


《计算机应用》唯一官方网站 ›› 2025, Vol. 45 ›› Issue (2): 411-420.DOI: 10.11772/j.issn.1001-9081.2024010130
• 人工智能 • 上一篇
刘弘业, 陈锡爱( ), 曾涛
), 曾涛
收稿日期:2024-02-05
修回日期:2024-04-15
接受日期:2024-04-15
发布日期:2024-05-09
出版日期:2025-02-10
通讯作者:
陈锡爱
作者简介:刘弘业(1998—),男,浙江杭州人,硕士研究生,主要研究方向:文本检测、文本识别、多模态内容理解基金资助:
Hongye LIU, Xiai CHEN(), Tao ZENG
Received:2024-02-05
Revised:2024-04-15
Accepted:2024-04-15
Online:2024-05-09
Published:2025-02-10
Contact:
Xiai CHEN
About author:LIU Hongye, born in 1998, M. S candidate. His research interests include text detection, text recognition, multimodal content understanding.Supported by:摘要:
预训练再微调范式广泛应用于各种单模态和多模态的任务中。然而,随着模型规模的指数级别增长,微调预训练模型的所有参数变得非常困难。为了解决这个问题,设计一种基于选择状态空间的三模态适配器,它可以冻结预训练模型,只针对少量额外的参数微调,并完成三模态间的密集交互。具体地,提出一个基于选择状态空间的长期语义选择模块和一个基于视觉或音频中心的短期语义交互模块,这两个模块被按顺序插入各顺序编码器之间,以完成三模态信息的密集交互。长期语义选择模块旨在抑制三模态中的冗余信息,短期语义交互模块则对短时间内的局部模态特征进行交互建模。与之前需要在大规模三模态数据集上进行预训练的方法相比,所提方法更灵活,它可以继承任意强大的单模态或双模态模型。在Music-AVQA三模态评测数据集上,所提方法取得了80.19%的平均准确率,较LAVISH提升了4.09个百分点。
中图分类号:
刘弘业, 陈锡爱, 曾涛. 基于选择状态空间的三模态适配器[J]. 计算机应用, 2025, 45(2): 411-420.
Hongye LIU, Xiai CHEN, Tao ZENG. Tri-modal adapter based on selective state space[J]. Journal of Computer Applications, 2025, 45(2): 411-420.
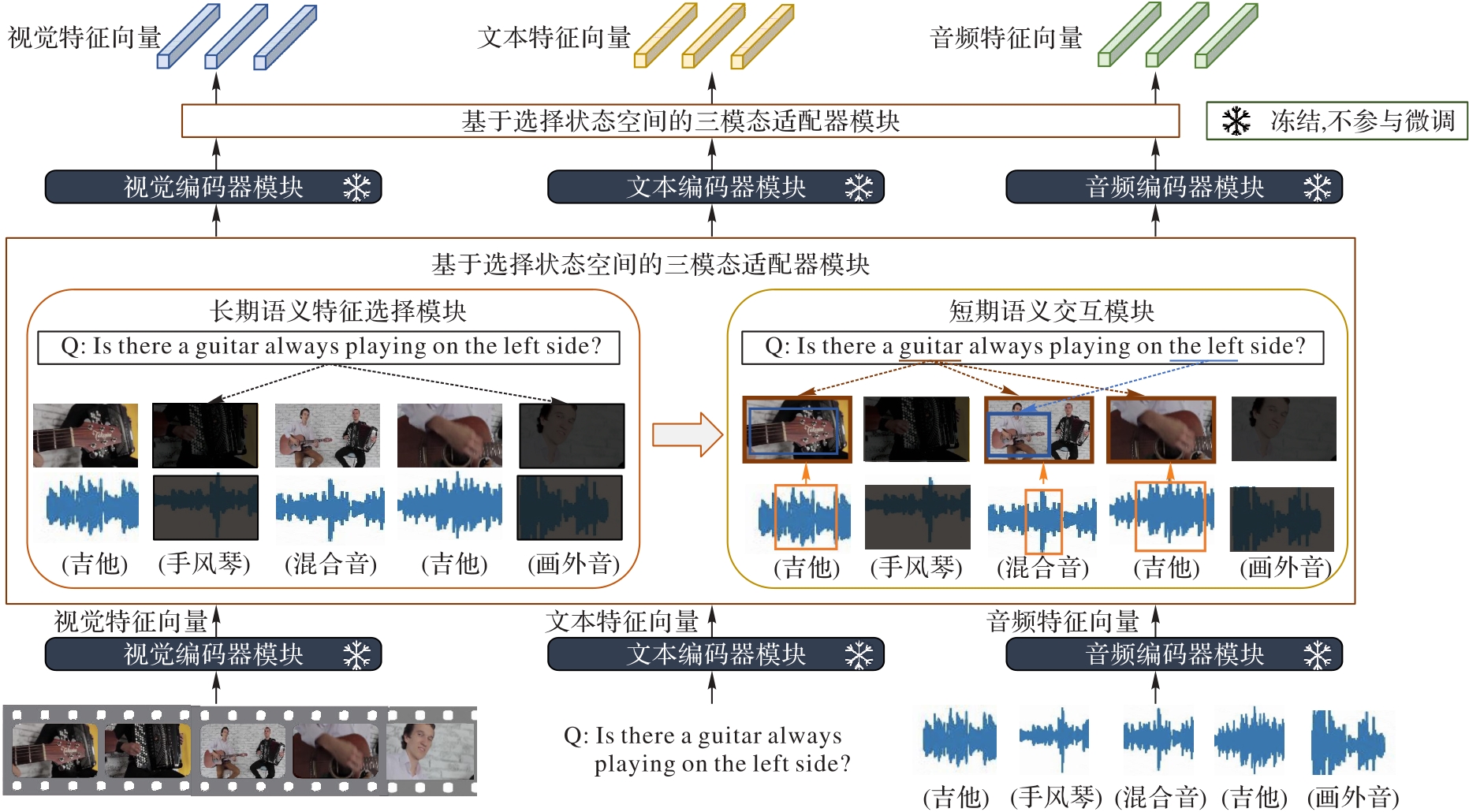
图1 基于选择状态空间的多模态适配器模型结构
Fig. 1 Structure of multimodal adapter model based on selective state space

图2 长期语义选择模块与短期语义交互模块的结构
Fig. 2 Structures of long-term semantic selection module and short-term semantic interaction module
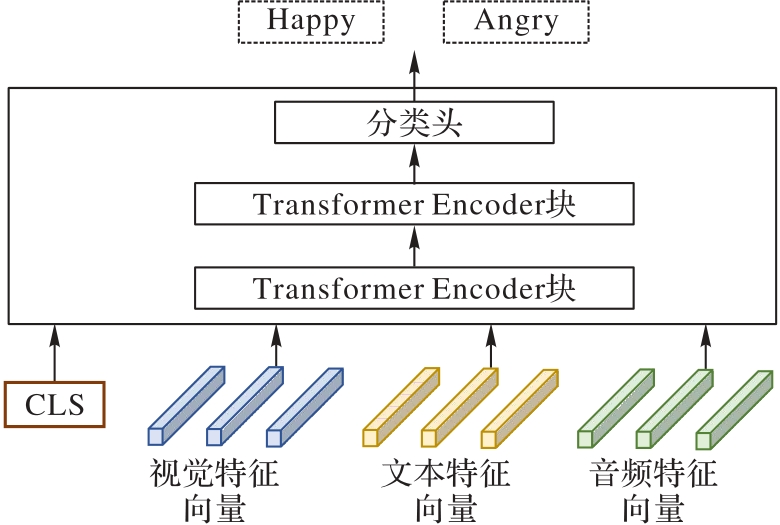
图3 预测器模块的结构
Fig. 3 Structure of predictor module
| 方法 | AQ | VQ | AVQ | 平均值 | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| 计数类 | 比较类 | 计数类 | 定位类 | 存在类 | 定位类 | 计数类 | 比较类 | 时序类 | ||
| FCNLSTM[ | 70.45 | 66.22 | 63.89 | 46.74 | 82.01 | 46.28 | 59.34 | 62.15 | 47.33 | 60.34 |
| GRU[ | 72.21 | 66.89 | 67.72 | 70.11 | 81.71 | 59.44 | 62.64 | 61.88 | 60.07 | 67.07 |
| HCAttn[ | 70.25 | 54.91 | 64.05 | 66.37 | 79.10 | 49.51 | 59.97 | 55.25 | 56.43 | 62.30 |
| MCAN[ | 77.50 | 55.24 | 71.56 | 70.93 | 80.40 | 54.48 | 64.91 | 57.22 | 47.57 | 65.49 |
| PSAC[ | 75.64 | 66.06 | 68.64 | 69.79 | 77.59 | 55.02 | 63.42 | 61.17 | 59.47 | 66.54 |
| HME[ | 74.76 | 63.56 | 67.97 | 69.46 | 80.30 | 53.18 | 63.19 | 62.69 | 59.83 | 66.45 |
| HCRN[ | 68.59 | 50.92 | 64.39 | 61.81 | 54.47 | 41.53 | 53.38 | 52.11 | 47.69 | 55.73 |
| AVSD[ | 72.41 | 61.90 | 67.39 | 74.19 | 81.61 | 58.79 | 63.89 | 61.52 | 61.41 | 67.44 |
| TGSG[ | 78.18 | 67.05 | 71.56 | 76.83 | 81.81 | 64.51 | 70.80 | 66.01 | 63.23 | 71.52 |
| LAVISH[ | 75.59 | 84.13 | 77.45 | 72.91 | 71.91 | 77.52 | 75.81 | 76.75 | 77.62 | 76.10 |
| SSMMA | 80.75 | 81.04 | 80.82 | 81.23 | 82.46 | 78.11 | 77.23 | 77.02 | 78.32 | 80.19 |
表1 不同方法在Music-AVQA数据集上的准确率对比 ( %)
Tab. 1 Accuracy comparison of different methods on Music-AVQA dataset
| 方法 | AQ | VQ | AVQ | 平均值 | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| 计数类 | 比较类 | 计数类 | 定位类 | 存在类 | 定位类 | 计数类 | 比较类 | 时序类 | ||
| FCNLSTM[ | 70.45 | 66.22 | 63.89 | 46.74 | 82.01 | 46.28 | 59.34 | 62.15 | 47.33 | 60.34 |
