


《计算机应用》唯一官方网站 ›› 2026, Vol. 46 ›› Issue (3): 915-923.DOI: 10.11772/j.issn.1001-9081.2025040475
邵培荣, 蔺素珍( ), 王彦博
), 王彦博
收稿日期:2025-04-30
修回日期:2025-06-14
接受日期:2025-06-23
发布日期:2025-06-26
出版日期:2026-03-10
通讯作者:
蔺素珍
作者简介:邵培荣(2001—),女,山西运城人,硕士研究生,CCF会员,主要研究方向:虚拟试衣、图像处理基金资助:
Peirong SHAO, Suzhen LIN(), Yanbo WANG
Received:2025-04-30
Revised:2025-06-14
Accepted:2025-06-23
Online:2025-06-26
Published:2026-03-10
Contact:
Suzhen LIN
About author:SHAO Peirong, born in 2001, M. S. candidate. Her research interests include virtual try-on, image processing.Supported by:摘要:
针对当前虚拟试衣方法无法充分保留目标服装的局部细节的问题,以及使用扩散模型生成试衣结果时,变分自编码器(VAE)会将输入数据映射到低维空间,从而导致模特手部和脸部高频细节特征丢失的问题,提出一种以人为中心的细节增强虚拟试衣方法。首先,将服装不可知的人体图、人体姿态图和目标服装输入几何匹配模块(GMM)以得到粗扭曲服装结果;其次,构建服装扭曲细化(GWR)模块增强粗扭曲服装的细节特征;再次,将服装扭曲图、服装不可知的人体图以及人体姿态图等拼接后和文本特征作为UNet的输入,融合文本特征与图像特征通过去噪逐步生成清晰的图像;继次,构建掩码特征连接(MFC)模块,引入坐标注意力机制,更准确地定位模特的位置信息,保留模特手部和脸部的高频细节特征,实现以人为中心的结果;最后,将MFC模块的输出与UNet的输出进行融合解码,得到最终的试衣结果。实验结果表明,与LADI-VTON(LAtent DIffusion-Virtual Try-ON)方法相比,所提方法在Dress Code数据集上的结构相似度指数(SSIM)指标提升了1.41%,在感知相似度(LPIPS)、FID(Fréchet Inception Distance)和KID(Kernel Inception Distance)指标上分别降低了7.32%、31.03%和64.56%,验证了所提方法的虚拟试衣效果更优。
中图分类号:
邵培荣, 蔺素珍, 王彦博. 以人为中心的细节增强虚拟试衣方法[J]. 计算机应用, 2026, 46(3): 915-923.
Peirong SHAO, Suzhen LIN, Yanbo WANG. Human-centric detail-enhanced virtual try-on method[J]. Journal of Computer Applications, 2026, 46(3): 915-923.
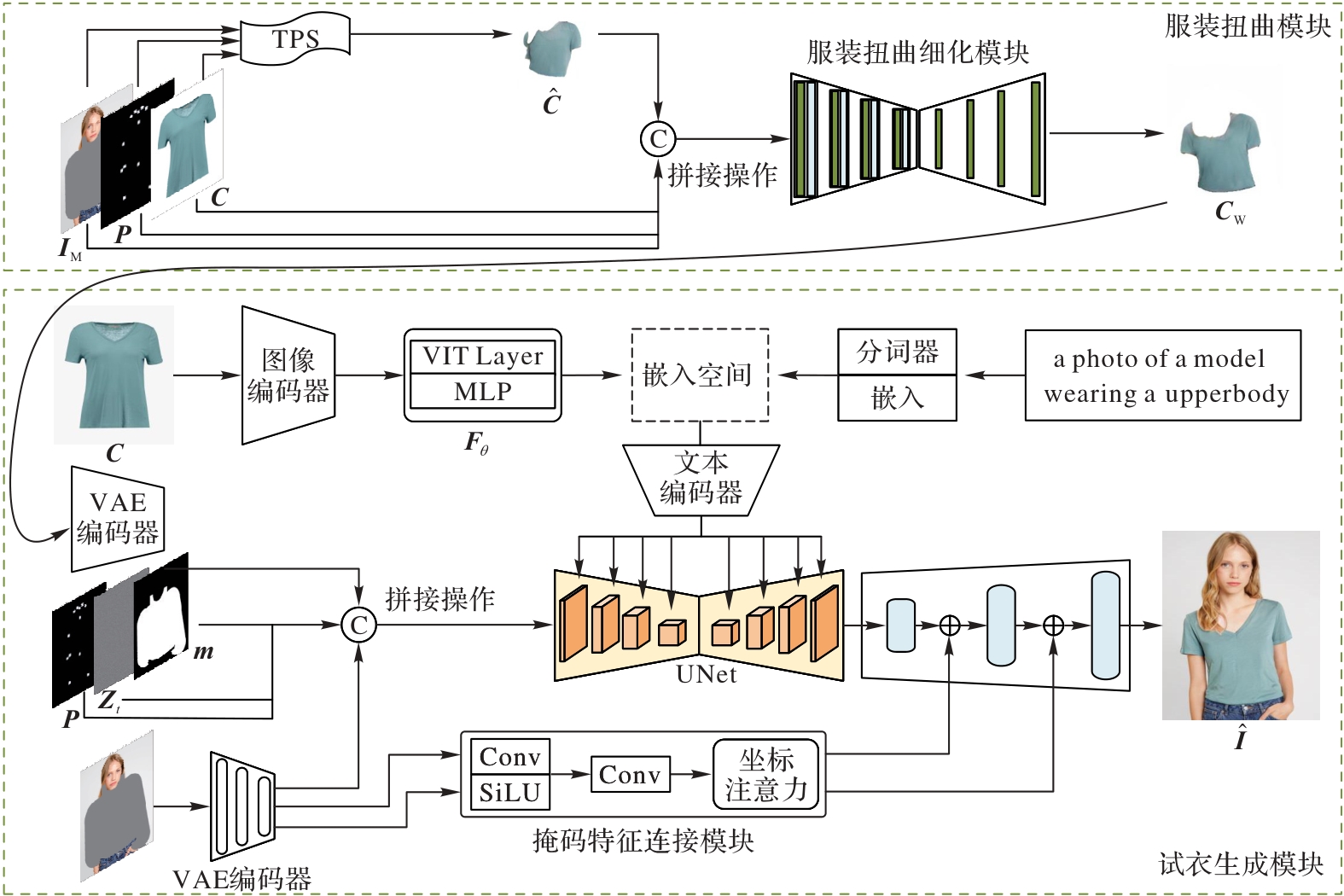
图1 本文方法的整体网络结构
Fig. 1 Overall network structure of proposed method
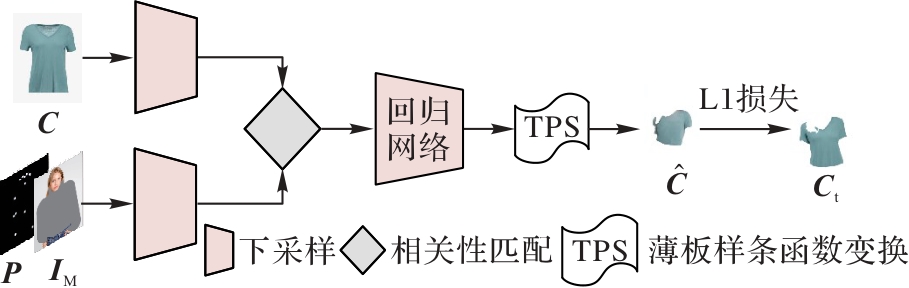
图2 粗扭曲模块
Fig. 2 Coarse warp module

图3 服装扭曲结果对比
Fig. 3 Comparison of garment warping results
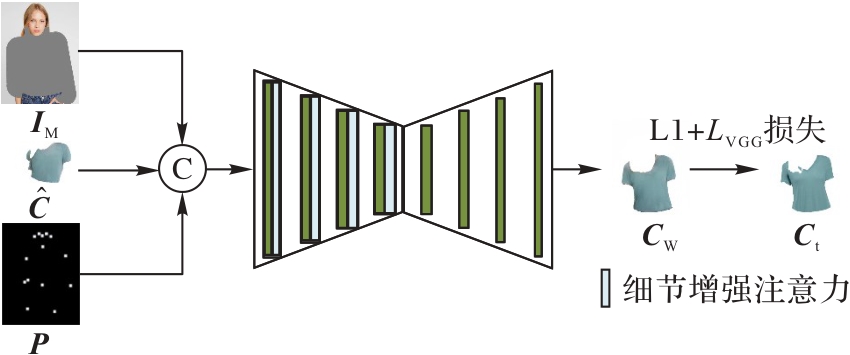
图4 GWR模块的结构
Fig. 4 Structure of GWR module
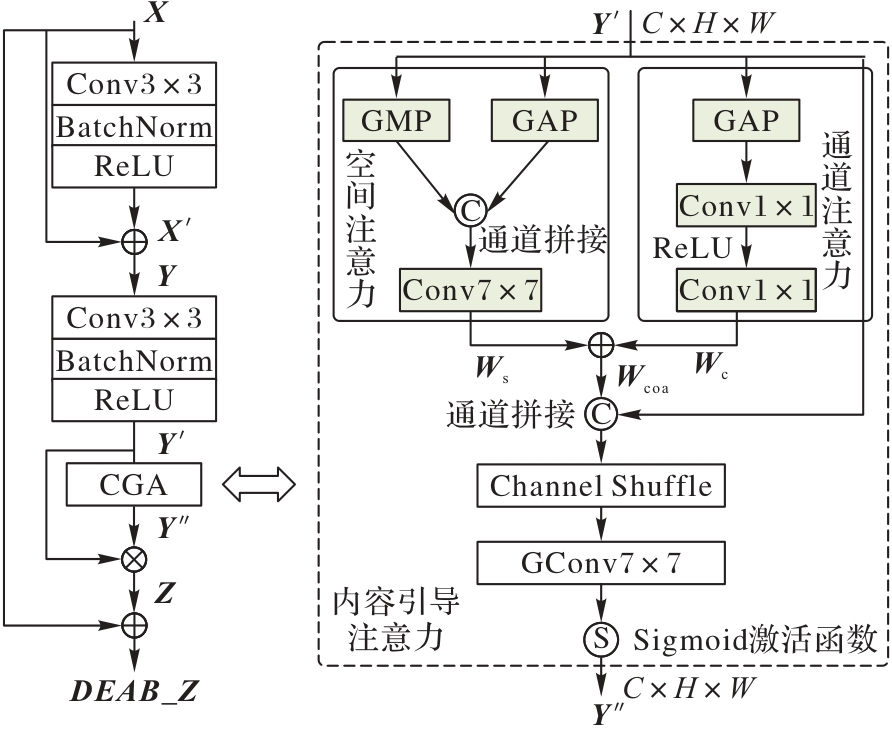
图5 DEAB的结构
Fig. 5 Structure of DEAB
| 层名 | 网络结构 | 输出尺寸 |
