


《计算机应用》唯一官方网站 ›› 2025, Vol. 45 ›› Issue (4): 1190-1198.DOI: 10.11772/j.issn.1001-9081.2024030331
刘天宇, 陶冶( ), 鲁超峰, 刘家旺
), 鲁超峰, 刘家旺
收稿日期:2024-03-25
修回日期:2024-04-29
接受日期:2024-05-06
发布日期:2024-06-04
出版日期:2025-04-10
通讯作者:
陶冶
作者简介:刘天宇(1999—),女,山东济宁人,硕士研究生,主要研究方向:自然语言处理、说话人识别基金资助:
Tianyu LIU, Ye TAO(), Chaofeng LU, Jiawang LIU
Received:2024-03-25
Revised:2024-04-29
Accepted:2024-05-06
Online:2024-06-04
Published:2025-04-10
Contact:
Ye TAO
About author:LIU Tianyu, born in 1999, M. S. candidate. Her research interests include natural language processing, speaker identification.Supported by:摘要:
小说中的说话人识别(SI)旨在通过引语所在上下文判断它的说话人。这项任务对在制作有声书的过程中为不同的角色分配合适的声音有很大帮助。然而,现有方法对引语上下文的选择主要以固定窗口值为主,这种方式不够灵活,会产生冗余文段,导致模型不易捕捉到真正有用的信息。另外,由于不同小说的引语数量和写作风格差异巨大,仅靠少量的标注样本无法使模型充分泛化,同时数据集的标注比较昂贵。为了解决上述问题,提出一个融合叙事单元和可靠标签的小说说话人识别框架。首先,使用基于叙事单元的上下文选择(NUCS)方法选择合适长度的上下文,从而让模型高度聚焦与引语归因最密切的文段;其次,构建一个说话人评分网络(SSN),并把生成的上下文作为输入;此外,引入自训练,并设计一个可靠伪标签选择(RPLS)算法,从而在一定程度上弥补标签样本过少的不足,筛选出更可靠且质量更高的伪标签样本;最后,构建并标注一个包含11本中文小说的中文小说说话人识别语料库(CNSI)。为评价所提框架,在2个公开数据集和自建数据集上进行实验,结果表明,融合叙事单元和可靠标签的小说说话人识别框架优于CSN(Candidate Scoring Network)、E2E_SI和ChatGPT-3.5等方法。
中图分类号:
刘天宇, 陶冶, 鲁超峰, 刘家旺. 融合叙事单元和可靠标签的小说说话人识别框架[J]. 计算机应用, 2025, 45(4): 1190-1198.
Tianyu LIU, Ye TAO, Chaofeng LU, Jiawang LIU. Novel speaker identification framework based on narrative unit and reliable label[J]. Journal of Computer Applications, 2025, 45(4): 1190-1198.

