


《计算机应用》唯一官方网站 ›› 2023, Vol. 43 ›› Issue (11): 3579-3586.DOI: 10.11772/j.issn.1001-9081.2022111660
所属专题: 多媒体计算与计算机仿真
秦强强, 廖俊国( ), 周弋荀
), 周弋荀
收稿日期:2022-11-09
修回日期:2023-03-03
接受日期:2023-03-03
发布日期:2023-03-20
出版日期:2023-11-10
通讯作者:
廖俊国
作者简介:秦强强(1997—),男,安徽芜湖人,硕士研究生,CCF会员,主要研究方向:人工智能、目标检测
Qiangqiang QIN, Junguo LIAO(), Yixun ZHOU
Received:2022-11-09
Revised:2023-03-03
Accepted:2023-03-03
Online:2023-03-20
Published:2023-11-10
Contact:
Junguo LIAO
About author:QIN Qiangqiang, born in 1990, M. S. candidate. His research interests include artificial intelligence, object detection.摘要:
针对图像中的小目标特征信息少、占比低、易受环境影响等特点,提出一种基于多分支混合注意力的小目标检测算法SMAM-YOLO。首先,将通道注意力(CA)和空间注意力(SA)相结合,重新组合连接结构,提出一种混合注意力模块(MAM),增强模型对小目标特征在空间维度上的表达能力。其次,根据不同大小的感受野对目标影响的不同,基于混合注意力提出一种多分支混合注意力模块(SMAM);根据输入特征图的尺度自适应调整感受野大小,同时使用混合注意力增强不同分支下对小目标特征信息的捕获能力。最后,使用SMAM改进YOLOv5中的核心残差模块,提出一种基于CSPNet(Cross Stage Partial Network)和SMAM的特征提取模块CSMAM,而且CSMAM的额外计算开销可以忽略不计。在TinyPerson数据集上的实验结果表明,与基线算法YOLOv5s相比,当交并比(IoU)阈值为0.5时,SMAM-YOLO算法的平均检测精度(mAP50)提升了4.15个百分点,且检测速度达到74 frame/s;此外,与现有的一些主流小目标检测模型相比,SMAM-YOLO算法在mAP50上平均提升了1.46~6.84个百分点,且能满足实时性检测的需求。
中图分类号:
秦强强, 廖俊国, 周弋荀. 基于多分支混合注意力的小目标检测算法[J]. 计算机应用, 2023, 43(11): 3579-3586.
Qiangqiang QIN, Junguo LIAO, Yixun ZHOU. Small object detection algorithm based on split mixed attention[J]. Journal of Computer Applications, 2023, 43(11): 3579-3586.
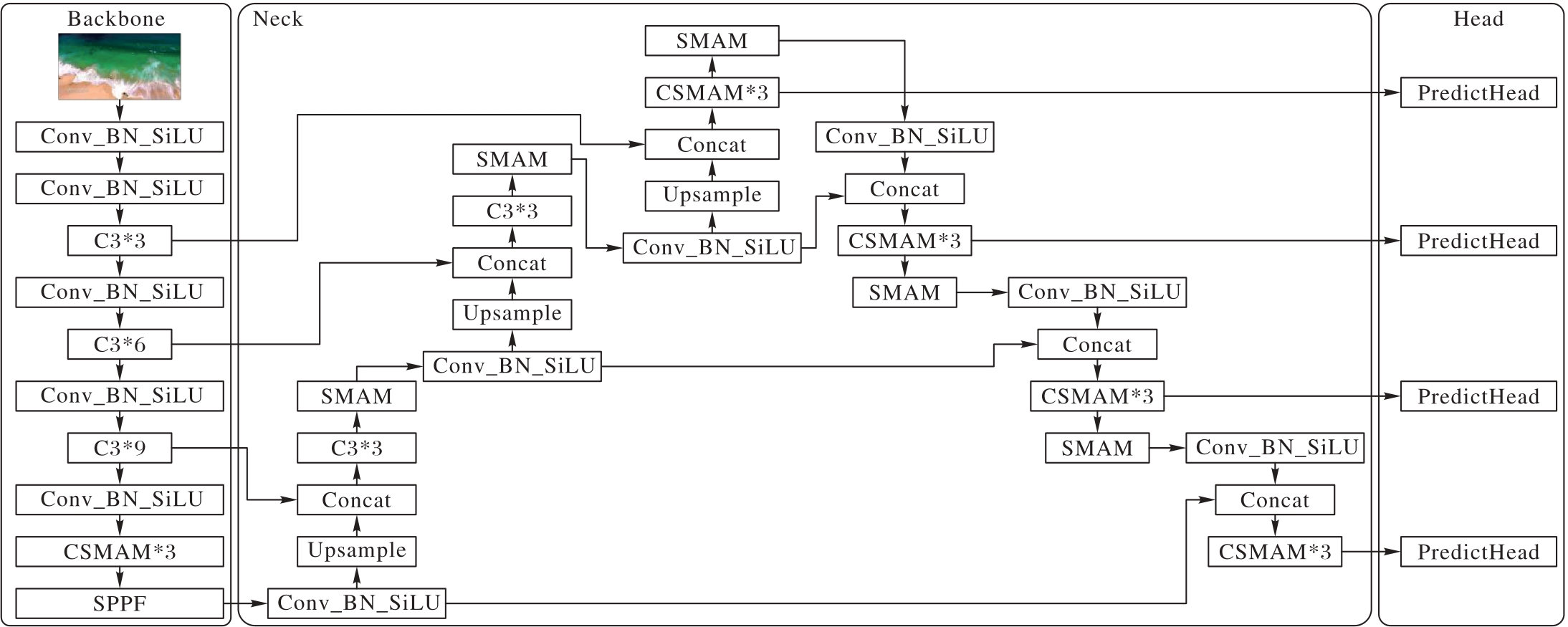
图1 SMAM-YOLO算法的整体网络结构
Fig. 1 Overall network structure of SMAM-YOLO algorithm
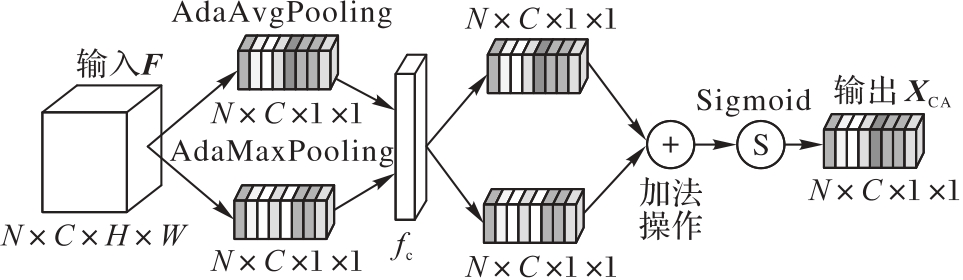
图2 CA模块结构
Fig. 2 Structure of CA module
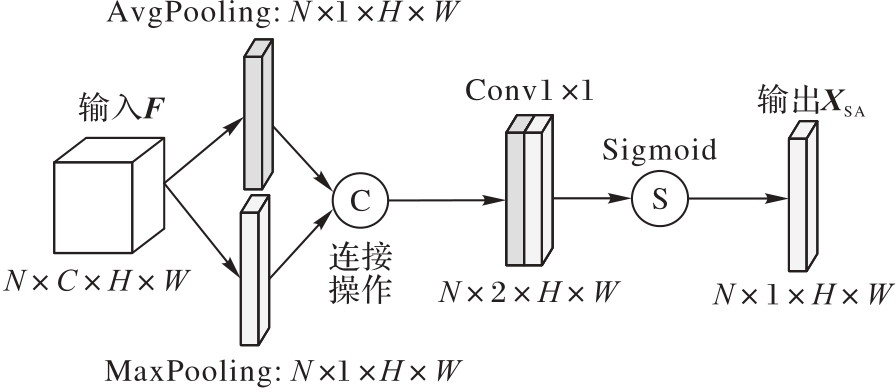
图3 SA模块结构