|---|---|---|
| input | — | (24,512,384) |
| inputConv | DoubleConv | (64,512,384) |
| down1 | MaxPool2d,DoubleConv,DEABlock | (128,256,192) |
| down2 | MaxPool2d,DoubleConv,DEABlock | (256,128,96) |
| down3 | MaxPool2d,DoubleConv,DEABlock | (512,64,48) |
| down4 | MaxPool2d,DoubleConv,DEABlock | (512,32,24) |
| up1 | Unsample,DoubleConv | (256,64,48) |
| up2 | Unsample,DoubleConv | (128,128,96) |
| up3 | Unsample,DoubleConv | (64,256,192) |
| up4 | Unsample,DoubleConv | (64,512,384) |
表1 服装扭曲细化模块的网络参数
Tab. 1 Network parameters of garment warp refinement module
| 层名 | 网络结构 | 输出尺寸 |
|---|---|---|
| input | — | (24,512,384) |
| inputConv | DoubleConv | (64,512,384) |
| down1 | MaxPool2d,DoubleConv,DEABlock | (128,256,192) |
| down2 | MaxPool2d,DoubleConv,DEABlock | (256,128,96) |
| down3 | MaxPool2d,DoubleConv,DEABlock | (512,64,48) |
| down4 | MaxPool2d,DoubleConv,DEABlock | (512,32,24) |
| up1 | Unsample,DoubleConv | (256,64,48) |
| up2 | Unsample,DoubleConv | (128,128,96) |
| up3 | Unsample,DoubleConv | (64,256,192) |
| up4 | Unsample,DoubleConv | (64,512,384) |
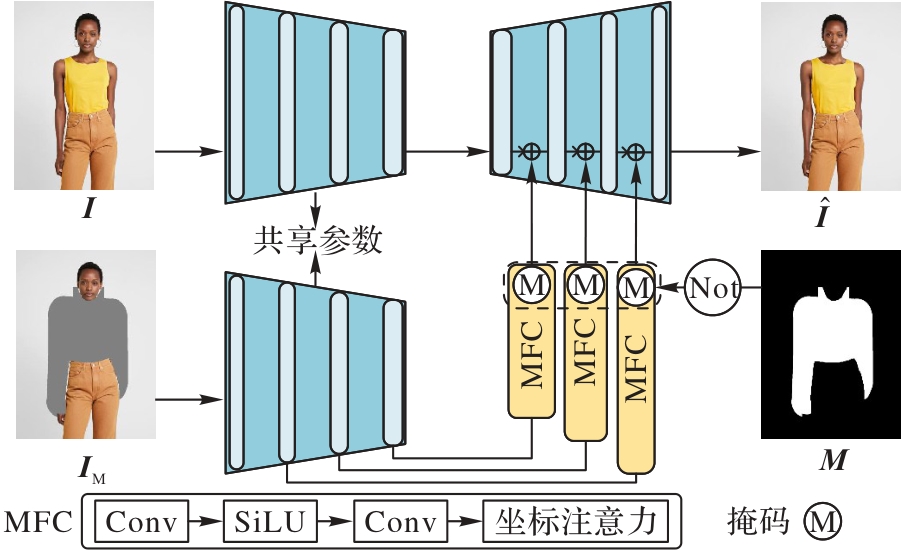
图6 MFC模块的结构
Fig. 6 Structure of MFC module
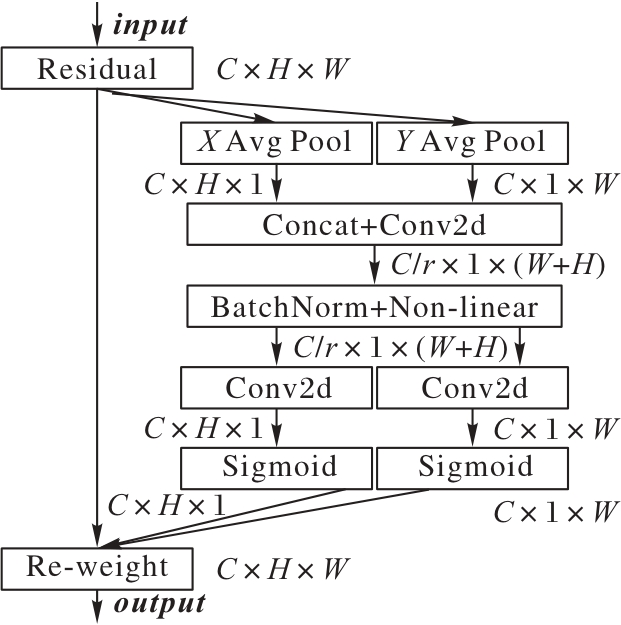
图7 坐标注意力机制的结构
Fig. 7 Structure of coordinate attention

图8 VITON-HD数据集上不同虚拟试衣方法的结果对比
Fig. 8 Results comparison of different virtual try-on methods on VITON-HD dataset

图9 Dress Code数据集上不同虚拟试衣方法的结果对比
Fig. 9 Results comparison of different virtual try-on methods on Dress Code dataset
| 方法 | FID | KID | SSIM | LPIPS |
|---|---|---|---|---|
| HR-VTON | 12.20 | 3.79 | 0.813 9 | 0.202 8 |
| GP-VTON | 9.66 | 1.58 | 0.216 1 | |
| LADI-VTON | 9.41 | 1.60 | 0.814 9 | |
| IDM-VTON | 1.40 | 0.808 1 | 0.210 1 | |
| OOTDiffusion | 9.59 | 1.53 | 0.798 6 | 0.215 2 |
| 本文方法 | 9.05 | 0.823 7 | 0.197 2 |