图1 引语类型
Fig. 1 Types of quotation
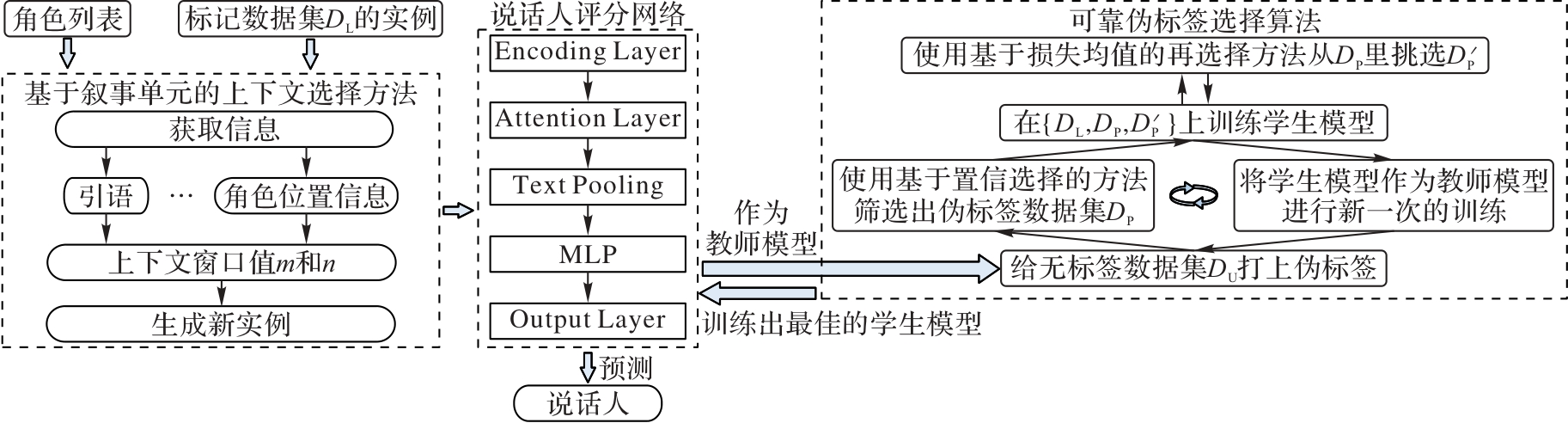
图2 本文方法的框架
Fig. 2 Structure of proposed framework
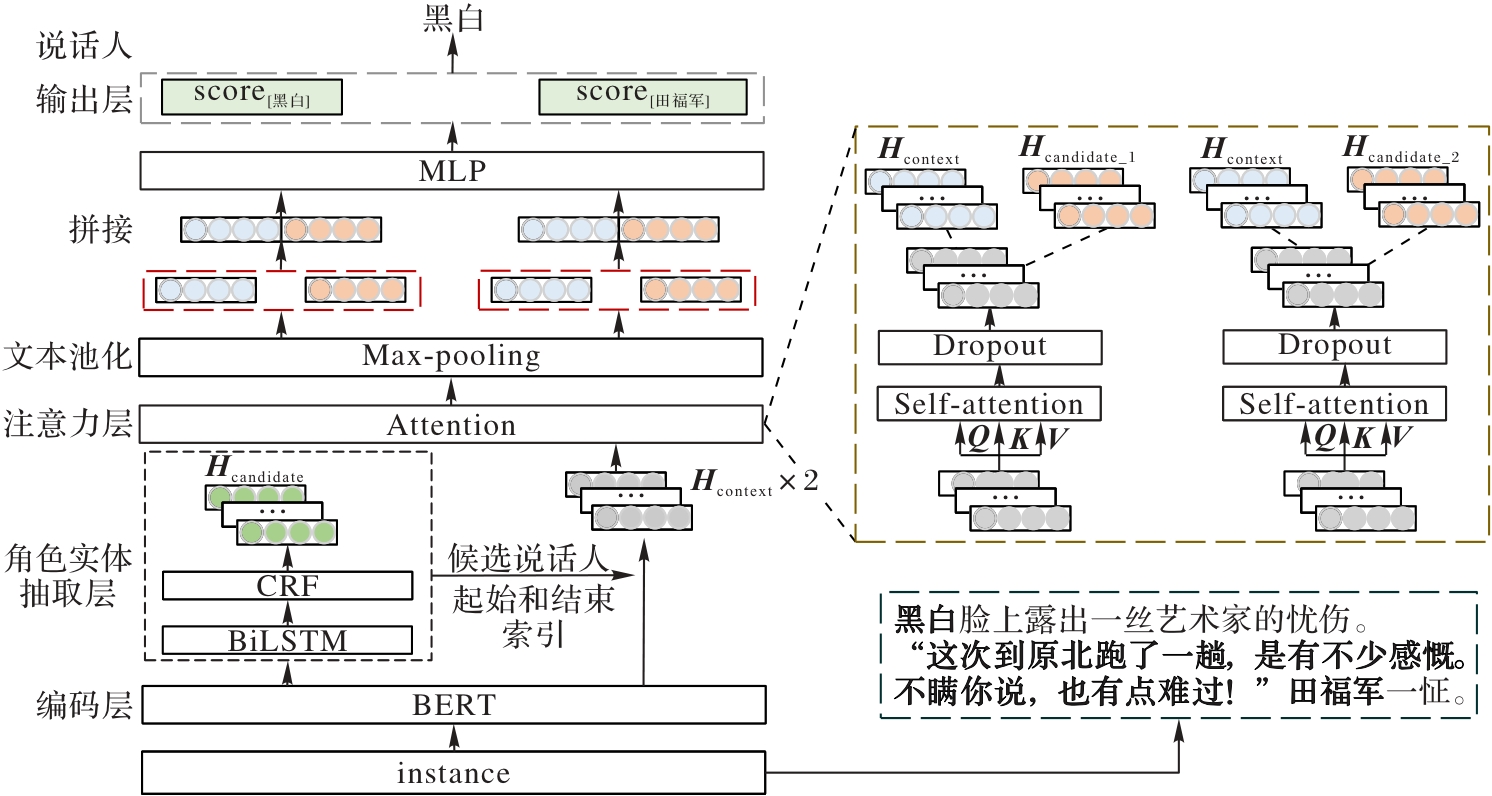
图3 本文网络的结构
Fig. 3 Structure of proposed network
| 数据集 | 训练集 样本数 | 验证集 样本数 | 测试集 样本数 | 书籍 数 | 全部 句数 | 对话 句数 | 对话 占比/% |
|---|---|---|---|---|---|---|---|
| WP | 2 000 | 298 | 298 | 1 | 15 171 | 2 596 | 17.11 |
| JY | 17 159 | 5 719 | 5 719 | 3 | 69 043 | 28 597 | 41.42 |
| CNSI | 20 204 | 6 658 | 6 658 | 11 | 89 705 | 26 862 | 29.94 |
表1 数据集信息
Tab. 1 Information of datasets
| 数据集 | 训练集 样本数 | 验证集 样本数 | 测试集 样本数 | 书籍 数 | 全部 句数 | 对话 句数 | 对话 占比/% |
|---|---|---|---|---|---|---|---|
| WP | 2 000 | 298 | 298 | 1 | 15 171 | 2 596 | 17.11 |
| JY | 17 159 | 5 719 | 5 719 | 3 | 69 043 | 28 597 | 41.42 |
| CNSI | 20 204 | 6 658 | 6 658 | 11 | 89 705 | 26 862 | 29.94 |
| 方法 | 预训练模型 | 规则使用情况 | WP | JY | CNSI |
|---|---|---|---|---|---|
| Random | 无 | 无 | 37.6 | 33.7 | 42.7 |
| Rule | 无 | 纯规则 | 72.1 | 86.6 | 78.4 |
| SVM | 无 | 基于规则的特征 | 61.0 | 94.5 | — |
| MLP | 无 | 基于规则的特征 | 70.5 | 95.6 | — |
| CSN | BERT-base | 后处理 | 82.5 | 97.4 | 89.1 |
| ChatGPT-3.5-turbo | GPT-3.5 | 无 | 83.8 | 97.9 | 90.7 |
| E2E_SI | RoBERTa-wwm-large | 无 | 80.9 | 98.3 | 86.1 |
| SSN | BERT-wwm-ext | 无 | 83.5 | 98.1 | 90.9 |
| SSN | BERT-base | 无 | 84.3 | 98.3 | 91.3 |
表2 各方法在不同数据集上的准确率对比 (%)
Tab. 2 Comparison of accuracies of various methods on different datasets
| 方法 | 预训练模型 | 规则使用情况 | WP | JY | CNSI |
|---|---|---|---|---|---|
| Random | 无 | 无 | 37.6 | 33.7 | 42.7 |
| Rule | 无 | 纯规则 | 72.1 | 86.6 | 78.4 |
| SVM | 无 | 基于规则的特征 | 61.0 | 94.5 | — |
| MLP | 无 | 基于规则的特征 | 70.5 | 95.6 | — |
| CSN | BERT-base | 后处理 | 82.5 | 97.4 | 89.1 |
| ChatGPT-3.5-turbo | GPT-3.5 | 无 | 83.8 | 97.9 | 90.7 |
| E2E_SI | RoBERTa-wwm-large | 无 | 80.9 | 98.3 | 86.1 |
| SSN | BERT-wwm-ext | 无 | 83.5 | 98.1 | 90.9 |
| SSN | BERT-base | 无 | 84.3 | 98.3 | 91.3 |

图4 引语归因示例
Fig. 4 Example of quotation attribution
| [m,n] | 上下文平均字数 | 平均候选人数 | 准确率/% |
