


《计算机应用》唯一官方网站 ›› 2025, Vol. 45 ›› Issue (11): 3564-3572.DOI: 10.11772/j.issn.1001-9081.2024111567
• 人工智能 • 上一篇
刘爽( ), 罗桂君, 孟佳娜
), 罗桂君, 孟佳娜
收稿日期:2024-11-05
修回日期:2025-03-16
接受日期:2025-03-20
发布日期:2025-04-02
出版日期:2025-11-10
通讯作者:
刘爽
作者简介:罗桂君(2000—),男,湖南衡阳人,硕士研究生,主要研究方向:信息抽取、自然语言处理基金资助:
Shuang LIU(), Guijun LUO, Jiana MENG
Received:2024-11-05
Revised:2025-03-16
Accepted:2025-03-20
Online:2025-04-02
Published:2025-11-10
Contact:
Shuang LIU
About author:LUO Guijun, born in 2000, M. S. candidate. His research interests include information extraction, natural language processing.Supported by:摘要:
实体和关系抽取(ERE)通常采用流水线的方式进行处理,但这种流水线方法仅依赖于前一个任务的输出,导致命名实体识别和关系抽取之间出现信息交互问题,且容易引发误差传播问题。针对以上问题,提出一种面向实体和关系抽取的记忆增强模型(MEERE)。该模型引入类似记忆的机制,使每个任务不仅能利用前一任务的输出,还能反向影响前一任务,从而捕获实体和关系间的复杂交互。为进一步减轻误差传播,同时引入实体跨度筛选机制。该机制通过在联合模块中动态地筛选和验证实体跨度,确保只有高质量的实体被用于关系抽取,从而提升模型的鲁棒性和准确性。最后利用表格解码方式处理关系重叠问题。在3个广泛使用的基准数据集(ACE05、SciERC和CoNLL04)上的实验结果表明,MEERE在ERE任务上表现出了显著的优势。与Tab-Seq在CoNLL04数据集上相比,MEERE在命名实体识别和关系抽取上的性能都有显著提升,命名实体识别的F1值提升了0.5个百分点,关系严格评估的F1值提升了3.0个百分点;相较于PURE-F模型,MEERE实现了不少于9倍的加速效果,并且关系抽取性能更佳。这些结果验证了所提出的记忆增强模型在探索实体和关系交互作用方面的有效性。
中图分类号:
刘爽, 罗桂君, 孟佳娜. 基于记忆增强和跨度筛选的实体和关系联合抽取模型[J]. 计算机应用, 2025, 45(11): 3564-3572.
Shuang LIU, Guijun LUO, Jiana MENG. Joint extraction model of entities and relations based on memory enhancement and span screening[J]. Journal of Computer Applications, 2025, 45(11): 3564-3572.

图1 SciERC数据集的示例
Fig. 1 Example of ScIERC dataset
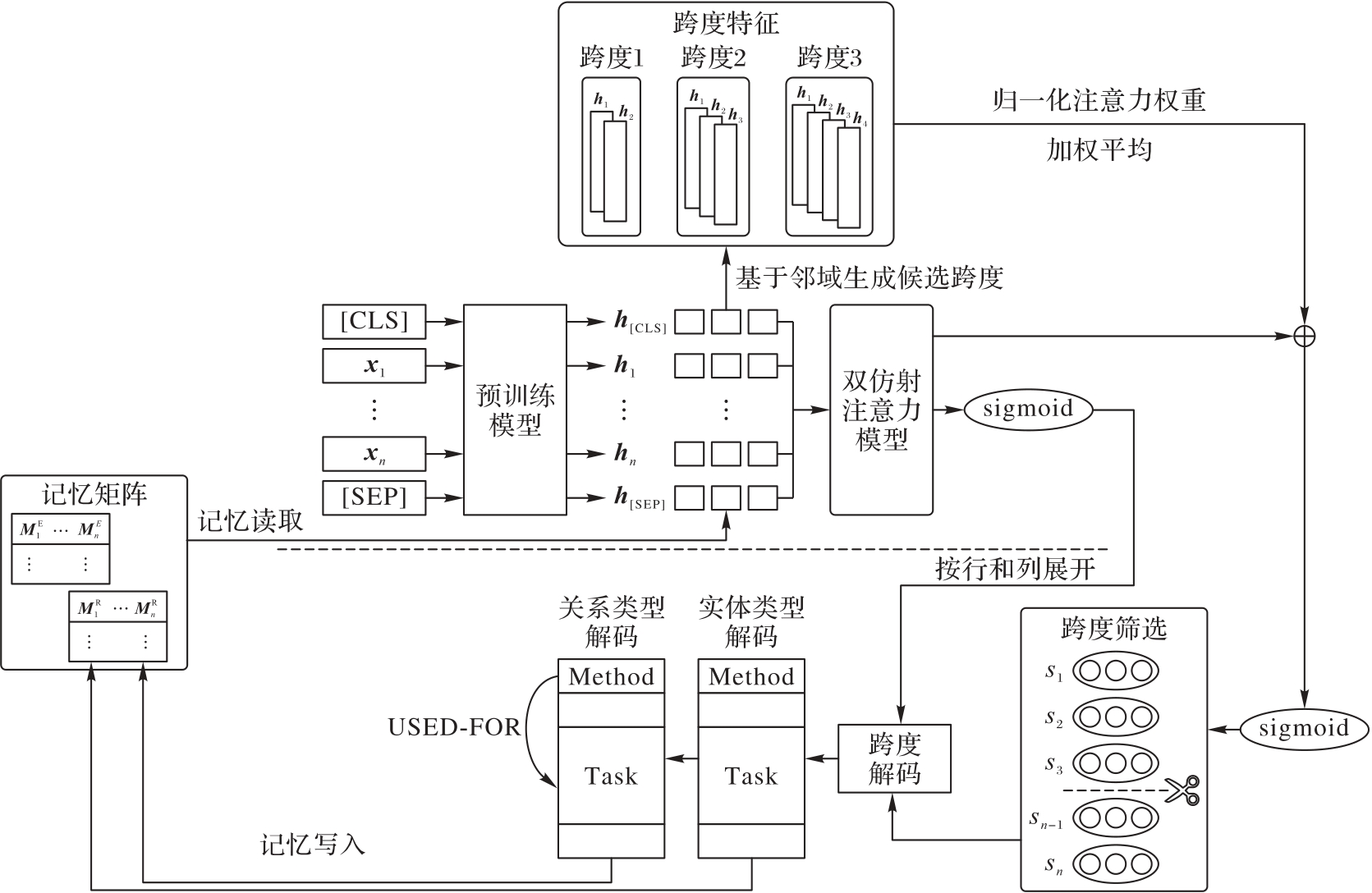
图2 模型总体架构
Fig. 2 Overall architecture of model
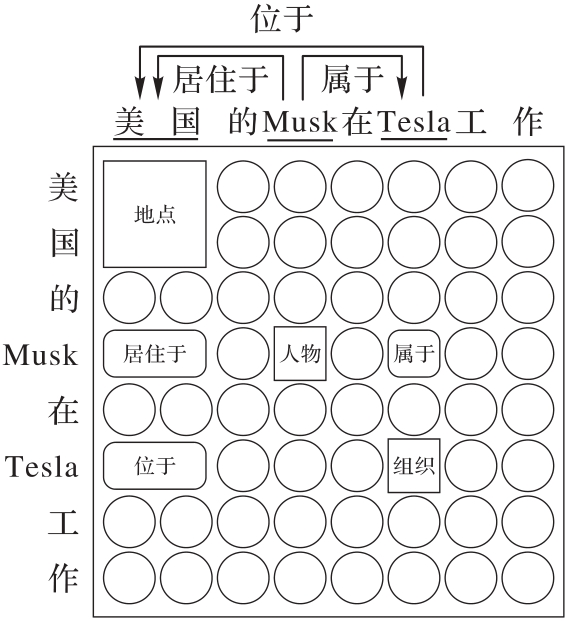
图3 解码表格示例
Fig. 3 Decoding table example
| 数据集 | 样本数 | 实体数 | 关系数 | ||
|---|---|---|---|---|---|
| 训练集 | 验证集 | 测试集 | |||
| ACE05 | 10 051 | 2 424 | 2 050 | 7 | 6 |
| SciERC | 1 864 | 275 | 551 | 6 | 7 |
| CoNLL04 | 922 | 231 | 288 | 4 | 5 |
表1 数据集的统计信息
Tab. 1 Statistics of datasets
| 数据集 | 样本数 | 实体数 | 关系数 | ||
|---|---|---|---|---|---|
| 训练集 | 验证集 | 测试集 | |||
| ACE05 | 10 051 | 2 424 | 2 050 | 7 | 6 |
| SciERC | 1 864 | 275 | 551 | 6 | 7 |
| CoNLL04 | 922 | 231 | 288 | 4 | 5 |
