


《计算机应用》唯一官方网站 ›› 2026, Vol. 46 ›› Issue (4): 1158-1170.DOI: 10.11772/j.issn.1001-9081.2025040474
• 网络空间安全 • 上一篇
王晓宇1, 李欣1,2,3( ), 薛迪1, 蒋章涛1, 王威1, 肖岩军4
), 薛迪1, 蒋章涛1, 王威1, 肖岩军4
收稿日期:2025-04-29
修回日期:2025-06-26
接受日期:2025-06-27
发布日期:2025-07-07
出版日期:2026-04-10
通讯作者:
李欣
作者简介:王晓宇(2001—),女,湖北宜昌人,硕士研究生,CCF会员,主要研究方向:大语言模型、风险评估基金资助:
Xiaoyu WANG1, Xin LI1,2,3(), Di XUE1, Zhangtao JIANG1, Wei WANG1, Yanjun XIAO4
Received:2025-04-29
Revised:2025-06-26
Accepted:2025-06-27
Online:2025-07-07
Published:2026-04-10
Contact:
Xin LI
About author:WANG Xiaoyu, born in 2001, M. S. candidate. Her research interests include large language models, risk assessment.Supported by:摘要:
视频监控网络中的安全漏洞危害公共安全乃至国家安全。面对安全威胁的持续演进,亟须增量学习方法。然而,现有方法面临少样本学习性能不足、语义模糊致分类偏差和动态扩展新类别能力受限这三大挑战,导致增量学习分类失准。因此,提出一种基于大语言模型(LLM)的增量漏洞分类框架(IVCF-LLM),该框架采用数据分层与动态阈值机制确保训练数据的均衡分布。在顶层分类阶段,首先,利用GPT-4o深层分析环节从少量样本中提取漏洞触发词,生成高质量分类提示词模板(即技能);其次,优化关键词提取机制,精准识别漏洞成因和攻击方式,匹配出最优技能指导GPT-3.5 Turbo实现准确分类;最后,引入知识蒸馏技术实现新旧技能的无缝融合,完成类别增量学习(CIL)。在子层分类阶段,通过构建常见弱点列举(CWE)知识图谱,结合静态知识注入与动态关系检索策略,实现细粒度精准分类。实验结果表明,在自建数据集上,IVCF-LLM在准确率和马修斯相关系数(MCC)上分别达到了75.0%和65.7%,均优于文本到弱点映射(Text2Weak)、语义常见弱点列举预测器(SCP)和提示词分类等模型;在通用网络安全数据集上,IVCF-LLM的准确率显著优于SCP模型15.9个百分点,验证了所提框架的有效性和跨场景稳定性。
中图分类号:
王晓宇, 李欣, 薛迪, 蒋章涛, 王威, 肖岩军. 基于大语言模型的视频监控网络安全漏洞分类框架[J]. 计算机应用, 2026, 46(4): 1158-1170.
Xiaoyu WANG, Xin LI, Di XUE, Zhangtao JIANG, Wei WANG, Yanjun XIAO. Vulnerability classification framework for video surveillance network security based on large language models[J]. Journal of Computer Applications, 2026, 46(4): 1158-1170.
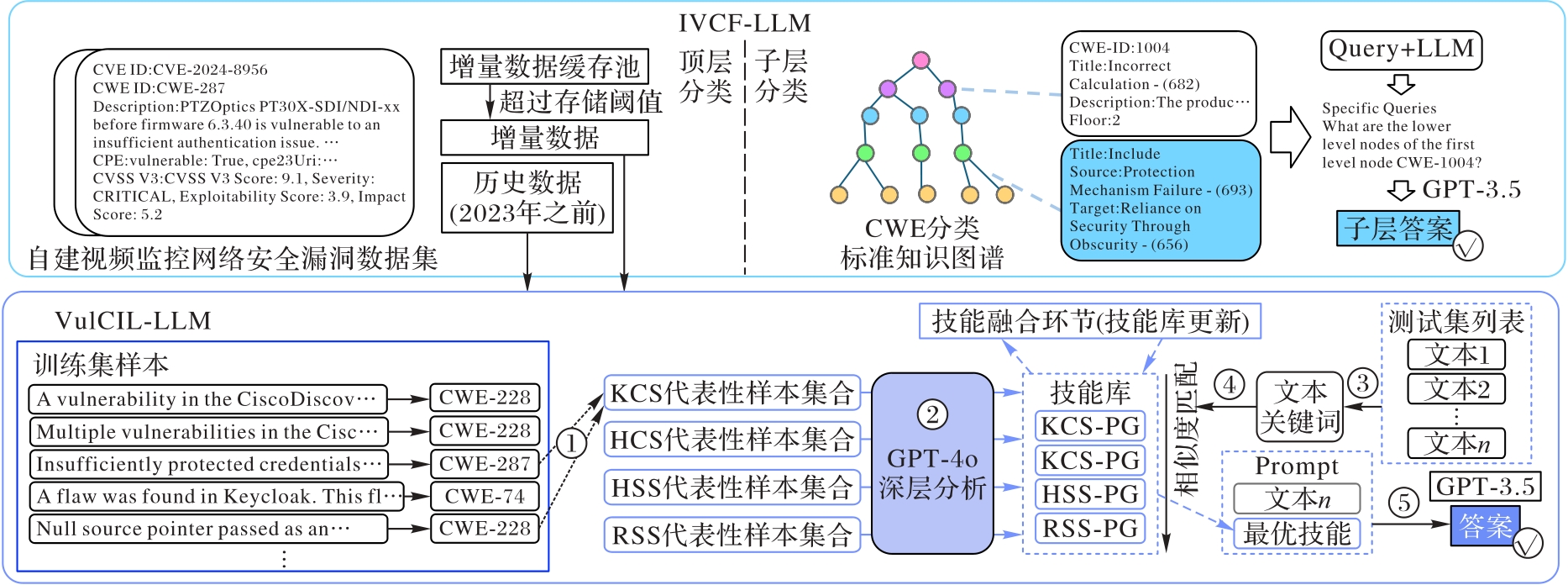
图1 IVCF-LLM的整体架构
Fig. 1 Overall architecture of IVCF-LLM

图2 数据收集与预处理流程
Fig. 2 Flow of data collection and pre-processing
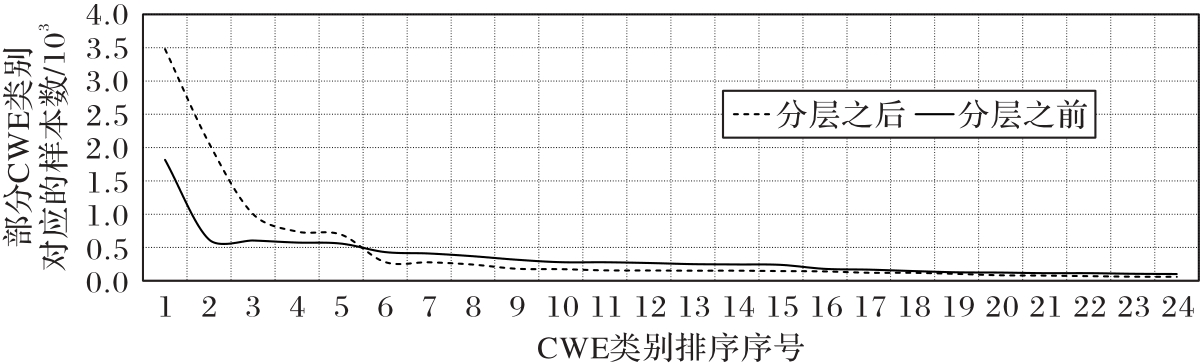
图3 分层前后CWE类别数据的分布对比
Fig. 3 Comparison of CWE data distribution before and after stratification
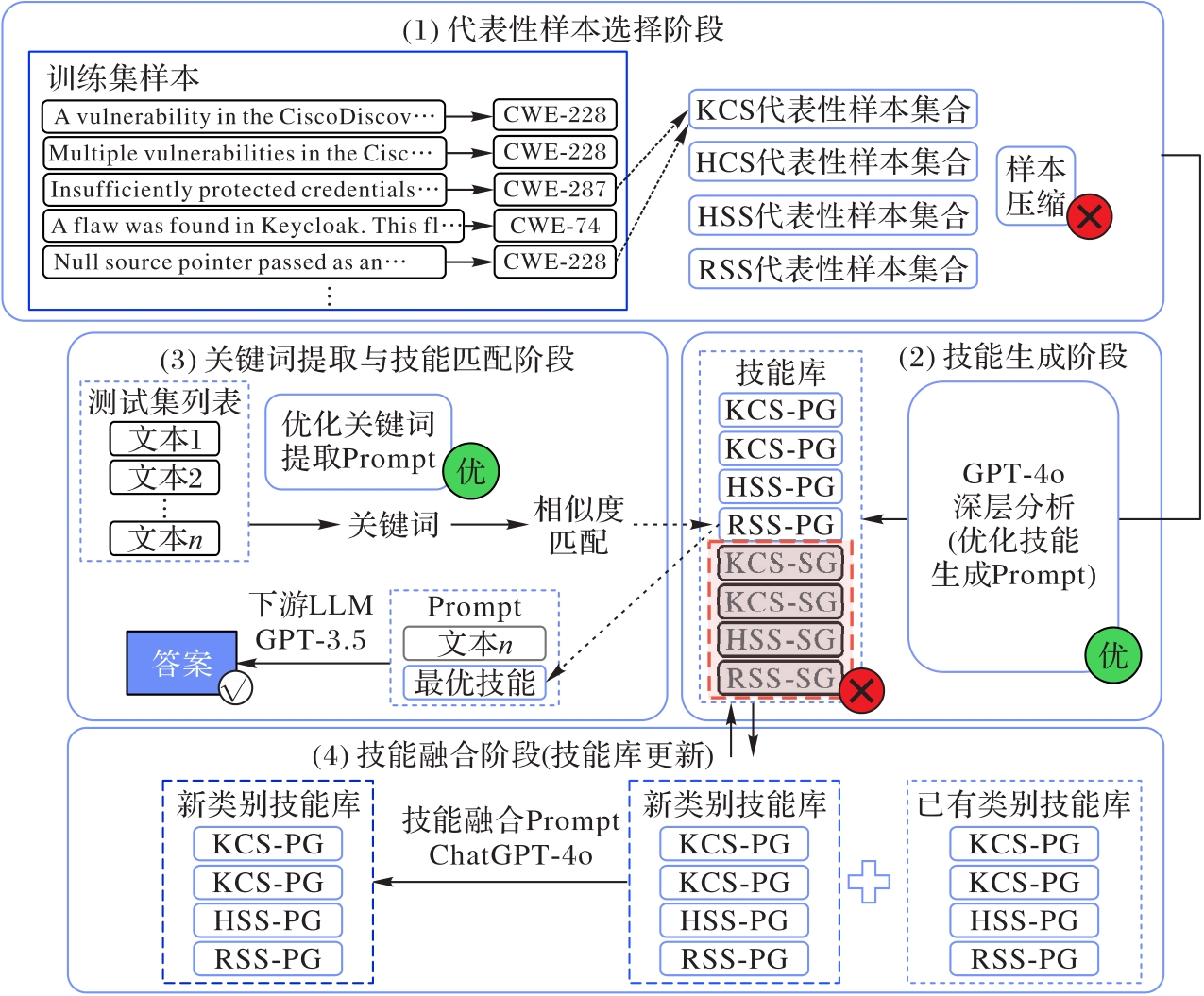
图4 VulCIL-LLM框架的流程
Fig. 4 Flow of VulCIL-LLM framework

图5 技能生成示例
Fig. 5 Example of skill generation
