


《计算机应用》唯一官方网站 ›› 2025, Vol. 45 ›› Issue (3): 755-764.DOI: 10.11772/j.issn.1001-9081.2024101477
袁成哲1,2, 陈国华2,3( ), 李丁丁2,3, 朱源3, 林荣华2,3, 钟昊2,3, 汤庸3,4
), 李丁丁2,3, 朱源3, 林荣华2,3, 钟昊2,3, 汤庸3,4
收稿日期:2024-10-21
修回日期:2025-02-15
接受日期:2025-02-19
发布日期:2025-03-04
出版日期:2025-03-10
通讯作者:
陈国华
作者简介:袁成哲(1991—),男,湖南汉寿人,讲师,博士,CCF会员,主要研究方向:文本摘要、结构化数据生成、学者知识图谱、数据清洗基金资助:
Chengzhe YUAN1,2, Guohua CHEN2,3(), Dingding LI2,3, Yuan ZHU3, Ronghua LIN2,3, Hao ZHONG2,3, Yong TANG3,4
Received:2024-10-21
Revised:2025-02-15
Accepted:2025-02-19
Online:2025-03-04
Published:2025-03-10
Contact:
Guohua CHEN
About author:YUAN Chengzhe, born in 1991, Ph. D., lecturer. His research interests include text summarization, structured data generation, academic knowledge graph, data cleaning.Supported by:摘要:
针对现有大语言模型(LLM)在跨领域知识处理、实时学术信息更新及输出质量保证方面的局限,提出基于学术社交网络(ASN)的学者LLM——ScholatGPT。ScholatGPT结合知识图谱增强生成(KGAG)与检索增强生成(RAG),以提升精准语义检索与动态知识更新的能力,并通过微调优化以强化学术文本的生成质量。首先,基于学者网(SCHOLAT)关系数据构建学者知识图谱,并利用LLM进行语义增强;其次,提出KGAG检索模型,结合RAG实现多路混合检索,增强LLM的精准检索能力;最后,利用微调技术优化模型,使它在各学术领域的生成质量得到提升。实验结果表明,ScholatGPT在学术问答任务中的精确率达83.2%,相较于GPT-4o和AMiner AI提升了69.4和11.5个百分点,在学者画像、代表作识别和研究领域分类等任务上均表现优异。在回答相关性、连贯性和可读性方面,ScholatGPT取得了稳定且具有竞争力的表现,在专业性与可读性之间实现了较好的平衡。此外,基于ScholatGPT开发的学者智库和学术信息推荐系统等智能应用有效提升了学术信息获取的效率。
中图分类号:
袁成哲, 陈国华, 李丁丁, 朱源, 林荣华, 钟昊, 汤庸. ScholatGPT:面向学术社交网络的大语言模型及智能应用[J]. 计算机应用, 2025, 45(3): 755-764.
Chengzhe YUAN, Guohua CHEN, Dingding LI, Yuan ZHU, Ronghua LIN, Hao ZHONG, Yong TANG. ScholatGPT: a large language model for academic social networks and its intelligent applications[J]. Journal of Computer Applications, 2025, 45(3): 755-764.
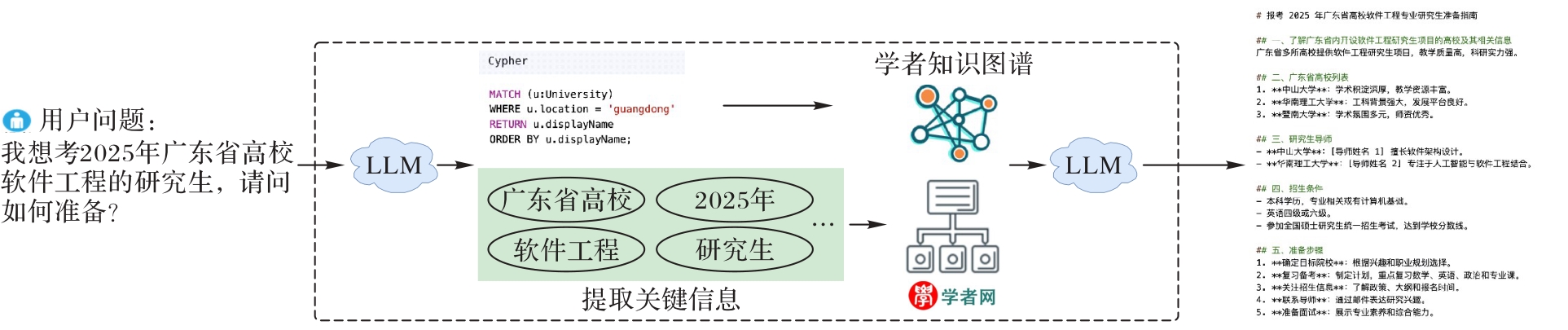
图1 ScholatGPT的工作流程
Fig. 1 Workflow of ScholatGPT
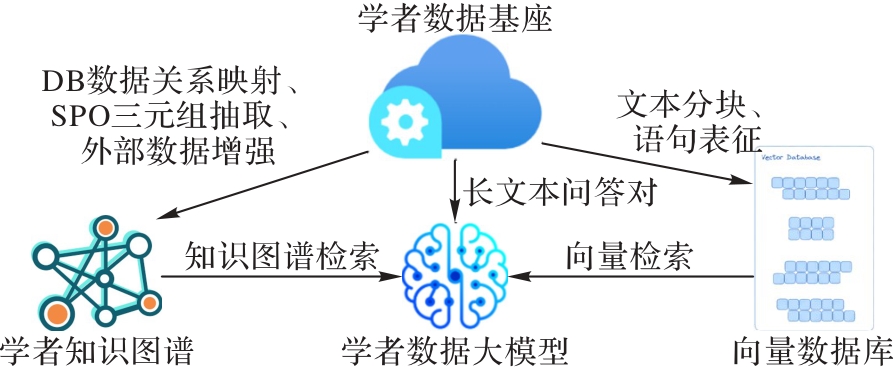
图2 ScholatGPT的整体框架