Fig. 3 Structure of SA module
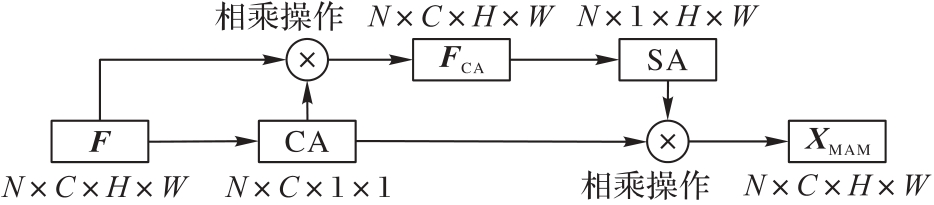
图4 MAM的结构
Fig.4 Structure of MAM
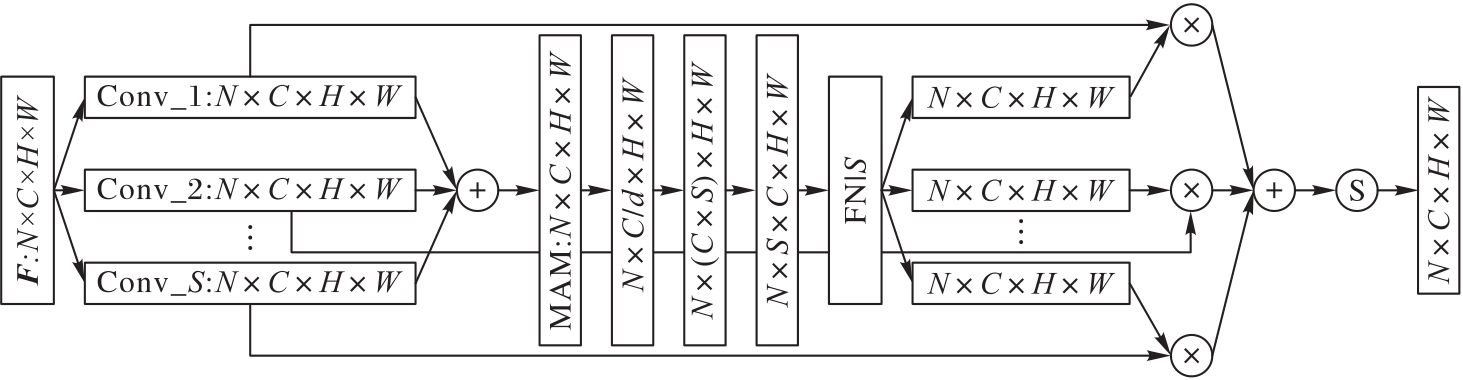
图5 SMAM的网络结构
Fig.5 Network structure of SMAM

图6 CSMAM的网络结构
Fig.6 Network structure of CSMAM
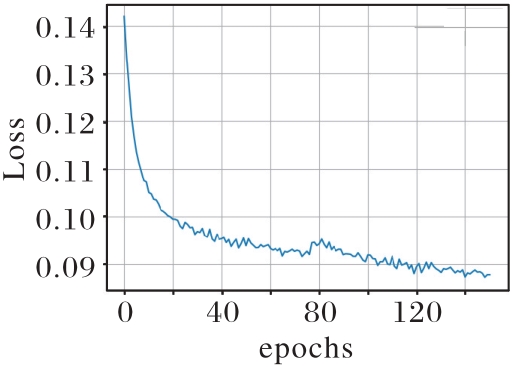
图7 训练损失曲线
Fig. 7 Curve of training loss
| 模型 | 输入 分辨率 | 参数量/106 | 模型 大小/MB | GFLOPs | mAP50/% | FPS1 280/(frame·s-1) |
|---|---|---|---|---|---|---|
| YOLOv5s | 640×640 | 7.02 | 56.81 | 15.8 | 32.27 | 122 |
| 960×960 | 7.02 | 57.02 | 33.9 | 41.34 | 122 | |
| 1 280×1 280 | 7.02 | 57.31 | 57.3 | 47.92 | 122 | |
| SMAM-YOLO | 640×640 | 7.37 | 60.59 | 19.9 | 38.16 | 74 |
| 960×960 | 7.37 | 61.44 | 42.6 | 45.82 | 74 | |
| 1 280×1 280 | 7.37 | 62.62 | 74.4 | 52.07 | 74 |
表1 分辨率实验结果
Tab. 1 Experimental results of resolution
| 模型 | 输入 分辨率 | 参数量/106 | 模型 大小/MB | GFLOPs | mAP50/% | FPS1 280/(frame·s-1) |
|---|---|---|---|---|---|---|
| YOLOv5s | 640×640 | 7.02 | 56.81 | 15.8 | 32.27 | 122 |
| 960×960 | 7.02 | 57.02 | 33.9 | 41.34 | 122 | |
| 1 280×1 280 | 7.02 | 57.31 | 57.3 | 47.92 | 122 | |
| SMAM-YOLO | 640×640 | 7.37 | 60.59 | 19.9 | 38.16 | 74 |
| 960×960 | 7.37 | 61.44 | 42.6 | 45.82 | 74 | |
| 1 280×1 280 | 7.37 | 62.62 | 74.4 | 52.07 | 74 |
| 序号 | 基线 | P2 | SMAM | CSMAM | 模型层数 | 参数量/106 | 模型大小/MB | GFLOPs | mAP50/% | FPS/(frame·s-1) |
|---|---|---|---|---|---|---|---|---|---|---|
| a | √ | 270 | 7.02 | 57.31 | 57.27 | 47.92 | 122 | |||
| b | √ | √ | 328 | 7.17 | 60.63 | 65.39 | 49.70 | 91 | ||
| c | √ | √ | √ | 496 | 7.62 | 64.43 | 76.16 | 51.71 | 78 | |
| d | √ | √ | √ | √ | 587 | 7.37 | 62.62 | 74.40 | 52.07 | 74 |
