


《计算机应用》唯一官方网站 ›› 2025, Vol. 45 ›› Issue (10): 3161-3169.DOI: 10.11772/j.issn.1001-9081.2024101489
• 人工智能 • 上一篇
曾正东, 赵明( )
)
收稿日期:2024-10-30
修回日期:2025-01-11
接受日期:2025-01-16
发布日期:2025-02-07
出版日期:2025-10-10
通讯作者:
赵明
作者简介:曾正东(1999—),男,广东中山人,硕士研究生,CCF会员,主要研究方向:人体姿态估计、计算机视觉、目标检测基金资助:Received:2024-10-30
Revised:2025-01-11
Accepted:2025-01-16
Online:2025-02-07
Published:2025-10-10
Contact:
Ming ZHAO
About author:ZENG Zhengdong, born in 1999, M. S. candidate. His research interests include human pose estimation, computer vision, object detection.Supported by:摘要:
近期关于人体姿态估计的研究表明,充分发挥二维姿态潜在空间信息的能力,获取具有代表性的特征,可产生更准确的三维姿态估计结果。因此,提出一种基于图注意力机制的时空上下文网络,该网络包括带滑动窗口的时间上下文网络(TCN)、由肢体引导的全局图注意力机制网络(EGAT)和基于姿态语法的局部图注意力卷积网络(PGCN)。首先,使用STCN将长序列的二维关节位置转化为单序列的人体姿态潜在特征,从而有效聚合和利用远、近距离的人体姿态信息,并大幅降低计算成本。其次,提出EGAT模块,以有效计算全局空间上下文。该模块将人体边缘节点视为“交通枢纽”,为它们与其他节点之间的信息交换建立桥梁。再次,利用图注意力机制进行自适应权值分配,对人体关节进行全局上下文计算。最后,设计PGCN模块,利用图卷积网络(GCN)计算和建模局部空间上下文,它强调人体对称节点的运动一致性和人体骨骼的运动关联结构。在Human3.6M和HumanEva-Ⅰ这2个复杂的标准数据集上评估所提模型。实验结果表明,所提模型具有更优越的性能,在输入帧长度为81的情况下,所提模型在数据集Human3.6M上的每个关节的平均位置误差(MPJPE)达43.5 mm,与目前先进算法MCFNet(Multi-scale Cross Fusion Network)相比降低了10.5%,体现出更高的准确度。
中图分类号:
曾正东, 赵明. 基于图注意力机制的三维人体姿态估计时空上下文网络[J]. 计算机应用, 2025, 45(10): 3161-3169.
Zhengdong ZENG, Ming ZHAO. Spatio-temporal context network for 3D human pose estimation based on graph attention[J]. Journal of Computer Applications, 2025, 45(10): 3161-3169.
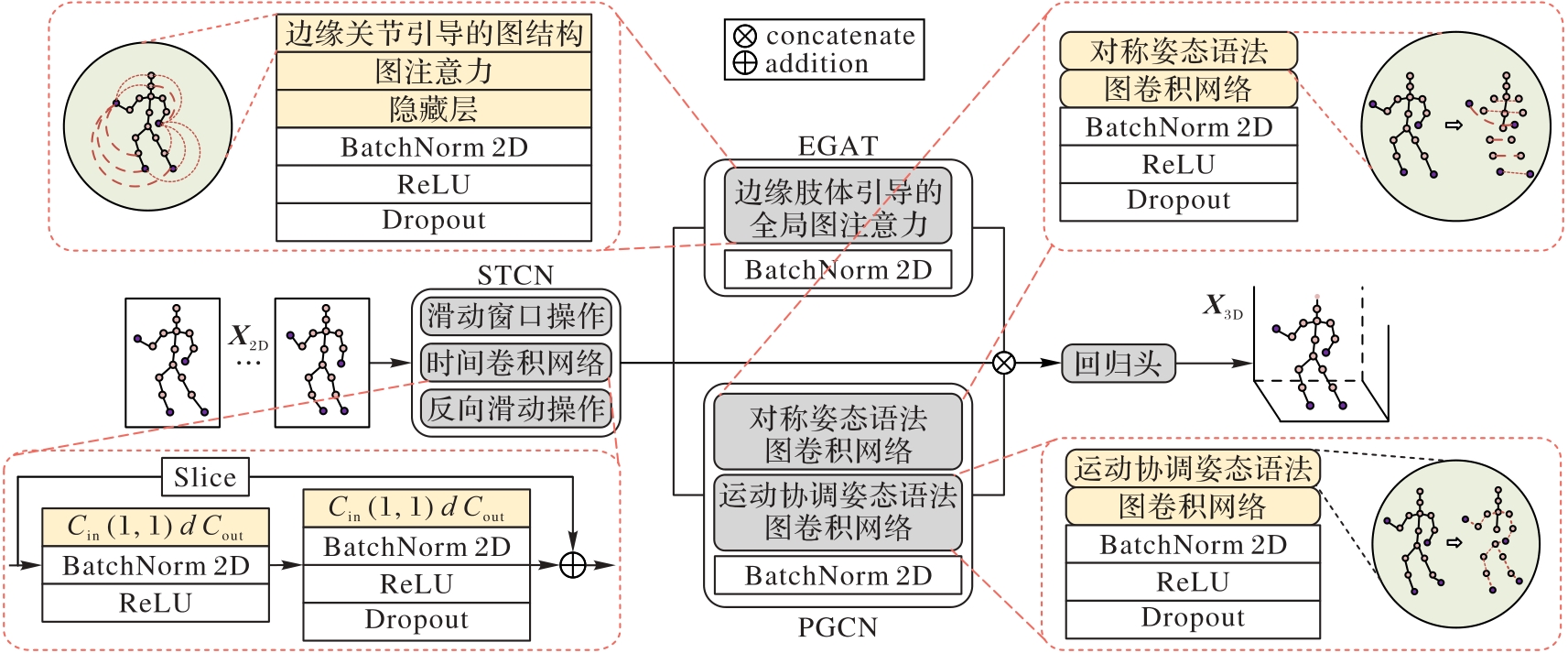
图1 本文模型的总体框架
Fig. 1 Overall framework of proposed model
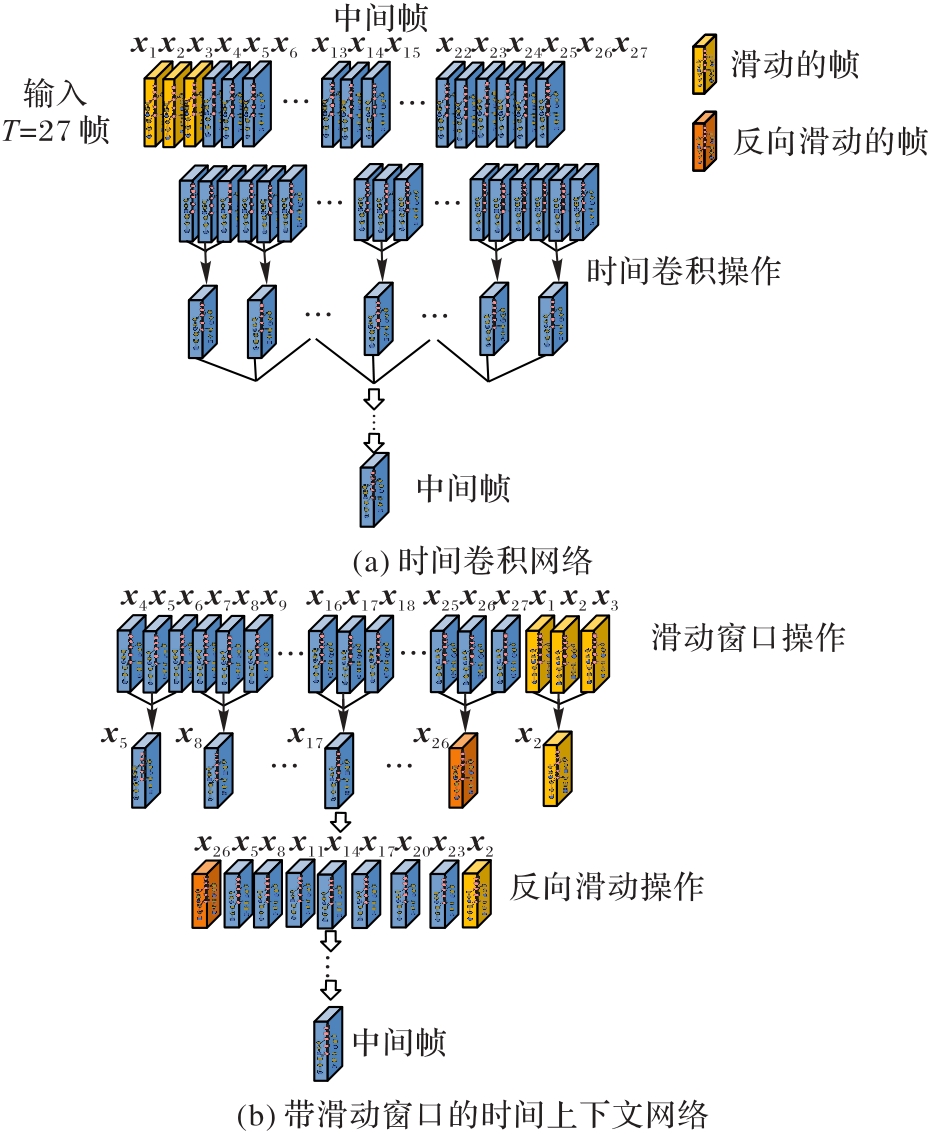
图2 时间卷积网络和带滑动窗口的时间上下文网络的结构
Fig. 2 Structures of temporal convolution network and temporal context network with shifted windows
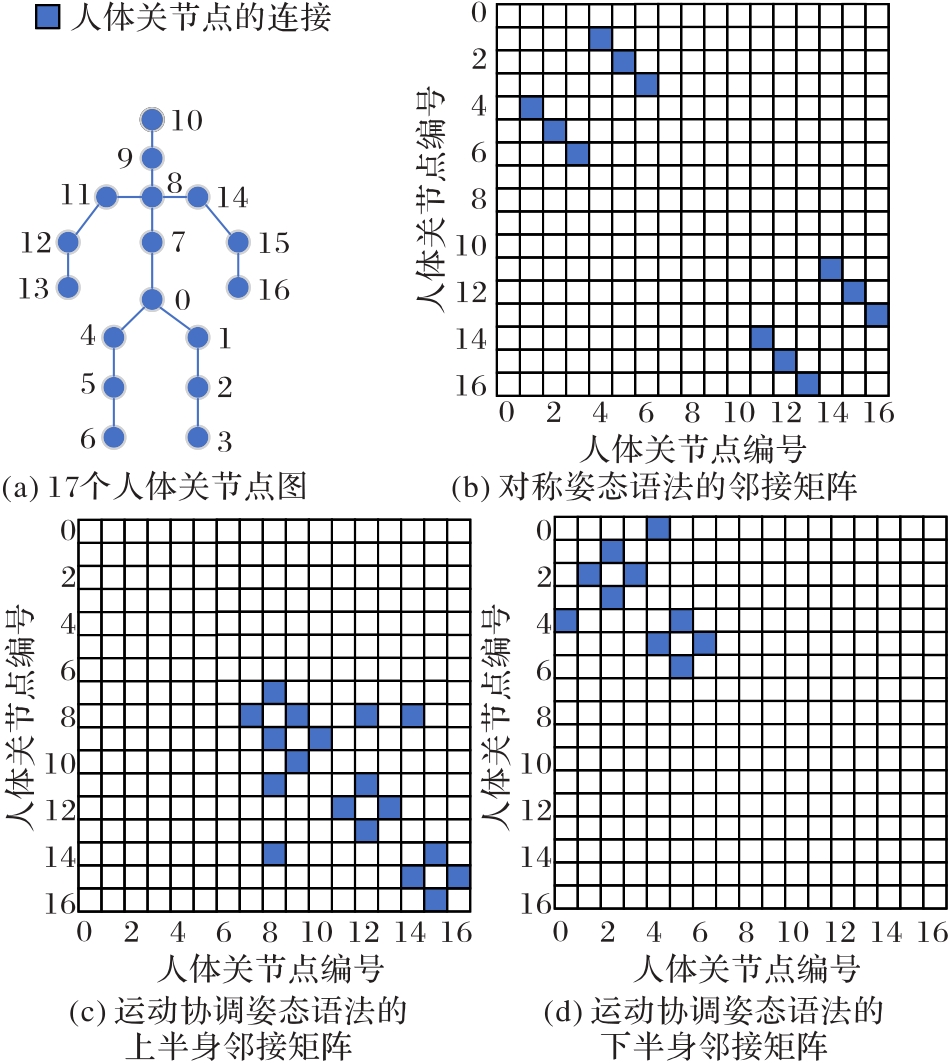
图3 人体骨骼图和姿态语法邻接矩阵
Fig. 3 Human skeleton map and adjacency matrices of pose grammars
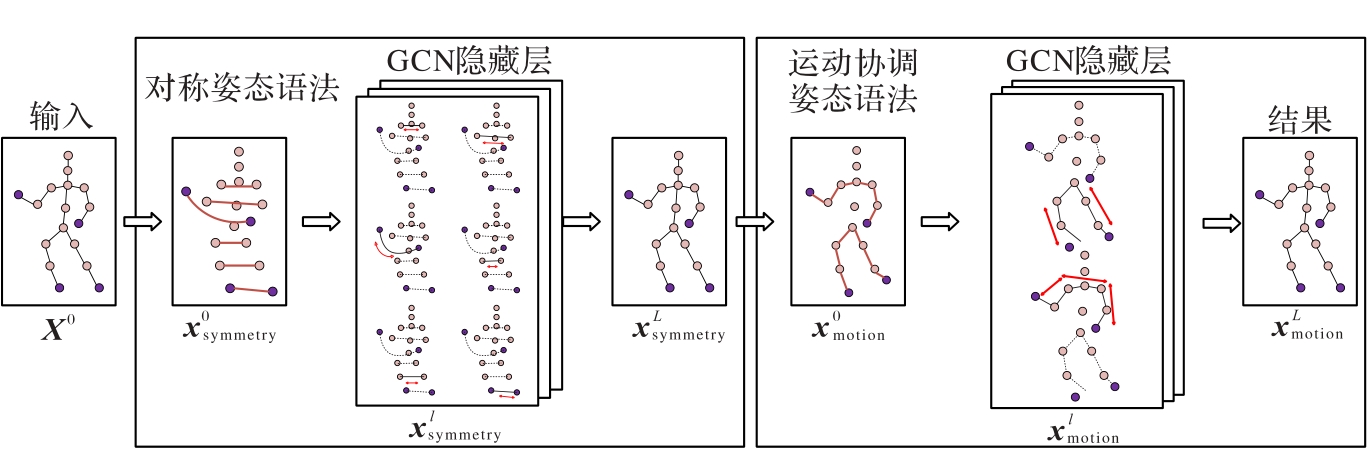
图4 PGCN的结构
Fig. 4 Structure of PGCN
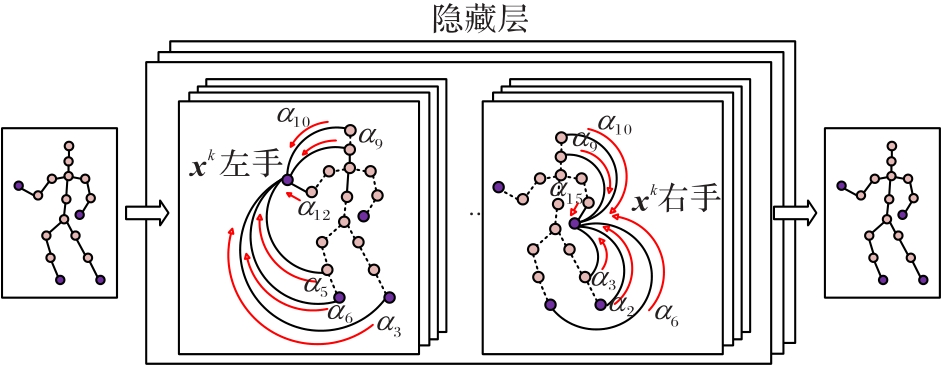
图5 EGAT的结构
Fig. 5 Structure of EGAT
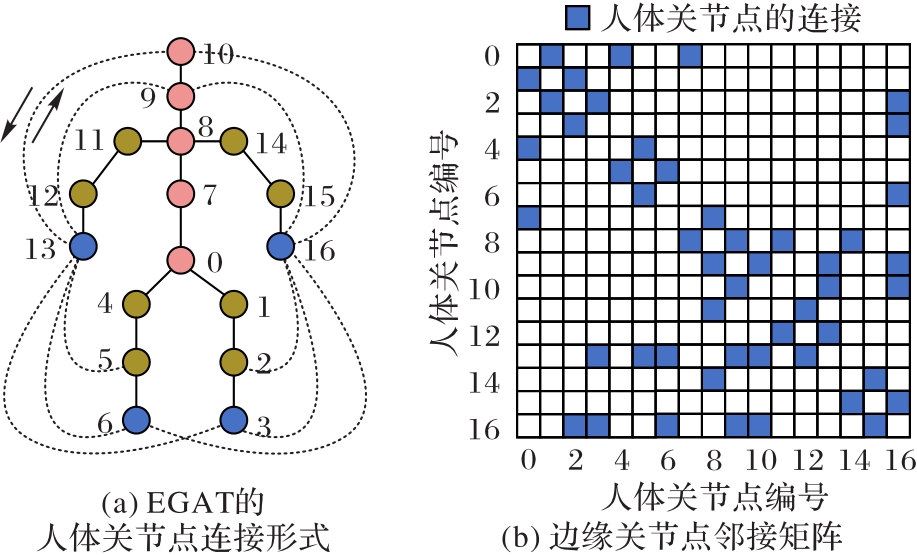
图6 人体骨骼连接图与边缘关节点邻接矩阵
Fig. 6 Human skeleton connection map and adjacency matrix of extremities
| 模型 | Dir | Disc | Eat | Gree | Phon | Phot | Pose | Purc | Sit | SitD | Smok | Wait | WalkD | Walk | WalkT. | Avg. |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 文献[ | 46.3 | 46.9 | 50.1 | 56.2 | 45.1 | 44.1 | 58.0 | 65.0 | 48.4 | 44.5 | 47.1 | 32.5 | 33.2 | 46.7 | ||
| 文献[ | 45.2 | 49.9 | 47.5 | 50.9 | 54.9 | 66.1 | 48.5 | 46.3 | 59.7 | 71.5 | 51.4 | 48.6 | 53.9 | 39.9 | 44.1 | 51.9 |
| 文献[ | 42.4 | 49.2 | 45.7 | 49.4 | 50.4 | 58.2 | 47.9 | 46.0 | 57.5 | 63.0 | 49.7 | 46.6 | 52.2 | 38.9 | 40.8 | 49.4 |