Fig. 2 Overall framework of ScholatGPT
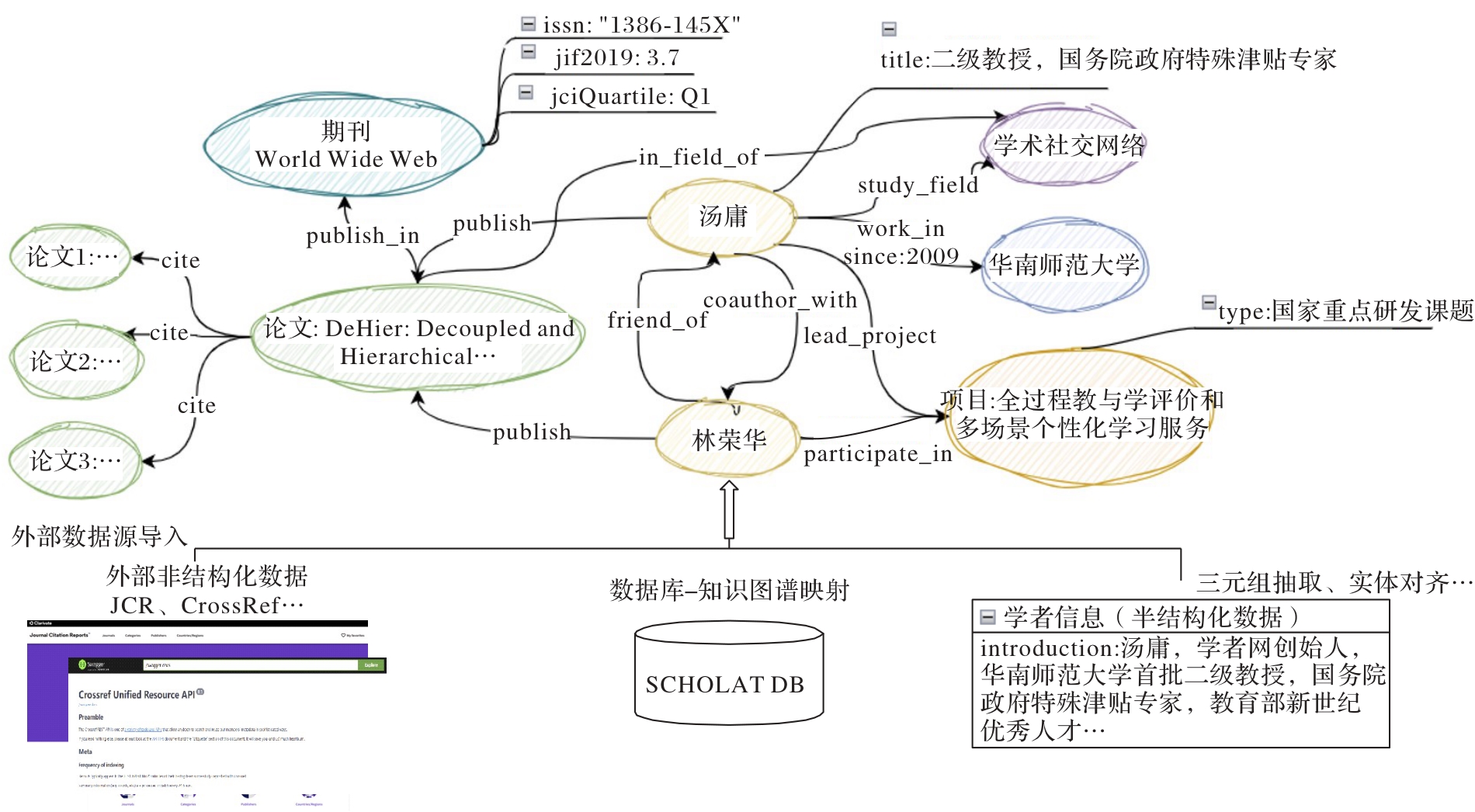
图3 学者知识图谱构建过程
Fig. 3 Construction process of scholar knowledge graph
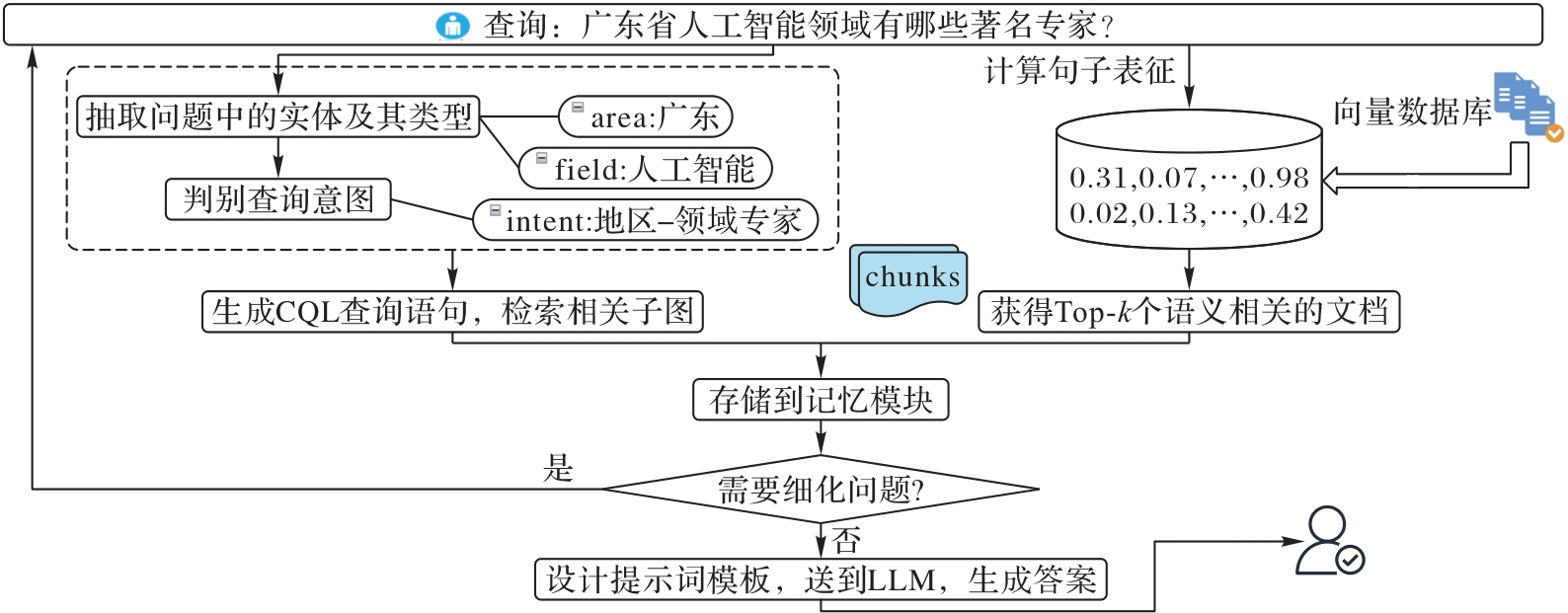
图4 KGAG的思维链
Fig. 4 Chain-of-thought of KGAG
| 问题 | 类别 | 问题数 | 示例问题 |
|---|---|---|---|
| Q1 | 学者简介 | 30 | 介绍张三教授的研究领域和主要成就。 |
| Q2 | 领域代表学者 | 30 | 某领域内的著名学者有哪些?他们的贡献是什么? |
| Q3 | 学术成果推荐 | 30 | 请推荐2023年在自然语言处理领域发表的高影响力论文。 |
| Q4 | 学者合作网络 | 30 | 张三与哪些学者有合作关系?他们共同发表了哪些论文? |
| Q5 | 用户个性化问题 | 30 | 我正在研究图神经网络,请推荐相关的经典论文和领域专家。 |
表1 长文本测试问题数据的示例
Tab. 1 Examples of long text test question data
| 问题 | 类别 | 问题数 | 示例问题 |
|---|---|---|---|
| Q1 | 学者简介 | 30 | 介绍张三教授的研究领域和主要成就。 |
| Q2 | 领域代表学者 | 30 | 某领域内的著名学者有哪些?他们的贡献是什么? |
| Q3 | 学术成果推荐 | 30 | 请推荐2023年在自然语言处理领域发表的高影响力论文。 |
| Q4 | 学者合作网络 | 30 | 张三与哪些学者有合作关系?他们共同发表了哪些论文? |
| Q5 | 用户个性化问题 | 30 | 我正在研究图神经网络,请推荐相关的经典论文和领域专家。 |
| 模型 | 问题 | 精确率/% | 相关性 | 连贯性 | 可读性 |
|---|---|---|---|---|---|
| GPT-4o | Q1 | 2.30 | 4.43 | 3.73 | 4.70 |
| Q2 | 15.20 | 4.30 | 4.00 | 4.67 | |
| Q3 | 17.40 | 4.27 | 4.00 | 4.03 | |
| Q4 | 1.80 | 4.30 | 4.47 | 4.80 | |
| Q5 | 32.40 | 3.83 | 4.60 | 4.83 | |
| 平均 | 13.80 | 4.23 | 4.16 | 4.61 | |
| Llama-3.1-8B | Q1 | 0.00 | 4.70 | 3.73 | 4.30 |
| Q2 | 12.60 | 4.13 | 3.80 | 4.80 | |
| Q3 | 9.80 | 3.80 | 4.33 | 4.57 | |
| Q4 | 3.90 | 4.17 | 3.67 | 3.50 | |
| Q5 | 15.80 | 3.80 | 4.80 | 4.10 | |
| 平均 | 8.40 | 4.12 | 4.07 | 4.25 | |
| GLM4-9b | Q1 | 3.10 | 4.27 | 4.80 | 4.83 |
| Q2 | 13.90 | 4.67 | 3.63 | 4.13 | |
| Q3 | 6.90 | 4.07 | 3.93 | 3.83 | |
| Q4 | 4.30 | 3.73 | 4.67 | 3.73 | |
| Q5 | 19.30 | 3.80 | 4.53 | 4.77 | |
| 平均 | 9.50 | 4.11 | 4.31 | 4.26 | |
| AMiner AI | Q1 | 94.70 | 4.43 | 4.12 | 4.58 |
| Q2 | 72.90 | 4.10 | 3.91 | 4.13 | |
| Q3 | 79.80 | 3.89 | 4.29 | 4.14 | |
| Q4 | 50.30 | 4.11 | 4.12 | 3.81 | |