| 设备名 | 环境配置 |
|---|---|
| Ubuntu20.04 | |
| CPU | 15 vCPU Intel Xeon Platinum 8474C |
| GPU | GeForce RTX 3090 |
| 内存 | 80 GB |
| Python | 3.8.10 |
| 深度学习框架 | PyTorch1.11.0+CU113 |
表2 实验环境
Tab. 2 Experimental environment
| 设备名 | 环境配置 |
|---|---|
| Ubuntu20.04 | |
| CPU | 15 vCPU Intel Xeon Platinum 8474C |
| GPU | GeForce RTX 3090 |
| 内存 | 80 GB |
| Python | 3.8.10 |
| 深度学习框架 | PyTorch1.11.0+CU113 |
| 参数 | ACE05 | SciERC | CoNLL04 |
|---|---|---|---|
| 0.000 05 | 0.000 05 | 0.000 05 | |
| 训练次数 | 200 | 300 | 200 |
| 批次大小 | 16 | 16 | 16 |
| 丢弃值 | 0.4 | 0.4 | 0.4 |
| 梯度修剪值 | 5.0 | 5.0 | 5.0 |
| 权重衰减率 | 0.000 01 | 0.000 01 | 0.000 01 |
| 早停轮数 | 30 | 30 | 30 |
| 隐藏层大小 | 150 | 150 | 150 |
| 预热率 | 0.2 | 0.2 | 0.2 |
| 跨度系数 | 0.5 | 0.5 | 0.5 |
| 上下文窗口大小 | 300 | 200 | 400 |
| 跨度长度限制 | 8 | 12 | 8 |
| 距离阈值 | 1.4 | 1.4 | 1.2 |
表3 实验参数设置
Tab. 3 Experimental parameter setting
| 参数 | ACE05 | SciERC | CoNLL04 |
|---|---|---|---|
| 0.000 05 | 0.000 05 | 0.000 05 | |
| 训练次数 | 200 | 300 | 200 |
| 批次大小 | 16 | 16 | 16 |
| 丢弃值 | 0.4 | 0.4 | 0.4 |
| 梯度修剪值 | 5.0 | 5.0 | 5.0 |
| 权重衰减率 | 0.000 01 | 0.000 01 | 0.000 01 |
| 早停轮数 | 30 | 30 | 30 |
| 隐藏层大小 | 150 | 150 | 150 |
| 预热率 | 0.2 | 0.2 | 0.2 |
| 跨度系数 | 0.5 | 0.5 | 0.5 |
| 上下文窗口大小 | 300 | 200 | 400 |
| 跨度长度限制 | 8 | 12 | 8 |
| 距离阈值 | 1.4 | 1.4 | 1.2 |
| 模型 | 编码器 | ACE05 | SciERC | CoNLL04 | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Ent | Rel | Rel+ | Ent | Rel | Rel+ | Ent | Rel | Rel+ | ||
| Joint w/ Global | — | 80.8 | 52.1 | 49.5 | — | — | — | — | — | — |
| SPtree | LSTM | 83.4 | — | 55.6 | — | — | — | — | — | — |
| DYGIE | ELMO | 88.4 | 63.2 | — | 65.2 | 41.6 | — | — | — | — |
| Multi‑turn QA | BERTL | 84.8 | — | 60.2 | — | — | — | — | — | — |
| OneIE | 88.8 | 67.5 | — | — | — | — | — | — | — | |
| DYGIE++ | BERTB/ SciBERT | 88.6 | 63.4 | — | — | — | — | — | — | — |
| TANL | 89.0 | — | 63.7 | — | — | — | 90.3 | — | 70.0 | |
| PURE‑F | 90.1 | 67.7 | 64.8 | 68.9 | 50.1 | 36.8 | — | — | — | |
| PURE‑A | — | 66.5 | — | — | 48.1 | — | — | — | — | |