|---|---|---|---|
| [-5,+5] | 268 | 3.28 | 89.8 |
| [-10,+10] | 552 | 4.32 | 89.2 |
| NUCS | 176 | 2.86 | 91.3 |
表3 CNSI数据集上不同上下文确定方法的对比
Tab. 3 Comparison of different context determination methods on CNSI dataset
| [m,n] | 上下文平均字数 | 平均候选人数 | 准确率/% |
|---|---|---|---|
| [-5,+5] | 268 | 3.28 | 89.8 |
| [-10,+10] | 552 | 4.32 | 89.2 |
| NUCS | 176 | 2.86 | 91.3 |

图 5 不同窗口值确定上下文法的对比
Fig. 5 Comparison of contexts generated by different window value determination methods
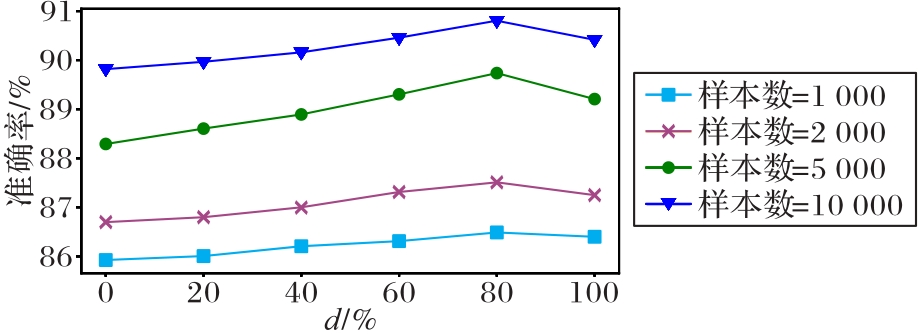
图6 不同数量的样本和不同的d对应的性能
Fig. 6 Performance corresponding to different numbers of samples and different d values
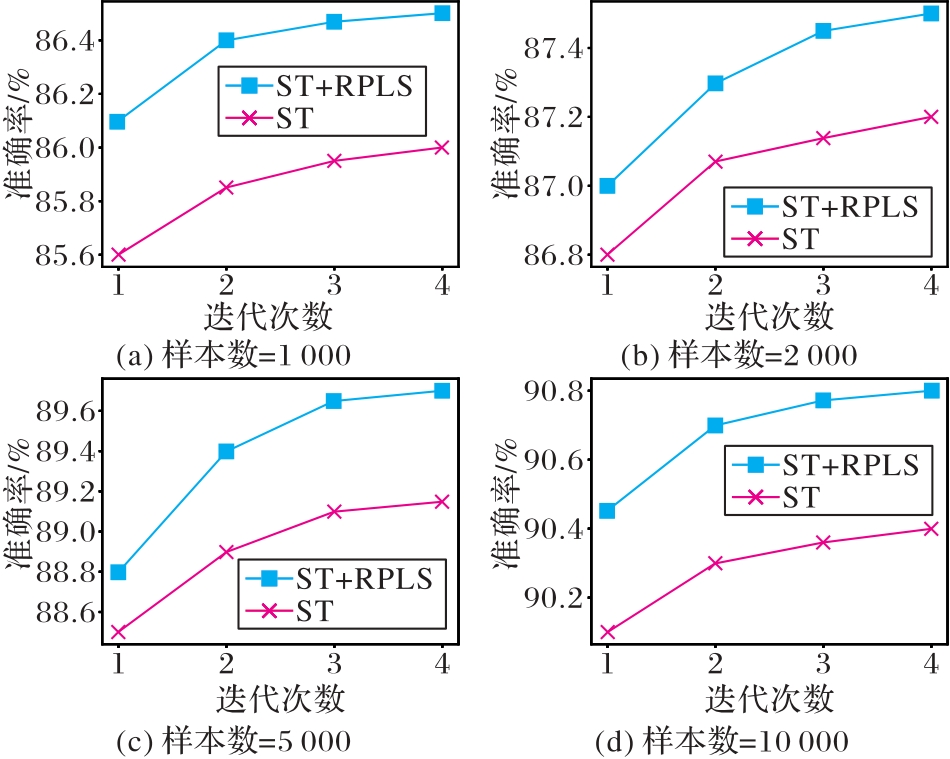
图7 RPLS算法对说话人识别效果的影响
Fig. 7 Influence of RPLS algorithm on speaker identification performance
| 方法 | 不同DL下的准确率/% | ||||
|---|---|---|---|---|---|
| DL=1 000 | DL=2 000 | DL=5 000 | DL=10 000 | DL=20 000 | |
| SSN | 85.9 | 86.7 | 88.3 | 89.8 | 91.3 |
| SSN+ST | 86.1 | 87.2 | 89.1 | 90.4 | 91.4 |
| SSN+ST+RPLS | 86.5 | 87.5 | 89.7 | 90.8 | 91.7 |
表4 消融实验结果
Tab. 4 Results of ablation experiments
| 方法 | 不同DL下的准确率/% | ||||
|---|---|---|---|---|---|
| DL=1 000 | DL=2 000 | DL=5 000 | DL=10 000 | DL=20 000 | |
| SSN | 85.9 | 86.7 | 88.3 | 89.8 | 91.3 |
| SSN+ST | 86.1 | 87.2 | 89.1 | 90.4 | 91.4 |
| SSN+ST+RPLS | 86.5 | 87.5 | 89.7 | 90.8 | 91.7 |
| 1 | ZHANG J Y, BLACK A W, SPROAT R. Identifying speakers in children’s stories for speech synthesis [C]// Proceedings of the 8th European Conference on Speech Communication and Technology. [S.l.]: ISCA, 2003: 2041-2044. |
| 2 | GREENE E, MISHRA T, HAFFNER P, et al. Predicting character-appropriate voices for a TTS-based storyteller system [C]// Proceedings of the INTERSPEECH 2012. [S.l.]: ISCA, 2012: 2210-2213. |
| 3 | PAN J, WU L, YIN X, et al. A chapter-wise understanding system for text-to-speech in Chinese novels [C]// Proceedings of the 2021 IEEE International Conference on Acoustics, Speech and Signal Processing. Piscataway: IEEE, 2021: 6069-6073. |