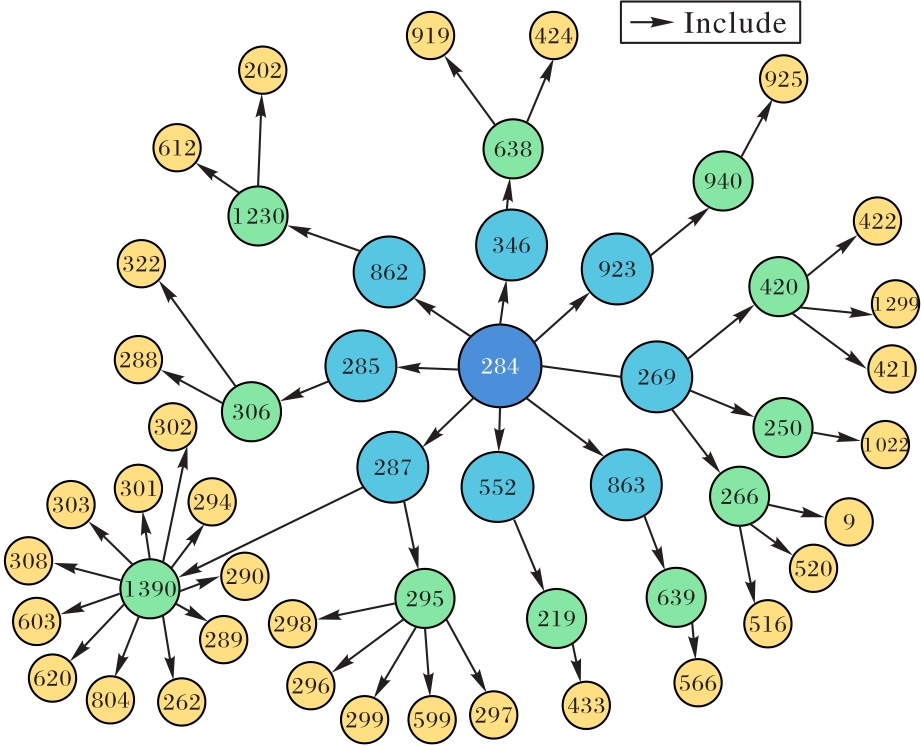
图6 CWE-284多层级节点的父子关系图
Fig. 6 Parent-child relationship diagram of CWE-284 multi-level nodes
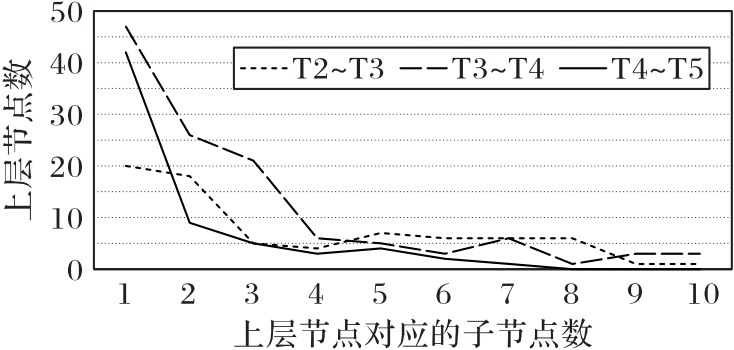
图7 各层子节点数的分布
Fig. 7 Distribution of number of sub-nodes in each layer
| 层级 | 总样本数N | 类别数 | |||
|---|---|---|---|---|---|
| DT2-init | 5 676 | 21 | 1 600 | 2 038 | 2 038 |
| DT2-new | 4 742 | 26 | 480 | 2 131 | 2 131 |
| DT3 | 8 427 | 124 | 0 | 0 | 8 427 |
| DT4 | 5 624 | 65 | 0 | 0 | 5 624 |
| DT5 | 3 569 | 36 | 0 | 0 | 3 569 |
表1 各层级数据集的划分详情
Tab. 1 Dataset division details by level
| 层级 | 总样本数N | 类别数 | |||
|---|---|---|---|---|---|
| DT2-init | 5 676 | 21 | 1 600 | 2 038 | 2 038 |
| DT2-new | 4 742 | 26 | 480 | 2 131 | 2 131 |
| DT3 | 8 427 | 124 | 0 | 0 | 8 427 |
| DT4 | 5 624 | 65 | 0 | 0 | 5 624 |
| DT5 | 3 569 | 36 | 0 | 0 | 3 569 |
| 实际类别 | 预测类别 | |
|---|---|---|
| 预测为正类(1) | 预测为负类(0) | |
| 实际为正类(1) | 真实正例(TP) | 假负例(FN) |
| 实际为负类(0) | 假正例(FP) | 真实负例(TN) |
表2 二分类问题的混淆矩阵
Tab. 2 Confusion matrix of binary classification problem
| 实际类别 | 预测类别 | |
|---|---|---|
| 预测为正类(1) | 预测为负类(0) | |
| 实际为正类(1) | 真实正例(TP) | 假负例(FN) |
| 实际为负类(0) | 假正例(FP) | 真实负例(TN) |
| 顶层类别数 | 测试集分类准确率 | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| (10,5) | 33 | 0.913 | 0.872 | 0.851 | 0.818 | 0.775 | 0.625 | 0.809 | 0.361 |
| (10,10) | 33 | 0.920 | 0.894 | 0.848 | 0.805 | 0.749 | 0.689 | 0.817 | 0.475 |
| (20,8) | 30 | 0.948 | 0.922 | 0.824 | 0.819 | 0.779 | 0.638 | 0.822 | 0.441 |
| (20,16) | 30 | 0.930 | 0.922 | 0.837 | 0.828 | 0.805 | 0.745 | 0.844 | 0.620 |
| (40,8) | 26 | 0.936 | 0.855 | 0.838 | 0.829 | / | 0.799 | 0.852 | 0.613 |
| (40,16) | 26 | 0.940 | 0.884 | 0.863 | 0.858 | / | 0.833 | 0.876 | 0.658 |
| (40,20) | 26 | 0.952 | 0.912 | 0.872 | 0.868 | / | 0.851 | 0.891 | 0.670 |
| (60,18) | 20 | 0.934 | 0.923 | 0.901 | 0.898 | / | 0.886 | 0.908 | 0.758 |
| (60,30) | 20 | 0.940 | 0.933 | 0.902 | 0.882 | / | 0.871 | 0.905 | 0.736 |
表3 不同参数设置的实验结果
Tab. 3 Experimental results with different parameter settings
