


《计算机应用》唯一官方网站 ›› 2026, Vol. 46 ›› Issue (4): 1275-1282.DOI: 10.11772/j.issn.1001-9081.2025050589
• 多媒体计算与计算机仿真 • 上一篇
何帅, 邓春华( )
)
收稿日期:2025-05-29
修回日期:2025-08-26
接受日期:2025-09-09
发布日期:2025-09-15
出版日期:2026-04-10
通讯作者:
邓春华
作者简介:何帅(1997—),男,山东菏泽人,硕士研究生,主要研究方向:计算机视觉、少样本目标检测
基金资助:Received:2025-05-29
Revised:2025-08-26
Accepted:2025-09-09
Online:2025-09-15
Published:2026-04-10
Contact:
Chunhua DENG
About author:HE Shuai, born in 1997, M. S. candidate. His research interests include computer vision, few-shot object detection.
Supported by:摘要:
目标检测技术在计算机视觉领域得到了广泛应用,但现有方法大多依赖大量标注数据,难以解决现实中面临的新类别样本稀缺问题。尽管现有开放词汇目标检测(OVD)方法具备一定的跨类泛化能力,但在面向结构相近的新类别时,普遍存在语义匹配粗略、空间定位精度不足的问题。针对上述问题,提出一种基于YOLO-World的少样本学习目标检测算法。首先,提出类别感知卷积核构建模块(CCKCM),将文本语义嵌入与图像特征融合,提升模型在少样本条件下对新类别的语义感知能力;其次,设计一种融合滑动卷积与几何空间约束的高效目标匹配与定位机制,在保持较低计算复杂度的同时,实现对目标区域的快速匹配与精准定位;最后,构建一个面向少样本目标检测(FSOD)任务的图像数据集,涵盖多个典型场景与目标类别。实验结果表明,所提算法在PASCAL VOC 2007+2012数据集上的10-shot下新类的平均精度达到了73.4%,比FM-FSOD提高了1.4个百分点。可见,所提算法为实际场景中新类别目标的快速识别提供了一条可行的技术路径。
中图分类号:
何帅, 邓春华. 基于YOLO-World的少样本学习目标检测算法[J]. 计算机应用, 2026, 46(4): 1275-1282.
Shuai HE, Chunhua DENG. Object detection algorithm with few-shot learning based on YOLO-World[J]. Journal of Computer Applications, 2026, 46(4): 1275-1282.

图1 语义相似性的说明
Fig. 1 Explanation of semantic similarity
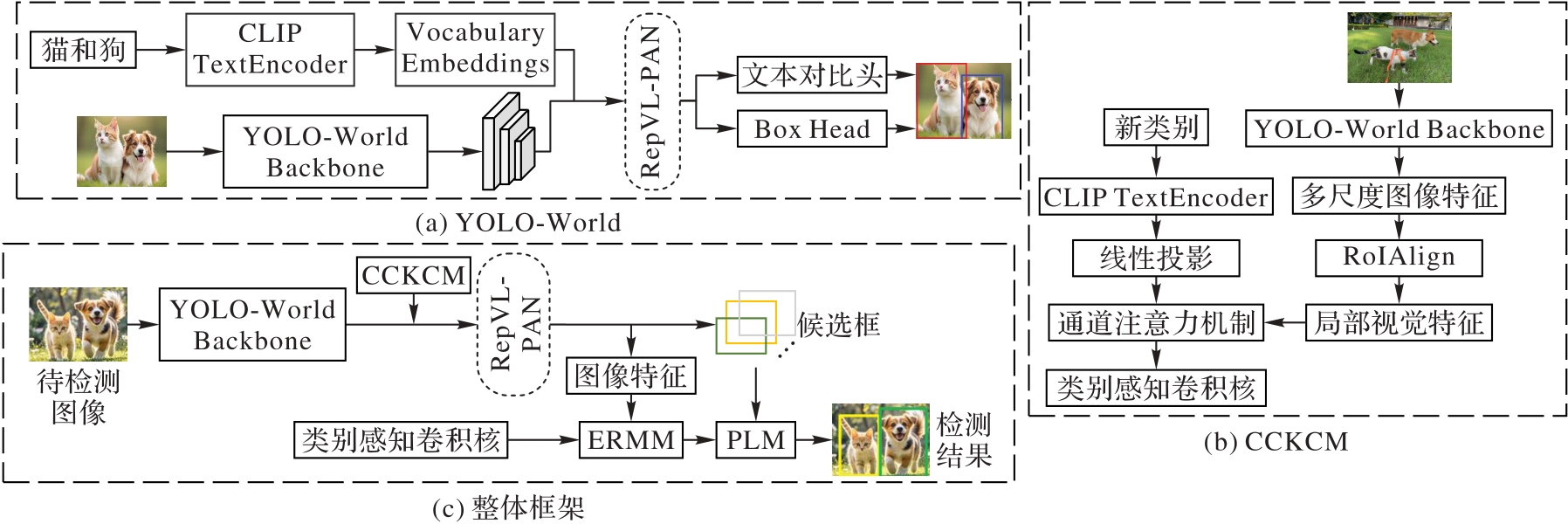
图2 整体流程
Fig. 2 Overall flow

图3 自建数据集中的类别图像
Fig. 3 Category images in self-built dataset
| 算法 | nAP0.5 | |||
|---|---|---|---|---|
| 1-shot | 3-shot | 5-shot | 10-shot | |
| TFA w/ fc[ | 5.6 | 12.5 | 15.9 | 19.0 |
| TFA w/ cos[ | 5.7 | 12.0 | 15.2 | 19.0 |
| MPSR[ | 4.1 | 9.4 | 12.5 | 17.8 |
| QA-FewDet[ | 10.2 | 17.9 | 20.4 | 23.8 |
| Meta-DETR[ | 12.4 | 21.6 | 25.2 | 30.6 |
| FS-DETR[ | 13.5 | 18.8 | 20.6 | 21.6 |
| FM-FSOD[ | 7.9 | 21.8 | 30.3 | 38.6 |
| 本文算法 | 8.7 | 21.6 | 31.4 | 39.7 |
表1 不同算法在机场新类别数据集上的检测性能 (%)
Tab. 1 Detection performance of different algorithms on airport dataset of new categories
| 算法 | nAP0.5 | |||
|---|---|---|---|---|
| 1-shot | 3-shot | 5-shot | 10-shot | |
| TFA w/ fc[ | 5.6 | 12.5 | 15.9 | 19.0 |
| TFA w/ cos[ | 5.7 | 12.0 | 15.2 | 19.0 |
| MPSR[ | 4.1 | 9.4 | 12.5 | 17.8 |
| QA-FewDet[ | 10.2 | 17.9 | 20.4 | 23.8 |
| Meta-DETR[ | 12.4 | 21.6 | 25.2 | 30.6 |
