


《计算机应用》唯一官方网站 ›› 2022, Vol. 42 ›› Issue (3): 757-763.DOI: 10.11772/j.issn.1001-9081.2021040857
所属专题: 人工智能; 2021年中国计算机学会人工智能会议(CCFAI 2021)
• 2021年中国计算机学会人工智能会议(CCFAI 2021) • 上一篇 下一篇
张璐, 方春, 祝铭( )
)
收稿日期:2021-05-25
修回日期:2021-06-30
接受日期:2021-07-06
发布日期:2021-11-09
出版日期:2022-03-10
通讯作者:
祝铭
作者简介:张璐(1996—),男,山东潍坊人,硕士研究生,主要研究方向:计算机视觉、深度学习基金资助:
Lu ZHANG, Chun FANG, Ming ZHU()
Received:2021-05-25
Revised:2021-06-30
Accepted:2021-07-06
Online:2021-11-09
Published:2022-03-10
Contact:
Ming ZHU
About author:ZHANG Lu, born in 1996, M. S. candidate. His research interests include computer vision, deep learning.Supported by:摘要:
为了加强对老年人的监护、降低跌倒带来的安全风险,提出了一种新的基于Res2Net-YOLACT和融合特征的室内跌倒检测算法。首先,通过融入Res2Net模块的YOLACT网络来提取视频图像序列中的人体轮廓;然后,利用两级判断的方法做出跌倒决策,其中一级判别通过运动速度特征粗略判断是否发生异常状态,二级通过融合人体形状特征和深度特征的模型结构对人体姿势进行判别;最后,当检测出跌倒且发生时间大于阈值时,发出跌倒报警。实验结果表明,该跌倒检测算法可以在复杂的场景下很好地提取到人体轮廓,对光照的鲁棒性较好,并且检测速度可达每秒28帧,能满足实时检测要求。此外,融入手工特征后的算法分类性能表现更优,分类准确率达98.65%,比卷积神经网络(CNN)特征算法提升了1.03个百分点。
中图分类号:
张璐, 方春, 祝铭. 基于Res2Net-YOLACT和融合特征的室内跌倒检测算法[J]. 计算机应用, 2022, 42(3): 757-763.
Lu ZHANG, Chun FANG, Ming ZHU. Indoor fall detection algorithm based on Res2Net-YOLACT and fusion feature[J]. Journal of Computer Applications, 2022, 42(3): 757-763.

图1 Res2Net-YOLACT的网络结构
Fig.1 Network structure of Res2Net-YOLACT
| 网络层 | 卷积结构 | 卷积核 | 卷积步长 | 特征图大小 |
|---|---|---|---|---|
| 输入层 | — | — | — | 550×550 |
| Conv1 | — | 7×7@64 | 2 | 275×275 |
| Pool1 | Maxpool | 3×3@64 | 2 | 138×138 |
| L1 | Bottlenect (×3) | 1×1@64 3×3@64 3×3@64 3×3@64 1×1@256 | — | 138×138 |
| L2 | Bottlenect (×4) | 1×1@128 3×3@128 3×3@128 3×3@128 1×1@512 | — | 69×69 |
| L3 | Bottlenect (×6) | 1×1@256 3×3@256 3×3@256 3×3@256 1×1@1024 | — | 35×35 |
| L4 | Bottlenect (×3) | 1×1@512 3×3@512 3×3@512 3×3@512 1×1@2 048 | — | 18×18 |
表1 用于特征提取的Res2Net-50骨干网络
Tab.1 Res2Net-50 backbone network for feature extraction
| 网络层 | 卷积结构 | 卷积核 | 卷积步长 | 特征图大小 |
|---|---|---|---|---|
| 输入层 | — | — | — | 550×550 |
| Conv1 | — | 7×7@64 | 2 | 275×275 |
| Pool1 | Maxpool | 3×3@64 | 2 | 138×138 |
| L1 | Bottlenect (×3) | 1×1@64 3×3@64 3×3@64 3×3@64 1×1@256 | — | 138×138 |
| L2 | Bottlenect (×4) | 1×1@128 3×3@128 3×3@128 3×3@128 1×1@512 | — | 69×69 |
| L3 | Bottlenect (×6) | 1×1@256 3×3@256 3×3@256 3×3@256 1×1@1024 | — | 35×35 |
| L4 | Bottlenect (×3) | 1×1@512 3×3@512 3×3@512 3×3@512 1×1@2 048 | — | 18×18 |

图2 跌倒检测总体流程
Fig.2 Overall flowchart of fall detection
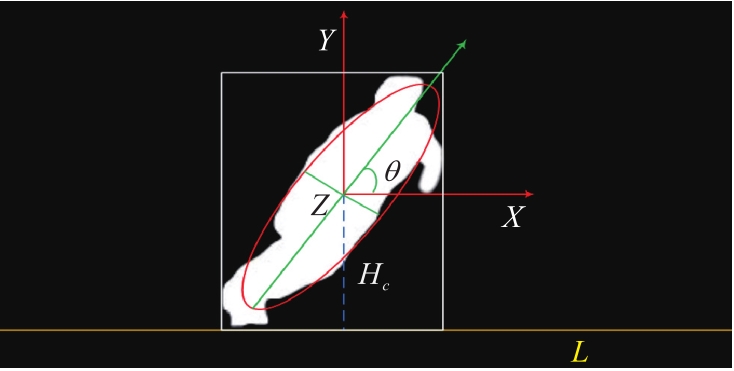
图3 跌倒人体的椭圆拟合及关键参数