| 文献[ | 45.6 | 49.7 | 46.0 | 49.3 | 52.2 | 58.8 | 47.5 | 46.1 | 58.2 | 66.1 | 50.7 | 47.5 | 52.6 | 39.2 | 41.6 | 50.1 |
| 文献[ | 43.9 | 47.6 | 45.5 | 48.9 | 50.1 | 58.0 | 46.2 | 44.5 | 55.7 | 62.9 | 49.0 | 45.8 | 51.8 | 38.0 | 39.9 | 48.5 |
| MCFNet[ | 44.1 | 48.0 | 44.0 | 47.2 | 50.9 | 56.8 | 47.0 | 45.4 | 64.7 | 49.2 | 46.3 | 52.5 | 38.6 | 40.7 | 48.6 | |
| 文献[ | 40.7 | 43.7 | 40.7 | 42.7 | 42.9 | 41.2 | 57.4 | 44.8 | 44.4 | 30.8 | 31.3 | |||||
| 文献[ | 43.7 | 48.2 | 44.1 | 49.8 | 56.1 | 46.0 | 46.0 | 44.2 | 56.3 | 60.7 | 48.8 | 44.9 | 50.9 | 37.2 | 39.6 | 47.7 |
| 本文模型(T=81) | 42.2 | 45.9 | 55.1 | 56.8 | 60.9 | 43.1 | 43.5 |
表1 不同模型在Human3.6M数据集上的MPJPE (mm)
Tab. 1 MPJPE of different models on Human3.6M dataset
| 模型 | Dir | Disc | Eat | Gree | Phon | Phot | Pose | Purc | Sit | SitD | Smok | Wait | WalkD | Walk | WalkT. | Avg. |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 文献[ | 46.3 | 46.9 | 50.1 | 56.2 | 45.1 | 44.1 | 58.0 | 65.0 | 48.4 | 44.5 | 47.1 | 32.5 | 33.2 | 46.7 | ||
| 文献[ | 45.2 | 49.9 | 47.5 | 50.9 | 54.9 | 66.1 | 48.5 | 46.3 | 59.7 | 71.5 | 51.4 | 48.6 | 53.9 | 39.9 | 44.1 | 51.9 |
| 文献[ | 42.4 | 49.2 | 45.7 | 49.4 | 50.4 | 58.2 | 47.9 | 46.0 | 57.5 | 63.0 | 49.7 | 46.6 | 52.2 | 38.9 | 40.8 | 49.4 |
| 文献[ | 45.6 | 49.7 | 46.0 | 49.3 | 52.2 | 58.8 | 47.5 | 46.1 | 58.2 | 66.1 | 50.7 | 47.5 | 52.6 | 39.2 | 41.6 | 50.1 |
| 文献[ | 43.9 | 47.6 | 45.5 | 48.9 | 50.1 | 58.0 | 46.2 | 44.5 | 55.7 | 62.9 | 49.0 | 45.8 | 51.8 | 38.0 | 39.9 | 48.5 |
| MCFNet[ | 44.1 | 48.0 | 44.0 | 47.2 | 50.9 | 56.8 | 47.0 | 45.4 | 64.7 | 49.2 | 46.3 | 52.5 | 38.6 | 40.7 | 48.6 | |
| 文献[ | 40.7 | 43.7 | 40.7 | 42.7 | 42.9 | 41.2 | 57.4 | 44.8 | 44.4 | 30.8 | 31.3 | |||||
| 文献[ | 43.7 | 48.2 | 44.1 | 49.8 | 56.1 | 46.0 | 46.0 | 44.2 | 56.3 | 60.7 | 48.8 | 44.9 | 50.9 | 37.2 | 39.6 | 47.7 |
| 本文模型(T=81) | 42.2 | 45.9 | 55.1 | 56.8 | 60.9 | 43.1 | 43.5 |
| 模型 | Dir | Disc | Eat | Gree | Phon | Phot | Pose | Purc | Sit | SitD | Smok | Wait | WalkD | Walk | WalkT. | Avg. |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 文献[ | 35.9 | 40.0 | 38.0 | 41.5 | 42.5 | 51.4 | 37.8 | 36.0 | 48.6 | 56.6 | 41.8 | 38.3 | 42.7 | 31.7 | 36.2 | 41.2 |
| 文献[ | 35.7 | 38.6 | 36.3 | 40.5 | 39.2 | 44.5 | 37.0 | 35.4 | 46.4 | 51.2 | 40.5 | 35.6 | 41.7 | 30.7 | 33.9 | 39.1 |
| 文献[ | 35.9 | 40.3 | 36.7 | 41.4 | 39.1 | 43.4 | 37.1 | 35.5 | 46.2 | 59.7 | 39.9 | 38.0 | 41.9 | 32.9 | 34.2 | 39.9 |
| MCFNet[ | 37.7 | 35.4 | 39.1 | 40.0 | 44.4 | 36.7 | 34.3 | 52.4 | 39.9 | 35.2 | 41.7 | 30.6 | 33.9 | 38.7 | ||
