | 帧速率/fps |
|---|---|---|
| JTSC[ | 9.160 | — |
| DeepPrior++[ | 8.100 | 30 |
| REN-4×6×6[ | 7.630 | 30 |
| REN-9×6×6[ | 7.310 | — |
| DenseReg[ | 7.300 | 28 |
| Pose-REN[ | 6.790 | — |
| HandPointNet[ | 6.935 | 48 |
| P2P[ | 6.328 | 42 |
| V2V*[ | 6.286 | 4 |
| A2J[ | 6.461 | 105 |
| HigherA2J | 6.110 | 121 |
| 方法 | 手掌 | 手腕1 | 手腕2 | 拇指根 | 拇指中 | 拇指间 | 食指中 | 食物尖 | 中指中 | 中指尖 | 无名指中 | 无名指尖 | 小指中 | 小指尖 | 平均 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| REN-4×6×6[ | 8.2 | 14.0 | 11.3 | 12.0 | 13.1 | 15.6 | 12.1 | 17.8 | 10.7 | 17.2 | 9.9 | 16.2 | 11.8 | 17.4 | 13.39 |
| Pose-REN[ | 7.4 | 13.9 | 11.5 | 10.7 | 11.3 | 13.9 | 10.9 | 16.8 | 8.7 | 14.5 | 8.2 | 13.4 | 9.4 | 14.9 | 11.81 |
| HandPointNet[ | 7.9 | 9.6 | 8.8 | 8.6 | 10.4 | 12.5 | 10.9 | 14.6 | 8.6 | 13.3 | 7.9 | 12.7 | 9.3 | 12.4 | 10.54 |
| Point-to-Point[ | 6.9 | 9.1 | 8.3 | 7.9 | 8.5 | 10.5 | 9.2 | 12.0 | 7.8 | 10.6 | 7.0 | 10.3 | 7.7 | 10.7 | 9.04 |
| A2J[ | 7.3 | 9.3 | 9.3 | 7.9 | 8.2 | 10.6 | 8.4 | 10.8 | 7.4 | 9.6 | 6.9 | 8.7 | 7.1 | 9.2 | 8.61 |
| HigherA2J | 6.6 | 9.7 | 9.0 | 7.2 | 8.2 | 10.4 | 7.9 | 10.1 | 6.6 | 8.9 | 6.4 | 8.7 | 7.2 | 9.2 | 8.29 |
表5 在NYU数据集上不同关键点的误差 (mm)
Tab. 5 Errors of different key points on NYU dataset
| 方法 | 手掌 | 手腕1 | 手腕2 | 拇指根 | 拇指中 | 拇指间 | 食指中 | 食物尖 | 中指中 | 中指尖 | 无名指中 | 无名指尖 | 小指中 | 小指尖 | 平均 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| REN-4×6×6[ | 8.2 | 14.0 | 11.3 | 12.0 | 13.1 | 15.6 | 12.1 | 17.8 | 10.7 | 17.2 | 9.9 | 16.2 | 11.8 | 17.4 | 13.39 |
| Pose-REN[ | 7.4 | 13.9 | 11.5 | 10.7 | 11.3 | 13.9 | 10.9 | 16.8 | 8.7 | 14.5 | 8.2 | 13.4 | 9.4 | 14.9 | 11.81 |
| HandPointNet[ | 7.9 | 9.6 | 8.8 | 8.6 | 10.4 | 12.5 | 10.9 | 14.6 | 8.6 | 13.3 | 7.9 | 12.7 | 9.3 | 12.4 | 10.54 |
| Point-to-Point[ | 6.9 | 9.1 | 8.3 | 7.9 | 8.5 | 10.5 | 9.2 | 12.0 | 7.8 | 10.6 | 7.0 | 10.3 | 7.7 | 10.7 | 9.04 |
| A2J[ | 7.3 | 9.3 | 9.3 | 7.9 | 8.2 | 10.6 | 8.4 | 10.8 | 7.4 | 9.6 | 6.9 | 8.7 | 7.1 | 9.2 | 8.61 |
| HigherA2J | 6.6 | 9.7 | 9.0 | 7.2 | 8.2 | 10.4 | 7.9 | 10.1 | 6.6 | 8.9 | 6.4 | 8.7 | 7.2 | 9.2 | 8.29 |
| 方法 | 手掌 | 拇指根 | 拇指中 | 拇指尖 | 食指根 | 食指中 | 食物尖 | 中指根 | 中指中 | 中指尖 | 无名指根 | 无名指中 | 无名指尖 | 小指根 | 小指中 | 小指尖 | 平均 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| REN-4×6×6[ | 5.1 | 6.4 | 6.6 | 8.1 | 5.7 | 7.7 | 10.9 | 5.3 | 8.3 | 10.8 | 5.6 | 7.9 | 11.0 | 6.4 | 6.9 | 9.4 | 7.63 |