| GRU[ | 72.21 | 66.89 | 67.72 | 70.11 | 81.71 | 59.44 | 62.64 | 61.88 | 60.07 | 67.07 |
| HCAttn[ | 70.25 | 54.91 | 64.05 | 66.37 | 79.10 | 49.51 | 59.97 | 55.25 | 56.43 | 62.30 |
| MCAN[ | 77.50 | 55.24 | 71.56 | 70.93 | 80.40 | 54.48 | 64.91 | 57.22 | 47.57 | 65.49 |
| PSAC[ | 75.64 | 66.06 | 68.64 | 69.79 | 77.59 | 55.02 | 63.42 | 61.17 | 59.47 | 66.54 |
| HME[ | 74.76 | 63.56 | 67.97 | 69.46 | 80.30 | 53.18 | 63.19 | 62.69 | 59.83 | 66.45 |
| HCRN[ | 68.59 | 50.92 | 64.39 | 61.81 | 54.47 | 41.53 | 53.38 | 52.11 | 47.69 | 55.73 |
| AVSD[ | 72.41 | 61.90 | 67.39 | 74.19 | 81.61 | 58.79 | 63.89 | 61.52 | 61.41 | 67.44 |
| TGSG[ | 78.18 | 67.05 | 71.56 | 76.83 | 81.81 | 64.51 | 70.80 | 66.01 | 63.23 | 71.52 |
| LAVISH[ | 75.59 | 84.13 | 77.45 | 72.91 | 71.91 | 77.52 | 75.81 | 76.75 | 77.62 | 76.10 |
| SSMMA | 80.75 | 81.04 | 80.82 | 81.23 | 82.46 | 78.11 | 77.23 | 77.02 | 78.32 | 80.19 |
| 方法 | MAE(↓) | Corr/% | A类/% | B类/% | ||
|---|---|---|---|---|---|---|
| Acc-2 | F1-Score | Acc-2 | F1-Score | |||
| MuIT[ | 0.591 | 69.4 | — | — | 81.6 | 81.6 |
| ICCN[ | 0.565 | 71.3 | — | — | 84.2 | 84.2 |
| MISA[ | 0.555 | 75.6 | 83.6 | 83.8 | 85.5 | 85.3 |
| AVLD[ | 0.527 | 78.1 | 84.5 | 84.7 | 86.4 | 86.3 |
| Self-MM[ | 0.530 | 76.5 | 82.8 | 82.5 | 85.2 | 85.3 |
| i-Code[ | 0.502 | 81.1 | 85.3 | 85.6 | 87.5 | 87.4 |
| SSMMA | 0.498 | 81.3 | 85.5 | 85.9 | 87.7 | 87.7 |
表2 CMU-MOSEI情感分析任务的实验结果
Tab. 2 Experimental results of CMU-MOSEI sentiment analysis task
| 方法 | MAE(↓) | Corr/% | A类/% | B类/% | ||
|---|---|---|---|---|---|---|
| Acc-2 | F1-Score | Acc-2 | F1-Score | |||
| MuIT[ | 0.591 | 69.4 | — | — | 81.6 | 81.6 |
| ICCN[ | 0.565 | 71.3 | — | — | 84.2 | 84.2 |
| MISA[ | 0.555 | 75.6 | 83.6 | 83.8 | 85.5 | 85.3 |
| AVLD[ | 0.527 | 78.1 | 84.5 | 84.7 | 86.4 | 86.3 |
| Self-MM[ | 0.530 | 76.5 | 82.8 | 82.5 | 85.2 | 85.3 |
| i-Code[ | 0.502 | 81.1 | 85.3 | 85.6 | 87.5 | 87.4 |
| SSMMA | 0.498 | 81.3 | 85.5 | 85.9 | 87.7 | 87.7 |
| 方法 | Acc | F1-Score | Precision | Recall |
|---|---|---|---|---|
| DFG[ | 38.6 | 49.4 | 53.4 | 45.6 |
| MISA[ | 39.8 | 45.0 | 37.1 | 57.1 |
| RAVEN[ | 40.3 | 51.1 | 63.3 | 42.9 |
| HHMPN[ | 43.4 | 52.8 | 59.1 | 47.6 |
| SIMM[ | 41.8 | 48.4 | 48.2 | 48.6 |
| i-Code[ | 50.2 | 56.2 | 50.7 | 63.0 |
| SSMMA | 50.7 | 56.5 | 63.4 | 51.1 |
表3 CMU-MOSEI情绪识别任务的实验结果 (%)
Tab. 3 Experimental results of CMU-MOSEI emotion recognition task
| 方法 | Acc | F1-Score | Precision | Recall |
|---|---|---|---|---|
| DFG[ | 38.6 | 49.4 | 53.4 | 45.6 |
| MISA[ | 39.8 | 45.0 | 37.1 | 57.1 |
| RAVEN[ | 40.3 | 51.1 | 63.3 | 42.9 |
| HHMPN[ | 43.4 | 52.8 | 59.1 | 47.6 |
| SIMM[ | 41.8 | 48.4 | 48.2 | 48.6 |
| i-Code[ | 50.2 | 56.2 | 50.7 | 63.0 |
| SSMMA | 50.7 | 56.5 | 63.4 | 51.1 |
| 方法 | UR-FUNNY | VIOLIN |
|---|---|---|
| MISA[ | 70.61 | — |
| MuIT[ | 70.55 | — |
| HERO[ | — | 68.59 |
| GVE[ | — | 68.39 |
| i-Code[ | 79.17 | 72.90 |
| SSMMA | 79.15 | 73.08 |
表4 UR-FUNNY和VIOLIN任务上的准确率对比 ( %)
Tab. 4 Comparison of accuracy on UR-FUNNY and VIOLIN tasks
| 方法 | UR-FUNNY | VIOLIN |
|---|---|---|