| MEERE | 89.2 | 67.9 | 65.0 | 69.6 | 50.9 | 38.9 | 89.8 | 75.7 | 73.1 | |
| Tab‑Seq | ALBERT/ SciBERT | 89.5 | — | 64.3 | — | — | — | 90.1 | 73.8 | 73.6 |
| PFN | 89.0 | — | 66.8 | 66.8 | — | 38.4 | — | — | — | |
| UniRE | 90.0 | — | 66.0 | 68.4 | — | 36.9 | — | — | — | |
| TablERT | 87.8 | 65.0 | 61.8 | — | — | — | 90.5 | 73.2 | 72.2 | |
| MEERE | 89.9 | 68.6 | 67.0 | 69.6 | 50.9 | 38.9 | 90.6 | 77.0 | 76.6 | |
表4 在ACE05、SciERC和CoNLL04测试集上的F1值比较 ( %)
Tab. 4 Comparison of F1 values on ACE05, SciERC, and CoNLL04 test sets
| 模型 | 编码器 | ACE05 | SciERC | CoNLL04 | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Ent | Rel | Rel+ | Ent | Rel | Rel+ | Ent | Rel | Rel+ | ||
| Joint w/ Global | — | 80.8 | 52.1 | 49.5 | — | — | — | — | — | — |
| SPtree | LSTM | 83.4 | — | 55.6 | — | — | — | — | — | — |
| DYGIE | ELMO | 88.4 | 63.2 | — | 65.2 | 41.6 | — | — | — | — |
| Multi‑turn QA | BERTL | 84.8 | — | 60.2 | — | — | — | — | — | — |
| OneIE | 88.8 | 67.5 | — | — | — | — | — | — | — | |
| DYGIE++ | BERTB/ SciBERT | 88.6 | 63.4 | — | — | — | — | — | — | — |
| TANL | 89.0 | — | 63.7 | — | — | — | 90.3 | — | 70.0 | |
| PURE‑F | 90.1 | 67.7 | 64.8 | 68.9 | 50.1 | 36.8 | — | — | — | |
| PURE‑A | — | 66.5 | — | — | 48.1 | — | — | — | — | |
| MEERE | 89.2 | 67.9 | 65.0 | 69.6 | 50.9 | 38.9 | 89.8 | 75.7 | 73.1 | |
| Tab‑Seq | ALBERT/ SciBERT | 89.5 | — | 64.3 | — | — | — | 90.1 | 73.8 | 73.6 |
| PFN | 89.0 | — | 66.8 | 66.8 | — | 38.4 | — | — | — | |
| UniRE | 90.0 | — | 66.0 | 68.4 | — | 36.9 | — | — | — | |
| TablERT | 87.8 | 65.0 | 61.8 | — | — | — | 90.5 | 73.2 | 72.2 | |
| MEERE | 89.9 | 68.6 | 67.0 | 69.6 | 50.9 | 38.9 | 90.6 | 77.0 | 76.6 | |
| 设置 | ACE05 | SciERC | ||
|---|---|---|---|---|
| Ent | Rel+ | Ent | Rel+ | |
| MEERE | 89.9 | 67.0 | 69.6 | 38.9 |
| 移除记忆模块 | 88.5 | 64.9 | 66.7 | 36.0 |
| 移除跨度筛选模块 | 88.2 | 65.9 | 68.4 | 38.2 |
| 移除跨句子上下文 | 89.9 | 65.8 | 69.5 | 38.8 |
| 移除双向关系 | 89.8 | 65.7 | 69.3 | 38.4 |
表5 在ACE05和SciERC测试集上移除不同组件的F1值 ( %)
Tab. 5 F1 values with different components removed on ACE 05 and SciERC test sets
| 设置 | ACE05 | SciERC | ||