| Q5 | 60.90 | 3.98 | 4.39 | 4.10 | |
| 平均 | 71.70 | 4.10 | 4.17 | 4.15 | |
| ScholatGPT | Q1 | 78.40 | 3.43 | 4.70 | 4.37 |
| Q2 | 91.30 | 4.67 | 3.70 | 4.14 | |
| Q3 | 85.10 | 4.71 | 4.70 | 4.10 | |
| Q4 | 79.50 | 4.33 | 4.63 | 3.47 | |
| Q5 | 81.90 | 3.77 | 3.57 | 4.53 | |
| 平均 | 83.20 | 4.18 | 4.26 | 4.12 |
表2 不同模型的性能对比结果
Tab. 2 Performance comparison results of different models
| 模型 | 问题 | 精确率/% | 相关性 | 连贯性 | 可读性 |
|---|---|---|---|---|---|
| GPT-4o | Q1 | 2.30 | 4.43 | 3.73 | 4.70 |
| Q2 | 15.20 | 4.30 | 4.00 | 4.67 | |
| Q3 | 17.40 | 4.27 | 4.00 | 4.03 | |
| Q4 | 1.80 | 4.30 | 4.47 | 4.80 | |
| Q5 | 32.40 | 3.83 | 4.60 | 4.83 | |
| 平均 | 13.80 | 4.23 | 4.16 | 4.61 | |
| Llama-3.1-8B | Q1 | 0.00 | 4.70 | 3.73 | 4.30 |
| Q2 | 12.60 | 4.13 | 3.80 | 4.80 | |
| Q3 | 9.80 | 3.80 | 4.33 | 4.57 | |
| Q4 | 3.90 | 4.17 | 3.67 | 3.50 | |
| Q5 | 15.80 | 3.80 | 4.80 | 4.10 | |
| 平均 | 8.40 | 4.12 | 4.07 | 4.25 | |
| GLM4-9b | Q1 | 3.10 | 4.27 | 4.80 | 4.83 |
| Q2 | 13.90 | 4.67 | 3.63 | 4.13 | |
| Q3 | 6.90 | 4.07 | 3.93 | 3.83 | |
| Q4 | 4.30 | 3.73 | 4.67 | 3.73 | |
| Q5 | 19.30 | 3.80 | 4.53 | 4.77 | |
| 平均 | 9.50 | 4.11 | 4.31 | 4.26 | |
| AMiner AI | Q1 | 94.70 | 4.43 | 4.12 | 4.58 |
| Q2 | 72.90 | 4.10 | 3.91 | 4.13 | |
| Q3 | 79.80 | 3.89 | 4.29 | 4.14 | |
| Q4 | 50.30 | 4.11 | 4.12 | 3.81 | |
| Q5 | 60.90 | 3.98 | 4.39 | 4.10 | |
| 平均 | 71.70 | 4.10 | 4.17 | 4.15 | |
| ScholatGPT | Q1 | 78.40 | 3.43 | 4.70 | 4.37 |
| Q2 | 91.30 | 4.67 | 3.70 | 4.14 | |
| Q3 | 85.10 | 4.71 | 4.70 | 4.10 | |
| Q4 | 79.50 | 4.33 | 4.63 | 3.47 | |
| Q5 | 81.90 | 3.77 | 3.57 | 4.53 | |
| 平均 | 83.20 | 4.18 | 4.26 | 4.12 |
| 基座模型 | 不同检索方式下的精确率 | ||
|---|---|---|---|
| none | RAG | KGAG | |
| Qwen2.5 | 10.9 | 81.5 | 82.9 |
| Qwen2.5(Fine-tuned) | 58.1 | 81.7 | 83.2 |