Fig.3 Ellipse fitting and key parameters of falling human body

图4 姿势分类的模型结构
Fig.4 Model structure of behavior classification
| 层数 | 输入尺寸 | 卷积核 | 池化 | 输出尺寸 |
|---|---|---|---|---|
| 输入层 | 30×30 | — | — | 30×30 |
| Conv1 | 30×30 | 3×3@32 | — | 28×28@32 |
| Pooling1 | 28×28 | — | Max pooling | 14×14@32 |
| Conv2 | 14×14 | 3×3@16 | — | 12×12@16 |
| Pooling2 | 12×12 | — | Max pooling | 6×6@16 |
| Conv3 | 6×6 | 3×3@8 | — | 4×4@8 |
| Pooling3 | 4×4 | — | Max pooling | 4×4@8 |
| FC | 4×4@8 | — | — | 1×128 |
| FC | 1×128 | — | — | 1×64 |
| 输出层 | 1×64 | — | — | 1×4 |
表2 卷积神经网络参数
Tab.2 Convolutional neural network parameters
| 层数 | 输入尺寸 | 卷积核 | 池化 | 输出尺寸 |
|---|---|---|---|---|
| 输入层 | 30×30 | — | — | 30×30 |
| Conv1 | 30×30 | 3×3@32 | — | 28×28@32 |
| Pooling1 | 28×28 | — | Max pooling | 14×14@32 |
| Conv2 | 14×14 | 3×3@16 | — | 12×12@16 |
| Pooling2 | 12×12 | — | Max pooling | 6×6@16 |
| Conv3 | 6×6 | 3×3@8 | — | 4×4@8 |
| Pooling3 | 4×4 | — | Max pooling | 4×4@8 |
| FC | 4×4@8 | — | — | 1×128 |
| FC | 1×128 | — | — | 1×64 |
| 输出层 | 1×64 | — | — | 1×4 |

图5 不同人体姿势的提取结果
Fig.5 Extraction results of different human poses
| 视频名称 | 视频大小 | 录制环境 | 包含的行为活动 |
|---|---|---|---|
| Video1 | 320×240 | 白天光照充足 | 站立、弯身、跌倒 |
| Video2 | 320×240 | 白天光照充足 | 站立、弯身、坐 |
| Video3 | 320×240 | 夜晚灯光(亮光) | 站立、弯身、跌倒 |
| Video4 | 320×240 | 夜晚灯光(亮光) | 站立、弯身、坐 |
| Video5 | 320×240 | 夜晚灯光(暗光) | 站立、弯身、跌倒 |
| Video6 | 320×240 | 夜晚灯光(暗光) | 站立、弯身、坐 |
表3 视频信息的介绍
Tab.3 Introduction of video information
| 视频名称 | 视频大小 | 录制环境 | 包含的行为活动 |
|---|---|---|---|
| Video1 | 320×240 | 白天光照充足 | 站立、弯身、跌倒 |
| Video2 | 320×240 | 白天光照充足 | 站立、弯身、坐 |
| Video3 | 320×240 | 夜晚灯光(亮光) | 站立、弯身、跌倒 |
| Video4 | 320×240 | 夜晚灯光(亮光) | 站立、弯身、坐 |
| Video5 | 320×240 | 夜晚灯光(暗光) | 站立、弯身、跌倒 |
| Video6 | 320×240 | 夜晚灯光(暗光) | 站立、弯身、坐 |

图6 不同人体轮廓提取算法的对比结果
Fig.6 Comparison results of different human contour extraction algorithms
| 算法 | 视频名称 | Recall/% | Precision/% | F1/% | 速度/fps |
|---|---|---|---|---|---|
| GMM | Video1 | 88.43 | 34.56 | 49.70 | — |
| Video2 | 91.67 | 45.24 | 60.52 | ||
| Video3 | 79.21 | 37.86 | 51.23 | ||
| Video4 | 73.77 | 32.98 | 45.58 | ||
| Video5 | 88.18 | 40.17 | 55.20 | ||
| Video6 | 75.64 | 36.61 | 49.34 | ||
| 均值 | 82.82 | 37.90 | 52.00 | ||
| Codebook | Video1 | 78.34 | 48.34 | 59.79 | — |
| Video2 | 85.71 | 36.87 | 51.56 | ||
| Video3 | 76.81 | 38.57 | 51.35 | ||
| Video4 | 70.66 | 37.81 | 49.26 | ||
| Video5 | 82.19 | 40.18 | 53.97 | ||