| FS-DETR[ | 13.5 | 18.8 | 20.6 | 21.6 |
| FM-FSOD[ | 7.9 | 21.8 | 30.3 | 38.6 |
| 本文算法 | 8.7 | 21.6 | 31.4 | 39.7 |

图4 本文算法在机场新类别数据集和PASCAL VOC数据集上的可视化检测结果
Fig. 4 Visualized detection results of proposed algorithm on airport dataset of new categories and PASCAL VOC dataset
| 算法 | 新分割1 | 新分割2 | 新分割3 | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1-shot | 2-shot | 3-shot | 5-shot | 10-shot | 1-shot | 2-shot | 3-shot | 5-shot | 10-shot | 1-shot | 2-shot | 3-shot | 5-shot | 10-shot | |
| TFA w/ fc[ | 36.8 | 29.1 | 43.6 | 55.7 | 57.0 | 18.2 | 29.0 | 33.4 | 35.5 | 39.0 | 27.7 | 33.6 | 42.5 | 48.7 | 50.2 |
| TFA w/ cos[ | 39.8 | 36.1 | 44.7 | 55.7 | 56.0 | 23.5 | 26.9 | 34.1 | 35.1 | 39.1 | 30.8 | 34.8 | 42.8 | 49.5 | 49.8 |
| MPSR[ | 41.7 | 42.5 | 51.4 | 55.2 | 61.8 | 24.4 | 29.3 | 39.2 | 39.9 | 47.8 | 35.6 | 41.8 | 42.3 | 48.0 | 49.7 |
| FSCE[ | 44.2 | 43.8 | 51.4 | 61.9 | 63.4 | 27.3 | 29.5 | 43.5 | 44.2 | 50.2 | 37.2 | 41.9 | 47.5 | 54.6 | 58.5 |
| QA-FewDet[ | 42.4 | 51.9 | 55.7 | 62.6 | 63.4 | 25.9 | 37.8 | 46.6 | 48.9 | 51.1 | 35.2 | 42.9 | 47.8 | 54.8 | 53.5 |
| FCT[ | 49.9 | 57.1 | 57.9 | 63.2 | 67.1 | 27.6 | 34.5 | 43.7 | 49.2 | 51.2 | 39.5 | 54.7 | 52.3 | 57.0 | 58.7 |
| FS-DETR[ | 45.0 | 48.5 | 51.5 | 52.7 | 56.1 | 37.3 | 41.3 | 43.4 | 46.6 | 49.0 | 43.8 | 47.1 | 50.6 | 52.1 | 56.9 |
| Meta-DETR[ | 40.6 | 51.4 | 58.0 | 59.2 | 63.6 | 37.0 | 36.6 | 43.7 | 49.1 | 54.6 | 41.6 | 45.9 | 52.7 | 58.9 | 60.6 |
| FM-FSOD[ | 40.1 | 53.5 | 57.0 | 68.6 | 72.0 | 33.1 | 36.3 | 48.8 | 54.8 | 64.7 | 39.2 | 50.2 | 55.7 | 63.4 | 68.1 |
| 本文算法 | 44.5 | 51.3 | 58.6 | 69.1 | 73.4 | 32.6 | 38.9 | 49.6 | 56.2 | 66.4 | 42.8 | 53.6 | 56.1 | 65.2 | 69.8 |
表2 不同算法在PASCAL VOC 数据集上的少样本目标检测性能(nAP0.5) (%)
Tab. 2 Few-shot object detection performance of different methods on PASCAL VOC dataset (nAP0.5)
| 算法 | 新分割1 | 新分割2 | 新分割3 | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1-shot | 2-shot | 3-shot | 5-shot | 10-shot | 1-shot | 2-shot | 3-shot | 5-shot | 10-shot | 1-shot | 2-shot | 3-shot | 5-shot | 10-shot | |
| TFA w/ fc[ | 36.8 | 29.1 | 43.6 | 55.7 | 57.0 | 18.2 | 29.0 | 33.4 | 35.5 | 39.0 | 27.7 | 33.6 | 42.5 | 48.7 | 50.2 |
| TFA w/ cos[ | 39.8 | 36.1 | 44.7 | 55.7 | 56.0 | 23.5 | 26.9 | 34.1 | 35.1 | 39.1 | 30.8 | 34.8 | 42.8 | 49.5 | 49.8 |
