


《计算机应用》唯一官方网站 ›› 2025, Vol. 45 ›› Issue (10): 3111-3120.DOI: 10.11772/j.issn.1001-9081.2024101525
• 人工智能 • 上一篇
范锦涛1,2,3, 陈艳平1,2,3, 杨采薇1,2,3, 林川1,2,3( )
)
收稿日期:2024-11-14
修回日期:2025-01-22
接受日期:2025-01-23
发布日期:2025-02-14
出版日期:2025-10-10
通讯作者:
林川
作者简介:范锦涛(2000—),男,贵州毕节人,硕士研究生,主要研究方向:信息抽取、自然语言处理基金资助:
Jintao FAN1,2,3, Yanping CHEN1,2,3, Caiwei YANG1,2,3, Chuan LIN1,2,3()
Received:2024-11-14
Revised:2025-01-22
Accepted:2025-01-23
Online:2025-02-14
Published:2025-10-10
Contact:
Chuan LIN
About author:FAN Jintao, born in 2000, M. S. candidate. His research interests include information extraction, natural language processing.Supported by:摘要:
现有对比学习(CL)方法在嵌套命名实体识别(NER)任务中存在以下2个主要缺点:1)枚举生成的候选实体作为对比学习的对象,缺失上下文语义依赖和边界信息;2)产生不必要的噪声和无效信息,增加模型的计算负担且弱化了对比学习的性能,提出一个两阶段命名实体识别框架。在第一阶段,通过边界识别模型生成候选实体边界,并通过边界集成模块生成候选实体,减少不必要的负候选实体的生成;同时,在候选实体两侧插入注意力线索,生成对应的候选实体文本,使得模型能够感知上下文语义和边界信息。在第二阶段,提出一个双编码框架用于识别实体,通过对比学习将候选实体文本和实体类型注释映射到相同向量表征空间中,对比的对象不再是候选实体,而是带有注意力线索的句子。此外,设计带有标签语义的分类参数矩阵,丰富模型对候选实体的理解能力。实验结果表明,与Binder方法相比,所提方法在GENIA、ACE2005和ACE2004这3个嵌套数据集上的F1值分别提升了1.22、3.42和2.31个百分点,验证了所提方法对嵌套NER任务的有效性。
中图分类号:
范锦涛, 陈艳平, 杨采薇, 林川. 结合边界信息的对比学习嵌套命名实体识别[J]. 计算机应用, 2025, 45(10): 3111-3120.
Jintao FAN, Yanping CHEN, Caiwei YANG, Chuan LIN. Nested named entity recognition by contrastive learning with boundary information[J]. Journal of Computer Applications, 2025, 45(10): 3111-3120.

图1 本文模型的框架
Fig. 1 Framework of proposed model
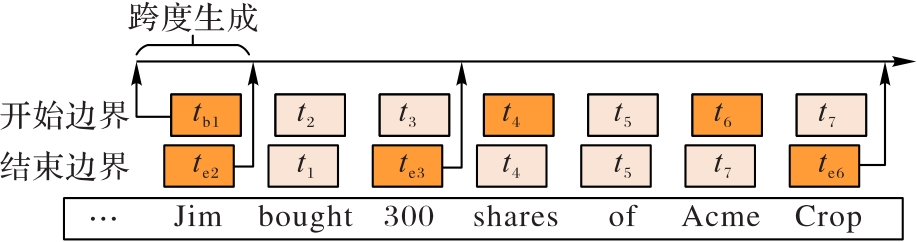
图2 边界集成框架
Fig. 2 Framework of boundary integration

图3 实体分类框架
Fig. 3 Framework of entity classification
| 数据集 | 句子数 | 平均句长 | 嵌套总数 | 实体数 | 平均实体长度 | ||||
|---|---|---|---|---|---|---|---|---|---|
| 训练集 | 验证集 | 测试集 | 训练集 | 验证集 | 测试集 | ||||
| ACE2004 | 6 200 | 745 | 812 | 22.61 | 15 095 | 22 204 | 2 514 | 3 035 | 2.50 |
| ACE2005 | 7 194 | 969 | 1 047 | 18.97 | 15 052 | 24 441 | 3 200 | 2 993 | 3.18 |
| GENIA | 15 023 | 1 669 | 1 854 | 25.41 | 10 263 | 45 144 | 5 365 | 5 506 | 1.97 |
表1 数据集的统计信息
Tab. 1 Statistical information of datasets
| 数据集 | 句子数 | 平均句长 | 嵌套总数 | 实体数 | 平均实体长度 | ||||
|---|---|---|---|---|---|---|---|---|---|
| 训练集 | 验证集 | 测试集 | 训练集 | 验证集 | 测试集 | ||||
| ACE2004 | 6 200 | 745 | 812 | 22.61 | 15 095 | 22 204 | 2 514 | 3 035 | 2.50 |
| ACE2005 | 7 194 | 969 | 1 047 | 18.97 | 15 052 | 24 441 | 3 200 | 2 993 | 3.18 |
| GENIA | 15 023 | 1 669 | 1 854 | 25.41 | 10 263 | 45 144 | 5 365 | 5 506 | 1.97 |
