


《计算机应用》唯一官方网站 ›› 2026, Vol. 46 ›› Issue (4): 1300-1308.DOI: 10.11772/j.issn.1001-9081.2025040398
• 多媒体计算与计算机仿真 • 上一篇
崔选1,2, 刘波1,2( )
)
收稿日期:2025-04-14
修回日期:2025-06-30
接受日期:2025-07-02
发布日期:2025-07-07
出版日期:2026-04-10
通讯作者:
刘波
作者简介:崔选(1999—),男,湖南娄底人,硕士研究生,主要研究方向:计算机视觉、图像处理
基金资助:Received:2025-04-14
Revised:2025-06-30
Accepted:2025-07-02
Online:2025-07-07
Published:2026-04-10
Contact:
Bo LIU
About author:CUI Xuan, born in 1999, M. S. candidate. His research interests include computer vision, image processing.
Supported by:摘要:
基于生成对抗网络(GAN)潜空间的无监督人脸属性编辑方法具有效率高和无需标注数据的优点,然而这类方法在解耦性和可控性方面仍面临挑战,如在操控特定人脸属性时,可能会引起其他属性的意外变化,从而影响编辑效果,以及难以精确控制所编辑人脸属性的变化程度。针对上述问题,提出基于动态卷积自编码器的无监督人脸属性编辑(AUFAE)方法。该方法通过在潜空间中学习有效的语义向量,实现对人脸属性的精准编辑。具体地,设计动态卷积自编码器网络(DCAE-Net)作为主干网络,该网络的编码器部分采用动态卷积(DyConv)的方式动态提取潜空间的局部特征,从而学习具有局部特性的语义向量;在解码器部分则融入通道注意力(CA)机制建立通道间的非线性依赖关系,使模型能够自主地聚焦不同语义相关的特征通道,有效促进语义向量的独立性学习。为了增强语义向量的解耦性和可控性,引入基于属性边界向量的损失函数训练DCAE-Net。此外,引入软正交损失确保语义向量之间相互独立,进一步提升解耦性能。实验结果表明,在3个预训练GAN生成模型上,与3种主流的人脸属性编辑方法相比,AUFAE的弗雷歇距离(FID)减小了37.43%~50.21%,学习感知图像块相似度(LPIPS)减小了23.61%~42.85%,结构相似性指数(SSIM)提高了7.04%~13.42%。在直观视觉上,AUFAE在人脸属性编辑过程中也未出现属性耦合现象。可见,AUFAE能够有效地缓解人脸编辑过程中的属性耦合现象,并实现更精确的人脸属性编辑。
中图分类号:
崔选, 刘波. 基于动态卷积自编码器的无监督人脸属性编辑方法[J]. 计算机应用, 2026, 46(4): 1300-1308.
Xuan CUI, Bo LIU. Unsupervised face attribute editing method based on dynamic convolutional autoencoder[J]. Journal of Computer Applications, 2026, 46(4): 1300-1308.