| 顶层类别数 | 测试集分类准确率 | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| (10,5) | 33 | 0.913 | 0.872 | 0.851 | 0.818 | 0.775 | 0.625 | 0.809 | 0.361 |
| (10,10) | 33 | 0.920 | 0.894 | 0.848 | 0.805 | 0.749 | 0.689 | 0.817 | 0.475 |
| (20,8) | 30 | 0.948 | 0.922 | 0.824 | 0.819 | 0.779 | 0.638 | 0.822 | 0.441 |
| (20,16) | 30 | 0.930 | 0.922 | 0.837 | 0.828 | 0.805 | 0.745 | 0.844 | 0.620 |
| (40,8) | 26 | 0.936 | 0.855 | 0.838 | 0.829 | / | 0.799 | 0.852 | 0.613 |
| (40,16) | 26 | 0.940 | 0.884 | 0.863 | 0.858 | / | 0.833 | 0.876 | 0.658 |
| (40,20) | 26 | 0.952 | 0.912 | 0.872 | 0.868 | / | 0.851 | 0.891 | 0.670 |
| (60,18) | 20 | 0.934 | 0.923 | 0.901 | 0.898 | / | 0.886 | 0.908 | 0.758 |
| (60,30) | 20 | 0.940 | 0.933 | 0.902 | 0.882 | / | 0.871 | 0.905 | 0.736 |
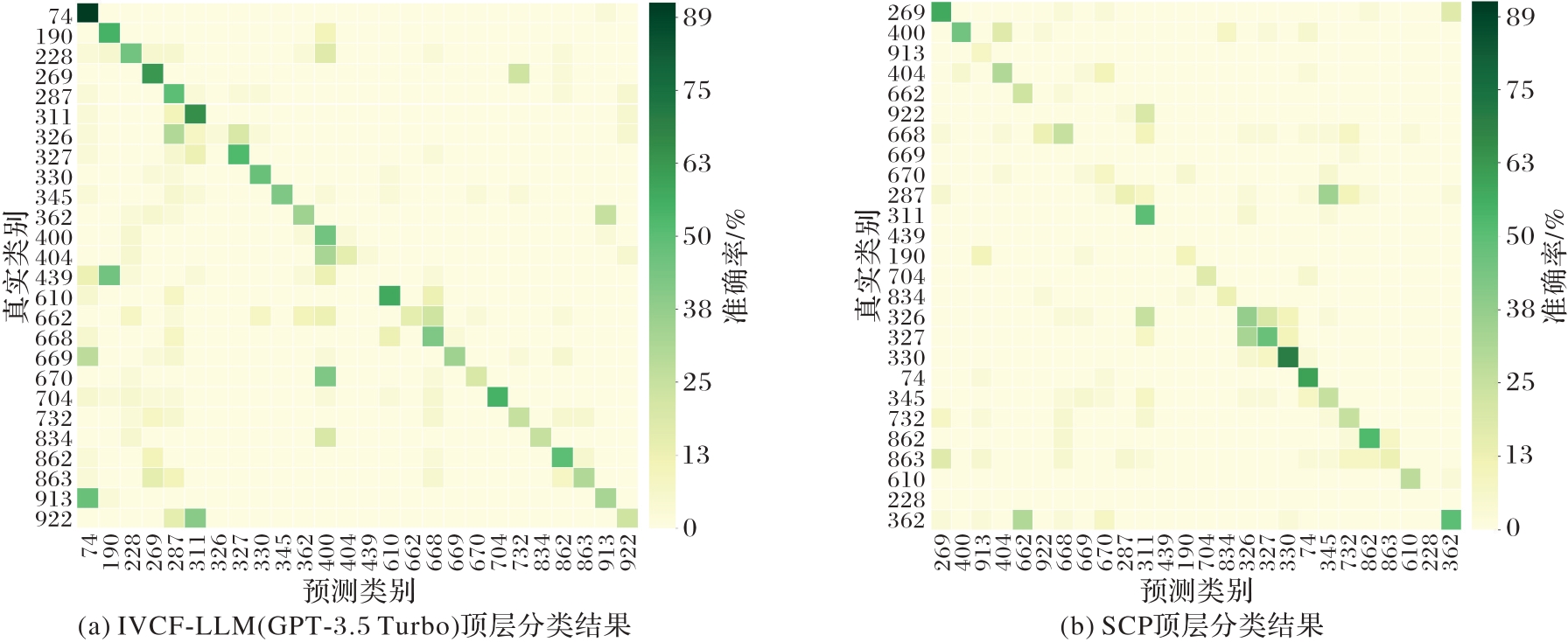
图8 顶层分类的混淆矩阵
Fig. 8 Top-level classification confusion matrices
| 阶段 | 分类器 | Acc | MCC |
|---|---|---|---|
| 层次判断 | SCP | 85.2 | 37.7 |
| 顶层分类 | Text2Weak(3-small) | 39.8 | 38.3 |
| Text2Weak(3-small)(top5) | 71.6 | 60.5 | |
| SCP | 68.2 | 66.4 | |
| IVCF-LLM(GLM-4-Flash) | 78.5 | 65.8 | |
| IVCF-LLM(GPT-3.5 Turbo) | 85.9 | 78.4 | |
| 子层分类 | SCP | 55.0 | 45.8 |
| IVCF-LLM(GLM-4-Flash) | 83.7 | 64.5 | |
| IVCF-LLM(GPT-3.5 Turbo) | 86.9 | 67.1 | |
| 全局分类 | Text2Weak(3-small) | 20.3 | 10.6 |
| Text2Weak(3-small)(top5) | 36.3 | 25.1 | |
| Text2Weak(add-002) | 17.1 | 7.0 | |
| Text2Weak(add-002)(top5) | 27.1 | 14.3 | |
| SCP | 52.9 | 51.5 | |
| Prompt(GPT-3.5 Turbo) | 55.8 | 50.9 | |
| IVCF-LLM(GLM-4-Flash) | 65.2 | 58.3 | |
| IVCF-LLM(GPT-3.5 Turbo) | 75.0 | 65.7 |
表 4 对比实验结果 (%)
Tab. 4 Results of comparison experiments
| 阶段 | 分类器 | Acc | MCC |
|---|---|---|---|
| 层次判断 | SCP | 85.2 | 37.7 |
| 顶层分类 | Text2Weak(3-small) | 39.8 | 38.3 |
| Text2Weak(3-small)(top5) | 71.6 | 60.5 | |
| SCP | 68.2 | 66.4 | |
| IVCF-LLM(GLM-4-Flash) | 78.5 | 65.8 | |
| IVCF-LLM(GPT-3.5 Turbo) | 85.9 | 78.4 | |
| 子层分类 | SCP | 55.0 | 45.8 |
| IVCF-LLM(GLM-4-Flash) | 83.7 | 64.5 | |