|---|---|---|---|---|
| Ent | Rel+ | Ent | Rel+ | |
| MEERE | 89.9 | 67.0 | 69.6 | 38.9 |
| 移除记忆模块 | 88.5 | 64.9 | 66.7 | 36.0 |
| 移除跨度筛选模块 | 88.2 | 65.9 | 68.4 | 38.2 |
| 移除跨句子上下文 | 89.9 | 65.8 | 69.5 | 38.8 |
| 移除双向关系 | 89.8 | 65.7 | 69.3 | 38.4 |
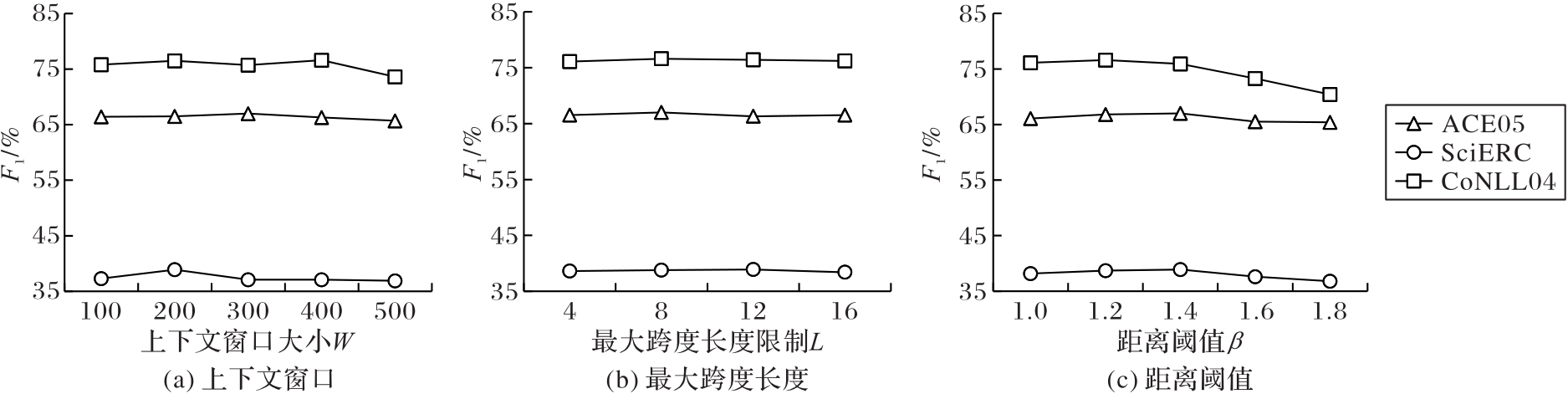
图4 不同设置对模型性能的影响
Fig. 4 Influence of different settings on model performance
| 模型 | ACE05 | SciERC | ||
|---|---|---|---|---|
| Rel(F1)/% | 每秒处理的 句子数 | Rel(F1)/% | 每秒处理的 句子数 | |
| PURE-F | 67.7 | 14.7 | 50.1 | 19.9 |
| PURE-A | 66.5 | 237.6 | 48.8 | 194.7 |
| MEERE | 67.9 | 220.1 | 50.9 | 185.5 |
表6 不同模型在ACE05和SciERC测试集上的F1值和速度比较
Tab. 6 F1 value and speed comparisons of different models on ACE05 and SciERC test sets
| 模型 | ACE05 | SciERC | ||
|---|---|---|---|---|
| Rel(F1)/% | 每秒处理的 句子数 | Rel(F1)/% | 每秒处理的 句子数 | |
| PURE-F | 67.7 | 14.7 | 50.1 | 19.9 |
| PURE-A | 66.5 | 237.6 | 48.8 | 194.7 |
| MEERE | 67.9 | 220.1 | 50.9 | 185.5 |
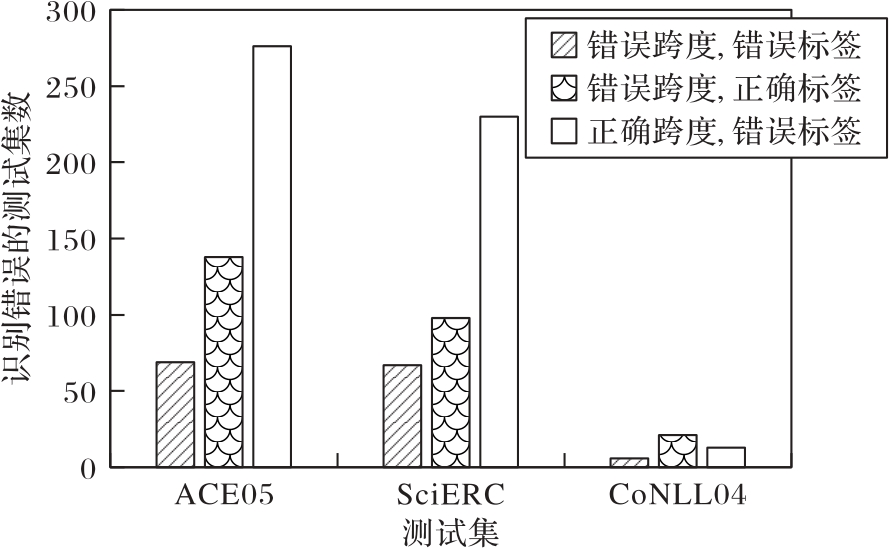
图5 实体识别中的错误分析
Fig. 5 Error analysis in entity recognition

图6 SciERC测试集的案例
Fig. 6 Case of SciERC test set
| [1] | 鄂海红,张文静,肖思琪,等. 深度学习实体关系抽取研究综述[J]. 软件学报, 2019, 30(6):1793-1818. |
| E H H, ZHANG W J, XIAO S Q, et al. Survey of entity relationship extraction based on deep learning[J]. Journal of Software, 2019, 30(6): 1793-1818. | |
| [2] | LUAN Y, HE L, OSTENDORF M, et al. Multi-task identification of entities, relations, and coreference for scientific knowledge graph construction[C]// Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing. Stroudsburg: ACL, 2018: 3219-3232. |
| [3] | LIN Y, SHEN S, LIU Z, et al. Neural relation extraction with selective attention over instances[C]// Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Stroudsburg: ACL, 2016: 2124-2133. |
| [4] | YAN Z, YANG S, LIU W, et al. Joint entity and relation extraction with span pruning and hypergraph neural networks[C]// Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing. Stroudsburg: ACL, 2023: 7512-7526. |