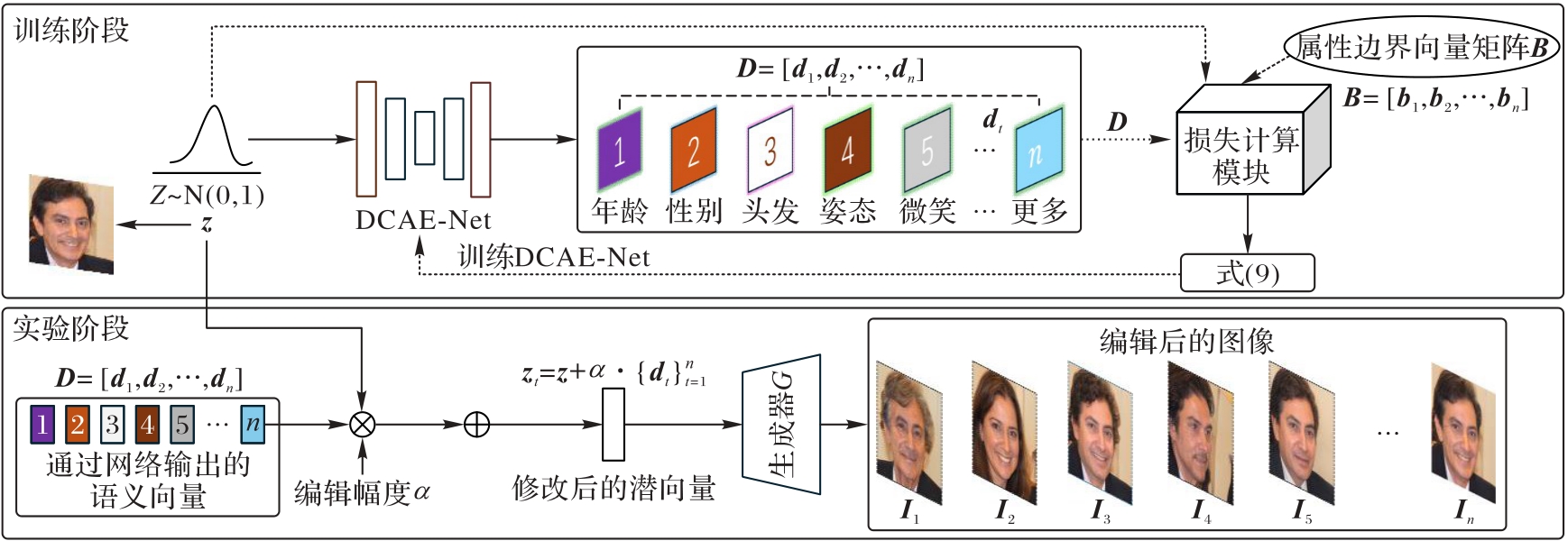
图1 AUFAE的框架
Fig. 1 Framework of AUFAE
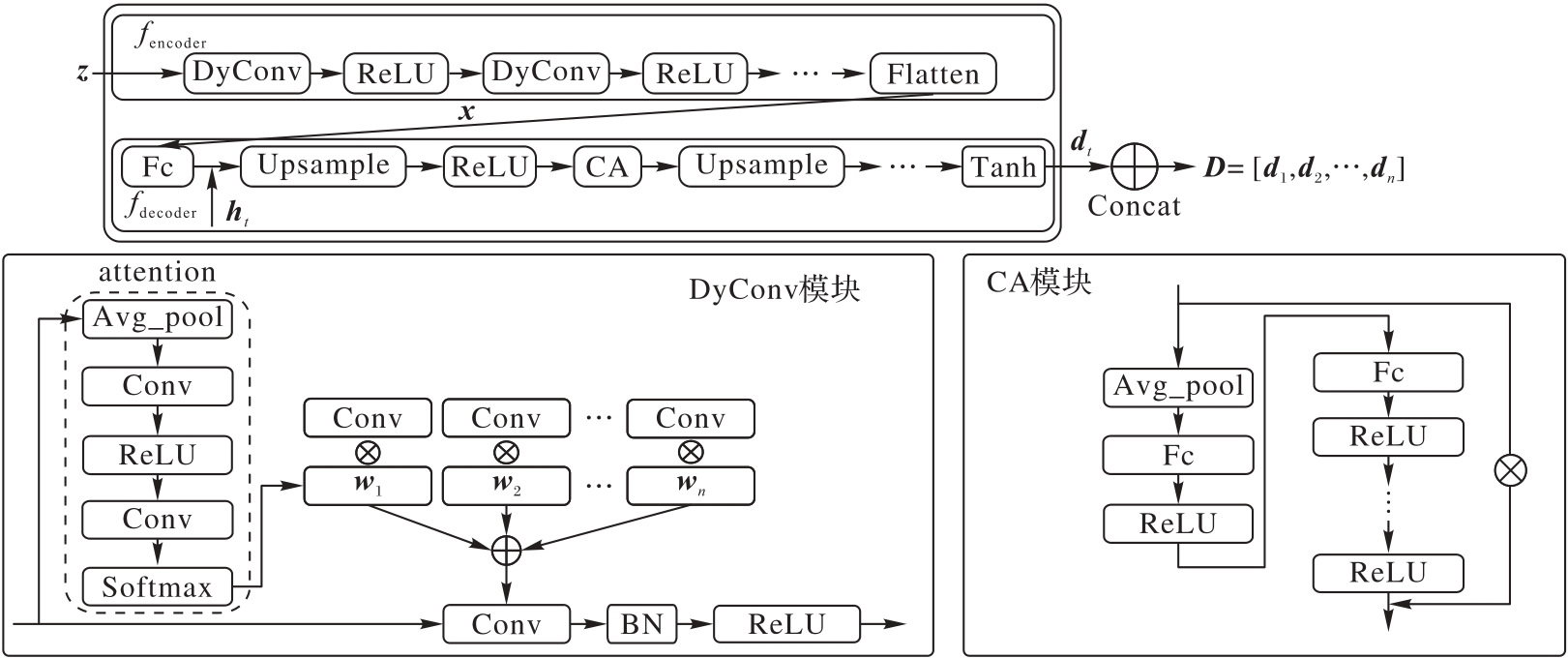
图2 DCAE-Net的网络结构
Fig. 2 Network structure of DCAE-Net
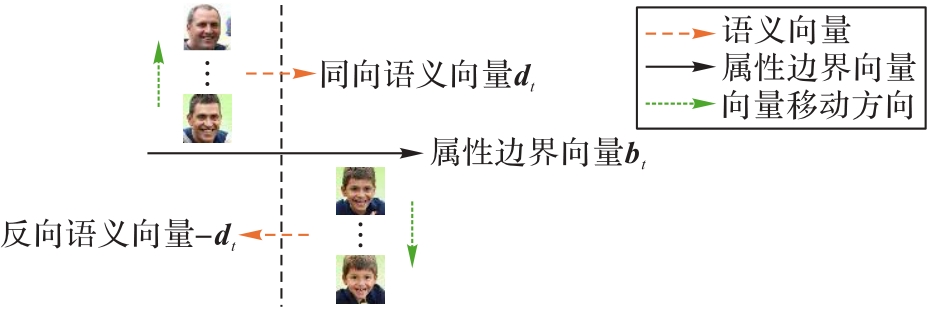
图3 属性边界向量的示意图
Fig. 3 Schematic diagram of attribute boundary vectors

图4 在3个预训练GAN模型(ProGAN、StyleGAN和StyleGAN2)上的损失变化
Fig. 4 Changes of loss functions on three pre-trained GAN models (ProGAN, StyleGAN, and StyleGAN2)
| 环境 | 项目 | 具体内容 |
|---|---|---|
| 硬件配置 | GPU | NVIDIA A100 80 GB PCIe GPU |
| CPU | Intel Xeon Platinum 8358 | |
| 软件配置 | 操作系统 | Ubuntu 18.04.1 |
| 开发环境 | PyTorch 1.10 |
表1 实验环境配置
Tab. 1 Experimental environment configuration
| 环境 | 项目 | 具体内容 |
|---|---|---|
| 硬件配置 | GPU | NVIDIA A100 80 GB PCIe GPU |
| CPU | Intel Xeon Platinum 8358 | |
| 软件配置 | 操作系统 | Ubuntu 18.04.1 |
| 开发环境 | PyTorch 1.10 |
| 生成模型 | 属性名 | InterFaceGAN | AdaTrans | SDFlow | AUFAE | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| FID | LPIPS | SSIM | FID | LPIPS | SSIM | FID | LPIPS | SSIM | FID | LPIPS | SSIM | ||
| ProGAN | Age | 79.10 | 0.32 | 0.69 | 70.65 | 0.29 | 0.72 | 62.95 | 0.26 | 0.74 | 34.54 | 0.18 | 0.81 |
| Hair | 50.31 | 0.25 | 0.77 | 76.77 | 0.30 | 0.71 | 60.76 | 0.24 | 0.77 | 38.06 | 0.20 | 0.79 | |
| Gender | 89.52 | 0.36 | 0.65 | 76.47 | 0.30 | 0.71 | 74.35 | 0.31 | 0.69 | 47.44 | 0.25 | 0.73 | |
| Pose | 65.06 | 0.39 | 0.61 | — | — | — | — | — | — | 45.90 | 0.28 | 0.70 | |
| Smile | 45.82 | 0.21 | 0.80 | 75.86 | 0.32 | 0.69 | 60.66 | 0.23 | 0.78 | 33.76 | 0.18 | 0.81 | |
| 平均 | 65.96 | 0.31 | 0.70 | 74.94 | 0.30 | 0.71 | 64.68 | 0.26 | 0.75 | 39.94 | 0.22 | 0.77 | |
| StyleGAN | Age | 68.93 | 0.33 | 0.68 | 62.34 | 0.26 | 0.74 | 59.39 | 0.24 | 0.72 | 41.57 | 0.21 | 0.80 |
| Hair | 68.63 | 0.32 | 0.71 | 72.55 | 0.35 | 0.66 | 66.50 | 0.25 | 0.71 | 35.78 | 0.19 | 0.81 | |
| Gender | 82.38 | 0.38 | 0.63 | 78.59 | 0.33 | 0.68 | 68.08 | 0.26 | 0.69 | 46.36 | 0.24 | 0.76 | |
| Pose | 75.65 | 0.41 | 0.61 | — | — | — | — | — | — | 43.25 | 0.25 | 0.76 | |
| Smile | 30.65 | 0.17 | 0.84 | 68.21 | 0.33 | 0.68 | 57.42 | 0.22 | 0.73 | 39.59 | 0.20 | 0.81 | |
