


《计算机应用》唯一官方网站 ›› 2025, Vol. 45 ›› Issue (3): 808-814.DOI: 10.11772/j.issn.1001-9081.2024101434
康斌1,2, 陈斌2,3( ), 王俊杰3,4, 李昱林3,4, 赵军智5, 咸伟志6
), 王俊杰3,4, 李昱林3,4, 赵军智5, 咸伟志6
收稿日期:2024-10-11
修回日期:2024-11-26
接受日期:2024-12-04
发布日期:2025-01-06
出版日期:2025-03-10
通讯作者:
陈斌
作者简介:康斌(1998—),男,甘肃临洮人,博士研究生,主要研究方向:多模态检索、目标检测基金资助:
Bin KANG1,2, Bin CHEN2,3(), Junjie WANG3,4, Yulin LI3,4, Junzhi ZHAO5, Weizhi XIAN6
Received:2024-10-11
Revised:2024-11-26
Accepted:2024-12-04
Online:2025-01-06
Published:2025-03-10
Contact:
Bin CHEN
About author:KANG Bin, born in 1998, Ph. D. candidate. His research interests include multi-modal retrieval, object detection.Supported by:摘要:
基于文本的人物检索旨在通过使用文本描述作为查询来识别特定人物。现有的先进方法通常设计多种对齐机制实现跨模态数据在全局和局部的对应关系,然而忽略了不同对齐机制之间的相互影响。因此,提出一种多粒度共享语义中心关联机制,深入探索全局对齐和局部对齐之间的促进和抑制效应。首先,引入一个多粒度交叉对齐模块,并通过增强图像-句子和局部区域-分词之间的交互,实现跨模态数据在联合嵌入空间的多层次对齐;其次,建立一个共享语义中心,将它作为一个可学习的语义枢纽,并通过全局特征和局部特征的关联,增强不同对齐机制之间的语义一致性,促进全局和局部特征的协同作用。在共享语义中心内,计算图像特征和文本特征之间的局部和全局跨模态相似性关系,提供一种全局视角与局部视角的互补度量,并最大限度地促进多种对齐机制之间的正向效应;最后,在CUHK-PEDES数据集上进行实验。结果表明:所提方法在Rank-1指标上较基线方法显著提升了8.69个百分点,平均精度均值(mAP)提升了6.85个百分点。在ICFG-PEDES和RSTPReid数据集上所提方法也取得了优异的性能,明显超越了所有对比方法。
中图分类号:
康斌, 陈斌, 王俊杰, 李昱林, 赵军智, 咸伟志. 基于多粒度共享语义中心关联的文本到人物检索方法[J]. 计算机应用, 2025, 45(3): 808-814.
Bin KANG, Bin CHEN, Junjie WANG, Yulin LI, Junzhi ZHAO, Weizhi XIAN. Text-based person retrieval method based on multi-granularity shared semantic center association[J]. Journal of Computer Applications, 2025, 45(3): 808-814.