| MISA[ | 70.61 | — |
| MuIT[ | 70.55 | — |
| HERO[ | — | 68.59 |
| GVE[ | — | 68.39 |
| i-Code[ | 79.17 | 72.90 |
| SSMMA | 79.15 | 73.08 |
| 实验序号 | 长期语义选择模块 | 短期语义 交互模块(视觉) | 短期语义 交互模块(音频) | 可学习向量 | AQ | VQ | AVQ |
|---|---|---|---|---|---|---|---|
| 1 | × | × | × | × | 76.71 | 79.56 | 65.73 |
| 2 | × | √ | × | × | 76.79 | 80.07 | 67.57 |
| 3 | × | × | √ | × | 77.54 | 79.67 | 66.17 |
| 4 | × | √ | √ | × | 78.64 | 80.23 | 75.91 |
| 5 | √ | √ | √ | × | 80.34 | 80.89 | 77.53 |
| 6 | √ | √ | √ | √ | 80.90 | 81.03 | 78.63 |
表5 SSMMA在Music-AVQA数据集上各模块的消融实验结果 (%)
Tab. 5 Ablation experimental results of SSMMA modules on Music-AVQA dataset
| 实验序号 | 长期语义选择模块 | 短期语义 交互模块(视觉) | 短期语义 交互模块(音频) | 可学习向量 | AQ | VQ | AVQ |
|---|---|---|---|---|---|---|---|
| 1 | × | × | × | × | 76.71 | 79.56 | 65.73 |
| 2 | × | √ | × | × | 76.79 | 80.07 | 67.57 |
| 3 | × | × | √ | × | 77.54 | 79.67 | 66.17 |
| 4 | × | √ | √ | × | 78.64 | 80.23 | 75.91 |
| 5 | √ | √ | √ | × | 80.34 | 80.89 | 77.53 |
| 6 | √ | √ | √ | √ | 80.90 | 81.03 | 78.63 |

图4 长期语义选择模块在Music-AVQA数据集上的可视化
Fig. 4 Visualization of long-term semantic selection module on Music-AVQA dataset
| 实验序号 | 视觉 | 文本 | 音频 | AQ | VQ | AVQ |
|---|---|---|---|---|---|---|
| 7 | CLIP | CLIP | W2V-Conf | 80.90 | 81.03 | 78.63 |
| 8 | Swin | CLIP | W2V-Conf | 80.67 | 80.74 | 78.28 |
| 9 | CLIP | BART | W2V-Conf | 80.97 | 81.01 | 78.84 |
表6 不同骨干网络的消融实验结果 ( %)
Tab. 6 Ablation experimental results of different backbone networks
| 实验序号 | 视觉 | 文本 | 音频 | AQ | VQ | AVQ |
|---|---|---|---|---|---|---|
| 7 | CLIP | CLIP | W2V-Conf | 80.90 | 81.03 | 78.63 |
| 8 | Swin | CLIP | W2V-Conf | 80.67 | 80.74 | 78.28 |
| 9 | CLIP | BART | W2V-Conf | 80.97 | 81.01 | 78.84 |
| 方法 | 可训练参数量/106 | AQ/% | VQ/% | AVQ/% |
|---|---|---|---|---|
| 冻结模态编码器 | 33 | 80.90 | 81.03 | 78.63 |
| 全模型参数微调 | 1 150 | 79.34 | 80.27 | 75.28 |
表7 模型可训练参数的消融实验结果
Tab. 7 Ablation experimental results of model trainable parameters
| 方法 | 可训练参数量/106 | AQ/% | VQ/% | AVQ/% |
|---|---|---|---|---|
| 冻结模态编码器 | 33 | 80.90 | 81.03 | 78.63 |
| 全模型参数微调 | 1 150 | 79.34 | 80.27 | 75.28 |
| 方法 | 可训练参数量/106 | AQ/% | VQ/% | AVQ/% |
|---|---|---|---|---|
| SSM | 33 | 80.90 | 81.03 | 78.63 |
| RNN | 41 | 77.32 | 79.31 | 76.21 |
| LSTM | 44 | 78.42 | 80.32 | 76.13 |
| GRU | 43 | 77.11 | 78.45 | 75.98 |
| Transformer | 83 | 79.84 | 80.41 | 77.31 |
表8 选择状态空间的消融实验结果
Tab. 8 Ablation experimental results of selective state-space
| 方法 | 可训练参数量/106 | AQ/% | VQ/% | AVQ/% |
|---|---|---|---|---|
| SSM | 33 | 80.90 | 81.03 | 78.63 |
| RNN | 41 | 77.32 | 79.31 | 76.21 |
| LSTM | 44 | 78.42 | 80.32 | 76.13 |
| GRU | 43 | 77.11 | 78.45 | 75.98 |
| Transformer | 83 | 79.84 | 80.41 | 77.31 |
| 1 | LI J, SELVARAJU R R, GOTMARE A D, et al. Align before fuse: vision and language representation learning with momentum distillation[C]// Proceedings of the 35th International Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2021: 9694-9705. |