表2 VITON-HD数据集上的定量对比结果
Tab. 2 Quantitative comparison results on VITON-HD dataset
| 方法 | FID | KID | SSIM | LPIPS |
|---|---|---|---|---|
| HR-VTON | 12.20 | 3.79 | 0.813 9 | 0.202 8 |
| GP-VTON | 9.66 | 1.58 | 0.216 1 | |
| LADI-VTON | 9.41 | 1.60 | 0.814 9 | |
| IDM-VTON | 1.40 | 0.808 1 | 0.210 1 | |
| OOTDiffusion | 9.59 | 1.53 | 0.798 6 | 0.215 2 |
| 本文方法 | 9.05 | 0.823 7 | 0.197 2 |
| 方法 | 上半身服装 | 下半身服装 | 裙子 | 所有类别 | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| FID | KID | FID | KID | FID | KID | FID | KID | SSIM | LPIPS | |
| GP-VTON | 12.46 | 1.52 | 16.92 | 3.29 | 0.753 9 | 0.300 2 | ||||
| LADI-VTON | 13.96 | 3.02 | 14.61 | 3.32 | 6.96 | 2.37 | ||||
| IDM-VTON | 17.76 | 6.06 | 14.04 | 3.38 | 6.95 | 2.74 | 0.862 3 | 0.152 1 | ||
| OOTDiffusion | 12.28 | 1.56 | 16.48 | 4.62 | 14.68 | 3.42 | 6.23 | 2.97 | 0.849 9 | 0.138 2 |
| 本文方法 | 10.81 | 0.77 | 12.40 | 1.82 | 11.70 | 1.40 | 4.80 | 0.84 | 0.883 4 | 0.124 1 |
表3 基于Dress Code 数据集上的定量对比结果
Tab. 3 Quantitative comparison results on Dress Code dataset
| 方法 | 上半身服装 | 下半身服装 | 裙子 | 所有类别 | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| FID | KID | FID | KID | FID | KID | FID | KID | SSIM | LPIPS | |
| GP-VTON | 12.46 | 1.52 | 16.92 | 3.29 | 0.753 9 | 0.300 2 | ||||
| LADI-VTON | 13.96 | 3.02 | 14.61 | 3.32 | 6.96 | 2.37 | ||||
| IDM-VTON | 17.76 | 6.06 | 14.04 | 3.38 | 6.95 | 2.74 | 0.862 3 | 0.152 1 | ||
| OOTDiffusion | 12.28 | 1.56 | 16.48 | 4.62 | 14.68 | 3.42 | 6.23 | 2.97 | 0.849 9 | 0.138 2 |
| 本文方法 | 10.81 | 0.77 | 12.40 | 1.82 | 11.70 | 1.40 | 4.80 | 0.84 | 0.883 4 | 0.124 1 |
| 数据集 | 方法 | FID | KID | SSIM | LPIPS |
|---|---|---|---|---|---|
| VITON-HD | LADI-VTON | 9.41 | 1.60 | 0.814 9 | 0.202 6 |
| LADI-VTON(+MFC) | 1.46 | ||||
| LADI-VTON(+GWR) | 9.09 | 0.815 2 | 0.201 7 | ||