| Pose-REN[ | 5.1 | 6.4 | 6.9 | 7.2 | 6.7 | 6.7 | 8.6 | 5.0 | 6.6 | 8.8 | 5.3 | 6.6 | 8.8 | 6.4 | 5.9 | 7.5 | 6.79 |
| HandPointNet[ | 5.3 | 6.3 | 6.4 | 7.3 | 6.6 | 7.1 | 7.7 | 5.4 | 7.4 | 9.0 | 5.7 | 7.7 | 8.6 | 6.4 | 6.6 | 7.3 | 6.93 |
| Point-to-Point[ | 6.0 | 6.2 | 4.9 | 6.2 | 6.2 | 5.7 | 7.0 | 5.6 | 6.4 | 7.8 | 5.7 | 6.8 | 7.5 | 5.9 | 6.0 | 7.4 | 6.33 |
| A2J[ | 5.7 | 6.0 | 6.3 | 6.9 | 7.0 | 5.7 | 6.3 | 5.5 | 6.4 | 7.6 | 5.5 | 6.2 | 7.6 | 7.2 | 6.3 | 7.3 | 6.46 |
| HigherA2J | 5.4 | 5.4 | 5.4 | 6.1 | 6.1 | 5.1 | 6.1 | 5.2 | 6.0 | 7.6 | 5.3 | 6.2 | 7.9 | 6.7 | 6.4 | 7.0 | 6.11 |
表6 在ICVL数据集上不同关键点的误差 (mm)
Tab. 6 Errors of different key points on ICVL dataset
| 方法 | 手掌 | 拇指根 | 拇指中 | 拇指尖 | 食指根 | 食指中 | 食物尖 | 中指根 | 中指中 | 中指尖 | 无名指根 | 无名指中 | 无名指尖 | 小指根 | 小指中 | 小指尖 | 平均 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| REN-4×6×6[ | 5.1 | 6.4 | 6.6 | 8.1 | 5.7 | 7.7 | 10.9 | 5.3 | 8.3 | 10.8 | 5.6 | 7.9 | 11.0 | 6.4 | 6.9 | 9.4 | 7.63 |
| Pose-REN[ | 5.1 | 6.4 | 6.9 | 7.2 | 6.7 | 6.7 | 8.6 | 5.0 | 6.6 | 8.8 | 5.3 | 6.6 | 8.8 | 6.4 | 5.9 | 7.5 | 6.79 |
| HandPointNet[ | 5.3 | 6.3 | 6.4 | 7.3 | 6.6 | 7.1 | 7.7 | 5.4 | 7.4 | 9.0 | 5.7 | 7.7 | 8.6 | 6.4 | 6.6 | 7.3 | 6.93 |
| Point-to-Point[ | 6.0 | 6.2 | 4.9 | 6.2 | 6.2 | 5.7 | 7.0 | 5.6 | 6.4 | 7.8 | 5.7 | 6.8 | 7.5 | 5.9 | 6.0 | 7.4 | 6.33 |
| A2J[ | 5.7 | 6.0 | 6.3 | 6.9 | 7.0 | 5.7 | 6.3 | 5.5 | 6.4 | 7.6 | 5.5 | 6.2 | 7.6 | 7.2 | 6.3 | 7.3 | 6.46 |
| HigherA2J | 5.4 | 5.4 | 5.4 | 6.1 | 6.1 | 5.1 | 6.1 | 5.2 | 6.0 | 7.6 | 5.3 | 6.2 | 7.9 | 6.7 | 6.4 | 7.0 | 6.11 |
| 实验描述 | 平均误差/mm |
|---|---|
使用XY偏差估计分支和Z偏差估计分支 替代XYZ偏差估计分支 | 8.52 |
| 去掉偏差估计损失 | 8.58 |
| 使用SmoothL1损失函数替换距离损失函数 | 8.43 |
| HigherA2J | 8.29 |
表7 在NYU数据集上的消融实验结果
Tab. 7 Ablation experimental results on NYU dataset
| 实验描述 | 平均误差/mm |
|---|---|
使用XY偏差估计分支和Z偏差估计分支 替代XYZ偏差估计分支 | 8.52 |
| 去掉偏差估计损失 | 8.58 |
| 使用SmoothL1损失函数替换距离损失函数 | 8.43 |
| HigherA2J | 8.29 |
| 损失函数 | 骨干网络 | 平均误差/mm | |
|---|---|---|---|
| NYU数据集 | ICVL数据集 | ||
| 距离损失函数 | ResNet18 | 8.55 | 6.38 |
| SmoothL1 | 8.82 | 6.47 | |
| 距离损失函数 | ResNet50 | 8.29 | 6.11 |
| SmoothL1 | 8.43 | 8.33 | |
表8 在NYU数据集和ICVL数据集上距离损失函数和SmoothL1损失函数结果对比
Tab. 8 Result comparison between distance loss and SmoothL1 loss on NYU dataset and ICVL datasets
| 损失函数 | 骨干网络 | 平均误差/mm | |