| 4 | 陈田,蔡从虎,袁晓辉,等. 基于多尺度卷积和自注意力特征融合的多模态情感识别方法[J]. 计算机应用, 2024, 44(2):369-376. |
| CHEN T, CAI C H, YUAN X H, et al. Multimodal emotion recognition method based on multiscale convolution and self-attention feature fusion [J]. Journal of Computer Applications, 2024, 44(2): 369-376. | |
| 5 | POPOV V, VOVK I, GOGORYAN V, et al. Grad-TTS: a diffusion probabilistic model for text-to-speech [C]// Proceedings of the 38th International Conference on Machine Learning. New York: JMLR.org, 2021: 8599-8608. |
| 6 | YU D, SUN K, CARDIE C, et al. Dialogue-based relation extraction [C]// Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics. Stroudsburg: ACL, 2022: 4927-4940. |
| 7 | JIANG Y, XU Y, ZHAN Y, et al. The CRECIL corpus: a new dataset for extraction of relations between characters in Chinese multi-party dialogues [C]// Proceedings of the 13th Language Resources and Evaluation Conference. Paris: European Language Resources Association, 2022: 2337-2344. |
| 8 | ELSNER M. Character-based kernels for novelistic plot structure[C]// Proceedings of the 13th Conference of the European Chapter of the Association for Computational Linguistics. Stroudsburg: ACL, 2012: 634-644. |
| 9 | CHEN R H G, CHEN C C, CHEN C M. Unsupervised cluster analyses of character networks in fiction: community structure and centrality [J]. Knowledge-Based Systems, 2019, 163: 800-810. |
| 10 | BINGENHEIMER M, HUNG J J, WILES S. Social network visualization from TEI data [J]. Literary and Linguistic Computing, 2011, 26(3): 271-278. |
| 11 | RYDBERG C J. Social networks and the language of Greek tragedy[J]. Journal of the Chicago Colloquium on Digital Humanities and Computer Science, 2011, 1(3): 1-11. |
| 12 | AGARWAL A, CORVALAN A, JENSEN J, et al. Social network analysis of Alice in Wonderland [C]// Proceedings of the NAACL-HLT 2012 Workshop on Computational Linguistics for Literature. Stroudsburg: ACL, 2012: 88-96. |