| 本文方法 | 9.05 | 1.41 | 0.823 7 | 0.197 2 | |
| Dress Code | LADI-VTON | 6.96 | 2.37 | 0.871 1 | 0.133 9 |
| LADI-VTON(+MFC) | 5.49 | 1.19 | |||
| LADI-VTON(+GWR) | 0.875 1 | 0.130 6 | |||
| 本文方法 | 4.80 | 0.84 | 0.883 4 | 0.124 1 |
表4 消融实验的定量对比结果
Tab. 4 Quantitative comparison results of ablation experiments
| 数据集 | 方法 | FID | KID | SSIM | LPIPS |
|---|---|---|---|---|---|
| VITON-HD | LADI-VTON | 9.41 | 1.60 | 0.814 9 | 0.202 6 |
| LADI-VTON(+MFC) | 1.46 | ||||
| LADI-VTON(+GWR) | 9.09 | 0.815 2 | 0.201 7 | ||
| 本文方法 | 9.05 | 1.41 | 0.823 7 | 0.197 2 | |
| Dress Code | LADI-VTON | 6.96 | 2.37 | 0.871 1 | 0.133 9 |
| LADI-VTON(+MFC) | 5.49 | 1.19 | |||
| LADI-VTON(+GWR) | 0.875 1 | 0.130 6 | |||
| 本文方法 | 4.80 | 0.84 | 0.883 4 | 0.124 1 |
| [1] | PONS-MOLL G, PUJADES S, HU S, et al. ClothCap: seamless 4D clothing capture and retargeting [J]. ACM Transactions on Graphics, 2017, 36(4): No.73. |
| [2] | PATEL C, LIAO Z, PONS-MOLL G. TailorNet: predicting clothing in 3D as a function of human pose, shape and garment style[C]// Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2020: 7363-7373. |
| [3] | 胡新荣,张君宇,彭涛,等. 级联跨域特征融合的虚拟试衣[J]. 计算机应用, 2022, 42(4): 1269-1274. |
| HU X R, ZHANG J Y, PENG T, et al. Cascaded cross-domain feature fusion for virtual try-on [J]. Journal of Computer Applications, 2022, 42(4): 1269-1274. | |
| [4] | CHOI S, PARK S, LEE M, et al. VITON-HD: high-resolution virtual try-on via misalignment-aware normalization [C]// Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2021: 14126-14135. |
| [5] | LEWIS K M, VARADHARAJAN S, KEMELMACHER-SHLIZERMAN I. TryOnGAN: body-aware try-on via layered interpolation [J]. ACM Transactions on Graphics, 2021, 40(4): No.115. |