| 类型 | 模型 | ACE2004 | ACE2005 | GENIA | |||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| P | R | F1 | P | R | F1 | P | R | F1 | |||
基于 序列 | Layered | — | — | — | 74.20 | 70.30 | 72.20 | 78.50 | 71.30 | 74.70 | |
| Pyramid | 86.08 | 86.48 | 86.28 | 83.95 | 85.39 | 84.66 | 79.45 | 78.94 | 79.19 | ||
基于 跨度 | Biaffine | 87.30 | 86.00 | 86.70 | 85.20 | 85.60 | 85.40 | 78.20 | 78.20 | 78.20 | |
| Locate and Label | 87.44 | 87.38 | 87.41 | 86.09 | 87.27 | 86.67 | 80.19 | 80.89 | 80.54 | ||
| W2NER | 87.33 | 87.71 | 87.52 | 85.03 | 88.62 | 86.79 | 83.10 | 79.76 | 81.39 | ||
| Triaffine | 87.13 | 87.68 | 87.60 | 86.70 | 86.94 | 86.82 | 80.42 | 82.06 | 81.23 | ||
| Boundary Smooth | 88.43 | 87.53 | 87.98 | 86.25 | 88.07 | 87.15 | — | — | — | ||
| DiffusionNER | 88.11 | 88.66 | 88.39 | 86.15 | 87.72 | 86.93 | 82.10 | 80.97 | 81.53 | ||
| 其他 | Seq2Seq | — | — | 84.33 | — | — | 83.42 | — | — | 78.20 | |
| BartNER | 87.23 | 86.41 | 86.84 | 83.16 | 86.38 | 84.74 | 78.57 | 79.30 | 78.93 | ||
| PIQN | 88.48 | 87.81 | 88.14 | 86.27 | 88.60 | 87.42 | 83.24 | 80.35 | 81.77 | ||
| PromptNER | 87.58 | 88.76 | 88.16 | 86.07 | 88.38 | 87.21 | — | — | — | ||
| Binder | 86.63 | 87.55 | 87.09 | 82.60 | 87.00 | 84.80 | 83.40 | 78.30 | 80.80 | ||
| 文献[ | — | — | — | — | — | — | 81.92 | 80.49 | 81.19 | ||
| 本文模型 | 92.44 | 86.41 | 89.40 | 90.22 | 86.30 | 88.22 | 82.79 | 81.26 | 82.02 | ||
表2 不同数据集上的实验结果对比 (%)
Tab. 2 Comparison of experimental results on different datasets
| 类型 | 模型 | ACE2004 | ACE2005 | GENIA | |||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| P | R | F1 | P | R | F1 | P | R | F1 | |||
基于 序列 | Layered | — | — | — | 74.20 | 70.30 | 72.20 | 78.50 | 71.30 | 74.70 | |
| Pyramid | 86.08 | 86.48 | 86.28 | 83.95 | 85.39 | 84.66 | 79.45 | 78.94 | 79.19 | ||
基于 跨度 | Biaffine | 87.30 | 86.00 | 86.70 | 85.20 | 85.60 | 85.40 | 78.20 | 78.20 | 78.20 | |
| Locate and Label | 87.44 | 87.38 | 87.41 | 86.09 | 87.27 | 86.67 | 80.19 | 80.89 | 80.54 | ||
| W2NER | 87.33 | 87.71 | 87.52 | 85.03 | 88.62 | 86.79 | 83.10 | 79.76 | 81.39 | ||
| Triaffine | 87.13 | 87.68 | 87.60 | 86.70 | 86.94 | 86.82 | 80.42 | 82.06 | 81.23 | ||
| Boundary Smooth | 88.43 | 87.53 | 87.98 | 86.25 | 88.07 | 87.15 | — | — | — | ||
| DiffusionNER | 88.11 | 88.66 | 88.39 | 86.15 | 87.72 | 86.93 | 82.10 | 80.97 | 81.53 | ||
| 其他 | Seq2Seq | — | — | 84.33 | — | — | 83.42 | — | — | 78.20 | |