表2 消融实验结果
Tab. 2 Ablation experimental results
| 序号 | 基线 | P2 | SMAM | CSMAM | 模型层数 | 参数量/106 | 模型大小/MB | GFLOPs | mAP50/% | FPS/(frame·s-1) |
|---|---|---|---|---|---|---|---|---|---|---|
| a | √ | 270 | 7.02 | 57.31 | 57.27 | 47.92 | 122 | |||
| b | √ | √ | 328 | 7.17 | 60.63 | 65.39 | 49.70 | 91 | ||
| c | √ | √ | √ | 496 | 7.62 | 64.43 | 76.16 | 51.71 | 78 | |
| d | √ | √ | √ | √ | 587 | 7.37 | 62.62 | 74.40 | 52.07 | 74 |
| 模型 | 参数 量/106 | 模型 大小/MB | GFLOPs | mAP50/% | FPS/(frame·s-1) |
|---|---|---|---|---|---|
| CBAM | 7.23 | 60.41 | 64.56 | 50.61 | 77.02 |
| YOLOX-S | 9.01 | 212.23 | 92.99 | 47.61 | 69.98 |
| PP-YOLO-S | 7.91 | 59.16 | 63.37 | 48.23 | 117.08 |
| DETR | 41.00 | 123.65 | 86.01 | 46.16 | 27.90 |
| YOLOv7-tiny | 6.02 | 48.58 | 47.38 | 45.23 | 131.21 |
| YOLOv5s | 7.02 | 60.28 | 60.28 | 50.02 | 63.29 |
| SMAM-YOLO | 7.37 | 62.62 | 74.42 | 52.07 | 74.07 |
表3 不同小目标检测模型的对比实验结果
Tab. 3 Comparison experimental results of different small object detection models
| 模型 | 参数 量/106 | 模型 大小/MB | GFLOPs | mAP50/% | FPS/(frame·s-1) |
|---|---|---|---|---|---|
| CBAM | 7.23 | 60.41 | 64.56 | 50.61 | 77.02 |
| YOLOX-S | 9.01 | 212.23 | 92.99 | 47.61 | 69.98 |
| PP-YOLO-S | 7.91 | 59.16 | 63.37 | 48.23 | 117.08 |
| DETR | 41.00 | 123.65 | 86.01 | 46.16 | 27.90 |
| YOLOv7-tiny | 6.02 | 48.58 | 47.38 | 45.23 | 131.21 |
| YOLOv5s | 7.02 | 60.28 | 60.28 | 50.02 | 63.29 |
| SMAM-YOLO | 7.37 | 62.62 | 74.42 | 52.07 | 74.07 |
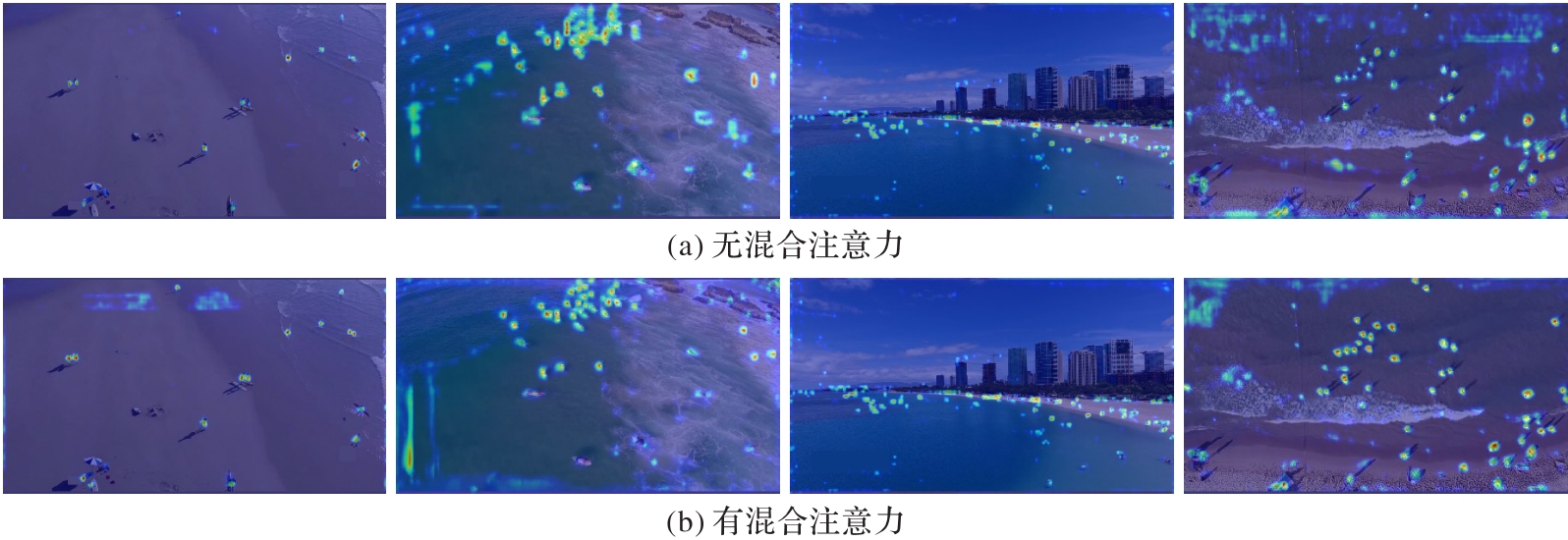
图8 添加混合注意力前后的热力图
Fig. 8 Heat maps before and after adding mixed attention

图9 添加混合注意力前后的检测效果图