| 13 | JUNG J J, YOU E, PARK S B. Emotion-based character clustering for managing story-based contents: a cinemetric analysis[J]. Multimedia Tools and Applications, 2013, 65: 29-45. |
| 14 | LI J, ZHANG C, TAN H, et al. Complex networks of characters in fictional novels [C]// Proceedings of the IEEE/ACIS 18th International Conference on the Computer and Information Science. Piscataway: IEEE, 2019: 417-420. |
| 15 | GLASS K, BANGAY S. A naïve salience-based method for speaker identification in fiction books [EB/OL]. [2023-12-13].. |
| 16 | SARMENTO L, NUNES S. Automatic extraction of quotes and topics from news feeds [EB/OL]. [2023-12-05]. . |
| 17 | PARK T, KIM S H. Novel character identification utilizing semantic relation with animate nouns in Korean[J]. ACM Transactions on Asian and Low-Resource Language Information Processing, 2018, 17(4): 1-17. |
| 18 | ELSON D K, McKEOWN K R. Automatic attribution of quoted speech in literary narrative [C]// Proceedings of the 24th AAAI Conference on Artificial Intelligence. Palo Alto: AAAI Press, 2010: 1013-1019. |
| 19 | HE H, BARBOSA D, KONDRAK G. Identification of speakers in novels [C]// Proceedings of the 51st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Stroudsburg: ACL, 2013: 1312-1320. |
| 20 | MUZNY G, FANG M, CHANG A, et al. A two-stage sieve approach for quote attribution [C]// Proceedings of the 15th Conference of the European Chapter of the Association for Computational Linguistics: Volume 1, Long Papers. Stroudsburg: ACL, 2017: 460-470. |
| 21 | SHAHIN I. Identifying speakers using their emotion cues [J]. International Journal of Speech Technology, 2011, 14(2): 89-98. |
| 22 | O’KEEFE T, PARETI S, CURRAN J R, et al. A sequence labelling approach to quote attribution [C]// Proceedings of the 2012 Joint Conference on Empirical Methods in Natural Language Processing and Computational Natural Language Learning. Stroudsburg: ACL, 2012: 790-799. |