| 平均 | 65.25 | 0.32 | 0.69 | 70.42 | 0.32 | 0.69 | 62.85 | 0.24 | 0.71 | 41.31 | 0.22 | 0.79 | |
| StyleGAN2 | Age | 69.39 | 0.37 | 0.76 | 74.03 | 0.26 | 0.79 | 52.41 | 0.18 | 0.81 | 28.98 | 0.15 | 0.85 |
| Hair | 61.16 | 0.34 | 0.78 | 81.85 | 0.25 | 0.78 | 45.57 | 0.28 | 0.78 | 37.70 | 0.20 | 0.80 | |
| Gender | 62.77 | 0.33 | 0.79 | 79.92 | 0.26 | 0.79 | 59.00 | 0.22 | 0.77 | 27.23 | 0.14 | 0.86 | |
| Pose | 74.95 | 0.38 | 0.76 | — | — | — | — | — | — | 30.18 | 0.16 | 0.84 | |
| Smile | 69.95 | 0.36 | 0.77 | 44.18 | 0.25 | 0.80 | 50.21 | 0.26 | 0.78 | 30.29 | 0.16 | 0.84 | |
| 平均 | 67.64 | 0.37 | 0.77 | 70.00 | 0.26 | 0.79 | 51.80 | 0.24 | 0.79 | 30.88 | 0.16 | 0.84 | |
表2 不同方法的关键人脸属性编辑效果对比
Tab. 2 Comparison of facial attribute editing effects by different methods
| 生成模型 | 属性名 | InterFaceGAN | AdaTrans | SDFlow | AUFAE | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| FID | LPIPS | SSIM | FID | LPIPS | SSIM | FID | LPIPS | SSIM | FID | LPIPS | SSIM | ||
| ProGAN | Age | 79.10 | 0.32 | 0.69 | 70.65 | 0.29 | 0.72 | 62.95 | 0.26 | 0.74 | 34.54 | 0.18 | 0.81 |
| Hair | 50.31 | 0.25 | 0.77 | 76.77 | 0.30 | 0.71 | 60.76 | 0.24 | 0.77 | 38.06 | 0.20 | 0.79 | |
| Gender | 89.52 | 0.36 | 0.65 | 76.47 | 0.30 | 0.71 | 74.35 | 0.31 | 0.69 | 47.44 | 0.25 | 0.73 | |
| Pose | 65.06 | 0.39 | 0.61 | — | — | — | — | — | — | 45.90 | 0.28 | 0.70 | |
| Smile | 45.82 | 0.21 | 0.80 | 75.86 | 0.32 | 0.69 | 60.66 | 0.23 | 0.78 | 33.76 | 0.18 | 0.81 | |
| 平均 | 65.96 | 0.31 | 0.70 | 74.94 | 0.30 | 0.71 | 64.68 | 0.26 | 0.75 | 39.94 | 0.22 | 0.77 | |
| StyleGAN | Age | 68.93 | 0.33 | 0.68 | 62.34 | 0.26 | 0.74 | 59.39 | 0.24 | 0.72 | 41.57 | 0.21 | 0.80 |
| Hair | 68.63 | 0.32 | 0.71 | 72.55 | 0.35 | 0.66 | 66.50 | 0.25 | 0.71 | 35.78 | 0.19 | 0.81 | |
| Gender | 82.38 | 0.38 | 0.63 | 78.59 | 0.33 | 0.68 | 68.08 | 0.26 | 0.69 | 46.36 | 0.24 | 0.76 | |
| Pose | 75.65 | 0.41 | 0.61 | — | — | — | — | — | — | 43.25 | 0.25 | 0.76 | |
| Smile | 30.65 | 0.17 | 0.84 | 68.21 | 0.33 | 0.68 | 57.42 | 0.22 | 0.73 | 39.59 | 0.20 | 0.81 | |