表3 消融实验结果对比 (%)
Tab. 3 Comparison of ablation experiment results
| 基座模型 | 不同检索方式下的精确率 | ||
|---|---|---|---|
| none | RAG | KGAG | |
| Qwen2.5 | 10.9 | 81.5 | 82.9 |
| Qwen2.5(Fine-tuned) | 58.1 | 81.7 | 83.2 |

图5 基于ScholatGPT的智能应用框架
Fig. 5 Intelligent application framework based on ScholatGPT
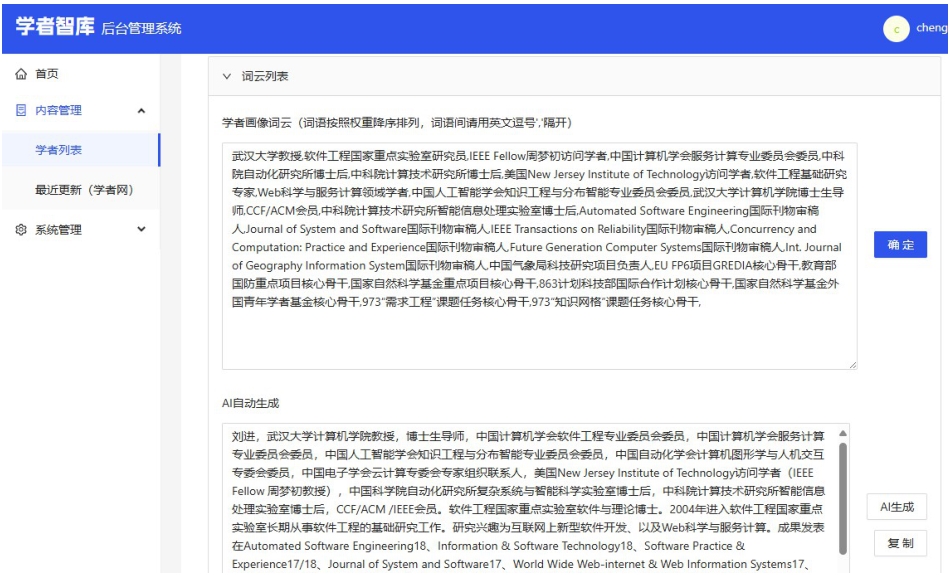
图6 基于ScholatGPT的画像标签云生成
Fig. 6 Generation of profile tag cloud based on ScholatGPT
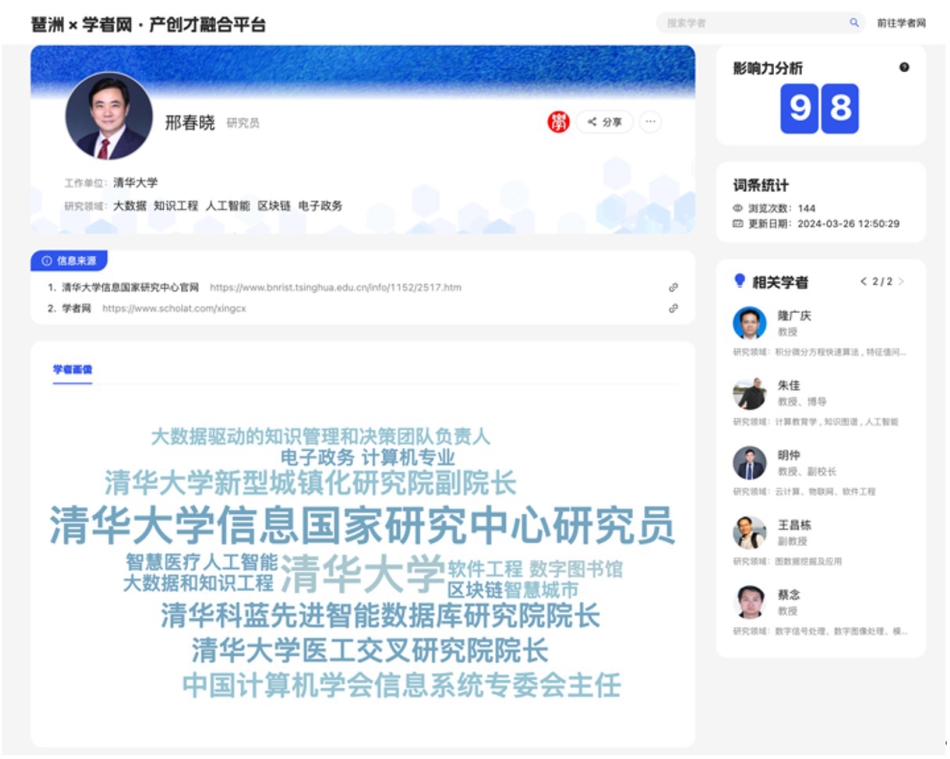
图7 基于ScholatGPT的学者画像
Fig. 7 Scholar profile based on ScholatGPT
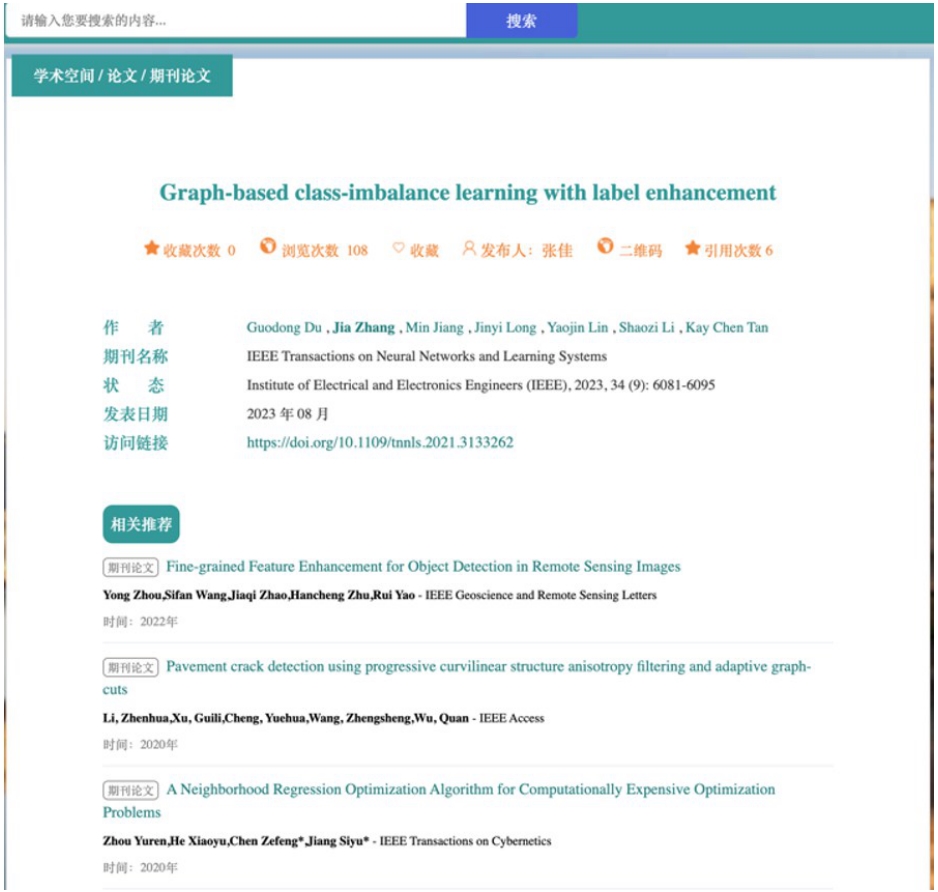
图8 个性化学术论文推荐
Fig. 8 Personalized academic paper recommendations
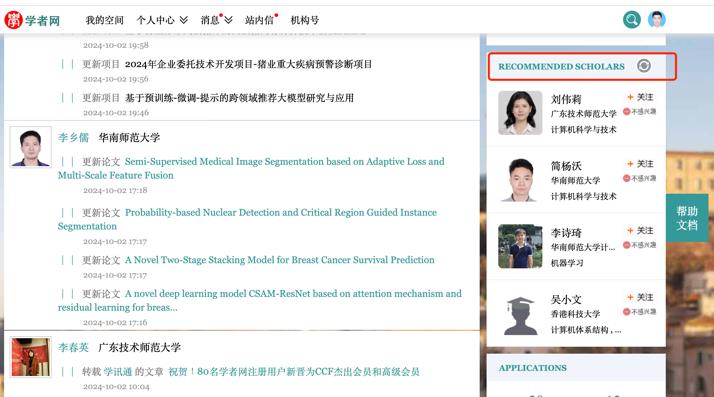
图9 个性化学者推荐
Fig. 9 Personalized scholar recommendation
| 1 | 徐月梅,胡玲,赵佳艺,等. 大语言模型的技术应用前景与风险挑战[J]. 计算机应用, 2024, 44(6):1655-1662. |
| XU Y M, HU L, ZHAO J Y, et al. Technology application prospects and risk challenges of large language models [J]. Journal of Computer Applications, 2024, 44(6): 1655-1662. | |
| 2 | CHENG D, HUANG S, WEI F. Adapting large language models via reading comprehension [EB/OL]. [2024-09-22]. . |
| 3 | RADFORD A, WU J, CHILD R, et al. Language models are unsupervised multitask learners [EB/OL]. [2023-09-22]. . |
| 4 | CADEDDU A, CHESSA A, DE LEO V, et al. A comparative analysis of knowledge injection strategies for large language models in the scholarly domain [J]. Engineering Applications of Artificial Intelligence, 2024, 133(Pt B): No.108166. |
| 5 | PAN S, LUO L, WANG Y, et al. Unifying large language models and knowledge graphs: a roadmap [J]. IEEE Transactions on Knowledge and Data Engineering, 2024, 36(7):3580-3599. |
| 6 | SANMARTIN D. KG-RAG: bridging the gap between knowledge and creativity [EB/OL]. [2024-06-18]. . |