| 文献[ | 33.4 | 33.3 | 42.3 | 45.8 | 36.7 | 35.6 | 24.0 | 24.5 | ||||||||
| 本文模型(T=81) | 33.4 | 36.2 | 35.1 | 36.0 | 32.2 | 32.1 | 45.1 | 48.3 | 32.9 | 35.4 |
表2 不同模型在Human3.6M数据集上的p-MPJPE (mm)
Tab. 2 p-MPJPE of different models on Human3.6M dataset
| 模型 | Dir | Disc | Eat | Gree | Phon | Phot | Pose | Purc | Sit | SitD | Smok | Wait | WalkD | Walk | WalkT. | Avg. |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 文献[ | 35.9 | 40.0 | 38.0 | 41.5 | 42.5 | 51.4 | 37.8 | 36.0 | 48.6 | 56.6 | 41.8 | 38.3 | 42.7 | 31.7 | 36.2 | 41.2 |
| 文献[ | 35.7 | 38.6 | 36.3 | 40.5 | 39.2 | 44.5 | 37.0 | 35.4 | 46.4 | 51.2 | 40.5 | 35.6 | 41.7 | 30.7 | 33.9 | 39.1 |
| 文献[ | 35.9 | 40.3 | 36.7 | 41.4 | 39.1 | 43.4 | 37.1 | 35.5 | 46.2 | 59.7 | 39.9 | 38.0 | 41.9 | 32.9 | 34.2 | 39.9 |
| MCFNet[ | 37.7 | 35.4 | 39.1 | 40.0 | 44.4 | 36.7 | 34.3 | 52.4 | 39.9 | 35.2 | 41.7 | 30.6 | 33.9 | 38.7 | ||
| 文献[ | 33.4 | 33.3 | 42.3 | 45.8 | 36.7 | 35.6 | 24.0 | 24.5 | ||||||||
| 本文模型(T=81) | 33.4 | 36.2 | 35.1 | 36.0 | 32.2 | 32.1 | 45.1 | 48.3 | 32.9 | 35.4 |
| 模型 | S1 | S2 | S3 | Avg. |
|---|---|---|---|---|
| 文献[ | 19.7 | 46.8 | 27.9 | |
| 文献[ | 22.3 | 19.5 | 29.7 | 23.8 |
| 文献[ | 19.9 | |||
| 本文模型 | 15.2 | 12.3 | 40.8 | 22.7 |
表3 HumanEva-Ⅰ数据集上的p-MPJPE (mm)
Tab. 3 p-MPJPE on HumanEva-Ⅰ dataset
| 模型 | S1 | S2 | S3 | Avg. |
|---|---|---|---|---|
| 文献[ | 19.7 | 46.8 | 27.9 | |
| 文献[ | 22.3 | 19.5 | 29.7 | 23.8 |
| 文献[ | 19.9 | |||
| 本文模型 | 15.2 | 12.3 | 40.8 | 22.7 |
输入 帧长度 | 模型 | Human3.6M数据集 | ||
|---|---|---|---|---|
| 参数量/106 | 计算量/GFLOPs | MPJPE/mm | ||
| 27 | 文献[ | 8.56 | 0.017 | 48.8 |
| 文献[ | 31.88 | 0.061 | 45.3 | |
| 本文模型 | 7.01 | 0.057 | 44.7 | |
| 81 | 文献[ | 12.75 | 0.025 | 47.7 |
| 文献[ | 45.53 | 0.088 | 44.6 | |
| 本文模型 | 7.06 | 0.082 | 43.5 | |
| 243 | 文献[ | 16.95 | 0.033 | 46.8 |
| 文献[ | 59.10 | 0.116 | 44.1 | |
| 本文模型 | 7.41 | 0.112 | 42.9 | |
表4 不同输入帧长度下模型的参数量与仿真分析效果
Tab. 4 Parameters and simulation analysis effects of models under different input frame lengths
输入 帧长度 | 模型 | Human3.6M数据集 | ||
|---|---|---|---|---|
| 参数量/106 | 计算量/GFLOPs | MPJPE/mm | ||
| 27 | 文献[ | 8.56 | 0.017 | 48.8 |
| 文献[ | 31.88 | 0.061 | 45.3 | |
| 本文模型 | 7.01 | 0.057 | 44.7 | |
| 81 | 文献[ | 12.75 | 0.025 | 47.7 |
| 文献[ | 45.53 | 0.088 | 44.6 | |
| 本文模型 | 7.06 | 0.082 | 43.5 | |
| 243 | 文献[ | 16.95 | 0.033 | 46.8 |
| 文献[ | 59.10 | 0.116 | 44.1 | |
| 本文模型 | 7.41 | 0.112 | 42.9 | |
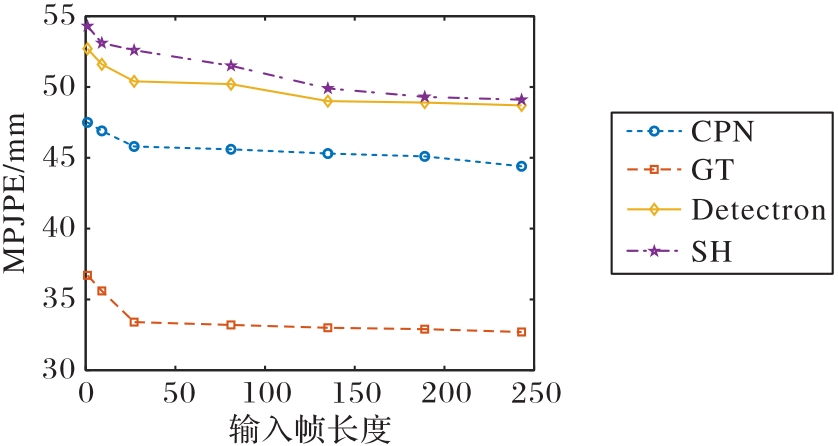
图7 不同2D姿态检测器上和不同输入帧长度的输出下的MPJPE预测结果