| 平均 | 65.25 | 0.32 | 0.69 | 70.42 | 0.32 | 0.69 | 62.85 | 0.24 | 0.71 | 41.31 | 0.22 | 0.79 | |
| StyleGAN2 | Age | 69.39 | 0.37 | 0.76 | 74.03 | 0.26 | 0.79 | 52.41 | 0.18 | 0.81 | 28.98 | 0.15 | 0.85 |
| Hair | 61.16 | 0.34 | 0.78 | 81.85 | 0.25 | 0.78 | 45.57 | 0.28 | 0.78 | 37.70 | 0.20 | 0.80 | |
| Gender | 62.77 | 0.33 | 0.79 | 79.92 | 0.26 | 0.79 | 59.00 | 0.22 | 0.77 | 27.23 | 0.14 | 0.86 | |
| Pose | 74.95 | 0.38 | 0.76 | — | — | — | — | — | — | 30.18 | 0.16 | 0.84 | |
| Smile | 69.95 | 0.36 | 0.77 | 44.18 | 0.25 | 0.80 | 50.21 | 0.26 | 0.78 | 30.29 | 0.16 | 0.84 | |
| 平均 | 67.64 | 0.37 | 0.77 | 70.00 | 0.26 | 0.79 | 51.80 | 0.24 | 0.79 | 30.88 | 0.16 | 0.84 | |

图5 在不同生成模型上编辑年龄属性的可视化比较
Fig. 5 Visualization comparison of age attribute editing on different generative models

图6 在不同生成模型上编辑性别属性的可视化比较
Fig. 6 Visualization comparison of gender attribute editing on different generative models

图7 在不同生成模型上编辑发型属性的可视化比较
Fig. 7 Visualization comparison of hair attribute editing on different generative models

图8 在不同生成模型上编辑微笑属性的可视化比较
Fig. 8 Visualization comparison of smile attribute editing ondifferent generative models
| 方法序号 | 组成 | FID | LPIPS | SSIM |
|---|---|---|---|---|
| 1 | DCAE-Net | 47.16 | 0.24 | 0.78 |
| 2 | MLP | 45.01 | 0.24 | 0.77 |
| 3 | DCAE-Net | 53.24 | 0.28 | 0.71 |
| 4 | DCAE-Net | 42.34 | 0.23 | 0.77 |
| 5 | DCAE-Net | 41.31 | 0.22 | 0.79 |
表3 消融实验的量化结果
Tab. 3 Quantitative results of ablation experiments
| 方法序号 | 组成 | FID | LPIPS | SSIM |
|---|---|---|---|---|
| 1 | DCAE-Net | 47.16 | 0.24 | 0.78 |
| 2 | MLP | 45.01 | 0.24 | 0.77 |
| 3 | DCAE-Net | 53.24 | 0.28 | 0.71 |
| 4 | DCAE-Net | 42.34 | 0.23 | 0.77 |
| 5 | DCAE-Net | 41.31 | 0.22 | 0.79 |

图 9 消融实验的可视化结果
Fig. 9 Visualization results of ablation experiments
| [1] | 靳聪,周满玲,林美秀,等. VR/AR-AdaptFace:面向虚拟现实与增强现实的自适应多模态面部替换模型[J]. 中国传媒大学学报(自然科学版), 2024, 31(4): 55-63. |
| JIN C, ZHOU M L, LIN M X, et al. VR/AR-AdaptFace: an adaptive multimodal face replacement model for virtual and augmented reality [J]. Journal of Communication University of China (Science and Technology), 2024, 31(4): 55-63. | |