| IVCF-LLM(GPT-3.5 Turbo) | 86.9 | 67.1 | |
| 全局分类 | Text2Weak(3-small) | 20.3 | 10.6 |
| Text2Weak(3-small)(top5) | 36.3 | 25.1 | |
| Text2Weak(add-002) | 17.1 | 7.0 | |
| Text2Weak(add-002)(top5) | 27.1 | 14.3 | |
| SCP | 52.9 | 51.5 | |
| Prompt(GPT-3.5 Turbo) | 55.8 | 50.9 | |
| IVCF-LLM(GLM-4-Flash) | 65.2 | 58.3 | |
| IVCF-LLM(GPT-3.5 Turbo) | 75.0 | 65.7 |
| 阶段 | 分类器 | Acc | MCC |
|---|---|---|---|
| T2 | IVCF-LLM(未优化) | 55.9 | 47.8 |
| IVCF-LLM(删除1) | 79.9 | 69.0 | |
| IVCF-LLM(删除2) | 81.5 | 72.0 | |
| IVCF-LLM(删除3) | 78.5 | 68.7 | |
| IVCF-LLM(删除4) | 74.4 | 63.6 | |
| IVCF-LLM | 85.9 | 78.4 | |
| T3 | Standard Prompt | 67.7 | 63.6 |
| IVCF-LLM | 89.5 | 86.4 | |
| T4 | Standard Prompt | 85.0 | 68.8 |
| IVCF-LLM | 98.0 | 97.4 | |
| T5 | Standard Prompt | 89.0 | 75.8 |
| IVCF-LLM | 99.1 | 98.0 |
表5 消融实验结果 (%)
Tab. 5 Ablation experimental results
| 阶段 | 分类器 | Acc | MCC |
|---|---|---|---|
| T2 | IVCF-LLM(未优化) | 55.9 | 47.8 |
| IVCF-LLM(删除1) | 79.9 | 69.0 | |
| IVCF-LLM(删除2) | 81.5 | 72.0 | |
| IVCF-LLM(删除3) | 78.5 | 68.7 | |
| IVCF-LLM(删除4) | 74.4 | 63.6 | |
| IVCF-LLM | 85.9 | 78.4 | |
| T3 | Standard Prompt | 67.7 | 63.6 |
| IVCF-LLM | 89.5 | 86.4 | |
| T4 | Standard Prompt | 85.0 | 68.8 |
| IVCF-LLM | 98.0 | 97.4 | |
| T5 | Standard Prompt | 89.0 | 75.8 |
| IVCF-LLM | 99.1 | 98.0 |
| 层级 | 总样本数N | 类别数 | |||
|---|---|---|---|---|---|
| DT2-init | 14 498 | 21 | 1 600 | 8 240 | 8 240 |
| DT2-new | 1 605 | 26 | 480 | 562 | 563 |
| DT3 | 14 453 | 124 | 0 | 0 | 14 453 |
| DT4 | 6 786 | 65 | 0 | 0 | 6 786 |
| DT5 | 3 564 | 36 | 0 | 0 | 3 564 |
表6 跨场景漏洞子集的匹配统计
Tab. 6 Matching statistics of cross-scenario vulnerability subset
| 层级 | 总样本数N | 类别数 | |||
|---|---|---|---|---|---|
| DT2-init | 14 498 | 21 | 1 600 | 8 240 | 8 240 |
| DT2-new | 1 605 | 26 | 480 | 562 | 563 |
| DT3 | 14 453 | 124 | 0 | 0 | 14 453 |
| DT4 | 6 786 | 65 | 0 | 0 | 6 786 |
| DT5 | 3 564 | 36 | 0 | 0 | 3 564 |
| 阶段 | 分类器 | Acc | MCC |
|---|---|---|---|
| 层次判断 | SCP | 85.5 | 37.8 |