Fig. 9 Detection effect diagrams before and after adding mixed attention
| 1 | LIN T Y, DOLLÁR P, GIRSHICK R, et al. Feature pyramid networks for object detection[C]// Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition. Washington, DC: IEEE Computer Society, 2017: 936-944. 10.1109/cvpr.2017.106 |
| 2 | LIU S, QI L, QIN H, et al. Path aggregation network for instance segmentation[C]// Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2018: 8759-8768. 10.1109/cvpr.2018.00913 |
| 3 | GHIASI G, LIN T Y, LE Q V. NAS-FPN: learning scalable feature pyramid architecture for object detection[C]// Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Washington, DC: IEEE Computer Society, 2019: 7029-7038. 10.1109/cvpr.2019.00720 |
| 4 | LIANG Z, SHAO J, ZHANG D, et al. Small object detection using deep feature pyramid networks[C]// Proceedings of the 2018 Pacific Rim Conference on Multimedia, LNCS 11166. Cham: Springer, 2018: 554-564. |
| 5 | TAN M, PANG R, LE Q V. EfficientDet: scalable and efficient object detection[C]// Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Washington, DC: IEEE Computer Society, 2020: 10778-10787. 10.1109/cvpr42600.2020.01079 |
| 6 | HU J, SHEN L, SUN G. Squeeze-and-excitation networks[C]// Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Washington, DC: IEEE Computer Society, 2018: 7132-7141. 10.1109/cvpr.2018.00745 |
| 7 | WOO S, PARK J, LEE J Y, et al. CBAM: convolutional block attention module[C]// Proceedings of the 2018 European Conference on Computer Vision, LNCS 11211. Cham: Springer, 2018: 3-19. |
