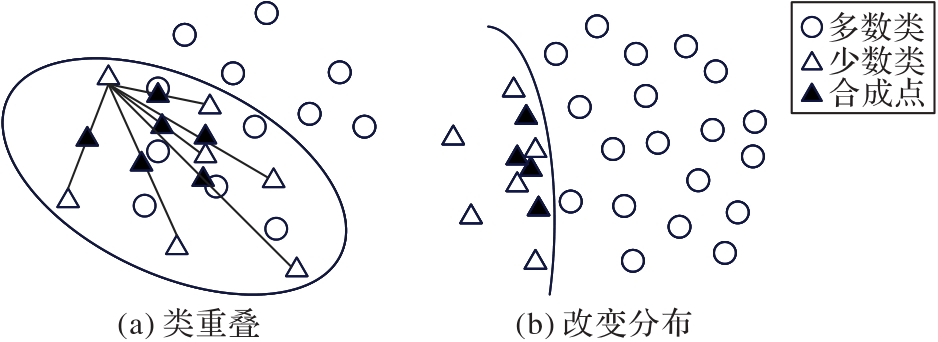
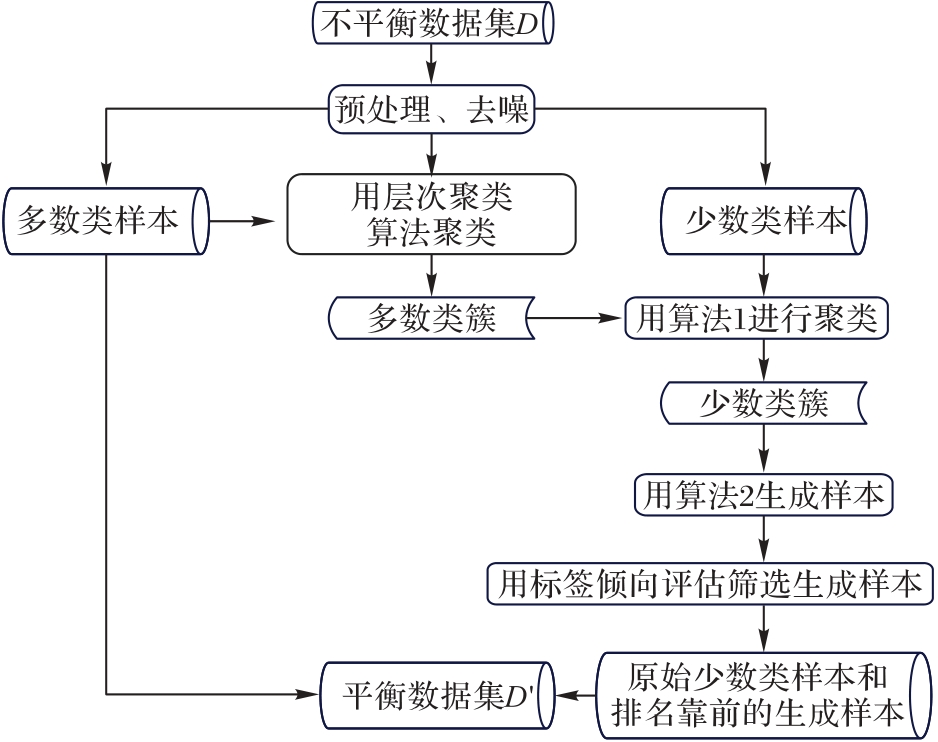
| [1] |
CHANDOLA V, BANERJEE A, KUMAR V. Anomaly detection: a survey [J]. ACM Computing Surveys, 2009, 41(3): No.15.
|
| [2] |
SHATNAWI R. Improving software fault-prediction for imbalanced data [C]// Proceedings of the 2012 International Conference on Innovations in Information Technology. Piscataway: IEEE, 2012: 54-59.
|
| [3] |
FAWCETT T, PROVOST F. Adaptive fraud detection [J]. Data Mining and Knowledge Discovery, 1997, 1(3): 291-316.
|
| [4] |
KRAWCZYK B, GALAR M, JELEŃ Ł, et al. Evolutionary undersampling boosting for imbalanced classification of breast cancer malignancy [J]. Applied Soft Computing, 2016, 38: 714-726.
|
| [5] |
VUTTIPITTAYAMONGKOL P, ELYAN E. Overlap-based undersampling method for classification of imbalanced medical datasets [C]// Proceedings of the 2020 International Conference on Artificial Intelligence Applications and Innovations, IFIPAICT 584. Cham: Springer, 2020: 358-369.
|
| [6] |
MAJID A, ALI S, IQBAL M, et al. Prediction of human breast and colon cancers from imbalanced data using nearest neighbor and support vector machines [J]. Computer Methods and Programs in Biomedicine, 2014, 113(3): 792-808.
|
| [7] |
LIU Y, LOH H T, SUN A. Imbalanced text classification: a term weighting approach [J]. Expert Systems with Applications, 2009, 36(1): 690-701.