| 顶层分类 | Text2Weak(3-small) | 38.9 | 37.8 |
| Text2Weak(3-small)(top5) | 71.8 | 61.0 | |
| SCP | 68.5 | 64.4 | |
| IVCF-LLM(GLM-4-Flash) | 72.1 | 59.8 | |
| IVCF-LLM(GPT-3.5 Turbo) | 79.6 | 68.4 | |
| 子层分类 | SCP | 55.3 | 45.7 |
| IVCF-LLM(GLM-4-Flash) | 83.7 | 64.5 | |
| IVCF-LLM(GPT-3.5 Turbo) | 86.7 | 67.0 | |
| 全局分类 | Text2Weak(3-small) | 20.3 | 10.6 |
| Text2Weak(3-small)(top5) | 36.5 | 25.0 | |
| Text2Weak(add-002) | 17.5 | 8.0 | |
| Text2Weak(add-002)(top5) | 27.0 | 14.3 | |
| SCP | 53.2 | 52.6 | |
| Prompt(GPT-3.5 Turbo) | 52.6 | 48.9 | |
| IVCF-LLM(GLM-4-Flash) | 60.2 | 51.3 | |
| IVCF-LLM(GPT-3.5 Turbo) | 69.1 | 60.7 |
表7 跨场景CWE特征鲁棒性测试结果 (%)
Tab. 7 Robustness test results of cross-scenario CWE features
| 阶段 | 分类器 | Acc | MCC |
|---|---|---|---|
| 层次判断 | SCP | 85.5 | 37.8 |
| 顶层分类 | Text2Weak(3-small) | 38.9 | 37.8 |
| Text2Weak(3-small)(top5) | 71.8 | 61.0 | |
| SCP | 68.5 | 64.4 | |
| IVCF-LLM(GLM-4-Flash) | 72.1 | 59.8 | |
| IVCF-LLM(GPT-3.5 Turbo) | 79.6 | 68.4 | |
| 子层分类 | SCP | 55.3 | 45.7 |
| IVCF-LLM(GLM-4-Flash) | 83.7 | 64.5 | |
| IVCF-LLM(GPT-3.5 Turbo) | 86.7 | 67.0 | |
| 全局分类 | Text2Weak(3-small) | 20.3 | 10.6 |
| Text2Weak(3-small)(top5) | 36.5 | 25.0 | |
| Text2Weak(add-002) | 17.5 | 8.0 | |
| Text2Weak(add-002)(top5) | 27.0 | 14.3 | |
| SCP | 53.2 | 52.6 | |
| Prompt(GPT-3.5 Turbo) | 52.6 | 48.9 | |
| IVCF-LLM(GLM-4-Flash) | 60.2 | 51.3 | |
| IVCF-LLM(GPT-3.5 Turbo) | 69.1 | 60.7 |
| 任务类型 | 调用频次 | 平均响应时间/s | 平均Token消耗 | |
|---|---|---|---|---|
| 输入 | 输出 | |||
| 技能生成 | 24 | 11.69±0.6 | 9 259 | 598 |
| 技能融合 | 4 | 10.83±0.7 | 2 825 | 936 |
表8 资源消耗分布
Tab. 8 Distribution of resource consumption
| 任务类型 | 调用频次 | 平均响应时间/s | 平均Token消耗 | |
|---|---|---|---|---|
| 输入 | 输出 | |||
| 技能生成 | 24 | 11.69±0.6 | 9 259 | 598 |
| 技能融合 | 4 | 10.83±0.7 | 2 825 | 936 |
| [1] | 刘玥. 视频监控脆弱性检测系统的设计与实现[J]. 现代信息科技, 2024, 8(24): 158-162, 170. |
| LIU Y. Design and implementation of video surveillance vulnerability detection system[J]. Modern Information Technology, 2024, 8(24): 158-162, 170. | |