| 8 | QIN Z, ZHANG P, WU F, et al. FcaNet: frequency channel attention networks[C]// Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision. Piscataway: IEEE, 2021: 763-772. 10.1109/iccv48922.2021.00082 |
| 9 | WANG C Y, LIAO H Y M, WU Y H, et al. CSPNet: a new backbone that can enhance learning capability of CNN[C]// Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops. Washington, DC: IEEE Computer Society, 2020: 1571-1580. 10.1109/cvprw50498.2020.00203 |
| 10 | 李科岑,王晓强,林浩,等. 深度学习中的单阶段小目标检测方法综述[J]. 计算机科学与探索, 2022, 16(1):41-58. 10.3778/j.issn.1673-9418.2110003 |
| LI K C, WANG X Q, LIN H, et al. A survey of one-stage small object detection methods in deep learning[J]. Journal of Frontiers of Computer Science and Technology, 2022, 16(1): 41-58. 10.3778/j.issn.1673-9418.2110003 | |
| 11 | KISANTAL M, WOJNA Z, MURAWSKI J, et al. Augmentation for small object detection[EB/OL]. [2023-02-12].. 10.5121/csit.2019.91713 |
| 12 | GONG Y, YU X, DING Y, et al. Effective fusion factor in FPN for tiny object detection[C]// Proceedings of the 2021 IEEE Winter Conference on Applications of Computer Vision. Piscataway: IEEE, 2021: 1159-1167. 10.1109/wacv48630.2021.00120 |
| 13 | JIANG N, YU X, PENG X, et al. SM+: refined scale match for tiny person detection[C]// Proceedings of the 2021 IEEE International Conference on Acoustics, Speech and Signal Processing. Piscataway: IEEE, 2021: 1815-1819. 10.1109/icassp39728.2021.9414162 |
| 14 | 李文涛,彭力. 多尺度通道注意力融合网络的小目标检测算法[J]. 计算机科学与探索, 2021, 15(12):2390-2400. |
| LI W T, PENG L. Small objects detection algorithm with multi-scale channel attention fusion network[J]. Journal of Frontiers of Computer Science and Technology, 2021, 15(12): 2390-2400. | |