| [6] | LEE S, GU G, PARK S, et al. High-resolution virtual try-on with misalignment and occlusion-handled conditions [C]// Proceedings of the 2022 European Conference on Computer Vision, LNCS 13677. Cham: Springer, 2022: 204-219. |
| [7] | XIE Z, HUANG Z, DONG X, et al. GP-VTON: towards general purpose virtual try-on via collaborative local-flow global-parsing learning [C]// Proceedings of the 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2023: 23550-23559. |
| [8] | YANG Z, CHEN J, SHI Y, et al. OccluMix: towards de-occlusion virtual try-on by semantically-guided mixup [J]. IEEE Transactions on Multimedia, 2023, 25: 1477-1488. |
| [9] | CHOI Y, KWAK S, LEE K, et al. Improving diffusion models for authentic virtual try-on in the wild [C]// Proceedings of the 2024 European Conference on Computer Vision, LNCS 15144. Cham: Springer, 2025: 206-235. |
| [10] | KIM J, GU G, PARK M, et al. Stable VITON: learning semantic correspondence with latent diffusion model for virtual try-on [C]// Proceedings of the 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2024: 8176-8185. |
| [11] | XU Y, GU T, CHEN W, et al. OOTDiffusion: outfitting fusion based latent diffusion for controllable virtual try-on [C]// Proceedings of the 39th AAAI Conference on Artificial Intelligence. Palo Alto: AAAI Press, 2025: 8996-9004. |
| [12] | MORELLI D, BALDRATI A, CARTELLA G, et al. LaDI-VTON: latent diffusion textual-inversion enhanced virtual try-on[C]// Proceedings of the 31st ACM International Conference on Multimedia. New York: ACM, 2023: 8580-8589. |
| [13] | GOODFELLOW I, POUGET-ABADIE J, MIRZA M, et al. Generative adversarial networks [J]. Communications of the ACM, 2020, 63(11): 139-144. |
| [14] | ROMBACH R, BLATTMANN A, LORENZ D, et al. High-resolution image synthesis with latent diffusion models [C]// Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2022: 10674-10685. |