| [2] | YOU Y, JIANG J, JIANG Z, et al. TIM: threat context-enhanced TTP intelligence mining on unstructured threat data[J]. Cybersecurity, 2022, 5: No.3. |
| [3] | HADDAD A, AARAJ N, NAKOV P, et al. Automated mapping of CVE vulnerability records to MITRE CWE weaknesses[EB/OL]. [2024-11-14].. |
| [4] | WANG Q, GAO Y, REN J, et al. An automatic classification algorithm for software vulnerability based on weighted word vector and fusion neural network[J]. Computers and Security, 2023, 126: No.103070. |
| [5] | KOTA K, MANJUNATHA A, SREE V S. CWE prediction using CVE description — the semantic similarity approach[J]. Procedia Computer Science, 2024, 235: 1167-1178. |
| [6] | SIMONETTO S, OOSTVEEN R, VAN EDE T, et al. Text2Weak: mapping CVEs to CWEs using description embeddings analysis[EB/OL]. [2024-11-15].. |
| [7] | OOSTVEEN R. CWE-ASSIST: a framework for automating CWE classification[D/OL]. [2024-06-20].. |
| [8] | TURTIAINEN H, COSTIN A. VulnBERTa: on automating CWE weakness assignment and improving the quality of cybersecurity CVE vulnerabilities through ML/NLP[C]// Proceedings of the 2024 IEEE European Symposium on Security and Privacy Workshops. Piscataway: IEEE, 2024: 618-625. |
| [9] | DAS S S, DUTTA A, PUROHIT S, et al. Towards automatic mapping of vulnerabilities to attack patterns using large language models[C]// Proceedings of the 2022 IEEE International Symposium on Technologies for Homeland Security. Piscataway: IEEE, 2022: 1-7. |
| [10] | AGHAEI E, AL-SHAER E, SHADID W, et al. Automated CVE analysis for threat prioritization and impact prediction[EB/OL]. [2024-11-15].. |
| [11] | 王晓宇,李欣,胡勉宁,等. 基于大语言模型的CIL-LLM类别增量学习框架[J]. 计算机科学与探索, 2025, 19(2): 374-384. |
| WANG X Y, LI X, HU M N, et al. CIL-LLM: incremental learning framework based on large language models for category classification[J]. Journal of Frontiers of Computer Science and Technology, 2025, 19(2): 374-384. | |
