


《计算机应用》唯一官方网站 ›› 2026, Vol. 46 ›› Issue (4): 1050-1057.DOI: 10.11772/j.issn.1001-9081.2025040517
胡婕1,2,3, 李鹏程1, 孙军1,2,3( ), 张佳傲1
), 张佳傲1
收稿日期:2025-05-12
修回日期:2025-07-15
接受日期:2025-07-17
发布日期:2025-07-22
出版日期:2026-04-10
通讯作者:
孙军
作者简介:胡婕(1977—),女,湖北汉川人,教授,博士,主要研究方向:复杂语义大数据管理、自然语言处理基金资助:
Jie HU1,2,3, Pengcheng LI1, Jun SUN1,2,3(), Jiaao ZHANG1
Received:2025-05-12
Revised:2025-07-15
Accepted:2025-07-17
Online:2025-07-22
Published:2026-04-10
Contact:
Jun SUN
About author:HU Jie, born in 1977, Ph. D., professor. Her research interests include complex semantic big data management, natural language processing.Supported by:摘要:
现有的无监督关键短语提取模型对复杂的上下文和多层次语义信息的捕获能力不足,无法获取多维度信息。因此,提出一种基于多视角信息增强和层次化权重的关键短语提取模型。首先,利用BERT(Bidirectional Encoder Representations from Transformers)预训练模型对文本和候选短语进行编码,获得嵌入表示;并且,通过加权平均池化优化文本嵌入,并计算它们与候选短语的全局相似度,以实现全局信息增强,提升对语义关联的理解。其次,提出基于图结构的边界感知局部中心性计算方法,以增强局部信息获取能力。最后,融合多因素计算权重,从多个维度评估候选短语的重要性。在Inspec、SemEval 2017和SemEval-2010等6个公开数据集上的实验结果表明,与基线模型PromptRank相比,所提模型的F1@5值提高了0.87~2.68个百分点,F1@10值提高了1.11~2.24个百分点,F1@15值提高了0.54~2.25个百分点。可见,所提模型的综合性能得到了有效提升。
中图分类号:
胡婕, 李鹏程, 孙军, 张佳傲. 基于多视角信息增强和层次化权重的关键短语抽取模型[J]. 计算机应用, 2026, 46(4): 1050-1057.
Jie HU, Pengcheng LI, Jun SUN, Jiaao ZHANG. Key phrase extraction model based on multi-perspective information enhancement and hierarchical weighting[J]. Journal of Computer Applications, 2026, 46(4): 1050-1057.
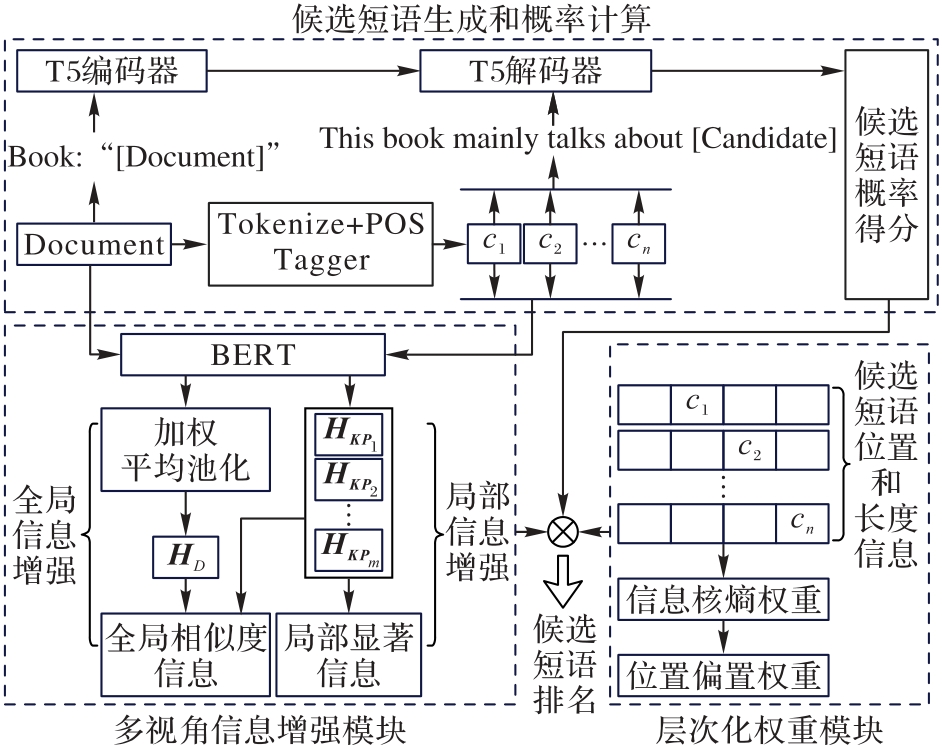
图1 本文模型的结构
Fig. 1 Structure of proposed model
| 数据集 | 文档数 | 文档平均长度 | 候选关键 短语总数 | 黄金关键 短语总数 |
|---|---|---|---|---|
| Inspec | 500 | 122 | 15 841 | 4 912 |
| SemEval 2017 | 493 | 170 | 21 264 | 8 387 |
| SemEval-2010 | 243 | 190 | 4 355 | 1 506 |
| DUC2001 | 308 | 725 | 35 926 | 2 479 |
| NUS | 211 | 7 702 | 25 494 | 2 453 |
| Krapivin | 460 | 8 545 | 55 875 | 2 641 |
表1 数据集详情
Tab. 1 Dataset details
| 数据集 | 文档数 | 文档平均长度 | 候选关键 短语总数 | 黄金关键 短语总数 |
|---|---|---|---|---|
| Inspec | 500 | 122 | 15 841 | 4 912 |
| SemEval 2017 | 493 | 170 | 21 264 | 8 387 |
| SemEval-2010 | 243 | 190 | 4 355 | 1 506 |
| DUC2001 | 308 | 725 | 35 926 | 2 479 |
| NUS | 211 | 7 702 | 25 494 | 2 453 |
| Krapivin | 460 | 8 545 | 55 875 | 2 641 |
| 参数 | 值 | 参数 | 值 |
|---|---|---|---|
| BERT层数 | 12 | b2 | 512 |
| T5层数 | 24 | 隐藏层大小 | 768 |
| b1 | 512 | 输入最大长度 | 512 |
表2 模型参数
Tab. 2 Model parameters
| 参数 | 值 | 参数 | 值 |
|---|---|---|---|
| BERT层数 | 12 | b2 | 512 |
| T5层数 | 24 | 隐藏层大小 | 768 |
| b1 | 512 | 输入最大长度 | 512 |
| 评价指标 | 模型 | Inspec | SemEval 2017 | SemEval-2010 | DUC2001 | NUS | Krapivin |
|---|---|---|---|---|---|---|---|
| F1@5 | TextRank | 21.58(-12.31) | 16.43(-13.39) | 7.42(-11.92) | 11.02(-17.81) | 1.80(-16.63) | 6.04(-10.94) |
| SingleRank | 14.88(-19.01) | 18.23(-11.59) | 8.69(-10.65) | 19.14(-9.69) | 2.98(-15.45) | 8.12(-8.86) | |
| TopicRank | 12.20(-21.69) | 17.10(-12.72) | 9.93(-9.41) | 19.97(-8.86) | 4.54(-13.89) | 8.94(-8.04) | |