| MPSR[ | 41.7 | 42.5 | 51.4 | 55.2 | 61.8 | 24.4 | 29.3 | 39.2 | 39.9 | 47.8 | 35.6 | 41.8 | 42.3 | 48.0 | 49.7 |
| FSCE[ | 44.2 | 43.8 | 51.4 | 61.9 | 63.4 | 27.3 | 29.5 | 43.5 | 44.2 | 50.2 | 37.2 | 41.9 | 47.5 | 54.6 | 58.5 |
| QA-FewDet[ | 42.4 | 51.9 | 55.7 | 62.6 | 63.4 | 25.9 | 37.8 | 46.6 | 48.9 | 51.1 | 35.2 | 42.9 | 47.8 | 54.8 | 53.5 |
| FCT[ | 49.9 | 57.1 | 57.9 | 63.2 | 67.1 | 27.6 | 34.5 | 43.7 | 49.2 | 51.2 | 39.5 | 54.7 | 52.3 | 57.0 | 58.7 |
| FS-DETR[ | 45.0 | 48.5 | 51.5 | 52.7 | 56.1 | 37.3 | 41.3 | 43.4 | 46.6 | 49.0 | 43.8 | 47.1 | 50.6 | 52.1 | 56.9 |
| Meta-DETR[ | 40.6 | 51.4 | 58.0 | 59.2 | 63.6 | 37.0 | 36.6 | 43.7 | 49.1 | 54.6 | 41.6 | 45.9 | 52.7 | 58.9 | 60.6 |
| FM-FSOD[ | 40.1 | 53.5 | 57.0 | 68.6 | 72.0 | 33.1 | 36.3 | 48.8 | 54.8 | 64.7 | 39.2 | 50.2 | 55.7 | 63.4 | 68.1 |
| 本文算法 | 44.5 | 51.3 | 58.6 | 69.1 | 73.4 | 32.6 | 38.9 | 49.6 | 56.2 | 66.4 | 42.8 | 53.6 | 56.1 | 65.2 | 69.8 |
| 算法 | Precision | Recall | F1 | mAP0.5 |
|---|---|---|---|---|
| YOLOv10m[ | 79.14 | 69.95 | 74.27 | 75.23 |
| YOLOv10n[ | 73.92 | 62.70 | 67.78 | 68.54 |
| YOLO11m[ | 77.65 | 69.72 | 73.47 | 75.62 |
| YOLO11n[ | 75.22 | 63.31 | 68.74 | 69.20 |
| YOLOv12m[ | 79.36 | 71.38 | 75.17 | 76.02 |
| YOLOv12n[ | 74.78 | 64.09 | 69.01 | 70.24 |
| RT-DETR-l[ | 79.89 | 73.40 | 76.49 | 77.73 |
| YOLO-World-M[ | 80.40 | 73.56 | 76.83 | 77.98 |
| 本文算法 | 80.86 | 73.95 | 77.26 | 78.42 |
表3 不同算法在PASCAL VOC数据集上的检测性能 (%)
Tab. 3 Detection performance of different algorithms on PASCAL VOC dataset
| 算法 | Precision | Recall | F1 | mAP0.5 |
|---|---|---|---|---|
| YOLOv10m[ | 79.14 | 69.95 | 74.27 | 75.23 |
| YOLOv10n[ | 73.92 | 62.70 | 67.78 | 68.54 |
| YOLO11m[ | 77.65 | 69.72 | 73.47 | 75.62 |
| YOLO11n[ | 75.22 | 63.31 | 68.74 | 69.20 |
| YOLOv12m[ | 79.36 | 71.38 | 75.17 | 76.02 |
| YOLOv12n[ | 74.78 | 64.09 | 69.01 | 70.24 |
| RT-DETR-l[ | 79.89 | 73.40 | 76.49 | 77.73 |
| YOLO-World-M[ | 80.40 | 73.56 | 76.83 | 77.98 |
| 本文算法 | 80.86 | 73.95 | 77.26 | 78.42 |
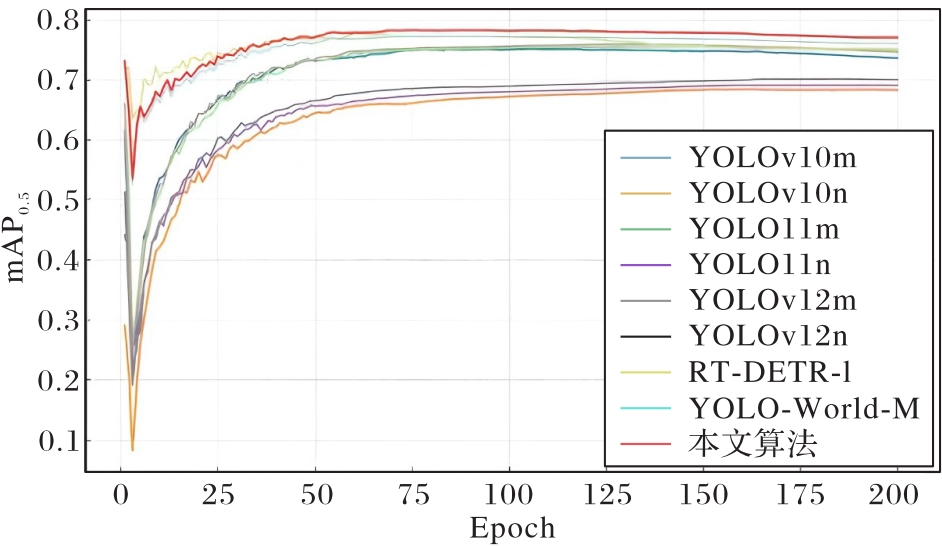
图5 不同算法的mAP0.5比较
Fig. 5 Comparison of mAP0.5 of different algorithms
| 算法 | 模型参数量/106 | 算法 | 模型参数量/106 |
|---|---|---|---|