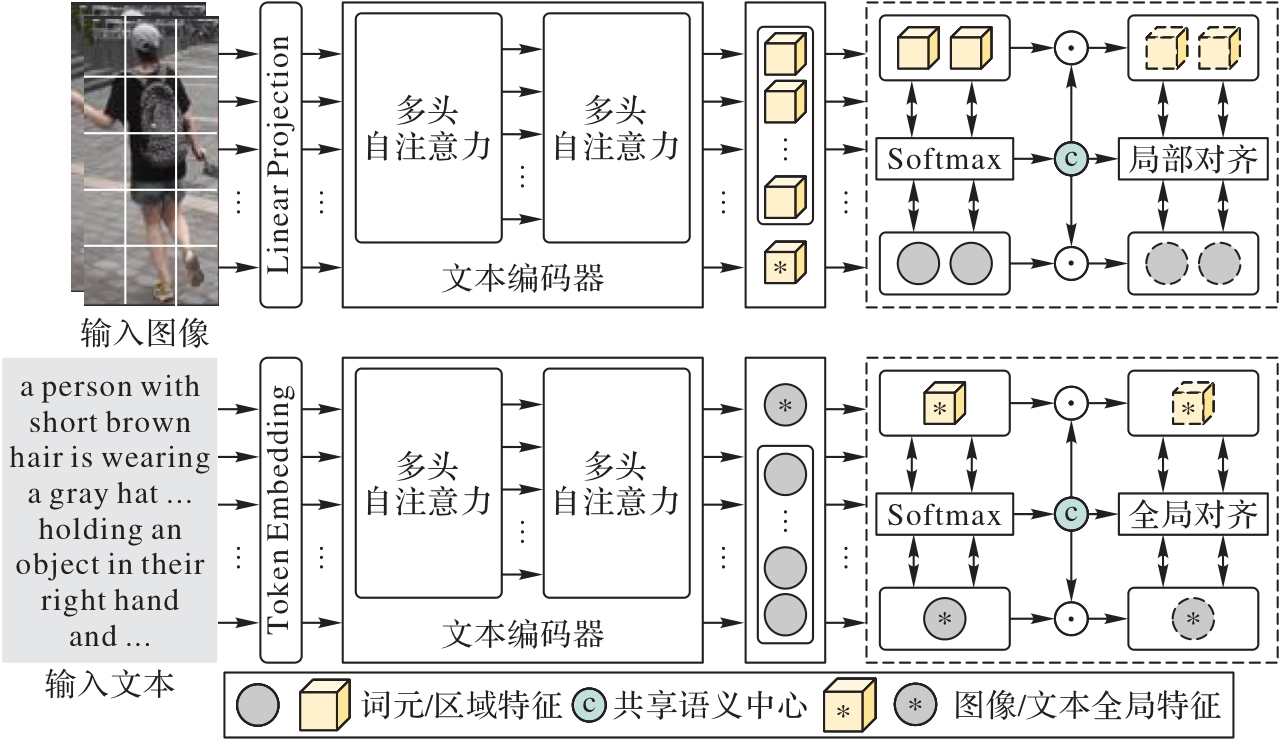
图1 本文方法的整体结构
Fig. 1 Overall structure of proposed method
| 方法 | Rank-1 | Rank-5 | Rank-10 | mAP |
|---|---|---|---|---|
| baseline | 57.44 | 75.79 | 82.22 | 33.03 |
| DSSL | 59.98 | 80.41 | 87.56 | — |
| CTLG | 57.69 | 75.79 | 82.67 | — |
| CFine | 60.83 | 76.55 | 82.42 | — |
| IRRA | 63.46 | 80.25 | 85.82 | 38.06 |
| BiLMa | 63.83 | 80.15 | 85.74 | 38.26 |
| TBPS-CLIP | 65.05 | 80.34 | 85.47 | 39.83 |
| 本文方法 | 66.13 | 80.95 | 86.32 | 39.88 |
表1 CUHK-PEDES数据集上不同方法的性能比较 (%)
Tab. 1 Performance comparison of different methods on CUHK-PEDES dataset
| 方法 | Rank-1 | Rank-5 | Rank-10 | mAP |
|---|---|---|---|---|
| baseline | 57.44 | 75.79 | 82.22 | 33.03 |
| DSSL | 59.98 | 80.41 | 87.56 | — |
| CTLG | 57.69 | 75.79 | 82.67 | — |
| CFine | 60.83 | 76.55 | 82.42 | — |
| IRRA | 63.46 | 80.25 | 85.82 | 38.06 |
| BiLMa | 63.83 | 80.15 | 85.74 | 38.26 |
| TBPS-CLIP | 65.05 | 80.34 | 85.47 | 39.83 |
| 本文方法 | 66.13 | 80.95 | 86.32 | 39.88 |
| 方法 | Rank-1 | Rank-5 | Rank-10 | mAP |
|---|---|---|---|---|
| baseline | 57.44 | 75.79 | 82.22 | 33.03 |
| IVT | 56.04 | 73.60 | 80.22 | — |
| CTLG | 57.69 | 75.79 | 82.67 | — |
| CFine | 60.83 | 76.55 | 82.42 | — |
| IRRA | 63.46 | 80.25 | 85.82 | 38.06 |
| BiLMa | 63.83 | 80.15 | 85.74 | 38.26 |
| TBPS-CLIP | 65.05 | 80.34 | 85.47 | 39.83 |
| 本文方法 | 66.26 | 80.99 | 86.12 | 39.81 |
表2 ICFG-PEDES数据集上不同方法的性能比较 (%)
Tab. 2 Performance comparison of different methods on ICFG-PEDES dataset
| 方法 | Rank-1 | Rank-5 | Rank-10 | mAP |
|---|---|---|---|---|
| baseline | 57.44 | 75.79 | 82.22 | 33.03 |
| IVT | 56.04 | 73.60 | 80.22 | — |
| CTLG | 57.69 | 75.79 | 82.67 | — |
| CFine | 60.83 | 76.55 | 82.42 | — |
| IRRA | 63.46 | 80.25 | 85.82 | 38.06 |
| BiLMa | 63.83 | 80.15 | 85.74 | 38.26 |
| TBPS-CLIP | 65.05 | 80.34 | 85.47 | 39.83 |
| 本文方法 | 66.26 | 80.99 | 86.12 | 39.81 |
| 方法 | Rank-1 | Rank-5 | Rank-10 | mAP |
|---|---|---|---|---|
| baseline | 56.67 | 78.09 | 86.62 | 44.25 |
| DSSL | 32.43 | 55.08 | 63.19 | — |
| SSAN | 43.50 | 67.80 | 77.15 | — |
| IVT | 46.70 | 70.00 | 78.80 | — |
| CFine | 50.55 | 72.50 | 81.60 | — |
| IRRA | 60.20 | 81.30 | 88.20 | 47.17 |
| BiLMa | 61.20 | 81.50 | 88.80 | 48.51 |
| TBPS-CLIP | 61.95 | 83.55 | 88.75 | 48.26 |
| 本文方法 | 62.85 | 84.63 | 89.92 | 48.79 |
表3 RSTPReid数据集上不同方法的性能比较 (%)