| MultipartiteRank | 13.41(-20.48) | 17.39(-12.43) | 10.13(-9.21) | 21.70(-7.13) | 6.17(-12.26) | 9.29(-7.69) | |
| YAKE | 8.02(-25.87) | 11.84(-17.98) | 6.82(-12.52) | 11.99(-16.84) | 7.85(-10.58) | 8.09(-8.89) | |
| EmbedRank(BERT) | 28.92(-4.97) | 20.03(-9.79) | 10.46(-8.88) | 8.12(-20.71) | 3.75(-14.68) | 4.05(-12.93) | |
| SIFRank(ELMo) | 29.38(-4.51) | 22.38(-7.44) | 11.16(-8.18) | 24.30(-4.53) | 3.01(-15.42) | 1.62(-15.36) | |
| MDERank(BERT) | 26.17(-7.72) | 22.81(-7.01) | 12.95(-6.39) | 13.05(-15.78) | 15.24(-3.19) | 11.78(-5.20) | |
| PromptRank | 31.73(-2.16) | 27.14(-2.68) | 17.24(-2.10) | 27.39(-1.44) | 17.24(-1.19) | 16.11(-0.87) | |
| MICRank | 30.06(-3.83) | 23.01(-6.84) | 15.52(-3.83) | 26.24(-2.59) | 15.76(-2.67) | 14.01(-2.97) | |
| Attention-Seeker | 35.49(+1.60) | 25.40(-4.42) | 19.00(-0.34) | — | — | 20.79(+3.81) | |
| 本文模型 | 33.89 | 29.82 | 19.34 | 28.83 | 18.43 | 16.98 | |
| F1@10 | TextRank | 27.53(-12.59) | 25.83(-13.61) | 11.27(-11.34) | 17.45(-15.87) | 3.02(-18.41) | 9.43(-8.39) |
| SingleRank | 21.50(-18.62) | 27.73(-11.71) | 12.94(-9.67) | 23.86(-9.46) | 4.51(-16.92) | 10.53(-7.29) | |
| TopicRank | 17.24(-22.88) | 22.62(-16.82) | 12.52(-10.09) | 21.73(-11.59) | 7.93(-13.50) | 9.01(-8.81) | |
| MultipartiteRank | 18.18(-21.94) | 23.73(-15.71) | 12.91(-9.70) | 24.10(-9.22) | 8.57(-12.86) | 9.35(-8.47) | |
| YAKE | 11.47(-28.65) | 18.14(-21.30) | 11.01(-11.60) | 14.18(-19.14) | 11.05(-10.38) | 9.35(-8.47) | |
| EmbedRank(BERT) | 38.55(-1.57) | 31.01(-8.43) | 16.35(-6.26) | 11.62(-21.70) | 6.34(-15.09) | 6.60(-11.22) | |
| SIFRank(ELMo) | 39.12(-1.00) | 32.60(-6.84) | 16.03(-6.58) | 27.60(-5.72) | 5.34(-16.09) | 2.52(-15.30) | |
| MDERank(BERT) | 33.81(-6.31) | 32.51(-6.93) | 17.07(-5.54) | 17.31(-16.01) | 18.33(-3.10) | 12.93(-4.89) | |
| PromptRank | 37.88(-2.24) | 37.76(-1.68) | 20.66(-1.95) | 31.59(-1.73) | 20.13(-1.30) | 16.71(-1.11) | |
| MICRank | 39.05(-1.07) | 33.58(-5.86) | 20.34(-2.27) | 29.73(-3.59) | 18.95(-2.93) | 16.00(-1.82) | |
| Attention-Seeker | 40.14(+0.02) | 34.35(-4.91) | 23.07(+0.46) | — | — | 18.25(+0.43) | |
| 本文模型 | 40.12 | 39.44 | 22.61 | 33.32 | 21.43 | 17.82 | |
| F1@15 | TextRank | 27.62(-12.80) | 30.50(-12.61) | 13.47(-9.67) | 18.84(-13.67) | 3.53(-17.23) | 9.95(-6.99) |
| SingleRank | 24.13(-16.29) | 31.73(-11.38) | 14.4(-8.74) | 23.43(-9.08) | 4.92(-15.84) | 10.42(-6.52) | |
| TopicRank | 19.33(-21.09) | 24.87(-18.24) | 12.26(-10.88) | 20.97(-11.54) | 9.37(-11.39) | 8.30(-8.64) | |
| MultipartiteRank | 20.52(-19.90) | 26.87(-16.24) | 13.24(-9.90) | 23.62(-8.89) | 10.82(-9.94) | 9.16(-7.78) | |
| YAKE | 13.65(-26.77) | 20.55(-22.56) | 12.55(-10.59) | 14.28(-18.23) | 13.09(-7.67) | 9.12(-7.82) | |
| EmbedRank(BERT) | 39.77(-0.65) | 36.72(-6.39) | 19.35(-3.79) | 13.58(-18.93) | 8.11(-12.65) | 7.84(-9.10) | |