| TFA | 60.3 | FM-FSOD | 75.6 |
| FSCE | 60.3 | 本文算法 | 65.3 |
| FS-DETR | 75.4 |
表4 模型参数量的比较
Tab. 4 Comparison of model parameters
| 算法 | 模型参数量/106 | 算法 | 模型参数量/106 |
|---|---|---|---|
| TFA | 60.3 | FM-FSOD | 75.6 |
| FSCE | 60.3 | 本文算法 | 65.3 |
| FS-DETR | 75.4 |
| 主干模型 | mAP0.5 | |
|---|---|---|
| 无CCKCM | 有CCKCM | |
| YOLO-World-S | 12.4 | 24.9 |
| YOLO-World-M | 15.7 | 27.2 |
| YOLO-World-L | 18.9 | 30.1 |
表5 CCKCM的消融实验结果对比 (%)
Tab. 5 Comparison of CCKCM ablation experimental results
| 主干模型 | mAP0.5 | |
|---|---|---|
| 无CCKCM | 有CCKCM | |
| YOLO-World-S | 12.4 | 24.9 |
| YOLO-World-M | 15.7 | 27.2 |
| YOLO-World-L | 18.9 | 30.1 |
| 主干模型 | mAP0.5 | |
|---|---|---|
| 局部视觉特征 | CCKCM | |
| YOLO-World-S | 13.1 | 24.9 |
| YOLO-World-M | 16.2 | 27.2 |
| YOLO-World-L | 19.5 | 30.1 |
表6 CCKCM的文本语义消融实验结果对比 (%)
Tab. 6 Comparison of CCKCM text semantic ablation experimental results
| 主干模型 | mAP0.5 | |
|---|---|---|
| 局部视觉特征 | CCKCM | |
| YOLO-World-S | 13.1 | 24.9 |
| YOLO-World-M | 16.2 | 27.2 |
| YOLO-World-L | 19.5 | 30.1 |
| Baseline | CCKCM | ERMM+PLM | nAP0.5 | Loc-Acc | |
|---|---|---|---|---|---|
| 3-shot | 5-shot | ||||
| √ | — | — | — | ||
| √ | √ | 40.5 | 52.1 | 76.2 | |
| √ | √ | √ | 58.6 | 69.1 | 89.3 |
表7 各子模块在不同少样本条件下检测性能的消融实验结果 (%)
Tab. 7 Ablation experimental results of detection performance of each submodule under different few-shot conditions
| Baseline | CCKCM | ERMM+PLM | nAP0.5 | Loc-Acc | |
|---|---|---|---|---|---|
| 3-shot | 5-shot | ||||
| √ | — | — | — | ||
| √ | √ | 40.5 | 52.1 | 76.2 | |
| √ | √ | √ | 58.6 | 69.1 | 89.3 |
| [1] | KHANAM R, HUSSAIN M. YOLOv11: an overview of the key architectural enhancements[EB/OL]. [2024-04-11].. |
| [2] | ZHU Z, LIN K, JAIN A K, et al. Transfer learning in deep reinforcement learning: a survey[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2023, 45(11): 13344-13362. |
| [3] | NAJDENKOSKA I, ZHEN X, WORRING M. Meta learning to bridge vision and language models for multimodal few-shot learning[EB/OL]. [2024-04-11].. |
| [4] | CHENG T, SONG L, GE Y, et al. YOLO-World: real-time open-vocabulary object detection[C]// Proceedings of the 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2024: 16901-16911. |