| [5] | ZHAO T, YAN Z, CAO Y, et al. Asking effective and diverse questions: a machine reading comprehension based framework for joint entity-relation extraction[C]// Proceedings of the 29th International Joint Conferences on Artificial Intelligence. California: IJCAI.org, 2020: 3948-3954. |
| [6] | LI X, YIN F, SUN Z, et al. Entity-relation extraction as multi-turn question answering[C]// Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics. Stroudsburg: ACL,2019: 1340-1350. |
| [7] | TAKANOBU R, ZHANG T, LIU J, et al. A hierarchical framework for relation extraction with reinforcement learning[C]// Proceedings of the 33rd AAAI Conference on Artificial Intelligence. Palo Alto: AAAI Press, 2019: 7072-7079. |
| [8] | YE D, LIN Y, LI P, et al. Packed levitated marker for entity and relation extraction[C]// Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Stroudsburg: ACL, 2022: 4904-4917. |
| [9] | YAN Z, JIA Z, TU K. An empirical study of pipeline vs. joint approaches to entity and relation extraction[C]// Proceedings of the 2nd Conference of the Asia-Pacific Chapter of the Association for Computational Linguistics and the 12th International Joint Conference on Natural Language Processing (Volume 2: Short Papers). Stroudsburg: ACL, 2022: 437-443. |
| [10] | MIWA M, BANSAL M. End-to-end relation extraction using LSTMs on sequences and tree structures[C]// Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Stroudsburg: ACL, 2016: 1105-1116. |
| [11] | WANG J, LU W. Two are better than one: joint entity and relation extraction with table-sequence encoders[C]// Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing. Stroudsburg: ACL, 2020: 1706-1721. |
| [12] | WANG Y, SUN C, WU Y, et al. UniRE: a unified label space for entity relation extraction[C]// Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers). Stroudsburg: ACL, 2021: 220-231. |
| [13] | GUPTA P, SCHÜTZE H, ANDRASSY B. Table filling multi-task recurrent neural network for joint entity and relation extraction[C]// Proceedings of the 26th International Conference on Computational Linguistics: Technical Papers. [S.l.]: The COLING 2016 Organizing Committee, 2016: 2537-2547. |