| SIFRank(ELMo) | 39.82(-0.60) | 37.25(-5.86) | 18.42(-4.72) | 27.96(-4.55) | 5.86(-14.90) | 3.00(-13.94) | |
| MDERank(BERT) | 36.17(-4.25) | 37.18(-5.93) | 20.09(-3.05) | 19.13(-13.38) | 17.95(-2.81) | 12.58(-4.36) | |
| PromptRank | 38.17(-2.25) | 41.57(-1.54) | 21.35(-1.79) | 31.01(-1.50) | 20.12(-0.64) | 16.02(-0.92) | |
| MICRank | 40.20(-0.22) | 38.36(-3.75) | 21.58(-1.56) | 30.31(-3.04) | 19.46(-1.30) | 15.54(-1.40) | |
| Attention-Seeker | 39.22(-1.20) | 38.50(-3.61) | 23.81(+0.67) | — | — | 16.22(-0.72) | |
| 本文模型 | 40.42 | 42.11 | 23.14 | 33.51 | 20.76 | 16.94 |
表3 各模型在6个数据集上的评价指标对比 (%)
Tab. 3 Evaluation index comparison of different models on six datasets
| 评价指标 | 模型 | Inspec | SemEval 2017 | SemEval-2010 | DUC2001 | NUS | Krapivin |
|---|---|---|---|---|---|---|---|
| F1@5 | TextRank | 21.58(-12.31) | 16.43(-13.39) | 7.42(-11.92) | 11.02(-17.81) | 1.80(-16.63) | 6.04(-10.94) |
| SingleRank | 14.88(-19.01) | 18.23(-11.59) | 8.69(-10.65) | 19.14(-9.69) | 2.98(-15.45) | 8.12(-8.86) | |
| TopicRank | 12.20(-21.69) | 17.10(-12.72) | 9.93(-9.41) | 19.97(-8.86) | 4.54(-13.89) | 8.94(-8.04) | |
| MultipartiteRank | 13.41(-20.48) | 17.39(-12.43) | 10.13(-9.21) | 21.70(-7.13) | 6.17(-12.26) | 9.29(-7.69) | |
| YAKE | 8.02(-25.87) | 11.84(-17.98) | 6.82(-12.52) | 11.99(-16.84) | 7.85(-10.58) | 8.09(-8.89) | |
| EmbedRank(BERT) | 28.92(-4.97) | 20.03(-9.79) | 10.46(-8.88) | 8.12(-20.71) | 3.75(-14.68) | 4.05(-12.93) | |
| SIFRank(ELMo) | 29.38(-4.51) | 22.38(-7.44) | 11.16(-8.18) | 24.30(-4.53) | 3.01(-15.42) | 1.62(-15.36) | |
| MDERank(BERT) | 26.17(-7.72) | 22.81(-7.01) | 12.95(-6.39) | 13.05(-15.78) | 15.24(-3.19) | 11.78(-5.20) | |
| PromptRank | 31.73(-2.16) | 27.14(-2.68) | 17.24(-2.10) | 27.39(-1.44) | 17.24(-1.19) | 16.11(-0.87) | |
| MICRank | 30.06(-3.83) | 23.01(-6.84) | 15.52(-3.83) | 26.24(-2.59) | 15.76(-2.67) | 14.01(-2.97) | |
| Attention-Seeker | 35.49(+1.60) | 25.40(-4.42) | 19.00(-0.34) | — | — | 20.79(+3.81) | |
| 本文模型 | 33.89 | 29.82 | 19.34 | 28.83 | 18.43 | 16.98 | |
| F1@10 | TextRank | 27.53(-12.59) | 25.83(-13.61) | 11.27(-11.34) | 17.45(-15.87) | 3.02(-18.41) | 9.43(-8.39) |
| SingleRank | 21.50(-18.62) | 27.73(-11.71) | 12.94(-9.67) | 23.86(-9.46) | 4.51(-16.92) | 10.53(-7.29) | |
| TopicRank | 17.24(-22.88) | 22.62(-16.82) | 12.52(-10.09) | 21.73(-11.59) | 7.93(-13.50) | 9.01(-8.81) | |
| MultipartiteRank | 18.18(-21.94) | 23.73(-15.71) | 12.91(-9.70) | 24.10(-9.22) | 8.57(-12.86) | 9.35(-8.47) | |
| YAKE | 11.47(-28.65) | 18.14(-21.30) | 11.01(-11.60) | 14.18(-19.14) | 11.05(-10.38) | 9.35(-8.47) | |
| EmbedRank(BERT) | 38.55(-1.57) | 31.01(-8.43) | 16.35(-6.26) | 11.62(-21.70) | 6.34(-15.09) | 6.60(-11.22) | |
| SIFRank(ELMo) | 39.12(-1.00) | 32.60(-6.84) | 16.03(-6.58) | 27.60(-5.72) | 5.34(-16.09) | 2.52(-15.30) | |