| [5] | ZHANG Y, YANG Q. A survey on multi-task learning[J]. IEEE Transactions on Knowledge and Data Engineering, 2022, 34(12): 5586-5609. |
| [6] | ZHANG J, HUANG J, JIN S, et al. Vision-language models for vision tasks: a survey[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2024, 46(8): 5625-5644. |
| [7] | REN S, HE K, GIRSHICK R, et al. Faster R-CNN: towards real-time object detection with region proposal networks[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2017, 39(6): 1137-1149. |
| [8] | REDMON J, DIVVALA S, GIRSHICK R, et al. You only look once: unified, real-time object detection[C]// Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2016: 779-788. |
| [9] | CARION N, MASSA F, SYNNAEVE G, et al. End-to-end object detection with Transformers[C]// Proceedings of the 2020 European Conference on Computer Vision, LNCS 12346. Cham: Springer, 2020: 213-229. |
| [10] | VASWANI A, SHAZEER N, PARMAR N, et al. Attention is all you need[C]// Proceedings of the 31st International Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2017: 6000-6010. |
| [11] | SHI C, YANG S. EdaDet: open-vocabulary object detection using early dense alignment[C]// Proceedings of the 2023 IEEE/CVF International Conference on Computer Vision. Piscataway: IEEE, 2023: 15678-15688. |
| [12] | ZHOU X, GIRDHAR R, JOULIN A, et al. Detecting twenty-thousand classes using image-level supervision[C]// Proceedings of the 2022 European Conference on Computer Vision, LNCS 13669. Cham: Springer, 2022: 350-368. |
| [13] | JIA C, YANG Y, XIA Y, et al. Scaling up visual and vision-language representation learning with noisy text supervision[C]// Proceedings of the 38th International Conference on Machine Learning. New York: JMLR.org, 2021: 4904-4916. |
| [14] | YAO L, HAN J, LIANG X, et al. DetCLIPv2: scalable open-vocabulary object detection pre-training via word-region alignment[C]// Proceedings of the 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2023: 23497-23506. |
| [15] | MINDERER M, GRITSENKO A, STONE A, et al. Simple open-vocabulary object detection[C]// Proceedings of the 2022 European Conference on Computer Vision, LNCS 13670. Cham: Springer, 2022: 728-755. |
| [16] | 杭焕云,刘俊. 结合解耦与广义微调的少样本目标检测[J]. 计算机工程与应用, 2026, 62(4): 293-301. |