Fig. 7 MPJPE prediction results on different 2D pose detectors under output with different input frame lengths
| 输入帧长度 | 窗口大小 | MPJPE/mm |
|---|---|---|
| 27 | 9 | 45.6 |
| 3 | 44.7 | |
| 1 | 45.3 | |
| 81 | 9 | 43.9 |
| 3 | 43.5 | |
| 1 | 44.3 | |
| 243 | 9 | 43.2 |
| 3 | 42.9 | |
| 1 | 44.0 |
表5 不同滑动窗口大小下的模型性能
Tab. 5 Model performance under different sliding window sizes
| 输入帧长度 | 窗口大小 | MPJPE/mm |
|---|---|---|
| 27 | 9 | 45.6 |
| 3 | 44.7 | |
| 1 | 45.3 | |
| 81 | 9 | 43.9 |
| 3 | 43.5 | |
| 1 | 44.3 | |
| 243 | 9 | 43.2 |
| 3 | 42.9 | |
| 1 | 44.0 |
| 隐藏层维度 | 层数 | MPJPE/mm |
|---|---|---|
| 64 | 2 | 44.5 |
| 3 | 44.2 | |
| 4 | 45.1 | |
| 128 | 2 | 44.1 |
| 3 | 43.5 | |
| 4 | 44.8 | |
| 256 | 2 | 45.1 |
| 3 | 44.9 | |
| 4 | 45.8 |
表6 图卷积模型的不同超参数分析结果
Tab. 6 Analysis results of different hyperparameters for graph convolutional model
| 隐藏层维度 | 层数 | MPJPE/mm |
|---|---|---|
| 64 | 2 | 44.5 |
| 3 | 44.2 | |
| 4 | 45.1 | |
| 128 | 2 | 44.1 |
| 3 | 43.5 | |
| 4 | 44.8 | |
| 256 | 2 | 45.1 |
| 3 | 44.9 | |
| 4 | 45.8 |
| 模型 | MPJPE | 性能差值 |
|---|---|---|
| 本文模型 | 45.7 | |
| 本文模型去除STCN | 47.5 | 1.8 |
| 本文模型去除PGCN | 49.9 | 4.2 |
| 本文模型去除EGAT | 48.6 | 2.9 |
表7 本文模型中不同模块的消融实验结果 (mm)
Tab. 7 Ablation experimental results for different modules in proposed model
| 模型 | MPJPE | 性能差值 |
|---|---|---|
| 本文模型 | 45.7 | |
| 本文模型去除STCN | 47.5 | 1.8 |
| 本文模型去除PGCN | 49.9 | 4.2 |
| 本文模型去除EGAT | 48.6 | 2.9 |
| 模型连接方式 | MPJPE |
|---|---|
| 并联 | 45.7 |
| 串联 | 46.3 |
表8 PGCN和EGAT在模型中不同连接方式的结果对比 (mm)
Tab. 8 Results comparison under different connection methods of PGCN and EGAT in model
| 模型连接方式 | MPJPE |
|---|---|
| 并联 | 45.7 |
| 串联 | 46.3 |
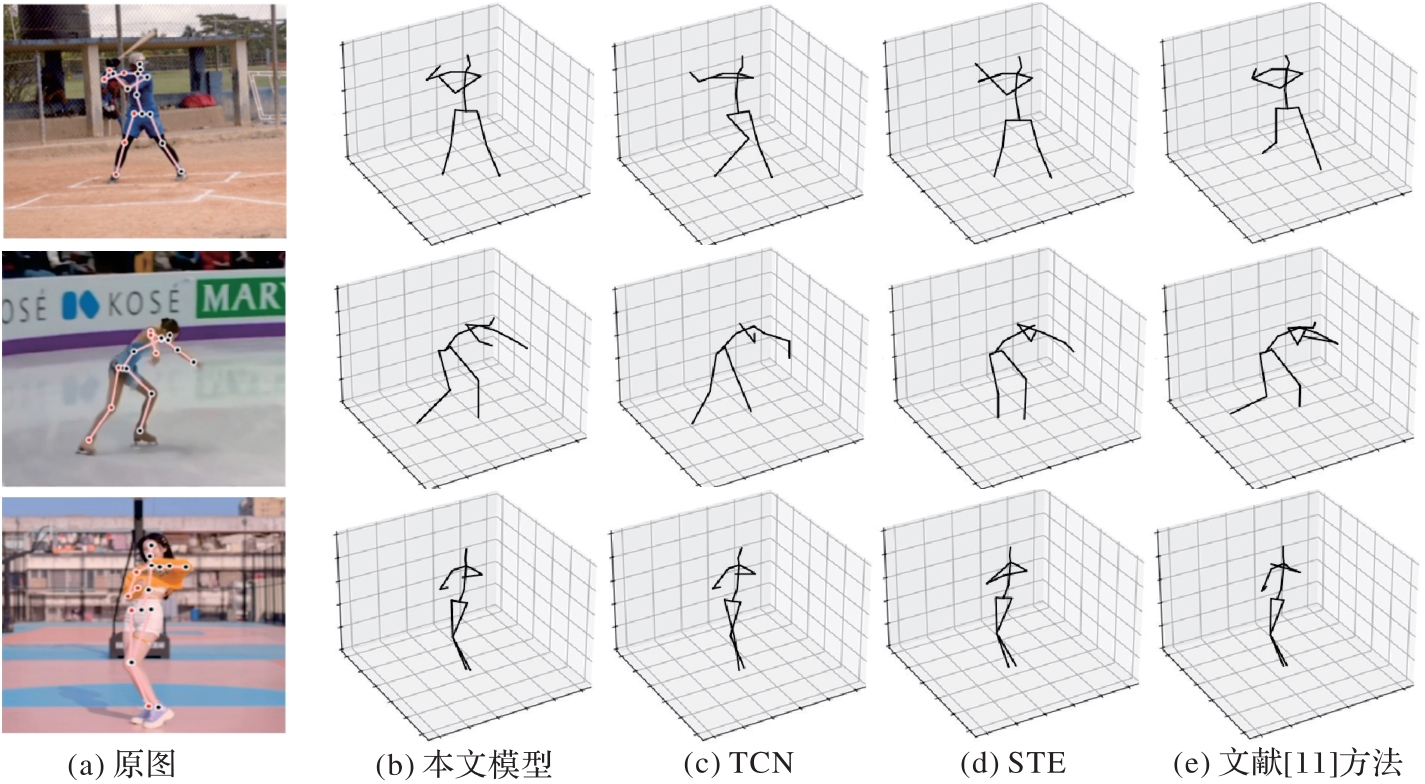
图8 本文模型与先进模型的定性比较
Fig. 8 Qualitative comparison of proposed model with state-of-the-art models
| [1] | ZHAO T, LI S, NGAN K N, et al. 3-D reconstruction of human body shape from a single commodity depth camera[J]. IEEE Transactions on Multimedia, 2019, 21(1): 114-123. |
| [2] | MARTINEZ J, HOSSAIN R, ROMERO J, et al. A simple yet effective baseline for 3D human pose estimation[C]// Proceedings of the 2017 IEEE International Conference on Computer Vision. Piscataway: IEEE, 2017: 2659-2668. |
| [3] | PAVLLO D, FEICHTENHOFER C, GRANGIER D, et al. 3D human pose estimation in video with temporal convolutions and semi-supervised training[C]// Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2019: 7745-7754. |
| [4] | HUA G, LI W, ZHANG Q, et al. Weakly-supervised 3D human pose estimation with cross-view U-shaped graph convolutional network[J]. IEEE Transactions on Multimedia, 2023, 25: 1832-1843. |