| 7 | VASWANI A, SHAZEER N, PARMAR N, et al. Attention is all you need [C]// Proceedings of the 31st International Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2017: 6000-6010. |
| 8 | MIN B, ROSS H, SULEM E, et al. Recent advances in natural language processing via large pre-trained language models: a survey[J]. ACM Computing Surveys, 2024, 56(2): No.30. |
| 9 | BROWN T B, MANN B, RYDER N, et al. Language models are few-shot learners [C]// Proceedings of the 34th International Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2020: 1877-1901. |
| 10 | OpenAI. GPT-4 technical report [EB/OL]. [2023-08-28].. |
| 11 | Meta. Introducing Meta LLaMA 3: the most capable openly available LLM to date [EB/OL]. [2024-09-30]. . |
| 12 | REN X, ZHOU P, MENG X, et al. PanGu-Σ: towards trillion parameter language model with sparse heterogeneous computing [R/OL]. [2024-05-04]. . |
| 13 | Team GLM. ChatGLM: a family of large language models from GLM-130B to GLM-4 All Tools [EB/OL]. [2024-08-06]. . |
| 14 | HU L, LIU Z, ZHAO Z, et al. A survey of knowledge enhanced pre-trained language models [J]. IEEE Transactions on Knowledge and Data Engineering, 2024, 36(4):1413-1430. |
| 15 | LIN R, TANG F, HE C, et al. DIRS-KG: a KG-enhanced interactive recommender system based on deep reinforcement learning [J]. World Wide Web, 2023, 26(5):2471-2493. |
| 16 | FAN W, DING Y, NING L, et al. A survey on RAG meeting LLMs: towards retrieval-augmented large language models [C]// Proceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining. New York: ACM, 2024: 6491-6501. |
| 17 | RAO J, LIN J. RAMO: retrieval-augmented generation for enhancing MOOCs recommendations [C]// Joint Proceedings of the Human-Centric eXplainable AI in Education and the Leveraging Large Language Models for Next Generation Educational Technologies Workshops Co-located with 17th International Conference on Educational Data Mining. Aachen: CEUR-WS.org, 2024: No.9. |