| 2 | RADFORD A, KIM J W, HALLACY C, et al. Learning transferable visual models from natural language supervision[C]// Proceedings of the 38th International Conference on Machine Learning. New York: JMLR.org, 2021: 8748-8763. |
| 3 | SINGH A, HU R, GOSWAMI V, et al. FLAVA: a foundational language and vision alignment model[C]// Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2022: 15617-15629. |
| 4 | BAO H, WANG W, DONG L, et al. VLMo: unified vision-language pre-training with mixture-of-modality-experts[C]// Proceedings of the 36th International Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2022: 32897-32912. |
| 5 | CHEN Y C, LI L, YU L, et al. UNITER: Universal image-text representation learning[C]// Proceedings of the 2020 European Conference on Computer Vision, LNCS 12375. Cham: Springer, 2020: 104-120. |
| 6 | WANG W, BAO H, DONG L, et al. Image as a foreign language: BEIT pretraining for vision and vision-language tasks[C]// Proceedings of the 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2023: 19175-19186. |
| 7 | LI J, LI D, XIONG C, et al. BLIP: bootstrapping language-image pre-training for unified vision-language understanding and generation[C]// Proceedings of the 39th International Conference on Machine Learning. New York: JMLR.org, 2022: 12888-12900. |
| 8 | HOULSBY N, GIURGIU A, JASTRZĘBSKI S, et al. Parameter-efficient transfer learning for NLP[C]// Proceedings of the 36th International Conference on Machine Learning. New York: JMLR.org, 2019: 2790-2799. |
| 9 | PFEIFFER J, KAMATH A, RÜCKLÉ A, et al. AdapterFusion: non-destructive task composition for transfer learning [C]// Proceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics: Main Volume. Stroudsburg: ACL, 2021: 487-503. |
| 10 | CHEN H, TAO R, ZHANG H, et al. Conv-Adapter: exploring parameter efficient transfer learning for ConvNets[C]// Proceedings of the 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops. Piscataway: IEEE, 2024: 1551-1561. |
| 11 | CHEN Z, DUAN Y, WANG W, et al. Vision transformer adapter for dense predictions[EB/OL]. [2024-07-10].. |
| 12 | JU C, HAN T, ZHENG K, et al. Prompting visual-language models for efficient video understanding[C]// Proceedings of the 2022 European Conference on Computer Vision, LNCS 13695. Cham: Springer, 2022: 105-124. |
| 13 | SUNG Y L, CHO J, BANSAL M. VL-adapter: parameter-efficient transfer learning for vision-and-language tasks[C]// Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2022: 5227-5237. |
| 14 | LIN Y B, SUNG Y L, LEI J, et al. Vision transformers are parameter-efficient audio-visual learners[C]// Proceedings of the 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2023: 2299-2309. |
| 15 | ALAYRAC J B, DONAHUE J, LUC P, et al. Flamingo: a visual language model for few-shot learning[C]// Proceedings of the 36th International Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2022: 23716-23736. |
| 16 | WANG T, MENG Q, LIN L, et al. Self-assembled dehydropeptide nanocarrier as a delivery system for antitumor drug temozolomide[J]. Bioorganic Chemistry, 2022, 124: No.105842. |