| [5] | LEE K, LEE I, LEE S. Propagating LSTM: 3D pose estimation based on joint interdependency[C]// Proceedings of the 2018 European Conference on Computer Vision, LNCS 11211. Cham: Springer, 2018: 123-141. |
| [6] | HOSSAIN M R I, LITTLE J J. Exploiting temporal information for 3D human pose estimation[C]// Proceedings of the 2018 European Conference on Computer Vision, LNCS 11214. Cham: Springer, 2018: 69-86. |
| [7] | CAI Y, GE L, LIU J, et al. Exploiting spatial-temporal relationships for 3D pose estimation via graph convolutional networks[C]// Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision. Piscataway: IEEE, 2019: 2272-2281. |
| [8] | 谭大艺,田炜,熊璐. 融合双序列姿态的驾驶员行为识别方法[J/OL]. 计算机工程与应用, [2024-11-26]. . |
| TAN D Y, TIAN W, XIONG L. Driver behavior recognition method using dual-sequence pose integration[J/OL]. Computer Engineering and Applications [2024-11-26]. . | |
| [9] | LI W, LIU H, DING R, et al. Exploiting temporal contexts with strided Transformer for 3D human pose estimation[J]. IEEE Transactions on Multimedia, 2023, 25:1282-1293. |
| [10] | WANG B, SHU Y, FU X, et al. Enhanced limb constraints and global attention integration for 3D human pose estimation[C]// Proceedings of the 7th International Conference on Advanced Algorithms and Control Engineering. Piscataway: IEEE, 2024: 278-282. |
| [11] | ZHANG L, SHAO X, LI Z, et al. Spatio-temporal attention graph for monocular 3D human pose estimation[C]// Proceedings of the 2022 IEEE International Conference on Image Processing. Piscataway: IEEE, 2022: 1231-1235. |
| [12] | ZHAO L, PENG X, TIAN Y, et al. Semantic graph convolutional networks for 3D human pose regression[C]// Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2019: 3420-3430. |
| [13] | 齐绪兴,徐成,曾凤彩,等. 基于深度学习的人体姿态估计综述 [C]// 中国计算机用户协会网络应用分会2024年第二十八届网络新技术与应用年会论文集. 北京: 中国计算机用户协会, 2024: 280-283. |
| QI X X, XU C, ZENG F C, et al. Review of human pose estimation based on deep learning[C]// Proceedings of the 2024 28th Annual Conference on Network New Technologies and Applications by the Network Application Branch of the China Computer Users Association. Beijing: China Computer Users Association, 2024: 280-283. | |
| [14] | XU Y L, WANG W, LIU T, et al. Monocular 3D pose estimation via pose grammar and data augmentation[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2022, 44(10):6327-6344. |
| [15] | LIU Y, HEL-OR H, KAPLAN C S, et al. Computational symmetry in computer vision and computer graphics[J]. Foundations and Trends® in Computer Graphics and Vision, 2010, 5(1/2):1-195. |