| MDERank(BERT) | 33.81(-6.31) | 32.51(-6.93) | 17.07(-5.54) | 17.31(-16.01) | 18.33(-3.10) | 12.93(-4.89) | |
| PromptRank | 37.88(-2.24) | 37.76(-1.68) | 20.66(-1.95) | 31.59(-1.73) | 20.13(-1.30) | 16.71(-1.11) | |
| MICRank | 39.05(-1.07) | 33.58(-5.86) | 20.34(-2.27) | 29.73(-3.59) | 18.95(-2.93) | 16.00(-1.82) | |
| Attention-Seeker | 40.14(+0.02) | 34.35(-4.91) | 23.07(+0.46) | — | — | 18.25(+0.43) | |
| 本文模型 | 40.12 | 39.44 | 22.61 | 33.32 | 21.43 | 17.82 | |
| F1@15 | TextRank | 27.62(-12.80) | 30.50(-12.61) | 13.47(-9.67) | 18.84(-13.67) | 3.53(-17.23) | 9.95(-6.99) |
| SingleRank | 24.13(-16.29) | 31.73(-11.38) | 14.4(-8.74) | 23.43(-9.08) | 4.92(-15.84) | 10.42(-6.52) | |
| TopicRank | 19.33(-21.09) | 24.87(-18.24) | 12.26(-10.88) | 20.97(-11.54) | 9.37(-11.39) | 8.30(-8.64) | |
| MultipartiteRank | 20.52(-19.90) | 26.87(-16.24) | 13.24(-9.90) | 23.62(-8.89) | 10.82(-9.94) | 9.16(-7.78) | |
| YAKE | 13.65(-26.77) | 20.55(-22.56) | 12.55(-10.59) | 14.28(-18.23) | 13.09(-7.67) | 9.12(-7.82) | |
| EmbedRank(BERT) | 39.77(-0.65) | 36.72(-6.39) | 19.35(-3.79) | 13.58(-18.93) | 8.11(-12.65) | 7.84(-9.10) | |
| SIFRank(ELMo) | 39.82(-0.60) | 37.25(-5.86) | 18.42(-4.72) | 27.96(-4.55) | 5.86(-14.90) | 3.00(-13.94) | |
| MDERank(BERT) | 36.17(-4.25) | 37.18(-5.93) | 20.09(-3.05) | 19.13(-13.38) | 17.95(-2.81) | 12.58(-4.36) | |
| PromptRank | 38.17(-2.25) | 41.57(-1.54) | 21.35(-1.79) | 31.01(-1.50) | 20.12(-0.64) | 16.02(-0.92) | |
| MICRank | 40.20(-0.22) | 38.36(-3.75) | 21.58(-1.56) | 30.31(-3.04) | 19.46(-1.30) | 15.54(-1.40) | |
| Attention-Seeker | 39.22(-1.20) | 38.50(-3.61) | 23.81(+0.67) | — | — | 16.22(-0.72) | |
| 本文模型 | 40.42 | 42.11 | 23.14 | 33.51 | 20.76 | 16.94 |
| 模型 | 评价指标 | Inspec | SemEval 2017 | SemEval-2010 | DUC2001 | NUS | Krapivin |
|---|---|---|---|---|---|---|---|
| 本文模型 | F1@5 | 33.89 | 29.82 | 19.34 | 28.83 | 18.43 | 16.98 |
| F1@10 | 40.12 | 39.44 | 22.61 | 33.32 | 21.43 | 17.82 | |
| F1@15 | 40.42 | 42.11 | 23.14 | 33.51 | 20.76 | 16.94 | |
| 去除T5模型 | F1@5 | 27.35 | 22.39 | 13.28 | 24.58 | 14.23 | 13.14 |
| F1@10 | 36.13 | 32.18 | 17.69 | 27.64 | 17.36 | 15.62 | |
| F1@15 | 37.32 | 38.93 | 18.23 | 27.86 | 17.03 | 15.41 | |
| 去除全局信息增强 | F1@5 | 31.74 | 26.32 | 17.36 | 28.35 | 17.23 | 15.63 |
| F1@10 | 39.25 | 37.22 | 20.03 | 32.16 | 20.09 | 16.86 | |
| F1@15 | 39.43 | 41.06 | 22.09 | 32.13 | 20.02 | 16.53 | |
| 去除局部信息增强 | F1@5 | 29.43 | 24.58 | 15.43 | 27.54 | 16.38 | 15.32 |
| F1@10 | 38.15 | 35.81 | 19.05 | 30.45 | 19.49 | 16.82 | |
| F1@15 | 39.39 | 40.64 | 20.42 | 30.86 | 19.34 | 14.52 | |
| 去除层次化权重 | F1@5 | 30.25 | 24.69 | 16.35 | 27.32 | 15.96 | 15.21 |
| F1@10 | 38.69 | 36.24 | 19.85 | 30.02 | 19.73 | 16.52 | |
| F1@15 | 38.92 | 41.75 | 20.32 | 30.51 | 19.67 | 16.32 |
表4 消融实验结果 (%)
Tab. 4 Ablation experimental results