| 15 | SZEGEDY C, LIU W, JIA Y, et al. Going deeper with convolutions[C]// Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition. Washington, DC: IEEE Computer Society, 2015: 1-9. 10.1109/cvpr.2015.7298594 |
| 16 | XIE S, GIRSHICK R, DOLLÁR P, et al. Aggregated residual transformations for deep neural networks[C]// Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition. Washington, DC: IEEE Computer Society, 2017: 5987-5995. 10.1109/cvpr.2017.634 |
| 17 | LI X, WANG W, HU X, et al. Selective kernel networks[C]// Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Washington, DC: IEEE Computer Society, 2019: 510-519. 10.1109/cvpr.2019.00060 |
| 18 | ZHANG H, WU C, ZHANG Z, et al. ResNeSt: split-attention networks[C]// Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops. Washington, DC: IEEE Computer Society, 2022: 2735-2745. 10.1109/cvprw56347.2022.00309 |
| 19 | REDMON J, DIVVALA S, GIRSHICK R, et al. You only look once: unified, real-time object detection[C]// Proceedings of the IEEE 2016 Conference on Computer Vision and Pattern Recognition. Washington, DC: IEEE Computer Society, 2016: 779-788. 10.1109/cvpr.2016.91 |
| 20 | REN S, HE K, GIRSHICK R, et al. Faster R-CNN: towards real-time object detection with region proposal networks[C]// Proceedings of the 28th International Conference on Neural Information Processing Systems — Volume 1. Cambridge: MIT Press, 2015:91-99. |
| 21 | HE K, GKIOSARI G, DOLLÁR P, et al. Mask R-CNN[C]// Proceedings of the 2017 IEEE International Conference on Computer Vision. Piscataway: IEEE, 2017: 2980-2988. 10.1109/iccv.2017.322 |