| [15] | RADFORD A, KIM J W, HALLACY C, et al. Learning transferable visual models from natural language supervision [C]// Proceedings of the 2021 International Conference on Machine Learning. New York: JMLR.org, 2021: 8748-8763. |
| [16] | RONNEBERGER O, FISCHER P, BROX T. U-Net: convolutional networks for biomedical image segmentation [C]// Proceedings of the 2015 Medical Image Computing and Computer-Assisted Intervention, LNCS 9351. Cham: Springer, 2015: 234-241. |
| [17] | WANG B, ZHENG H, LIANG X, et al. Toward characteristic-preserving image-based virtual try-on network [C]// Proceedings of the 2018 European Conference on Computer Vision, LNCS 11217. Cham: Springer, 2018: 607-623. |
| [18] | DUCHON J. Splines minimizing rotation-invariant semi-norms in Sobolev spaces [C]// Constructive Theory of Functions of Several Variables: Proceedings of a Conference Held at Oberwolfach, April 25 — May 1, 1976, LNM 571. Berlin: Springer, 1977: 85-100. |
| [19] | ISOLA P, ZHU J Y, ZHOU T, et al. Image-to-image translation with conditional adversarial networks [C]// Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2017: 5967-5976. |
| [20] | MORELLI D, FINCATO M, CORNIA M, et al. Dress Code: high-resolution multi-category virtual try-on [C]// Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops. Piscataway: IEEE, 2022: 2230-2234. |
| [21] | CAO Z, SIMON T, WEI S E, et al. Realtime multi-person 2D pose estimation using part affinity fields [C]// Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2017: 1302-1310. |
| [22] | CHEN Z, HE Z, LU Z M. DEA-Net: single image dehazing based on detail-enhanced convolution and content-guided attention [J]. IEEE Transactions on Image Processing, 2024, 33: 1002-1015. |