| 17 | ZENG Y, ZHANG X, LI H. Multi-grained vision language pre-training: aligning texts with visual concepts[EB/OL]. [2024-07-10].. |
| 18 | ZENG Y, ZHANG X, LI H, et al. X2-VLM: all-in-one pre-trained model for vision-language tasks[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2024, 46(5): 3156-3168. |
| 19 | LEE K H, CHEN X, HUA G, et al. Stacked cross attention for image-text matching[C]// Proceedings of the 2018 European Conference on Computer Vision, LNCS 11208. Cham: Springer, 2018: 212-228. |
| 20 | LU J, XIONG C, PARIKH D, et al. Knowing when to look: adaptive attention via a visual sentinel for image captioning[C]// Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2017: 3242-3250. |
| 21 | DEVLIN J, CHANG M W, LEE K, et al. BERT: pre-training of deep bidirectional Transformers for language understanding C]// Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers). Stroudsburg: ACL, 2019: 4171-4186. |
| 22 | YU Z, YU J, CUI Y, et al. Deep modular co-attention networks for visual question answering[C]// Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2019: 6274-6283. |
| 23 | LI X, YIN X, LI C, et al. Oscar: object-semantics aligned pre-training for vision-language tasks[C]// Proceedings of the 2020 European Conference on Computer Vision, LNCS 12375. Cham: Springer, 2020: 121-137. |
| 24 | LU J, BATRA D, PARIKH D, et al. ViLBERT: pretraining task-agnostic visiolinguistic representations for vision-and-language tasks[C]// Proceedings of the 31st International Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2019: 13-23. |
| 25 | TAN H, BANSAL M. LXMERT: learning cross-modality encoder representations from transformers[C]// Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing. Stroudsburg: ACL, 2019: 5100-5111. |
| 26 | CUI Y, YU Z, WANG C, et al. ROSITA: enhancing vision-and-language semantic alignments via cross-and intra-modal knowledge integration[C]// Proceedings of the 29th ACM International Conference on Multimedia. New York: ACM, 2021: 797-806. |
| 27 | YU F, TANG J, YIN W, et al. ERNIE-ViL: knowledge enhanced vision language representations through scene graphs[C]// Proceedings of the 35th AAAI Conference on Artificial Intelligence. Palo Alto: AAAI Press, 2021: 3208-3216. |
| 28 | LIN B, ZHU Y, CHEN Z, et al. Adapt: Vision-language navigation with modality-aligned action prompts[C]// Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2022: 15396-15406. |
| 29 | DOU Z Y, XU Y, GAN Z, et al. An empirical study of training end-to-end vision-and-language transformers[C]// Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2022: 18145-18155. |
| 30 | SHEN S, LI L H, TAN H, et al. How much can CLIP benefit vision-and-language tasks?[EB/OL]. [2024-07-10].. |
| 31 | WANG P, YANG A, MEN R, et al. OFA: unifying architectures, tasks, and modalities through a simple sequence-to-sequence learning framework[C]// Proceedings of the 39th International Conference on Machine Learning. New York: JMLR.org, 2022: 23318-23340. |