|---|---|---|---|
| NYU数据集 | ICVL数据集 | ||
| 距离损失函数 | ResNet18 | 8.55 | 6.38 |
| SmoothL1 | 8.82 | 6.47 | |
| 距离损失函数 | ResNet50 | 8.29 | 6.11 |
| SmoothL1 | 8.43 | 8.33 | |
| 1 | 李瑞.图像和深度图中的动作识别与手势姿态估计[D].杭州:浙江大学,2019. |
| LI R. Action recognition and hand pose estimation in images and depth maps [D]. Hangzhou: Zhejiang University, 2019. | |
| 2 | GE L H, LIANG H, YUAN J Set al. 3D convolutional neural networks for efficient and robust hand pose estimation from single depth images [C]// Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2017: 1991-2000. 10.1109/cvpr.2017.602 |
| 3 | FEHR M, FURRER F, DRYANOVSKI I, et al. TSDF-based change detection for consistent long-term dense reconstruction and dynamic object discovery [C]// Proceedings of the 2017 IEEE International Conference on Robotics and automation. Piscataway: IEEE, 2017: 5237-5244. 10.1109/icra.2017.7989614 |
| 4 | MOON G, CHANG J Y, LEE K M. V2V-PoseNet: voxel-to-voxel prediction network for accurate 3D hand and human pose estimation from a single depth map [C]// Proceedings of the 2018 International Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2018: 5079-5088. 10.1109/cvpr.2018.00533 |
| 5 | GE L H, REN Z, YUAN J S. Point-to-point regression PointNet for 3D hand pose estimation [C]// Proceedings of the 2018 European Conference on Computer Vision. Cham: Springer, 2018: 475-491. 10.1007/978-3-030-01261-8_29 |
| 6 | TOMPSON J, STEIN M, LECUN Y, et al. Real-time continuous pose recovery of human hands using convolutional networks [J]. ACM Transactions on Graphics, 2014, 33(5): 1-10. 10.1145/2629500 |
| 7 | GE L H, LIANG H, YUAN J S, et al. Robust 3D hand pose estimation from single depth images using multi-view CNNs [J]. IEEE Transactions on Image Processing, 2018, 27(9): 4422-4436. 10.1109/tip.2018.2834824 |
| 8 | SUN X, XIAO B, WEI F Y, et al. Integral human pose regression [C]// Proceedings of the 2018 European Conference on Computer Vision. Cham: Springer, 2018: 529-545. 10.1007/978-3-030-01231-1_33 |
| 9 | XIONG F, ZHANG B S, XIAO Y, et al. A2j: Anchor-to-joint regression network for 3D articulated pose estimation from a single depth image [C]// Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision. Piscataway: IEEE, 2019: 793-802. 10.1109/iccv.2019.00088 |