| BartNER | 87.23 | 86.41 | 86.84 | 83.16 | 86.38 | 84.74 | 78.57 | 79.30 | 78.93 | ||
| PIQN | 88.48 | 87.81 | 88.14 | 86.27 | 88.60 | 87.42 | 83.24 | 80.35 | 81.77 | ||
| PromptNER | 87.58 | 88.76 | 88.16 | 86.07 | 88.38 | 87.21 | — | — | — | ||
| Binder | 86.63 | 87.55 | 87.09 | 82.60 | 87.00 | 84.80 | 83.40 | 78.30 | 80.80 | ||
| 文献[ | — | — | — | — | — | — | 81.92 | 80.49 | 81.19 | ||
| 本文模型 | 92.44 | 86.41 | 89.40 | 90.22 | 86.30 | 88.22 | 82.79 | 81.26 | 82.02 | ||
| 消融策略 | F1 | ||
|---|---|---|---|
| ACE2004 | ACE2005 | GENIA | |
| w/o | 88.45 | 87.39 | 81.42 |
| w/o | 88.77 | 87.66 | 81.60 |
| w/o | 89.17 | 88.08 | 81.87 |
| w/o | 87.47 | 86.57 | 81.32 |
| w/o | 85.93 | 84.99 | 79.86 |
| w/o | 87.19 | 86.13 | 80.83 |
| r/o | 88.42 | 87.32 | 81.65 |
| r/o MLP | 88.73 | 87.62 | 81.75 |
| w/o Attention cues | 88.84 | 87.69 | 81.82 |
表3 消融实验结果 (%)
Tab. 3 Ablation experimental results
| 消融策略 | F1 | ||
|---|---|---|---|
| ACE2004 | ACE2005 | GENIA | |
| w/o | 88.45 | 87.39 | 81.42 |
| w/o | 88.77 | 87.66 | 81.60 |
| w/o | 89.17 | 88.08 | 81.87 |
| w/o | 87.47 | 86.57 | 81.32 |
| w/o | 85.93 | 84.99 | 79.86 |
| w/o | 87.19 | 86.13 | 80.83 |
| r/o | 88.42 | 87.32 | 81.65 |
| r/o MLP | 88.73 | 87.62 | 81.75 |
| w/o Attention cues | 88.84 | 87.69 | 81.82 |
| 融合策略 | GENIA | ACE2005 | ||||
|---|---|---|---|---|---|---|
| P | R | F1 | P | R | F1 | |
| CLS | 81.25 | 81.88 | 81.56 | 89.85 | 86.13 | 87.95 |
| CLS+[S] | 80.35 | 81.84 | 81.09 | 89.74 | 86.17 | 87.92 |
| CLS+[E] | 80.28 | 82.02 | 81.14 | 89.87 | 85.97 | 87.88 |
| CLS+[S]+[E] | 82.79 | 81.26 | 82.02 | 90.22 | 86.30 | 88.22 |
表4 在两个数据集上的特征融合策略实验结果 (%)
Tab. 4 Experimental results of feature fusion strategies on two datasets
| 融合策略 | GENIA | ACE2005 | ||||
|---|---|---|---|---|---|---|
| P | R | F1 | P | R | F1 | |
| CLS | 81.25 | 81.88 | 81.56 | 89.85 | 86.13 | 87.95 |
| CLS+[S] | 80.35 | 81.84 | 81.09 | 89.74 | 86.17 | 87.92 |
| CLS+[E] | 80.28 | 82.02 | 81.14 | 89.87 | 85.97 | 87.88 |
| CLS+[S]+[E] | 82.79 | 81.26 | 82.02 | 90.22 | 86.30 | 88.22 |
| 策略 | 跨度总数 | 正确实体数 | ξ/% | P/% | R/% | F1/% |
|---|---|---|---|---|---|---|
| 仅枚举 | 79 555 | 2 782 | 92.95 | 13.34 | 85.57 | 23.09 |
| 边界枚举 | 13 452 | 2 661 | 88.91 | 50.93 | 82.29 | 62.92 |
| 边界匹配 | 8 235 | 2 748 | 91.81 | 90.22 | 86.30 | 88.22 |
| 边界补足 | 17 853 | 2 832 | 94.62 | 51.63 | 86.47 | 64.65 |
表5 在ACE2005数据集上的跨度生成策略实验结果