| 18 | WU S, İRSOY O, LU S, et al. BloombergGPT: a large language model for finance [EB/OL]. [2024-10-06]. . |
| 19 | XIONG H, WANG S, ZHU Y, et al. DoctorGLM: fine-tuning your Chinese doctor is not a herculean task [EB/OL]. [2023-07-30]. . |
| 20 | SINGHAL K, TU T, GOTTWEIS J, et al. Towards expert-level medical question answering with large language models [EB/OL]. [2023-09-06]. . |
| 21 | HUANG Q, TAO M, ZHANG C, et al. Lawyer LLaMA: enhancing LLMs with legal knowledge [EB/OL]. [2024-05-16].. |
| 22 | ZHANG Q, CHEN M, BUKHARIN A, et al. AdaLoRA: adaptive budget allocation for parameter-efficient fine-tuning [EB/OL]. [2024-03-10].. |
| 23 | ZHANG R, HAN J, ZHOU A, et al. LLaMA-Adapter: efficient fine-tuning of language models with zero-init attention [EB/OL]. [2024-10-16]. . |
| 24 | RAM O, LEVINE Y, DALMEDIGOS I, et al. In-context retrieval-augmented language models [J]. Transactions of the Association for Computational Linguistics, 2023, 11: 1316-1331. |
| 25 | WANG L, YANG N, HUANG X, et al. Large search model: redefining search stack in the era of LLMs [J]. ACM SIGIR Forum, 2023, 57(2): No.23. |
| 26 | CHEN H T, XU F, ARORA S, et al. Understanding retrieval augmentation for long-form question answering [EB/OL]. [2024-10-12]. . |
| 27 | SHI F, CHEN X, MISRA K, et al. Large language models can be easily distracted by irrelevant context [C]// Proceedings of the 40th International Conference on Machine Learning. New York: JMLR.org, 2023: 31210-31227. |
| 28 | JI S, PAN S, CAMBRIA E, et al. A survey on knowledge graphs: representation, acquisition, and applications [J]. IEEE Transactions on Neural Networks and Learning Systems, 2021, 33(2): 494-514. |