| 10 | HE K M, ZHANG X Y, REN S Q, et al. Deep residual learning for image recognition [C]// Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2016: 770-778. 10.1109/cvpr.2016.90 |
| 11 | HUANG W T, REN P F, WANG J Y, et al. AWR: adaptive weighting regression for 3D hand pose estimation [C]// Proceedings of the 2020 AAAI Conference on Artificial Intelligence. Menlo Park, CA: AAAI Press, 2020: 11061-11068. 10.1609/aaai.v34i07.6761 |
| 12 | YUAN S, YE Q, GARCIA-HERNANDO G,et al. The 2017 hands in the million challenge on 3D hand pose estimation [EB/OL]. [2020-06-20]. . |
| 13 | YUAN S X, YE Q, STENGER B,et al. BigHand2.2M benchmark: Hand pose dataset and state of the art analysis [C]// Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2017: 4866-4874. 10.1109/cvpr.2017.279 |
| 14 | JUNG H YUB, LEE S, SEOK HEO Y,et al. Random tree walk toward instantaneous 3D human pose estimation [C]// Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2015: 2467-2474. 10.1109/cvpr.2015.7298861 |
| 15 | GUO H K, WANG G J, CHEN X H,et al. Towards good practices for deep 3D hand pose estimation [EB/OL]. [2020-06-23]. . |
| 16 | CHEN X H, WANG G J, GUO H K,et al. Pose guided structured region ensemble network for cascaded hand pose estimation [J]. Neurocomputing, 2020, 395: 138-149. 10.1016/j.neucom.2018.06.097 |
| 17 | TANG D H, JIN CHANG H, TEJANI A,et al. Latent regression forest: structured estimation of 3D articulated hand posture [C]// Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2014: 3786-3793. 10.1109/cvpr.2014.490 |
| 18 | YUAN S X, GARCIA-HERNANDO G, STENGER B,et al. Depth-based 3D hand pose estimation: from current achievements to future goals [C]// Proceedings of the 2018 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2018: 2636-2645. 10.1109/cvpr.2018.00279 |
| 19 | GE L H, CAI Y J, WENG J W,et al. Hand PointNet: 3D hand pose estimation using point sets [C]// Proceedings of the 2018 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2018: 8417-8426. 10.1109/cvpr.2018.00878 |
| 20 | MADADI M, ESCALERA S, BARÓ X,et al. End-to-end global to local CNN learning for hand pose recovery in depth data [EB/OL]. [2020-05-26]. . 10.1049/cvi2.12064 |