| [14] | SUN C, GONG Y, WU Y, et al. Joint type inference on entities and relations via graph convolutional networks[C]// Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics. Stroudsburg: ACL, 2019: 1361-1370. |
| [15] | NGUYEN M V, LAI V D, NGUYEN T H. Cross-task instance representation interactions and label dependencies for joint information extraction with graph convolutional networks[C]// Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. Stroudsburg: ACL, 2021: 27-38. |
| [16] | YANG B, CARDIE C. Joint inference for fine-grained opinion extraction[C]// Proceedings of the 51st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Stroudsburg: ACL, 2013: 1640-1649. |
| [17] | KATIYAR A, CARDIE C. Investigating LSTMs for joint extraction of opinion entities and relations[C]// Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Stroudsburg: ACL, 2016: 919-929. |
| [18] | WADDEN D, WENNBERG U, LUAN Y, et al. Entity, relation, and event extraction with contextualized span representations [C]// Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP). Stroudsburg: ACL, 2019: 5784-5789. |
| [19] | SHEN Y, MA X, TANG Y, et al. A trigger-sense memory flow framework for joint entity and relation extraction[C]// Proceedings of the Web Conference 2021. New York: ACM, 2021: 1704-1715. |
| [20] | HUANG J, LI X, DU Y, et al. An aspect-opinion joint extraction model for target-oriented opinion words extraction on global space[J]. Applied Intelligence, 2025, 55: No.23. |
| [21] | LV F, LIANG T, FEI Z, et al. Progressive multigranularity information propagation for coupled aspect-opinion extraction[J]. IEEE Transactions on Neural Networks and Learning Systems, 2024, 35(6): 7577-7586. |
| [22] | MA D, XU J, WANG Z, et al. Entity-aspect-opinion-sentiment quadruple extraction for fine-grained sentiment analysis[EB/OL]. [2024-10-13].. |
| [23] | FEI H, WU S, LI J, et al. LasUIE: unifying information extraction with latent adaptive structure-aware generative language model[C]// Proceedings of the 36th International Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2022: 15460-15475. |