Tab. 3 Performance comparison of different methods on RSTPReid dataset
| 方法 | Rank-1 | Rank-5 | Rank-10 | mAP |
|---|---|---|---|---|
| baseline | 56.67 | 78.09 | 86.62 | 44.25 |
| DSSL | 32.43 | 55.08 | 63.19 | — |
| SSAN | 43.50 | 67.80 | 77.15 | — |
| IVT | 46.70 | 70.00 | 78.80 | — |
| CFine | 50.55 | 72.50 | 81.60 | — |
| IRRA | 60.20 | 81.30 | 88.20 | 47.17 |
| BiLMa | 61.20 | 81.50 | 88.80 | 48.51 |
| TBPS-CLIP | 61.95 | 83.55 | 88.75 | 48.26 |
| 本文方法 | 62.85 | 84.63 | 89.92 | 48.79 |

图2 在CUHK-PEDES数据集上的可视化结果
Fig. 2 Visualization results on CUHK-PEDES dataset
| 方法 | Rank-1 | Rank-5 | Rank-10 | mAP |
|---|---|---|---|---|
| baseline | 57.44 | 75.79 | 82.22 | 33.03 |
| GA | 60.08 | 77.50 | 83.50 | 34.50 |
| LA | 60.32 | 77.94 | 83.78 | 35.01 |
| MGCA(GA+LA) | 63.20 | 79.80 | 85.10 | 36.80 |
| MGCA+SSC | 65.10 | 80.30 | 85.80 | 38.50 |
| 本文方法 | 66.13 | 80.95 | 86.32 | 39.88 |
表4 CUHK-PEDES数据集上的消融实验结果 (%)
Tab. 4 Ablations experimental results on CUHK-PEDES dataset
| 方法 | Rank-1 | Rank-5 | Rank-10 | mAP |
|---|---|---|---|---|
| baseline | 57.44 | 75.79 | 82.22 | 33.03 |
| GA | 60.08 | 77.50 | 83.50 | 34.50 |
| LA | 60.32 | 77.94 | 83.78 | 35.01 |
| MGCA(GA+LA) | 63.20 | 79.80 | 85.10 | 36.80 |
| MGCA+SSC | 65.10 | 80.30 | 85.80 | 38.50 |
| 本文方法 | 66.13 | 80.95 | 86.32 | 39.88 |
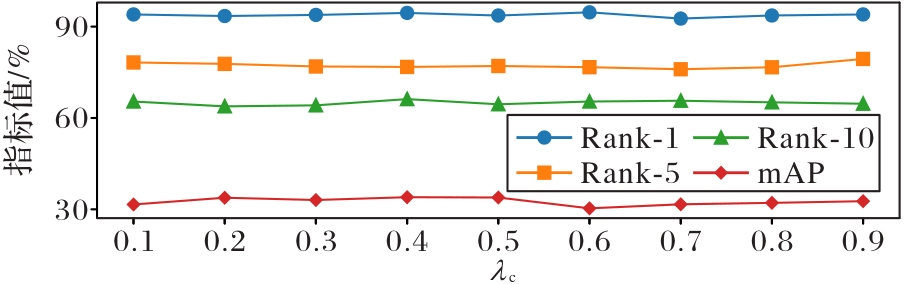
图3 参数分析
Fig. 3 Parameter analysis
| 1 | YU C, LIU X, WANG Y, et al. TF-CLIP: learning text-free CLIP for video-based person re-identification [C]// Proceedings of the 38th AAAI Conference on Artificial Intelligence. Palo Alto: AAAI Press, 2024: 6764-6772. |
| 2 | GAO L, NIU K, JIAO B, et al. Addressing information inequality for text-based person search via pedestrian-centric visual denoising and bias-aware alignments [J]. IEEE Transactions on Circuits and Systems for Video Technology, 2023, 33(12): 7884-7899. |
| 3 | ZHUANG W, GAN X, WEN Y, et al. Optimizing performance of federated person re-identification: benchmarking and analysis [J]. ACM Transactions on Multimedia Computing, Communications and Applications, 2023, 19(1s): No.38. |
| 4 | 姜定,叶茫. 面向跨模态文本到图像行人重识别的Transformer网络[J]. 中国图象图形学报, 2023, 28(5): 1384-1395. |
| JIANG D, YE M. Transformer network for cross-modal text-to-image person re-identification [J]. Journal of Image and Graphics, 2023, 28(5): 1384-1395. | |