Tab. 5 Experimental results of span generation strategies on ACE2005 dataset
| 策略 | 跨度总数 | 正确实体数 | ξ/% | P/% | R/% | F1/% |
|---|---|---|---|---|---|---|
| 仅枚举 | 79 555 | 2 782 | 92.95 | 13.34 | 85.57 | 23.09 |
| 边界枚举 | 13 452 | 2 661 | 88.91 | 50.93 | 82.29 | 62.92 |
| 边界匹配 | 8 235 | 2 748 | 91.81 | 90.22 | 86.30 | 88.22 |
| 边界补足 | 17 853 | 2 832 | 94.62 | 51.63 | 86.47 | 64.65 |
| 标签插入策略 | P | R | F1 |
|---|---|---|---|
| [S] | 68.15 | 33.31 | 44.75 |
| [E] | 85.55 | 27.90 | 42.08 |
| [S]+[E] | 90.22 | 86.30 | 88.22 |
表6 在ACE2005数据集上的注意力线索策略实验结果 (%)
Tab. 6 Experimental results of attention cue strategies on ACE2005 dataset
| 标签插入策略 | P | R | F1 |
|---|---|---|---|
| [S] | 68.15 | 33.31 | 44.75 |
| [E] | 85.55 | 27.90 | 42.08 |
| [S]+[E] | 90.22 | 86.30 | 88.22 |

图4 注意力的可视化
Fig. 4 Attention visualization

图5 不同损失函数F1值的趋势
Fig. 5 F1 value trends for different loss functions

图6 不同损失函数嵌入空间的可视化
Fig. 6 Embedding space visualization of different loss functions
| 组序 | P/% | R/% | F1 /% | |||
|---|---|---|---|---|---|---|
| 开始边界 | 结束边界 | 开始边界 | 结束边界 | 开始边界 | 结束边界 | |
| 1 | 87.41 | 87.90 | 97.11 | 94.77 | 92.00 | 91.20 |
| 2 | 92.39 | 91.86 | 94.36 | 93.46 | 93.37 | 92.65 |
| 3 | 93.66 | 93.14 | 94.47 | 93.74 | 94.06 | 93.44 |
表7 ACE2005数据集上的边界识别实验结果
Tab. 7 Experimental results of boundary recognition on ACE2005 dataset
| 组序 | P/% | R/% | F1 /% | |||
|---|---|---|---|---|---|---|
| 开始边界 | 结束边界 | 开始边界 | 结束边界 | 开始边界 | 结束边界 | |
| 1 | 87.41 | 87.90 | 97.11 | 94.77 | 92.00 | 91.20 |
| 2 | 92.39 | 91.86 | 94.36 | 93.46 | 93.37 | 92.65 |
| 3 | 93.66 | 93.14 | 94.47 | 93.74 | 94.06 | 93.44 |
| 组序 | 跨度总数 | 正确实体数 | ξ/% | P/% | R/% | F1 /% |
|---|---|---|---|---|---|---|
| 1 | 9 124 | 2 798 | 93.48 | 84.77 | 87.44 | 86.09 |
| 2 | 8 071 | 2 712 | 90.61 | 90.47 | 84.73 | 87.51 |
| 3 | 8 235 | 2 748 | 91.81 | 90.22 | 86.30 | 88.22 |
表8 在3组边界识别数据上的实体识别性能对比
Tab. 8 Comparison of entity recognition performance on three groups of boundary recognition data
| 组序 | 跨度总数 | 正确实体数 | ξ/% | P/% | R/% | F1 /% |
|---|---|---|---|---|---|---|
| 1 | 9 124 | 2 798 | 93.48 | 84.77 | 87.44 | 86.09 |
| 2 | 8 071 | 2 712 | 90.61 | 90.47 | 84.73 | 87.51 |
| 3 | 8 235 | 2 748 | 91.81 | 90.22 | 86.30 | 88.22 |
| [1] | 邓依依,邬昌兴,魏永丰,等. 基于深度学习的命名实体识别综述[J]. 中文信息学报, 2021, 35(9): 30-45. |
| DENG Y Y, WU C X, WEI Y F, et al. A survey on named entity recognition based on deep learning[J]. Journal of Chinese Information Processing, 2021, 35(9): 30-45. | |