| 29 | HU S, ZOU L, YU J X, et al. Answering natural language questions by subgraph matching over knowledge graphs [J]. IEEE Transactions on Knowledge and Data Engineering, 2018, 30(5): 824-837. |
| 30 | LV S, GUO D, XU J, et al. Graph-based reasoning over heterogeneous external knowledge for commonsense question answering [C]// Proceedings of the 34th AAAI Conference on Artificial Intelligence. Palo Alto: AAAI Press, 2020: 8449-8456. |
| 31 | SUN J, XU C, TANG L, et al. Think-on-graph: deep and responsible reasoning of large language model on knowledge graph[EB/OL]. [2024-07-07]. . |
| 32 | WANG Y, LIPKA N, ROSSI R A, et al. Knowledge graph prompting for multi-document question answering [C]// Proceedings of the 38th AAAI Conference on Artificial Intelligence. Palo Alto: AAAI Press, 2024: 19206-19214. |
| 33 | ROSSETTI G, STELLA M, CAZABET R, et al. Y Social: an LLM-powered social media digital twin [EB/OL]. [2024-11-09].. |
| 34 | JIANG J, FERRARA E. Social-LLM: modeling user behavior at scale using language models and social network data [EB/OL]. [2024-05-07]. . |
| 35 | HAO G, WU J, PAN Q, et al. Quantifying the uncertainty of LLM hallucination spreading in complex adaptive social networks [J]. Scientific Reports, 2024, 14: No.16375. |
| 36 | STERGIOPOULOS V, TSIANAKA T, TOUSIDOU E. AMiner citation-data preprocessing for recommender systems on scientific publications [C]// Proceedings of the 25th Pan-Hellenic Conference on Informatics. New York: ACM, 2021: 23-27. |
| 37 | Team Qwen. Qwen2.5 technical report [R/OL]. [2025-02-17]. . |
| 38 | MITCHELL E, RAFAILOV R, SHARMA A, et al. An emulator for fine-tuning large language models using small language models[EB/OL]. [2024-01-23]. . |