| 22 | 曹家乐,李亚利,孙汉卿,等.基于深度学习的视觉目标检测技术综述[J].中国图象图形学报,2022,27(6):1697-1722. 10.11834/jig.220069 |
| CAO J L, LI Y L, SUN H Q, et al. A survey on deep learning based visual object detection[J]. Journal of Image and Graphics, 2022, 27(6): 1697-1722. 10.11834/jig.220069 | |
| 23 | REDMON J, FARHADI A. YOLO9000: better, faster, stronger[C]// Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition. Washington, DC: IEEE Computer Society, 2017: 6517-6525. 10.1109/cvpr.2017.690 |
| 24 | REDMON J, FARHADI A. YOLOv3: an incremental improvement[EB/OL]. [2023-02-12].. 10.1109/cvpr.2017.690 |
| 25 | BOCHKOVSKIY A, WANG C Y, LIAO H Y M. YOLOv4: optimal speed and accuracy of object detection[EB/OL]. [2023-02-12].. |
| 26 | YU X, GONG Y, JIANG N, et al. Scale match for tiny person detection[C]// Proceedings of the 2020 IEEE Winter Conference on Applications of Computer Vision. Piscataway: IEEE, 2020: 1246-1254. 10.1109/wacv45572.2020.9093394 |
| 27 | LONG X, DENG K, WANG G, et al. PP-YOLO: an effective and efficient implementation of object detector[EB/OL]. [2023-02-12].. 10.48550/arXiv.2007.12099 |
| 28 | ZHU X, SU W, LU L, et al. Deformable DETR: deformable transformers for end-to-end object detection[EB/OL]. [2023-02-12].. |
| 29 | WANG C Y, BOCHKOVSKIY A, LIAO H Y M. YOLOv7: trainable bag-of-freebies sets new state-of-the-art for real-time object detectors[EB/OL]. [2023-02-12].. 10.48550/arXiv.2207.02696 |
| 30 | GE Z, LIU S, WANG F, et al. YOLOX: exceeding YOLO series in 2021[EB/OL]. [2023-02-12].. |