| HANG H Y, LIU J. Few-shot object detection combining decoupling and generalized fine-tuning[J]. Computer Engineering and Applications, 2026, 62(4): 293-301. | |
| [17] | HAN G, MA J, HUANG S, et al. Few-shot object detection with fully cross-Transformer[C]// Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2022: 5321-5330. |
| [18] | HAN G, HUANG S, MA J, et al. Meta Faster R-CNN: towards accurate few-shot object detection with attentive feature alignment[C]// Proceedings of the 36th AAAI Conference on Artificial Intelligence. Palo Alto: AAAI Press, 2022: 780-789. |
| [19] | 李鸿天,史鑫昊,潘卫国,等. 融合多尺度和注意力机制的小样本目标检测[J]. 计算机应用, 2024, 44(5): 1437-1444. |
| LI H T, SHI X H, PAN W G, et al. Few-shot object detection via fusing multi-scale and attention mechanism[J]. Journal of Computer Applications, 2024, 44(5): 1437-1444. | |
| [20] | ZHANG X, LIU Y, WANG Y, et al. Detect everything with few examples[C]// Proceedings of the 8th Conference on Robot Learning. New York: JMLR.org, 2025: 3986-4004. |
| [21] | WANG X, HUANG T E, DARRELL T, et al. Frustratingly simple few-shot object detection[C]// Proceedings of the 37th International Conference on Machine Learning. New York: JMLR.org, 2020: 9919-9928. |
| [22] | HAN G, HE Y, HUANG S, et al. Query adaptive few-shot object detection with heterogeneous graph convolutional networks[C]// Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision. Piscataway: IEEE, 2021: 3243-3252. |
| [23] | ZHANG G, LUO Z, CUI K, et al. Meta-DETR: image-level few-shot detection with inter-class correlation exploitation[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2023, 45(11): 12832-12843. |
| [24] | BULAT A, GUERRERO R, MARTINEZ B, et al. FS-DETR: few-shot detection transformer with prompting and without re-training[C]// Proceedings of the 2023 IEEE/CVF International Conference on Computer Vision. Piscataway: IEEE, 2023: 11759-11768. |
| [25] | HAN G, LIM S N. Few-shot object detection with foundation models[C]// Proceedings of the 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2024: 28608-28618. |
| [26] | WU J, LIU S, HUANG D, et al. Multi-scale positive sample refinement for few-shot object detection[C]// Proceedings of the 2020 European Conference on Computer Vision, LNCS 12361. Cham: Springer, 2020: 456-472. |