| [16] | 闫永杰,李敏奇. 融合图卷积与Transformer的三维人体姿态估计网络[J]. 自动化应用, 2024, 65(13):71-75, 86. |
| YAN Y J, LI M Q. 3D human pose estimation network combining graph convolution and Transformer[J]. Automation Application, 2024, 65(13): 71-75, 86. | |
| [17] | LI W, LIU H, TANG H, et al. MHFormer: multi-hypothesis Transformer for 3D human pose estimation[C]// Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2022: 13137-13146. |
| [18] | SHI L, ZHANG Y F, CHENG J, et al. Two-stream adaptive graph convolutional networks for skeleton-based action recognition[C]// Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2019: 12018-12027. |
| [19] | ZOU Z, LIU T, WU D, et al. Compositional graph convolutional networks for 3D human pose estimation[C]// Proceedings of the 16th IEEE International Conference on Automatic Face and Gesture Recognition. Piscataway: IEEE, 2021:1-8. |
| [20] | BOUDAA B, TOUHAMI H. A graph attention networks model for session-based recommender systems[C]// Proceedings of the 2023 International Conference on Networking and Advanced Systems. Piscataway: IEEE, 2023: 70-73. |
| [21] | GU K, YANG L, MI M B, et al. Bias-compensated integral regression for human pose estimation[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2023, 45(9): 10687-10702. |
| [22] | PAVLAKOS G, ZHOU X, DERPANIS K G, et al. Coarse-to-fine volumetric prediction for single-image 3D human pose[C]// Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2017: 1263-1272. |
| [23] | FANG H S, XU Y, WANG W, et al. Learning pose grammar to encode human body configuration for 3D pose estimation[C]// Proceedings of the 32nd AAAI Conference on Artificial Intelligence. Palo Alto: AAAI Press, 2018: 6821-6828. |
| [24] | SCHIRMER L, LUCIO D, CRUZ L, et al. SGAT: semantic graph attention for 3D human pose estimation[C]// Proceedings of the 34th SIBGRAPI Conference on Graphics, Patterns and Images. Piscataway: IEEE, 2021: 255-262. |
| [25] | YAN S, XIONG Y, LIN D, et al. Spatial temporal graph convolutional networks for skeleton-based action recognition[C]// Proceedings of the 32nd AAAI Conference on Artificial Intelligence. Palo Alto: AAAI Press, 2018:7444-7452. |
| [26] | LIU J, DING H, SHAHROUDY A, et al. Feature boosting network for 3D pose estimation[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2020, 42(2):494-501. |
| [27] | SIGAL L, BALAN A O, BLACK M J. HumanEva: synchronized video and motion capture dataset and baseline algorithm for evaluation of articulated human motion[J]. International Journal of Computer Vision, 2010, 87(1/2): 4-27. |