| 32 | GAO P, GENG S, ZHANG R, et al. CLIP-Adapter: better vision-language models with feature adapters[J]. International Journal of Computer Vision, 2024, 132(2): 581-595. |
| 33 | MA S, ZENG Z, McDUFF D, et al. Active contrastive learning of audio-visual video representations[EB/OL]. [2024-07-10].. |
| 34 | MAHMUD T, MARCULESCU D. AVE-CLIP: AudioCLIP-based multi-window temporal transformer for audio visual event localization[C]// Proceedings of the 2023 IEEE/CVF Winter Conference on Applications of Computer Vision. Piscataway: IEEE, 2023: 5147-5156. |
| 35 | RAMASWAMY J, DAS S. See the sound, hear the pixels[C]// Proceedings of the 2020 IEEE Winter Conference on Applications of Computer Vision. Piscataway: IEEE, 2020: 2959-2968. |
| 36 | RAO V, KHALIL M I, LI H, et al. Dual perspective network for audio-visual event localization[C]// Proceedings of the 2022 European Conference on Computer Vision, LNCS 13694. Cham: Springer, 2022: 689-704. |
| 37 | TANG Z, CHO J, NIE Y, et al. TVLT: textless vision-language transformer[C]// Proceedings of the 36th International Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2022: 9617-9632. |
| 38 | TIAN Y, HU D, XU C. Cyclic co-learning of sounding object visual grounding and sound separation[C]// Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2021: 2744-2753. |
| 39 | MA S, ZENG Z, McDUFF D, et al. Contrastive learning of global and local video representations[C]// Proceedings of the 35th International Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2021: 7025-7040. |
| 40 | LIN Y B, LI Y J, WANG Y C F. Dual-modality seq2seq network for audio-visual event localization[C]// Proceedings of the 2019 IEEE International Conference on Acoustics, Speech and Signal Processing. Piscataway: IEEE, 2019: 2002-2006. |
| 41 | NAGRANI A, YANG S, ARNAB A, et al. Attention bottlenecks for multimodal fusion[C]// Proceedings of the 35th International Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2021: 14200-14213. |
| 42 | TIAN Y, SHI J, LI B, et al. Audio-visual event localization in unconstrained videos[C]// Proceedings of the 2018 European Conference on Computer Vision, LNCS 11206. Cham: Springer, 2018: 252-268. |
| 43 | AKBARI H, YUAN L, QIAN R, et al. VATT: Transformers for multimodal self-supervised learning from raw video, audio and text[C]// Proceedings of the 35th International Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2021: 24206-24221. |
| 44 | YANG Z, FANG Y, ZHU C, et al. i-Code: an integrative and composable multimodal learning framework[C]// Proceedings of the 37th AAAI Conference on Artificial Intelligence. Palo Alto: AAAI Press, 2023: 10880-10890. |
| 45 | LIN Z, GENG S, ZHANG R, et al. Frozen CLIP models are efficient video learners[C]// Proceedings of the 2022 European Conference on Computer Vision, LNCS 13695. Cham: Springer, 2022: 388-404. |
| 46 | ZHANG R, ZHANG W, FANG R, et al. Tip-Adapter: training-free adaption of CLIP for few-shot classification[C]// Proceedings of the 2022 European Conference on Computer Vision, LNCS 13695. Cham: Springer, 2022: 493-510. |