| 23 | IOSIF E, MISHRA T. From speaker identification to affective analysis: a multi-step system for analyzing children’s stories [C]// Proceedings of the 3rd Workshop on Computational Linguistics for Literature. Stroudsburg: ACL, 2014: 40-49. |
| 24 | YEUNG C Y, LEE J. Identifying speakers and listeners of quoted speech in literary works [C]// Proceedings of the 8th Conference of the International Joint Conference on Natural Language Processing (Volume 2: Short Papers). Stroudsburg: ACL, 2017: 325-329. |
| 25 | CHEN J X, LING Z H, DAI L R. A Chinese dataset for identifying speakers in novels [C]// Proceedings of the INTERSPEECH 2019. [S.l.]: ISCA, 2019: 1561-1565. |
| 26 | JIA Y, DOU H, CAO S, et al. Speaker identification and its application to social network construction for Chinese novels [C]// Proceedings of the 2020 International Conference on Asian Language Processing. Piscataway: IEEE, 2020: 13-18. |
| 27 | CHAGANTY A, MUZNY G. Quote attribution for literary text with neural networks [EB/OL]. [2023-10-13]. . |
| 28 | CHEN Y, LING Z H, LIU Q F. A neural-network-based approach to identifying speakers in novels [C]// Proceedings of the INTERSPEECH 2021. [S.l.]: ISCA, 2021: 4114-4118. |
| 29 | YU D, ZHOU B, YU D. End-to-end Chinese speaker identification [C]// Proceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. Stroudsburg: ACL, 2022: 2274-2285. |
| 30 | ZHANG Y, LIU Y. DirectQuote: a dataset for direct quotation extraction and attribution in news articles [C]// Proceedings of the 13th Language Resources and Evaluation Conference. Paris: European Language Resources Association, 2022: 6959-6966. |
| 31 | ZHOU B, YU D, YU D, et al. Cross-lingual speaker identification using distant supervision [EB/OL]. [2023-03-07].. |
| 32 | SU Z, XU L, XU J, et al. SIG: speaker identification in literature via prompt-based generation [C]// Proceedings of the 38th AAAI Conference on Artificial Intelligence. Palo Alto: AAAI Press, 2024: 19035-19043. |