| Video6 | 73.24 | 43.46 | 54.55 | ||
| 均值 | 77.83 | 40.35 | 53.16 | ||
| Mask RCNN | Video1 | 97.64 | 96.81 | 97.22 | ≈7 |
| Video2 | 98.33 | 95.33 | 96.80 | ||
| Video3 | 96.44 | 94.74 | 95.58 | ||
| Video4 | 96.14 | 96.83 | 96.48 | ||
| Video5 | 93.64 | 95.77 | 94.69 | ||
| Video6 | 94.87 | 94.45 | 94.66 | ||
| 均值 | 96.18 | 95.66 | 95.92 | ||
| YOLACT | Video1 | 97.11 | 96.17 | 96.63 | ≈24 |
| Video2 | 97.32 | 94.26 | 95.77 | ||
| Video3 | 94.65 | 95.17 | 94.91 | ||
| Video4 | 96.15 | 95.83 | 95.99 | ||
| Video5 | 93.12 | 94.31 | 93.71 | ||
| Video6 | 94.98 | 95.14 | 95.06 | ||
| 均值 | 95.56 | 95.15 | 95.35 | ||
| Res2Net-YOLACT | Video1 | 96.11 | 96.06 | 96.08 | ≈28 |
| Video2 | 97.27 | 94.43 | 95.83 | ||
| Video3 | 93.91 | 94.81 | 94.36 | ||
| Video4 | 95.91 | 96.03 | 95.97 | ||
| Video5 | 93.10 | 94.52 | 93.80 | ||
| Video6 | 94.66 | 94.48 | 94.57 | ||
| 均值 | 95.16 | 95.06 | 95.11 |
表4 不同人体轮廓提取算法的量化比较结果
Tab.4 Quantitative comparison results of different human contour extraction algorithms
| 算法 | 视频名称 | Recall/% | Precision/% | F1/% | 速度/fps |
|---|---|---|---|---|---|
| GMM | Video1 | 88.43 | 34.56 | 49.70 | — |
| Video2 | 91.67 | 45.24 | 60.52 | ||
| Video3 | 79.21 | 37.86 | 51.23 | ||
| Video4 | 73.77 | 32.98 | 45.58 | ||
| Video5 | 88.18 | 40.17 | 55.20 | ||
| Video6 | 75.64 | 36.61 | 49.34 | ||
| 均值 | 82.82 | 37.90 | 52.00 | ||
| Codebook | Video1 | 78.34 | 48.34 | 59.79 | — |
| Video2 | 85.71 | 36.87 | 51.56 | ||
| Video3 | 76.81 | 38.57 | 51.35 | ||
| Video4 | 70.66 | 37.81 | 49.26 | ||
| Video5 | 82.19 | 40.18 | 53.97 | ||
| Video6 | 73.24 | 43.46 | 54.55 | ||
| 均值 | 77.83 | 40.35 | 53.16 | ||
| Mask RCNN | Video1 | 97.64 | 96.81 | 97.22 | ≈7 |
| Video2 | 98.33 | 95.33 | 96.80 | ||
| Video3 | 96.44 | 94.74 | 95.58 | ||
| Video4 | 96.14 | 96.83 | 96.48 | ||
| Video5 | 93.64 | 95.77 | 94.69 | ||
| Video6 | 94.87 | 94.45 | 94.66 | ||
| 均值 | 96.18 | 95.66 | 95.92 | ||
| YOLACT | Video1 | 97.11 | 96.17 | 96.63 | ≈24 |
| Video2 | 97.32 | 94.26 | 95.77 | ||
| Video3 | 94.65 | 95.17 | 94.91 | ||
| Video4 | 96.15 | 95.83 | 95.99 | ||
| Video5 | 93.12 | 94.31 | 93.71 | ||
| Video6 | 94.98 | 95.14 | 95.06 | ||
| 均值 | 95.56 | 95.15 | 95.35 | ||
| Res2Net-YOLACT | Video1 | 96.11 | 96.06 | 96.08 | ≈28 |
| Video2 | 97.27 | 94.43 | 95.83 | ||
| Video3 | 93.91 | 94.81 | 94.36 | ||
| Video4 | 95.91 | 96.03 | 95.97 | ||
| Video5 | 93.10 | 94.52 | 93.80 | ||
| Video6 | 94.66 | 94.48 | 94.57 | ||