| [12] | Common Weakness Enumeration. CWE view: research concepts[EB/OL]. [2025-01-13].. |
| [13] | D’AUTUME C D M, RUDER S, KONG L, et al. Episodic memory in lifelong language learning[C]// Proceedings of the 33rd International Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2019: 13132-13141. |
| [14] | WANG Z, MEHTA S V, PÓCZOS B, et al. Efficient meta lifelong-learning with limited memory[EB/OL]. [2024-09-25].. |
| [15] | KIRKPATRICK J, PASCANU R, RABINOWITZ N, et al. Overcoming catastrophic forgetting in neural networks[J]. Proceedings of the National Academy of Sciences of the United States of America, 2017, 114(13): 3521-3526. |
| [16] | YAN S, XIE J, HE X. DER: dynamically expandable representation for class incremental learning[C]// Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2021: 3013-3022. |
| [17] | YIN W, LI J, XIONG C. ConTinTin: continual learning from task instructions[C]// Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Stroudsburg: ACL, 2022: 3062-3072. |
| [18] | WANG J, DONG D, SHOU L, et al. Effective continual learning for text classification with lightweight snapshots[C]// Proceedings of the 37th AAAI Conference on Artificial Intelligence. Palo Alto: AAAI Press, 2023: 10122-10130. |
| [19] | THUCNews dataset[DS/OL]. [2024-07-22].. |
| [20] | OpenAI. Introducing GPT-4o and more tools to ChatGPT free users[EB/OL]. [2025-01-13].. |
| [21] | OpenAI. GPT-3.5 Turbo fine-tuning and API updates[EB/OL]. [2025-01-13].. |
| [22] | National Institute of Standards and Technology. National vulnerability database[DB/OL]. [2025-01-13].. |
| [23] | MILOUSI K, KIRIAKIDIS P, MENGIDIS N, et al. Evaluating cybersecurity risk: a comprehensive comparison of vulnerability scoring methodologies[C]// Proceedings of the 19th International Conference on Availability, Reliability and Security. New York: ACM, 2024: No.52. |
| [24] | ZHOU Y, MURESANU A I, HAN Z, et al. Large language models are human-level prompt engineers[EB/OL]. [2024-10-22].. |