| 5 | LI J, JIANG M, KONG J, et al. Learning semantic polymorphic mapping for text-based person retrieval [J]. IEEE Transactions on Multimedia, 2024, 26: 10678-10691. |
| 6 | WANG D, YAN F, WANG Y, et al. Fine-grained semantics-aware representation learning for text-based person retrieval [C]// Proceedings of the 14th Annual ACM International Conference on Multimedia Retrieval. New York: ACM, 2024: 92-100. |
| 7 | YAN S, TANG H, ZHANG L, et al. Image-specific information suppression and implicit local alignment for text-based person search[J]. IEEE Transactions on Neural Networks and Learning Systems, 2024, 35(12): 17973-17986. |
| 8 | GAO C, CAI G, JIANG X, et al. Conditional feature learning based Transformer for text-based person search [J]. IEEE Transactions on Image Processing, 2022, 31: 6097-6108. |
| 9 | AGGARWAL S, BABU R V, CHAKRABORTY A. Text-based person search via attribute-aided matching [C]// Proceedings of the 2020 IEEE Winter Conference on Applications of Computer Vision. Piscataway: IEEE, 2020: 2606-2614. |
| 10 | BAO L, WEI L, ZHOU W, et al. Multi-granularity matching Transformer for text-based person search [J]. IEEE Transactions on Multimedia, 2024, 26: 4281-4293. |
| 11 | ZUO J, ZHOU H, NIE Y, et al. UFineBench: towards text-based person retrieval with ultra-fine granularity [C]// Proceedings of the 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2024: 22010-22019. |
| 12 | WU X, MA W, GUO D, et al. Text-based occluded person re-identification via multi-granularity contrastive consistency learning[C]// Proceedings of the 38th AAAI Conference on Artificial Intelligence. Palo Alto: AAAI Press, 2024: 6162-6170. |
| 13 | KANG B, CHEN B, WANG J, et al. Multi-path exploration and feedback adjustment for text-to-image person retrieval [EB/OL]. [2024-12-13]. . |
| 14 | KANG B, CHEN B, WANG J, et al. Multi-attribute consistency driven visual language framework for surface defect detection [C]// Proceedings of the 2024 IEEE International Conference on Multimedia and Expo. Piscataway: IEEE, 2024: 1-5. |
| 15 | MINDERER M, GRITSENKO A, HOULSBY N. Scaling open-vocabulary object detection [C]// Proceedings of the 37th International Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2023: 72983-73007. |