| 均值 | 95.16 | 95.06 | 95.11 |

图7 测试数据上准确率的对比结果
Fig.7 Accuracy comparison of three algorithms on test data
| 目标检测算法 | 跌倒检 测方法 | 跌倒检测帧数 | 误判 帧数 | 实际跌倒帧数 | 准确率/% | 误判率/% |
|---|---|---|---|---|---|---|
| Codebook | 阈值法 | 60 | 7 | 70 | 85.71 | 10.00 |
| GMM | 61 | 6 | 87.14 | 8.57 | ||
| Mask RCNN | 65 | 5 | 92.86 | 7.14 | ||
| YOLACT | 65 | 5 | 92.86 | 7.14 | ||
| Res2Net-YOLACT | 65 | 5 | 92.86 | 7.14 | ||
| Codebook | CNN 分类 | 61 | 4 | 70 | 87.14 | 5.71 |
| GMM | 62 | 3 | 88.57 | 4.29 | ||
| Mask RCNN | 66 | 2 | 94.29 | 2.86 | ||
| YOLACT | 67 | 2 | 95.71 | 2.86 | ||
| Res2Net-YOLACT | 67 | 2 | 95.71 | 2.86 | ||
| Codebook | 本文 算法 | 58 | 4 | 70 | 82.86 | 5.71 |
| GMM | 61 | 4 | 87.14 | 5.71 | ||
| Mask RCNN | 68 | 1 | 97.14 | 1.43 | ||
| YOLACT | 67 | 2 | 95.71 | 2.86 | ||
| Res2Net-YOLACT | 68 | 1 | 97.14 | 1.43 |
表5 不同跌倒检测算法对比实验
Tab.5 Comparison experiment of different fall detection algorithms
| 目标检测算法 | 跌倒检 测方法 | 跌倒检测帧数 | 误判 帧数 | 实际跌倒帧数 | 准确率/% | 误判率/% |
|---|---|---|---|---|---|---|
| Codebook | 阈值法 | 60 | 7 | 70 | 85.71 | 10.00 |
| GMM | 61 | 6 | 87.14 | 8.57 | ||
| Mask RCNN | 65 | 5 | 92.86 | 7.14 | ||
| YOLACT | 65 | 5 | 92.86 | 7.14 | ||
| Res2Net-YOLACT | 65 | 5 | 92.86 | 7.14 | ||
| Codebook | CNN 分类 | 61 | 4 | 70 | 87.14 | 5.71 |
| GMM | 62 | 3 | 88.57 | 4.29 | ||
| Mask RCNN | 66 | 2 | 94.29 | 2.86 | ||
| YOLACT | 67 | 2 | 95.71 | 2.86 | ||
| Res2Net-YOLACT | 67 | 2 | 95.71 | 2.86 | ||
| Codebook | 本文 算法 | 58 | 4 | 70 | 82.86 | 5.71 |
| GMM | 61 | 4 | 87.14 | 5.71 | ||
| Mask RCNN | 68 | 1 | 97.14 | 1.43 | ||
| YOLACT | 67 | 2 | 95.71 | 2.86 | ||
| Res2Net-YOLACT | 68 | 1 | 97.14 | 1.43 |
| 光照 | 跌倒检 测帧数 | 误判 帧数 | 实际跌 倒帧数 | 准确率/% | 误判率/% |
|---|---|---|---|---|---|
| 正常光 | 66 | 0 | 68 | 97.06 | 0.00 |
| 干扰光 | 70 | 2 | 73 | 95.89 | 2.74 |
| 正常光 | 69 | 1 | 71 | 97.18 | 1.41 |
| 干扰光 | 68 | 0 | 70 | 97.14 | 0.00 |
| 正常光 | 62 | 1 | 65 | 95.38 | 1.54 |
| 干扰光 | 64 | 0 | 67 | 95.52 | 0.00 |
| 正常光 | 72 | 2 | 74 | 97.30 | 2.70 |
| 干扰光 | 67 | 1 | 70 | 95.71 | 1.43 |
| 正常光 | 60 | 1 | 63 | 95.24 | 1.59 |
| 干扰光 | 58 | 0 | 60 | 96.67 | 0.00 |
表6 光照干扰对比实验结果
Tab.6 Comparison result with light interference
| 光照 | 跌倒检 测帧数 | 误判 帧数 | 实际跌 倒帧数 | 准确率/% | 误判率/% |
|---|---|---|---|---|---|
| 正常光 | 66 | 0 | 68 | 97.06 | 0.00 |
| 干扰光 | 70 | 2 | 73 | 95.89 | 2.74 |
| 正常光 | 69 | 1 | 71 | 97.18 | 1.41 |
| 干扰光 | 68 | 0 | 70 | 97.14 | 0.00 |
| 正常光 | 62 | 1 | 65 | 95.38 | 1.54 |
| 干扰光 | 64 | 0 | 67 | 95.52 | 0.00 |