| [2] | 黄蓉,陈艳平,扈应,等. 结合实体边界线索的中文命名实体识别方法[J]. 计算机工程与应用, 2024, 60(6): 199-206. |
| HUANG R, CHEN Y P, HU Y, et al. Chinese named entity recognition methods combined with entity boundary cues[J]. Computer Engineering and Applications, 2024, 60(6): 199-206. | |
| [3] | 余诗媛,郭淑明,黄瑞阳,等. 嵌套命名实体识别研究进展[J]. 计算机科学, 2021, 48(11A): 1-10. |
| YU S Y, GUO S M, HUANG R Y, et al. Overview of nested named entity recognition[J]. Computer Science, 2021, 48(11A): 1-10. | |
| [4] | CHEN Y, HU Y, LI Y, et al. A boundary assembling method for nested biomedical named entity recognition[J]. IEEE Access, 2020, 8: 214141-214152. |
| [5] | ZHANG S, CHENG H, GAO J, et al. Optimizing bi-encoder for named entity recognition via contrastive learning[EB/OL]. [2024-08-25].. |
| [6] | CHEN Y, HUANG R, PAN L, et al. A controlled attention for nested named entity recognition[J]. Cognitive Computation, 2023, 15(1): 132-145. |
| [7] | 郭云乔,唐庭龙,李小龙. 基于深度学习的嵌套命名实体识别研究综述[J]. 长江信息通信, 2023, 36(4): 213-217. |
| GUO Y Q, TANG T L, LI X L. A survey of nested named entity recognition based on deep learning[J]. Changjiang Information and Communications, 2023, 36(4): 213-217. | |
| [8] | JU M, MIWA M, ANANIADOU S. A neural layered model for nested named entity recognition[C]// Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long Papers). Stroudsburg: ACL, 2018: 1446-1459. |
| [9] | WANG J, SHOU L, CHEN K, et al. Pyramid: a layered model for nested named entity recognition[C]// Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics. Stroudsburg: ACL, 2020: 5918-5928. |
| [10] | STRAKOVÁ J, STRAKA M, HAJIC J. Neural architectures for nested NER through linearization[C]// Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics. Stroudsburg: ACL, 2019: 5326-5331. |
| [11] | DEVLIN J, CHANG M W, LEE K, et al. BERT: pre-training of deep bidirectional Transformers for language understanding[C]// Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers). Stroudsburg: ACL, 2019: 4171-4186. |
| [12] | SOHRAB M G, MIWA M. Deep exhaustive model for nested named entity recognition[C]// Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing. Stroudsburg: ACL, 2018: 2843-2849. |
| [13] | SCHUSTER M, PALIWAL K K. Bidirectional recurrent neural networks[J]. IEEE Transactions on Signal Processing, 1997, 45(11): 2673-2681. |