| [24] | WAN Z, CHENG F, MAO Z, et al. GPT-RE: in-context learning for relation extraction using large language models[C]// Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing. Stroudsburg: ACL, 2023: 3534-3547. |
| [25] | RAFFEL C, SHAZEER N, ROBERTS A, et al. Exploring the limits of transfer learning with a unified text-to-text transformer[J]. Journal of Machine Learning Research, 2020, 21: 1-67. |
| [26] | LEWIS M, LIU Y, GOYAL N, et al. BART: denoising sequence-to-sequence pre-training for natural language generation, translation, and comprehension[C]// Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics. Stroudsburg: ACL, 2020: 7871-7880. |
| [27] | YE H, ZHANG N, CHEN H, et al. Generative knowledge graph construction: a review[C]// Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing. Stroudsburg: ACL, 2022: 1-17. |
| [28] | ZHAO T, YAN Z, CAO Y, et al. A unified multi-task learning framework for joint extraction of entities and relations[C]// Proceedings of the 35th AAAI Conference on Artificial Intelligence. Palo Alto: AAAI Press, 2021: 14524-14531. |
| [29] | LI S, JI H, HAN J. Document-level event argument extraction by conditional generation[C]// Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. Stroudsburg: ACL, 2021: 894-908. |
| [30] | GIORGI J, BADER G D, WANG B. A sequence-to-sequence approach for document-level relation extraction[C]// Proceedings of the 21st Workshop on Biomedical Language Processing. Stroudsburg: ACL, 2022: 10-25. |
| [31] | LIU T, JIANG Y E, MONATH N, et al. Autoregressive structured prediction with language models[C]// Findings of the Association for Computational Linguistics: EMNLP 2022. Stroudsburg: ACL, 2022: 993-1005. |
| [32] | ZHONG Z, CHEN D. A frustratingly easy approach for entity and relation extraction[C]// Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. Stroudsburg: ACL, 2021: 50-61. |