| 正常光 | 72 | 2 | 74 | 97.30 | 2.70 |
| 干扰光 | 67 | 1 | 70 | 95.71 | 1.43 |
| 正常光 | 60 | 1 | 63 | 95.24 | 1.59 |
| 干扰光 | 58 | 0 | 60 | 96.67 | 0.00 |
| 活动 | 视频片段数 | 检测结果 | |
|---|---|---|---|
| 跌倒数 | 非跌倒数 | ||
| 行走 | 100 | 0 | 100 |
| 坐起 | 100 | 3 | 97 |
| 下弯 | 100 | 3 | 97 |
| 躺 | 100 | 2 | 98 |
| 跌倒 | 100 | 97 | 3 |
表7 提出的跌倒检测算法的检测结果
Tab.7 Detection results of the proposed fall detection algorithm
| 活动 | 视频片段数 | 检测结果 | |
|---|---|---|---|
| 跌倒数 | 非跌倒数 | ||
| 行走 | 100 | 0 | 100 |
| 坐起 | 100 | 3 | 97 |
| 下弯 | 100 | 3 | 97 |
| 躺 | 100 | 2 | 98 |
| 跌倒 | 100 | 97 | 3 |
| 1 | 丁志宏, 杜书然, 王明鑫. 我国城市老年人跌倒状况及其影响因素研究[J]. 人口与发展, 2018, 24(4):120-128. |
| DING Z H, DU S R, WANG M X. Research on the falls and its risk factors among the urban aged in China[J]. Population and Development, 2018, 24(4):120-128. | |
| 2 | 师昉, 李福亮, 张思佳, 等. 中国老年跌倒研究的现状与对策[J]. 中国康复, 2018, 33(3):246-248. 10.3870/zgkf.2018.03.021 |
| SHI F, LI F L, ZHANG S J, et al. The status quo and countermeasures of research on elderly falls in China[J]. Chinese Journal of Rehabilitation, 2018, 33(3):246-248. 10.3870/zgkf.2018.03.021 | |
| 3 | SANTOS G, ENDO P, MONTEIRO K, et al. Accelerometer-based human fall detection using convolutional neural networks[J]. Sensors, 2019, 19(7):1644. 10.3390/s19071644 |
| 4 | CLEMENTE J, SONG W Z, VALERO M, et al. Indoor person identification and fall detection through non-intrusive floor seismic sensing[C]// Proceedings of the 2019 IEEE International Conference on Smart Computing. Piscataway: IEEE, 2019: 417-424. 10.1109/smartcomp.2019.00081 |
| 5 | EZATZADEH S, KEYVANPOUR M R. ViFa: an analytical framework for vision-based fall detection in a surveillance environment[J]. Multimedia Tools and Applications, 2019, 78(18): 25515-25537. 10.1007/s11042-019-7720-3 |
| 6 | LU X, XU C, WANG L, et al. Improved background subtraction method for detecting moving objects based on GMM[J]. IEEE Transactions on Electrical and Electronic Engineering, 2018, 13(11): 1540-1550. 10.1002/tee.22718 |
| 7 | KRUNGKAEW R, KUSAKUNNIRAN W. Foreground segmentation in a video by using a novel dynamic codebook[C]// Proceedings of the 2016 13th International Conference on Electrical Engineering/Electronics, Computer, Telecommunications and Information Technology. Piscataway: IEEE, 2016:1-6. 10.1109/ecticon.2016.7561253 |
| 8 | HE B, YU S. An improved background subtraction method based on ViBe[C]// Proceedings of the 7th Chinese Conference on Pattern Recognition. Cham: Springer, 2016: 356-368. 10.1007/978-981-10-3002-4_30 |