| [2] | XU Y, YIN Y, JIANG L, et al. TransEditor: Transformer-based dual-space GAN for highly controllable facial editing [C]// Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2022: 7673-7682. |
| [3] | HE X, ZHU M, CHEN D, et al. Diff-Privacy: diffusion-based face privacy protection [J]. IEEE Transactions on Circuits and Systems for Video Technology, 2024, 34(12): 13164-13176. |
| [4] | ZHU J Y, PARK T, ISOLA P, et al. Unpaired image-to-image translation using cycle-consistent adversarial networks [C]// Proceedings of the 2017 IEEE International Conference on Computer Vision. Piscataway: IEEE, 2017: 2242-2251. |
| [5] | TORBUNOV D, HUANG Y, YU H, et al. UVCGAN: UNet vision Transformer cycle-consistent GAN for unpaired image-to-image translation [C]// Proceedings of the 2023 IEEE/CVF Winter Conference on Applications of Computer Vision. Piscataway: IEEE, 2023: 702-712. |
| [6] | HUANG X, LIU M Y, BELONGIE S, et al. Multimodal unsupervised image-to-image translation [C]// Proceedings of the 2018 European Conference on Computer Vision, LNCS 11207. Cham: Springer, 2018: 179-196. |
| [7] | MIRZA M, OSINDERO S. Conditional generative adversarial nets[EB/OL]. [2025-04-10].. |
| [8] | LIU M, DING Y, XIA M, et al. STGAN: a unified selective transfer network for arbitrary image attribute editing [C]// Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2019: 3668-3677. |
| [9] | PERNUŠ M, ŠTRUC V, DOBRIŠEK S. MaskFaceGAN: high-resolution face editing with masked GAN latent code optimization [J]. IEEE Transactions on Image Processing, 2023, 32: 5893-5908. |
| [10] | 陶玲玲,刘波,李文博,等. 有闭解的可控人脸编辑算法[J]. 计算机应用, 2023, 43(2): 601-607. |
| TAO L L, LIU B, LI W B, et al. Controllable face editing algorithm with closed-form solutions[J]. Journal of Computer Applications, 2023, 43(2): 601-607. | |
| [11] | CHOI Y, CHOI M, KIM M, et al. StarGAN: unified generative adversarial networks for multi-domain image-to-image translation[C]// Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2018: 8789-8797. |
| [12] | CHOI Y, UH Y, YOO J, et al. StarGAN v2: diverse image synthesis for multiple domains [C]// Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2019: 8185-8194. |