| [23] | DENG J, DONG W, SOCHER R, et al. ImageNet: a large-scale hierarchical image database [C]// Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2009: 248-255. |
| [24] | ZHANG S, HAN X, ZHANG W, et al. Limb-aware virtual try-on network with progressive clothing warping [J]. IEEE Transactions on Multimedia, 2024, 26: 1731-1746. |
| [25] | ZHANG X, CHEN J, MA L, et al. A virtual try-on network with arm region preservation [J]. Applied Soft Computing, 2025, 175: No.112960. |
| [1] | 胡岩, 李鹏, 成姝燕. 基于直接引导扩散模型的对抗净化方法[J]. 《计算机应用》唯一官方网站, 2026, 46(3): 821-829. |
| [2] | 陈敏, 秦小林, 李绍涵, 杨昊, 李韬弘. 深度学习应用于强对流天气预测的综述[J]. 《计算机应用》唯一官方网站, 2026, 46(3): 980-992. |
| [3] | 李海丰, 刘文强, 李南莎, 桂仲成. 面向机场跑道的探地雷达杂波抑制算法[J]. 《计算机应用》唯一官方网站, 2026, 46(2): 659-665. |
| [4] | 贾源, 袁得嵛, 潘语泉, 王安然. 面向扩散模型输出的水印方法[J]. 《计算机应用》唯一官方网站, 2026, 46(1): 161-168. |
| [5] | 周金, 李玉芝, 张徐, 高硕, 张立, 盛家川. 复杂电磁环境下的调制识别网络[J]. 《计算机应用》唯一官方网站, 2025, 45(8): 2672-2682. |
| [6] | 冯兴杰, 卞兴鹏, 冯小荣, 王兴隆. 基于扩散模型的增量式时间序列缺失值填充算法[J]. 《计算机应用》唯一官方网站, 2025, 45(8): 2582-2591. |
| [7] | 李强, 白少雄, 熊源, 袁薇. 基于视觉大模型隐私保护的监控图像定位[J]. 《计算机应用》唯一官方网站, 2025, 45(3): 832-839. |
| [8] | 桂佳扬, 王顺吉, 周正康, 唐加山. 基于改进YOLOv8n的隧道内异物检测算法[J]. 《计算机应用》唯一官方网站, 2025, 45(2): 655-661. |
| [9] | 高鹏淇, 黄鹤鸣, 樊永红. 融合坐标与多头注意力机制的交互语音情感识别[J]. 《计算机应用》唯一官方网站, 2024, 44(8): 2400-2406. |
| [10] | 李晨阳, 张龙, 郑秋生, 钱少华. 基于扩散序列的多元可控文本生成[J]. 《计算机应用》唯一官方网站, 2024, 44(8): 2414-2420. |
| [11] | 徐劲松, 朱明, 李智强, 郭世杰. 基于激发和汇聚注意力的扩散模型生成对象的位置控制方法[J]. 《计算机应用》唯一官方网站, 2024, 44(4): 1093-1098. |
| [12] | 刘雨生, 肖学中. 基于扩散模型微调的高保真图像编辑[J]. 《计算机应用》唯一官方网站, 2024, 44(11): 3574-3580. |
| [13] | 郑秋梅, 牛薇薇, 王风华, 赵丹. 基于细节增强的双分支实时语义分割网络[J]. 《计算机应用》唯一官方网站, 2024, 44(10): 3058-3066. |
| [14] | 胡新荣, 张君宇, 彭涛, 刘军平, 何儒汉, 何凯. 级联跨域特征融合的虚拟试衣[J]. 《计算机应用》唯一官方网站, 2022, 42(4): 1269-1274. |
| [15] | 翟东海 左文杰 段维夏 鱼江 李同亮. 基于双十字曲率驱动扩散模型的图像修复算法[J]. 计算机应用, 2013, 33(12): 3536-3539. |
| 阅读次数 | ||||||
|
全文 |
|
|||||
|
摘要 |
|
|||||