| 16 | HONG W, WANG W, DING M, et al. CogVLM2: visual language models for image and video understanding [EB/OL]. [2024-07-13].. |
| 17 | RADFORD A, KIM J W, HALLACY C, et al. Learning transferable visual models from natural language supervision [C]// Proceedings of the 38th International Conference on Machine Learning. New York: JMLR.org, 2021: 8748-8763. |
| 18 | JIA C, YANG Y, XIA Y, et al. Scaling up visual and vision-language representation learning with noisy text supervision [C]// Proceedings of the 38th International Conference on Machine Learning. New York: JMLR.org, 2021: 4904-4916. |
| 19 | WANG A, YU J, YU A W, et al. SimVLM: simple visual language model pretraining with weak supervision [EB/OL]. [2024-07-13]. . |
| 20 | LI J, SELVARAJU R R, GOTMARE A D, et al. Align before fuse: vision and language representation learning with momentum distillation [C]// Proceedings of the 35th International Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2021: 9694-9705. |
| 21 | JING Y, WANG W, WANG L, et al. Cross-modal cross-domain moment alignment network for person search [C]// Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2020: 10675-10683. |
| 22 | LIN D, PENG Y X, MENG J, et al. Cross-modal adaptive dual association for text-to-image person retrieval [J]. IEEE Transactions on Multimedia, 2024, 26: 6609-6620. |
| 23 | ZUO J, HONG J, ZHANG F, et al. PLIP: language-image pre-training for person representation learning [EB/OL]. [2024-07-13]. . |
| 24 | DENG Y, HU Z, HAN J, et al. DualFocus: integrating plausible descriptions in text-based person re-identification [EB/OL]. [2024-07-08]. . |
| 25 | DING Z, DING C, SHAO Z, et al. Semantically self-aligned network for text-to-image part-aware person re-identification [EB/OL]. [2024-02-15]. . |
| 26 | ZHU A, WANG Z, LI Y, et al. DSSL: deep surroundings-person separation learning for text-based person retrieval [C]// Proceedings of the 29th ACM International Conference on Multimedia. New York: ACM, 2021: 209-217. |
| 27 | WU H, CHEN W, LIU Z, et al. Contrastive Transformer learning with proximity data generation for text-based person search [J]. IEEE Transactions on Circuits and Systems for Video Technology, 2024, 34(8): 7005-7016. |
| 28 | YAN S, DONG N, ZHANG L, et al. CLIP-driven fine-grained text-image person re-identification [J]. IEEE Transactions on Image Processing, 2023, 32: 6032-6046. |