| 9 | MIN W, WEI L, HAN Q, et al. Human fall detection based on motion tracking and shape aspect ratio[J]. International Journal of Multimedia and Ubiquitous Engineering, 2016, 11(10): 1-14. 10.14257/ijmue.2016.11.10.01 |
| 10 | VAIDEHI V, GANAPATHY K, MOHAN K, et al. Video based automatic fall detection in indoor environment[C]// Proceedings of the 2011 International Conference on Recent Trends in Information Technology. Piscataway: IEEE, 2011: 1016-1020. 10.1109/icrtit.2011.5972252 |
| 11 | LIN C, WANG S, HONG J, et al. Vision-based fall detection through shape features[C]// Proceedings of the 2016 IEEE 2nd International Conference on Multimedia Big Data. Piscataway: IEEE, 2016: 237-240. 10.1109/bigmm.2016.22 |
| 12 | MIRMAHBOUB B, SAMAVI S, KARIMI N, et al. Automatic monocular system for human fall detection based on variations in silhouette area[J]. IEEE Transactions on Biomedical Engineering, 2013, 60(2):427-436. 10.1109/tbme.2012.2228262 |
| 13 | TRA K, PHAM T V. Human fall detection based on adaptive background mixture model and HMM[C]// Proceedings of the 2013 International Conference on Advanced Technologies for Communications. Piscataway: IEEE, 2013:95-100. 10.1109/atc.2013.6698085 |
| 14 | YU M, GONG L, KOLLIAS S. Computer vision based fall detection by a convolutional neural network[C]// Proceedings of the 19th ACM International Conference on Multimodal Interaction. New York: ACM, 2017: 416-420. 10.1145/3136755.3136802 |
| 15 | KHAN M A, SHARIF M, AKRAM T, et al. Hand-crafted and deep convolutional neural network features fusion and selection strategy: an application to intelligent human action recognition[J]. Applied Soft Computing, 2019, 87:105986. 10.1016/j.asoc.2019.105986 |
| 16 | BOLYA D, ZHOU C, XIAO F, et al. YOLACT: real-time instance segmentation[C]// Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision. Piscataway: IEEE, 2019: 9157-9166. 10.1109/iccv.2019.00925 |
| 17 | HE K, ZHANG X, REN S, et al. Deep residual learning for image recognition[C]// Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2016: 770-778. 10.1109/cvpr.2016.90 |
| 18 | GAO S, CHENG M, ZHAO K, et al. Res2Net: a new multi-scale backbone architecture[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2019, 43(2): 652-662 . |
| 19 | LIU W, ANGUELOV D, ERHAN D, et al. SSD: single shot multibox detector[C]// Proceedings of the 2016 European Conference on Computer Vision. Cham: Springer, 2016: 21-37. 10.1007/978-3-319-46448-0_2 |