| [13] | HE Z, ZUO W, KAN M, et al. AttGAN: facial attribute editing by only changing what you want [J]. IEEE Transactions on Image Processing, 2019, 28(11): 5464-5478. |
| [14] | NAVEH C. Multi-directional subspace editing in style-space [C]// Proceedings of the 2023 IEEE/CVF International Conference on Computer Vision. Piscataway: IEEE, 2023: 7104-7114. |
| [15] | ZHUANG P, KOYEJO O, SCHWING A G. Enjoy your editing: controllable GANs for image editing via latent space navigation[EB/OL]. [2025-04-14]. . |
| [16] | SHEN Y, YANG C, TANG X, et al. InterFaceGAN: interpreting the disentangled face representation learned by GANs [J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2022, 44(4): 2004-2018. |
| [17] | HÄRKÖNEN E, HERTZMANN A, LEHTINEN J, et al. GANSpace: discovering interpretable GAN controls [C]// Proceedings of the 34th International Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2020: 9841-9850. |
| [18] | CHOI J, LEE J, YOON C, et al. Do not escape from the manifold: discovering the local coordinates on the latent space of GANs[EB/OL]. [2025-04-14].. |
| [19] | SHEN Y, ZHOU B. Closed-form factorization of latent semantics in GANs [C]// Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2021: 1532-1540. |
| [20] | HUANG Z, MA S, ZHANG J, et al. Adaptive nonlinear latent transformation for conditional face editing [C]// Proceedings of the 2023 IEEE/CVF International Conference on Computer Vision. Piscataway: IEEE, 2023: 20965-20974. |
| [21] | LI B, HUANG Z, SHAN H, et al. Semantic latent decomposition with normalizing flows for face editing [C]// Proceedings of the 2024 IEEE International Conference on Acoustics, Speech and Signal Processing. Piscataway: IEEE, 2024: 4165-4169. |
| [22] | ABDAL R, ZHU P, MITRA N J, et al. StyleFlow: attribute-conditioned exploration of StyleGAN-generated images using conditional continuous normalizing flows [J]. ACM Transactions on Graphics, 2021, 40(3): No.21. |