| [14] | SHEN Y, MA X, TAN Z, et al. Locate and label: a two-stage identifier for nested named entity recognition[C]// Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers). Stroudsburg: ACL, 2021: 2782-2794. |
| [15] | KHOSLA P, TETERWAK P, WANG C, et al. Supervised contrastive learning[C]// Proceedings of the 34th International Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2020: 18661-18673. |
| [16] | SI S, ZENG S, LIN J, et al. SCL-RAI: span-based contrastive learning with retrieval augmented inference for unlabeled entity problem in NER[C]// Proceedings of the 29th International Conference on Computational Linguistics. [S.l.]: International Committee on Computational Linguistics, 2022: 2313-2318. |
| [17] | ZHANG Z, SHI B, ZHANG H, et al. NerCo: a contrastive learning based two-stage Chinese NER method[C]// Proceedings of the 32nd International Joint Conference on Artificial Intelligence. California: ijcai.org, 2023: 5287-5295. |
| [18] | LI J, FEI H, LIU J, et al. Unified named entity recognition as word-word relation classification[C]// Proceedings of the 36th AAAI Conference on Artificial Intelligence. Palo Alto: AAAI Press, 2022: 10965-10973. |
| [19] | KIM J D, OHTA T, TATEISI Y, et al. GENIA corpus — a semantically annotated corpus for bio-textmining[J]. Bioinformatics, 2003, 19(S1): i180-i182. |
| [20] | DODDINGTON G, MITCHELL A, PRZYBOCKI M, et al. The Automatic Content Extraction (ACE) program — tasks, data, and evaluation[C]// Proceedings of the 4th International Conference on Language Resources and Evaluation. Paris: European Language Resources Association, 2004: 837-840. |
| [21] | LEE J, YOON W, KIM S, et al. BioBERT: a pre-trained biomedical language representation model for biomedical text mining[J]. Bioinformatics, 2020, 36(4): 1234-1240. |
| [22] | YU J, BOHNET B, POESIO M. Named entity recognition as dependency parsing[C]// Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics. Stroudsburg: ACL, 2020: 6470-6476. |
| [23] | YUAN Z, TAN C, HUANG S, et al. Fusing heterogeneous factors with Triaffine mechanism for nested named entity recognition[C]// Findings of the Association for Computational Linguistics: ACL 2022. Stroudsburg: ACL, 2022: 3174-3186. |
| [24] | ZHU E, LI J. Boundary smoothing for named entity recognition[C]// Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Stroudsburg: ACL, 2022: 7096-7108. |