| 20 | YU M, YU Y, RHUMA A, et al. An online one class support vector machine-based person-specific fall detection system for monitoring an elderly individual in a room environment[J]. IEEE Journal of Biomedical & Health Informatics, 2013, 17(6):1002-1014. 10.1109/jbhi.2013.2274479 |
| 21 | YAO G, LEI T, ZHONG J. A review of convolutional-neural-network-based action recognition[J]. Pattern Recognition Letters, 2018, 118:14-22. 10.1016/j.patrec.2018.05.018 |
| 22 | TAN C, SUN F, KONG T, et al. A survey on deep transfer learning[C]// Proceedings of the 27th International Conference on Artificial Neural Networks. Cham: Springer, 2018:270-279. 10.1007/978-3-030-01424-7_27 |
| 23 | FENG Q, GAO C, WANG L, et al. Spatio-temporal fall event detection in complex scenes using attention guided LSTM[J]. Pattern Recognition Letters, 2020, 130: 242-249. 10.1016/j.patrec.2018.08.031 |
| [1] | 李云, 王富铕, 井佩光, 王粟, 肖澳. 基于不确定度感知的帧关联短视频事件检测方法[J]. 《计算机应用》唯一官方网站, 2024, 44(9): 2903-2910. |
| [2] | 秦璟, 秦志光, 李发礼, 彭悦恒. 基于概率稀疏自注意力神经网络的重性抑郁疾患诊断[J]. 《计算机应用》唯一官方网站, 2024, 44(9): 2970-2974. |
| [3] | 陈虹, 齐兵, 金海波, 武聪, 张立昂. 融合1D-CNN与BiGRU的类不平衡流量异常检测[J]. 《计算机应用》唯一官方网站, 2024, 44(8): 2493-2499. |
| [4] | 赵宇博, 张丽萍, 闫盛, 侯敏, 高茂. 基于改进分段卷积神经网络和知识蒸馏的学科知识实体间关系抽取[J]. 《计算机应用》唯一官方网站, 2024, 44(8): 2421-2429. |
| [5] | 张春雪, 仇丽青, 孙承爱, 荆彩霞. 基于两阶段动态兴趣识别的购买行为预测模型[J]. 《计算机应用》唯一官方网站, 2024, 44(8): 2365-2371. |
| [6] | 王东炜, 刘柏辰, 韩志, 王艳美, 唐延东. 基于低秩分解和向量量化的深度网络压缩方法[J]. 《计算机应用》唯一官方网站, 2024, 44(7): 1987-1994. |
| [7] | 高阳峄, 雷涛, 杜晓刚, 李岁永, 王营博, 闵重丹. 基于像素距离图和四维动态卷积网络的密集人群计数与定位方法[J]. 《计算机应用》唯一官方网站, 2024, 44(7): 2233-2242. |
| [8] | 黄梦源, 常侃, 凌铭阳, 韦新杰, 覃团发. 基于层间引导的低光照图像渐进增强算法[J]. 《计算机应用》唯一官方网站, 2024, 44(6): 1911-1919. |
| [9] | 李健京, 李贯峰, 秦飞舟, 李卫军. 基于不确定知识图谱嵌入的多关系近似推理模型[J]. 《计算机应用》唯一官方网站, 2024, 44(6): 1751-1759. |
| [10] | 沈君凤, 周星辰, 汤灿. 基于改进的提示学习方法的双通道情感分析模型[J]. 《计算机应用》唯一官方网站, 2024, 44(6): 1796-1806. |
| [11] | 姚迅, 秦忠正, 杨捷. 生成式标签对抗的文本分类模型[J]. 《计算机应用》唯一官方网站, 2024, 44(6): 1781-1785. |
| [12] | 孙敏, 成倩, 丁希宁. 基于CBAM-CGRU-SVM的Android恶意软件检测方法[J]. 《计算机应用》唯一官方网站, 2024, 44(5): 1539-1545. |
| [13] | 席治远, 唐超, 童安炀, 王文剑. 基于双路时空网络的驾驶员行为识别[J]. 《计算机应用》唯一官方网站, 2024, 44(5): 1511-1519. |
| [14] | 高文烁, 陈晓云. 基于节点结构的点云分类网络[J]. 《计算机应用》唯一官方网站, 2024, 44(5): 1471-1478. |
| [15] | 陈天华, 朱家煊, 印杰. 基于注意力机制的鸟类识别算法[J]. 《计算机应用》唯一官方网站, 2024, 44(4): 1114-1120. |
| 阅读次数 | ||||||
|
全文 |
|
|||||
|
摘要 |
|
|||||