| [23] | BAYKAL A C, ANEES A B, CEYLAN D, et al. CLIP-guided StyleGAN inversion for text-driven real image editing [J]. ACM Transactions on Graphics, 2023, 42(5): No.172. |
| [24] | PATASHNIK O, WU Z, SHECHTMAN E, et al. StyleCLIP: text-driven manipulation of StyleGAN imagery [C]// Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision. Piscataway: IEEE, 2021: 2065-2074. |
| [25] | KINGMA D P, WELLING M. Auto-encoding variational Bayes[EB/OL]. [2025-03-11].. |
| [26] | RADFORD A, METZ L, CHINTALA S. Unsupervised representation learning with deep convolutional generative adversarial networks[EB/OL]. [2025-02-15].. |
| [27] | JOGIN M, MOHANA, MADHULIKA M S, et al. Feature extraction using Convolution Neural Networks (CNN) and deep learning [C]// Proceedings of the 3rd IEEE International Conference on Recent Trends in Electronics, Information and Communication Technology. Piscataway: IEEE, 2018: 2319-2323. |
| [28] | MENG C, YANG J, LIN W, et al. CTA-Net: a CNN-Transformer aggregation network for improving multi-scale feature extraction[EB/OL]. [2025-04-09].. |
| [29] | CUI T, LI J, LIU L. TAOTF: a two-stage approximately orthogonal training framework in deep neural networks [C]// Proceedings of the 26th European Conference on Artificial Intelligence/ 12th Conference on Prestigious Applications of Intelligent Systems. Amsterdam: IOS Press, 2023: 509-516. |
| [30] | KARRAS T, AILA T, LAINE S, et al. Progressive growing of GANs for improved quality, stability, and variation [EB/OL]. [2025-04-14].. |
| [31] | KARRAS T, LAINE S, AILA T. A style-based generator architecture for generative adversarial networks [C]// Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2019: 4396-4405. |
| [32] | KARRAS T, LAINE S, AITTALA M, et al. Analyzing and improving the image quality of StyleGAN [C]// Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2020: 8107-8116. |
| [33] | LIU Z, LUO P, WANG X, et al. Deep learning face attributes in the wild [C]// Proceedings of the 2015 IEEE International Conference on Computer Vision. Piscataway: IEEE, 2015: 3730-3738. |