| 模型 | 评价指标 | Inspec | SemEval 2017 | SemEval-2010 | DUC2001 | NUS | Krapivin |
|---|---|---|---|---|---|---|---|
| 本文模型 | F1@5 | 33.89 | 29.82 | 19.34 | 28.83 | 18.43 | 16.98 |
| F1@10 | 40.12 | 39.44 | 22.61 | 33.32 | 21.43 | 17.82 | |
| F1@15 | 40.42 | 42.11 | 23.14 | 33.51 | 20.76 | 16.94 | |
| 去除T5模型 | F1@5 | 27.35 | 22.39 | 13.28 | 24.58 | 14.23 | 13.14 |
| F1@10 | 36.13 | 32.18 | 17.69 | 27.64 | 17.36 | 15.62 | |
| F1@15 | 37.32 | 38.93 | 18.23 | 27.86 | 17.03 | 15.41 | |
| 去除全局信息增强 | F1@5 | 31.74 | 26.32 | 17.36 | 28.35 | 17.23 | 15.63 |
| F1@10 | 39.25 | 37.22 | 20.03 | 32.16 | 20.09 | 16.86 | |
| F1@15 | 39.43 | 41.06 | 22.09 | 32.13 | 20.02 | 16.53 | |
| 去除局部信息增强 | F1@5 | 29.43 | 24.58 | 15.43 | 27.54 | 16.38 | 15.32 |
| F1@10 | 38.15 | 35.81 | 19.05 | 30.45 | 19.49 | 16.82 | |
| F1@15 | 39.39 | 40.64 | 20.42 | 30.86 | 19.34 | 14.52 | |
| 去除层次化权重 | F1@5 | 30.25 | 24.69 | 16.35 | 27.32 | 15.96 | 15.21 |
| F1@10 | 38.69 | 36.24 | 19.85 | 30.02 | 19.73 | 16.52 | |
| F1@15 | 38.92 | 41.75 | 20.32 | 30.51 | 19.67 | 16.32 |
| F1@10/% | ||||||
|---|---|---|---|---|---|---|
| Inspec | SemEval 2017 | SemEval-2010 | DUC2001 | NUS | Krapivin | |
| 0.5 | 38.90 | 38.44 | 21.11 | 31.32 | 20.43 | 16.82 |
| 0.8 | 40.12 | 39.44 | 22.61 | 33.32 | 20.53 | 16.72 |
| 1.0 | 40.01 | 38.84 | 21.61 | 32.99 | 20.93 | 17.62 |
| 1.2 | 40.02 | 39.04 | 22.01 | 32.32 | 21.43 | 17.82 |
| 1.5 | 39.91 | 38.94 | 22.21 | 33.02 | 21.03 | 17.72 |
表5 α超参数的实验结果
Tab. 5 Experimental results of hyperparameter α
| F1@10/% | ||||||
|---|---|---|---|---|---|---|
| Inspec | SemEval 2017 | SemEval-2010 | DUC2001 | NUS | Krapivin | |
| 0.5 | 38.90 | 38.44 | 21.11 | 31.32 | 20.43 | 16.82 |
| 0.8 | 40.12 | 39.44 | 22.61 | 33.32 | 20.53 | 16.72 |
| 1.0 | 40.01 | 38.84 | 21.61 | 32.99 | 20.93 | 17.62 |
| 1.2 | 40.02 | 39.04 | 22.01 | 32.32 | 21.43 | 17.82 |
| 1.5 | 39.91 | 38.94 | 22.21 | 33.02 | 21.03 | 17.72 |
| F1@10/% | ||||||
|---|---|---|---|---|---|---|
| Inspec | SemEval 2017 | SemEval-2010 | DUC2001 | NUS | Krapivin | |
| 0.10 | 38.90 | 38.44 | 21.11 | 31.32 | 20.43 | 16.82 |
| 0.15 | 39.41 | 38.34 | 21.43 | 33.12 | 20.53 | 17.82 |
| 0.20 | 40.12 | 39.44 | 22.61 | 33.32 | 21.43 | 17.82 |
| 0.25 | 40.02 | 39.04 | 22.01 | 32.32 | 21.33 | 17.62 |
| 0.30 | 39.91 | 38.94 | 22.21 | 33.02 | 21.03 | 17.82 |
表6 β超参数的实验结果
Tab. 6 Experimental results of hyperparameter β
| F1@10/% | ||||||
|---|---|---|---|---|---|---|
| Inspec | SemEval 2017 | SemEval-2010 | DUC2001 | NUS | Krapivin | |
| 0.10 | 38.90 | 38.44 | 21.11 | 31.32 | 20.43 | 16.82 |
| 0.15 | 39.41 | 38.34 | 21.43 | 33.12 | 20.53 | 17.82 |
| 0.20 | 40.12 | 39.44 | 22.61 | 33.32 | 21.43 | 17.82 |
| 0.25 | 40.02 | 39.04 | 22.01 | 32.32 | 21.33 | 17.62 |
| 0.30 | 39.91 | 38.94 | 22.21 | 33.02 | 21.03 | 17.82 |
| F1@10/% | ||||||
|---|---|---|---|---|---|---|