| [28] | XU T, TAKANO W. Graph stacked hourglass networks for 3D human pose estimation[C]// Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2021: 16100-16109. |
| [29] | GONG K, ZHANG J, FENG J. PoseAug: a differentiable pose augmentation framework for 3D human pose estimation[C]// Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2021: 8571-8580. |
| [30] | ZOU J, SHAO M, XIA S. GraphRPE: relative position encoding graph Transformer for 3D human pose estimation[C]// Proceedings of the 2023 IEEE International Conference on Image Processing. Piscataway: IEEE, 2023: 895-899. |
| [31] | XUE Y, CHEN J, GU X, et al. Boosting monocular 3D human pose estimation with part aware attention[J]. IEEE Transactions on Image Processing, 2022, 31: 4278-4291. |
| [32] | LI M, CHEN S, ZHAO Y, et al. Dynamic multiscale graph neural networks for 3D skeleton based human motion prediction[C]// Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2020: 211-220. |
| [33] | LIU Y. Study on human pose estimation based on channel and spatial attention[C]// Proceedings of the 3rd International Conference on Consumer Electronics and Computer Engineering. Piscataway: IEEE, 2023: 47-50. |
| [34] | JANGADE J, BABULAL K S. Study on deep learning models for human pose estimation and its real time application[C]// Proceedings of the 6th International Conference on Information Systems and Computer Networks. Piscataway: IEEE, 2023:1-6. |
| [35] | LIU H, REN C. An effective 3D human pose estimation method based on dilated convolutions for videos[C]// Proceedings of the 2019 IEEE International Conference on Robotics and Biomimetics. Piscataway: IEEE, 2019:2327-2331. |
| [36] | LUTZ S, BLYTHMAN R, GHOSAL K, et al. Jointformer: single-frame lifting Transformer with error prediction and refinement for 3D human pose estimation[C]// Proceedings of the 26th International Conference on Pattern Recognition. Piscataway: IEEE, 2022: 1156-1163. |
| [37] | ZHAI K, NIE Q, OUYANG B, et al. HopFIR: hop-wise GraphFormer with intragroup joint refinement for 3D human pose estimation[C]// Proceedings of the 2023 IEEE/CVF International Conference on Computer Vision. Piscataway: IEEE, 2023: 14939-14949. |
| [38] | WANG D, LIU R, YI P, et al. MCFNet: multi-scale cross fusion network for 3D human pose estimation[C]// Proceedings of the 9th International Conference on Signal and Image Processing. Piscataway: IEEE, 2024: 684-688. |