|
| [8] |
MEHMOOD Z, ASGHAR S. Customizing SVM as a base learner with AdaBoost ensemble to learn from multi-class problems: a hybrid approach AdaBoost-MSVM [J]. Knowledge-Based Systems, 2021, 217: No.106845.
|
| [9] |
PURWAR A, SINGH S K. A novel ensemble classifier by combining sampling and genetic algorithm to combat multiclass imbalanced problems [J]. International Journal of Data Analysis Techniques and Strategies, 2020, 12(1): 30-42.
|
| [10] |
CHAWLA N V, BOWYER K W, HALL L O, et al. SMOTE: synthetic minority over-sampling technique [J]. Journal of Artificial Intelligence Research, 2002, 16: 321-357.
|
| [11] |
HAN H, WANG W Y, MAO B H. Borderline-SMOTE: a new over-sampling method in imbalanced data sets learning [C]// Proceedings of the 2005 International Conference on Intelligent Computing, LNCS 3644. Berlin: Springer, 2005: 878-887.
|
| [12] |
HE H, BAI Y, GARCIA E A, et al. ADASYN: adaptive synthetic sampling approach for imbalanced learning [C]// Proceedings of the 2008 IEEE International Joint Conference on Neural Networks (IEEE World Congress on Computational Intelligence). Piscataway: IEEE, 2008: 1322-1328.
|
| [13] |
MA L, FAN S. CURE-SMOTE algorithm and hybrid algorithm for feature selection and parameter optimization based on random forests [J]. BMC Bioinformatics, 2017, 18: No.169.
|
| [14] |
MACIEJEWSKI T, STEFANOWSKI J. Local neighbourhood extension of SMOTE for mining imbalanced data [C]// Proceedings of the 2011 IEEE Symposium on Computational Intelligence and Data Mining. Piscataway: IEEE, 2011: 104-111.
|
| [15] |
ABDI L, HASHEMI S. To combat multi-class imbalanced problems by means of over-sampling techniques [J]. IEEE Transactions on Knowledge and Data Engineering, 2016, 28(1): 238-251.
|
| [16] |
NEKOOEIMEHR I, LAI-YUEN S K. Adaptive Semi-Unsupervised Weighted Oversampling (A-SUWO) for imbalanced datasets [J]. Expert Systems with Applications, 2016, 46: 405-416.
|
| [17] |
DOUZAS G, BACAO F, LAST F. Improving imbalanced learning through a heuristic oversampling method based on k-means and SMOTE [J]. Information Sciences, 2018, 465: 1-20.
|
| [18] |
YUN J, HA J, LEE J S. Automatic determination of neighborhood size in SMOTE [C]// Proceedings of the 10th International Conference on Ubiquitous Information Management and Communication. New York: ACM, 2016: No.100.
|
| [19] |
TSAI C F, LIN W C, HU Y H, et al. Under-sampling class imbalanced datasets by combining clustering analysis and instance selection [J]. Information Sciences, 2019, 477: 47-54.
|
| [20] |
XIE X, LIU H, ZENG S, et al. A novel progressively undersampling method based on the density peaks sequence for imbalanced data [J]. Knowledge-Based Systems, 2021, 213: No.106689.
|
| [21] |
MOUTAOUAKIL K EL, ROUDANI M, OUISSARI A EL. Optimal Entropy Genetic Fuzzy-C-Means SMOTE (OEGFCM-SMOTE) [J]. Knowledge-Based Systems, 2023, 262: No.110235.
|
| [22] |
SALEHI A R, KHEDMATI M. A Cluster-based SMOTE Both-Sampling (CSBBoost) ensemble algorithm for classifying imbalanced data [J]. Scientific Reports, 2024, 14: No.5152.
|
| [23] |
VOORHEES E M. Implementing agglomerative hierarchic clustering algorithms for use in document retrieval [J]. Information Processing and Management, 1986, 22(6): 465-476.
|
| [24] |
陈静纯,袁春锋,谈芳,等.基于倾向评分匹配法的家庭医生签约对居民医疗健康服务获得感的影响[J].现代预防医学,2023, 50(18): 3347-3351.
|
|
CHEN J C, YUAN C F, TAN F, et al. The impact of contracted family doctor on residents’ medical and health service acquisition sense based on propensity score matching method [J]. Modern Preventive Medicine, 2023, 50(18): 3347-3351.
|
| [25] |
李蒙蒙,刘艺,李庚松,等.不平衡多分类算法综述[J].计算机应用,2022, 42(11): 3307-3321.
|
|
LI M M, LIU Y, LI G S, et al. Survey on imbalanced multi-class classification algorithms [J]. Journal of Computer Applications, 2022, 42(11): 3307-3321.
|


 ), 张宏扬1,2,3, 李雨欣1,2,3
), 张宏扬1,2,3, 李雨欣1,2,3