| Inspec | SemEval 2017 | SemEval-2010 | DUC2001 | NUS | Krapivin | |
| 0.7 | 38.90 | 38.44 | 21.11 | 31.32 | 20.43 | 16.82 |
| 0.8 | 40.02 | 38.14 | 22.41 | 32.32 | 21.43 | 16.72 |
| 0.9 | 40.12 | 39.44 | 22.61 | 33.32 | 20.93 | 17.72 |
| 1.0 | 40.02 | 39.04 | 22.01 | 32.32 | 20.83 | 17.02 |
表7 λ超参数的实验结果
Tab. 7 Experimental results of hyperparameter λ
| F1@10/% | ||||||
|---|---|---|---|---|---|---|
| Inspec | SemEval 2017 | SemEval-2010 | DUC2001 | NUS | Krapivin | |
| 0.7 | 38.90 | 38.44 | 21.11 | 31.32 | 20.43 | 16.82 |
| 0.8 | 40.02 | 38.14 | 22.41 | 32.32 | 21.43 | 16.72 |
| 0.9 | 40.12 | 39.44 | 22.61 | 33.32 | 20.93 | 17.72 |
| 1.0 | 40.02 | 39.04 | 22.01 | 32.32 | 20.83 | 17.02 |
| 模型 | F1@10 | ||
|---|---|---|---|
| Inspec | DUC2001 | NUS | |
| 本文模型 | 40.12 | 33.32 | 21.43 |
| AvgPool | 39.72 | 32.81 | 21.21 |
| MaxPool | 39.26 | 32.27 | 20.62 |
表8 全局信息增强池化的实验结果 (%)
Tab. 8 Experimental results of global information enhancement pooling
| 模型 | F1@10 | ||
|---|---|---|---|
| Inspec | DUC2001 | NUS | |
| 本文模型 | 40.12 | 33.32 | 21.43 |
| AvgPool | 39.72 | 32.81 | 21.21 |
| MaxPool | 39.26 | 32.27 | 20.62 |
| [1] | 胡少虎,张颖怡,章成志. 关键词提取研究综述[J]. 数据分析与知识发现, 2021, 5(3): 45-59. |
| HU S H, ZHANG Y Y, ZHANG C Z. Review of keyword extraction studies[J]. Data Analysis and Knowledge Discovery, 2021, 5(3): 45-59. | |
| [2] | 罗燕,赵书良,李晓超,等. 基于词频统计的文本关键词提取方法[J]. 计算机应用, 2016, 36(3): 718-725. |
| LUO Y, ZHAO S L, LI X C, et al. Text keyword extraction method based on word frequency statistics[J]. Journal of Computer Applications, 2016, 36(3): 718-725. | |
| [3] | ROELLEKE T, WANG J. TF-IDF uncovered: a study of theories and probabilities[C]// Proceedings of the 31st Annual International ACM SIGIR Conference on Research and Development in Information Retrieval. New York: ACM, 2008: 435-442. |
| [4] | CAMPOS R, MANGARAVITE V, PASQUALI A, et al. YAKE! collection-independent automatic keyword extractor[C]// Proceedings of the 2018 European Conference on Information Retrieval, LNCS 10772. Cham: Springer, 2018: 806-810. |
| [5] | MIHALCEA R, TARAU P. TextRank: bringing order into text[C]// Proceedings of the 2004 Conference on Empirical Methods in Natural Language Processing. Stroudsburg: ACL, 2004: 404-411. |
| [6] | WAN X, XIAO J. CollabRank: towards a collaborative approach to single-document keyphrase extraction[C]// Proceedings of the 22nd International Conference on Computational Linguistics. [S.l.]: Coling 2008 Organizing Committee, 2008: 969-976. |
| [7] | BOUGOUIN A, BOUDIN F, DAILLE B. TopicRank: graph-based topic ranking for keyphrase extraction[C]// Proceedings of the 6th International Joint Conference on Natural Language Processing. [S.l.]: Asian Federation of Natural Language Processing, 2013: 543-551. |