| [34] | HEUSEL M, RAMSAUER H, UNTERTHINER T, et al. GANs trained by a two time-scale update rule converge to a local nash equilibrium [C]// Proceedings of the 31st International Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2017: 6629-6640. |
| [35] | ZHANG R, ISOLA P, EFROS A A, et al. The unreasonable effectiveness of deep features as a perceptual metric [C]// Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2018: 586-595. |
| [36] | WANG Z, BOVIK A C, SHEIKH H R, et al. Image quality assessment: from error visibility to structural similarity [J]. IEEE Transactions on Image Processing, 2004, 13(4): 600-612. |
| [1] | 陈敏, 秦小林, 李绍涵, 杨昊, 李韬弘. 深度学习应用于强对流天气预测的综述[J]. 《计算机应用》唯一官方网站, 2026, 46(3): 980-992. |
| [2] | 樊娜, 罗闯, 张泽晖, 张梦瑶, 穆鼎. 基于改进生成对抗网络的车辆轨迹语义隐私保护机制[J]. 《计算机应用》唯一官方网站, 2026, 46(1): 169-180. |
| [3] | 王丽芳, 任文婧, 郭晓东, 张荣国, 胡立华. 用于低剂量CT图像降噪的多路特征生成对抗网络[J]. 《计算机应用》唯一官方网站, 2026, 46(1): 270-279. |
| [4] | 菅银龙, 陈学斌, 景忠瑞, 钟琪, 张镇博. 联邦学习中基于条件生成对抗网络的数据增强方案[J]. 《计算机应用》唯一官方网站, 2026, 46(1): 21-32. |
| [5] | 邓伊琳, 余发江. 基于LSTM和可分离自注意力机制的伪随机数生成器[J]. 《计算机应用》唯一官方网站, 2025, 45(9): 2893-2901. |
| [6] | 周金, 李玉芝, 张徐, 高硕, 张立, 盛家川. 复杂电磁环境下的调制识别网络[J]. 《计算机应用》唯一官方网站, 2025, 45(8): 2672-2682. |
| [7] | 黄颖, 高胜美, 陈广, 刘苏. 结合信噪比引导的双分支结构和直方图均衡的低照度图像增强网络[J]. 《计算机应用》唯一官方网站, 2025, 45(6): 1971-1979. |
| [8] | 李慧, 贾炳志, 王晨曦, 董子宇, 李纪龙, 仲兆满, 陈艳艳. 基于Swin Transformer的生成对抗网络水下图像增强模型[J]. 《计算机应用》唯一官方网站, 2025, 45(5): 1439-1446. |
| [9] | 潘理虎, 彭守信, 张睿, 薛之洋, 毛旭珍. 面向运动前景区域的视频异常检测[J]. 《计算机应用》唯一官方网站, 2025, 45(4): 1300-1309. |
| [10] | 上官宏, 任慧莹, 张雄, 韩兴隆, 桂志国, 王燕玲. 基于双编码器双解码器GAN的低剂量CT降噪模型[J]. 《计算机应用》唯一官方网站, 2025, 45(2): 624-632. |
| [11] | 黄靖, 彭鑫, 李文豪, 胡凯, 王腾, 黄亚敏, 文元桥. 多尺度特征融合的高质量声呐图像生成方法[J]. 《计算机应用》唯一官方网站, 2025, 45(12): 3987-3994. |
| [12] | 徐国愚, 闫晓龙, 张一丹. 基于动态上采样的轻量级生成对抗网络DU-FastGAN[J]. 《计算机应用》唯一官方网站, 2025, 45(10): 3067-3073. |
| [13] | 高阳峄, 雷涛, 杜晓刚, 李岁永, 王营博, 闵重丹. 基于像素距离图和四维动态卷积网络的密集人群计数与定位方法[J]. 《计算机应用》唯一官方网站, 2024, 44(7): 2233-2242. |
| [14] | 刘丽, 侯海金, 王安红, 张涛. 基于多尺度注意力的生成式信息隐藏算法[J]. 《计算机应用》唯一官方网站, 2024, 44(7): 2102-2109. |
| [15] | 孙逊, 冯睿锋, 陈彦如. 基于深度与实例分割融合的单目3D目标检测方法[J]. 《计算机应用》唯一官方网站, 2024, 44(7): 2208-2215. |
| 阅读次数 | ||||||
|
全文 |
|
|||||
|
摘要 |
|
|||||