| 47 | LI G, WEI Y, TIAN Y, et al. Learning to answer questions in dynamic audio-visual scenarios[C]// Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2022: 19086-19096. |
| 48 | ZADEH A, LIANG P P, PORIA S, et al. Multimodal language analysis in the wild: CMU-MOSEI dataset and interpretable dynamic fusion graph[C]// Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Stroudsburg: ACL, 2018: 2236-2246. |
| 49 | HASAN M K, RAHMAN W, ZADEH A, et al. UR-FUNNY: a multimodal language dataset for understanding humor[C]// Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing. Stroudsburg: ACL, 2019: 2046-2056. |
| 50 | LIU J, CHEN W, CHENG Y, et al. VIOLIN: a large-scale dataset for video-and-language inference[C]// Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2020: 10897-10907. |
| 51 | FAYEK H M, JOHNSON J. Temporal reasoning via audio question answering[J]. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 2020, 28: 2283-2294. |
| 52 | GULATI A, QIN J, CHIU C C, et al. Conformer: convolution augmented transformer for speech recognition[C]// Proceedings of the INTERSPEECH 2020. [S.l.]: International Speech Communication Association, 2020: 5036-5040. |
| 53 | ANTOL S, AGRAWAL A, LU J, et al. VQA: visual question answering[C]// Proceedings of the 2015 IEEE International Conference on Computer Vision. Piscataway: IEEE, 2015: 2425-2433. |
| 54 | LI X, SONG J, GAO L, et al. Beyond RNNs: positional self-attention with co-attention for video question answering[C]// Proceedings of the 33rd AAAI Conference on Artificial Intelligence. Palo Alto: AAAI Press, 2019: 8658-8665. |
| 55 | FAN C, ZHANG X, ZHANG S, et al. Heterogeneous memory enhanced multimodal attention model for video question answering[C]// Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2019: 1999-2007. |
| 56 | LE T M, LE V, VENKATESH S, et al. Hierarchical conditional relation networks for video question answering[C]// Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2020: 9969-9978. |
| 57 | TSAI Y H H, BAI S, LIANG P P, et al. Multimodal transformer for unaligned multimodal language sequences[C]// Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics. Stroudsburg: ACL, 2019, 2019: 6558-6569. |
| 58 | SUN Z, SARMA P K, SETHARES W A, et al. Learning relationships between text, audio, and video via deep canonical correlation for multimodal language analysis[C]// Proceedings of the 34th AAAI Conference on Artificial Intelligence. Palo Alto: AAAI Press, 2020: 8992-8999. |
| 59 | HAZARIKA D, ZIMMERMANN R, PORIA S. MISA: modality-invariant and-specific representations for multimodal sentiment analysis[C]// Proceedings of the 28th ACM International Conference on Multimedia. New York: ACM, 2020: 1122-1131. |
| 60 | LUO H, JI L, HUANG Y, et al. ScaleVLAD: improving multimodal sentiment analysis via multi-scale fusion of locally descriptors[EB/OL]. [2024-07-10].. |
| 61 | YU W, XU H, YUAN Z, et al. Learning modality-specific representations with self-supervised multitask learning for multimodal sentiment analysis[C]// Proceedings of the 35th AAAI Conference on Artificial Intelligence. Palo Alto: AAAI Press, 2021: 10790-10797. |