| [8] | BOUDIN F. Unsupervised keyphrase extraction with multipartite graphs[C]// Proceedings of the 2018 Conference on the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 2 (Short Papers). Stroudsburg: ACL, 2018: 667-672. |
| [9] | WEN Y, YUAN H, ZHANG P. Research on keyword extraction based on Word2Vec weighted TextRank[C]// Proceedings of the 2nd IEEE International Conference on Computer and Communications. Piscataway: IEEE, 2016: 2109-2113. |
| [10] | FLORESCU C, CARAGEA C. PositionRank: an unsupervised approach to keyphrase extraction from scholarly documents[C]// Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Stroudsburg: ACL, 2017: 1105-1115. |
| [11] | WANG R, LIU W, McDONALD C. Using word embeddings to enhance keyword identification for scientific publications[C]// Proceedings of the 2015 Australasian Database Conference, LNCS 9093. Cham: Springer, 2015: 257-268. |
| [12] | MAHATA D, KURIAKOSE J, SHAH R, et al. Key2Vec: automatic ranked keyphrase extraction from scientific articles using phrase embeddings[C]// Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 2 (Short Papers). Stroudsburg: ACL, 2018: 634-639. |
| [13] | BENNANI-SMIRES K, MUSAT C, HOSSMANN A, et al. Simple unsupervised keyphrase extraction using sentence embeddings[C]// Proceedings of the 22nd Conference on Computational Natural Language Learning. Stroudsburg: ACL, 2018: 221-229. |
| [14] | SUN Y, QIU H, ZHENG Y, et al. SIFRank: a new baseline for unsupervised keyphrase extraction based on pre-trained language model[J]. IEEE Access, 2020, 8: 10896-10906. |
| [15] | SARZYNSKA-WAWER J, WAWER A, PAWLAK A, et al. Detecting formal thought disorder by deep contextualized word representations[J]. Psychiatry Research, 2021, 304: No.114135. |
| [16] | DING H, LUO X. AttentionRank: unsupervised keyphrase extraction using self and cross attentions[C]// Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing. Stroudsburg: ACL, 2021: 1919-1928. |
| [17] | ZHANG L, CHEN Q, WANG W, et al. MDERank: a masked document embedding rank approach for unsupervised keyphrase extraction[C]// Findings of the Association for Computational Linguistics: ACL 2022. Stroudsburg: ACL, 2022: 396-409. |
| [18] | KONG A, ZHAO S, CHEN H, et al. PromptRank: unsupervised keyphrase extraction using prompt[C]// Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics. Stroudsburg: ACL, 2023: 9788-9801. |
| [19] | BAI R, LIU F, ZHUANG X, et al. MICRank: multi-information interconstrained keyphrase extraction[J]. Expert Systems with Applications, 2024, 249(Pt C): No.123744. |
| [20] | LÓPEZ ZAPATA E D, TANG C, SHIMADA A. Attention-Seeker: dynamic self-attention scoring for unsupervised keyphrase extraction[C]// Proceedings of the 31st International Conference on Computational Linguistics. Stroudsburg: ACL, 2025: 5011-5026. |