| 33 | CHEN Y, HE T, ZHOU H, et al. Symbolization, prompt, and classification: a framework for implicit speaker identification in novels [C]// Findings of the Association for Computational Linguistics: EMNLP 2023. Stroudsburg: ACL, 2023: 3455-3467. |
| 34 | DEVLIN J, CHANG M W, LEE K, et al. BERT: pre-training of deep bidirectional Transformers for language under-standing [C]// Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers). Stroudsburg: ACL, 2019: 4171-4186. |
| 35 | LIU Y, OTT M, GOYAL N, et al. RoBERTa: a robustly optimized BERT pretraining approach [EB/OL]. [2024-03-09].. |
| 36 | BROWN T B, MANN B, RYDER N, et al. Language models are few-shot learners [C]// Proceedings of the 34th International Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2020: 1877-1901. |
| 37 | PLATT J C. Sequential minimal optimization: a fast algorithm for training support vector machines [EB/OL]. [2023-06-14]. . |
| 38 | ROSENBLATT F. The perceptron: a probabilistic model for information storage and organization in the brain [J]. Psychological Review, 1958, 65(6): 386-408. |
| 39 | XU L, HU H, ZHANG X, et al. CLUE: a Chinese language understanding evaluation benchmark [C]// Proceedings of the 28th International Conference on Computational Linguistics. Stroudsburg: ACL, 2020: 4762-4772. |
| 40 | ROTH D. Incidental supervision: moving beyond supervised learning [C]// Proceedings of the 31st AAAI Conference on Artificial Intelligence. Palo Alto: AAAI Press, 2017: 4885-4890. |
| 41 | LEE J, YEUNG C Y. An annotated corpus of direct speech [C]// Proceedings of the 10th International Conference on Language Resources and Evaluation. Paris: European Language Resources Association, 2016: 1059-1063. |
| 42 | EK A, WIRÉN M, ÖSTLING R, et al. Identifying speakers and addressees in dialogues extracted from literary fiction [C]// Proceedings of the 11th International Conference on Language Resources and Evaluation. Paris: European Language Resources Association, 2018: 817-824. |