| [27] | SUN B, LI B, CAI S, et al. FSCE: few-shot object detection via contrastive proposal encoding[C]// Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2021: 7348-7358. |
| [28] | WANG A, CHEN H, LIU L, et al. YOLOv10: real-time end-to-end object detection[C]// Proceedings of the 38th International Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2024: 107984-108011. |
| [29] | TIAN Y, YE Q, DOERMANN D. YOLOv12: attention-centric real-time object detectors[EB/OL]. [2024-04-11].. |
| [30] | ZHAO Y, LV W, XU S, et al. DETRs beat YOLOs on real-time object detection[C]// Proceedings of the 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2024: 16965-16974. |
| [1] | 刘欢娴, 王洪涛, 王宪奥, 王洪梅, 徐伟峰. 跨模态语义关联的多模态事实验证[J]. 《计算机应用》唯一官方网站, 2026, 46(4): 1069-1076. |
| [2] | 刘汉卿, 桑国明, 张益嘉. 结合密集多尺度特征融合和特征知识增强Transformer的遥感图像描述模型[J]. 《计算机应用》唯一官方网站, 2026, 46(3): 741-749. |
| [3] | 韩锋, 卜永丰, 梁浩翔, 黄舒雯, 张朝阳, 孙士杰. 基于多层次时空交互依赖的车辆轨迹异常检测[J]. 《计算机应用》唯一官方网站, 2026, 46(2): 604-612. |
| [4] | 付锦程, 杨仕友. 基于贝叶斯优化和特征融合混合模型的短期风电功率预测[J]. 《计算机应用》唯一官方网站, 2026, 46(2): 652-658. |
| [5] | 梁瑾裕, 高宏娟, 杜晓飞. 基于潜在特征增强进行解耦的三维人脸生成方法[J]. 《计算机应用》唯一官方网站, 2026, 46(1): 216-223. |
| [6] | 昝志辉, 王雅静, 李珂, 杨智翔, 杨光宇. 基于SAA-CNN-BiLSTM网络的多特征融合语音情感识别方法[J]. 《计算机应用》唯一官方网站, 2026, 46(1): 69-76. |
| [7] | 曹柠, 温昕, 郝雁嵘, 曹锐. 多域特征融合的轻量化运动想象脑电信号解码神经网络[J]. 《计算机应用》唯一官方网站, 2026, 46(1): 289-296. |
| [8] | 李维刚, 邵佳乐, 田志强. 基于双注意力机制和多尺度融合的点云分类与分割网络[J]. 《计算机应用》唯一官方网站, 2025, 45(9): 3003-3010. |
| [9] | 许志雄, 李波, 边小勇, 胡其仁. 对抗样本嵌入注意力U型网络的3D医学图像分割[J]. 《计算机应用》唯一官方网站, 2025, 45(9): 3011-3016. |
| [10] | 王芳, 胡静, 张睿, 范文婷. 内容引导下多角度特征融合医学图像分割网络[J]. 《计算机应用》唯一官方网站, 2025, 45(9): 3017-3025. |
| [11] | 梁一鸣, 范菁, 柴汶泽. 基于双向交叉注意力的多尺度特征融合情感分类[J]. 《计算机应用》唯一官方网站, 2025, 45(9): 2773-2782. |
| [12] | 习怡萌, 邓箴, 刘倩, 刘立波. 跨模态信息融合的视频-文本检索[J]. 《计算机应用》唯一官方网站, 2025, 45(8): 2448-2456. |
| [13] | 颜承志, 陈颖, 钟凯, 高寒. 基于多尺度网络与轴向注意力的3D目标检测算法[J]. 《计算机应用》唯一官方网站, 2025, 45(8): 2537-2545. |
| [14] | 林进浩, 罗川, 李天瑞, 陈红梅. 基于跨尺度注意力网络的胸部疾病分类方法[J]. 《计算机应用》唯一官方网站, 2025, 45(8): 2712-2719. |
| [15] | 陈亮, 王璇, 雷坤. 复杂场景下跨层多尺度特征融合的安全帽佩戴检测算法[J]. 《计算机应用》唯一官方网站, 2025, 45(7): 2333-2341. |
| 阅读次数 | ||||||
|
全文 |
|
|||||
|
摘要 |
|
|||||