| 39 | ZENG J, HUANG R, MALIK W, et al. Large language models for social networks: applications, challenges, and solutions [EB/OL]. [2024-01-23].. |
| 40 | YUAN C, HE Y, LIN R, et al. Graph embedding for scholar recommendation in academic social networks [J]. Frontiers in Physics, 2021, 9: No.768006. |
| [1] | 徐月梅, 叶宇齐, 何雪怡. 大语言模型的偏见挑战:识别、评估与去除[J]. 《计算机应用》唯一官方网站, 2025, 45(3): 697-708. |
| [2] | 曹鹏, 温广琪, 杨金柱, 陈刚, 刘歆一, 季学纯. 面向测试用例生成的大模型高效微调方法[J]. 《计算机应用》唯一官方网站, 2025, 45(3): 725-731. |
| [3] | 秦小林, 古徐, 李弟诚, 徐海文. 大语言模型综述与展望[J]. 《计算机应用》唯一官方网站, 2025, 45(3): 685-696. |
| [4] | 何静, 沈阳, 谢润锋. 大语言模型幻觉现象的识别与优化[J]. 《计算机应用》唯一官方网站, 2025, 45(3): 709-714. |
| [5] | 王猛, 张大千, 周冰艳, 马倩影, 吕继东. 基于时序知识图谱补全的CTCS-3级列控车载接口设备故障诊断方法[J]. 《计算机应用》唯一官方网站, 2025, 45(2): 677-684. |
| [6] | 程子栋, 李鹏, 朱枫. 物联网威胁情报知识图谱中潜在关系的挖掘[J]. 《计算机应用》唯一官方网站, 2025, 45(1): 24-31. |
| [7] | 李瑞, 李贯峰, 胡德洲, 高文馨. 融合路径与子图特征的知识图谱多跳推理模型[J]. 《计算机应用》唯一官方网站, 2025, 45(1): 32-39. |
| [8] | 吕学强, 王涛, 游新冬, 徐戈. 层次融合多元知识的命名实体识别框架——HTLR[J]. 《计算机应用》唯一官方网站, 2025, 45(1): 40-47. |
| [9] | 薛桂香, 王辉, 周卫峰, 刘瑜, 李岩. 基于知识图谱和时空扩散图卷积网络的港口交通流量预测[J]. 《计算机应用》唯一官方网站, 2024, 44(9): 2952-2957. |
| [10] | 武杰, 张安思, 吴茂东, 张仪宗, 王从宝. 知识图谱在装备故障诊断领域的研究与应用综述[J]. 《计算机应用》唯一官方网站, 2024, 44(9): 2651-2659. |
| [11] | 赵宇博, 张丽萍, 闫盛, 侯敏, 高茂. 基于改进分段卷积神经网络和知识蒸馏的学科知识实体间关系抽取[J]. 《计算机应用》唯一官方网站, 2024, 44(8): 2421-2429. |
| [12] | 李健京, 李贯峰, 秦飞舟, 李卫军. 基于不确定知识图谱嵌入的多关系近似推理模型[J]. 《计算机应用》唯一官方网站, 2024, 44(6): 1751-1759. |
| [13] | 林欣蕊, 王晓菲, 朱焱. 基于局部扩展社区发现的学术异常引用群体检测[J]. 《计算机应用》唯一官方网站, 2024, 44(6): 1855-1861. |
| [14] | 于右任, 张仰森, 蒋玉茹, 黄改娟. 融合多粒度语言知识与层级信息的中文命名实体识别模型[J]. 《计算机应用》唯一官方网站, 2024, 44(6): 1706-1712. |
| [15] | 徐月梅, 胡玲, 赵佳艺, 杜宛泽, 王文清. 大语言模型的技术应用前景与风险挑战[J]. 《计算机应用》唯一官方网站, 2024, 44(6): 1655-1662. |
| 阅读次数 | ||||||
|
全文 |
|
|||||
|
摘要 |
|
|||||