| [25] | Povio. GPT-4 Turbo preview: exploring the 128k context window[EB/OL]. [2024-07-22].. |
| [26] | OpenAI. New and improved embedding model[EB/OL]. [2025-01-14].. |
| [27] | Team GLM. ChatGLM: a family of large language models from GLM-130B to GLM-4 all tools[EB/OL]. [2024-07-30].. |
| [28] | 张添植,周刚,张爽,等. 针对图文模态间实体对齐的目标实体情感分类[J]. 计算机工程, 2026, 52(3): 222-233. |
| ZHANG T Z, ZHOU G, ZHANG S, et al. Image-text multimodal entity alignment for target-oriented sentiment classification[J]. Computer Engineering, 2026, 52(3): 222-233. |
| [1] | 师凯洲, 何旋, 候国义, 李根, 李泷杲, 黄翔. 基于大语言模型的机载产品计量溯源知识图谱构建方法[J]. 《计算机应用》唯一官方网站, 2026, 46(4): 1086-1095. |
| [2] | 张昊洋, 张丽萍, 闫盛, 李娜, 张学飞. 面向知识图谱补全的大模型方法综述[J]. 《计算机应用》唯一官方网站, 2026, 46(3): 683-695. |
| [3] | 郗恩康, 范菁, 金亚东, 董华, 俞浩, 孙伊航. 联邦学习在隐私安全领域面临的威胁综述[J]. 《计算机应用》唯一官方网站, 2026, 46(3): 798-808. |
| [4] | 黄奕明, 邹喜华, 邓果, 郑狄. 预回答与召回过滤:双阶段RAG问答系统优化方法[J]. 《计算机应用》唯一官方网站, 2026, 46(3): 696-707. |
| [5] | 吴定佳, 崔喆. 增强模式链接与多生成器协同的SQL生成框架MG-SQL[J]. 《计算机应用》唯一官方网站, 2026, 46(3): 723-731. |
| [6] | 王日龙, 李振平, 李晓松, 高强, 何亚, 钟勇, 赵英潇. 多Agent协作的知识推理框架[J]. 《计算机应用》唯一官方网站, 2026, 46(3): 708-714. |
| [7] | 沈斌, 陈晓宁, 程华, 房一泉, 王慧锋. 基于大语言模型的本科教学评估智能系统[J]. 《计算机应用》唯一官方网站, 2026, 46(3): 993-1003. |
| [8] | 高飞, 陈董, 边帝行, 范文强, 刘起东, 吕培, 张朝阳, 徐明亮. 面向学科撤销后科研人员重分配的多阶段耦合决策框架[J]. 《计算机应用》唯一官方网站, 2026, 46(2): 416-426. |
| [9] | 林怡, 夏冰, 王永, 孟顺达, 刘居宠, 张书钦. 基于AI智能体的隐藏RESTful API识别与漏洞检测方法[J]. 《计算机应用》唯一官方网站, 2026, 46(1): 135-143. |
| [10] | 谢欣冉, 崔喆, 陈睿, 彭泰来, 林德坤. 基于层次过滤与标签语义扩展的大模型零样本重排序方法[J]. 《计算机应用》唯一官方网站, 2026, 46(1): 60-68. |
| [11] | 张滨滨, 秦永彬, 黄瑞章, 陈艳平. 结合大语言模型与动态提示的裁判文书摘要方法[J]. 《计算机应用》唯一官方网站, 2025, 45(9): 2783-2789. |
| [12] | 冯涛, 刘晨. 自动化偏好对齐的双阶段提示调优方法[J]. 《计算机应用》唯一官方网站, 2025, 45(8): 2442-2447. |
| [13] | 孙熠衡, 刘茂福. 基于知识提示微调的标书信息抽取方法[J]. 《计算机应用》唯一官方网站, 2025, 45(4): 1169-1176. |
| [14] | 徐月梅, 叶宇齐, 何雪怡. 大语言模型的偏见挑战:识别、评估与去除[J]. 《计算机应用》唯一官方网站, 2025, 45(3): 697-708. |
| [15] | 杨燕, 叶枫, 许栋, 张雪洁, 徐津. 融合大语言模型和提示学习的数字孪生水利知识图谱构建[J]. 《计算机应用》唯一官方网站, 2025, 45(3): 785-793. |
| 阅读次数 | ||||||
|
全文 |
|
|||||
|
摘要 |
|
|||||