| [25] | SHEN Y, SONG K, TAN X, et al. DiffusionNER: boundary diffusion for named entity recognition[C]// Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Stroudsburg: ACL, 2023: 3875-3890. |
| [26] | YAN H, GUI T, DAI J, et al. A unified generative framework for various NER subtasks[C]// Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers). Stroudsburg: ACL, 2021: 5808-5822. |
| [27] | SHEN Y, WANG X, TAN Z, et al. Parallel instance query network for named entity recognition[C]// Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Stroudsburg: ACL, 2022: 947-961. |
| [28] | SHEN Y, TAN Z, WU S, et al. PromptNER: prompt locating and typing for named entity recognition[C]// Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Stroudsburg: ACL, 2023: 12492-12507. |
| [29] | VIG J. BertViz: a tool for visualizing multihead self-attention in the BERT model[EB/OL]. [2024-08-25].. |
| [30] | VAN DER MAATEN L, HINTON G. Visualizing data using t-SNE[J]. Journal of Machine Learning Research, 2008, 9: 2579-2605. |
| [1] | 刘超, 余岩化. 融合降噪策略与多视图对比学习的知识感知推荐模型[J]. 《计算机应用》唯一官方网站, 2025, 45(9): 2827-2837. |
| [2] | 许志雄, 李波, 边小勇, 胡其仁. 对抗样本嵌入注意力U型网络的3D医学图像分割[J]. 《计算机应用》唯一官方网站, 2025, 45(9): 3011-3016. |
| [3] | 王祉苑, 彭涛, 杨捷. 分布外检测中训练与测试的内外数据整合[J]. 《计算机应用》唯一官方网站, 2025, 45(8): 2497-2506. |
| [4] | 谢劲, 褚苏荣, 强彦, 赵涓涓, 张华, 高勇. 用于胸片中硬负样本识别的双支分布一致性对比学习模型[J]. 《计算机应用》唯一官方网站, 2025, 45(7): 2369-2377. |
| [5] | 王震洲, 郭方方, 宿景芳, 苏鹤, 王建超. 面向智能巡检的视觉模型鲁棒性优化方法[J]. 《计算机应用》唯一官方网站, 2025, 45(7): 2361-2368. |
| [6] | 余明峰, 秦永彬, 黄瑞章, 陈艳平, 林川. 基于对比学习增强双注意力机制的多标签文本分类方法[J]. 《计算机应用》唯一官方网站, 2025, 45(6): 1732-1740. |
| [7] | 颜文婧, 王瑞东, 左敏, 张青川. 基于风味嵌入异构图层次学习的食谱推荐模型[J]. 《计算机应用》唯一官方网站, 2025, 45(6): 1869-1878. |
| [8] | 姜超英, 李倩, 刘宁, 刘磊, 崔立真. 基于图对比学习的再入院预测模型[J]. 《计算机应用》唯一官方网站, 2025, 45(6): 1784-1792. |
| [9] | 胡文彬, 蔡天翔, 韩天乐, 仲兆满, 马常霞. 融合对比学习与情感分析的多模态反讽检测模型[J]. 《计算机应用》唯一官方网站, 2025, 45(5): 1432-1438. |
| [10] | 龙雨菲, 牟宇辰, 刘晔. 基于张量化图卷积网络和对比学习的多源数据表示学习模型[J]. 《计算机应用》唯一官方网站, 2025, 45(5): 1372-1378. |
| [11] | 田仁杰, 景明利, 焦龙, 王飞. 基于混合负采样的图对比学习推荐算法[J]. 《计算机应用》唯一官方网站, 2025, 45(4): 1053-1060. |
| [12] | 党伟超, 温鑫瑜, 高改梅, 刘春霞. 基于多视图多尺度对比学习的图协同过滤[J]. 《计算机应用》唯一官方网站, 2025, 45(4): 1061-1068. |
| [13] | 陈维, 施昌勇, 马传香. 基于多模态数据融合的农作物病害识别方法[J]. 《计算机应用》唯一官方网站, 2025, 45(3): 840-848. |
| [14] | 王元龙, 刘亭华, 张虎. 基于跨模态对比学习的常识问答模型[J]. 《计算机应用》唯一官方网站, 2025, 45(3): 732-738. |
| [15] | 杨晟, 李岩. 面向目标检测的对比知识蒸馏方法[J]. 《计算机应用》唯一官方网站, 2025, 45(2): 354-361. |
| 阅读次数 | ||||||
|
全文 |
|
|||||
|
摘要 |
|
|||||