| [21] | NAZARUKA E, OSIS J, GRIBERMAN V. Using Stanford CoreNLP capabilities for semantic information extraction from textual descriptions[C]// Proceedings of the 2019 International Conference on Evaluation of Novel Approaches to Software Engineering, CCIS 1172. Cham: Springer, 2020: 1-21. |
| [22] | HULTH A. Improved automatic keyword extraction given more linguistic knowledge[C]// Proceedings of the 2003 Conference on Empirical Methods in Natural Language Processing. Stroudsburg: ACL, 2003: 216-223. |
| [23] | KIM S N, MEDELYAN O, KAN M Y, et al. SemEval-2010 task 5: automatic keyphrase extraction from scientific[C]// Proceedings of the 5th International Workshop on Semantic Evaluation. Stroudsburg: ACL, 2010: 21-26. |
| [24] | AUGENSTEIN I, DAS M, RIEDEL S, et al. SemEval 2017 task 10: ScienceIE-extracting keyphrases and relations from scientific publications[C]// Proceedings of the 11th International Workshop on Semantic Evaluation. Stroudsburg: ACL, 2017: 546-555. |
| [25] | NGUYEN T D, KAN M Y. Keyphrase extraction in scientific publications[C]// Proceedings of the 2007 International Conference on Asian Digital Libraries, LNCS 4822. Berlin: Springer, 2007: 317-326. |
| [26] | WAN X, XIAO J. Single document keyphrase extraction using neighborhood knowledge[C]// Proceedings of the 23rd Conference on Artificial Intelligence. Palo Alto: AAAI Press, 2008: 855-860. |
| [27] | KRAPIVIN M, AUTAEU A, MARCHESE M. Large dataset for keyphrases extraction[R]. Trento: University of Trento, 2009. |
| [1] | 索逸凡, 刘松华, 郝秋智. 基于高阶特征聚合的时间序列异常检测方法[J]. 《计算机应用》唯一官方网站, 2026, 46(4): 1131-1138. |
| [2] | 尹春勇, 张不凡. 基于多尺度的多变量时间序列异常检测模型[J]. 《计算机应用》唯一官方网站, 2026, 46(3): 790-797. |
| [3] | 董莉梅, 李雁姿, 李家印, 许力. 基于邻域增强的无监督图异常检测[J]. 《计算机应用》唯一官方网站, 2026, 46(2): 458-466. |
| [4] | 王艺涵, 路翀, 陈忠源. 跨模态文本信息增强的多模态情感分析模型[J]. 《计算机应用》唯一官方网站, 2025, 45(7): 2237-2244. |
| [5] | 黄颖, 高胜美, 陈广, 刘苏. 结合信噪比引导的双分支结构和直方图均衡的低照度图像增强网络[J]. 《计算机应用》唯一官方网站, 2025, 45(6): 1971-1979. |
| [6] | 何玉林, 李旭, 贺颖婷, 崔来中, 黄哲学. 基于最大均值差异的子空间高斯混合模型聚类集成算法[J]. 《计算机应用》唯一官方网站, 2025, 45(6): 1712-1723. |
| [7] | 杨雅莉, 黎英, 章育涛, 宋佩华. 面向人脸识别的多模态研究方法综述[J]. 《计算机应用》唯一官方网站, 2025, 45(5): 1645-1657. |
| [8] | 王文鹏, 秦寅畅, 师文轩. 工业缺陷检测无监督深度学习方法综述[J]. 《计算机应用》唯一官方网站, 2025, 45(5): 1658-1670. |
| [9] | 杨定木, 倪龙强, 梁晶, 邱照原, 张永真, 齐志强. 基于语义相似度的协议转换方法[J]. 《计算机应用》唯一官方网站, 2025, 45(4): 1263-1270. |
| [10] | 潘理虎, 彭守信, 张睿, 薛之洋, 毛旭珍. 面向运动前景区域的视频异常检测[J]. 《计算机应用》唯一官方网站, 2025, 45(4): 1300-1309. |
| [11] | 安俊秀, 杨林旺, 柳源. 基于邻近性语义感知的无监督文本风格迁移[J]. 《计算机应用》唯一官方网站, 2025, 45(4): 1139-1147. |
| [12] | 李林昊, 韩冬, 董永峰, 李英双, 王振. 基于关联信息增强与关系平衡的场景图生成方法[J]. 《计算机应用》唯一官方网站, 2025, 45(3): 953-962. |
| [13] | 李雨轩, 陈斌, 咸伟志. 基于去噪反向蒸馏的无监督工业异常检测[J]. 《计算机应用》唯一官方网站, 2025, 45(11): 3721-3729. |
| [14] | 蒋章涛, 李欣, 张士豪, 赵心阳. 融合BERT与X-means算法的微博舆情热度分析预测模型[J]. 《计算机应用》唯一官方网站, 2025, 45(10): 3138-3145. |
| [15] | 王一铭, 李世源, 廖南清, 陈庆锋. 基于证据深度学习的不确定性感知无监督医学图像配准模型[J]. 《计算机应用》唯一官方网站, 2025, 45(10): 3371-3380. |
| 阅读次数 | ||||||
|
全文 |
|
|||||
|
摘要 |
|
|||||