| 43 | PAPAY S, PADÓ S. RiQuA: a corpus of rich quotation annotation for English literary text [C]// Proceedings of the 12th Language Resources and Evaluation Conference. Paris: European Language Resources Association, 2020: 835-841. |
| 44 | VASWANI A, SHAZEER N, PARMAR N, et al. Attention is all you need [C]// Proceedings of the 31st International Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2017: 6000-6010. |
| 45 | PATEL A, LI B, RASOOLI M S, et al. Bidirectional language models are also few-shot learners [EB/OL]. [2023-03-14].. |
| [1] | 杨杰, 尼玛扎西, 仁青东主, 祁晋东, 才让东知. 基于预训练模型标记器重构的藏文分词系统[J]. 《计算机应用》唯一官方网站, 2025, 45(4): 1199-1204. |
| [2] | 李嘉欣, 莫思特. 基于MiniRBT-LSTM-GAT与标签平滑的台区电力工单分类[J]. 《计算机应用》唯一官方网站, 2025, 45(4): 1356-1362. |
| [3] | 王利琴, 耿智雷, 李英双, 董永峰, 边萌. 基于路径和增强三元组文本的开放世界知识推理模型[J]. 《计算机应用》唯一官方网站, 2025, 45(4): 1177-1183. |
| [4] | 孙海涛, 林佳瑜, 梁祖红, 郭洁. 结合标签混淆的中文文本分类数据增强技术[J]. 《计算机应用》唯一官方网站, 2025, 45(4): 1113-1119. |
| [5] | 鲁超峰, 陶冶, 文连庆, 孟菲, 秦修功, 杜永杰, 田云龙. 融合大语言模型和预训练模型的少量语料说话人-情感语音转换方法[J]. 《计算机应用》唯一官方网站, 2025, 45(3): 815-822. |
| [6] | 党伟超, 范英豪, 高改梅, 刘春霞. 融合时序与全局上下文特征增强的弱监督动作定位[J]. 《计算机应用》唯一官方网站, 2025, 45(3): 963-971. |
| [7] | 刘弘业, 陈锡爱, 曾涛. 基于选择状态空间的三模态适配器[J]. 《计算机应用》唯一官方网站, 2025, 45(2): 411-420. |
| [8] | 洪予晨, 李金龙. 基于预训练的符号化音乐生成[J]. 《计算机应用》唯一官方网站, 2025, 45(2): 578-583. |
| [9] | 刘赏, 周煜炜, 代娆, 董林芳, 刘猛. 融合注意力和上下文信息的遥感图像小目标检测算法[J]. 《计算机应用》唯一官方网站, 2025, 45(1): 292-300. |
| [10] | 朱亮, 慕京哲, 左洪强, 谷晶中, 朱付保. 基于联邦图神经网络的位置隐私保护推荐方案[J]. 《计算机应用》唯一官方网站, 2025, 45(1): 136-143. |
| [11] | 李斌, 林民, 斯日古楞null, 高颖杰, 王玉荣, 张树钧. 基于提示学习和全局指针网络的中文古籍实体关系联合抽取方法[J]. 《计算机应用》唯一官方网站, 2025, 45(1): 75-81. |
| [12] | 吴相岚, 肖洋, 刘梦莹, 刘明铭. 基于语义增强模式链接的Text-to-SQL模型[J]. 《计算机应用》唯一官方网站, 2024, 44(9): 2689-2695. |
| [13] | 赵志强, 马培红, 黑新宏. 基于双重注意力机制的人群计数方法[J]. 《计算机应用》唯一官方网站, 2024, 44(9): 2886-2892. |
| [14] | 杜郁, 朱焱. 构建预训练动态图神经网络预测学术合作行为消失[J]. 《计算机应用》唯一官方网站, 2024, 44(9): 2726-2731. |
| [15] | 张春雪, 仇丽青, 孙承爱, 荆彩霞. 基于两阶段动态兴趣识别的购买行为预测模型[J]. 《计算机应用》唯一官方网站, 2024, 44(8): 2365-2371. |
| 阅读次数 | ||||||
|
全文 |
|
|||||
|
摘要 |
|
|||||