| [39] | KANG N, CHEN G, ZHANG C, et al. A Transformer-based approach for 3D human pose estimation in rehabilitation exercise movements[C]// Proceedings of the 5th International Conference on Computer Vision, Image and Deep Learning. Piscataway: IEEE, 2024: 424-429. |
| [40] | CHOI J, SHIM D, KIM H J. DiffuPose: monocular 3D human pose estimation via denoising diffusion probabilistic model[C]// Proceedings of the 2023 IEEE/RSJ International Conference on Intelligent Robots and Systems. Piscataway: IEEE, 2023: 3773-3780. |
| [41] | CHEN T, FANG C, SHEN X, et al. Anatomy-aware 3D human pose estimation with bone based pose decomposition[J]. IEEE Transactions on Circuits and Systems for Video Technology, 2022, 32(1): 198-209. |
| [42] | NEWELL A, YANG K, DENG J. Stacked hourglass networks for human pose estimation[C]// Proceedings of the 2016 European Conference on Computer Vision, LNCS 9912. Cham: Springer, 2016: 483-499. |
| [43] | 刘星,王宇晶. 基于双循环Transformer的三维人体姿态估计[J]. 传感技术学报, 2024, 37(7):1236-1243. |
| LIU X, WANG Y J. 3D human pose estimation based on dual circulation Transformer[J]. Chinese Journal of Sensors and Actuators, 2024, 37(7): 1236-1243. |
| [1] | 魏利利, 闫丽蓉, 唐晓芬. 上下文语义表征和像素关系纠正的小样本目标检测[J]. 《计算机应用》唯一官方网站, 2025, 45(9): 2993-3002. |
| [2] | 张硕, 孙国凯, 庄园, 冯小雨, 王敬之. 面向区块链节点分析的eclipse攻击动态检测方法[J]. 《计算机应用》唯一官方网站, 2025, 45(8): 2428-2436. |
| [3] | 俞凯乐, 廖家俊, 毛嘉莉, 黄小鹏. 多约束条件下钢铁物流车货匹配的多目标优化[J]. 《计算机应用》唯一官方网站, 2025, 45(8): 2477-2483. |
| [4] | 闫家鑫, 陈艳平, 杨卫哲, 黄瑞章, 秦永彬. 基于特征组合的异构图注意力网络关系抽取[J]. 《计算机应用》唯一官方网站, 2025, 45(8): 2470-2476. |
| [5] | 李嘉欣, 莫思特. 基于MiniRBT-LSTM-GAT与标签平滑的台区电力工单分类[J]. 《计算机应用》唯一官方网站, 2025, 45(4): 1356-1362. |
| [6] | 胡健鹏, 张立臣. 面向多时间步风功率预测的深度时空网络模型[J]. 《计算机应用》唯一官方网站, 2025, 45(1): 98-105. |
| [7] | 朱亮, 慕京哲, 左洪强, 谷晶中, 朱付保. 基于联邦图神经网络的位置隐私保护推荐方案[J]. 《计算机应用》唯一官方网站, 2025, 45(1): 136-143. |
| [8] | 杨航, 李汪根, 张根生, 王志格, 开新. 基于图神经网络的多层信息交互融合算法用于会话推荐[J]. 《计算机应用》唯一官方网站, 2024, 44(9): 2719-2725. |
| [9] | 顾焰杰, 张英俊, 刘晓倩, 周围, 孙威. 基于时空多图融合的交通流量预测[J]. 《计算机应用》唯一官方网站, 2024, 44(8): 2618-2625. |
| [10] | 柯添赐, 刘建华, 孙水华, 郑智雄, 蔡子杰. 融合强关联依赖和简洁语法的方面级情感分析模型[J]. 《计算机应用》唯一官方网站, 2024, 44(6): 1786-1795. |
| [11] | 郭洁, 林佳瑜, 梁祖红, 罗孝波, 孙海涛. 基于知识感知和跨层次对比学习的推荐方法[J]. 《计算机应用》唯一官方网站, 2024, 44(4): 1121-1127. |
| [12] | 郭磊, 贾真, 李天瑞. 面向方面级情感分析的交互式关系图注意力网络[J]. 《计算机应用》唯一官方网站, 2024, 44(3): 696-701. |
| [13] | 徐大鹏, 侯新民. 基于网络结构设计的图神经网络特征选择方法[J]. 《计算机应用》唯一官方网站, 2024, 44(3): 663-670. |
| [14] | 王利琴, 张特, 许智宏, 董永峰, 杨国伟. 融合实体语义及结构信息的知识图谱推理[J]. 《计算机应用》唯一官方网站, 2024, 44(11): 3371-3378. |
| [15] | 蒋汶娟, 过弋, 付娇娇. 融合图注意力的复杂时序知识图谱推理问答模型[J]. 《计算机应用》唯一官方网站, 2024, 44(10): 3047-3057. |
| 阅读次数 | ||||||
|
全文 |
|
|||||
|
摘要 |
|
|||||