| [33] | DOZAT T, MANNING C D. Deep biaffine attention for neural dependency parsing[EB/OL]. [2024-10-13]. . |
| [34] | LUAN Y, WADDEN D, HE L, et al. A general framework for information extraction using dynamic span graphs[C]// Proceedings of the 2019 Conference of the North Association for Computational Linguistics, Volume 1 (Long and Short Papers). Stroudsburg: ACL, 2019: 3036-3046. |
| [35] | WU W, WANG F, YUAN A, et al. CorefQA: coreference resolution as query-based span prediction[C]// Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics. Stroudsburg: ACL, 2020: 6953-6963. |
| [1] | 张伟, 牛家祥, 马继超, 沈琼霞. 深层语义特征增强的ReLM中文拼写纠错模型[J]. 《计算机应用》唯一官方网站, 2025, 45(8): 2484-2490. |
| [2] | 王祉苑, 彭涛, 杨捷. 分布外检测中训练与测试的内外数据整合[J]. 《计算机应用》唯一官方网站, 2025, 45(8): 2497-2506. |
| [3] | 王利琴, 耿智雷, 李英双, 董永峰, 边萌. 基于路径和增强三元组文本的开放世界知识推理模型[J]. 《计算机应用》唯一官方网站, 2025, 45(4): 1177-1183. |
| [4] | 邱冰婕, 张超群, 汤卫东, 梁弼诚, 崔丹阳, 罗海升, 陈启明. 基于双重对比学习的零样本关系抽取模型[J]. 《计算机应用》唯一官方网站, 2025, 45(11): 3555-3563. |
| [5] | 李斌, 林民, 斯日古楞null, 高颖杰, 王玉荣, 张树钧. 基于提示学习和全局指针网络的中文古籍实体关系联合抽取方法[J]. 《计算机应用》唯一官方网站, 2025, 45(1): 75-81. |
| [6] | 吴相岚, 肖洋, 刘梦莹, 刘明铭. 基于语义增强模式链接的Text-to-SQL模型[J]. 《计算机应用》唯一官方网站, 2024, 44(9): 2689-2695. |
| [7] | 魏超, 陈艳平, 王凯, 秦永彬, 黄瑞章. 基于掩码提示与门控记忆网络校准的关系抽取方法[J]. 《计算机应用》唯一官方网站, 2024, 44(6): 1713-1719. |
| [8] | 黄梦林, 段磊, 张袁昊, 王培妍, 李仁昊. 基于Prompt学习的无监督关系抽取模型[J]. 《计算机应用》唯一官方网站, 2023, 43(7): 2010-2016. |
| [9] | 高永兵, 高军甜, 马蓉, 杨立东. 用户粒度级的个性化社交文本生成模型[J]. 《计算机应用》唯一官方网站, 2023, 43(4): 1021-1028. |
| [10] | 许亮, 张春, 张宁, 田雪涛. 融合多Prompt模板的零样本关系抽取模型[J]. 《计算机应用》唯一官方网站, 2023, 43(12): 3668-3675. |
| [11] | 江静, 陈渝, 孙界平, 琚生根. 融合后验概率校准训练的文本分类算法[J]. 《计算机应用》唯一官方网站, 2022, 42(6): 1789-1795. |
| [12] | 张海丰, 曾诚, 潘列, 郝儒松, 温超东, 何鹏. 结合BERT和特征投影网络的新闻主题文本分类方法[J]. 《计算机应用》唯一官方网站, 2022, 42(4): 1116-1124. |
| [13] | 王小鹏, 孙媛媛, 林鸿飞. 基于刑事Electra的编-解码关系抽取模型[J]. 《计算机应用》唯一官方网站, 2022, 42(1): 87-93. |
| [14] | 李志超, 吐尔地·托合提, 艾斯卡尔·艾木都拉. 基于动态注意力和多角度匹配的答案选择模型[J]. 《计算机应用》唯一官方网站, 2021, 41(11): 3156-3163. |
| [15] | 李自强, 王正勇, 陈洪刚, 李林怡, 何小海. 基于外观和动作特征双预测模型的视频异常行为检测[J]. 计算机应用, 2021, 41(10): 2997-3003. |
| 阅读次数 | ||||||
|
全文 |
|
|||||
|
摘要 |
|
|||||