| 31 | SELVARAJU R R, COGSWELL M, DAS A, et al. Grad-CAM: visual explanations from deep networks via gradient-based localization[C]// Proceedings of the 2017 IEEE International Conference on Computer Vision. Piscataway: IEEE, 2017: 618-626. 10.1109/iccv.2017.74 |
| [1] | 潘烨新, 杨哲. 基于多级特征双向融合的小目标检测优化模型[J]. 《计算机应用》唯一官方网站, 2024, 44(9): 2871-2877. |
| [2] | 李烨恒, 罗光圣, 苏前敏. 基于改进YOLOv5的Logo检测算法[J]. 《计算机应用》唯一官方网站, 2024, 44(8): 2580-2587. |
| [3] | 姬张建, 杜娜. 基于改进VariFocalNet的微小目标检测[J]. 《计算机应用》唯一官方网站, 2024, 44(7): 2200-2207. |
| [4] | 刘瑞华, 郝子赫, 邹洋杨. 基于多层级精细特征融合的步态识别算法[J]. 《计算机应用》唯一官方网站, 2024, 44(7): 2250-2257. |
| [5] | 刘越, 刘芳, 武奥运, 柴秋月, 王天笑. 基于自注意力机制与图卷积的3D目标检测网络[J]. 《计算机应用》唯一官方网站, 2024, 44(6): 1972-1977. |
| [6] | 邓亚平, 李迎江. YOLO算法及其在自动驾驶场景中目标检测综述[J]. 《计算机应用》唯一官方网站, 2024, 44(6): 1949-1958. |
| [7] | 黄梦源, 常侃, 凌铭阳, 韦新杰, 覃团发. 基于层间引导的低光照图像渐进增强算法[J]. 《计算机应用》唯一官方网站, 2024, 44(6): 1911-1919. |
| [8] | 韩贵金, 张馨渊, 张文涛, 黄娅. 基于多特征融合的自监督图像配准算法[J]. 《计算机应用》唯一官方网站, 2024, 44(5): 1597-1604. |
| [9] | 李鸿天, 史鑫昊, 潘卫国, 徐成, 徐冰心, 袁家政. 融合多尺度和注意力机制的小样本目标检测[J]. 《计算机应用》唯一官方网站, 2024, 44(5): 1437-1444. |
| [10] | 李鑫, 孟乔, 皇甫俊逸, 孟令辰. 基于分离式标签协同学习的YOLOv5多属性分类[J]. 《计算机应用》唯一官方网站, 2024, 44(5): 1619-1628. |
| [11] | 王昊冉, 于丹, 杨玉丽, 马垚, 陈永乐. 面向工控系统未知攻击的域迁移入侵检测方法[J]. 《计算机应用》唯一官方网站, 2024, 44(4): 1158-1165. |
| [12] | 贾宗泽, 高鹏飞, 马应龙, 刘晓峰, 夏海鑫. 基于注意力机制的多特征融合对话行为层次化分类方法[J]. 《计算机应用》唯一官方网站, 2024, 44(3): 715-721. |
| [13] | 蒋占军, 吴佰靖, 马龙, 廉敬. 多尺度特征和极化自注意力的Faster-RCNN水漂垃圾识别[J]. 《计算机应用》唯一官方网站, 2024, 44(3): 938-944. |
| [14] | 李新叶, 侯晔凝, 孔英会, 燕志旗. 结合特征融合与增强注意力的少样本目标检测[J]. 《计算机应用》唯一官方网站, 2024, 44(3): 745-751. |
| [15] | 吴宁, 罗杨洋, 许华杰. 基于多尺度特征融合的遥感图像语义分割方法[J]. 《计算机应用》唯一官方网站, 2024, 44(3): 737-744. |
| 阅读次数 | ||||||
|
全文 |
|
|||||
|
摘要 |
|
|||||