| 29 | JIANG D, YE M. Cross-modal implicit relation reasoning and aligning for text-to-image person retrieval [C]// Proceedings of the 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2023: 2787-2797. |
| 30 | FUJII T, TARASHIMA S. BiLMa: bidirectional local-matching for text-based person re-identification [C]// Proceedings of the 2023 IEEE/CVF International Conference on Computer Vision Workshops. Piscataway: IEEE, 2023: 2778-2782. |
| 31 | CAO M, BAI Y, ZENG Z, et al. An empirical study of CLIP for text-based person search [C]// Proceedings of the 38th AAAI Conference on Artificial Intelligence. Palo Alto: AAAI Press, 2024: 465-473. |
| 32 | SHU X, WEN W, WU H, et al. See finer, see more: implicit modality alignment for text-based person retrieval [C]// Proceedings of the 2022 European Conference on Computer Vision Workshops, LNCS 13805. Cham: Springer, 2023: 624-641. |
| [1] | 尹学辉 傅林琳 周尚波. 渐进式上下文交互和注意力机制的混凝土路面裂缝检测网络 [J]. 《计算机应用》唯一官方网站, 0, (): 0-0. |
| [2] | 汪书民 周香伶 李生林. 基于特征融合的低光场景下的自适应人脸识别[J]. 《计算机应用》唯一官方网站, 0, (): 0-0. |
| [3] | 上官宏, 任慧莹, 张雄, 韩兴隆, 桂志国, 王燕玲. 基于双编码器双解码器GAN的低剂量CT降噪模型[J]. 《计算机应用》唯一官方网站, 2025, 45(2): 624-632. |
| [4] | 何秋润, 胡节, 彭博, 李天源. 基于上下文信息的多尺度特征融合织物疵点检测算法[J]. 《计算机应用》唯一官方网站, 2025, 45(2): 640-646. |
| [5] | 余松森, 林智凡, 薛国鹏, 徐建宇. 基于改进YOLOv8的轻量级大幅面瓷砖缺陷检测算法[J]. 《计算机应用》唯一官方网站, 2025, 45(2): 647-654. |
| [6] | 高照耀 张展 胡亮亮 许光宇 周胜 胡雨欣 林子捷 周超. 基于残差复卷积网络的7T超高场磁共振并行成像算法[J]. 《计算机应用》唯一官方网站, 0, (): 0-0. |
| [7] | 袁家奇 黄荣 董爱华 周树波 刘浩. 聚合广义上下文特征的人体解析方法[J]. 《计算机应用》唯一官方网站, 0, (): 0-0. |
| [8] | 张佳慧 李晓明 张嘉祥. 强化形态感知的路面缺陷检测算法[J]. 《计算机应用》唯一官方网站, 0, (): 0-0. |
| [9] | 梁杰涛, 罗兵, 付兰慧, 常青玲, 李楠楠, 易宁波, 冯其, 何鑫, 邓辅秦. 基于坐标几何采样的点云配准方法[J]. 《计算机应用》唯一官方网站, 2025, 45(1): 214-222. |
| [10] | 黄颖, 李昌盛, 彭慧, 刘苏. 用于动态场景高动态范围成像的局部熵引导的双分支网络[J]. 《计算机应用》唯一官方网站, 2025, 45(1): 204-213. |
| [11] | 况世雄 姚俊波 陆佳炜 王琪冰 肖刚. 基于动态图卷积网络的电梯乘客异常行为数据增强方法[J]. 《计算机应用》唯一官方网站, 0, (): 0-0. |
| [12] | 郑川江, 贾学富, 杨心宇, 李小雪. 三维重建中的弱纹理场景智能补全方法[J]. 《计算机应用》唯一官方网站, 0, (): 206-211. |
| [13] | 刘玉婉, 郭智溢, 邢冠宇, 刘艳丽. 差异感知的室内场景动态光照在线估计方法[J]. 《计算机应用》唯一官方网站, 0, (): 184-191. |
| [14] | 刘展阳, 刘进锋. 基于知识蒸馏的不存储旧数据的类增量学习[J]. 《计算机应用》唯一官方网站, 0, (): 12-17. |
| [15] | 王子怡 李卫军 刘雪洋 丁建平 刘世侠 苏易礌. 基于Swin Transformer与多尺度特征融合的图像描述方法#br# [J]. 《计算机应用》唯一官方网站, 0, (): 0-0. |
| 阅读次数 | ||||||
|
全文 |
|
|||||
|
摘要 |
|
|||||