| 21 | XU C, GOVINDARAJAN L N, ZHANG Y,et al. Lie-X: depth image based articulated object pose estimation, tracking, and action recognition on lie groups [J]. International Journal of Computer Vision, 2017, 123(3): 454-478. 10.1007/s11263-017-0998-6 |
| 22 | OBERWEGER M, LEPETIT V. DeepPrior++: improving fast and accurate 3D hand pose estimation [C]// Proceedings of the 2017 IEEE International Conference on Computer Vision Workshops. Piscataway: IEEE, 2017: 585-594. 10.1109/iccvw.2017.75 |
| 23 | WAN C D, PROBST T, GOOL L VAN,et al. Dense 3D regression for hand pose estimation [C]// Proceedings of the 2018 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2018: 5147-5156. 10.1109/cvpr.2018.00540 |
| 24 | FOURURE D, EMONET R, FROMONT E,et al. Multi-task, multi-domain learning: application to semantic segmentation and pose regression [J]. Neurocomputing, 2017, 251: 68-80. 10.1016/j.neucom.2017.04.014 |
| [1] | 黄云川, 江永全, 黄骏涛, 杨燕. 基于元图同构网络的分子毒性预测[J]. 《计算机应用》唯一官方网站, 2024, 44(9): 2964-2969. |
| [2] | 李顺勇, 李师毅, 胥瑞, 赵兴旺. 基于自注意力融合的不完整多视图聚类算法[J]. 《计算机应用》唯一官方网站, 2024, 44(9): 2696-2703. |
| [3] | 秦璟, 秦志光, 李发礼, 彭悦恒. 基于概率稀疏自注意力神经网络的重性抑郁疾患诊断[J]. 《计算机应用》唯一官方网站, 2024, 44(9): 2970-2974. |
| [4] | 王熙源, 张战成, 徐少康, 张宝成, 罗晓清, 胡伏原. 面向手术导航3D/2D配准的无监督跨域迁移网络[J]. 《计算机应用》唯一官方网站, 2024, 44(9): 2911-2918. |
| [5] | 潘烨新, 杨哲. 基于多级特征双向融合的小目标检测优化模型[J]. 《计算机应用》唯一官方网站, 2024, 44(9): 2871-2877. |
| [6] | 李云, 王富铕, 井佩光, 王粟, 肖澳. 基于不确定度感知的帧关联短视频事件检测方法[J]. 《计算机应用》唯一官方网站, 2024, 44(9): 2903-2910. |
| [7] | 陈虹, 齐兵, 金海波, 武聪, 张立昂. 融合1D-CNN与BiGRU的类不平衡流量异常检测[J]. 《计算机应用》唯一官方网站, 2024, 44(8): 2493-2499. |
| [8] | 赵宇博, 张丽萍, 闫盛, 侯敏, 高茂. 基于改进分段卷积神经网络和知识蒸馏的学科知识实体间关系抽取[J]. 《计算机应用》唯一官方网站, 2024, 44(8): 2421-2429. |
| [9] | 张春雪, 仇丽青, 孙承爱, 荆彩霞. 基于两阶段动态兴趣识别的购买行为预测模型[J]. 《计算机应用》唯一官方网站, 2024, 44(8): 2365-2371. |
| [10] | 刘禹含, 吉根林, 张红苹. 基于骨架图与混合注意力的视频行人异常检测方法[J]. 《计算机应用》唯一官方网站, 2024, 44(8): 2551-2557. |
| [11] | 李钟华, 白云起, 王雪津, 黄雷雷, 林初俊, 廖诗宇. 基于图像增强的低照度人脸检测[J]. 《计算机应用》唯一官方网站, 2024, 44(8): 2588-2594. |
| [12] | 邓凯丽, 魏伟波, 潘振宽. 改进掩码自编码器的工业缺陷检测方法[J]. 《计算机应用》唯一官方网站, 2024, 44(8): 2595-2603. |
| [13] | 顾焰杰, 张英俊, 刘晓倩, 周围, 孙威. 基于时空多图融合的交通流量预测[J]. 《计算机应用》唯一官方网站, 2024, 44(8): 2618-2625. |
| [14] | 石乾宏, 杨燕, 江永全, 欧阳小草, 范武波, 陈强, 姜涛, 李媛. 面向空气质量预测的多粒度突变拟合网络[J]. 《计算机应用》唯一官方网站, 2024, 44(8): 2643-2650. |
| [15] | 吴筝, 程志友, 汪真天, 汪传建, 王胜, 许辉. 基于深度学习的患者麻醉复苏过程中的头部运动幅度分类方法[J]. 《计算机应用》唯一官方网站, 2024, 44(7): 2258-2263. |
| 阅读次数 | ||||||
|
全文 |
|
|||||
|
摘要 |
|
|||||