| 62 | WANG Y, SHEN Y, LIU Z, et al. Words can shift: dynamically adjusting word representations using nonverbal behaviors[C]// Proceedings of the 33rd AAAI Conference on Artificial Intelligence. Palo Alto: AAAI Press, 2019: 7216-7223. |
| 63 | ZHANG D, JU X, ZHANG W, et al. Multi-modal multi-label emotion recognition with heterogeneous hierarchical message passing[C]// Proceedings of the 35th AAAI Conference on Artificial Intelligence. Palo Alto: AAAI Press, 2021: 14338-14346. |
| 64 | WU X, CHEN Q G, HU Y, et al. Multi-view multi-label learning with view-specific information extraction[C]// Proceedings of the 28th International Joint Conference on Artificial Intelligence. California: ijcai.org, 2019: 3884-3890. |
| 65 | LI L, CHEN Y C, CHENG Y, et al. HERO: hierarchical encoder for video+language omni-representation pre-training[C]// Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing. Stroudsburg: ACL, 2020: 2046-2065. |
| 66 | CHEN J, KONG Y. Explainable video entailment with grounded visual evidence[C]// Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision. Piscataway: IEEE, 2021: 2001-2010. |
| 67 | LEWIS M, LIU Y, GOYAL N, et al. BART: denoising sequence-to-sequence pre-training for natural language generation, translation, and comprehension[C]// Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics. Stroudsburg: ACL, 2020: 7871-7880. |
| 68 | KIRKPATRICK J, PASCANU R, RABINOWITZ N, et al. Overcoming catastrophic forgetting in neural networks[J]. Proceedings of the National Academy of Sciences of the United States of America, 2017, 114(13): 3521-3526. |
| [1] | 黄朋 林佳瑜 梁祖红. 基于提示学习和互信息的中文无监督对比学习方法[J]. 《计算机应用》唯一官方网站, 0, (): 0-0. |
| [2] | 李顺勇 刘坤 曹利娜 赵兴旺. 基于二部图和一致图学习的多视图聚类算法[J]. 《计算机应用》唯一官方网站, 0, (): 0-0. |
| [3] | 张维 龚中伟 李志新 罗佩华 宋玲玲. 学习行为增强的知识追踪模型[J]. 《计算机应用》唯一官方网站, 0, (): 0-0. |
| [4] | 李进 刘立群. 基于残差 Swin Transformer 的 SAR 与可见光图像融合[J]. 《计算机应用》唯一官方网站, 0, (): 0-0. |
| [5] | 范锦涛 陈艳平 杨采薇 林川. 结合边界信息的对比学习嵌套命名实体识别[J]. 《计算机应用》唯一官方网站, 0, (): 0-0. |
| [6] | 云健 高新茹 刘涛 毕文洁. 兼顾高效性和安全性的新型联邦学习方案[J]. 《计算机应用》唯一官方网站, 0, (): 0-0. |
| [7] | 陈路 王怀瑶 刘京阳 闫涛 陈斌. 融合空间-傅里叶域信息的机器人低光环境抓取检测[J]. 《计算机应用》唯一官方网站, 0, (): 0-0. |
| [8] | 马灿 黄瑞章 任丽娜 白瑞娜 伍瑶瑶. 基于大语言模型的多输入中文拼写纠错方法[J]. 《计算机应用》唯一官方网站, 0, (): 0-0. |
| [9] | 谢斌红, 高婉银, 陆望东, 张英俊, 张睿. 小样本相似性匹配特征增强的密集目标计数网络[J]. 《计算机应用》唯一官方网站, 2025, 45(2): 403-410. |
| [10] | 富坤, 应世聪, 郑婷婷, 屈佳捷, 崔静远, 李建伟. 面向小样本节点分类的图数据增强方法[J]. 《计算机应用》唯一官方网站, 2025, 45(2): 392-402. |
| [11] | 严雪文, 黄章进. 基于对比学习的小样本图像分类方法[J]. 《计算机应用》唯一官方网站, 2025, 45(2): 383-391. |
| [12] | 蒋铭, 王琳钦, 赖华, 高盛祥. 基于编辑约束的端到端越南语文本正则化方法[J]. 《计算机应用》唯一官方网站, 2025, 45(2): 362-370. |
| [13] | 王雅伦, 张仰森, 朱思文. 面向知识推理的位置编码标题生成模型[J]. 《计算机应用》唯一官方网站, 2025, 45(2): 345-353. |
| [14] | 高照耀 张展 胡亮亮 许光宇 周胜 胡雨欣 林子捷 周超. 基于残差复卷积网络的7T超高场磁共振并行成像算法[J]. 《计算机应用》唯一官方网站, 0, (): 0-0. |
| [15] | 袁家奇 黄荣 董爱华 周树波 刘浩. 聚合广义上下文特征的人体解析方法[J]. 《计算机应用》唯一官方网站, 0, (): 0-0. |
| 阅读次数 | ||||||
|
全文 |
|
|||||
|
摘要 |
|
|||||